基于机器学习的交通安全对话机器人开发
2023-02-21张思楠郭佳陆磊周海辰陈菁菁
张思楠 郭佳 陆磊 周海辰 陈菁菁
关键词:交通安全;青少年;宣传教育;机器学习
1引言
青少年是道路交通事故的主要受害者之一。世界卫生组织数据表明,2016年约有18万名儿童死于道路交通事故,道路交通伤害成为所有年龄段的第八大死亡原因,也是5~29岁儿童和年轻人死亡的主要原因。我国每年约有1万名儿童死于道路交通伤害,道路交通伤害是我国儿童第1位死亡原因。
交通安全意识匮乏,是导致青少年交通安全事故发生的重要原因之一。青少年交通安全知识宣传教育是研究者长期关注的重要研究课题。王丽等[1]发现不同学校在交通安全知识与行为等方面存在显著差异,并提出对低年级学生应该侧重于交通安全知识教育,对高年级学生注重交通行为规范。Gao等[2]调查研究了国内五所幼儿园,结果表明学生不喜欢阅读相关书籍和观看视频等传统的交通教育方式。孟子慕等[3]基于深度学习算法,开发了儿童交通安全人机互动问答机器人。周丽嫦等[4]通过设计交通安全游戏,加强幼儿的交通安全意识。
首先,现有的校园交通安全教育宣传大多集中于每年的全国道路交通安全宣传日,无法达到长效宣传效果。其次,青少年活泼好动,动手能力强,对枯燥的文本宣传方式不感兴趣。综上所述,有必要研究开发一款操作简单便捷、教育形式灵活多样、用户互动参与度高的交通安全宣传教育软件,以对青少年进行交通安全教育。
项目组研发了一种适用于青少年交通安全法规知识教育的语音对话机器人软件,通过语音互动方式进行《道路交通安全法》的学习,从而提高青少年学习交通安全知识的主动性和趣味性,切实增强青少年的交通安全意识。
2软件设计
2.1整体技术流程
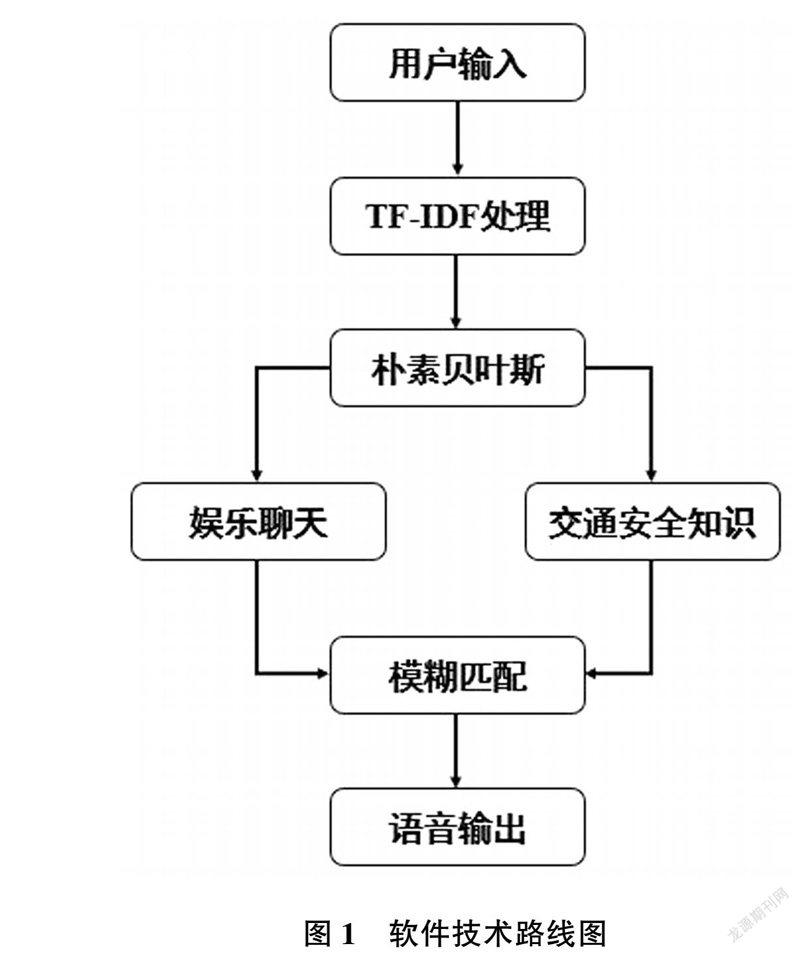
交通安全对话软件基于机器学习Sklearn框架,以PyCharm作为软件的开发环境,可視化界面采用wxPython工具包完成。交通安全对话软件针对的咨询问题比较明确,大多涉及交通规则知识,常见的问题和法律法规可以通过相关网站获得。其次,还需要小部分的娱乐话题,用于增加聊天的趣味性。软件技术路线图如图1所示。
2.2基于搜索和语料库的聊天功能
由于该软件的定位比较明确,适用人群为青少年群体,因此在软件功能和界面的设计上较为简单清晰。整个页面由两个聊天对话框和两个按钮组成,两个聊天对话框分别展示使用者和后台所输出的语音,两个按钮分别实现开始聊天和结束聊天功能。
聊天对话实现的大致流程如下。
(1)语音识别(Speech Recognition):对用户输入的语音进行语音识别,并把识别到的文本展示到前端界面。
(2)分词(Word Segmentation):对识别后的文本采用jieba模块进行分词操作。
(3)数据预处理(Data Preprocessing):用户输入的语音极大可能带有其他冗余字词,首先要对分词后的文本进行检查并纠正。建立停用词表,词表包含助词、连词、量词等对文本分类没有实质性影响的无关信息词汇[5],去除无关词可以更好地与提问者所提出的问题进行匹配。
(4)计算文本相似度(Text Similarity):对预处理后的数据和语料库中的问题进行比对,采用基于行连接存储的稀疏矩阵计算文本之间的相似度。
(5)排序(Sort):根据计算的文本相似度进行排序,获取相似度最高的3个问答作为返回结果。
(6)过滤结果(Filter Results):将上一步骤结果做最后一层过滤,采用模糊匹配技术,将相似度最高的问答作为结果语音输出给用户,同时将文本展示在对话框中。
2.3基于机器学习的问题类别预测功能
该问答软件针对的领域比较明确,为快速匹配交通安全相关知识,需要建立自定义词表。词表里存放交通领域中经常出现的词汇,用以和用户输入的语音进行比对。采用逻辑表达式、朴素贝叶斯等方法对用户输入的问题进行预测分类。
3具体流程和相关技术分析
3.1语音识别
利用Python中的PyAudio库进行语音的识别。PyAudio提供了PortAudio的Python语言版本,该库具有录音、播放、生成wav文件等功能,是一个跨平台的音频I/O库。在用户说话时进行录音,生成对应的wav文件,应用百度API进行语音识别,并转写成中文文本,供其他步骤使用。
3.2数据处理
在数据处理部分,除上述建立停用词表和自定义词表外,还需要对主要语料库进行填充。将《道路交通安全法》以[类别、问题、回答]的格式保存到CSV外部文件。在程序中读取语料库采用pickle工具包,将预处理后的语料库CSV文件序列化至本地,进而在下次使用语料库时不需要再次进行预处理,能够有效节省处理的时间。同样,修改语料库后则需重新将CSV文件序列化至本地,生成对应的模型文件。
3.3TF-IDF
在文本分类过程中,需要识别输入文本中的重要特征词汇,软件使用TF-IDF技术[6]评估词汇的重要程度。TF-IDF的原理是字词的重要性会随着它在文件中出现的次数成正比增加,同时会随着它在语料库中出现的频率成反比下降。换言之,一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章,因此可以通过计算TF和IDF的值来衡量文字特征重要程度。引入TF-IDF的目的在于为后续的朴素贝叶斯分类器服务,朴素贝叶斯无论是训练或是预测,均要求输入必须是数学形式,才能输入分类器中进行训练和预测。Sklearn框架实现的TF-IDF算法不能完全满足程序的要求,为解决训练和预测时维度不同的问题,需要对算法针对性做两处改进。一是对于训练和预测样本的TF-IDF处理均放置在一个函数中完成,可以保证数学矩阵输出时的维度一致性;二是使用toarry函数将TF-IDF处理得到的稀疏矩阵转换为稠密矩阵,保证维度一致,方便后续进行进一步处理。
3.4朴素贝叶斯分类
软件使用的语料库分为娱乐聊天语料库和交通安全知识语料库两种,需要使用贝叶斯分类器对用户输入进行分类,以便匹配不同的数据库完成更加精准的输出。Python中sklearn根据不同场景提供了三种常用的朴素贝叶斯模型,即
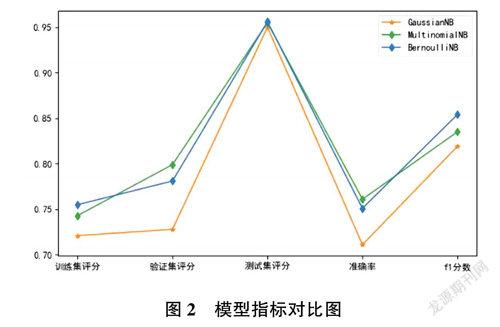
GaussianNB,MultinomialNB和BernoulliNB。为了测试模型与软件所使用语料库的匹配程度,以软件使用的交通知识语料库和娱乐语料库为数据基础,建立模型测试数据集和训练数据集。分别使用三种模型对数据集进行训练和预测,得到的模型指标如图2所示。
如图2所示,在小规模训练集下,朴素贝叶斯算法的三种模型指标比较稳定,在三个模型中MultinomialNB和BernoulliNB多用于文本分类,但BernoulliNB适用于二元离散值样本特征。软件所使用的数据集中特征量较大,不宜使用BernoulliNB。MultinomialNB在处理交通数据集时所表现的综合效果最好,与数据集更匹配[7]。
3.5fuzz模糊匹配
当用户提出的问题需要与语料库中的问题进行对比时,使用字符串模糊匹配(fuzzy string matching)实现。用户的输入经过一系列格式化处理转换为可以适配的格式后,与事先构建的语料库问题进行匹配,返回匹配程度高的问题并将对应的答案作为程序的输出。输出的结果进行格式化处理,转换为语音进行文字播报,同时输出至图形化用户交互界面。
4结束语
(1)本文介绍了基于机器学习的交通安全对话软件从设计到实现的全过程。依托Python对《道路交通安全法》进行了文本分割、特征识别,利用机器学习sklearn框架建立了文本识别匹配模型。(2)在文本识别的基础上,对比了朴素贝叶斯的三种模型指标,结果表明软件所使用的MultinomialNB模型在交通数据集上有更好的表现。(3)在软件的基础上,可以建立家庭、学校和社会三位一体的长效宣传教育机制,从而不断提高青少年的交通安全意识,增强交通法规意识。(4)从实际应用方面考虑,首先,末来仍需不断更新语料库,并扩大问答软件的聊天范围,进一步提高软件的可互动性。其次,可以将软件移植到硬件机器人上,使软件更具独立性和趣味性。
