基于机器学习模型的HSE审核短文本分类技术研究*
2023-01-14王梦涵贺辉宗厉建祥贺伟东李绪延辛一男石秀丽
王梦涵,贺辉宗,厉建祥,贺伟东,李绪延,辛一男,石秀丽
(1.中石化安全工程研究院有限公司,山东青岛 266104 2.中石化管理体系认证(青岛)有限公司,山东青岛 266071 3.中国石化北京石油分公司,北京 100022)
1 研究背景与现状
目前,石油化工行业HSE管理体系审核量化精度较低、审核重点精准度不足[1],如何挖掘审核历史数据中的有效信息成为亟待解决的问题。通过对文本进行自动分类分析,为审核的策划实施提供智能辅助,从而发现企业HSE管理需要重点关注的问题,促进HSE管理向数据驱动型方向发展。李绪延,等[2]通过分析审核历史数据,建立具有审核知识库和专业分析模型的审核工具,支撑HSE管理体系审核工作的开展,并实现审核结果的反馈和横纵向多维对比分析。
审核过程中收集的不符合项描述短文本数据,多采用自由文本形式,往往具有结构不统一、描述不规范、专业词汇多、语义关系弱、文本长度短等问题[3],基于自然语言处理(NLP)的机器学习文本分类技术是处理此类问题的有效方法。文本分类是指,给定文档集和一个类别集(标签集),利用某种学习方法或算法得到分类函数,将文档集中的每一篇文档映射到类别集中的一个或多个类别中[4]。常用的文本分类算法包括SVM、KNN、决策树、朴素贝叶斯等,何伟,等[5]采用考虑特征信息增益的深度加权朴素贝叶斯方法对中文文本进行分类,并对比了多组中文文本数据的分类效果。结合相关领域的研究基础,对比多种分类算法后提出了一种融合专业知识词典和机器学习模型的短文本分类方法。
2 HSE审核分类标签体系构建
针对目前HSE审核短文本的分类维度较多的现状,基于某石化公司HSE管理体系6个方面的两层分类指标,构建HSE审核短文本分类模型。该模型二级指标包含领导承诺和责任、策划、支持、运行过程管控、绩效评价、改进;三级指标包含34个,如图1所示。

图1 HSE审核分类标签体系
某石化公司HSE管理体系审核信息化系统中包含的不符合项文本信息,涉及某石化公司29个专业的业务流程,包含油气勘探开发、炼油化工、油品销售、石油工程、炼化工程等核心业务板块审核发现的不符合项信息,共有11 003条。不符合项信息包含不符合项描述、不符合项标签、专业领域、所在企业、整改情况、严重程度、责任部门等内容。通过选取问题文本中的关键词汇,构建初始分类标签词库,从而实现对以上信息的自动分类,辅助识别主要不符合项来源,筛选影响企业提升安全管理水平的主要因素。以二级指标“策划”为例,包含不同分类维度的四级标签词汇39项,如表1所示。

表1 不符合项指标分类
3 基于机器学习模型的文本分类方法
文本分类方法包含无监督分类方法、有监督分类方法以及半监督分类方法。有监督分类方法需要人工标记训练集中的样本类别。无监督分类方法无需对样本进行标注,模型计算生成分类结果,具有不确定性。由于无法预设样本数据的分类类别,仅依靠样本的参数与标签信息来推导分类的结果[6-7],获得符合期望的分类结果概率较低。综合以上因素,采用半监督关键词提取方法,以兼顾人为干预的准确性与模型训练的高效性。通过借助少量语料训练模型,利用模型对未标注文本的关键词进行提取,人工对提取结果进行干预,将正确的标注加入训练数据集中进行模型训练,基于模型方法进行文本分类的流程如图2所示。

图2 基于模型方法的文本分类流程
3.1 文本数据集选取
审核文本语料库构建基于审核系统中积累的不符合项文本数据,共计11 003条。样本集划分为训练集和测试集两个部分,训练集用于分类模型的学习,占整个文本集的70%;测试集用于评价分类模型,占整个文本集的30%。
3.2 文本数据预处理
短文本分类任务开始前,需对语料进行数据预处理,主要包括分词、停用词过滤、异常值处理等内容。
a) 分词。抓取审核系统中的不符合项文本数据作为实验语料,中文分词采用Jieba分词工具,并导入自定义词典进行专有名词识别。
b) 停用词过滤。通过导入哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库和安全管理专业停用词表进行数据清洗,过滤掉停用词以及标点符号。
c) 异常值处理。此次导入的审核短文本中,由于前期人为录入的不确定性,存在部分异常的词汇,通过人工对异常进行修正,去除错误词汇,从而为后续的文本分类提供辅助。
经过上述处理,将得到更高质量的短文本数据集,利用清洗后的数据及分类关键词进行后续的短文本分类实验,从而提升分类效果。
3.3 文本关键词抽取
词频-逆文档频率(TF-IDF)是一种基于统计特征的关键词提取方法,用于评估标签词重要程度。词频-逆文档频率认为词汇在文本中出现次数越多则越重要,同时在文本集中出现次数越多则不具有特征区分能力。词频(Term Frequency,TF)指词语在指定文本中出现的频率,计算过程需要对词数进行归一化处理,以防止长文本词数值偏高。设词wi在文本dj中出现的词频记为Ti,j(i,j=1,2,…,n),计算方法见式(1)。
(1)
式中:ni,j——词wi在文本dj中出现的次数;
∑nj——文本dj中所有字词出现次数之和;
Ti,j——词在文本中出现的词频。
设词wi在所有文本中出现的逆文本频率记为IDFi,计算方法见式(2)。
(2)
式中:|j:wi∈dj|——包含词wi的文本数量;
|D|——语料文本集数量。
词wi针对文本dj的TF-IDF值记为τi,j,计算方法见式(3)。
τi,j=Ti,j·IDFi
(3)
可以看出,τi,j值越大,说明wi具有更好的特征区分能力,则wi对于D的重要性也就越高,而IDFi值越大说明wi在部分文本内的出现频次越高,则wi具有更好的特征区分能力。通过计算τi,j值将一个给定文本dj同其对应的所有分类标签关联起来。设文本dj的词集|Dj|=m,将Dj中每个词wi,j,根据其τi,j值大小进行排序,记为Dj={w1,j,w2,j,…,wm,j}。
逐条计算系统中不符合项文本数据的文本分词重要度,得到分词TF-IDF值。以“风险识别与评估”标签下的不符合项为例,在重要度计算结果中选取TF-IDF值排名前10的文本特征词汇作为将来的分类标签库的待补充关键词,得到不符合项分类关键词排序如表2所示。

表2 不符合项分类关键词TF-IDF排序
3.4 分类器的选择与训练
对比了短文本分类常用的分类方法,包含逻辑回归和多项式朴素贝叶斯模型与支持向量机模型。
3.4.1 逻辑回归模型
逻辑回归(Logistic Regression,LR)算法是一种常用的非线性二分类因变量回归统计模型,具有速度快、实现简单及存储资源低等特点,在机器学习领域也得到了广泛应用。逻辑回归算法是在线性回归算法基础上,将最终分类结果采用Sigmoid函数进行映射以应对非线性情况,使得输出结果在[0,1],根据输出数值的大小划分样本的类别。
3.4.2 多项式朴素贝叶斯模型
多项式朴素贝叶斯模型(Multinomial Naive Bayes,MNB)将文档看作词袋模型,考虑词汇在文本中的出现频率对预测文本类别的影响。
文本类别C={C1,C2,…,Cn},对于给定的文本集D={D1,D2,…,Dn},设Di为文本集中任意一条文本,包含m个特征词汇Di={t1,t2,…,tm},将其对应的最大的后验概率的类别作为文本Di的分类类别,后验概率计算方法见式(4)。
(4)
式中:Cj——类别集合C中的某一特定文本类别;
P(Cj)——类别Cj出现的概率;
P(Di|Cj)——文本Di属于类别Cj的条件概率;
P(Di)=P(t1,t2,…,tm)——所有特征的联合概率。
贝叶斯分类的过程就是求解P(Cj|Di)最大值的过程,对于给定的训练文本,P(Di)是个常数。因此,求解过程可转化为求解式(5)。
(5)
式中:Cmap——最终的分类结果。
根据条件独立性假设对式(5)进行简化,见式(6)。

(6)
式中:m——特征单词数;
tk——(k=1,2,3…,m)表示文档Di中的第k个特征词。
先验概率P(Cj)和条件概率P(tk|Cj)分别由式(7)和式(8)计算得到。
(7)
(8)
式中:n——总的训练文档数;
v——表示类别个数;
Ci——第i篇训练文档的类别;
TFitk——特征词在文档Di中的出现频数;
δ——二值函数。
在此基础上,可对特征词进行加权处理。由于每次计算的概率值可能会比较小,通常对计算结果取对数处理。
3.4.3 持向量机模型
相比于对逻辑回归、多项式朴素贝叶斯等机器学习方法,支持向量机(Support Vector Machine,SVM)基于统计方法分类精度较高,鲁棒性强,是目前解决实际问题效果较好的一种机器学习算法。
SVM将文本向量数据映射到高维数据空间,计算获取分割超平面,平面与数据的间隔距离越大,说明分类的效果会越好,决策边界面方程如式(9)所示。
W·X+b=0
(9)
式中:X——平面上的点;
W——平面上的法向量,决定了超平面的方向;
b——实数,代表超平面到原点的距离。
标准SVM分类模型属于二值分类。实际情况中,多数样本的类别都会大于两类,属于多类分类问题。为此需要对标准SVM进行扩展以满足多分类需求[8-9]。
对于一个给定的训练样本集,并用(xi,yi)来表示,假设样本数量为n,共有k个类别,xi表示输入的训练数据,yi表示输出的类别,其中,i=1,2,…,n,yi∈{1,2,…,k},通过测试训练样本构建一个分类函数见式(10),将两个平行的超平面作为间隔边界以判别样本所属的类别。
(10)
对上述二值分类问题拓展到多类分类问题,文本的分类函数如式(11)所示。
(11)
4 分类效果评估指标
目前,文本分类通常选择准确率A(即所有的预测正确类别占总类别的比重)、精确率P(即正确预测为正的占全部预测为正的比例)、召回率R(即正确预测为正的占全部实际为正的比例)和综合指标F1值等评价指标对分类效果进行评价。
F1值是反映分类器整体性能的指标,F1值越大,分类效果越好。F1值的计算方法见式(12)。
(12)
5 实验结果与分析
算法测试所使用的样本共计11 003条问题,其中训练样本7 703条,测试样本3 300条,各二级标签样本占比如图3所示。问题可能同时具备多个类别标签,当同时匹配到多个关键词时,根据优先级标注规则进行判断,优先匹配权重更高的标签词类别。
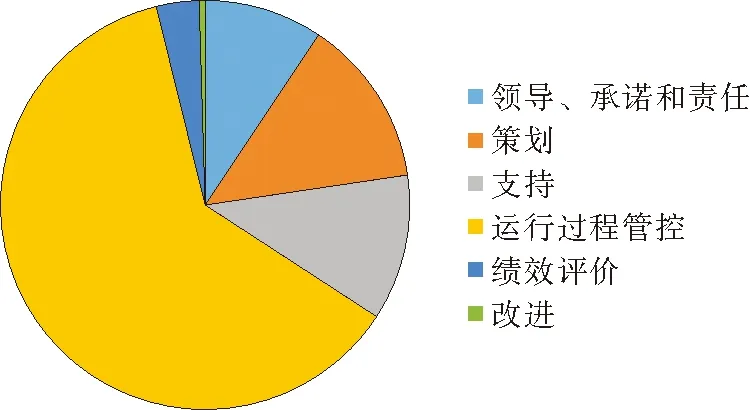
图3 不同分类标签占比
去除样本数过少的干扰类别,计算各类别预测宏平均值,采用准确率、精确率、召回率以及F1值作为验证指标,对分类结果进行对比,同时考虑使用安全管理专业词表对于分类结果的影响,实验结果如表3所示。通过对比可以发现在使用专业词典的条件下,分类准确率均有所提升,综合对比三类算法SVM性能优于其它两种算法。

表3 不同分类模型预测效果对比
6 结论
尝试对审核短文本进行分类,通过半监督学习的方法进行特征选择,根据业务和管理流程建立审核不符合项关键词标签体系,包含4级指标,其中第四层指标包含247个类别。使用4层指标对样本数据进行人工标注,采用基于关键词和基于机器学习模型的方法对审核不符合项样本数据进行文本分类,在现有TF-IDF关键词提取方法的基础上,对关键词库中的词汇给予更合理的权重系数,人工对候选关键词的评分进行了修正,使提取出的关键词更符合问题文本主题。验证了文本分类方法在HSE审核短文本分类场景下的应用效果,解决了短文本篇幅较短,关键词提取准确率较低的问题,最终结果表明SVM模型分类效果更优,适用性强。通过对HSE审核短文本的分类分析,有效利用了HSE管理体系审核数据,为企业HSE管理决策提供科学的数据支撑。
