Cross‐domain sequence labelling using language modelling and parameter generating
2022-12-31BoZhouJianyingChenQianhuaCaiYunXueChiYangJingHe
Bo Zhou|Jianying Chen|Qianhua Cai|Yun Xue|Chi Yang|Jing He
1School of Electronics and Information Engineering,South China Normal University,Foshan,China
2Department of Neroscience,University of Oxford,Oxford,Oxfordshire,Britain
Abstract Sequence labelling(SL)tasks are currently widely studied in the field of natural language processing.Most sequence labelling methods are developed on a large amount of labelled training data via supervised learning,which is time‐consuming and expensive.As an alternative,domain adaptation is proposed to train a deep‐learning model for sequence labelling in a target domain by exploiting existing labelled training data in related source domains.To this end,the authors propose a Bi‐LSTM model to extract more‐related knowledge from multi‐source domains and learn specific context from the target domain.Further,the language modelling training is also applied to cross‐domain adaptability facilitating.The proposed model is extensively evaluated with the named entity recognition and part‐of‐speech tagging tasks.The empirical results demonstrate the effectiveness of the cross‐domain adaption.Our model outperforms the state‐of‐the‐art methods used in both cross‐domain tasks and crowd annotation tasks.
1|INTRODUCTION
Linguistic sequence labelling(SL)is one of the classic tasks in natural language processing(NLP)whose purpose is to assign a label to each unit in a sequence and thus map a sequence of observations to a sequence of labels[1].As a pivot step in the most NLP applications,SL is widely applied to numerous real‐world issues including but not limited to part‐of‐speech(POS)tagging[2],named entity recognition(NER)[3]and word segmentation[4,5].Basically,SL algorithms exploit the manually‐labelled data,based on which effective approaches are required for leveraging distinctive features from limited information[6].Previous studies employing the supervised learning models mainly depend on high‐quality annotations of data[7].In such studies,the collection of annotated data is both time‐consuming and expensive.More recently,there is an ongoing trend to apply deep‐learning‐based models to detect the distinctive feature in SL tasks[8].Specifically,the recurrent neural network(RNN)is both creative and practical in obtaining the long‐term relation within sequential structure[2].
More recently,the SL of cross‐domain is pronounced.Ongoing studies report that parameter transferring and language model show their superiorities in cross domain adaptation[9].On the one hand,parameter transferring contains parameter sharing and generating.By using trained models,the former aims to transfer the shared information from the source domain to target ones[10],while the latter result in a variety of learnable parameters for information extraction across different domains[11].On the other hand,LM is capable of capturing both the targets and the context patterns during training[12].As reported in Ref.[13],on the task of named entity recognition(NER),the transferring of knowledge is performed by contrasting large raw data in both domains through cross‐domain LM training.Besides,the effectiveness of attention mechanisms is also highlighted due to its dynamically aggregating the specific knowledge among sources[7].
Notwithstanding,the use of the aforementioned approaches are still limited mainly because there is a significant drop for domains of big differences.That is,current methods fail to apply the trained model to the target domain whenever the shared knowledge is absent.In spite of the adaptation into one single target domain,the knowledge transferring to a variety of new domains is still challenging.Furthermore,while restricted to modelling training in a source domain,the learning of specific knowledge within the target domain has the potential to benefit the SL tasks as well.
There is a considerable gap between effectively delivering the trained model to multi‐domains and the state‐of‐the‐art results.In this work,we tend to approach this problem in two ways,that is,extracting shared information from multi‐source domains and learning specific knowledge from the target domain.In this way,based on the Bi‐LSTM model,an accurate and efficient approach for SL among distinguishing domains is designed and deployed.Typically,our contributions are threefold:
(1)Parameter sharing is conducted via the model training process within multi‐tasks and multi‐domains.Besides,the model parameters are specifically selected in line with the context of the target domain.
(2)LM is dedicatedly established and performed as the pretraining task of the model,which aims to learn the contextual information and domain‐specific knowledge.
(3)The attention mechanism is applied to collect the domain‐specific knowledge from different source domains.In this way,more relevant information from source domains is conveyed to the target domain.
2|RELATED WORK
2.1|Sequence labeling(SL)
Classical methods for SL are generally linear statistical models,including Hidden Markov Models(HMMs)[14],Maximum Entropy Markov Models(MEMMs)[15],Conditional Random Fields(CRFs)[16]etc.All these models heavily rely on the hand‐crafted features and task‐specific resources.In contrast,the deep neural networks facilitate the process by automatically extracting features from raw text via model training.Both CNN‐and RNN‐based models are built up to deal with such issues.Zhao et al.[1]propose a Deep Gated Dual Path CNN architecture to capture a large context through stacked convolutions.Yang et al.[10]devise a transfer learning approach based on a hierarchical RNN that exploits the information from different lingual/domain data sets by sharing multi‐task model parameters.As a commonly‐used RNN variant,long short‐term memory(LSTM)is widespread in existing studies.With the integration of CRF,BiLSTM‐based methods are deemed best able to achieve state‐of‐the‐arts performance across various SL tasks[2,6,17].
2.2|Parameter transferring
Generally,the main purpose of parameter transferring is to improve the performance on a target task by joint training with a source task.Parameter sharing,well‐known for its use in across‐languages/domains/applications,has an impressive performance in tasks with fewer available annotations[10,18].With the combination of domain properties,not only the domain specific parameters but also the representation vectors can be derived[19].Nevertheless,multi‐task learning based on parameter sharing has the limitation in parameter setting due to potential conflict of information[13].In an effort to mitigate this deficiency,parameter generating is one such direction,with previous publications exploring its feasibility and validating its efficacy.Platanios et al.[11]devise a contextual parameter generator(CPG)that generates the parameters for the encoder and the decoder of a neural machine translation system.On the task of NER,Jia et al.[13]propose a parameter generating network of deep‐learning models to transfer knowledge across domains and applications.
2.3|Language model
So much is the significance of training the model that language models(LMs)are employed in neural networks to obtain specific representations in multi‐tasks[20].Liu et al.[21]construct a task‐aware neural LM termed as LM‐LSTM‐CRF,which incorporates character‐aware neural LM to extract character‐level embedding.Liu et al.[22]propose a way of compressing LM as a module of RNN.Accordingly,the LM for preserving useful information with respect to specific tasks can be applied to cross‐domain SL tasks.
3|OUR APPROACH
3.1|Problem definition
For a given sentenceSi=[Si,1,Si,2,…,Si,n]from multi‐source domains,we takeskas thekth source domain andstas the target domain.Let Θ=(W⊗Ik)(k=1,2,…,p)be the parameters involved in each domain whereWstands for the shared parameters andIkfor the domain‐specific parameters and⊗is the tensor contraction processing.That is,the parameters for every source domain are the integration ofWandIk.Similarly,in the target domain,we have the parameters composing ofW,Ilmtandwhereis pretrained from the language model task andItslis the outcome of integratingIkand the target‐domain contexts.Figure 1 presents the framework of the multi‐domain SL task,which is the base of our model.
3.2|Model establishing
Figure 2 shows the architecture of our model.For each input sentence,the proposed model firstly maps the words into word embeddings via the shared input layer.Subsequently,a Bi‐LSTM is employed for context encoding and a parameter generator is taken to resolve the parameters of Bi‐LSTM within the parameter generating layer.Specifically,for the inputs of SL tasks,the attention mechanism is also applied to parameter generating.Lastly,the outcomes are sent to different tasks in line with the processing in the output layer.
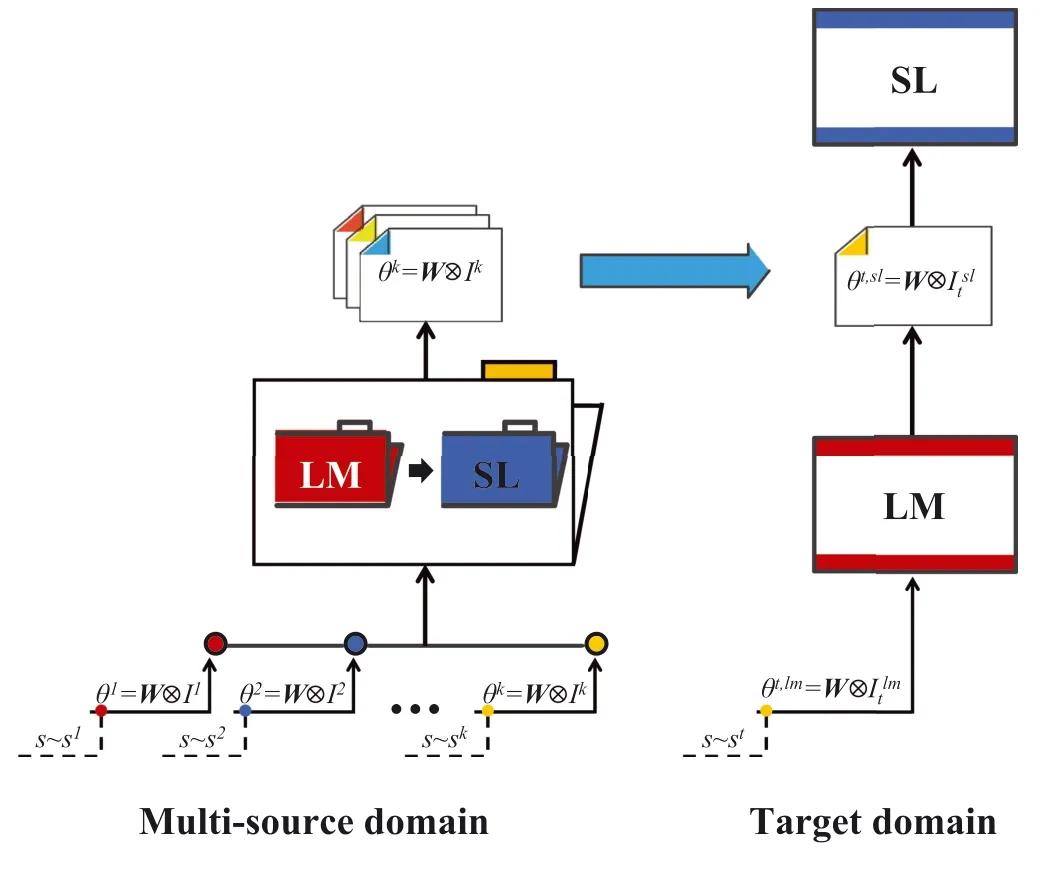
FIGURE 1 Illustration of using the multi‐source domain model in SL.SL represents sequence labelling tasks and LM represents language modelling
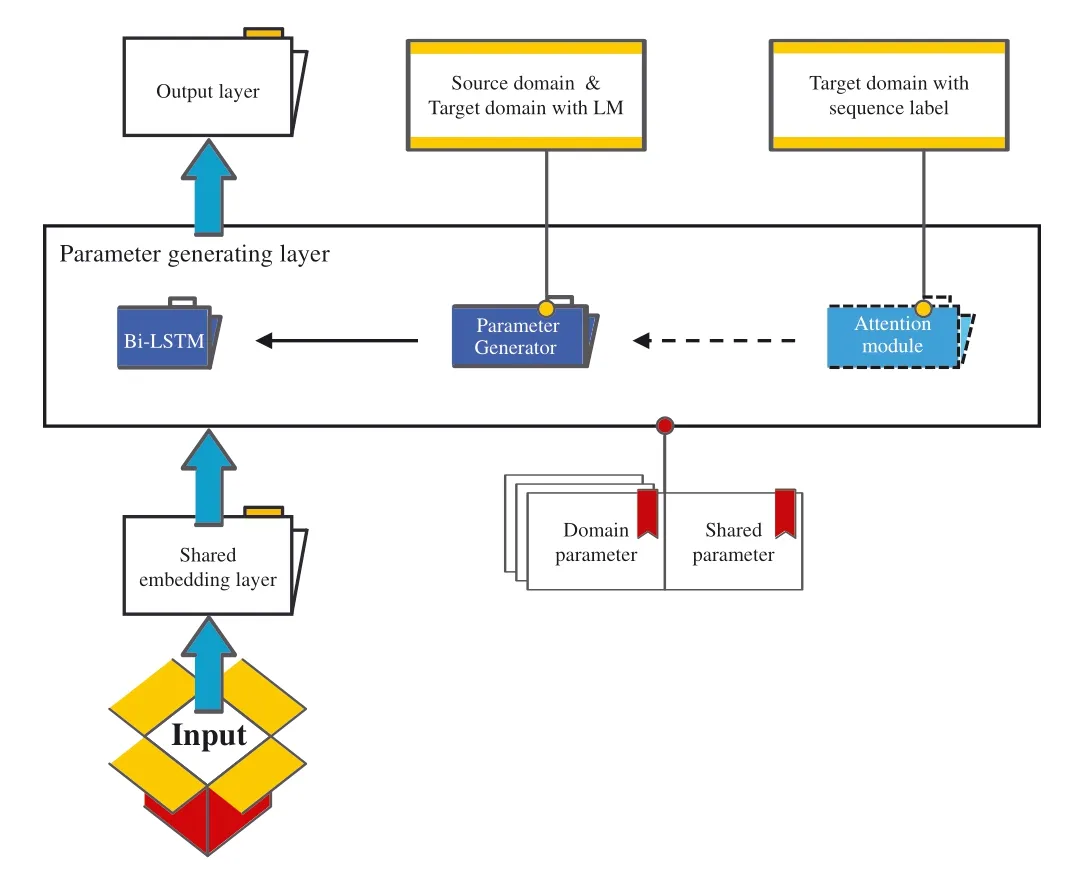
FIGURE 2 Model overview
The following sections describe each component of the proposed model in more detail.
3.3|Shared embedding layer
We define a sentence collectionS=[S1,…,Si,…,Sm]with the corresponding label
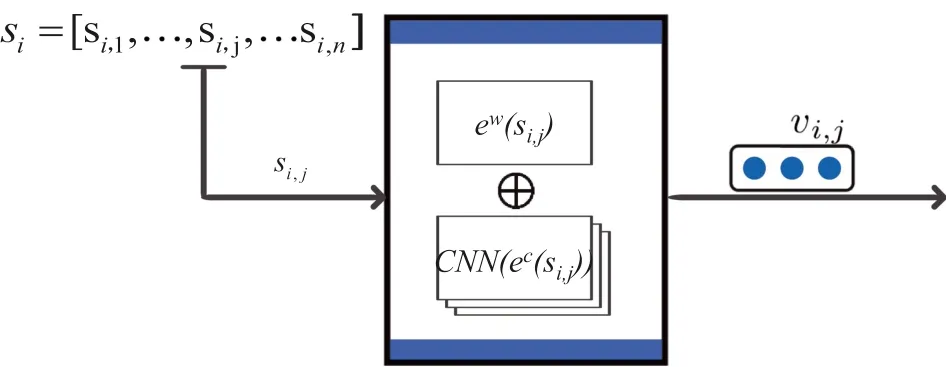
FIGURE 3 Concatenation principle of word embedding and character embedding.Module input:a word from a given sentence;module output:concatenation of word embedding and character embedding
that comes from the target domain and of SL tasks.Letbe the input sentence with the corresponding label.On the task of SL,the input from thek(k=1,2,…,p)‐th source domain is defined aswhile that of the target domain is.Similarly,the related raw text in thekth source domain isand that in the target domain is given as.
As shown in Figure 3,in this layer,a convolutional neural network(CNN)is performed to extract the character‐level features from the input sequence,whose outputs are concatenated with the word embeddings.Accordingly,we have the layer output as follows:
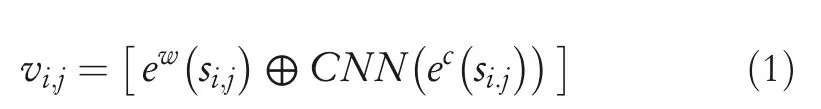
wherevi,jis the word representation of wordsi,j,ewis a shared word embedding lookup table andecis the specific shared character embedding lookup table.
3.4|Parameter generating layer
The parameter generating layer is constructed on the basic Bi‐LSTM,which aims to transfer knowledge across domains via parameter transferring.In addition to the shared parameter,a parameter generator is devised for Bi‐LSTM parameter determination.Figure 4 shows the parameter transferring scheme together with its principle.Concretely,each input sentence can be classified into the following category based on the type of task and the specific domain:
If a sentence is of either the LM task or SL task from the source domain(s),the Bi‐LSTM parameter set is generated directly in the parameter generator.
If a sentence is of the LM task from the target domain,the Bi‐LSTM parameters are generated directly in the parameter generator.
If a sentence is of the SL task from the target domain,the Bi‐LSTM parameters are generated with the parameter generator and attention.
Basically,for a sentence from the source domain,the parameter setapplied to Bi‐LSTM is delivered as follows:
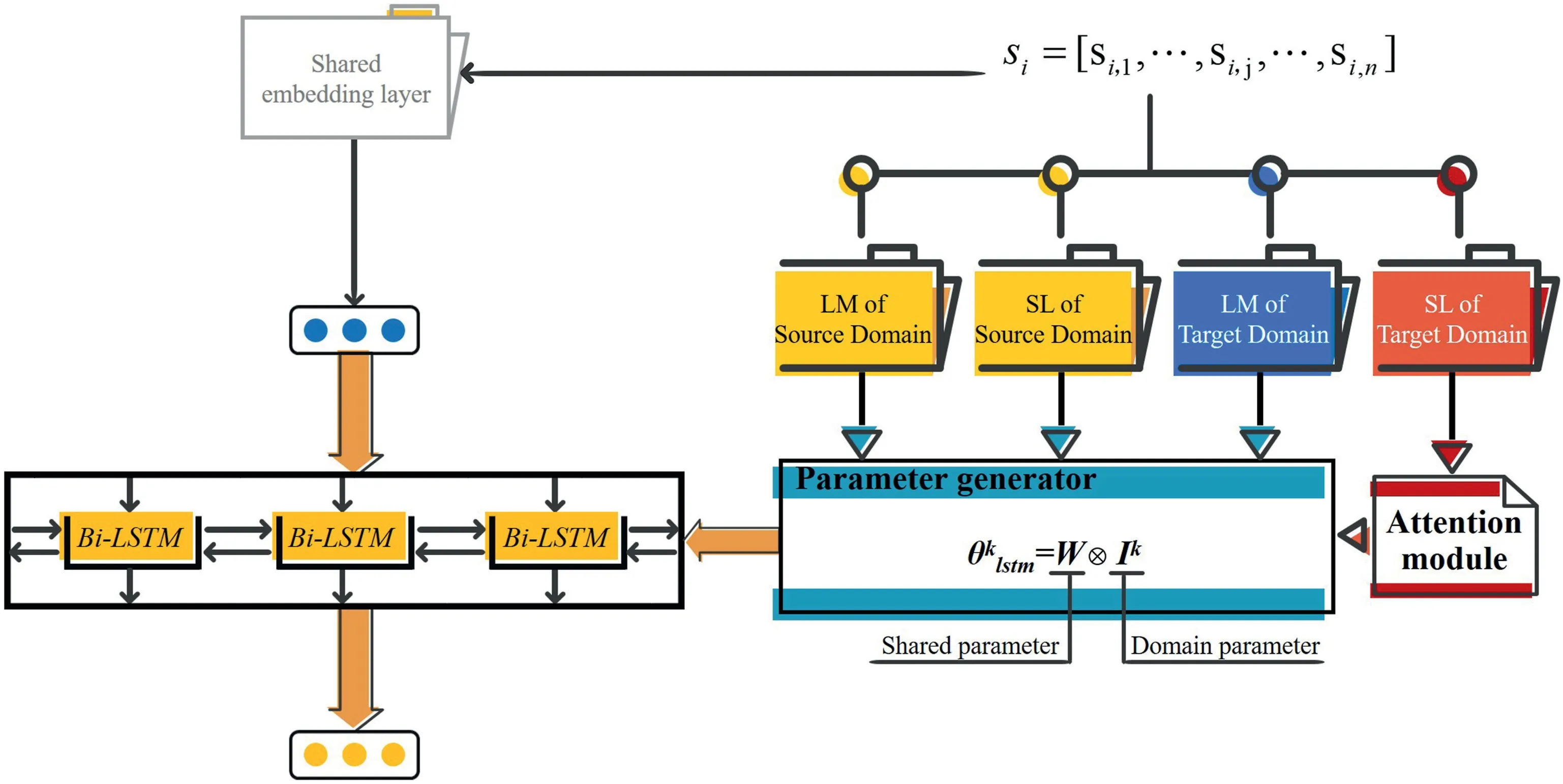
FIGURE 4 Parameter generation principle.Module input:a sentence of the target domain or multi‐source domains;module output:long short‐term memory(LSTM)hidden state of each word in the sentence

whereWstands for the shared parameter withWϵRP(LSTM)×UandIkindicates that from thekth source domain withIkϵRU;P(LSTM)is the total number of parameters;⊗refers to processing of tensor concatenation.
With the word representationvi,jfrom the shared embedding layer sent to the Bi‐LSTM,the outputs of hidden states of both forward and backward directions are derived as follows:

Similarly,for the sentence of the LM task from the target domain,the parameters of Bi‐LSTM is obtained in the same process as presented in Equation(2)‐(4).Notably,this LM task is considered as a pretraining step of SL,whose parameter set can be further exploited in SL tasks.
In terms of input of the SL task from the target domain,the attention module is carried out to facilitate the parameter generating(see Figure 5).Based on the pretraining from LM,we have the representation of sentencesiby concatenating the last hidden states of forward LSTM and backward LSTM,which is
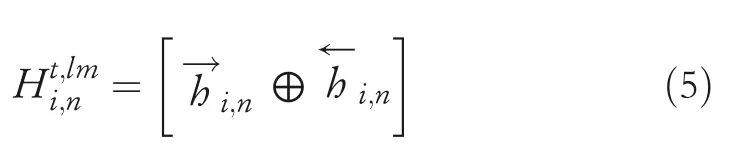
At this stage,the target domain‐specific sentence representations,as well as the source domain parameterIk,are fed into the attention module to obtain a normalised weight for each source domain.That is,the attentive weightαkiof each source domain denoting the source‐domain knowledge can be conveyed as
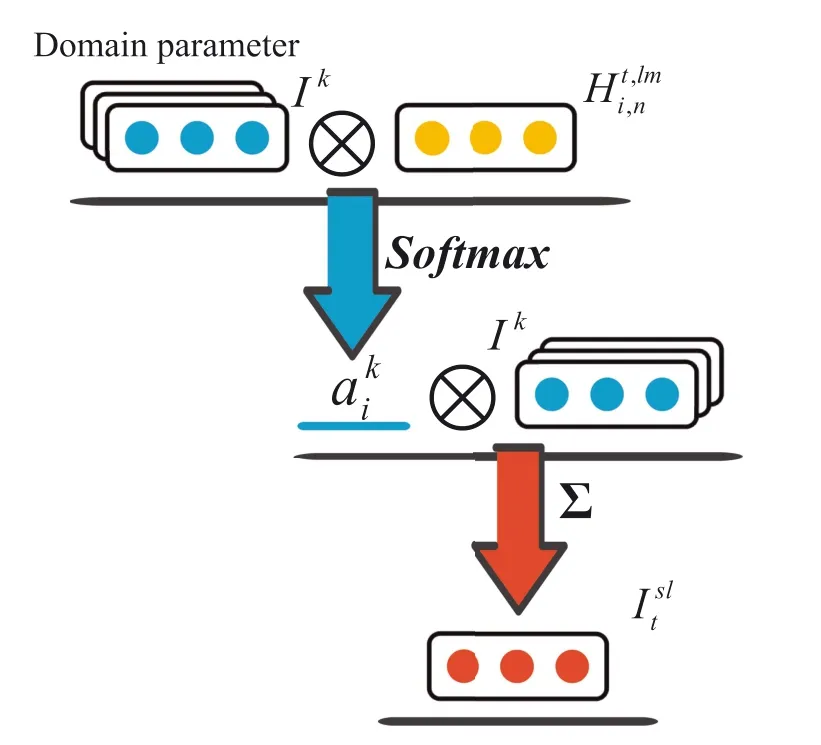
FIGURE 5 Attention module in parameter generating layer.Module input:sentence embedding and parameters of multi‐source domains;module output:Target domain‐specific long short‐term memory(LSTM)parameter of each sentence
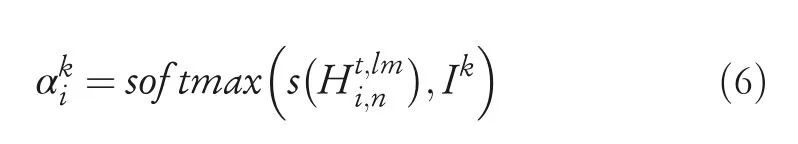
where
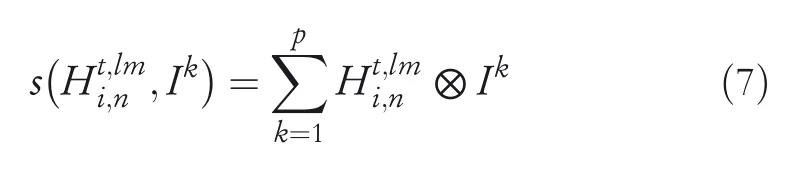
Computation of target‐domain parameter for the SL task is facilitated by using the source‐domain attention weight:
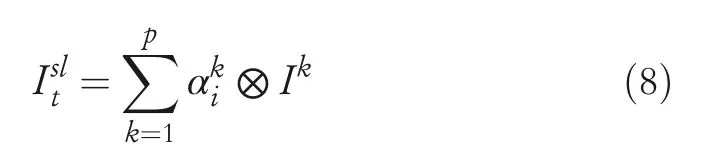
As presented in Equation(8),more information from source domains is integrated intoof the target domain.Correspondingly,the parameter set of Bi‐LSTM,which refers to the SL task of the target domain,is obtained,that is,

Notably,computing of attention weights is eliminated with respect to one single source domain.As such,the LSTM parameters of the target domain are obtained by integrating shared parameters and the dataset parameters,which is given as
Subsequently,for the Bi‐LSTM unit,the parameterand the inputvi,jare taken to resolve the hidden‐state outputs.We have indeed
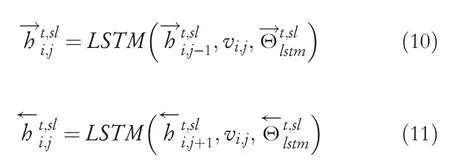
3.5|Output layer
As mentioned above,for both source domains and the target domain,the input sentences are of either the LM task or SL task.Specifically,we employ the CRFs to process sentences of SL and Negative Sampling Softmax(NSSoftmax)to those of ML as presented in Figure 6.Each component is depicted as follows:
CRFs[13]:In terms of the SL tasks,the output of the parameter generating layer is the concatenating of hidden states from forward and backward LSTM, that is,with the corresponding label sequenceyi=yi,1,…,yi,j,…,yi,n.The probability on labelyiis defined as follows:
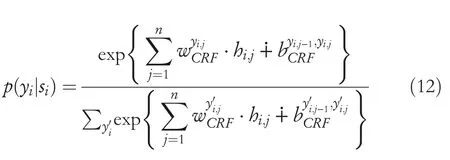
whererefers to an arbitrary label sequence;is the weight parameter with respect toyi,j;is the bias toyi,jandyi,j−1.Notably,the first‐order Viterbi algorithm is taken to extract the highest scored label sequence,while the proposed CRF is shared across the source and target domains.
NSSoftmax[13]:In line with the Bi‐LSTM model,the forward hidden states and the backward hidden states are applied to a forward‐LM and a backward‐LM,respectively.Given the forward LSTM hidden statethe probability of the next wordsi,j+1onsi,1:jcan be computed by using the NSSoftmax:

FIGURE 6 Output layer.Module input:long short‐term memory(LSTM)hidden states;Conditional Random Field(CRF)output:sequence labelling(SL)outcomes of words sentence;NSSoftmax output:probability on word in the sentence
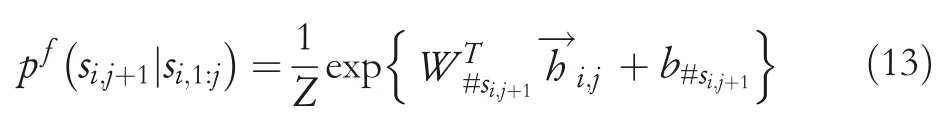
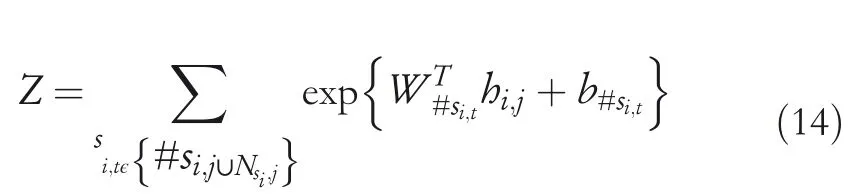
and
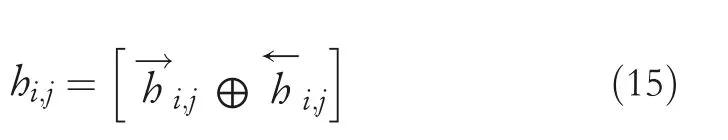
where#si,jis the vocabulary index of the target wordsi,j,WTis the transpose of the corresponding target word vector andb#the target word bias.In Equation(13),Zstands for the normalisation item,andNsi,jis the negative sample set ofsi,j.Each element in the set is a random number from 1 to the cross‐domain vocabulary size.
Similarly,the probability of the prior wordsi,j−1onsi,j:ncan be obtained from the forward LSTM hidden statewhich is
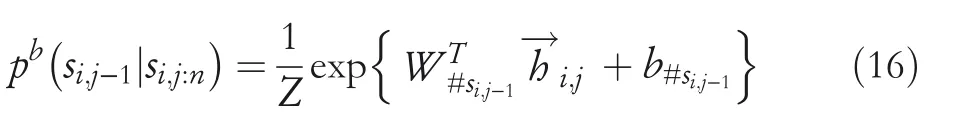
3.6|Model training
Since the SL of the target domain is considered as zero‐resource learning with cross‐domain adaptation,the training processes are carried out on SL of source domains and LM on both target domain and source domains.
Sequence labelling of source domains:For a labelled dataset,the negative log‐likelihood loss is conducted for model training,which is
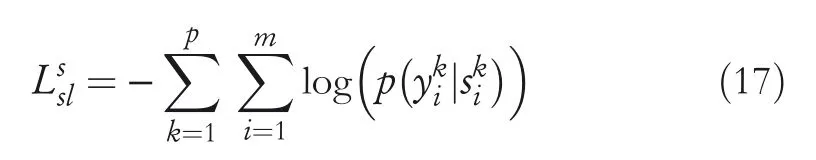
LM of source domains and the target domain:Given a labelled datasetfrom source domains,the forward‐and backward‐LM are jointly trained by using NSSoftmax,whose loss function is expressed as
可见,老火汤虽深受中医食疗思想的影响,但并不等同于药膳。那么,“老火汤”是何时开始成为广东居民的日常饮食呢?徐珂《清稗类钞》曾载曰:“(闽粤人)餐时必佐以汤。”[注](清)徐珂编撰:《清稗类钞13》,中华书局,1986年,第6242页。即至少在晚清时期,粤人已经形成了吃饭喝汤的饮食习惯。但结合其他文献来看,清代粤人日常所食之汤应非“老火汤”类的汤品。
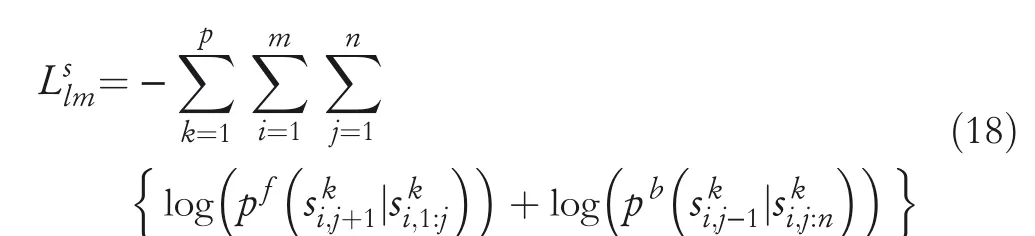
In such a manner,for a datasetfrom a target domain,the loss function is
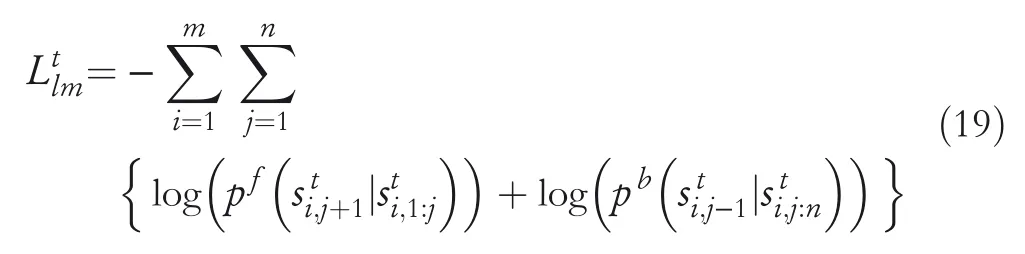
In most cases,we jointly train the SL and LM on both target domain and source domains.The overall loss is denoted as
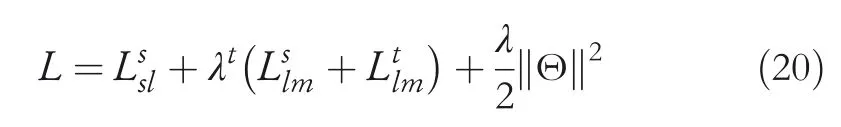
whereλtis the task weight of LM,λis the weight ofL2regularisation and Θ stands for the parameters set.
4|EXPERIMENT
In line with the purpose of SL tasks,we conduct two kinds of evaluations,one for evaluating the cross‐domain adaptability of the proposed model in NER and POS tagging tasks,the other for evaluating the working performance in NER via the training using crowd‐sourced data.As mentioned above,the crowd annotation task has only one source dataset,whose target domain parameters are generated without calculating the attention weights.
4.1|Dataset
Cross‐domain dataset:On the task of cross‐domain adaptability evaluating,both OntoNotes v5[7,23]and Universal Dependencies(UD)v2.3[7,24]are taken as the datasets for the cross‐domain sequence label.
OntoNotes v5[23]:The OntoNotes v5 is generally applied to NER tasks.In this experiment,the English part of Onto-Notes v5,which involves 9 named entities and 6 domains,is selected.Specifically,the 6 domains are broadcast conversation(BC),broadcast news(BN),magazine(MZ),newswire(NW),telephone conversation(TC),and web(WB).
Universal Dependencies(UD)v2.3[24]:The GUM part of UD v2.3 is used in the POS tagging task.This dataset is annotated with 17 tags and 7 fields.The 7 fields are the following:academic,bio,fiction,news,voyage,wiki,and interview.
Details of each cross‐domain dataset is exhibited in Table 1.
Crowd‐Annotation Datasets:We use the crowd‐annotation datasets[7]based on the 2003 CoNLL dataset[25],while Amazon’s Mechanical Turk(AMT)[26]as the testing set for the NER task.Statistics of the datasets in this experiment are shown in Table 2.
Similar to Ref.[7],all the sentences as well as the corresponding entities are selected for further processing.All the datasets are subdivided into train sets,development sets and test sets(see Table 3).
4.2|Hyperparameter settings
In this experiment,the NCRF++is taken as the basic model for a variety of tasks[27].The dimension of character‐level embedding,word‐level embedding and the LSTM hidden layer are set to 30,100,and 200,respectively,while the training episode is set to 100 epochs.All word embeddings are initialised using 100‐dimensional word vectors pretrained by Glove[28]and fine‐tuned during training.The character embeddings are obtained via random initialisation[13].The batch sizes of cross‐domain NER and cross‐domain POS tagging are 10 and 20,respectively,with the learning rate of 0.01 using RMSprop.We use domain‐specific parameters of size 200.
4.3|Baseline models
To comprehensively evaluate the performance of the proposed model,4 baseline methods are taken for comparison in NER tasks.For all the baseline models,the dimension of character‐level,word‐level embeddings and the LSTM hidden layer are set to 30,100 and 150,respectively.In addition,model parameters are updated by stochastic gradient descent(SGD).The learning rate is initialised as 0.015 and decayed by 5% of each epoch.
MTL‐MVT[29]:Multi‐source data is sent to a multi‐task learning model with parameter sharing among different tasks.The predicted labels from multi‐sources are voted,aggregated and applied to the target domain.
MTL‐BEA[30]:Based on a probabilistic graphical model,a transfer model and a generative model is established.Correspondingly,the transition probability is computed and the label for the target domain is thus generated.
Co‐NER‐LM[13]:The cross‐domain‐adaption is performed using cross‐domain LM while the knowledge transfer is carried out by designing a parameter generating network.
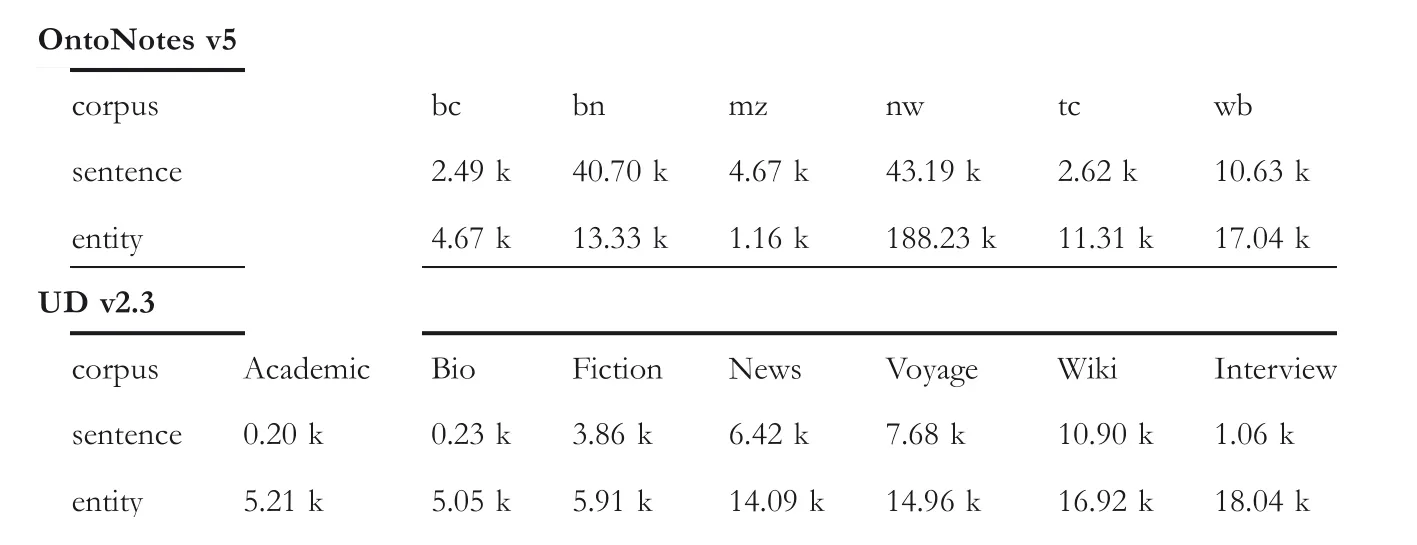
TABLE 1 Statistics of cross‐domain datasets

TABLE 2 Statistics of crowd‐annotation datasets
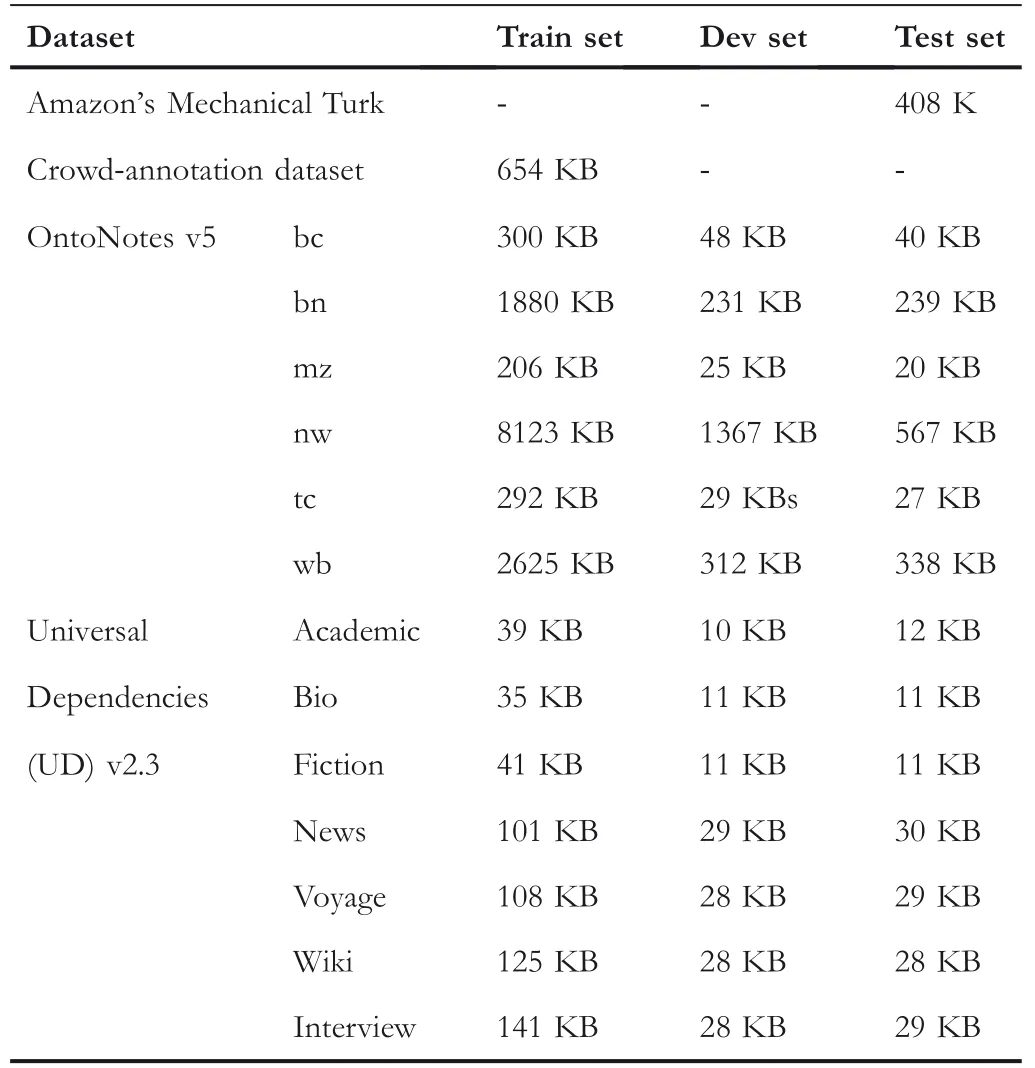
TABLE 3 Dataset subdivision
MULTI‐TASK+PGN[13]:A parameter generation network is developed to generate the parameters of LSTM from both the source domain and target domain.
ConNet[7]:Representation of each source is learnt from annotation of multiple sources.In addition,a context‐aware attention module is exploited to dynamically aggregate source‐specific knowledge.
BERT‐BASE[31]:The pretrained BERT is employed to extract contextual information while the parameters are fine‐tuned on specific tasks.
For the purpose of model optimisation,our method is trained using the crowd‐sourced data,whose effectiveness is verified in the NER tasks as well.On this occasion,6 crowd‐sourced‐training‐models are taken as the baselines,which are the following:
Crowd‐Add[32]:An LSTM‐Crowd model is devised where crowd components are element‐wise added to tags scores.
Crowd‐Cat[32]:In a LSTM‐Crowd‐based‐model,the crowd vectors are concatenated to the outputof the LSTM hidden layer.
MVT‐SLM[7]:The majority voting,based on the crowd annotation data,is conducted on the token level.Thus,the majority of labels is selected as the gold label for each token.
MVS‐SLM[7]:Similar to MVT,the majority voting is at the sequence level.
CRF‐MA[26]:A probabilistic approach is devised for the sequence label using CRFs with data from multiple annotators,which relies on a latent variable model where the reliability of the annotators are handled as latent variables.
CL‐MW(MW)[33]:A crowd layer is integrated into a CNN model to learn the weight matrices.The trained model is applied to label prediction.
4.4|Results
Evaluation on cross‐domain adaptability:The experimental results of our model compared to the baseline methods are shown in Table 4 and Table 5.The working performance of cross‐domain NER tasks is demonstrated by F1 score while that of cross‐domain POS tagging by accuracy.Among all these methods,the proposed model produces results competitive with the edge‐cutting ConNet model.For the cross‐domain NER tasks,our model obtains the highest F1 score on the evaluation settings of tasks of WB,TC and BC(see Table 4).On the other hand,Table 5 shows that our model achieves the best average accuracy,which outperforms ConNet 0.07%;the main reason is that the use of the attention mechanism aggregates shared knowledge from multi‐sources and thus eliminates the discrepancy among domains.In addition,the domain‐specific knowledge is also obtained via LM.By contrast,both MULTI‐TASK+PGN and Co‐NER‐LM use the LM as a bridge,but ignore the discrepancy among different domains.Moreover,MTL‐MVT is constructed on the basis of cross‐domain parameter sharing and MTL‐BEA exploits the probabilistic graphical model to predict the domain‐specific knowledge,whereas both of these models fail to makefull use of the knowledge from source domains and model the difference among domains.Since our model employs the parameter transferring as well as LM training,it is reasonable to expect better performance in different target domains,as it is the case.

TABLE 4 Experimental results of cross‐domain named entity recognition(NER)

TABLE 5 Experimental results of cross‐domain part‐of‐speech(POS)tagging
However,in comparison with the state‐of‐the‐art methods,our method fails to exceed the performance of the best methods in all the cross‐domain adaptability evaluation.According to Table 4,the accuracy of our model is not as high as that of ConNet in three evaluation sets.Pretraining using LM not just learns domain‐specific knowledge but also introduces unrelated domain information,which results in the drop of accuracy.Another possible explanation for this is that the multi‐domain transferring largely depends on the selecting of the source domain.Taking the NER task as an example,we focus on analysing the error by removing a specific domain every time from the current source domains.The results are presented in Figure 7.In some cases,the target domain and the source domain are of close relation.For instance,both BN and BC concern the broadcasting while BN and NW relate to journalism.In this way,for the target domain of either BC or NW,the F1 score decreases substantially due to the removal of BN.According to Figure 7,the working performance separately drops by 3.62% and 3.25% for target domains BC and NW without the source domain BN,which is significant.By contrast,for domains of little association,for example,TC and BN(the former contains a large number of colloquial expressions while the latter involves formal statements),there exist less impact on each other.As an example,for the target domain BN,the F1 score even improves by 0.45% while removing the source domain TC.We shall thus infer that the close connection between the target domain and source domain will effectively decrease the recognition error and facilitate the cross‐domain adaptation.
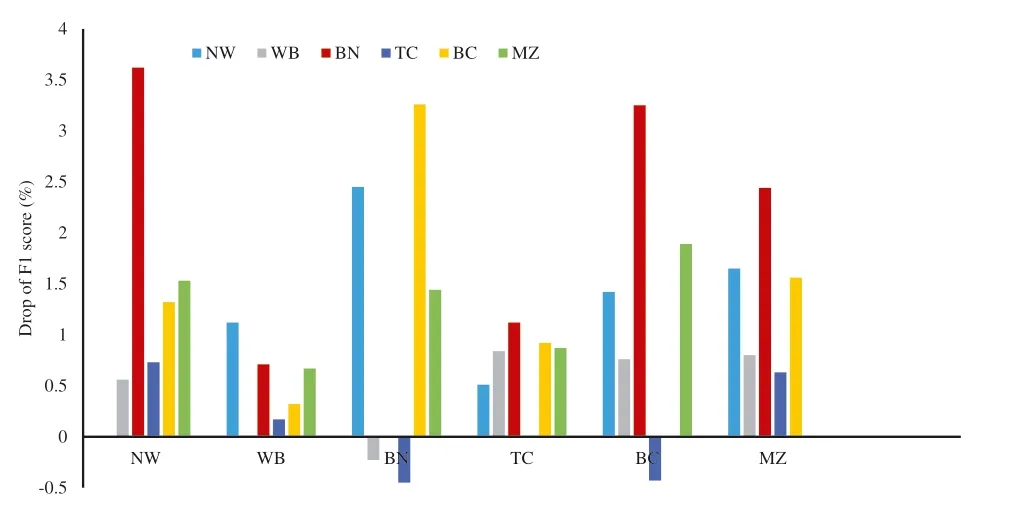
FIGURE 7 Drop of F1 by removing one source domain
Furthermore,the attention weight between any two different domains of the dataset OntoNotes v5 is investigated(Figure 8).Similar to the aforementioned inference,the domains of a closer relation make a greater contribution to each other in the NER task.One can easily see that the highest two attentive scores are generated between BN and NWas well as BC and BN,which conforms to our analysis of the recognition error.
Evaluation on crowd‐annotation training:The working performance of our model and the baselines on the real‐world dataset AMT is exhibited in Table 6.There is a considerable gap of F1‐score between our model and the other 10 methods.The minimum performance gap of 2.81% is observed against the Co‐NER‐LM model.In this way,our model presents the superiority in learning from the noisy annotation data.Typically,most widely‐applied models obtain a comparatively high precision but a low recall.This issue is on account of the deficiency in capturing the entity information of the target domain from multiple annotators.Note that only one source domain is used in the crowd‐annotation task,and the application of domain‐specific knowledge is no longer superior to the baselines.In addition,the crowd‐annotation dataset contains a certain amount of noise that affects the training results.Comparing with the baselines,the LM of our method cannot just learn the contextual information but also filter the noise from samples.As such,a higher recall as well as a higher F1‐score,is accessible.Clearly,our model is a better alternative to the state‐of‐the‐art methods.
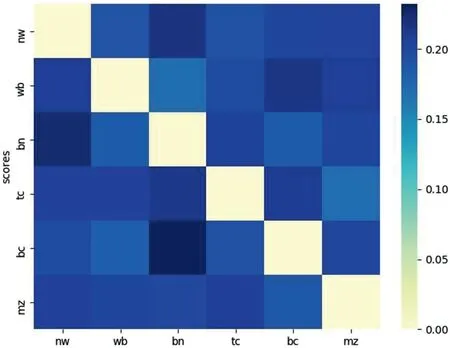
FIGURE 8 Attention weight between different domains.The vertical axis represents the target domain and the horizontal axis represents the source domain.The value on the right side stands for the attention weight

TABLE 6 Experimental results of real‐world crowd‐sourced named entity recognition(NER)
4.5|Ablation experiment
In order to determine the importance of the different components in our model,an ablation study is carried out on cross‐domain tasks.Our model is taken as the baseline.Specifically,MULTI‐TASK‐without LM represents the removal of LM from the model,which is trained in the source domain using SL tasks,with parameter generating via the attention mechanism;MULTI‐TASK‐without attention stands for the ablation of the attention network while the model is trained based on SL and LM tasks;STM‐without LM andAttention denotes that the model is trained in the source domain only using SL tasks,without LM and attention mechanism.
According to Table 7,the removal of the attention mechanism and LM results in the F1 decline of 2.50% and 2.86% on average in NER tasks.Likewise,for the POS task,the accuracy drop of MULTI‐TASK‐without LM and MULTI‐TASK‐without attention is 1.25%and 1.18%,respectively(see Table 8).The STM‐without LM&Attention model has the worst results in all evaluation settings.For NER task,since LM is more capable of learning domain‐specific knowledge and contextual information,the average F1 of MULTI‐TASK‐without attention is slightly higher than that of MULTI‐TASK‐without LM.By contrast,the POS information is irrelevant to the domain.Thus,the contribution of LM and the attention mechanism is comparable in POS tasks.
4.6|Case study
To further verify the capability of the proposed model,it is advisable to visualise the method presentation.In this case,three sentences are selected and applied to the NER task.The proposed model with and without LM,as well as ConNet are taken for comparison.According to Figure 9,both ConNet and our model captures all the nouns and predicts their labels successfully.By contrast,the proposed model without LM misidentifies the entities‘Soviet’,‘West’and‘Indies’.In line with the real label,all these entities in the three sentences can be precisely recognised,which indicates the effectiveness of our model in SL tasks.
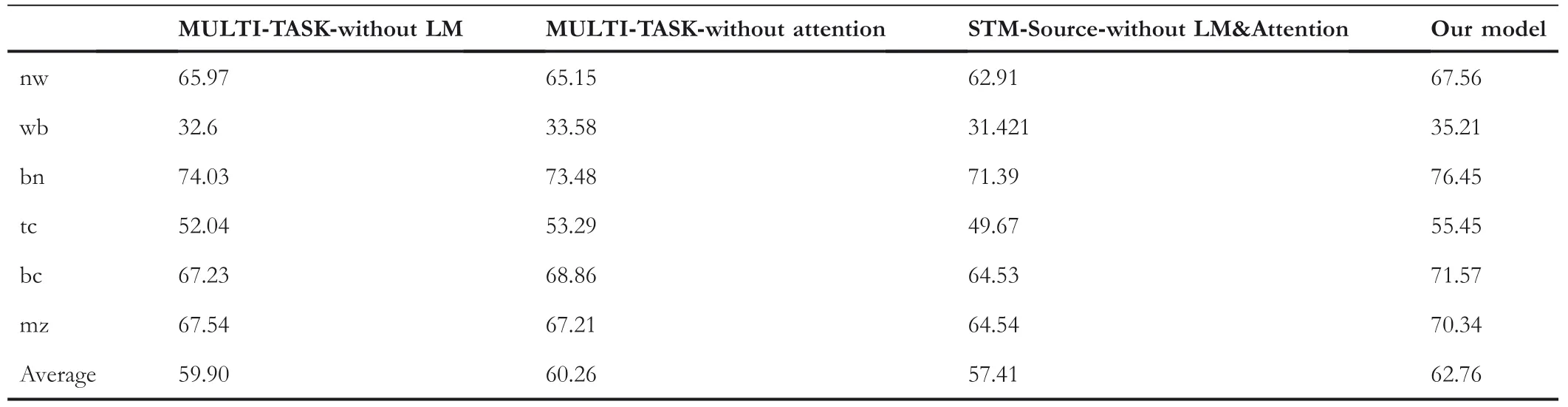
TABLE 7 Ablation study in the cross‐domain named entity recognition(NER)task

TABLE 8 Ablation study in cross‐domain part‐of‐speech(POS)task
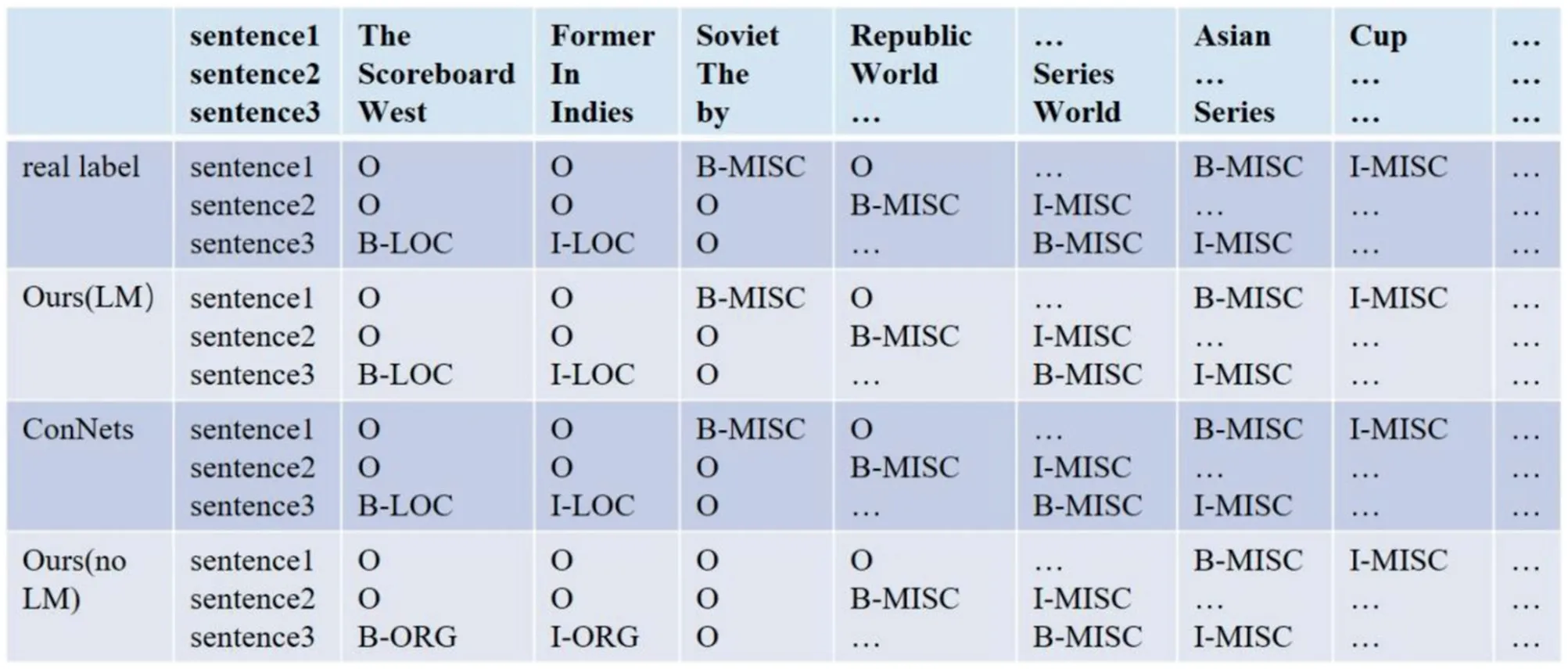
FIGURE 9 An example of sentence prediction results.B–beginning of the entity,I–intermediate of the entity.O–not an entity,MISC–other entity,PER–personal name,LOC–location name,and ORG–organisation name
5|CONCLUSION
In this work,we establish a Bi‐LSTM based‐architecture in SL,which integrates the parameter transferring principle,attention mechanism,CRF and NSSoftmax.Despite the discrepancy of information distribution among domains,the proposed model is capable of extracting more‐related knowledge from multi‐source domains and learning specific context from the target domain.With the LM training,our model thus shows its distinctiveness in cross‐domain adaptation.Experiments are conducted on NER and POS tagging tasks to validate that our model stably obtains a decent performance in cross‐domain adaptation.In addition,with the training of crowd‐annotation,the experimental results for NER are further improved,indicating the effectiveness of learning from noisy annotations for higher‐quality labels.
ACKNOWLEDGMENTS
This work was supported by the National Statistical Science Research Project of China under Grant No.2016LY98,the Science and Technology Department of Guangdong Province in China under Grant Nos.2016A010101020,2016A010101021 and 2016A010101022,the Characteristic Innovation Projects of Guangdong Colleges and Universities(No.2018KTSCX049),and the Science and Technology Plan Project of Guangzhou under Grant Nos.202102080258 and 201903010013.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
DATA AVAILABILITY STATEMENT
Data that support the findings of this study are available from the corresponding author upon reasonable request.
ORCID
Bo Zhouhttps://orcid.org/0000-0001-8097-6668
猜你喜欢
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Modelling of a shape memory alloy actuator for feedforward hysteresis compensator considering load fluctuation
- Apple grading method based on neural network with ordered partitions and evidential ensemble learning
- An improved bearing fault detection strategy based on artificial bee colony algorithm
- Parameter optimization of control system design for uncertain wireless power transfer systems using modified genetic algorithm
- Passive robust control for uncertain Hamiltonian systems by using operator theory
- Humanoid control of lower limb exoskeleton robot based on human gait data with sliding mode neural network