基于加权集成的深度投票模型大豆灰斑病分级研究
2022-11-11孙红敏王钰涵戴百生李晓明孟希璠
孙红敏,王钰涵,戴百生,李晓明,孟希璠,那 晨
(1.东北农业大学电气与信息学院,哈尔滨 150030;2.东北农业大学农学院,哈尔滨 150030)
大豆在农作物生产中占有重要地位,是粮食、饲料、经济兼用型作物,也是农业、制药、酿造、食品等产业原材料。优质大豆植株是农业和工业生产高产、优质、高效保障。每年因病害造成大豆减产达到10%~25%,病害特征大多体现在叶片上,少量体现在根部[1]。不同品种大豆对于病害表现形式也不同,及早发现并合理喷药,可减少经济损失,保障大豆产量。根据病害等级需要采取不同措施,避免药物浪费,污染环境。大豆叶片病害发病初期,特征相似,依靠经验易错过最佳防治时期[2]。根据大豆植株患病等级采取相应措施,对病害有效防治、避免药物浪费、减少环境污染、降低经济损失具有重要意义[3]。
随着计算机视觉和人工智能技术发展,相关技术在农业领域中越来越被重视,如汤晓东等利用基于HSI空间的三次标记分水岭算法提取目标叶片,计算形态参数,使用概率神经网络分类器实现在复杂背景下识别大豆形态,准确率达到85.37%[4];谭克竹等使用BP神经网络实现大豆病害识别,准确率达到94%[5];范伟坚阐述传统病害识别原理和缺陷,总结卷积神经网络在农作物病害识别中应用的优势[6];蒋丰千等通过对大豆病害图片的二值化和轮廓分割等预处理构建数据集,多方面优化模型,使得该方法在训练集上的准确率大幅提升,但测试集上准确率仅78%[7];Gui提出一种基于LeNet的深度卷积网络用于大豆叶片病害分类,分类准确率达到93.54%[8]。综上所述,现有研究主要集中在对大豆叶片病害的分类识别,对具体病害程度的自动分级关注较少[9],多数工作主要采用改进或优化传统卷积神经网络模型研究,识别精度有待提高[10]。
目前卷积神经网络技术应用于农产品品种、病害识别等方面研究日趋成熟,具备大豆病害分级的可行性[11-12]。现有研究主要通过优化单一卷积神经网络完成病害分类,对复杂分类问题,识别精度有待改进,针对这一问题,本文以常见大豆灰斑病病害叶片为研究对象,采用卷积神经网络对大豆灰斑病分级可行性进行分析和研究。通过数据增强、数据裁剪等方式对大豆叶片灰斑病图片作预处理,对比不同卷积神经网络模型分级性能,将训练的基础模型组合和优化,受Ayan等提出集成策略启发[13],提出一种加权深度投票模型,通过迁移学习训练,优选传统卷积神经网络模型,利用遗传算法得出不同模型加权投票权重,对传统卷积神经网络模型加权集成,实现大豆叶片灰斑病分级。
1 试验材料
1.1 数据采集
本试验所用大豆病害叶片图像拍摄于东北农业大学转基因实验基地。试验过程中,通过对不同品种大豆进行灰斑病病原菌株接种,获得不同等级灰斑病大豆叶片,拍摄采集所需图像数据集。
详细过程如下:通过随机区组设计方法选用本次试验种植区域,采用垄作方式对试验种植大豆,行长1.5 m、宽0.5 m,人工点播,行距0.4 m、株距0.05 m,每个品种、株系单行种植以便图像采集。种植完成后,实验室培育大豆灰斑病病原菌株,将菌株从试管内移出接种在PDA培养基,置于28℃恒温培养箱内活化7 d繁殖形成菌落,使用无菌打孔器沿菌丝延伸的边缘处打孔,将菌丝块的菌丝面紧贴在PDA培养基上扩繁。待菌株培养扩繁后,选取不同品种大豆植株同一位置生长相近的无病斑、无机械损伤、新鲜完全展开叶片接种灰斑病病原菌株,接种15 d充分发病后,采集图像,最终采集5 060张图片数据,部分数据如图1所示。

图1 大豆图像部分采集数据Fig.1 Part of the collected data of soybean images
1.2 分级方法
依据国家市场监督管理总局鉴定标准,大豆灰斑病分为五类,划分结果如表1所示。

表1 本文灰斑病等级划分标准Table 1 Grading standard of gray spot disease in this study
每一类分级后图片见图2。

图2 大豆灰斑病分级图片样本Fig.2 Image samples of soybean gray spot disease grading
由表1和图2可看出,不同等级大豆灰斑病叶片表现形式不同,高抗等级叶片病变面积小于1%,叶片图像与正常叶片相近。抗等级叶片具有少量病斑区域,分布较分散。中抗等级叶片表面有较多病斑区域且分布较分散。感等级叶片表面病斑区域较多,且分布集中,病斑面积近叶片面积一半。易感等级叶片表面病斑较多,分布于各区域,面积达到一半以上。
1.3 数据增强与数据集划分
卷积神经网络模型中有大量参数需被训练,为防止发生过拟合现象,需使用大量图像样本进行训练,本文在数据采集完成后,使用图像增强手段扩充数据集,在翻转、调节亮度、改变像素值、放缩、扭曲、增加噪声等增强方法中随机选择1~5种进行组合得到不同增强数据,在扩充数据集同时减少重复数据出现,增强后图片见图3。图3中,A为原始图片,通过图像增强手段得到若干图片,选择其中4张图片样本进行分析。其中,经放缩的增强方式得到图片B,经放大和翻转得到图片C。经扭曲得到图片D,经扭曲和翻转得到图片E。数据增强完成后按训练集、测试集、验证集1∶1.5∶1.5的比例进行数据集划分,划分结果见表2。
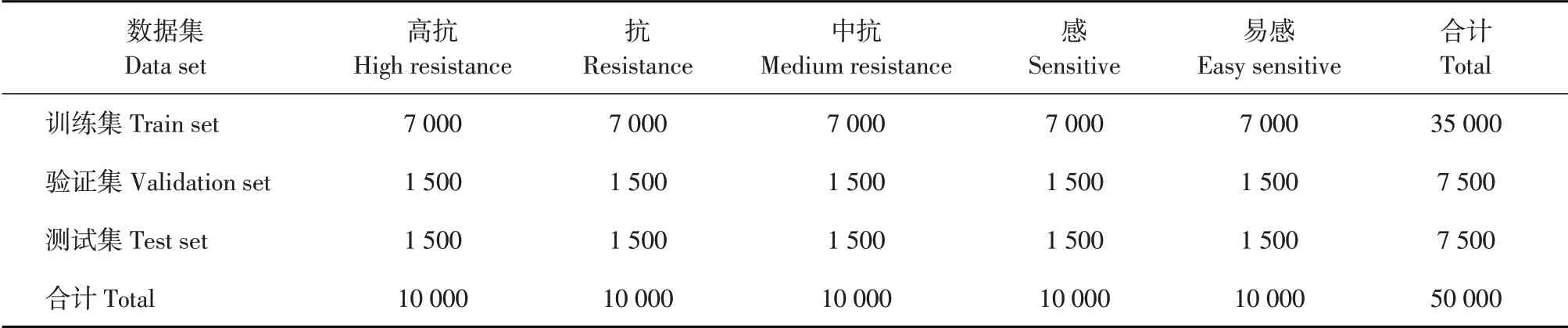
表2 数据集划分Table 2 Data set division

图3 数据增强后图片样本Fig.3 Image samples after data augmentation
2 试验方法
为实现大豆灰斑病自动分级,本文在传统卷积神经网络模型基础上构建一个集成模型,具体包括:训练7个单一深度卷积神经网络模型(VGG16、VGG19、Resnet50、Inception-V3、Xception、MobileNet、GoogleNet);选择其中准确率最高的3个模型。在此基础上通过遗传算法加权集成构建深度投票模型。该模型技术路线如图4所示。
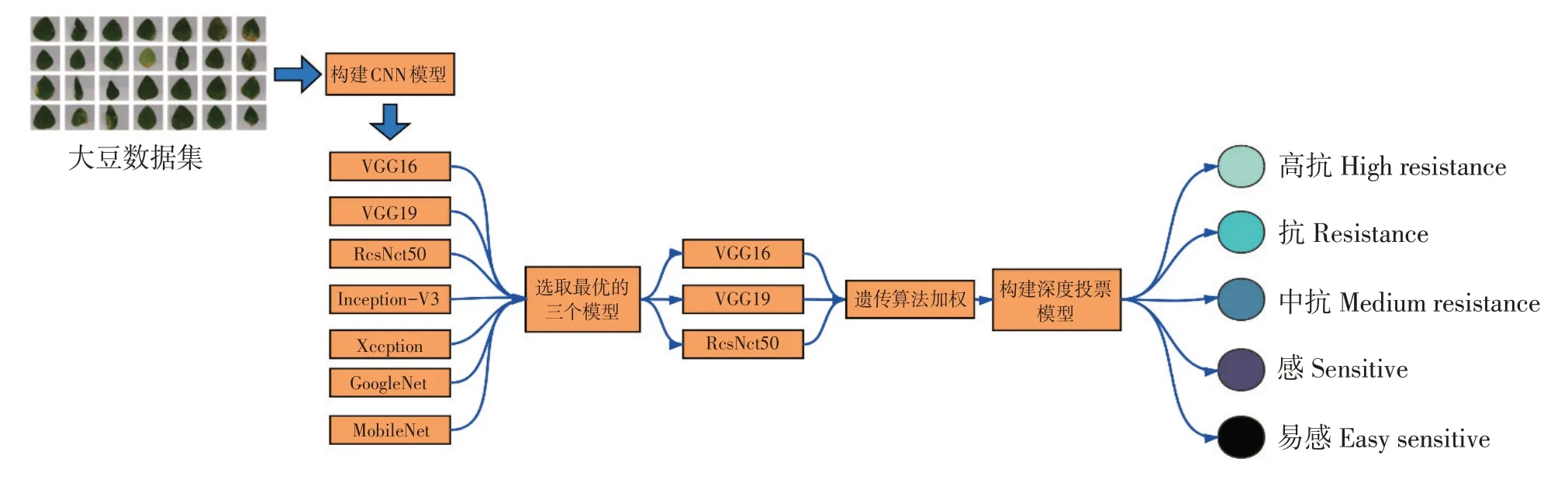
图4 技术流程Fig.4 Technology flowchart
2.1 单一深度卷积神经网络模型
卷积神经网络是一种带有卷积结构的深度学习模型,主要包括卷积层、池化层和全连接层。与传统神经网络模型相比,CNN使用局部感受野、权值共享、池化层等思想,有效减少网络参数个数,使神经网络适应性更强,缓解模型的过拟合问题并使得模型具备一定的位移、尺度、缩放、非线性形变稳定性。本文以VGG和残差网络为例,简要介绍其网络结构模型[14]。
VGGNet共有5个卷积层,每一个卷积层后链接一个最大池化层,最后为3个全连接层和一个soft max层,该网络使用3×3卷积核,网络中所有池化层采用2×2卷积核[15-16],其中VGG19网络结构如图5所示。
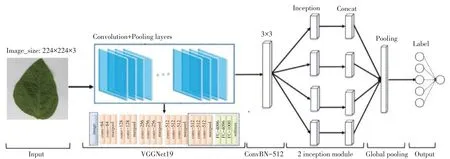
图5 VGG网络结构Fig.5 VGG network structure
RestNet是残差网络(Residual network)缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分。Rest-Net对输入作卷积操作,包含5个残差块(Residual Block),最后使用全局平均池化和Softmax代替参数量巨大的全连接层以便于更好进行分类任务,RestNet网络构成见图6[17-18]。本研究使用RestNet50模型结构,如图第5列所示。
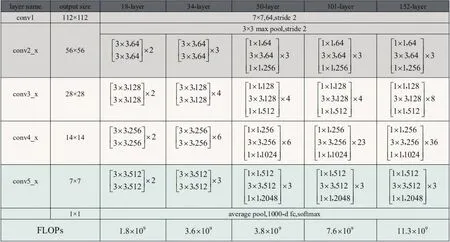
图6 RestNet网络结构Fig.6 RestNet network structure
2.2 构建深度投票模型
为提高对大豆灰斑病分级准确率,同时综合传统卷积神经网络模型特征提取优势和分类性能,本文提出一种构建加权深度投票模型方法,即在单一模型基础上,选择多个单一深度卷积神经网络模型,通过遗传算法学习得出深度投票模型权重,构建一个加权深度投票模型。
2.2.1 传统深度投票模型
使用卷积神经网络模型进行预测时,通过模型计算图像所属病害各等级的概率,并为该图像分配到具有最高概率值的标签[19]。对于单个模型,考虑一个n分类的任务,使用O(t)=(p1,p2,p3,…,pn),p1表示模型对于分类任务第i类的概率,且相加总和为1,若pi为n个概率中最大值,则该图像被预测为第i类,集成模型通过多个模型的概率相加,使用公式(1)进行计算:

式中,j-预测的类别;i-集成的第i个模型;m-集成模型个数;Pij-第i个模型预测属于第j类概率;O(j)-集成后的模型预测属于第j类概率,所有类别概率相加为1。
若O(j)为n类中最大值,则该集成模型分类结果为第j类,通过该方法可综合考虑多个模型的分类结果,有效提高分类精度。
2.2.2 加权深度投票模型
由公式(1)可知,传统深度投票模型是将各模型预测的概率相加,未考虑每一个模型对于集成后模型的优劣性能。故在此基础上,充分发挥每一个模型优势同时提高模型性能,为每个模型分配权重,对构建深度投票模型的基础模型进行加权,加权后的深度投票模型概率计算方式见公式(2)。

式中,wi-第i个模型的权重,且m个模型的权重相加为1;O(j)-加权后深度投票模型预测属于第j类的概率,且所有类别概率相加为1。
对m个模型权重wi的判定可认为是一个最优问题,通过遗传算法求解。遗传算法是一种基于进化论、遗传学和自然选择原理的启发式算法,通常被应用于权值确定,确定初始染色体数量,通过交叉和变异操作生成新染色体,计算适应度,剔除适应度最差的染色体,保持染色体数量不变,迭代若干次后选择适应度最好的染色体即为权值[20]。
在遗传算法中,假设初始群体由n条染色体组成,每条染色体包含w个随机产生的基因(即权重值),在0~1之间。将染色体基因和模型在验证数据集上的预测量相乘,得到预测标签。采用均方误差(MSE)函数计算适应度值。计算各染色体MSE适应度值后,通过考虑其适应度值,选择最佳的m条染色体创建新染色体。分别采用交叉和突变技术,从已确定的m条最佳染色体中获得2m条新染色体。计算新生成染色体的适应度值,并将其添加到种群中。为保持种群大小不变,剔除适应度最差的2m条染色体。这些操作重复进行k代,确定MSE最小的染色体,最后得到最优权值。所提出的基于遗传算法的加权方法步骤如图7所示。
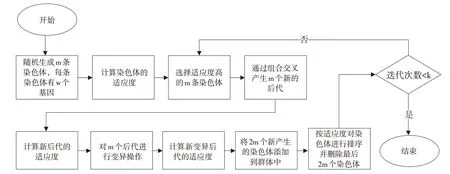
图7 本文遗传算法优化流程Fig.7 Flow chart of genetic algorithm optimization in study
3 结果与分析
3.1 评价指标
为更好分析模型性能,本文所采取评估指标为准确率、精确率、召回率以及F1值。具体计算方式如下:

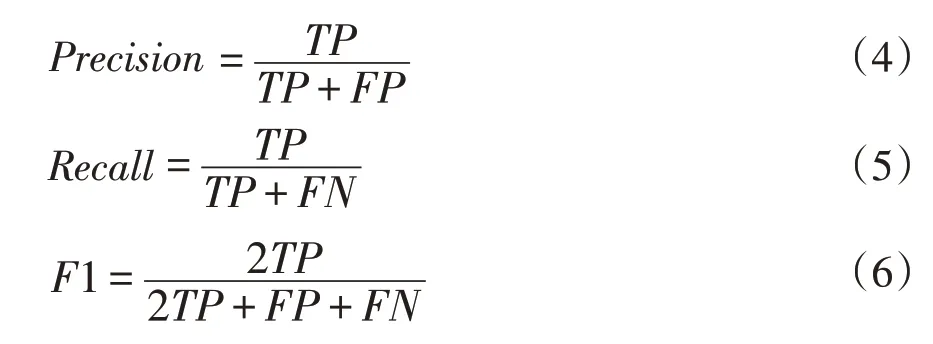
式中,TP-实际为正且被预测为正的样本数量;FP-实际为负但被预测为正的样本数量;FN-实际为正但被预测为负的样本的数量;TN-实际为负且被预测为负的样本的数量。。
3.2 单一深度卷积神经网络试验结果
本研究采用7个常见卷积神经网络模型(VGG16、VGG19、Resnet50、Inception-V3,Xception,MobileNet,GoogleNet)进行训练与测试。通过图像工作站(HP Z6)进行模型训练和测试,图像工作站显卡为RTX 5000 16G,支持GPU并行运算,内存192GB。训练所使用的模型基于Tensorflowgpu 2.2.0版本和python3.6版本。
训练所得曲线与相应评价结果和模型训练参数信息见表3。
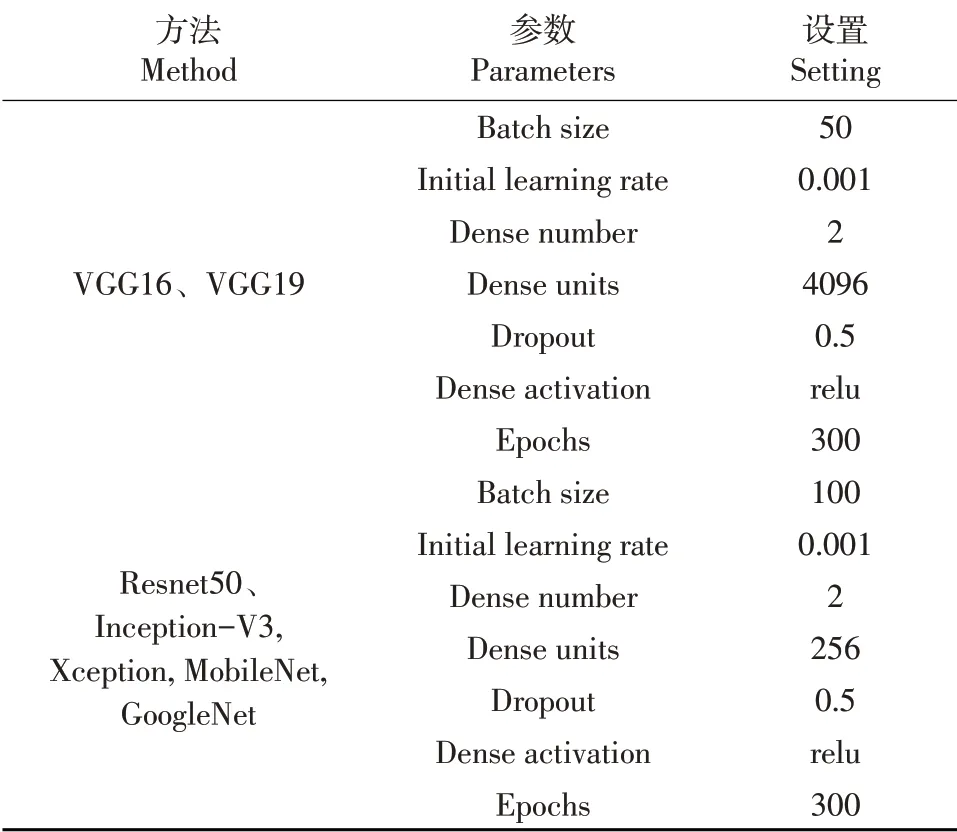
表3 单一深度卷积神经网络模型的训练参数Table 3 Training parameters of single CNN models
训练所得模型准确率曲线如图8所示。
由图8可看出,单一深度卷积神经网络模型训练200次后,训练集上准确率趋于收敛,VGG16和VGG19在训练集上收敛速度更快,准确率更高。训练完成后,针对测试集中7 500张图像样本,开展模型评估,结果见表4。
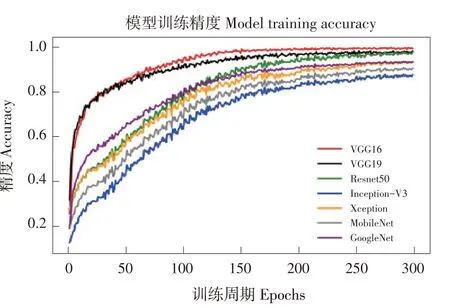
图8 7个单一深度卷积神经网络训练准确率曲线Fig.8 Training accuracy curve of seven single CNN models
由表4可看出,常见单一深度卷积神经网络模型中,VGG19在测试集上的准确率最高,达到88.7%。为构建集成模型,对训练7个模型进行评估后,选择准确率最高的3个模型即VGG16、VGG19和Resnet50,为分析3个模型优劣势以及样本分类情况,建立模型混淆矩阵见图9。
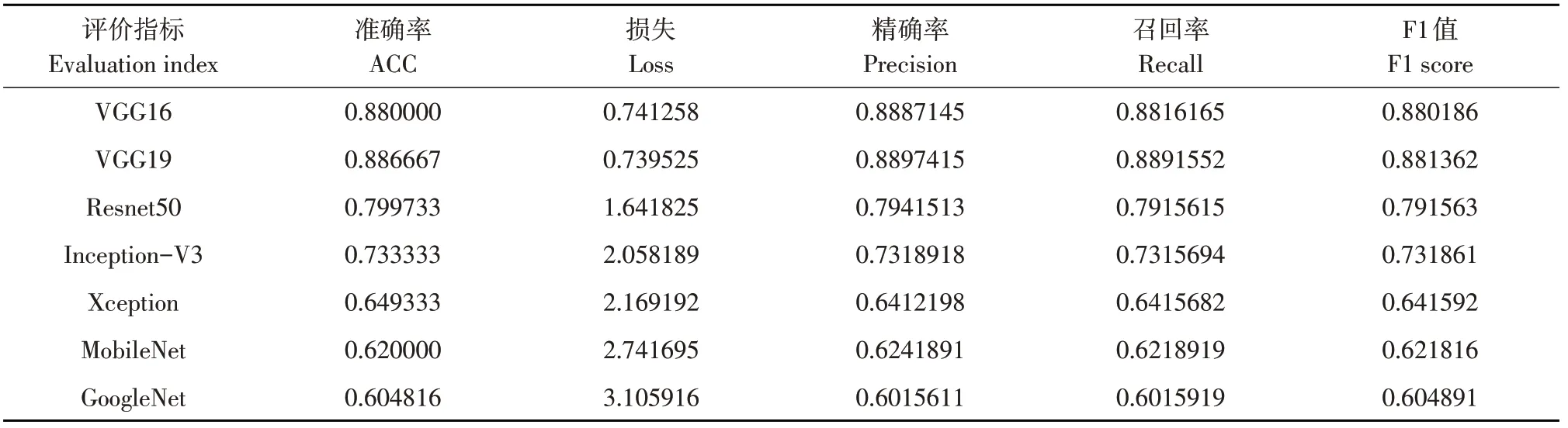
表4 单一模型评估结果Table 4 Evaluation results of 7 single models
由图9中3个模型混淆矩阵可看出,针对于病害的5个等级,不同模型对于不同等级识别准确率有一定差别。在VGG16模型中,识别出病变较大叶片准确率为89%,对于高抗叶片识别准确率仅为84%,由于病害等级相似导致高抗叶片误识别成抗性;在VGG19模型中,高抗叶片识别准确率达到97%,相较于VGG16模型提高13%,但其他等级识别准确率为86%,相较于VGG16模型下降3%;RestNet50模型识别易感等级叶片准确率最高,达到91%,因此,针对这些问题,本文将上述3个模型进行集成改进,使每一个模型充分发挥自身优点,部分样本分级情况如表5所示。

表5 部分分类样本Table 5 Partial grading samples
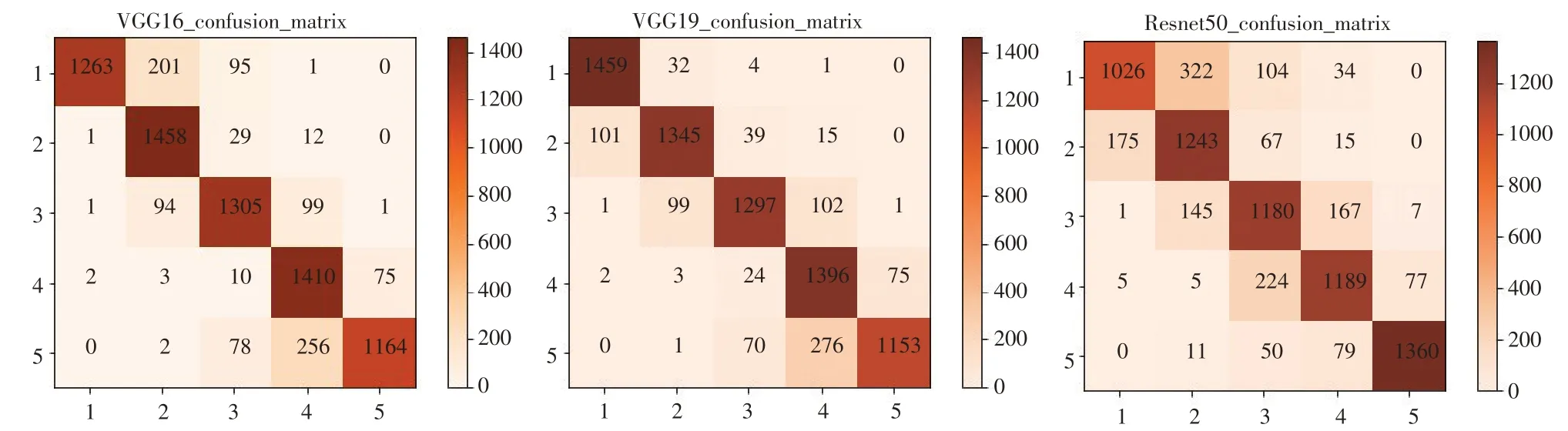
图9 准确率最高的3个模型混淆矩阵Fig.9 Confusion matrix of the three models with the highest accuracy
3.3 集成模型性能分析
综上,选择VGG16、VGG19和Resnet50 3个模型构建集成模型,并使用遗传算法加权深度投票模型对其优化,在遗传算法中,初始染色体数量为8条,每一条上有3个基因,每一次迭代选取4条染色体,为避免陷入局部最优解,交叉率设为0.95,变异率设为0.005,通过交叉变异等操作生产新的8条染色体,将16条染色体计算MSE,剔除最差的8条染色体,保持不变种群规模,计算迭代100次的过程中每一个MSE,最终得到最小MSE染色体上3个权值为:0.31、0.36、0.33,作为3个集成模型权重,即w1=0.31,w2=0.36,w3=0.33。
对集成后模型,使用原始模型最好的VGG19模型进行对比分析,结果见表6。
由表6可知,使用深度投票模型在测试集上的准确率相较于传统单一卷积神经网络模型VGG19高1.7%,使用遗传算法自动学习每一个模型加权权重后构建集成模型准确率提高2.7%,表明使用遗传算法加权取得更好效果,同时建立两个集成模型混淆矩阵如图10所示。

图10 深度投票模型的混淆矩阵Fig.10 The confusion matrix of the deep voting model

表6 集成模型评估指标Table 6 Deep voting model evaluation indicators
由图10可见,采用深度投票模型解决传统单一模型的弊端,利用各模型优点进行训练和预测,深度投票模型分级情况见表7。由表7可知,集成模型能够准确识别部分单一模型中误分类样本,但相近病害等级的图片部分识别有误,需进一步研究。

表7 部分样本分级情况Table 7 Grading situation of some samples
4 讨论与结论
本文针对大豆灰斑病5个等级病害图片样本,运用卷积神经网络和深度投票方法,开展大豆灰斑病自动分级研究,提出使用遗传算法加权,构建基于卷积神经网络的深度投票模型。通过试验验证,该模型有效解决大豆灰斑病各等级之间因差距细微导致的准确率低问题,为大豆其他病害分级提供新思路和方法。
a.采用7个卷积神经网络模型(VGG16、VGG19、Resnet50、Inception-V3,Xception,MobileNet,GoogleNet)进行训练与测试,试验结果准确率分别为:VGG模型88.0%、VGG19模型88.7%、Resnet50模型80.0%、Inception-V3模型73.3%、Xception模型64.9%、MobileNet模型62.0%、Goo-gleNet模型60.5%。结果表明,使用卷积神经网络对大豆灰斑病进行分级具有可行性,但传统卷积神经网络模型针对病害分级准确率较低,不同的卷积神经网络模型对于不同等级准确率差异较大,需综合不同卷积神经网络模型用于大豆灰斑病分级研究。
b.基于上述传统卷积网络训练结果,提出遗传算法加权构建深度投票模型,与传统卷积神经网络相比,该模型在7 500张图片所组成的测试集上分级精度达到93%,相较于传统卷积神经网络中准确率最高的VGG19模型提高4.3%,相较于不加权深度投票模型也有提高,有效解决传统模型识别的弊端,为大豆病害分级和病害走势预测提供技术支持。但本文分级结果中,仍有部分分级有误,后续考虑引入注意力机制开展进一步研究。
c.本文提出的基于遗传算法构建加权深度投票模型,在大豆其他病害或其他农作物病害方面是否具有同样效果需进一步验证。
