基于司外揣内原理的中医“舌象-体质”深度学习模型构建研究
2022-11-09姜荣荣高佳奕
姜荣荣,高佳奕,杨 涛,3
(1.南京中医药大学护理学院,江苏 南京 210023;2.南京中医药大学人工智能与信息与信息技术学院,江苏 南京 210023;3.江苏省中医外用药开发与应用工程研究中心,江苏 南京 210023)
中医体质学说是以中医理论为主导,研究人类各种体质特征、体质类型的生理、病理特点,并以此分析疾病的反应状态、病变的性质及发展趋向,从而指导疾病预防和治疗的一门学说[1]。中医体质辨识是中医体质学说的核心内容之一,其通过四诊采集临床信息,通过中医理论辨识出体质结果[2]。在中医体质学说的发展过程中出现了多种体质分类方法[3-6],然而这些方法多依赖体质评分量表,效率较低,且问题回答存在主观性,影响体质判定结果。中医认为人是一个有机的整体,疾病变化的病理本质虽然藏之于内,但必有一定的症状、体征反映于外。司外揣内作为中医诊断的基本原理之一,对中医诊断和健康测评具有十分重要的意义。舌诊是中医诊断司外揣内原理的集中体现,是四诊中望诊的重要内容,人体的健康或疾病状态在舌象上会有较为明显的反映[7]。如何充分的利用舌诊信息,客观、标准、高效地评估中医体质,已经成为中医体质领域探索的方向之一。针对中医体质辨识,相关学者从不同角度进行了研究和探索[8-10],但大多采用传统机器学习算法构建中医体质模型,模型的精度有待进一步提升。随着计算机视觉技术的飞速发展,针对图像的识别、处理和分析技术取得了巨大进步[11]。因此,本研究提出基于中医司外揣内原理,构建“舌象-体质”深度学习模型,以期为中医体质辨识智能化发展提供参考。
1 模型构建
考虑到中医临床舌象数据集的样本数较少,且最终体质类别与舌色、舌苔色、舌形、舌态等多个特征潜在相关,特征不明显与训练样本较少可能会导致最终的分类结果精度较低。本文参考Woo S 等[12]的方法构建特征注意力模块,将舌图的多尺度信息融入注意力模块中,以残差方式堆叠,学习不同尺度、不同权重的图像特征,实现中医体质辨识模型;此外,模型额外引入有关舌象的文本描述信息进行辅助训练,通过文本与图像多模态信息相结合的模型学习方式实现中医体质的精准分类,模型结构见图1。
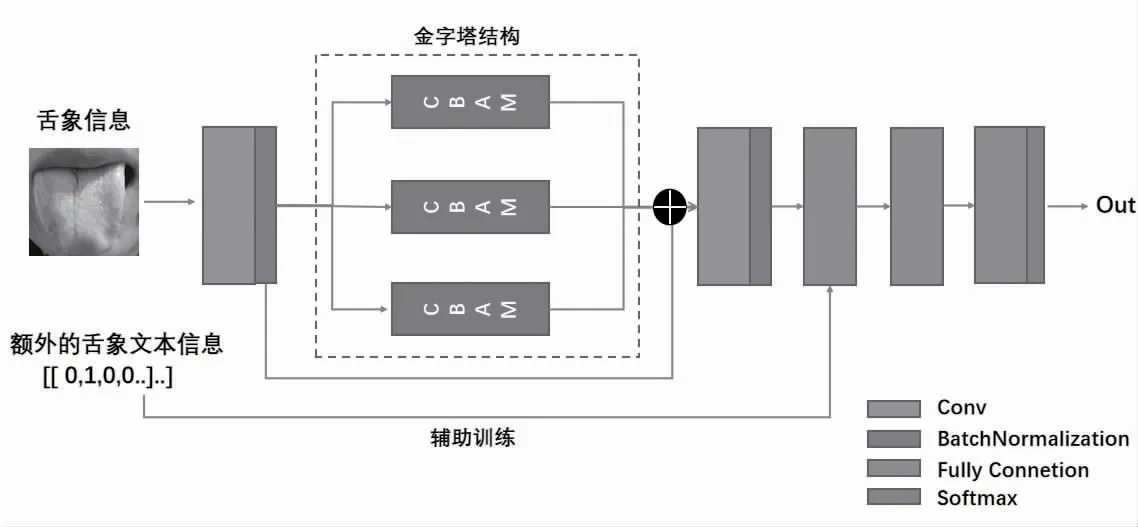
图1 中医体质辨识模型结构
卷积注意力模块(convolutional block attention module,CBAM)[12]旨在对卷积操作后的信息进行深一步学习,为各特征分配不同权重,对结果贡献明显的特征给予较高权重,相反对贡献较少的特征给予较少权重,将后续学习的关注点放在权重较高的特征上。本模块中的注意力分为空间注意力与通道注意力,二者采用串联的方式结合,见图2。
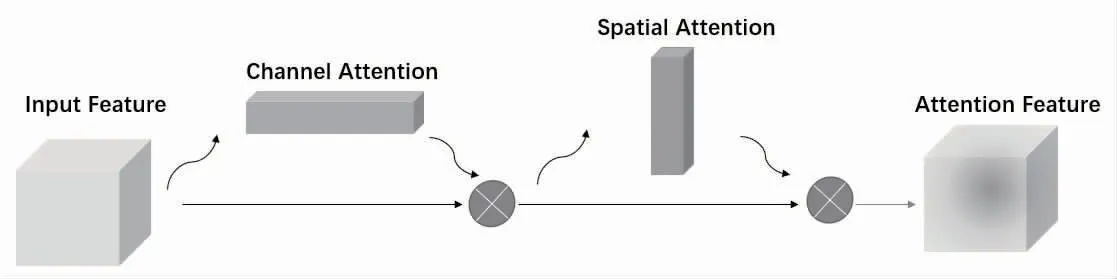
图2 CBAM 注意力模块
通道注意力即学习特征各个通道的重要程度,通过全局池化的方式将H*W 维度变换至1*1 维度,把注意力仅放在对通道特征的学习上。由于MaxPooling[13]与AveragePooling[13]的特点不同,又各具优势(MaxPooling 侧重于特征选择,选出分类辨识度更高的特征;AveragePooling 侧重于特征的融合,实现特征比较完整的传递),因此采用MaxPooling与AveragePooling 相结合的池化方式,Channel Attention 的结构见图3。
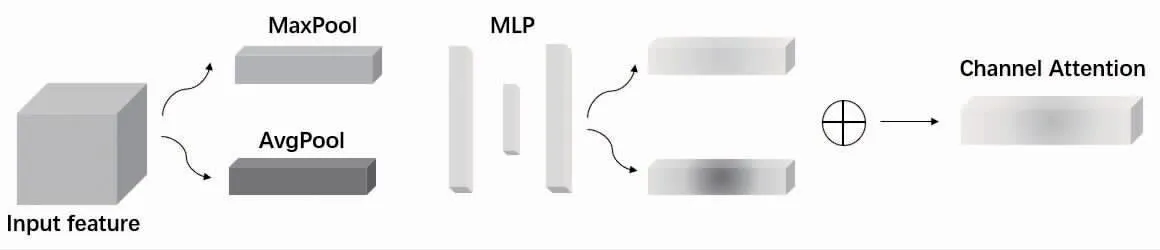
图3 Channel Attention 结构
各个注意力模块(CBAM 模块)的卷积核空洞率(dilation rate)有所差异,卷积核采用不同的感受野范围、堆叠注意力模块的方式获得不同感受野范围(即多尺度)的特征,在原卷积核的基础上获得长距离依赖特征,以此进一步提升模型的特征提取能力。
2 模型应用
2.1 数据集 本研究的实验数据来源于南京中医药大学医学信息实验室中医图像数据库,共检索出2014-2016 年利用手机采集的257 名志愿者的舌图,年龄25~86 岁,包括红色、绛舌、胖大舌、瘦小舌等多种舌象,其中部分志愿者采集了其不同时间段的多张舌图。排除未包括舌体区域的图像后,共纳入367 张舌图构建舌象数据集,其中3 张典型舌图见图4。
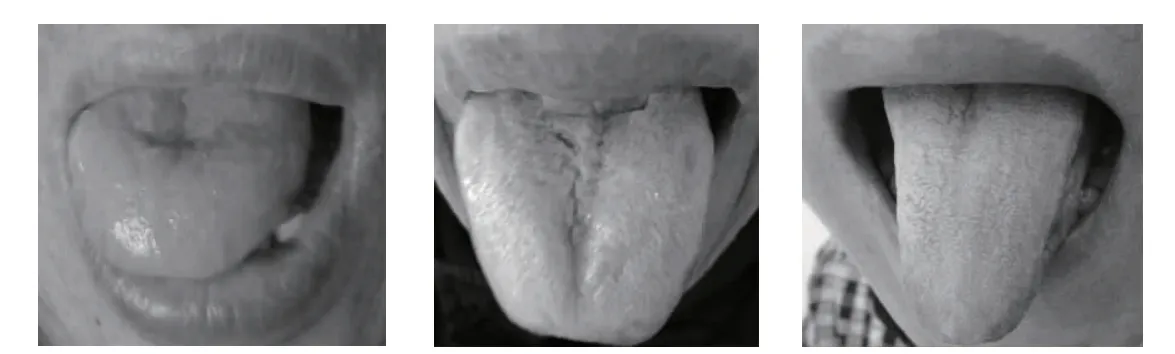
图4 舌象数据示例
2.2 数据预处理 数据集中的体质类型包括:痰湿质89 例、湿热质70 例、瘀血质42 例、气虚质40例、阳虚质34 例、阴虚质32 例、气郁质16 例及平和质3 例,其中气郁质与平和质的样本数较少,因此未纳入此次的体质类别。由于原始图像的大小不一,而全连接层需预定义权重矩阵的大小,因此,实验预先对图像的大小进行了统一,将其随机裁剪至224 像素*224 像素*3 通道大小。
因数据集的样本数有限,实验在输入前进行数据增强,从而更好地模拟舌象拍摄过程中不同的角度或光源亮度对拍摄造成的影响。采用调整亮度的数据增强方法将数据扩充至原来的3 倍。为了统一样本集的数据分布,提升网络泛化能力,实验预先对输入图像进行归一化,将所有样本的像素值调整至[-1,+1]区间内,且在输入网络前将样本随机打散,避免训练集中出现类别不均衡的现象。此外,额外加入有关舌象是否有齿痕、裂纹、芒刺的文本信息辅助训练,其中“有”与“无”采用0 和1 来表示。
2.3 网络参数设计 深度学习网络的部分超参数设置如下:选择Adam[14]作为优化器,交叉熵作为损失函数,学习率设置为1e-5,各卷积层的初始化权重采用截断正则化方式得到。3 个不同的CBMA 模块使用不同的dilation_rate,旨在获得不同感受野范围内,多尺度的特征注意力结果。
2.4 评价指标 采用经典的多分类评价指标[15]宏平均(Macro Average)和微平均(Micro Average)对模型整体进行评价,而针对其中的单个体质采用准确率(Precision,P)、召回率(Recall,R)和F1 进行评价。其中宏平均是针对每个类别的P、R 和F1 求得算数平均值,其计算公式如下:
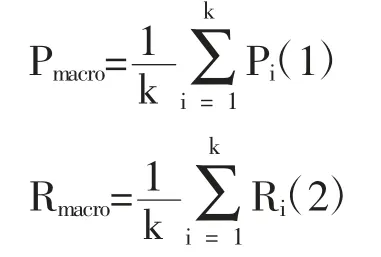
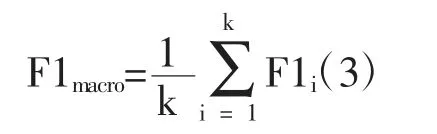
微平均的计算公式如下:
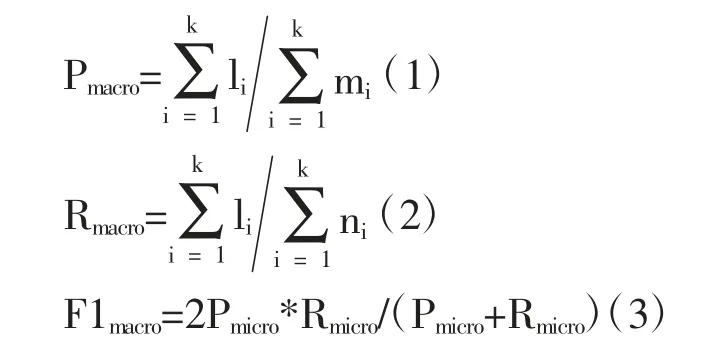
其中k 为类别数据,li 表示模型被预测为第i类且实际也属于第i 类的样本个数,mi 表示模型被预测为第i 类的样本个数,ni 表示实际属于第i 类的样本个数。
2.5 模型训练 采用十折交叉验证法[16]训练模型,设置随机值为1,取十折交叉验证结果作为最终体质分类结果,见表1。各体质类别的分类结果见表2。

表1 体质分类十折交叉验证结果
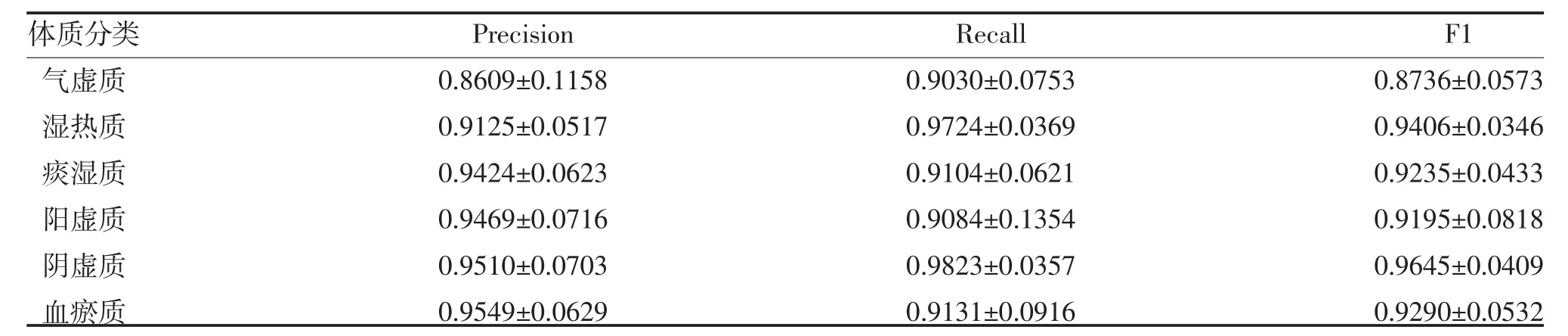
表2 体质分类结果
采用Class Activation Map 思想,对网络最后一层卷积层的特征图进行可视化,判定特征注意力的权重分配是否正确,直观地观察模型的学习结果。以湿热质与阴虚质为例,可视化图像中颜色较深的区域表示模型在学习过程中对该区域特征的关注度较高,见图5、6。可知对于湿热质而言,网络在学习过程中更关注其舌苔,即舌苔特征对于湿热质的分类更为重要;对于阴虚质而言,网络在学习过程中更关注其舌质,即舌质特征对于最终阴虚质分类的贡献程度更高,这与“舌苔反映邪实,舌质反映本虚”的中医理论相吻合。
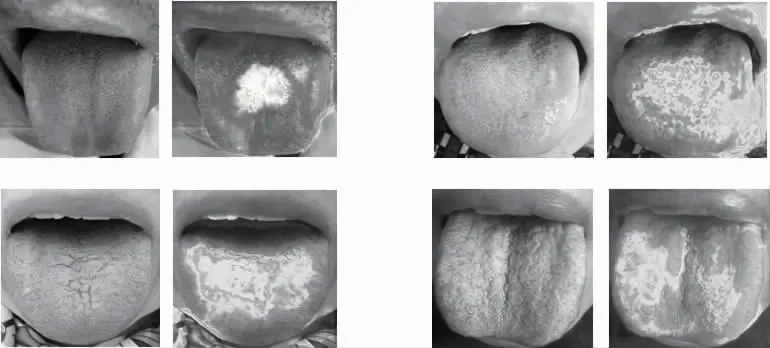
图5 湿热质特征图可视化结果
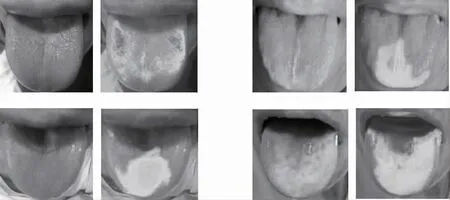
图6 阴虚质特征图可视化结果
3 总结
通过构建多尺度的注意力模型,将注意力模块以残差方式连接,实现多尺度、不同权重的特征学习,同时也适当引入相关文本信息,以图像与文本特征相互结合的方式共同训练模型,以此探寻舌象(外)与最终体质类别(内)之间的潜在关系,最终实现对6 种中医体质(气虚质、湿热质、痰湿质、阳虚质、阴虚质和血瘀质)的分类。本研究算法针对各体质类别的分类精度较高,并且通过可视化的形式观察特征图,直观地显示了训练过程中分配的特征注意力权重,发现其与中医理论相吻合。中医舌诊是中医特诊诊法之一,在健康评估和临床诊疗中发挥了重要作用,通过计算机视觉相关技术,构建舌图到中医体质的有效映射,可以为中医望诊和体质辨识的智能化发展提供参考。
