基于注塑过程数据的制品尺寸合格性判定
2022-11-04宋建王宇峰梁家睿李东
宋建 , 王宇峰, 梁家睿 , 李东*
(1.华南理工大学, 广东省高分子先进制造技术及装备重点实验室, 广州 510640; 2.华南理工大学, 聚合物加工工程教育部重点实验室, 广州 510640; 3.金发科技股份有限公司企业技术中心, 广州 510663)
由于塑料具有可塑性好、冲击强度较高、化学稳定性良好等特点,其制品已被广泛应用于各个行业。数据统计显示,经过“十二五”的快速发展,中国已经成为世界塑料制品生产、出口和消费大国。塑料的成型方法多种多样,主要成型方法包括挤出、注射、吹塑、膜压、层压、浇铸等,其中通过注塑成型工艺制造的塑料产品占了60%以上,注塑成型制品的质量越来越受到大家的关注,但现阶段注塑制品的质量检测主要是人工完成。人工检测不仅速度慢、人力和物力投入大,而且容易造成漏判和误判,因此研究新的解决方法成为亟待解决的问题。
为了解决以上问题,国内外研究者开展了大量的研究。Sadeghi[1]以工艺变量和材料等级变化为输入数据建立了4-2-3结构的BP(back propagation)神经网络预测模型,对注塑制品的质量进行预测。Min[2]采用响应表面分析的方法推导回归方程和优化工艺条件,对制件质量进行预测并间接实现了对注塑过程的在线监控。Zhu等[3]建立了以熔体温度、注塑速率、保压压力为输入数据,制件飞边为标签的模糊神经网络,对制件飞边进行了预测。Dumitrescu等[4]证明使用近红外线光谱监控注塑制品质量是可行的。利用光导纤维探头可以识别材料中的颜色变化和水分,进而实现对制件质量的预测。Chen等[5]以模具温度、保压压力等6个参数作为输入建立了一种反向传播神经网络模型来对注塑制品的质量进行预测。
上述研究均聚焦注塑制品的质量指标或者缺陷的回归预测,但实际生产过程中更关心的是注塑制品的质量指标是否合格。尺寸是注塑制品的重要质量指标之一,合格的注塑制品尺寸必须在公差范围内,否则产品将会判定为废品。鉴于此,现提出一种基于注塑加工过程数据对产品尺寸是否合格进行预测判定的方法,利用注塑成型过程中的成型机状态数据和高频采样数据,直接对注塑制品的尺寸是否合格进行智能判定,期望以此替代现有的人工品检,实现注塑制品质量检测的自动化与智能化,为企业增效降本。
1 数据集与预处理
1.1 数据集来源
本文中所使用的数据主要来源于富士康工业互联网有限公司提供的第四届工业大数据创新竞赛数据集,数据集包括注塑加工过程的SPC(statistical process control)数据和充模过程状态监测传感器的高频采样数据(简称“高频采样数据”)以及作为标签的尺寸数据。
注塑加工过程的SPC数据主要是注塑加工过程中每个模次的成型机台状态数据,通过SPC数据可以观察注塑过程的工艺稳定性,从整个注塑工艺对注塑过程进行分析,例如,温度均值、注射最大压力、填充时间、模具温度等可以通过系统日志进行获取,每个模次采集一次,总共有86维,16 600条数据;高频采样数据主要来源于注塑机的模腔内,冷却系统等通过高频传感器所获得的实时数据,通过高频采样数据可以对注塑过程的具体模块进行实时监测,针对具体的模块对注塑过程进行分析,例如,模腔压力、模腔温度、模温机循环水流量等,传感器的采样频率为50 Hz,总共有16 600个模次,每一个模次采集的传感器数据约为1 500条,总共有24维特征;其中数据集的标签为注塑制品的尺寸数据。
1.2 数据预处理
在注塑加工的过程中,由于设备故障、零件失灵等种种原因会造成数据的不完整。不完整的数据是无法用于数据挖掘的,将其纳入分析会使结论偏离实际情况。因此,对数据进行清洗是非常必要的。数据清洗规则是:对数据集中每个特征的缺失值进行统计,当缺失值达到总量的50%以上时,删除这个特征,而对于缺失值少于50%的特征使用均值进行填充。
在对数据进行统计分析的过程中,发现一些特征本身的价值并不大,但是对这些特征(如温度特征)进行处理后,比如进行均值处理,可以提炼出更加有价值的信息,所以对高频采样数据集进行了特征的构建。高频传感器所采集的模内温度、压力等数据每个模次会进行多次采集,由于频率较高,每个模次采集数量高达1 500多条,其中包含有大量冗余的数据,不仅对模型分类性能的影响较小,而且会增加模型训练时间,因此构建了传感器的均值特征,即将每个模次采集的传感器数据取各个特征的均值。最后合并所有的数据集。
数据集中的标签是某一重要部位的尺寸数值,为了实现分类效果,对标签数据进行重构,将尺寸在[199.96,200.04]mm范围内的合格数据标记为1,不在该范围内的尺寸标记为0。
经过上述处理后,最后得到了58维的新数据集,对此数据集按80%作为模型的训练集、20%作为模型的测试集进行随机分割。
2 特征选取
一个数据集中,与分类目标相关性高的特征有利于提高模型分类的准确性,因此构建模型时,数据集的特征质量对于分类的正确率会有很大的影响。注塑机的采集数据中部分特征与尺寸的相关性较小,这样的特征不仅对分类工作没有太大的帮助,还会增加学习过程的负担,降低模型的运行速率。本文主要使用卡方检测和基于树模型的特征选择方法对数据集进行特征选取。
2.1 特征选取方法
2.1.1 卡方检验(Chi-squared test)
卡方检验的基本思想是通过观察实际值与理论值的偏差来确定两个变量之间的独立性,对于x1,x2,…,xn等多个观察值通过卡方公式得到卡方值,即
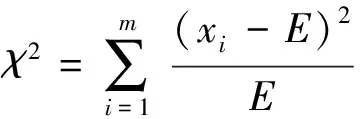
(1)
式(1)中:xi表示观察值;E表示期望值;χ2表示卡方值。
卡方值越大说明对应特征与标签的相关性越大,这个特征就越重要;反之,重要程度就越低。每个特征计算出对应的卡方值,通过计算出的卡方值进行特征重要程度排序,确定阈值,如果大于阈值,则选择该特征,否则,去除该特征。
2.1.2 基于树模型的特征选择法
基于树模型的特征选择法,主要以基尼不纯度的变化量作为特征选择依据。基尼指数是一种对数据不纯度度量的方法,即
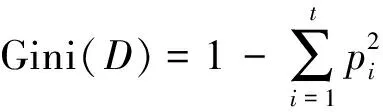
(2)
式(2)中:D为数据集;t为特征总数;pi表示类别为i的样本占总数的概率。基尼不纯度的增量公式为
ΔGini(A)=Gini(D)-Gini(D-A)
(3)
式(3)中:Gini(D-A)为数据集D确定特征A以后的基尼不纯度;ΔGini(A)为加入特征A以后的基尼不纯度的减少量,该值越大表明特征A与标签的相关性越大,可以通过ΔGini(A)对特征的重要性进行排序,设定阈值。当ΔGini(A)大于阈值时选择该特征;否则,删除该特征。
2.2 特征选取维度的确定
使用卡方检测特征选取计算出58维特征的卡方值,以此对特征重要程度排序,计算出58维特征卡方值的平均值为475.6,以475.6作为阈值,当卡方值大于475.6时,选择该特征,否则,删除该特征,共筛选出19维的特征,绘制卡方值的折线图如图1所示。
同样,使用基于树模型的特征选取方法计算出58维特征的ΔGini,以此对特征的重要程度进行排序,计算出ΔGini的平均值为0.016 5,以0.016 5作为阈值,选择ΔGini>0.016 5的特征,共筛选出了19维特征,绘制ΔGini的折线图如图2所示。
不难发现,两种特征选取方法以平均值为阈值选择出的特征维度都是19,最后确定了从58维的数据集中选择出较最重要的19维特征。

图1 卡方检测卡方值折线图Fig.1 Chi square detection chi square value line char
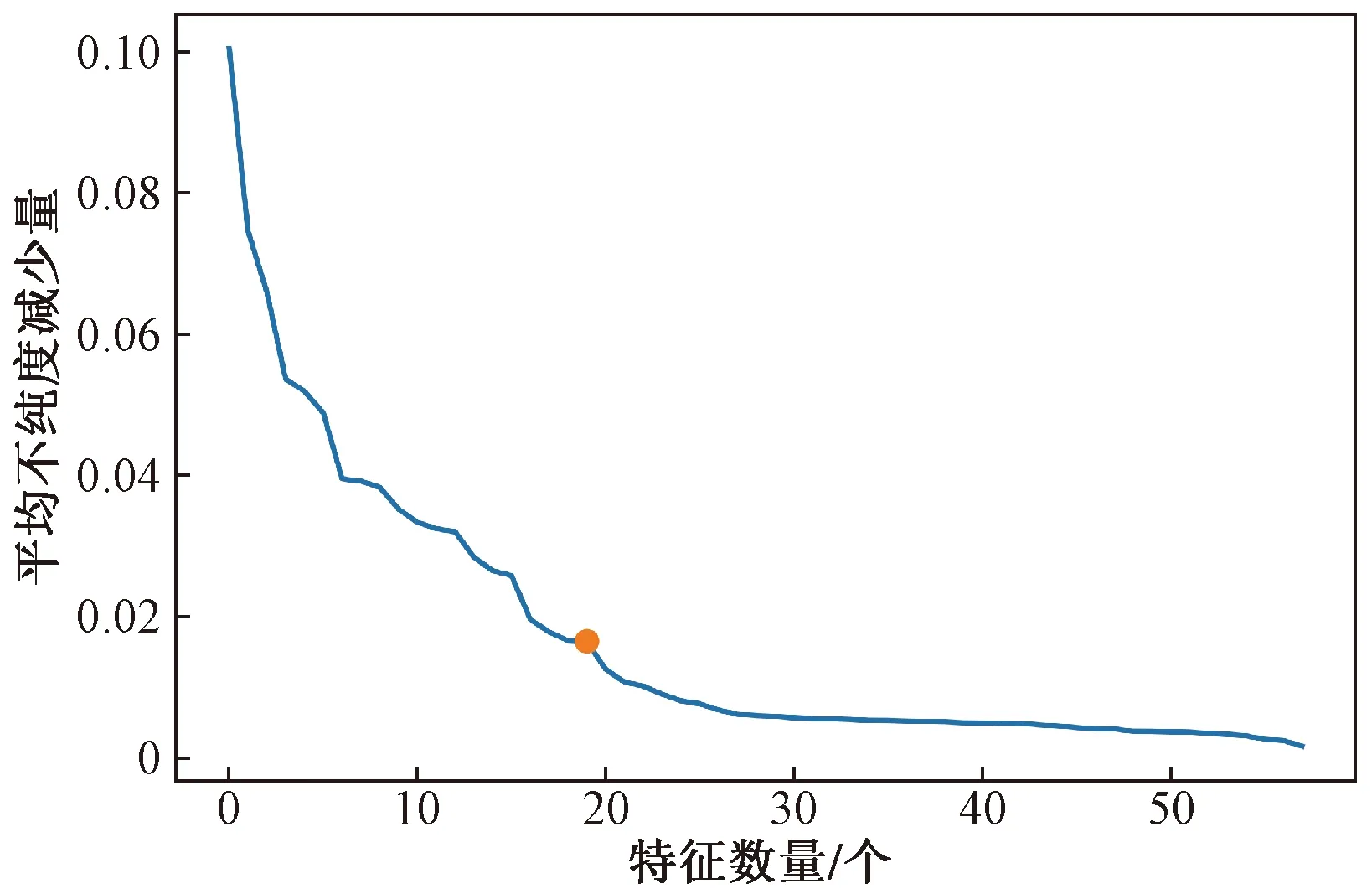
图2 基于树模型的特征选择平均不纯度减少折线图Fig.2 Feature selection based on tree model average impure reduction line graph
3 模型的选择
不同的模型具有一定的适用性,选择一个适合分类模型对注塑成型加工制品尺寸合格性的判定非常重要。通过查阅文献,初步筛选以下7种常用于工业数据分类的模型。
(1)K近邻(Kneighbors classifier,KNN)分类模型[6]:KNN能够直接利用待分类数据与训练样本之间的关系,最大限度减少由于数据特征的不恰当而造成的误差,实现简单,但是精度较低。
(2)逻辑回归(logistic regression,LR)分类模型[7]:LR是利用sigmoid函数进行二分类的分类模型,LR模型高效,但是当有缺失值时表现较差。
(3)贝叶斯(Naive Bayes,NB)分类模型[8]:NB以贝叶斯理论为依据,将事件的先验概率和后验概率联系了起来,通过贝叶斯公式进行分类,在分布独立假设成立的条件下,NB模型的分类效果较好。
(4)决策树(classification and regression tree,CART)分类模型[9]:CART是一种类似流程图的树结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,而每一个叶节点代表一种分类结果,CART树模型速度快、准确度高,但是容易发生过拟合。
(5)随机森林(random forest,RF)分类模型[10]:RF是一种集成学习模型,通过对多棵决策树模型的累加实现,统计每个基学习器分类结果,通过投票来决定终分类结果,集成模型的精度要比单个模型的精度高,但是容易受噪声影响。
(6)支持向量机(support vector machine,SVM)分类模型[11]:SVM通过寻找一个最优超平面对样本进行分割,使得超平面两边的类别间隔最大,SVM不适合海量数据的处理。
(7)神经网络MLP(multi-layer perceptron)分类模型[12]:MLP是最简单最原始的神经网络,主要包括输入层、隐藏层、输出层,而且MLP神经网络不同层之间是全连接的,MLP具有良好的容错性,但是学习速度慢。
以上7种分类模型各有优劣,基于训练集数据采用5折交叉验证的方法对分类模型进行初步的筛选。5折交叉验证主要是将初始的训练集分割成5个子样本,一个子样本作为验证模型的数据,其他4个样本用来训练模型。交叉验证重复5次,平均5次的结果,得到不同模型的验证分数来对模型进行初步的筛选,得到的分数越高,说明模型的分类性能越好。得到的7个分类模型的分数如表1所示。计算7个分数的平均值为0.951,选择0.951以上KNN、SVM、LR、NB、RF等5种分类模型。

表1 5折交叉验证分数表
4 结果与分析
4.1 结果对比分析
为了评估不同分类模型的表现,采用混淆矩阵的相关统计指标和性能曲线来比较不同模型的分类性能,其中使用到的指标[13-14]如下所示。
(1)TP(true positive):合格品被分类为合格品为真正类。
(2)FP(false positive):不合格品被分类为合格品,为假正类,即为漏判。
(3)FN(false negative):合格品被分类为不合格品,为假负类,即为误判。
(4)TN(true negative):不合格品被分类为不合格品,为真负类。
相比而言,比率指标更容易直观地观察出结果的差异,基于以上4个指标,可以进一步得到如下2个比率指标。
(1)TPR(true positive rate):合格品被分类为合格品的样本占所有合格品的比率,即

(4)
(2)FPR(false negative rate):不合格品被分类为合格品的样本占所有不合格品的比率,即
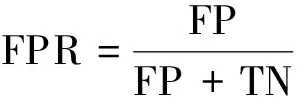
(5)
基于测试集数据使用ROC(receiver operating characteristic)曲线和AUC(area under curve)对各个分类器的性能进行评估[15],其中ROC曲线以FPR为横坐标,以TPR为纵坐标,当曲线越接近(0,1)点时错判的概率就越小,分类模型的准确性越高。AUC表示ROC曲线下的面积,AUC越接近1分类器泛化性能越好。
使用卡方检测特征选择法、基于树模型的特征选择法,可以得到不同的特征组合方式。对比5个分类模型与这两个特征选取方法结合后的ROC曲线和AUC,与卡方检测特征选取结合的分类模型的ROC曲线如图3所示,与基于树模型的特征选取法结合的分类模型的ROC曲线如图4所示,两个特征选取方法下各个分类模型的AUC如表2所示。
对比图3、图4中的ROC曲线可以发现,两个特征选取方法下,LR算法的ROC曲线非常明显得更加靠近(0,1)点,再对比卡方检测特征选取和基于树模型的特征选取下各个模型的AUC的值,LR算法的AUC都是最高的,卡方检测下AUC=0.93,基于树模型的特征选择方法下AUC=0.94,因此LR算法更加适合注塑加工制品尺寸合格性的分类。
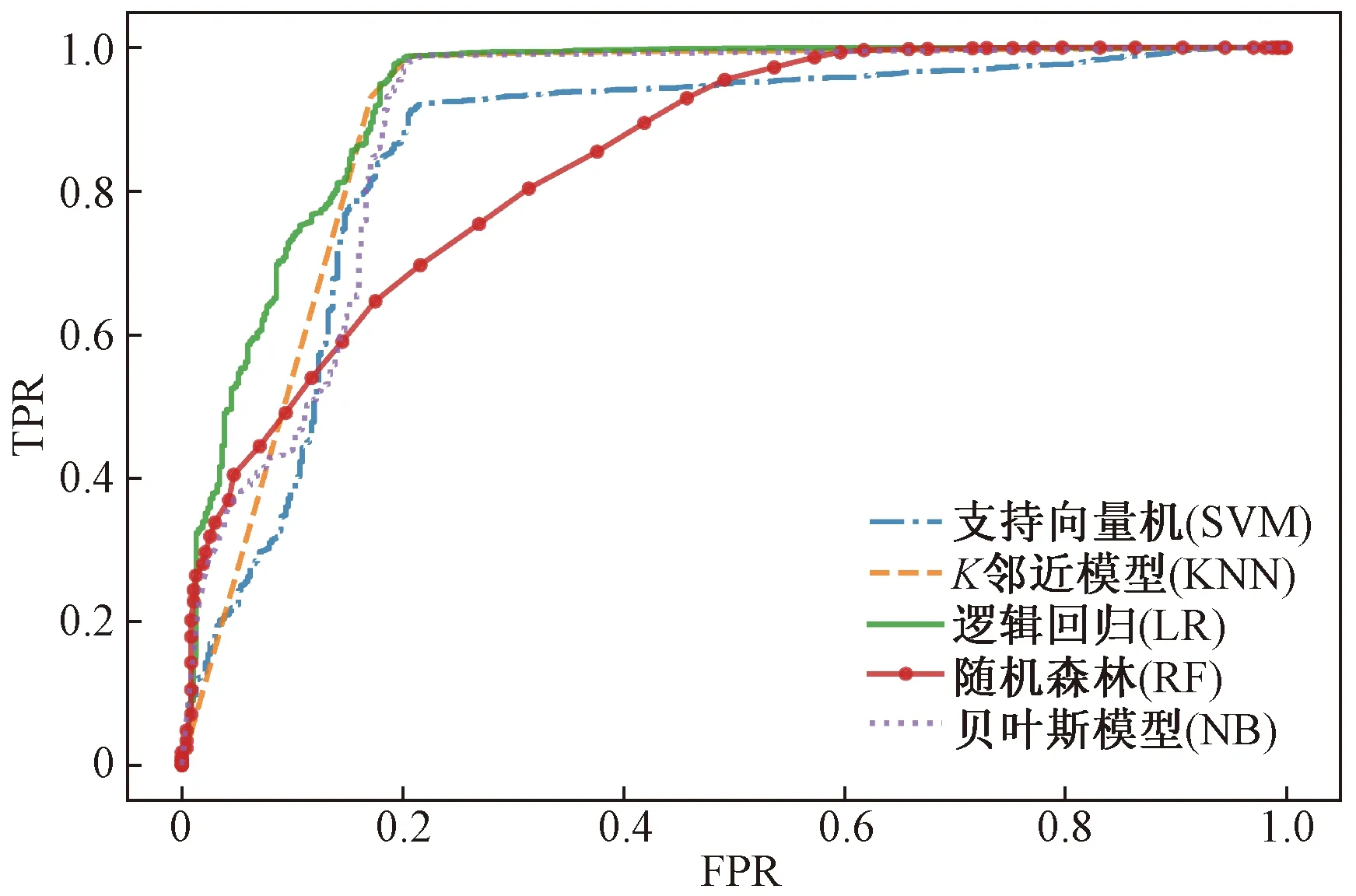
图3 与卡方检测特征选取法结合的分类模型ROC曲线Fig.3 ROC curve of classification model combined with Chi square detection feature selection method

图4 与基于树模型的特征选取法结合的分类模型ROC曲线Fig.4 ROC curve of classification model combined with feature selection method based on tree model

表2 AUC值
通过对表2中两个特征选择方法下5个分类模型的AUC进行对比可以发现,基于树模型的特征选取方法普遍要比卡方检测特征选择方法要高一些,说明基于树模型的特征选择方法更加适合注塑加工制品尺寸合格性的分类。
综合以上分析,最终确定以基于树模型的特征选择方法和LR算法组合的分类模型对注塑成型加工制品尺寸的合格性进行分类,得到测试集的分类结果数据如表3所示。

表3 分类结果数据
4.2 影响尺寸的变量重要性对比
使用基于树模型的特征选择方法对清洗后的数据进行特征变量筛选,保留了特征变量的原有属性。对选择出的特征进行重要性排序,便可看出哪些注塑成型过程变量对制品尺寸合格/不合格分类准确性的影响更大。图5为19个特征变量及其重要度排序。
从图5中可以看出,喷嘴头的射出压力、模温机的温度等对注塑制品尺寸稳定性的影响比较显著,因此当注塑制品的尺寸出现不合格的情况时,可根据本文给出的排序依次对影响较大的特征参数进行检查和调整。
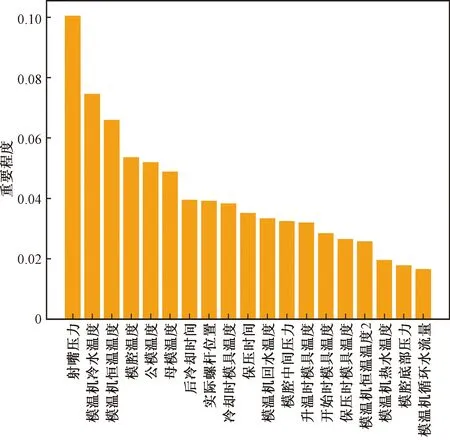
图5 基于树模型的特征选取选出的19个重要特征Fig.5 19 important features selected by feature selection based on tree model
5 结论
基于富士康工业互联网有限公司提供的第四届工业大数据竞赛注塑成型数据集进行了数据清洗、特征选取和标签重构,将数据集切分为训练集和测试集。基于训练集使用5折交叉验证对常用于工业的7种分类模型进行了筛选,选出了KNN、SVM、LR、NB、RF等5种分类模型,分别结合卡方检验和基于树模型的特征选择方法,对比分析了5个分类模型在测试集下与两个特征选择方法结合的ROC曲线和AUC,最后选择了ROC曲线最接近(0,1)、AUC最高的基于树模型特征选择方法与LR分类算法组合的分类模型,分类的准确率可达96.42%。同时,对特征变量重要性进行分析,识别出了对注塑制品尺寸影响较大的特征变量,对生产过程中产品质量的调控具有一定的指导意义。由于本文使用的数据集来源于竞赛网站,研究成果无法反馈服务生产制造环节,略有遗憾,接下来的研究工作将努力改进与提高。
