卡口数据驱动的车辆轨迹重构方法研究
2022-10-12张玉虎郑皎凌
张玉虎,郑皎凌,蒲 良,田 超
(1.成都信息工程大学 软件工程学院,成都 610225;2.中铁电气化局集团有限公司,北京 100036)
0 引言
在城市不断发展的今天,每时每刻都在不断产生车辆轨迹数据,海量的轨迹数据能够挖掘城市车辆移动特性[1],具有很大的研究价值,能够为许多应用领域提供有效信息。例如红绿灯优化[2]、路网预测[3-4]、交通拥堵分析[5-6]等。
现有车辆轨迹数据广泛采用基于位置的服务来记录移动数据,然而用户可能不会允许服务提供者连续地收集移动位置信息,服务提供商之间的数据共享也存在很高的障碍,这些记录下来的移动数据非常稀疏且记录的时间分布不均匀,将会不可避免的使得下游应用的性能下降,即使这些数据具有较高的用户覆盖率和很长的追踪时间[7]。例如由于数据的稀疏性问题,用户只会访问少数几个地点,这样就无法判断用户的兴趣位置[8],且这类使用基于位置服务的数据往往局限于某一个领域[9],无法覆盖到道路上所有的车辆数据,所以迫切需要一个更加丰富且可访问的车辆移动数据。
随着城市道路卡口覆盖率不断提高,每天将会产生海量的车辆移动数据。如此丰富的车辆移动数据,推动着研究人员去使用城市道路卡口收集的大规模数据来重构车辆轨迹。然而使用城市道路卡口产生的车辆移动数据来恢复车辆轨迹仍然十分具有挑战性,因为车辆在城市道路中穿行的过程中并不一定会被道路卡口摄像头连续拍摄,这样记录下来的车辆移动轨迹仍然稀疏且用户在前后2个卡口摄像头之间的移动轨迹具有非常大的不确定性。现有的解决方法是使用卡口收集的大规模视频和图像数据,通过对视频中的车辆图片聚集来还原车辆的移动轨迹[10]。然而由于卡口视频和图像数据中包含了大量的用户隐私数据,大多时候无法直接处理原始数据,而是通过对原始数据脱敏处理后生成的车辆移动的文本数据来还原车辆轨迹。
研究发现,车辆轨迹数据往往具有一定的周期性和重复性特征。通过分析长期的历史轨迹数据能有助于预测用户的下一个位置[11]。但是现实生活中的历史数据的周期性特征往往无法有效从大量的历史车辆移动数据中提取。一种方法是从多个历史轨迹中筛选出最常访问的位置作为候选位置[12],但是历史上最受欢迎的位置不一定是所有时间上都缺少的地点,车辆的流动具有很强的不确定性,无法使用一个固定的位置代表车辆缺少的地点。
针对上述问题,本文提出了一种基于卡口上下文和全局时间嵌入[13]的车辆轨迹重构方法,使用多头自我注意力[14]和动态卷积[15]组成的混合注意力学习卡口上下文之间的关系,将语言表示模型引入到轨迹处理当中。灵感来源于Bert (bidirectional encoder representation from transformers)中引入的掩码语言模型(masked language model,MLM)[16],通过使用上下文所提供的单词预测被掩盖单词。车辆移动数据中包含了车辆通过每一个卡口的数据,其中每一条车辆轨迹中的卡口和车辆轨迹之间的关系类似于单词和句子之间的关系。
1 问题描述
车辆轨迹还原模型的主要步骤包括:① 获取城市道路卡口记录的车辆数据生成车辆历史轨迹,并掩盖掉其中部分卡口数据;② 对车辆轨迹数据中的上下文进行学习;③ 推测出其中被掩盖的真实卡口编号数据以重构车辆轨迹。即根据输入的车辆历史轨迹[t1,t2,t3,t4,…,tn],通过动态掩盖其中部分卡口数据生成车辆轨迹[t1,
城市道路卡口和车辆轨迹中的其他卡口关联性可以定义为:
(1)
其中,Context(ti)={t1,…,ti-1,ti+1,…,tn}表示和卡口ti出现在同一条轨迹中的其他卡口。然后,利用最大对数似然对轨迹建模,目标函数为:
F=logp(ti|Context(ti))
(2)
在此模型中,对于每一条轨迹中被掩盖的卡口ti,都希望F最大。
定义1(车辆历史轨迹)。车辆历史轨迹定义为Tj={ti|i=1,2,3,…,n},1≤j≤n,其中ti={Cid,Sid,Lon,Lat,Time},Cid为车辆编号,Sid表示卡口编号,Lon表示卡口经度坐标,Lat表示卡口纬度坐标,j为时间步大小。
由于卡口生成的车辆移动数据是一系列按照时间顺序排序且携带了车辆编号、卡口编号、地理坐标和被拍摄时间信息的轨迹点,这些数据在时间上是连续的,为了生成符合模型的输入,需要将车辆移动数据按照不同的时间步长将连续时间车辆移动数据拆解,如果在同一个时间步长内具有多个卡口数据,使用在这个时间步长内的第一个卡口数据。例如T1是指将卡口生成的车辆移动数据按照以1分钟为时间步长取每一个时间步长内的第一个卡口数据生成的车辆轨迹,T1中的ti是编号为Cid的车辆在时间为Time经过经纬度为Lon,Lat的编号为Sid的卡口。
定义2(车辆掩盖轨迹)。给定一个目标车辆Cid的历史轨迹[t1,t2,t3,t4,…,tn],被掩盖后的车辆轨迹则可能为[t1,,〈masked〉,t2,t3,〈masked〉,…,tn]。其中〈masked〉指代被掩盖的卡口数据。
卡口生成的车辆轨迹在输入模型进行学习前,需要将车辆轨迹中的部分卡口数据进行随机掩盖,为了实现更多的掩盖策略,本文使用动态掩码方式对车辆轨迹进行掩盖。在训练前生成固定数量和方式的掩盖策略无法覆盖多样的缺失卡口序列,改为在每一次向模型输入一个新的序列之前随机生成一个新的掩盖策略,则能覆盖更多序列。
2 模型
针对车辆移动轨迹中的周期性、重复性特征和城市道路卡口上下文关系构建的系统框图如图1所示。将历史车辆卡口轨迹中的卡口向量化表示,为了模拟更多的轨迹缺失片段,使用动态掩盖方法对卡口生成的车辆移动轨迹进行遮盖。为了捕获车辆轨迹的周期性和重复性特征,使用局部时间嵌入和全局时间嵌入获取局部时序信息和全局时序信息,这样可以更好地重构车辆轨迹。最后,使用混合注意力学习轨迹上下文中已知卡口的序列来预测被掩盖的卡口信息。

图1 算法流程框图
2.1 时间嵌入模块
车辆在每一天中的相同时间从起点卡口到终点卡口的选择很有可能会是相似的,且车辆移动轨迹数据中记录的车辆通过每一个卡口的时间数据代表了车辆轨迹中的时间信息,通过获取不同卡口和时间之间的关系,将有助于恢复缺失的卡口,然而车辆轨迹中时间信息和不同卡口之间往往存在着复杂的时间关联性,无法简单的通过规则来描述其中的关系,为了将不同时间的卡口上下文情景区分开,获取车辆移动数据中的周期性和重复性特征,使用局部时间编码和全局时间编码,将车辆轨迹中所有时间数据嵌入。
2.1.1局部时间嵌入
沿用自然语言处理中单词的上下文说法形容车辆轨迹中不同卡口之间的关系。由于车辆轨迹中卡口上下文之间存在先后的关系,为了表示每一条车辆轨迹中卡口的局部上下文关系,将其中的局部位置进行编码嵌入。具体来说,对于每一条车辆移动数据使用固定位置嵌入,使用Transformer[14]中的位置编码 (position embedding,PE)对车辆移动数据中的局部时间进行编码,计算公式如下:
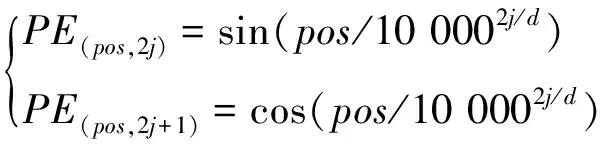
(3)
其中,pos表示卡口数据在整个车辆轨迹中的位置,1jd,j代表第j个维度,d代表嵌入的维度。将车辆中所有卡口的位置进行嵌入,使得原始的输入数据获得更多的上下文信息。
2.1.2全局时间嵌入
为了获取车辆轨迹中的周期性和重复性特征,单一使用局部时间嵌入不能捕获长时间车辆移动数据的全部特征,因为在不同时间下每一个卡口的语义和上下文信息是不同的,为了捕获长时间车辆轨迹中的特征,本文使用全局时间嵌入将层次时间信息进行嵌入,其中每一个全局时间嵌入使用一个可学习且词典大小有限的时间嵌入 (time embedding,TE)表示,当类别为小时时,词典大小为24。例如轨迹中的一个卡口记录时间在早上7点,则将7随机初始化为词典大小为24、嵌入维度为d的嵌入向量并随模型的学习不断更新,计算公式如下:
(4)
其中,p代表的是某一个类型的全局时间戳。在长时间的车辆移动数据中,不同的时间戳类型,如小时、周、月、节假日等数据,将车辆移动轨迹中不同位置、不同时间类型的时间戳嵌入后相加,使得每一个卡口数据中包含的更多时间信息被充分利用。在使用全局时间嵌入时,本文使用一天中的某一个小时和一周中的某一天2种时间戳进行嵌入。将卡口编号Sid随机初始化为维度为d、字典大小为576的向量u,学习模块输入计算如图2所示。
将卡口编号嵌入后的向量、局部时间嵌入和全局时间嵌入结合,得到输入到学习模块中的向量,计算方式如下:
xi=ui+PE(i, j)+vi
(5)
其中,1≦i≦n,1≦j≦d,xi为卡口ti输入到学习模块中的向量。
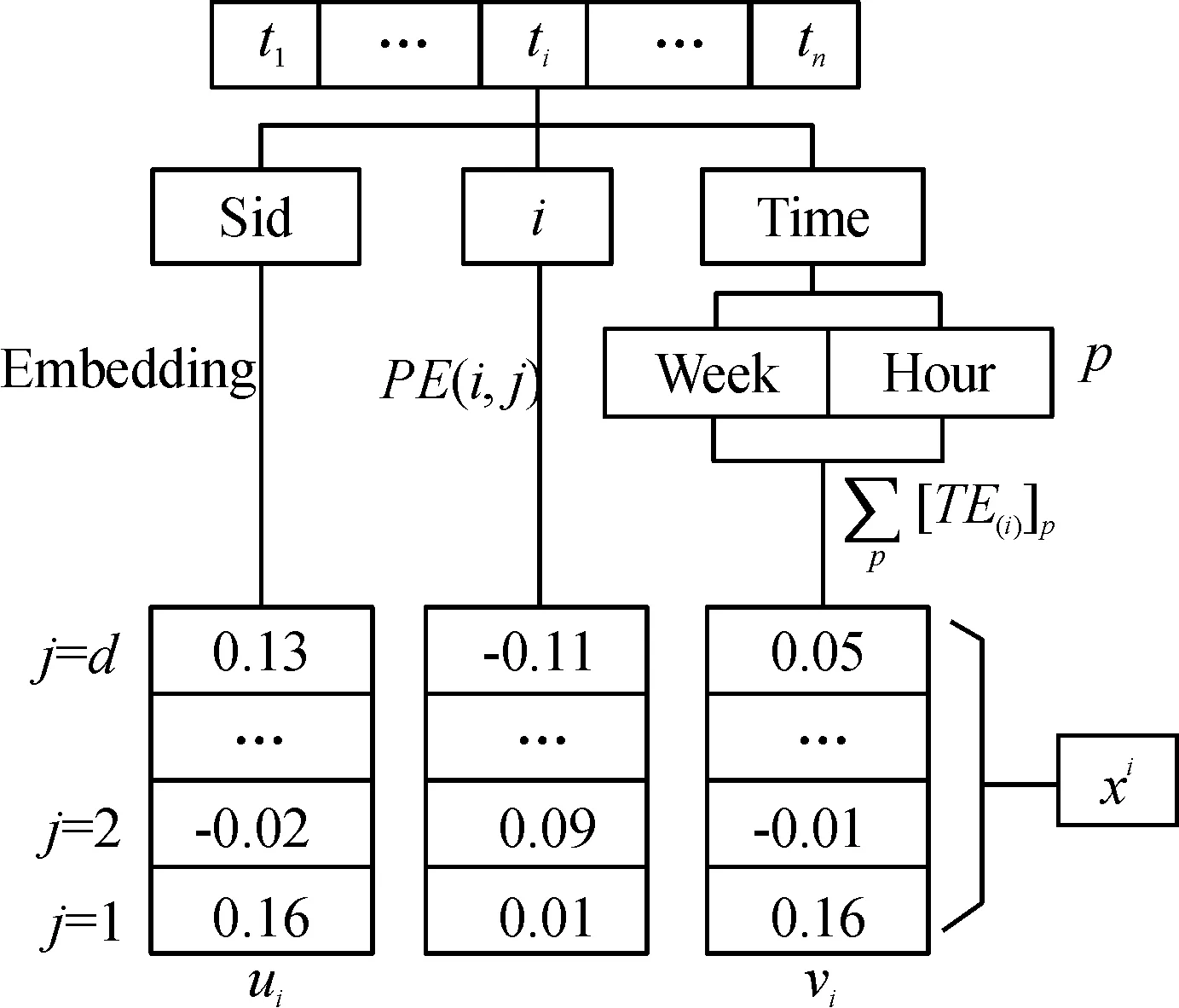
图2 学习模块输入向量
2.2 学习模块
2.2.1自我注意力
自注意力机制能够有效地从时间序列数据中学习复杂的模式和变化,例如通过使用Transformer模型学习流感疾病的时间序列来预测流感疾病在未来的变化[17]。本文为了还原车辆轨迹中被掩盖卡口的Sid数据,使用Transformer中的编码模块让卡口学习不同上下文的关系,以提高车辆轨迹还原的准确性。单个头下的轨迹注意力机制如图3所示。
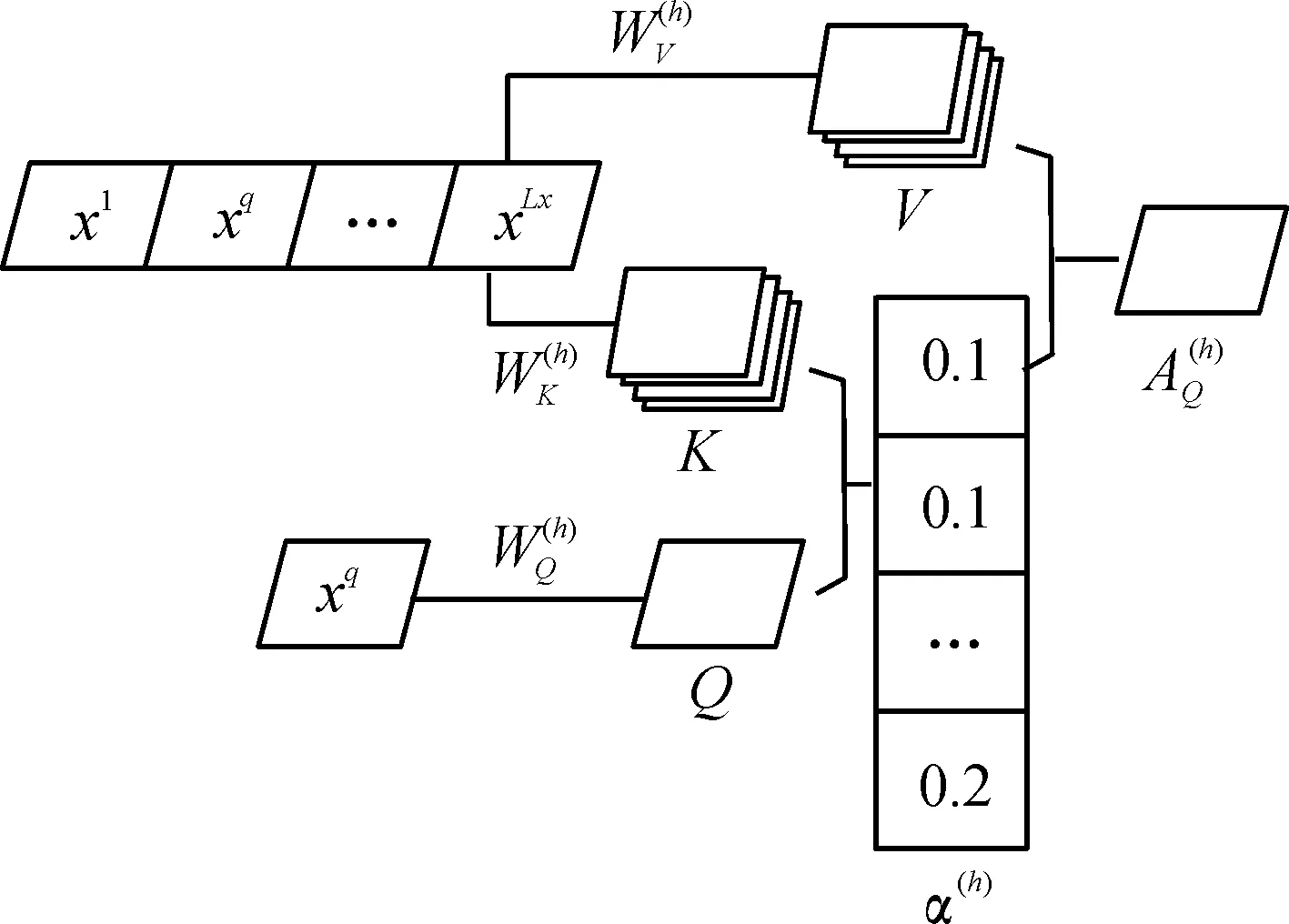
图3 单个头下的轨迹注意力机制
本文使用双向注意力机制计算不同时隙之间的相关性。例如,当前车辆轨迹生成嵌入向量中的时隙q和时隙p在h头下的相关性计算方式如下:
(6)
(7)
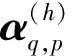
(8)
其中,Wv∈Rdk×d同样是一个变换矩阵。双向自我注意力机制能够获取车辆轨迹中前后卡口信息,从而更精准地推断缺失位置的卡口信息。但是车辆轨迹中含有多种复杂的关系,通过使用多头注意力机制进行计算能够获取多种关系的信息,计算方式如下:
(9)
其中,‖是concatenation(·)方法,H是总的头部的数量。通过在每一个头下学习到不同的关系,并将每一个头下面的注意力机制都组合起来,得到能表达更多车辆轨迹信息的数据。最后计算所有输入车辆轨迹中的时隙和同一轨迹中的其他时隙的相关性,更新时隙的嵌入向量,双向自我注意力中有H个自我注意的头,则Q、K和V嵌入向量被均匀地分割为dk=d/H维度,输入向量的双向自我注意力输出计算方式如下:
(10)
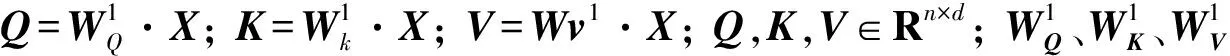
2.2.2混合注意力
多头注意力模块中,所有注意力头的查询都作用于整个输入序列,从全局角度生成注意力聚焦的信息。但在车辆轨迹中每一个时间步的卡口和相邻时间步的卡口关系显然更加紧密,卷积操作能够有效提取局部上下文信息[18-20],使得预测的结果更加准确。本文使用动态卷积提取卡口之间的局部关系,动态卷积如图4所示。

图4 动态卷积
将输入的维度从d映射到2d,然后使用门控线性激活函数计算输入,将一半的输入使用sigmoid函数计算后和剩下的一半输入进行点积操作。使用轻量级卷积建模局部的依赖关系,轻量级卷积是参数共享的深度卷积,轻量级卷积将权重和通道维度绑定,可以将卷积核简化为W∈Rk,轻量级卷积计算公式如下:
(11)
其中,卷积核被记为W∈Rk,x为输入向量,即车辆轨迹的嵌入向量,k为卷积核的宽度,i为深度卷积输出的第i个位置,c为输出的维度数,轻量级卷积计算时,卷积核的参数都是固定的,不利于获取卡口的多样性,但可以利用函数动态生成卷积核,动态卷积的计算公式如下:
(12)
其中,x为输入向量,在计算位置i时使用了一个位置相关的卷积核Wf=f(xi),f是一个具有可学习权重的线性模型,最后使用Softmax归一化每一个卡口的每一维。为了将全局信息和局部信息结合,使用concatenation方法将多头自我注意力生成的全局信息和动态卷积信息结合生成混合注意力信息,如图5所示。
计算公式如下:
(13)
其中,‖是concatenation(·)方法,SelfAttn(·)为自我注意力模块的输出,DynamicConv(·)为动态卷积模块的输出,最后将生成的混合注意力信息输入到前馈层进行处理。
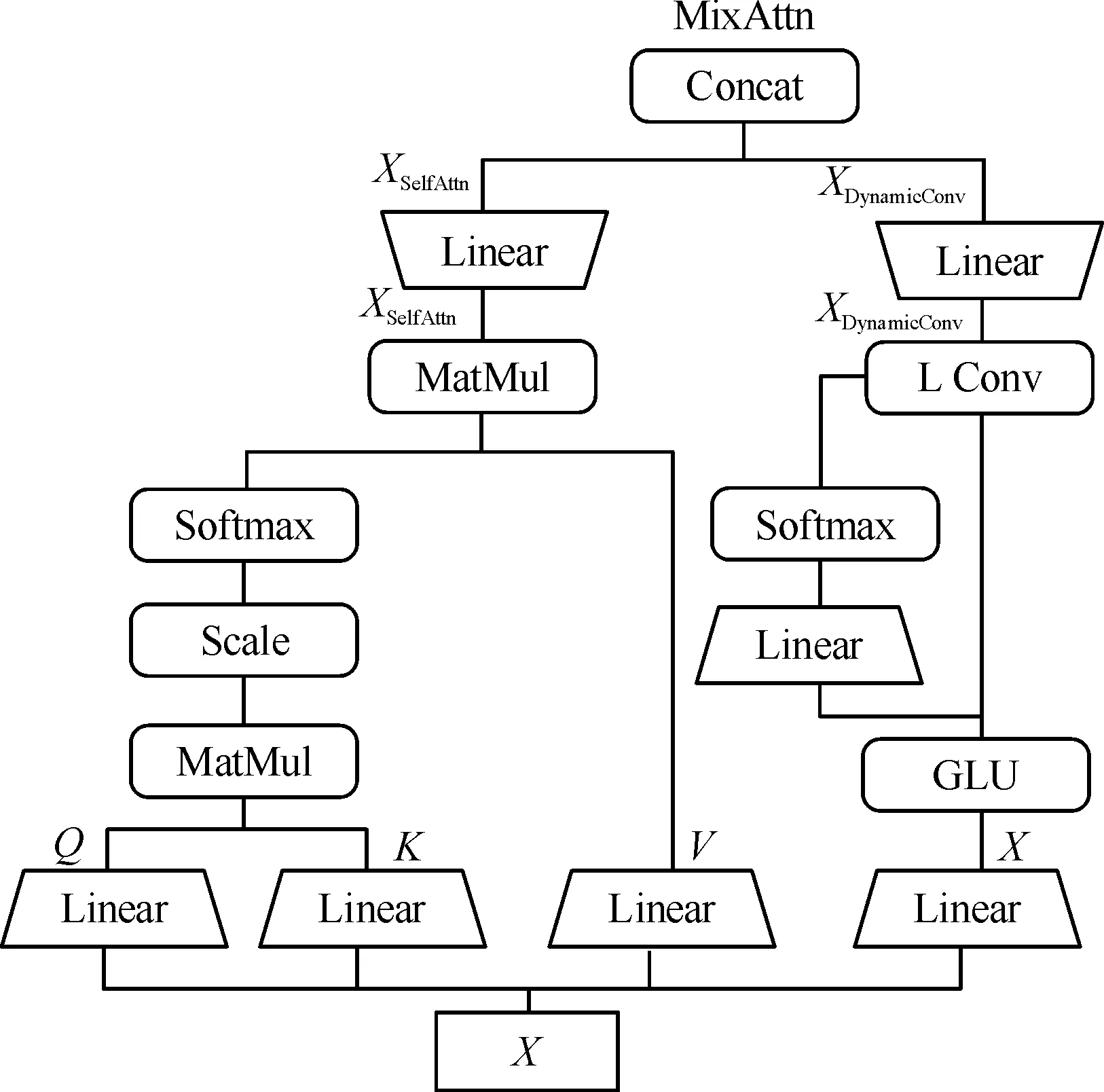
图5 混合注意力
2.2.3前馈网络
为了保持每一个位置的原有信息,在之后加入一个标准的残差连接并使用层归一化将网络中的隐藏层变为标准的正态分布。最后使用两层线性映射并在中间加上激活函数进行计算,计算方式如下:
X=Relu(XW1+b1)W2+b2
(14)
其中,X为混合注意力网络的结果输出,W1∈Rd×dff,W2∈Rdff×d是变换矩阵,Relu(z)=max(0,z)是非线性激活函数。
通过叠加多个Transformer的编码结构,学习车辆轨迹中不同卡口之间的上下文关系和卡口之间的相关性,用于获取不同时间、不同位置的卡口语义信息。
在最后一层编码器的输出上加入一个全连接的Softmax层,计算出被掩盖位置的卡口,输出所有卡口Sid是被掩盖的真实卡口Sid的概率,将概率最高的卡口选为被掩盖位置的输出。最后仅在被掩盖位置上的输出概率分布和真实标签之间使用交叉熵损失函数计算损失,计算方式如下:
(15)
其中,N为样本总数,M为卡口总数,a为被掩盖真实卡口的编号。当a=s时,yas= 1,否则yas= 0,pas为第a个还原轨迹中被掩盖的卡口编号属于s的预测概率。同时使用Adam优化器[21]进行梯度优化,通过小批量的随机训练得到梯度的变化并优化模型的权重。
2.3 算法流程
通过对原始的卡口数据进行处理得出,车辆在2个相邻卡口的通行时间在2 min以内的数据占比为61.91%,表明绝大多数车辆能在2 min以内通过2个相邻卡口。本文在生成阶段使用以2 min为间隔获取卡口,将总数大于6的卡口集合作为车辆的原始轨迹。实验使用算法1计算原始的车辆轨迹,算法1详细如下:
算法1:生成车辆轨迹
输入:城市道路卡口记录的数据
输出:车辆轨迹T2
1:TList← 城市道路卡口记录的数据
2:TList← 城市道路卡口记录的数据按照Cid聚集
3:fori(iinTList)do
4:i← 将聚集的卡口记录数据按照时间排序
5:time← {i中第一个卡口记录的时间,0}
6:k← 0

8: forj(jini) do
9: iftime[1]< 2 do
10:time[1]←j中记录的时间-time[0]
11: end if
12: iftime[1]> 2 andtime[1]< 4 do
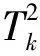
14:time← {j中记录的时间,0}
15: end if
16: iftime[1]>2 andtime[1]> 4 do

18:k←k+ 1
20: end if

23: end if
24:time← {j中记录的时间,0}
25: end if
26: end for
27: end for
在学习阶段,通过掩盖其中的卡口来学习车辆原始轨迹中的卡口和前后卡口之间的联系,在真实预测阶段使用Argmax计算最终输出中概率最大的卡口的Sid为被掩盖卡口的Sid。还原出来的车辆轨迹中的卡口集合使用Hidden Markov map matching算法[22],将卡口集合和实际地图匹配,还原出车辆的真实地图轨迹。车辆轨迹重构算法详细如下:
算法2:GT-Recovery
输入:城市道路卡口记录的数据
输出:被掩盖的卡口Sid数据
1:T2← 使用算法1生成车辆轨迹
2:TTrain←T2中前21天数据为训练集
3:TTest,←T2中后7天数据为测试集
4: 使用多头注意力和动态卷积实现混合注意力
5:学习模型编码层数为3,混合注意力中头数为4
6:Train← 将TTest按照每一次的训练的大小随机抽取其中的车辆轨迹生成学习模型的训练集
7: fori(iinTrain) do
8: 使用动态掩盖生成轨迹i的掩盖策略
9:X← 通过式(5)计算车辆的输入向量
10: forj(jin 3) do
11:MixAttn← 通过式(13)计算混合注意力网络的输出
12:X← 使用残差连接和归一化计算混合注意力网络的输出
13:X← 通过式(15)计算前馈网络输出
14:X← 使用残差连接和归一化计算混合注意力网络的输出
15:X← 使用Softmax计算每一个卡口是掩盖卡口的可能性。计算的结果中可能性最大的卡口Sid为目标结果。
16: 使用式(16)计算损失
17: 使用Adam进行梯度优化
18: end for
3 实验结果及分析
3.1 数据集
使用中国四川某市的576个城市交通卡口摄像头所采集的车辆移动数据。数据记录了2020年10月所有卡口拍摄到的记录。由于卡口摄像头拍摄的视频数据含有海量的敏感信息,所有的视频数据都被处理为结构化的文本数据,每天所采集的过车数据量大小为106级,车辆移动数据如表1所示。由于道路上摄像头经纬度的敏感性,其中经纬度信息不做展示。

表1 车辆移动数据
在将数据投入模型进行训练之前,对车辆移动数据进行预处理。首先,由于城市道路卡口大多安置在交叉路口上,车辆在通过卡口时可能会被多次记录,因此,在预处理时只保留车辆轨迹中相邻且重复的最后一个卡口数据。其次,将车辆轨迹中速度异常的卡口进行删除。最后,以2 min为时间步选择出车辆轨迹中卡口数量大于6的车辆轨迹来进行轨迹还原。本文经过预处理后共有420 000条车辆轨迹。
3.2 实验设置
3.2.1实验环境
本文模型使用Tensorflow实现,在Linux服务器上训练。该服务器的具体配置参数为:Ubuntu 18.04 LTS操作系统,GPU型号为I7-7700K,2条12 G显存的Nvidia RTX 2080Ti显卡。
3.2.2实验细节
实验的评价指标是根据被还原的卡口来进行计算的,使用Recall@k作为标准[9,12],如果正确的卡口能以最大概率恢复,则Recall@1等于1,否则等于0。最终的Recall@k是所有测试用例的平均值,Recall@k值越大,表明模型的性能越好。
为了评估性能,遮住部分车辆轨迹中的卡口数据,并将遮住的卡口作为真实值进行恢复,屏蔽其中30%的位置,掩盖车辆轨迹中1到6个卡口进行车辆轨迹的恢复。数据集按照时间划分,将最后一周中的82 000条车辆轨迹作为测试集,前面的338 000条车辆轨迹作为训练集。模型训练时随机读取车辆轨迹进行学习。使用的模型由3层含有混合注意力的编码器构成,卡口嵌入维度为256,每一个编码器由4头自我注意力和动态卷积组成。
3.3 算法还原性能
3.3.1不同算法性能
Top算法[12]是一种简单的基于计数的方法,在恢复时将其中最流行的位置用于恢复轨迹。
History算法[11]使用历史轨迹的每个时间段中最常被访问的位置来恢复轨迹。
RF算法[11]使用基于特征的机器学习方法。提取各轨迹的缺失时隙,并将缺失时隙的前后位置作为特征,训练随机森林分类器来进行恢复。
为了方便表达,使用GT-Recovery表示本文中的模型。从表2中可以分析出,传统的基于规则的模型均无法达到较高的准确率,虽然直觉上历史数据中经常被访问的地点有助于恢复车辆的移动轨迹,但是由于车辆移动的不确定性,传统的方法无法准确捕获车辆复杂的移动规律,单纯基于规则就无法准确恢复车辆轨迹。通过使用混合注意力机制编码层,可以更好地捕获车辆轨迹的移动特征,并较为准确地还原车辆轨迹中缺少的卡口。通过实验对比,使用基于卡口上下文学习和全局时间嵌入的模型能更好地还原车辆轨迹,证明了本文提出的方法能更有效地捕获车辆的移动方式、周期性特征和重复性特征。

表2 实验结果指标
3.3.2消融实验
测试了所有模块对最终结果准确率的影响,将模型中不同模块去掉,观察准确率的变化情况,结果如表3所示。其中GT-Recovery-G表示减去全局时间的结果,GT-Recovery-D表示减去动态掩盖后的结果,GT-Recovery-M表示减去局部上下文信息后的结果。分析可知,GT-Recovery优于所有的去掉模块后的结果,其中去掉全局时间后下降最多。对比GT-Recovery模型和GT-Recovery-G模型发现,在车辆轨迹嵌入时加入时间信息能够降低最后恢复的不确定性,提高还原的准确性。然而比较GT-Recovery-M模型和GT-Recovery模型,可以发现加入局部上下文信息后的提升有限,这是由于轨迹中的卡口数量较少,主要依赖轨迹全局信息恢复轨迹中缺失的卡口。

表3 消融实验结果指标
3.3.3不同缺失程度下的性能
通过测试模型在不同卡口缺失率下的恢复被掩盖卡口的性能,验证模型是否能够处理不同缺失率的情况,分别研究了卡口被掩盖的概率在30%~50%、50%~70%和70%~90%时的卡口恢复情况,掩盖其中的卡口时不会掩盖第一个和最后一个卡口数据。通过表4可以看出,随着车辆卡口缺失率的上升,卡口还原的准确率在不断下降,但还原准确率下降的趋势却不明显。一是为保证轨迹的原始通行信息,本文保留了车辆轨迹的起点卡口和终点卡口,且能被卡口连续记录的车辆轨迹较少,通过计算测试数据得出,车辆卡口轨迹中的卡口数量在6~8时占比为82.26%,在保留车辆起点卡口和终点卡口后,卡口缺失率在30%~90%的实际缺失的卡口数量差距并不明显。二是由于大多数车辆在通过具有相同起点和终点的卡口对时选择的路径是相似的,但实验结果表明,通过嵌入车辆轨迹的周期性和重复性特征,使用本文的模型还原车辆轨迹中缺失的卡口数据时,在数据缺失率增大的情况下,仍然具有更好的还原准确性。
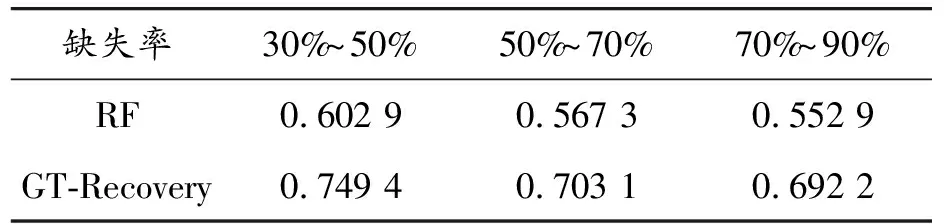
表4 不同缺失率下的实验结果指标
3.3.4不同嵌入维度下的性能
本文研究了嵌入维度数d、多头自我注意力机制的头数H和基于混合注意力机制的编码层数L对于车辆轨迹还原性能的影响,图6中显示了不同的嵌入维度在车辆轨迹还原中准确率的变换,在嵌入维度不断增加的情况下,还原的准确率也在逐步提高,在嵌入维度大于256后,最终的还原性能趋于稳定,使用大于256维度的嵌入,准确率将不会有巨大的提高,所以选择256作为模型的嵌入维度。图7中显示了不同自我注意力机制的头部数量和不同数量的编码层对于模型性能的影响,从图中可以得到,使用头部数量的多少对于最终还原的准确率影响不大,但使用更多的基于混合注意力机制的编码层能获得更好的还原准确率。通过对最终还原效果和效率的权衡,本文模型在训练时使用3层由4个头部数量的多头自我注意力模块和动态卷积模块组成的混合注意力模块构成的编码层。

图6 不同嵌入维度下的还原准确率
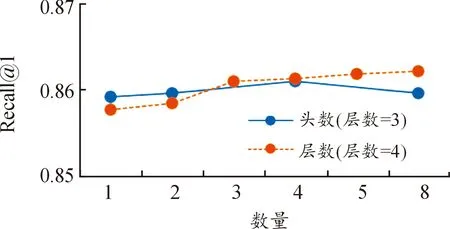
图7 不同头数和编码层数下的还原准确率
4 结论
利用城市中覆盖率不断提升的卡口摄像头生成的数据,对车辆轨迹进行还原,提出了一种基于卡口上下文和全局时间嵌入的城市车辆轨迹还原方法。使用全局时间嵌入和局部时间嵌入结合的方法,捕获车辆轨迹移动中的周期性特征,使用动态掩码语言模型模拟车辆轨迹在不同缺失率情况下的数据,将嵌入后的数据通过编码层中的混合注意力对车辆轨迹中的卡口上下文进行分析和学习。最后对比生成的结果和被掩盖结果,结果表明,模型能够更加有效地捕获车辆的复杂移动特征并能够较为准确地将被掩盖的车辆轨迹进行还原。但是由于城市卡口在记录通行车辆时具有很大的不确定性,车辆无法在一定时间步长内被多个卡口连续记录,使得车辆轨迹数据量不够大。在未来的工作中,将会考虑更多不同数据对于车辆轨迹还原的影响,探寻影响车辆移动模型的更多因素。
