电动汽车城市道路行驶工况特征参数智能混合搜索算法研究
2022-10-12吴若园罗文广覃永新蓝红莉
吴若园,罗文广,覃永新,蓝红莉,庞 娜
(1.广西科技大学 电气与信息工程学院,广西 柳州 545006;2.广西汽车零部件与整车技术重点实验室,广西 柳州 545006)
0 引言
汽车行驶工况既能为传统汽车设计提供动力匹配参考,降低燃油消耗率,减少污染物排放,也有助于设计新能源汽车高效动力系统和储能系统,通过合理分配电池功率降低能源消耗,提升行驶里程,对汽车工业发展具有重要意义[1-3],是目前的主要研究热点。除了目前已有的如新欧洲驾驶循环(new European driving cycle,NEDC)、世界轻型车测试循环(world light vehicle test cycle,WLTC)以及中国轻型车行驶工况(China light-duty vehicle test cycle,CLTC)等标准工况外,一些国家和地区也自行建立了符合当地车辆行驶情况的行驶工况,如都柏林工况[4]、南京工况[5]、上海工况[6]等。同时,研究人员根据当地车辆行驶情况建立了许多行驶工况识别模型,如学习向量化(learning vector quantization,LVQ)识别模型[7]、神经网络识别模型[8]等。
行驶工况特征参数最优子集是建立高性能工况识别模型的必要前提。Montazeri-GH等[9]建立了一种基于单一行驶工况特征参数的工况识别模型,但是对于复杂的行驶情况,这种仅基于车速的识别方法是不可靠的。罗玉涛等[10]将平均行驶车速和行驶距离这2个参数作为模糊控制器的输入变量仅能模糊辨识工况,而用时间等10个参数作为特征参数进行聚类分析,能得到更量化的工况类别属性。由此可见,为了提高工况识别的准确率,选择作为识别模型输入的特征参数数量要在合理范围内:若数量太少,则汽车行驶特点无法全面表征;若数量太多,则会造成维数灾难,加重计算负担。针对行驶工况特征参数选择问题,Wang等[11]利用数理统计方法筛选出5个特征参数,并用LVQ网络对增程式电动客车行驶工况进行识别;邓涛等[12]用统计直方图选出了9个特征参数,参数之间有显著差异,代表的行驶特点具有全面性,使LVQ神经网络识别模型准确率达到98.8%;仇多洋[13]通过直方图和盒形图方法筛选出各典型工况下存在较大差异的特征参数,最终选出平均速度等14个特征参数作为基于粒子群优化的LVQ行驶工况识别模型的输入参数。
特征参数选择算法主要基于Filter和Wrapper 2种框架进行运算。基于Filter框架特征参数选择算法是按照特征的重要性进行排序后“过滤”掉无关特征形成特征子集[14]。Munirathinam等[15]提出了一种基于Filter框架的特征选择模型Noisy Feature Removal-Relief (NFR-reliefF),有效地解决了高维数据的分类问题;Jha等[16]提出的多模态多目标优化(multi-modal multi-objective optimization,MMO)的Filter框架特征选择算法,不仅在准确度上有优势,而且为决策者提供了更多的最优子集。基于Wrapper框架特征参数选择算法通过评估封装在一起的分类器性能确定特征子集[17-18],已被广泛地用于情感分类[19]、早期糖尿病预测[20]、基因选择和癌症分类[21]等。上述2种框架的特征参数选择算法都是针对特定的特征参数全集进行计算,而对行驶工况特征参数分析后发现,分段参数部分的参数边界是不确定的,通常由研究人员按照经验或者根据需要定义,不同的参数边界对应的是不同的特征参数全集。迄今为止,对于这种特征参数选择算法的研究甚少,田毅等[22]采用内外两层循环的混合搜索算法,用自适应遗传算法搜索优化分段参数部分的参数边界,并用浮动搜索算法选择出了混合动力汽车特征参数最优子集。
针对行驶工况特征参数选择问题,将实车采集的数据预处理后进行运动学片段划分及主成分分析和聚类分析,产生训练分类器的训练数据集和测试数据集,并提出了一种基于智能混合搜索算法的行驶工况特征参数选择方法,将适用于全局搜索的粒子群算法(particle swarm optimization,PSO)与局部搜索能力较强的禁忌搜索算法(taboo search,TS)相结合,选择出行驶工况特征参数最优子集,使工况识别模型的识别准确率得到很大程度的提高。
1 数据预处理
电动汽车城市道路行驶数据来源于“工业和信息化部—中国汽车工况信息化系统”。按照电动汽车在城市道路行驶情况对以下5种不良数据进行处理:
1) 由于GPS信号丢失导致采集数据的时间不连续,用以秒为单位计时方式描述时间变量,各个数据对应第1 s,第2 s,…,第ns,使原始数据在时间上连续。
2) 据《城市道路行驶规范》,在城市道路行驶的车辆不得超过100 km/h,因此超速的数据用前1 s的数据替换。
3) 对于汽车加、减速度异常的数据进行速度插值处理。
4) 将长时间停车、堵车及以小于10 km/h的车速断续行驶情况按怠速情况处理。
5) 将怠速行驶超过180 s的数据按180 s处理[23]。
同时,使用平均滤波法[23]去除原始数据的噪声,并去除停车时产生的毛刺。将处理完成的数据进行运动学片段划分,并使用主成分分析和聚类分析[24-25]将2 923个运动学片段分为4个聚类,分别代表电动汽车的4种城市道路行驶工况,如图1所示。
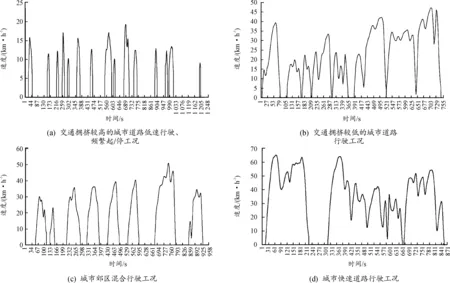
图1 定义的4类电动汽车城市道路行驶工况
2 行驶工况特征参数选择分析
2.1 行驶工况特征参数全集分析
特征参数全集需具有全面性以保证从中选择出的最优子集所含的特征参数能很好地代表汽车行驶情况,保证工况识别模型的准确性。采用22个特征参数作为行驶工况特征参数全集,分为3个部分[26]:标准参数部分、波动参数部分和分段参数部分。

3) 分段参数部分是对工况曲线变化规律的定性分析:速度小于v1(大于v1小于v2、大于v2小于v3、大于v3)的时间占总时间的百分比ηv1(ηv1-v2、ηv2-v3、ηv3)、减速度小于r2(小于r1大于r2、大于r1)的时间占减速时间的百分比ηr2(ηr1-r2、ηr1)、加速度小于a1(大于a1小于a2、大于a2)的时间占加速时间的百分比ηa1(ηa1-a2、ηa2)。其中v1、v2、v3为有关车速的参数边界,单位是km/h;r1、r2为有关减速度的参数边界,单位是m/s2;a1、a2为有关加速度的参数边界,单位是m/s2。
通过分析行驶工况特征参数全集可知,分段参数部分的参数边界不确定。为了得到最优的特征参数全集,在进行行驶工况特征参数选择时,需要先对分段参数部分的参数边界进行优化。但是如果直接使用特征参数全集作为行驶工况识别模型的输入则存在维数灾难问题,增加训练分类器的时间开销[27]。
2.2 测试数据集和训练数据集的建立
作为评价特征参数子集优劣的基础,测试数据集直接影响识别模型的性能[27]。在建立工况识别所需的测试数据集时,先确定行驶工况的分类类别,按照数据预处理的情况可知,分类类别为4类:电动汽车在交通拥挤度较高的城市道路低速行驶、频繁起/停工况,在交通拥挤度较低的城市道路行驶工况,在城市郊区混合行驶工况以及在城市快速道路行驶工况。
汽车在行驶过程中车速实时变化,为了保证汽车行驶工况识别模型的实时性,将各类城市行驶工况数据按照时间长度180 s等间隔分为2 500个速度小片段,共10 000个速度小片段。分别从各类工况数据中随机抽取20%的样本作为训练分类器的训练数据集,余下的80%的样本作为测试数据集。
2.3 特征参数选择过程分析
由分析可知,分段参数部分的参数边界v1、v2、v3、r1、r2、a1、a2不确定,需要先对边界进行优化,现有的特征参数选择方法并不适用于对未知特征参数全集进行特征选择。而确定了边界得到确定的特征参数全集后,采用现有的特征参数选择算法对拥有22个特征参数的中小规模的全集求解。
行驶工况特征参数选择的步骤如下:
1) 确定分段参数部分的参数边界v1、v2、v3、r1、r2、a1、a2,由此计算特征参数全集。
2) 任意一组参数边界对应一个特征参数全集,设Sw是特征参数全集上的一个特征参数子集。
3) 训练一个行驶工况分类器,并测试其工况识别准确度。识别准确度的计算公式为:
(1)
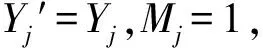
4) 一般情况下,当Racc最大时,选取特征参数个数最少的Sw,作为当前行驶工况特征参数的最优子集。
3 行驶工况特征参数智能混合搜索算法
3.1 算法总体设计
行驶工况特征参数选择,一是对边界的搜索,二是对子集的搜索。针对这2种搜索对象,选取全局搜索算法和局部搜索算法构成混合搜索算法进行最优子集的选择。在模式识别问题中,Wrapper方法虽然计算量大,但是考虑到整个特征子集对分类效果的影响,所得到的特征参数子集,其分类器准确度通常要优于Filter方法[28-29]。因此选用能使分类器准确度更高的Wrapper方法进行行驶工况特征选择,使工况分类效果更好。
搜索机制是Wrapper方法的核心[30]。寻找最优的行驶工况特征参数边界,生成特征参数全集,是特征参数选择问题的全局搜索,选择智能搜索算法比较合理。粒子群算法作为演化算法的代表,在特征选择中有利于优化搜索机制,常被用来寻优特征子集[31]。因此,选择操作简单却搜索效率高的粒子群算法作为全局搜索算法。对全局搜索得到的行驶工况特征参数全集进行最优子集搜索,是特征选择问题的局部搜索。对于中小规模的数据集进行搜索时,智能搜索算法易陷入局部最优。因此选用具有较强“爬山”能力的禁忌搜索算法作为局部搜索算法,搜索时可以克服演化算法容易陷入早熟的缺陷,跳出局部最优解,与演化算法结合可增加获得更好的全局最优解的概率[31]。
随机森林是一种灵活度高的新兴机器学习算法,相比于其他分类器,它在准确率方面有很大优势。随机森林由决策树组成,就分类问题而言,每棵决策树都是一个分类器。随机森林的建立分为以下3个步骤:① 用bootstrap方法抽取训练样本构成训练数据集,每个样本均构建一棵决策树;② 构成决策树的样本如树干一样进行“分叉”,当各分支属于同一类时终止“分叉”;③ 各决策树组成随机森林,每棵决策树对输入样本进行分类并投票,随机森林进行汇总并将投票次数最多的类别作为最终输出[32]。
采用粒子群-禁忌(particle swarm optimization-taboo search,PSO-TS)的智能混合搜索算法总体流程是计算标准参数和波动参数后,用粒子群算法搜索和优化分段参数部分的参数边界后得到确定的分段参数,由此计算出特征参数全集,用禁忌搜索算法搜索全集可产生使分类器识别准确度达到最高且含有较少参数个数的特征参数最优子集。
3.2 特征参数边界优化
基于粒子群算法的特征参数边界优化模型由优化参数、约束条件和目标函数构成。
1) 优化参数:v1、v2、v3、r1、r2、a1、a2。
2) 约束条件:对于优化参数v1、v2、v3、r1、r2、a1、a2的约束区间确定如下:
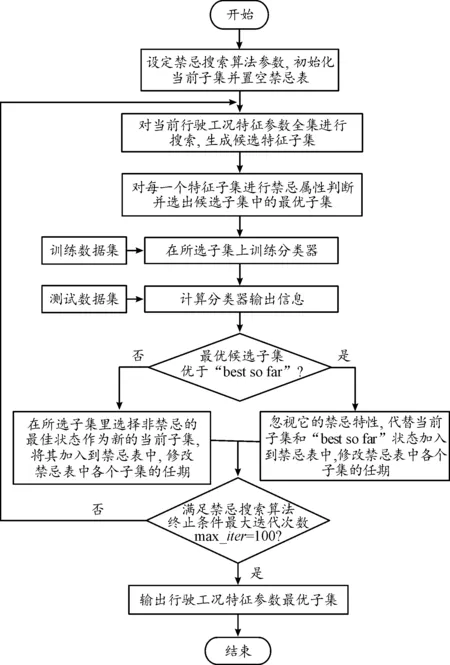
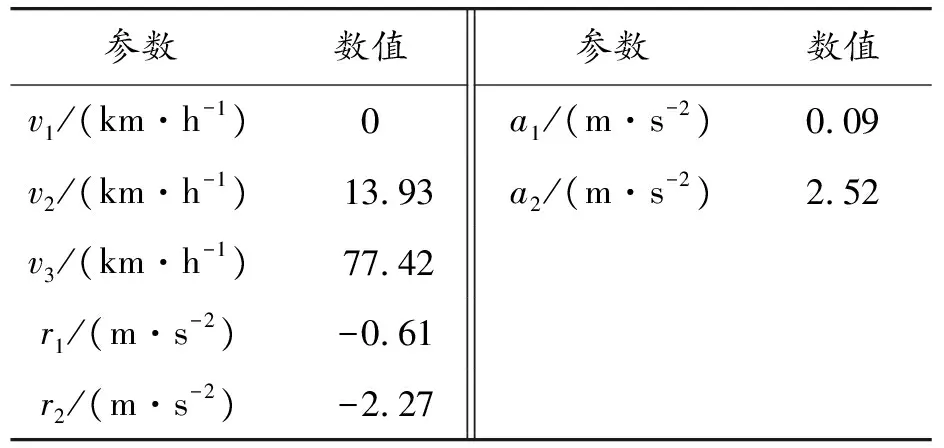
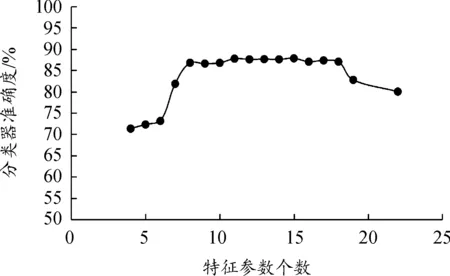
0≤v1 0≤|r1|<|r2|≤|rmax| 0≤a1 (2) 式中:vmax为最大速度,rmax为最大减速度,amax为最大加速度。 3)目标函数:对于工况识别模型来说,分类器的识别准确度最为重要,因此粒子群算法的目标函数为: f1=Racc1 (3) 式中:f1为粒子群算法的目标函数值;Racc1为全局搜索中分类器的识别准确度。 粒子群算法中,代表优化问题可行解的粒子由目标函数确定其适应度,并根据自身搜索到的最优解pid和整个粒子群的粒子历代搜索中的最优解pgd来更新速度和位置以保证尽可能地朝最优解所在区域“飞去”[33]。粒子根据下述公式更新速度和位置[31]: (4) zid(t+1)=zid(t)+vid(t+1) (5) 式中:vid(t+1)表示第i个粒子在t+1次迭代中第d维上的速度;zid(t+1)表示第i个粒子在t+1次迭代中第d维上的位置;ω为惯性权重,取ω=0.8;c1、c2为加速常数,c1=c2=0.5;rand( )为0~1之间的随机数。此外,为使粒子速度不致过大,设置速度上限vidmax,当vid(t+1)>vidmax时,vid(t+1)=vidmax;当vid(t+1)<-vidmax时,vid(t+1)=-vidmax。 在每一次迭代中,首先在满足约束条件的情况下有不同数值组合的v1、v2、v3、r1、r2、a1、a2,每一组v1、v2、v3、r1、r2、a1、a2都能相对应地计算出一组行驶工况特征参数全集,利用计算得到的特征参数全集训练分类器,记录分类器的识别准确度,从中选择出分类器识别准确度最高的那一组v1、v2、v3、r1、r2、a1、a2,此时该组的分类器识别准确度为本次全局极值,与历史全局极值进行比较后保留更优的结果,最后每组的v1、v2、v3、r1、r2、a1、a2取值根据自身最高的分类器识别准确度和全局最高的分类器识别准确度调整数值后进入下一次迭代。直到迭代次数epoch=30时,满足粒子群算法终止条件,输出最优的v1、v2、v3、r1、r2、a1、a2,并计算行驶工况特征参数全集。其中,最大迭代次数是根据实验确定的。取最大迭代次数为10、20、30、40、50到100进行实验,发现迭代次数较少时,虽然算法耗时短,但分类器分类效果不理想;当迭代次数增加到30时,分类器准确度达到87%;当迭代次数继续增加时,分类器准确度变化不大,始终保持在87.15%以下,甚至出现了低于87%的情况,而算法运行时间却大幅增加。因此在综合考虑求解过程中所耗时间和分类器准确度后选择30作为PSO的最大迭代次数。 特征参数PSO全局搜索流程如图2所示。 图2 特征参数PSO全局搜索流程框图 在特征参数全集中搜索到具有较少特征参数个数的最优子集,以提高计算效率并保证分类器识别准确度达到最高。这里采用禁忌搜索算法进行搜索。该算法中使用禁忌表记录搜索情况,在后续搜索中尽量避开已搜索的对象,避免迂回搜索和陷入局部最优解[34]。采用禁忌搜索算法进行特征参数选择的步骤为: 1) 设置参数,输入初始特征合集,即输入行驶工况特征参数全集,并置空禁忌表。设置参数如下:最大迭代次数max_iter=100,禁忌表长度taboo_size=50。其中最大迭代次数同样是综合考虑算法运行所耗时间和分类器准确度后选择的。固定最大迭代次数后,经多次实验可知:在禁忌表长度为50时,达到最优解的迭代步数较少,算法的收敛性较好,故选择50作为禁忌表长度。评价函数采用加权法建立: f2=WARacc2+WFNSW (6) 式中:f2为禁忌搜索算法的评价值;WA为分类器识别准确度的权重;Racc2为局部搜索中分类器的识别准确度;WF为特征参数子集中特征参数个数的权重;NSW为特征参数子集中特征参数个数。由于Racc2和NSW为不同数量级,它们的权重值要相适应,一般来说,WA应高于WF,因此取WA=0.995,WF=0.005。 2) 从邻域中选择若干个评价值最佳的特征子集产生候选子集并判断候选子集中的最优子集是否优于全局最好解,若是,则选择该最优子集;若不是,则选择候选子集中未被禁忌的最优子集。 3) 更新当前子集和禁忌表。 4) 判断是否达到最大迭代次数max_iter=100,若满足,则输出最优子集。 特征参数最优子集TS搜索流程如图3所示。 分类标签Yj=0、1、2、3分别代表图1所界定的4种电动汽车城市道路行驶工况。训练数据集选取了2 015个速度小片段,测试数据集中数据个数k,即速度小片段数量取值为8 061,其中正确分类的数据个数为7 073。采用式(1)可以计算得到分类器识别准确度为87.74%。优化后的特征参数边界如表1所示。 图3 特征参数最优子集TS搜索流程框图 参数数值参数数值v1/(km·h-1)0a1/(m·s-2)0.09v2/(km·h-1)13.93a2/(m·s-2)2.52v3/(km·h-1)77.42r1/(m·s-2)-0.61r2/(m·s-2)-2.27 4.2 最优子集中特征参数个数对分类器准确度的影响 图4为随机森林分类器的识别准确度与最优子集中特征参数个数的关系曲线。由图可见,最优子集的特征参数个数过少时,分类器因为缺少足够的行驶特征导致识别准确度较低;随着参数个数的增加,分类器识别准确度不断增加,当参数个数增加至11~15时,分类器的识别准确度保持在最高水平附近;此后参数个数继续增加,分类器识别准确度开始下降。显然,过少的特征参数不能很好地表征汽车行驶特征,恰当数量的特征参数则能保持分类器识别准确度处于较高水准,而当特征参数过多时容易造成维数灾难,一些不能很好地表征行驶特征的特征参数会干扰分类器的识别能力,不仅会造成分类器识别准确度下降,而且浪费计算时间。 图4 随机森林分类器的识别准确度与最优子集中特征参数个数的关系 遗传算法作为一种经典的智能算法,与粒子群算法同样被归类为仿生算法、全局优化算法和随机搜索算法。将遗传算法用于边界优化的混合搜索算法遗传-禁忌搜索算法(genetic algorithm-taboo search,GA-TS)与PSO-TS进行对比,计算结果如表2所示。 表2 采用不同全局优化算法的混合搜索算法的计算结果 从表2中可以得到,对于2种混合搜索算法选择出的行驶工况特征参数,标准参数部分两者的选择完全一致,由此可见,标准参数能很好地表征汽车行驶状态,对行驶工况分类起到很大作用。采用PSO-TS选择出最优子集的特征参数个数较GA-TS少,且在计算时间和分类器识别准确度上都有优势,主要原因是:遗传算法采用染色体一对一交叉的方法保留最优个体,而粒子群算法中的所有粒子都在能够记录自身和种群的最优值并朝最优个体移动,因此粒子群算法在信息共享方面具有全局性,较遗传算法的小范围信息共享有更高效率,个体也会以更快速度收敛于最优值。粒子群算法无需进行交叉和变异,只是通过粒子更新位置和速度找到最优解,在参数选择、计算效率等方面粒子群算法较遗传算法更有优势。 1) 对电动汽车城市道路行驶过程中采集到的速度数据进行处理和运动学片段划分,并使用主成分分析和k-means聚类分析得到4种行驶工况作为搜索算法中分类器的训练数据集和测试数据集。 2) 混合搜索算法通过粒子群算法搜索优化分段参数部分的参数边界,根据得到的边界计算特征参数全集,使用禁忌搜索算法对特征参数全集进行搜索,选择最能代表电动汽车城市道路行驶特征的特征参数组成最优子集,用于训练工况识别模型可以提高识别模型的效率和准确度。 3) 对选择的最优子集进行分析,得到随机森林分类器识别准确度与最优子集中参数个数之间的关系。另外,通过计算说明了粒子群算法作为混合搜索算法中的全局优化算法,相较于遗传算法可以选择个数更少的特征参数形成最优子集,并可提高搜索效率和分类器识别准确度。 今后的工作将针对PSO-TS混合搜索算法选取合适的算法参数进一步研究,并对算法进行改进以提高分类器的识别准确度。
3.3 特征参数最优子集搜索
4 计算结果及分析
4.1 特征参数最优子集
4.3 不同全局优化算法的计算结果及分析

5 结论
