基于改进胶囊网络的音调篡改检测算法*
2022-09-24杜海云王宏霞
杜海云,王宏霞
(四川大学,四川 成都 610207)
0 引言
多媒体技术的迅速发展让音频编辑变得方便,也让编辑后的音频更加逼真,但也存在潜在的威胁,如人耳可能很难分辨经过音频编辑软件修改的语音。此外,此类软件很容易获取,如果犯罪分子加以利用进行诈骗,或是案件审理过程中将伪造的语音作为证据呈递,会导致音频文件的安全性和真实性受到质疑[1-6]。常见的音频伪造方式有音色转换、语音合成和语音变调,其中,音色转换可以模仿目标者的说话音色,迷惑听者或说话人识别系统;音调修改能隐藏当前说话人的身份信息,比如在采访节目中通常会对被采访对象的语音进行变调处理来保护人身安全。在音频编辑软件工具和算法盛行之前,通常借助非电子方式变调,比如捏鼻,但要求说话人具备一定技巧。而音频编辑软件的出现降低了篡改语音的难度,因此篡改语音无需太多知识和技巧。然而,对音调进行篡改也有负面性,可能对说话人验证系统(Automatic Speaker Verification,ASV)产生威胁。为了保证音频文件的安全性不受质疑,需要检测算法能够识别音调篡改。此外,在真实场景下可能会存在各种噪声和压缩情况,而且噪声种类和强度各异,压缩编码格式和强度也各不相同。压缩和噪声的存在会让听感不自然,而且还会对算法的性能和ASV 系统的性能产生影响,所以设计的篡改语音检测算法需要能够抗衡噪声、压缩等真实场景下可能存在的这些干扰因素,即要求算法具有一定的鲁棒性。
音频篡改检测也被称为音频取证,分为主动取证和被动取证两种,主动取证会通过数字签名、水印等方式检测篡改[7],而被动取证无须预先嵌入信息来检测真伪,更加符合实际场景对算法的需求。
语音篡改检测领域发展至今已有一些成果。2013 年,Wu 等人[8]通过梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)特 征,对电子伪造语音进行检测。随后有研究将MFCC 的统计特性作为特征进行检测,性能有所改进[9]。2017年,Cao 等人[10]利用线性频率倒谱系数(Linear Frequency Cepstral Coefficients,LFCC)作 为 特 征检测音调篡改,但是在信噪比(Signal to Noise,SNR)较低的情况下,算法性能有所下降。2019 年,Wang 等人[11]在短时傅里叶变换(Short Time Fourier Transform,STFT)频谱图的基础上,结合改进的DenseNet 网络设计检测算法,在纯净语音数据上取得了较好的检测结果。同年,Dou 等人[12]提出了基于多分辨率的类耳蜗系数特征(Least Mean Square-Multi Resolution Cochleagram,LMS-MRCG)的算法,对含噪声的、音调篡改的语音进行检测,但同样在低SNR 环境下性能变差。2020 年,Ye 等人[13]研究了基于LFCC 特征和卷积神经网络(Convolution Neural Network,CNN)的方法,对音调篡改进行检测,算法表现较好,但实验中设计了过低的变调因子篡改的语音,而变调因子过低很可能无法隐藏说话人身份,说话人身份信息保留较为明显[3]。从以往的研究当中可以看出,该领域针对鲁棒性的研究较少,而且这些研究提出的算法在有噪声影响下,性能下降较为明显。
针对当前音调检测算法普遍鲁棒性较弱的问题,提出了一种基于改进胶囊网络的音调篡改检测算法。同时为增强算法的鲁棒性,将相对频谱感知线性预测(RelAtive SpecTrAl-Perceptual Linear Predictive,RASTA-PLP)特征和MFCC 特征进行融合,同时将提取特征、一阶差分系数和二阶差分系数映射至3 个通道构成整体特征,然后输入到改进的胶囊网络当中。该算法在检测不含噪声、含已知噪声、含未知噪声以及经过压缩的音调篡改语音实验中表现均较好。
1 基于改进胶囊网络的音调篡改检测算法
1.1 特征提取
目前语音变调的方式多为时域法,包括重采样和时域尺度变换两步,可改变信号频域信息。因此检测音调篡改的语音时,所使用的特征应当在识别不同变调因子篡改的语音时具有区分度。
变调语音检测中常见的特征有MFCC、线性预测编码系数(Linear Prediction Coding Coefficients,LPCC)、LFCC 等。在声学的其他相关领域中,感知线性预测系数(Perceptual Linear Predictive,PLP)和RASTA-PLP 特征也较为常见,面对鲁棒性问题,这两种特征通常用于加强算法的鲁棒性,这点在语音识别任务中有所验证[14]。RASTA-PLP是基于PLP 特征所设计的特征。PLP 特征经过人类听觉模型处理机制处理,输入信号选择经过听觉模型机制处理后所得到的信号,代替线性预测系数分析过程所使用的时域信号,更有利于鲁棒性强的语音特征提取。PLP 基于听觉模型的处理步骤包括临界频带分析、等响度预加重和强度—响度变换。RASTA-PLP 特征在PLP 特征基础上加入RASTA 滤波技术,改善了短时语音频谱易受到通道噪声影响的问题。RASTA 滤波通过利用低端限制频率很低的带通滤波器对语音进行处理,信号当中稳定的频率成分会被抑制,意味着对通道噪声也能进行一定程度的抑制[15]。RASTA-PLP 的特征提取过程如图1 所示,和PLP 特征提取过程类似,RASTA 滤波处理过后的信号共振峰结构保持良好。
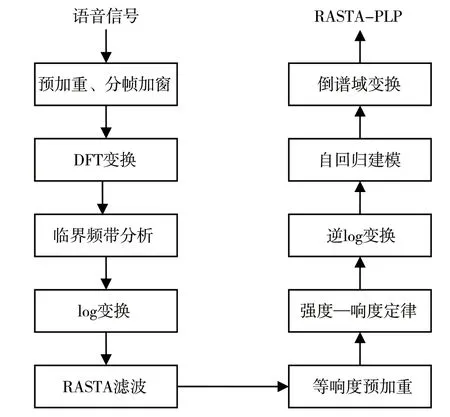
图1 RASTA-PLP 特征提取过程
如果经过变调处理,RASTA-PLP 的特征值也会发生改变。在TIMIT 划分的测试集中提取的第1维度的RASTA-PLP 特征值如图2 所示,图中横坐标分别表示+8 变调、原始语音和-8 变调的语音,纵坐标表示每种类型语音在所有分量上的平均值。可以看到第1 维度的特征值对于升调和降调都较为敏感,同时其他维度的特征也在升调或者降调时遵从类似的规律。RASTA-PLP 特征在区分不同变调语音时是可区分的,因此可以视为检测变调语音的特征。由于RASTA-PLP 特征也具有良好的抗噪性,所以通过融合RASTA 和PLP 特征来增强检测算法的鲁棒性。
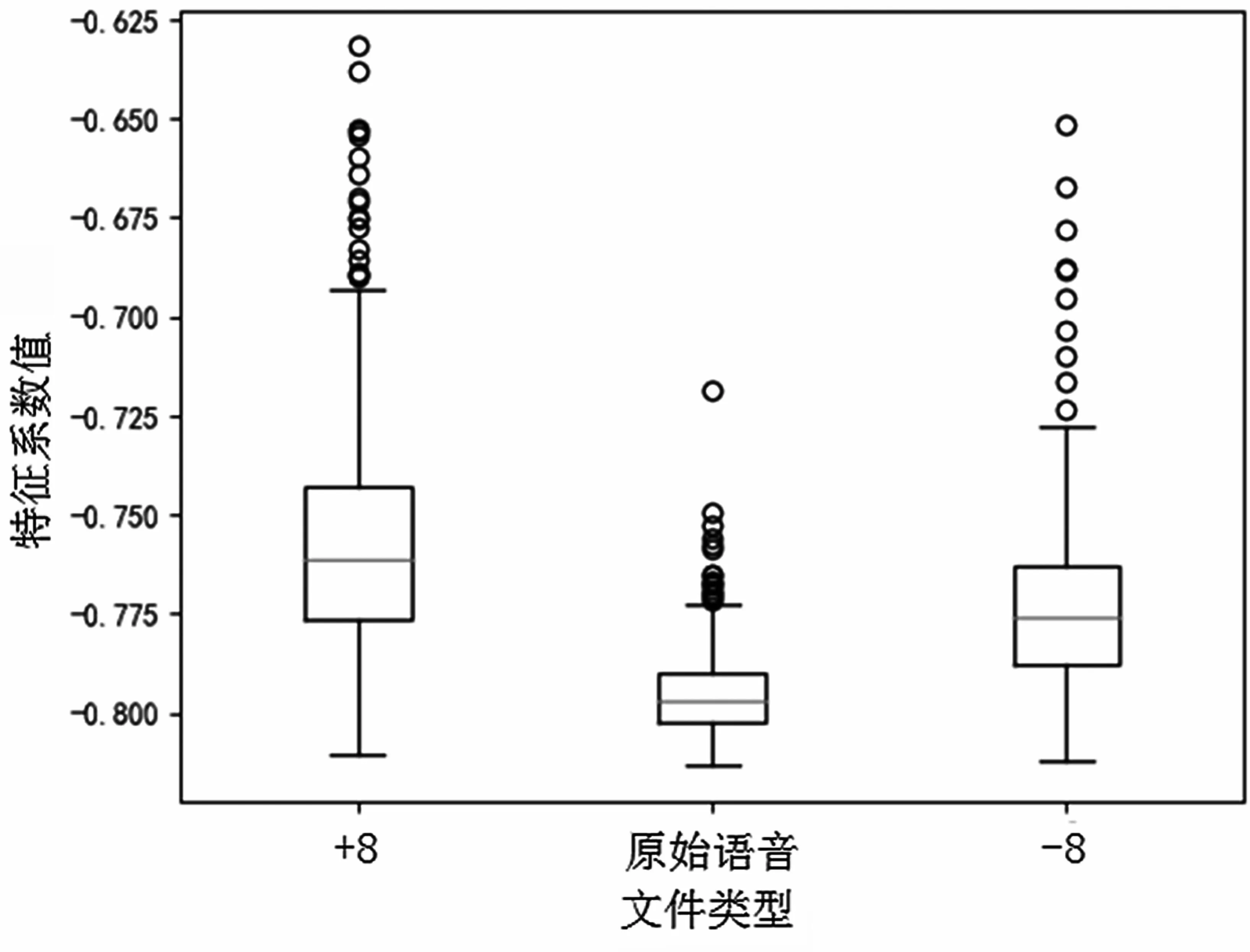
图2 在TIMIT 测试集中RASTA-PLP 特征第1 维度的分量
MFCC 特征在变调语音篡改检测任务中表现良好,其特征提取过程如图3 所示。MFCC 特征提取过程中,输入信号经预处理后需要经过快速傅里叶变换(Fast Fourier Transform,FFT)、Mel 滤波器、对数(log)运算和离散余弦变换(Discrete Cosine Transform,DCT),最终选取特征值得到MFCC 特征。
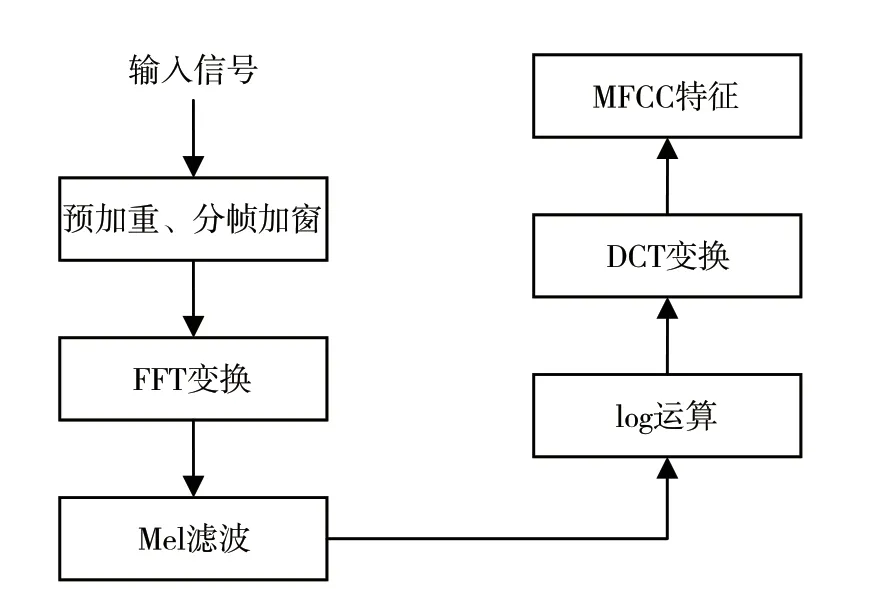
图3 MFCC 特征提取过程
以特征MFCC 提取过程为例[9],信号经预处理后,需要先经过FFT 变换,FFT 变换会计算每帧的频谱信息,再经过Mel 滤波器处理。该步骤的计算过程为:
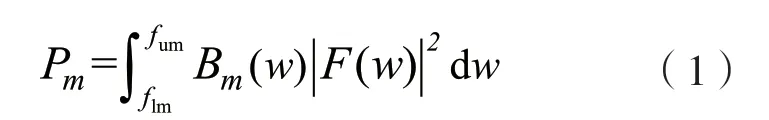
式中:w为信号帧的索引;F(w)为信号的频谱信息;B(w)为Mel 滤波器;下标m指经过的第m个Mel滤波器,1 ≤m≤M,M为Mel 滤波器的数量;fum为滤波器截止频率的上限;flm为截止下限频率;Pm为经过Mel 滤波器得到的功率。
对音频进行变调,会改变信号的频域信息,从而对FFT 和Mel 滤波器对信号的处理产生影响,频谱信息和功率都会发生改变,进而影响最终的MFCC 特征值,该特征值针对不同的音调改变也是具有区分度的,因此认为MFCC 可以用来检测音调篡改的特征。同时引入MFCC 特征的相关系数矩阵。假设MFCC 特征维度为L,对第j维度和第j´维度的分量计算相关系数,其中1 ≤j≤j´≤L,则相关系数矩阵特征的计算公式为:
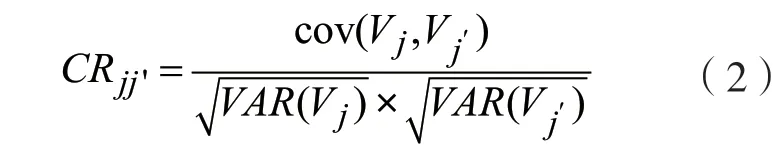
式中:Vj为第j维度的所有分量;cov 为协方差运算;VAR为方差运算;CRjj´为第j维度和第j´维度分量的相关系数。算法中使用的特征融合了RASTAPLP 特征、MFCC 特征及其相关系数矩阵,该融合特征可以表示为:
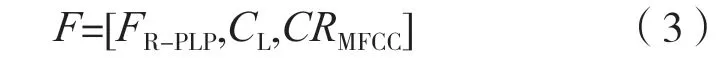
式中:FR-PLP为RASTA-PLP 特征系数;CL为MFCC特征;CRMFCC为MFCC 特征相关系数。拼接融合这些特征为F,构成了检测算法的输入特征信息。
同时,在特征提取时还计算了特征的一阶差分系数和二阶差分系数,但是并未将特征和差分系数值进行串联拼接,而是映射至特征图像的RGB 三通道中,作为网络的输入信息。
1.2 网络结构
本文使用的网络结构为改进的胶囊网络(Capsule Net)结构,胶囊网络结构是在2017 年由Hinton 等人[16]提出的。早在2011 年,胶囊的概念就有了雏形,之后对此概念进行了拓展和优化形成了胶囊网络,发展至今也出现了胶囊网络的各种变体。
CNN 网络在各种任务当中都有运用,但是随着研究的深入,其短板也暴露在视野中。CNN 多借助池化、卷积等非线性操作由浅到深逐层提取特征,最终对局部特征进行整合,但因为卷积池化运算会导致部分特征信息丢失,而丢失的特征信息可能对目标任务有帮助,并且最终层获取的信息一般是输入信息的很小一部分。此外,CNN 网络虽对减少模型参数量、计算量有益,但同时性能可能会下降。CNN 无法对输入数据内部的相对位置信息进行学习,一般只能判断是否存在某种模式,而胶囊网络让网络对输入数据的学习更加充分。
在胶囊网络中,特征表征的基本单位是胶囊结构,并将特征信息以向量的方式进行表达,而CNN的输出是标量形式。胶囊网络本质是一组多维向量,胶囊输出的模长表示该胶囊学习的模式出现的概率大小,例如如果输出向量的模长接近1,那么代表出现可能性接近100%。
初始胶囊网络结构在单个胶囊结构、路由算法和激活函数的设计和CNN 网络存在差异。单个胶囊结构的计算过程可以简化为图4 的流程,首先和输入相乘,胶囊的输入v是上个胶囊的输出;其次将w和输入v相乘,得到u,对向量进行加权处理,即将各个权重c和u分别进行相乘,其中c为标量;再次对加权后的向量进行求和,记为s;最后将其输入激活函数,胶囊网络的激活函数为Squashing非线性函数,其定义为:
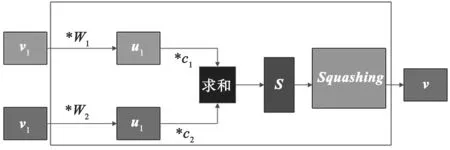
图4 胶囊结构计算过程
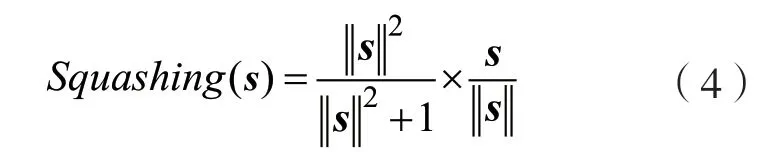
式中:等号右边第一个分式代表对s进行缩放,第二个分式可以视为s同等方向的单位向量。通过Squashing 函数能够很好地保留s的方向信息,并且将长度保证在0~1 之间,实现对向量的压缩和重分配,减少计算量。
在计算过程中,权重c是通过路由算法进行更新的,胶囊层内权重c的和为1。在2017 年提出的初始胶囊网络中,并非全部都为胶囊层,浅层结构中也存在卷积结构。浅层卷积结构提取输入信息中的低维特征,送入主胶囊层(PrimaryCaps)和数字胶囊层(DigitCaps),对深度特征进行提取。在主胶囊层中也存在卷积结构,主胶囊层的输出会送入数字胶囊层,数字胶囊层是全连接结构,输出代表分类结果,并且输出是向量形式,通过输出模长可判断输入信息是否存在某种模式,是否属于某个类别。
初始胶囊网络结构的浅层卷积所提取的特征可能无法很好地表示前端提取的特征,而且面对复杂输入和分类情况,算法性能可能欠佳。因此通过改进胶囊网络的卷积层结构来优化算法,加深输入胶囊层的特征信息,令胶囊网络更加适应输入信息和篡改检测任务,从而提升算法的性能,并且通过仿真实验证明,改进的算法具有一定的鲁棒性。
图5 展示了该算法的大致网络结构,输入的特征图像即融合特征F原是具有三通道的图像,但送入网络前进行处理,转化为灰度图像,转化过程为:L=G×587/1 000+R×299/1 000+B×114/1 000(5)式中:R,G,B分别代表RGB 3 个通道中的像素值。对3 个通道中的信息都进行保留,R通道代表静态特征信息,G和B通道代表动态特征信息。
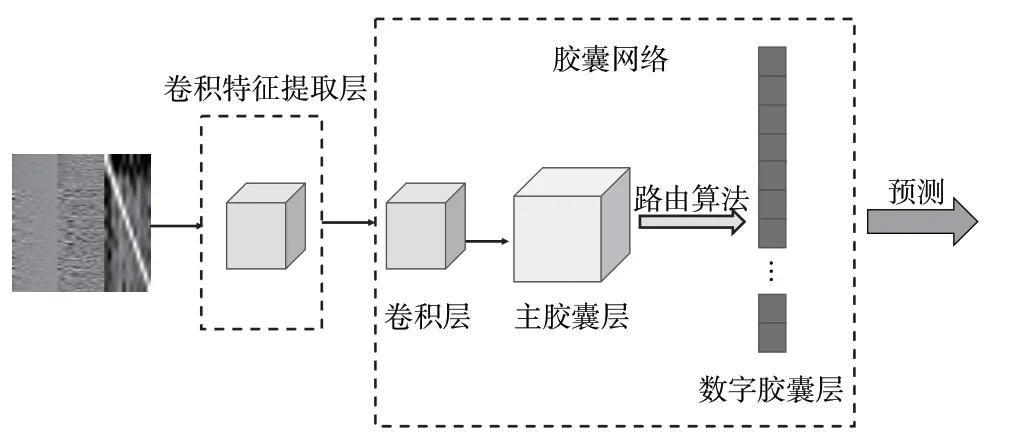
图5 改进的胶囊网络结构
因此,输入的训练数据实际大小为(224,224,1),之后对卷积层进行改进,将第一个卷积层卷积核大小设置为(9,9),输出设置为64 维,步距为4,填充为2,激活函数为ReLU,池化函数为自适应平均池化函数,该函数可以自动调整输出为程序中指定的维度。实验中将该池化层输出设置指定为(28,28,64),送入后续卷积层。详细网络结构参数设置见表1,表中介绍了网络层各层的输出和一些参数设置。

表1 改进的胶囊网络结构参数
2 实验设计与分析
2.1 数据集
实验数据来自TIMTI 数据集和TCHCHS30 数据集,对数据集内的纯净语音进行变调处理,变调工具使用Adobe Audition。实验中,TIMIT 数据集的训练集和测试集的数量比为9,即训练集5 670 句,测试集630 句;THCHS30 数据集是中文普通话数据集,训练集选择5 000 句,测试集500 句。变调因子范围为±4~±5,该范围的变调语音属于较弱的变调,如果变调因子小于此值,变调后的语音无法有效隐藏说话人身份信息,但同时过高的变调因子会令语音听感不自然而令人生疑。由于篡改检测算法在弱变调语音上一般性能会下降,因此为了寻求弱变调语音情况下篡改检测性能较好的解决方案,选择了±4~±5 的变调范围。
同时为了验证算法的鲁棒性,对语音进行加噪和压缩处理,噪声来自SPIB 数据集,选择其中说话人噪声、白噪声、车辆噪声、粉红噪声和通信信道噪声。为测试算法在未知噪声场景下的性能,车辆和通信信道噪声仅在测试集加入,其余噪声类型在训练集、测试集均加入,每个语音文件都加入一种噪声,强度不同,加噪后每个语音的SNR有20 dB、10 dB 和0 dB 3 种。压缩则是将文件压缩为比特率分别为64 kbit/s、128 kbit/s 和192 kbit/s 的MP3 文件,而原始语音文件的比特率是变化的,普遍为140 kbit/s 左右。在抗压缩性实验中考虑了比特率降低和虚高的情况,并且训练集和测试集均是由3 种比特率压缩后的语音混合而成,未将3 种压缩比特率单独实验。
2.2 性能分析
实验所使用的特征为第1 节中描述的融合特征F。将F的静态和动态特征分别映射至RGB 三通道,但是在网络的输入端对特征图像进行灰度处理,转化为单通道输入图像,以另一种方式保留特征信息。模型训练时优化器选择Adam,学习率初始设置为0.000 1,衰减设为0.98。实验将改进的胶囊网络模型与一些经典分类模型AlexNet、ResNet 和初始胶囊网络结构在设计的特征F上进行对比。在初始胶囊网络实验中,仅根据变调检测任务的分类数改变相关参数,即输出胶囊设为5,分别对应±4~±5和真实的语音文件分类。
算法性能评价指标为准确率。无噪声环境下变调语音篡改检测实验结果如表2 所示,表中的结果分别展示了其他模型和改进的胶囊网络在TIMIT 数据集和THCHS30 数据集上的性能,其中ResNet 模型为ResNet34。从表2 中的实验结果可以看出,在无噪声时所有模型在TIMIT 数据集和THCHS30 数据集上的表现都较好,改进后的胶囊网络表现比初始胶囊网络性能有所提升,改进的CapsNet 网络能够增强在无噪声环境下的检测算法性能,说明对特征卷积层进行加深在一定程度上能够加强性能。
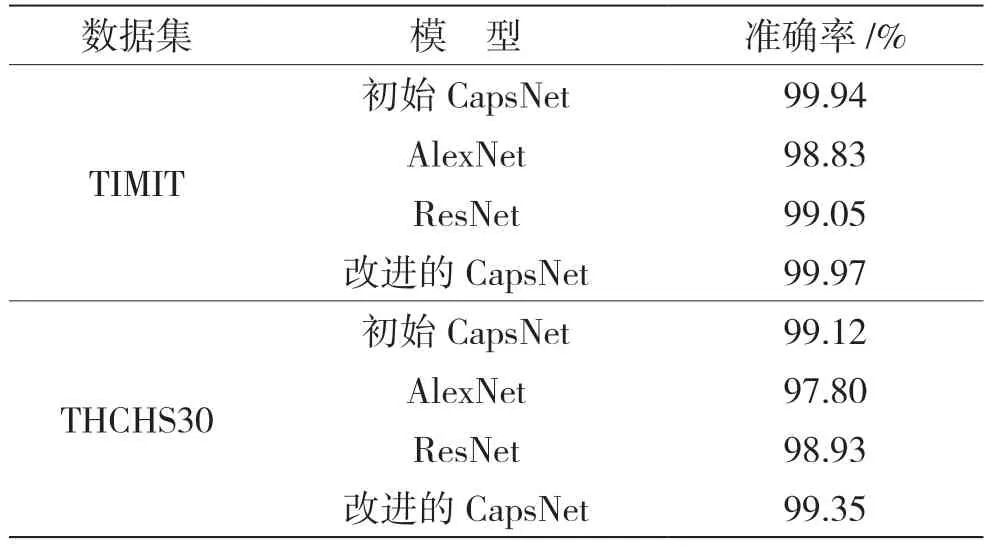
表2 无噪声环境下,不同模型的检测准确率
接下来对算法在噪声和压缩场景下的鲁棒性进行实验。在已知噪声场景、未知噪声场景和压缩场景下的语音检测准确率实验结果见表3,对比模型选择的是在无噪声场景下表现较好的初始CapsNet。
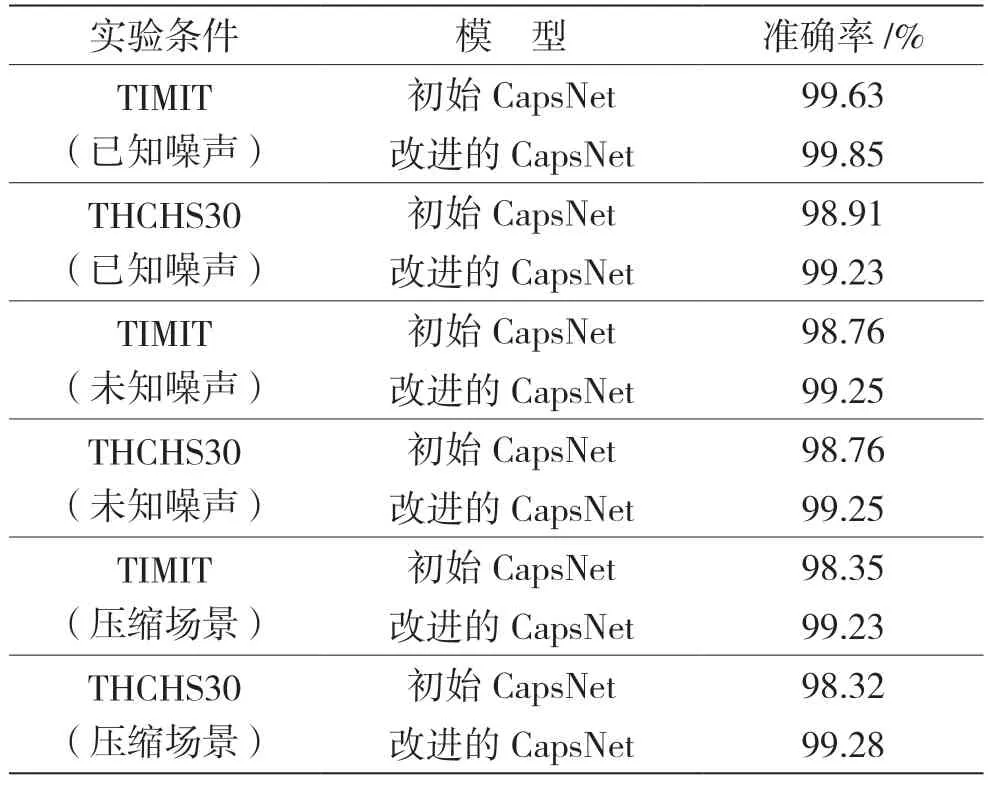
表3 在已知噪声、未知噪声和压缩情况下,不同模型检测准确率的比较
通过表3 结果可以得知,即使有噪声影响,胶囊网络的结构也可以对数据进行较好的训练,在已知噪声和未知噪声场景下算法性能受到的影响较小。虽然在未知噪声场景下算法性能较在已知噪声环境下有轻微幅度的下降,但算法保持着良好的抗噪性。在面对MP3 压缩时,初始胶囊网络表现略差于改进的胶囊网络,并且较无噪声无压缩环境下性能下降较多。通过该实验可以认为,利用特征F结合改进的胶囊网络结构可以实现良好的抗压缩性。因此,通过实验结果可知该算法具有良好的鲁棒性。
3 结语
语音编辑技术可能会引发安全问题,如果用于犯罪可能会对社会造成严重威胁。本文针对语音变调篡改检测展开研究,通过融合RASTA-PLP 特征和MFCC 相关特征,同时改进胶囊网络结构进行语音篡改检测。通过与其他算法进行对比实验可知,本文设计的算法在面对噪声和压缩这些常见的干扰因素时,能够保持良好的鲁棒性。
