基于依存距离惩罚的泰汉神经机器翻译方法*
2022-09-24张弘弢文永华
张弘弢,文永华,王 剑
(昆明理工大学,云南 昆明 650500)
0 引言
泰国作为“一带一路”倡议中重要的沿线国家,与我国的合作不断深化,人文交流愈发密切[1],翻译则是实现两国合作的桥梁。一直以来,人工翻译存在时间和经济成本过高的问题,而神经机器翻译的发展能使交流更加方便快捷。神经机器翻译效果很大程度上受平行语料质量的影响[2],泰汉属于典型的低资源语言对,缺少大规模、高质量的训练数据,因此泰汉神经机器翻译质量较差。
泰语和汉语在语法上存在较大差异:首先,泰语很少使用标点符号,句子之间一般通过空格符进行标记,模型很难利用标点等标记学习句子的结构信息,影响了模型对句子语义的理解;其次,在泰语语序中通常将修饰语置于被修饰语后面,例如泰语句子(标语上写着:“今晚,我们将用远光灯惩罚你。”)中,状语修饰短语(用远光灯)”位于被修饰语(惩罚)”的后面,与汉语的语序相反,这也是泰汉机器翻译质量不佳的重要原因。
结合泰语语法特征,利用句法知识提升泰汉机器翻译质量是重要的研究方向。但是泰语缺少成熟的句法分析工具,在依存句法分析领域可用的树库universal dependenies 中仅有1 000 句泰语标注测试集,人工标注训练集昂贵耗时且依赖语言学专家。泰语依存训练语料不足,导致解析模型不能得到充分的训练,很难获取泰语依存句法知识。
本文针对泰语和汉语之间高质量平行语料不足、泰语依存标注数据少、依存句法解析困难等问题,提出了融合无监督泰语依存句法信息的泰汉神经机器翻译方法。针对泰语依存句法解析质量不高的问题,提出了基于依存距离惩罚的泰汉神经机器翻译句法知识融合方法,该方法通过增加依存距离惩罚机制,有效缓解了句法解析噪声对翻译质量的影响,与transformer 相比,所提方法将泰汉机器翻译的双语评估替换(Bilingual Evaluation Understudy,BLEU)分数提高了0.46。
1 相关工作
泰语作为低资源语言,缺乏高质量的依存标注训练数据,而无监督依存句法分析方法可以从无标注数据中提取到依存标注结果。自配价依存句法模型(Dependency Model with Valence,DMV)[3]被提出之后,很长一段时间内,无监督依存句法分析的主要方法都是基于DMV 的,如Jiang 等人[4]提出的神经DMV 模型,Han 等人[5]提出的判别式神经DMV。自编码器模型是比较新的无监督方法,它借助编码器把句子映射到句法结构空间,然后利用解码器还原句子,如Cai 等人[6]提出了一种条件随机场自编码器方法,对输入句子的概率进行重构,避免了有向图的基本限制;Kim 等人[7]提出了无监督循环神经文法(Unsupervised Recurrent Neural Network Grammars,URNNG),可以缓解解码器的过拟合。与传统的纯无监督方法相比较,基于迁移学习的无监督方法更具有可行性,如Ahmad 等人[8]提出了在解码端使用基于图的依存句法分析方法,提高了依存句法分析的性能;陶广奉[9]利用大量未标注的汉泰平行句对,依靠汉泰之间的语言相似性,从现有的大规模汉语依存句法分析知识库中迁移构建了泰语的依存句法分析器。考虑到泰语缺少与其他语言间的高质量平行语料,本文无监督地在泰语和高资源语言之间进行词嵌入对齐,从而在不需要平行句对的情况下通过无监督迁移方法实现泰语依存句法分析。
现有的汉泰机器翻译的研究中使用的平行语料多为领域单一的未公开语料,平行语料的规模与质量受限,导致翻译任务的训练数据不充分,使编解码器的参数不能达到最优[10]。针对低资源语言的神经机器翻译方法中,融入依存句法结构知识是一类热门方法[11]。近年来,国内外众多学者对融合依存句法信息的翻译方法进行了研究,例如,Wang 等人[12]于2019 年使用依存句法树作为句子的句法结构表征,并提出两种策略来编码依存树中单词之间的位置关系;Choshen 等人[13]提出了一种基于Transformer 的通用方法,用于解决基于生成转换序列的树和图解码;2020 年,Bugliarello 等人[14]提出了父级自注意力机制(Parent-Scaled Self-Attention),将依存信息中子词到父词的依存距离信息融合到注意力机制中,该方法无需参数,简单高效,能有效提升翻译效果。但是,现有的句法信息融合方法大都依赖于成熟的句法解析器获取质量较高的依存信息,而泰语缺少成熟的句法解析工具,用无监督迁移方法获取的句法信息准确率还不能达到与标准解析结果相当的程度。为了降低泰语依存信息引入的噪声对翻译效果带来的不利影响,本文提出了依存距离惩罚机制,对现有的融合方法作出有针对性的改进,从而更有效地融入句法知识以提升翻译性能。
2 基于依存距离惩罚的泰汉神经机器翻译方法
本文将无监督依存句法解析获取的泰语依存句法信息通过改进的依存感知注意力机制融入基于Transformer 的泰汉神经机器翻译模型。该方法整体框架如图1 所示。

图1 融合无监督依存句法的泰汉神经机器翻译总框架
针对无监督获取的依存句法信息质量不高的问题,本文提出了依存距离惩罚方法。该方法根据依存距离对依存父词的位置信息赋予不同权重,并用依存感知注意力机制将父词依存位置信息融入Transformer 翻译模型。
2.1 无监督泰语依存句法知识获取
本文在泰汉神经机器翻译中融入的泰语依存句法结构知识,是采用一种无监督迁移的方法预先获取的。该方法不需要泰英平行语料,而是先借助高资源语言丰富的依存标注语料预训练解析模型,然后通过对齐矩阵将其迁移到泰语依存句法分析任务,最终实现从无标注的泰语数据中提取到依存结构知识。
本文所使用的无监督泰语依存句法分析方法分为4 个步骤。首先采用无监督方法通过对抗训练实现泰语和英语动态词嵌入的对齐;其次将基于深层Biaffine 注意力的神经网络依存解析模型[15]作为依存句法分析模型,利用英语丰富的依存句法树库预先学习依存句法分析模型,使模型参数得到更充分的训练;再次通过获取的词嵌入对齐矩阵将泰语和英语词向量映射到同一个空间,并跨语言共享所有模型参数,将预训练的依存句法分析模型迁移到泰语依存句法分析任务;最后使用该模型判断泰语无标注语料中每两个标记之间是否有依存关系,对于存在依存关系的再用分类器输出具体关系,最终完成无监督的泰语依存句法分析。
2.2 依存距离惩罚机制
本文融入的泰语依存句法知识是由无监督的方法学习到的,不能达到与标准依存树相当的准确率。为防止融合模型过度拟合到有噪声的依存信息,本文提出了依存距离惩罚机制,旨在减少依存信息中引入的噪声对翻译性能的影响,以提升句法信息融合的有效性。
依存感知注意力机制只需要通过计算每个位置标记的依存父词与所有标记间的距离函数,来获得距离关系矩阵。在获取的依存句法树中,依存距离越远的词之间,越可能累积形成错误的依存信息。而本文根据依存距离的远近对其赋予不同的权重,采取依存距离惩罚的方式使融合模型更偏袒直接父词依存信息,以此来减少噪声信息对翻译过程的影响。

图2 依存句法树剪枝示例
为了进一步求出距离关系,首先,对输入的长度为T的序列,判断位置t的父词pt与每个位置j的标记在依存句法树中的距离lpt,j,并计算位置t的父词与每个位置j的标记在序列中的距离|j-pt|,j=1,2,3,…,T;其次对每个距离|j-pt|计算距离关系dist(pt,j),以方差为σ2的正态分布的概率密度值来表示位置t的父词与每个位置j的标记在序列中的距离关系,其表达式为:

依存距离惩罚机制的原理如图3 所示,距离关系dist(pt,j)形成父词距离关系矩阵。根据每个位置t的父词与每个位置j的标记在依存句法树中的距离lpt,j的不同,选择要保留的距离关系信息dist(pt,j),分别得到不同的父词距离关系矩阵D1,D2和D3。
以泰语例句的第一个词“5 000”为例,它在距离关系矩阵D1中保留的距离关系信息如图2(a)所示,即保留完整的依存句法树;然后,将与“5 000”的父词(美元)”在依存句法树中相距大于2 的节点进行剪枝,剪枝后的依存句法树如图2(b)所示,树中剩下的节点为在距离关系矩阵D2中要与位置1 的父词保留距离关系信息的标记;再将与“5 000”的父词(美元)”在依存句法树中相距大于1 的节点进行剪枝,剪枝后的依存句法树如图2(c)所示,树中剩下的节点为在距离关系矩阵D3中要与位置1 的父词保留距离关系信息的标记。
本文对句子中的每个标记都根据依存句法树中的距离进行逐一剪枝,以此逐步生成3 个距离关系矩阵。在计算生成的距离关系矩阵D1中,包含每个位置t的父词与每个位置j的标记在序列中的距离关系dist(pt,j);而D2只保留每个位置t的父词和与其在依存树中的距离lpt,j不超过2 的位置j的标记在序列中的距离关系,矩阵D2中每个元素的计算公式为;

D3则只保留位置t的父词和与其具有直接依存关系的标记在序列中的距离关系,矩阵D3中每个元素的计算公式为:

上文中的例句生成的矩阵如图3 所示。可以看出,根据在依存句法树中的距离lpt,j的不同,依存距离关系矩阵所保留的距离关系元素越少,所包含的信息越侧重于在依存树中距离更近的关系特征。

图3 依存距离惩罚机制
为了降低输入的依存信息中的噪声对翻译效果产生的干扰,本文对获得的3 个父词距离关系矩阵D1,D2和D3进行加权求和,使模型对每个词更加偏袒其直接依存父词的依存特征,并得到依存距离惩罚后的父词距离关系矩阵D,具体公式为:

式中:λi为对不同的矩阵Di所赋予的不同权重。相应地,对D1和D2减小权重,对D3增大权重,以减少在依存句法树中距离较远的词间的距离信息对翻译过程的影响,通过这种方式来降低对不准确信息的融合所带来的噪声干扰。
2.3 基于依存注意力机制的句法信息融合方法
本文主要采用了基于依存感知注意力机制的Transformer 架构,将其作为句法信息融合模型,以获得一个能够高效训练的神经网络翻译模型。该方法在传统Transformer 架构上以依存感知注意力替代原本的自注意力,将与每个词具有依存关系的父词的绝对位置融入attention,借助父词信息提高翻译质量。依存感知注意力机制如图1 中的依存感知注意力机制部分所示,编码器由两部分输入:一个是包含T个标记的泰语句子的嵌入矩阵E∈RT×dmodel,另一个是句子中每个子词对应的父词的绝对位置组成的向量p。生成向量p需要用到通过依存句法分析过程获得的依存父词信息。
在多头注意力机制的每个头H中,对输入序列的每个标记算得3 个向量q,k,v,得到整个输入序列的矩阵Q∈RT×c,K∈RT×c,V∈RT×c,其中,c=dmodel/H。如式(5)所示,通过计算每个q和所有的k之间的点积,得到每个位置的标记与输入的其他部分的关注度分数,并将分数除以以避免点积较大时出现的梯度消失问题,得到分数矩阵S。
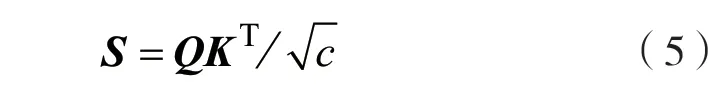
利用输入向量p分别计算得到3 个父词距离关系矩阵D1,D2和D3。为了减少输入的依存信息中的噪声对翻译效果产生的干扰,本文对3 个父词距离矩阵进行依存距离惩罚,获得最终的父词距离关系矩阵D。在2.2 节中对该过程进行具体描述。
如式(6)所示,由分数矩阵S和父词距离关系矩阵D得到融合矩阵N。N的第t行是根据每个标记与第t个标记的父词位置的距离关系,对第t个标记的关注度分数进行加权计算得到的。

最后,利用softmax 函数来产生句子中所有标记的权重分布,并用所得矩阵和矩阵V获得最终矩阵M,实现了将依存信息融合到Transformer 模型中。该翻译模型的其他部分与传统的Transformer 模型相同,训练的目标是最小化模型预测的概率分布与监督信号之间的交叉熵损失函数L(θ),其表达式为:

式中:y和y´分别为目标语言实际标记和模型预测的标记;X为输入序列;θ为模型训练的参数。
该方法中的距离函数仅依赖依存父词位置信息,有效地将泰语依存句法知识加入泰汉神经机器翻译的过程,这样既能减少由依存结构知识引入的过多噪声对翻译效果造成的干扰,又不需要额外的参数来训练依存感知注意力层,简单高效。
3 实验与分析
3.1 实验数据
在进行实验前,首先爬取汉泰平行句,并删去不符合要求的语料,获得106 万对汉泰平行句对。英语句子中存在空格作为天然的分词,而汉语和泰语都没有明显的词语间隔,本文分别使用jieba 分词工具和PyThaiNLP 分词器对汉语和泰语的语料进行分词。
对于泰汉神经机器翻译实验,本文将预处理后的平行语料拆分为训练集、验证集和测试集,并分别选取不同数量的平行句对构建了3 个语料库,如表1 所示。汉泰平行语料库1、汉泰平行语料库2、汉泰平行语料库3 分别由106 万对、52 万对、13万对预处理后的汉泰平行句对构成。

表1 泰汉翻译实验数据
3.2 实验设置与评价指标
在实验设置方面,所有实验均利用pytorch实现,采用基于Transformer 的改进模型,并将Transformer作为对比模型。所有实验的warm-up steps 设置为4 000,label smoothing设置为0.1,学习率设置为0.000 7,批大小max-tokens 设置为4 096,Dropout 设置为0.3。
在评价指标方面,本文使用BLEU值(双语评估替补)判断泰汉神经机器翻译的准确率,它表示candidate(所需评估的模型生成的句子)和reference(作为参考答案的人工译文)的相符程度,BLEU值越高则译文质量越好。
3.3 实验结果与分析
3.3.1 泰汉神经机器翻译对比实验及分析
本组实验主要展示融入无监督泰语依存句法信息的泰汉翻译结果,实验中依存距离惩罚机制的权重λ1,λ2和λ3分别为0.65,0.20 和0.15。如表2 所示,将本文方法在泰汉机器翻译实验的BLEU分数,分别与Transformer 方法和不使用依存距离惩罚机制的方法在泰汉翻译上的BLEU分数进行对比。

表2 泰汉神经机器翻译对比实验结果
此处使用本文方法和使用基于依存注意力机制的融合方法获得的BLEU分数,相比于Transformer模型,分别提高了0.46 分和0.18 分,该结果表明,在源语言端融合依存知识可以有效提升泰汉神经机器翻译任务的性能。此外,对融入的句法信息进行依存距离惩罚时,泰汉机器翻译的BLEU值相比直接融入句法信息提高了0.28 分。由于所使用的泰语依存句法知识是无监督迁移获得的,这些依存句法标注的准确度还不能达到与标准的依存句法树相当的程度。而基于依存注意力机制的融合方法在融入泰语依存信息时,关注每个位置的父词与每个词之间的距离关系。在依存树中相距较远的两者之间的依存关系经过累加后更可能存在错误,融合过程中如果引入了太多噪声,反而会降低翻译效果。因此,对依存信息按依存距离进行惩罚,有利于减少其中的错误带来的干扰。
同时,本文还对比了在各个模型下使用不同数据集时得到的BLEU分数,结果表明,随着使用的汉泰平行句对数量的显著减少,不同翻译方法的效果都有明显的降低。显然,平行句对的数量影响翻译模型的训练质量。但是,不管使用多大数量的训练数据,本文方法的翻译效果都有所提升。即使针对泰语这种低资源语言,该方法对提升翻译效果仍然具有一定帮助。
3.3.2 在多头注意力机制的不同层融合句法信息的对比实验及分析
受到Bugliarello 等人[14]实验的启发,本文也尝试在多头注意力机制的不同层融合泰语的句法结构知识,以研究不同注意力层的融合效果的差距。使用本文的融合方法分别在1~6 层融合泰语依存句法信息时,在汉泰平行语料库1 进行泰汉神经机器翻译得到的BLEU值如表3 所示。本组实验中依存距离惩罚机制的权重λ1,λ2和λ3分别为0.65,0.20和0.15。
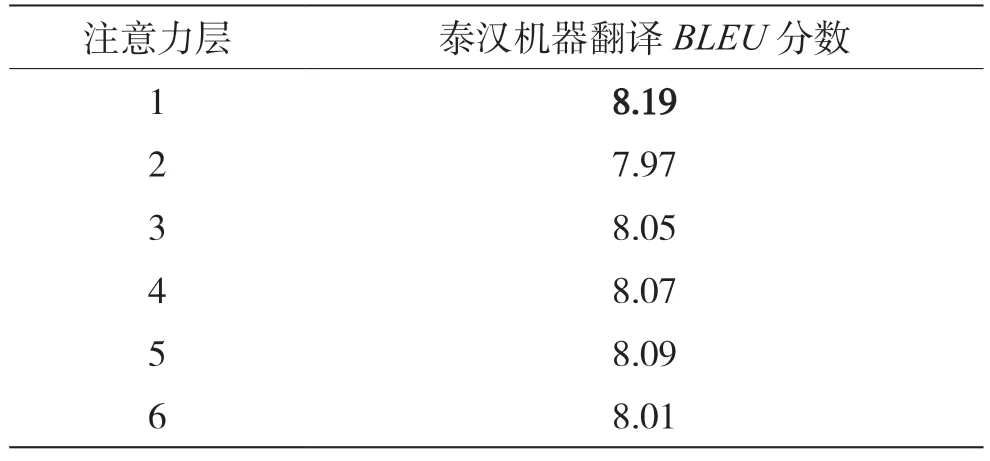
表3 多头注意力机制不同层融合句法信息的实验结果
实验结果表明,在多头注意力机制的第1 层进行泰语依存句法信息融合,取得了相对较高的BLEU值,与在第2 层进行融合获得的最低BLEU值相比,提升了0.22 分。正如Raganato 等人[16]的研究所表明的,多头注意力机制的第1 层会更多地关注将要翻译的单词本身。在第1 层引入父词的上下文信息可以使词嵌入包含更多特征,能够进一步帮助翻译模型更准确地完成翻译过程。因此,选择合适的融合层也有利于更有效地融入依存句法信息。
3.3.3 依存距离权重组合对比实验及分析
本组实验研究不同的权重组合对翻译效果的影响。使用本文的融合方法在汉泰平行语料库1 进行泰汉神经机器翻译得到的BLEU值如表4 所示。

表4 依存距离权重组合对比实验结果
在权重设置方案中,λ3=0.65 时,泰汉机器翻译的BLEU值为最高分8.19 分。实验结果表明,当权重更偏向具有直接依存关系的父词距离矩阵时,翻译的效果相对更好。由于无监督迁移获取的泰语依存句法信息准确率不高,在依存句法树上相距越远的两者之间越可能累积形成错误的依存关系,因此,对依存句法树中依存距离更近的标记之间赋予较高的权重,有利于融入更准确且重要的依存特征关系。
4 结语
本文提出了一种融合无监督依存句法的泰汉神经机器翻译方法,该方法通过无监督迁移获取泰语依存句法信息,并简单高效地融入到Transformer 模型。该方法减少了句法信息噪声对翻译效果的干扰,并利用泰语的依存结构知识帮助译文更加符合语言结构规范,一定程度上解决了由于缺乏高质量的汉泰平行语料导致模型训练不够充分所带来的泰汉翻译效果较差的问题。实验结果表明,该方法提升了泰汉神经机器翻译的性能。下一步工作中,将根据这种思路获取无监督泰语成分句法结构知识,并尝试提升其他低资源语言神经机器翻译性能。
