网络舆情受众参与行为标定数据空间构建*
2022-09-24张晓君
赵 旭 黄 微 张晓君
(1.吉林大学商学与管理学院 长春 132000;2.吉林师范大学图书馆 四平 136000)
0 引 言
第48次中国互联网络发展状况统计报告显示,截至2021年6月,我国网民规模为10.11 亿[1]。在互联网社会化升级和营造清朗网络空间的社会背景下,网络舆情分众化和时效性特征,使引导管控网络舆情受众的参与行为成为了现代化社会治理迫切需求[2]。
自20世纪末,国内外学者就开始展开网络舆情受众参与行为的研究。“受众”一词本义是指信息传播的接收者,这一定义强调了受众“接收者”的被动身份[3]。实际上,随着互联网的不断发展,网民数量持续稳定增长,网络舆情受众已经不仅是被动的舆情信息接收者,而是网络舆情产生、传播过程中的重要参与主体,是最直接的驱动力量。鉴于此,网络舆情受众被定义为“对社会敏感话题有持续关注度,并在网络空间以搜索、转载、回帖、评论、利用社交媒体发布原生新闻等形式,积极参与网络舆情信息生产传播的公民评论员[4]。而网络舆情受众参与行为更多的是指舆情受众的信息行为,所有与网络舆情信息源选择、信息使用、信息搜寻、信息交流等相关的人类行为[5]。
引导管控网络舆情受众的参与行为对于营造风清气朗互联网空间至关重要,而对网络舆情受众的参与行为靶向引导、有效管控的前提,则建立在网络舆情受众参与行为精准标定基础之上[6]。在网络舆情受众参与行为标定研究中,首先建立受众参与行为标准,将网络舆情受众参与行为划分为操作活动、交互活动和内驱活动[7];进而,基于舆情数据对单个舆情受众参与行为进行定性到定量、抽象到具体的描述,定量数据源自于对网络舆情受众个体的识别、行为的识别、情感的识别及体征的识别[8];最后对标定结果进行精度检验与校准,拟合参与行为轨迹,预测靶向引导的行为趋势[9]。

图1 网络舆情受众参与行为标定数据空间模型
然而,舆情事件信息散布在多个移动舆情平台。并且,数据形式复杂、数据体量较大、数据更新速度较快、信息价值密度较低。可是,PZ,DY〗数据整合汇聚在一个舆情受众参与行为标定大数据中心成本高、技术复杂,也会因为各移动舆情平台的数据保护壁垒而更不具有可行性[10]。同时,舆情受众参与行为标定最基础的标定粒度是单个受众,所有的舆情数据的数据对象必须明晰,进而确定舆情数据的占有、使用、收益、处分权利人,才能够建立任何一条舆情数据和受众、受众行为的关联,并基于舆情管理的多价值协同目标破除不同舆情平台的数据壁垒[11]。但是,即便解决了标定所需数据基础问题和数据对象问题,在展开受众行为标定及面向操作层面的靶向引导过程中,我们亦会发现,如何基于数据面向标定和引导需求提供精准、全面、智慧的数据服务和知识服务,是网络舆情受众参与行为标定的另一个关键问题[12]。
因而,在上述问题导向下,本文在梳理国内外相关学者的研究基础上,引入了数据空间的概念:数据空间是面向特定组织或个人的所有分布数据源及其丰富关联关系的集合,并包括数据对象、数据集、数据服务3个维度[13]。网络舆情受众参与行为标定数据空间则可以被界定为:面向特定舆情主体的所有移动舆情平台分布数据源及其丰富的舆情受众行为和数据关联关系的集合。
1 网络舆情受众参与行为标定数据空间模型
1.1 舆情受众参与行为标定数据空间模型框架
网络舆情受众参与行为标定数据空间模型由管理引擎、数据中枢系统和数据空间模型三大部分组成,如图1所示。参与行为标定数据协同需求驱动的管理引擎主要功能是感知参与行为标定对数据的需求,采集并调用数据,清洗并处理数据,沙盒数据输出。基于底层接口库的数据中枢系统主要功能则是对管理引擎进行管理、保障标定需求精准契合、中枢数据的实时更新。对数据对象进行管理,实现数据主体、舆情受众、数据权限、参与行为和数据关系的全生命周期管理。对数据集进行管理,保证数据具有较高的价值密度、适宜的体量、较细的粒度。提供数据服务和知识服务,保障舆情受众行为标定的数据基础和知识支撑。网络舆情受众参与行为标定数据空间模型则包括数据协同管理引擎模型、智能弹性数据沙盒模型、行为标定数据中枢模型、行为标定服务接口模型,融合爬虫技术、弹性分发技术、数据技术、语义本体技术,采用数据映射方法、生命周期管理方法、社会网络分析方法,实现上述模型的功能。
1.2 参与行为标定数据协同需求驱动的管理引擎模型
网络舆情受众参与行为标定数据协同需求驱动的管理引擎模型如图2所示,包括数据采集引擎、数据中枢引擎和数据输出引擎3个子引擎,数据采集引擎基于行为标定的数据需求,感知并触发采集行为指令,对多数据源数据进行并发采集。数据中枢引擎实际上是沙盒数据中枢引擎,执行数据清洗和处理,并暂存在沙盒数据集中。数据采集引擎在采集或调用数据前,需要根据数据中枢引擎的数据一致性检验结果,来判断是否执行采集或调用执行。数据输出引擎则是对数据沙盒的数据进行输出,以执行参与行为标定过程中的数据预检验。舆情数据沙盒可以理解为正式存储到数据中枢系统的暂存数据,以便在管理引擎的处理下,最终形成需求驱动、多源数据协同、价值密度较高、数据体量相对较小的子数据集,进而通过数据中枢系统引擎管理模块的检验,正式存储到数据中枢系统。
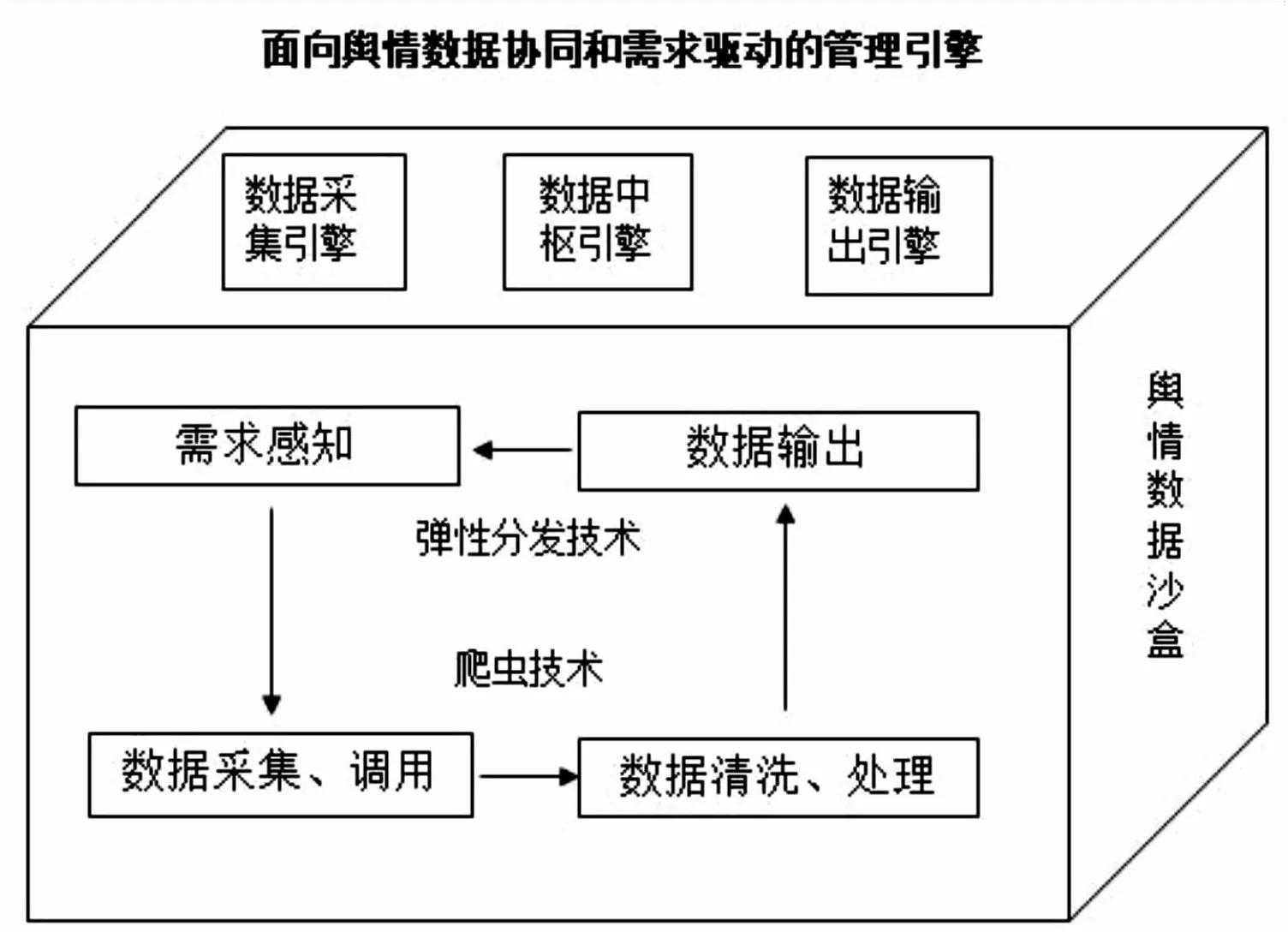
图2 网络舆情受众参与行为标定数据协同需求驱动的管理引擎模型
1.3 基于底层接口库的参与行为标定数据中枢系统模型
网络舆情受众参与行为标定数据中枢系统如图3所示,主要包括引擎管理模块、数据对象管理模块、数据集管理模块、数据服务模块,同时基于数据协同管理引擎接口、智能弹性数据沙盒接口、数据服务接口、行为标定数据中枢接口等接口库同舆情参与行为数据标定操作进行数据交互,并采用数据映射方法、智慧服务方法、生命周期管理方法、社会网络分析方法、分级管理技术、语义本体技术、云存储技术、大数据技术支撑中枢系统运行。

图3 基于底层接口库的网络舆情受众参与行为标定数据中枢系统模型
2 网络舆情受众参与行为标定数据空间算法
2.1 数据协同管理引擎算法
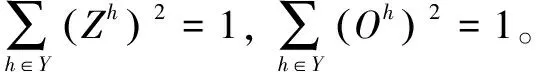
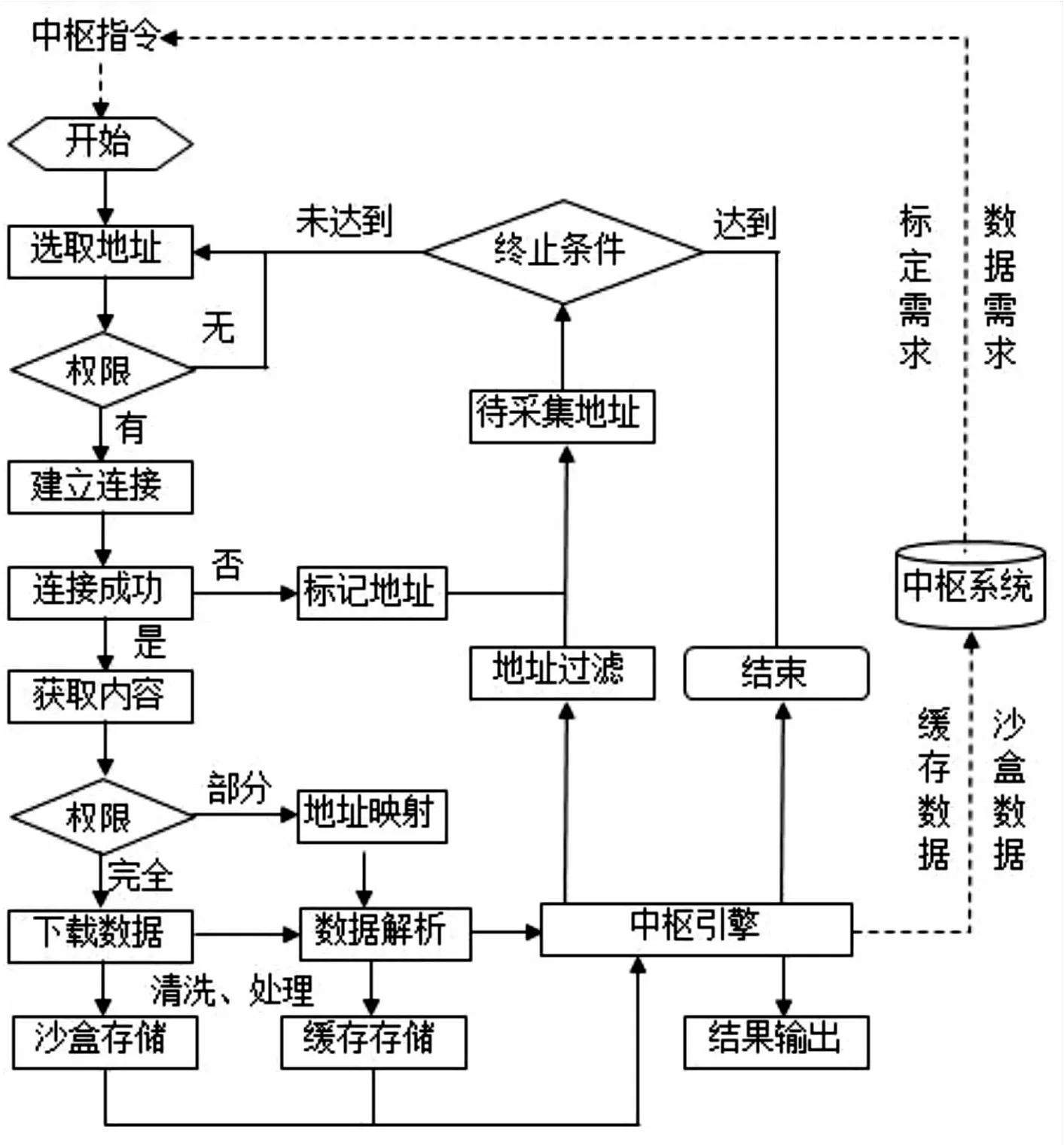
图5 数据协同管理引擎工作流程
定义J操作计算Zh,算法如公式(1)所示:
(1)
定义N操作计算Oh,算法如公式(2)所示:
(2)
接着开始HITS计算,初始化(D,k),D为j个种子数据源集合,k为任意自然数。设a=(1,1…1)∈Sj,设O0、Z0初始值为a,执行以下循环操作,返回Zk、Ok值:
Fori=1,2,…k
对Zi-1,Oi-1执行J操作,求得Zi
对0i-1,Oi-1执行N操作,求得Oi
END
接着判断数据权限,如果没有权限则重新选择数据源,对于有权限的数据源则建立连接,如果连接建立不成功,则入库到待采集地址,循环n次后仍然不成功则放弃采集。连接建立成功后,获取数据内容。具有完全数据权限的,则下载数据后,存储到数据沙盒,部分权限的则不下载数据,解析数据后,建立地址映射。中枢引擎负责数据的清洗、处理和数据输出,其核心的功能是对沙盒数据及待采集映射数据的相关性比对,本文采取基于块的相关性算法实现。
将数据源内容划分为多个独立的块,假设为标定内容块Cd、噪音块Cb、链接块Co。标定内容块与标定所需检索词相同或相似,或者同沙盒存储内容相同或相似,链接块指向与标定内容相关的链接,噪音块链接同待采集数据源没有关系。设定标定主题u,正在采集的数据源用Vi表示,已经获取的内容为Qi,Vi的链出数据地址用Vu表示,Vu为待采集数据源Qu,Qu的标定相关度用Sc表示。则Sc可以由公式(3)计算:
(3)
其中α为优先度,当Vu为噪音块链接,则同标定主题不相关。当Vu为标定内容块时,则与标定主题相关。本文采用以下方法改进词频逆文本频率指数(TF-IDF)算法[15],当Vu为导航链接块,数据源地址同标定主题索引有关,剔除噪音块及Qu∩Qi数据源,确定采集优先顺序,引入数据源数据协同权重改进TF-IDF算法来计算相似度,如公式(4)所示:
(4)
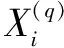
(5)
其中ti,l是标定主题词L在数据源的密度,O是数据源的数据总量,Ol是含有标定主题词L的数据页面总数,WSiSN为数据源的数据协同权重,如公式(6)所示:
(6)
公式(6)中,PRSi为目标数据源Alexa指数(alexa.cn)的3个月日均UV值,PLl为待采集数据地址的链出数量,PLk为待采集地址的链入和链出数量和。
沙盒数据和缓存数据在采集管理引擎中枢处理后,再通过数据中枢的协同管理引擎处理,确定最终是否存储到数据中枢。
2.2 智能弹性数据沙盒算法
网络舆情受众参与行为标定数据空间管理引擎的智能弹性数据沙盒工作流程如图5所示。

图5 智能弹性数据沙盒工作流程
数据沙盒作为一个相对临时的数据集,在数据管理引擎中具有重要的作用,一方面支持标定数据获取或者标定过程中的实时结果的输出;另一方面,基于敏捷开发的思维,避免数据直接存储到中枢系统数据集后,行为标定数据和标定需求不匹配而带来的时间和成本大幅上升问题。再者,对于采集的数据或者映射到的数据源,其真实性、可靠性、数据质量往往并不能在没有经过数据检验、数据集并不完善、采集映射进程还在进行的前提下,得到最终的可靠检验结果,此时数据或者映射地址存储到数据中枢数据库,会对数据中枢数据质量、时效性、真实性、价值密度带来很大影响。沙盒数据和映射数据、采集数据在数据检验和操作判断环节,一个最主要的标准就是内容相关度,本文提出基于舆情受众参与行为表示的内容相关度算法,首先构建内容子句网络图,接着计算词、节点、边权重,最后计算行为-内容相关度,得出不同行为维度下采集数据、映射数据和现有沙盒数据的相关程度,如下计算:
首先,将采集数据、映射数据以及沙盒数据进行字句提取,提取字句尽量充分覆盖该内容主题。接着,将每个子句作为网络图节点,以重合词建立连接构成无向图,边权重算法如公式(7)所示。其中,L1和L2代表子句构成的节点,Weight(L1,L2)代表L1和L2的边初始权重,|L1∩L2|代表子句分词集合交集词数量,|L1∪L2|代表子句分词集合并集词数量。
(7)
节点算法选择上,鉴于Text Rank算法[16]适用于无向图,并将关键词视为节点,因而本文将子句视为节点并进行改进来实现节点权重的迭代,如公式(8)所示。
WeightT(Li)=(1-e)+e×
(8)
其中e为阻尼系数取0.85[17],WeightT(Li)为节点Li权重,in(Li)和out(Lj)分别为节点Li的链入和链出。Weightij代表节点Li与Lj边权重,Weightjk代表节点Lj与Lk边权重。进而基于节点权重更新词权重,如公式(9)所示。其中,Weight(Xi)是词Xi权重,X为包含词Xi节点结合,WeightT(Lk)为节点Lk权重,L为全部节点,|L|为集合中元素数量。
(9)
节点间连接的边权重在词权重基础上计算,如公式(10)所示,Weight(L1,L2)为节点L1和L2连接的边权重。
(10)
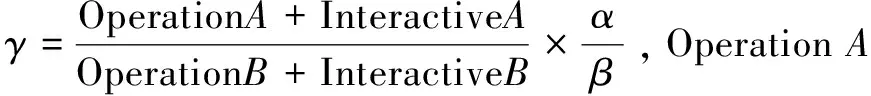
Sim(A,B)=
2.3 行为标定数据中枢算法
数据中枢系统主要实现数据引擎管理、数据对象管理、数据集管理和数据服务功能,数据引擎管理其实就是同数据协同管理引擎和数据沙盒的引擎指令交互,数据服务模块和数据集管理模块则主要基于传统的大数据、语义本体、社会网络分析等技术和方法,通过数据服务和知识服务接口实现有关功能。舆情受众参与行为数据空间同传统大数据的主要区别,就在于数据对象的管理,因而本文重点围绕数据对象权限,采用分级管理技术和生命周期管理方法,设计了行为标定数据中枢工作流程,如图6所示。
面向数据权限的舆情主体可以被区分为拥有全部数据权限的数据权人,拥有部分数据权限的被授权人,尚未确定数据权限的未授权人以及没有任何数据权限的不被授权人。从数据权限的类型来看,包括数据占有、使用、收益和处分4种类型。然而,网络舆情数据源多样,同一用户在跨数据源的身份标识可能不同,那么如何跨舆情网络匹配网络用户则是数据中枢需要解决的主要问题。只有解决了这个问题,才能够将不同舆情平台的同一用户识别出来,并基于数据权限展开行为识别和标定。因而,本文设计了基于好友的跨舆情平台用户身份匹配算法,计算过程如下:

图6 行为标定数据中枢工作流程
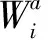
(12)
(13)

(14)
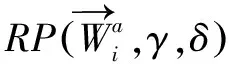
(15)
(16)
2.4 行为标定服务接口算法
网络舆情受众参与行为标定服务接口从标定需求出发,面向数据空间的知识服务和数据服务,基于数据指令和算法请求指令,执行相应的数据所示或算法操作,将返回结果通过Api工具进行输出,流程如图7所示。
从过程来看,首先基于指令进行数据检索,接着判断是否需要深度学习计算,一般情况下基于行为类型标签检索、数据源地址标签检索、受众ID检索是不需要深度学习计算的,那么则拼接查询语句,执行查询语句,返回数据结果并输出。如果需要深度学习计算,则进入消息队列等待,并输出是否处理的结果,同时请求计算,计算完成后输出数据结果。从算法请求流程来看,对提交的算法指令在算法库中进行检索,接着判断是否需要深度学习,不需要深度学习则拼接、执行语句,返回算法执行结果并输出。如果需要深度学习,则进一步计算后输出算法计算结果。然而,基于舆情主题进行检索,进而将输出数据作为标定基础数据集,也是舆情标定实践操作的重要内容,则需要采用科学的算法来提高检索精度,因而在公式(7)-(9)基础上,进一步改进算法,以适应主题-内容数据输出的检索需求,可如下计算。
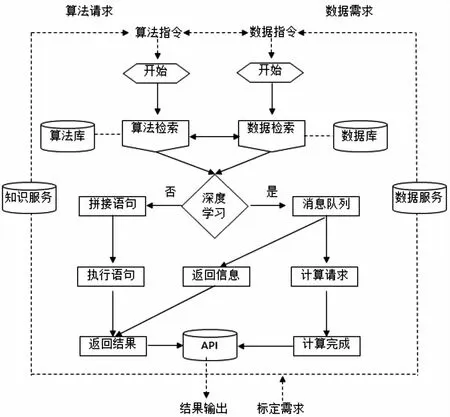
图7 行为标定服务接口工作流程
首先构建检索主题句和数据空间内容子句网络图,接着计算词、节点、边权重,最后计算主题-内容相关度。检索主题句进行字词提取,数据空间内容则进行子句、字词提取,将检索主题句和内容子句作为网络图节点,以重合词建立连接构成无向图,边权重算法如公式(17)所示。其中,L1代表检索主题句,L2代表内容子句构成的节点,Weight(L1,L2)代表L1和L2的边初始权重,|L1∩L2|代表检索主题句和内容子句分词集合交集词数量,|L1∪L2|代表子句分词集合并集词数量。
(17)
节点权重、边权重采用上文公式(8)-(10)计算,接着构建以检索主题句为节点A,以及数据空间内容句B为节点的无向网络图U,基于公式(18)计算检索主题-内容相关度。其中|U|为网络图U所有节点数量,k为节点Li边的数量,ConditionA为检索主题条件约束集,ConditionB为同检索主题条件约束集要素对应的数据空间内容条件属性集。例如ConditionA=(数据源:新浪微博,数据主体:光明日报),ConditionB=(数据源:新浪微博,数据主体:光明日报∪参考消息)。
Sim(A,B)=

(18)
最后,采用上述方法循环计算出所有数据内容同检索主题的相关度,按照从高到低排列,调整输出窗口大小输出数据,作为该主题下舆情受众参与行为标定的基础数据。
3 实验设计与结果分析
3.1 实验环境
a.实验工具。
操作系统Windows 10 专业版(64 位)
处理器Intel(R) Core(TM) i5-8250U
CPU @ 1.60GHz 1.80 GHz
内存4GB
编译环境Python 3.8.3、MATLAB2019a、
Gephi0.6.2
b.参数设置。
参数设置如表1所示。

表1 实验参数设置表
3.2 实验数据
采用爬虫在抖音、新浪微博获取数据,新浪微博样本数据样例见表2。
表2 “汤加火山爆发”事件舆情受众参与行为标定数据样本

续表2 “汤加火山爆发”事件舆情受众参与行为标定数据样本
3.3 结果分析
3.3.1数据协同管理引擎效率分析
在多次试验后,最终选择相关度指标0.2方案,进行了数据的采集。Python爬虫数据采集线程为10, 新浪微博以https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D%E6%B1%A4%E5%8A%A0%E7%81%AB%E5%B1%B1为起始地址,抖音以https://www.douyin.com/search/%E6%B1%A4%E5%8A%A0%E7%81%AB%E5%B1%B1%E5%96%B7%E5%8F%91?source=normal_search&aid=9cfa6148-ab76-4594-b149-d49c62bb6b6e&enter_from=recommend为起始地址开始爬取,耗时3小时24分,cpu平均利用率72% ,内存平均利用率83%。采集过程中共选取地址189个,连接失败地址12个,连接成功地址177个,其中抖音地址59个,新浪微博地址118个,最终采集新浪微博数据12 126条,采集抖音数据3 105条,抖音映射地址59个。为检测数据协同管理引擎算法效率,进一步将不采用算法的Python采集[18]和火车头采集[19]效果进行了对比,结果如表3所示。

表3 采集效率对比
结果表明,本文设计的数据采集流程清晰、有效,能够针对标定数据需求,采集到足够的样本数据,并降低了数据存储对硬件的要求。同不采用数据协同管理引擎算法的其他采集方式相比较,优点是样本数据质量更高、更精准,缺点是耗时虽然比火车头采集短,但是相较未应用本算法的普通Python采集方式,耗时相对较长。
3.3.2沙盒数据和映射数据分析
最终沙盒数据和映射数据统计如表4所示。随着相关度指标的上升,采集数据量、沙盒数据量、映射数据量和输出数据量都增大。说明相关度指标值越大,采集的数据内容和沙盒数据内容相似度越大,在达不到数据标定样本数据差异化要求情况下,将会采集并输出更多的数据。而相关度指标为0时,则说明采集内容和数据沙盒数据内容相似度较小,但是却可能存在偏离标定数据主题的情况。从映射数量来看,因为映射数据更多的是抖音的视频数据,因而,随着相关度指标的增大,映射数据量虽然有所攀升,但是幅度不大,说明抖音视频的内容相似度较小,而新浪微博的数据相似度较高。最终本文选择相关度为0.2展开进行其他数据实验,实验结束后,映射抖音数据地址2 105条,输出数据15 231条,沙盒中尚有21 294条数据待检验,因抖音映射数据的地址、对象、标题、标签、摘要元数据在沙盒及输出数据中,因而采集数据量是沙盒数据和输出数据之和36 525条。
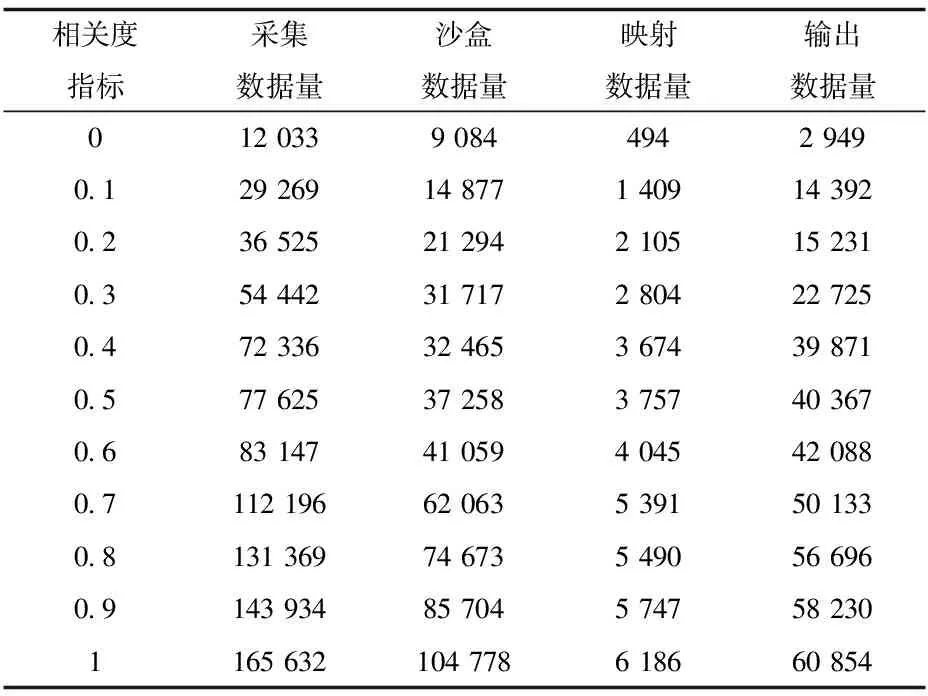
表4 沙盒数据和映射数据统计表
3.3.3行为标定中枢及服务数据分析
行为标定中枢数据存储了上述实验结果的输出数据,以便基于标定数据服务需求向标定行为人输出,有关数据结果已经在上文说明。但,行为数据中枢数据处理过程中,更重要的是采用了基于好友的跨舆情平台用户身份匹配算法,对于跨平台的同一真实用户进行识别。而此识别结果在标定服务中,作为检索主题-内容相关度条件约束,则能够更精准地匹配到中枢数据内容[20]。相关结果如表5和表6所示。
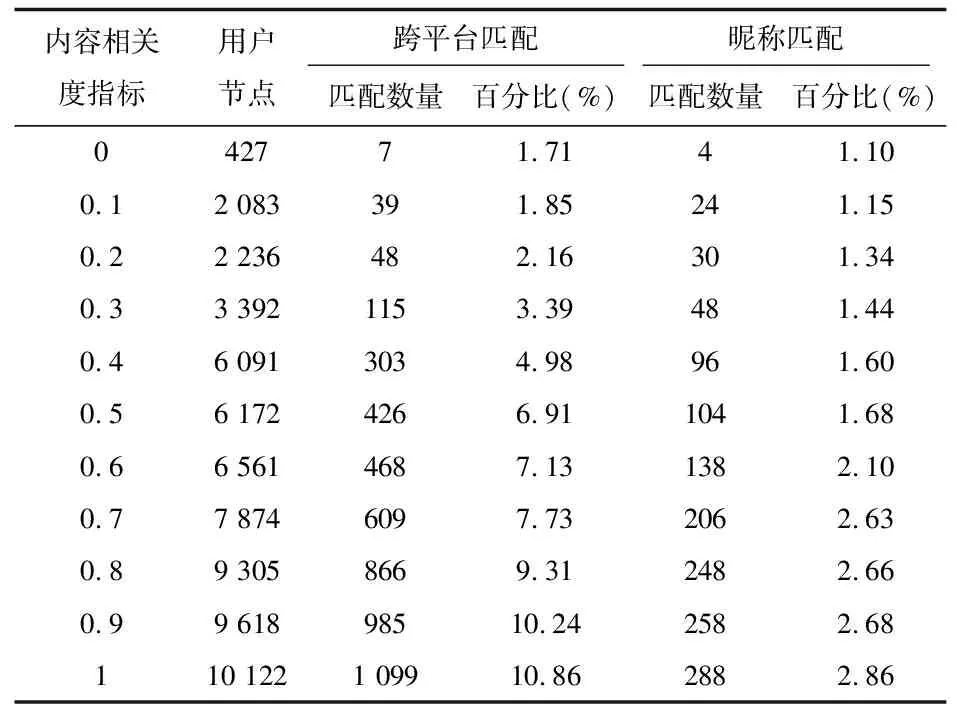
表5 跨舆情平台用户身份匹配和基于昵称匹配结果对比

表6 检索主题-内容相关度数据结果统计表
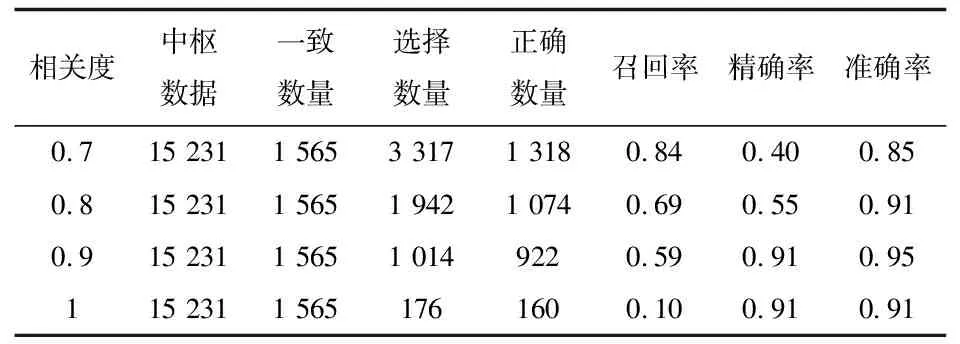
续表6 检索主题-内容相关度数据结果统计表
数据结果表明,基于好友的跨舆情平台用户身份匹配算法随着内容相关度指标的增加,识别效果得以提升,相较昵称识别的方式提高了识别精度。检索主题-内容相关度算法在检索主题-内容相关度设定为0.8以上时,能够取得较好的检索结果,其中表中相关度为检索主题-内容相关度,内容相关度取0.2,一致数量为检索主题-内容完全一致的数量,作为判定标准。选择数量为不同检索主题-内容相关度算法,检索到的数据数量,正确数量为选择数量中,同一致数量完全相同的数据量。
3.3.4数据空间可视化分析
基于获取的网络数据,采用Gephi软件绘图并获取数据统计结果。以舆情受众参与行为关系连接为边,构建了网络舆情受众参与行为标定数据空间的行为关系网络。网络图中,行为关系连接数为24 438,平均加权度为11.88,反映了标定数据空间用户参与行为较为紧密。参与行为统计结果显示,点赞行为比例为48.58,评论行为比率为15.76%,内驱行为比率为0.02%。从交互、参与和内驱行为汇总比例来看,比值为100∶30∶1。说明在标定数据空间,以交互行为数据为主,参与行为数据为辅,而内驱行为较少。也说明仅仅以获取到的基础数据作为舆情受众参与行为识别和标定的结果性数据存在疏漏、不科学、错误的可能性,需要进一步对行为表象形成的数据空间数据进行分析挖掘,特别是基于语义对内驱行为的挖掘。

图8 数据空间数据源核心节点图
以受众用户为节点,以链接关系为边,构建了舆情受众参与行为标定数据空间云图,数据空间用户节点众多,连接较为频繁,舆情受众关系明晰,具备参与行为标定的用户识别基础。以数据源为核心节点,以舆情话题相关性为边,构建数据源核心节点如图8所示。可见,新浪微博数据源的衍生话题较多,而抖音衍生话题较少,为基于话题对舆情受众参与行为进行标定和识别构建了数据基础。
4 结 论
针对网络舆情受众参与行为标定数据源分散、数据整合存在壁垒、数据主体不明晰、数据管理权限缺失现状,为解决舆情受众参与行为标定所需基础数据建设和知识支撑问题,构建了网络舆情受众参与行为标定数据空间模型,提出了网络舆情受众参与行为标定数据空间算法,并设计了实验,分析了实验结果。
结果表明,本文设计的数据采集流程清晰、有效,能够针对标定数据需求,采集到足够的样本数据,样本数据质量更高、更精准。智能弹性数据沙盒算法有效地起到了数据中枢数据缓冲、筛选的作用,跨舆情平台用户身份匹配算法识别效率较高,检索主题-内容算法在相关度设定合理的情况下,召回率、精准率、准确率达到理想效果。所构建的网络舆情受众参与行为标定数据空间数据体量合理、数据对象清晰、受众行为被如实反映。未来研究,将汇聚更多的数据源展开实验,并重点对本文提出的算法进一步优化。
