古代中国医学文献的命名实体识别研究
——以Flat-lattice增强的SikuBERT预训练模型为例*
2022-09-23刘江峰王东波
谢 靖,刘江峰,王东波
0 引言
古代中国医学文献所记录的中医知识是中华传统科学文化的重要分支,对中医文献进行深度加工和知识标注,有助于挖掘蕴含在其中的古代医学知识及中医哲学思想。比如,青蒿素的发现就是从古代中医文献《肘后备急方》中得到启发。古代中医文献以文言文的形式存在,是中国古籍文献的重要组成部分,其中的医学知识又形成了独立的医学和哲学体系,涉及较多中医学概念。古代中医文献的数字化、智能化加工,对中医知识的深度挖掘具有重要价值。其中,对古代中医文献进行命名实体识别,有助于理清古代中医文献的知识概念表达,是古代中医文献信息化、智能化处理的重要任务。
数字人文近年来成为中国古代文献研究的新范式,极大推动了中国古代文献智能化处理的进程。以古文献分词、词性标注、命名实体识别、语义消歧等为研究内容的文本挖掘方法得到了广泛关注,如王姗姗等在多维领域知识下对《诗经》的自动分词研究[1];李娜等对古籍方志地名的自动识别[2];王东波等对先秦典籍历史事件的自动识别[3];刘浏等对《春秋经传引得》中同名异指和异名同指现象的自动识别[4]。BERT预训练模型的提出为中国古文献智能处理提供了新思路,用户可以使用预训练模型完成断句、分词、词性标注、信息抽取等任务。例如,王倩等通过BERT-LSTM-CRF模型对《四库全书》进行断句和标点标注,调和平均值分别达86.41%与90.84%[5];张琪等构建了先秦典籍分词、词性一体化标注BERT模型,分词和词性标注准确率分别达到95.98%、88.97%[6];喻雪寒等采用RoBERTa-CRF模型实现对《左传》战争句论元的抽取,准确率达87.6%[7]。以上研究为数字人文环境下运用BERT预训练模型,实现中国古代医学文献的智能化处理提供了借鉴思路。
本文以古代中医文献的代表作《黄帝内经·素问》(以下简称《素问》)为研究对象,通过分词、命名实体标注构建“素问语料库”,该语料库能够体现《黄帝内经》所包含的中医学理论体系。在素问语料库基础上,利用由南京农业大学信息管理学院牵头、南京师范大学文学院共同构建的SikuBERT 及SikuRoBERTa 预训练模型,考查其对于古代中医文献命名实体自动标注的效果,并通过Flat-Lattice Transformer平面格子结构增强对《素问》中命名实体词汇的词向量表达,进而优化SikuBERT、SikuRoBERTa预训练模型对古代中医文献命名实体识别的效果,为古代中国医学文献的智能化处理做出益探索。
1 我国古代文献命名实体研究概述
1.1 命名实体研究
命名实体识别(Named Entity Recognition,NER)是信息抽取技术的重要组成,能从文本文献中识别预定义的命名实体,如新闻语料中的人物、地点、时间、事件。命名实体识别术语在MUC(Message Understanding Conferences)第六次会议上提出[8],并在其他相关国际会议中由人名、地名、机构名等逐渐细化扩展至跨语言、多领域的命名实体,如CoNLL-2003(Conference on Computational Natural Language Learning 2003)中提出的语言无关命名实体识别[9]。
命名实体识别是自然语言处理的关键任务,相关研究的发展主要历经了4个阶段。一是基于词典与规则的早期阶段,向晓雯等利用统计与规则相结合的方法,通过词性序列识别命名实体,实验结果F1 值达到80.02%[10];王昊构建基于层次模式匹配的实体识别模型,并应用于学术论文术语缩略语的识别,取得较好识别效果[11]。二是基于传统机器学习模型的阶段,陈怀兴等提出利用HMM 词对齐结果抽取命名实体翻译等价对的方法,具有较高的识别率[12];陆伟等采用条件随机场模型,利用词汇、词法及词型特征,实现对商务领域产品的命名实体识别,取得较为满意的识别效果[13]。三是基于深度学习模型的阶段,李丽双等提出基于CNN-BLSTMCRF的神经网络模型,其在BiocreativeⅡGM和JNLPBA2004生物医学语料上的F1值可达89.09%和74.40%[14];丁晟春等运用Bi-LSTM-CRF深度学习模型对商业领域中的企业全称实体、企业简称实体、人名实体进行自动识别,识别率平均F1值达90.85%[15]。四是基于自注意力及迁移模型的阶段,崔竞烽等对菊花古典诗词的7类命名实体进行标注,比对BiLSTM、BiLSTMCRF和BERT模型的识别效果,结果表明预训练模型BERT 的F1 值最高[16];陈美杉等提出基于KNN-BERT-BiLSTM-CRF 的实例及模型迁移框架,对肝癌自动问答中的命名实体进行标注,迁移效果表明F1值可以提升1.98%[17]。
从以上研究可看出,命名实体的研究文本对象包括新闻、商业产品资料、学术文献、网络社区文本、生物医学文本及病历等,实体对象也由人名、地名、机构名扩展至商务企业名、生物医学术语、古代诗词实体等。从近年来研究技术的发展来看,在深度学习和神经网络算法基础上,加入注意力、迁移学习等机制成为主流方案。在中文命名实体的识别应用中,由于中文分词的特殊性,分词效果对于命名实体识别效果具有一定影响,基于字的识别机制会丢失词汇级的上下文信息。Zhang等提出了用于中文命名实体识别的Lattice(格子结构),并将Lattice结构词向量应用于LSTM模型,避免了由于分词而导致的命名实体识别错误[18];Li等在Lattice结构上进一步提出了平面结构的Flat-lattice Transformer 微调索引机制,该机制可以继续提升Lattice-LSTM模型对命名实体识别的效果[19]。本文在选择适合古代中医文献命名实体识别的模型时,考虑到古文及中医术语构词的特殊性,采用Flat-lattice Transformer 结构完成对《素问》中《黄帝内经》术语的标注,并考查其对于现有古文BERT预训练模型的提升效果。
1.2 中文古籍BERT预训练模型研究
BERT模型是2018年由Google提出的一种双向Transformer预训练模型[20]。Transformer是Vaswani等提出的基于“自注意力机制(Selfattention)”叠加形成的深度网络,能够有效表达词汇上下文的特征[21]。BERT在大规模数据集上进行了预训练,用户可以直接下载预训练模型,而后通过微调(fine-tuning)获得更好的训练效果。对于用户而言,BERT预训练模型可以作为实验的组件进行搭配,所有任务无需从零开始。自提出以来,BERT预训练模型在自然语言处理相关领域均取得了优异效果。陆伟等基于BERT和LSTM方法构建对关键词的自动分类模型,实验效果中F1值达85%[22];赵旸等比对了BERT中文基础模型(BERT-Base-Chinese)和中文医学预训练模型(BERT-RePretraining-Med-Chi)在中文医学文献摘要数据上的分类效果,实验结果表明,BERT模型在大规模文本分类中能取得较好效果,而BERT-RePretraining-Med-Chi则能进一步提高分类效果[23];吴俊等在BERT中嵌入BiLSTM-CRF模型,令自建数据集的术语提取效果(F1值)达到92.96%[24]。
在数字人文研究领域,BERT 相关预训练模型的构建得到了国内学者的重视,包括中文RoBERTa(Chinese-RoBERTa-wmm-ext)、SikuBERT 及 SikuRoBERTa 等。 中文 RoBERTa是由哈工大讯飞联合实验室发布的中文预训练语言模型,其中Whole Word Masking(全词掩码,WWM)可以保证在BERT进行Mask任务时将粒度由字延伸至词,确保中文词汇整体参与BERT 自注意力机制[25]。SikuBERT、SikuRo-BERTa 预训练模型是在Bert-Base-Chinese、Chinese-RoBERTa-wwm基础上加入繁体《四库全书》继续训练后得到的预训练模型,在《左传》的分词、词性标注、断句、命名实体识别等多项任务中均表现优异[26]。文章以主流中文古籍BERT 预训练模型为基础,探索在中医这个特色主题文献集上BERT 预训练模型对中医学命名实体的识别效果。预训练模型见表1。
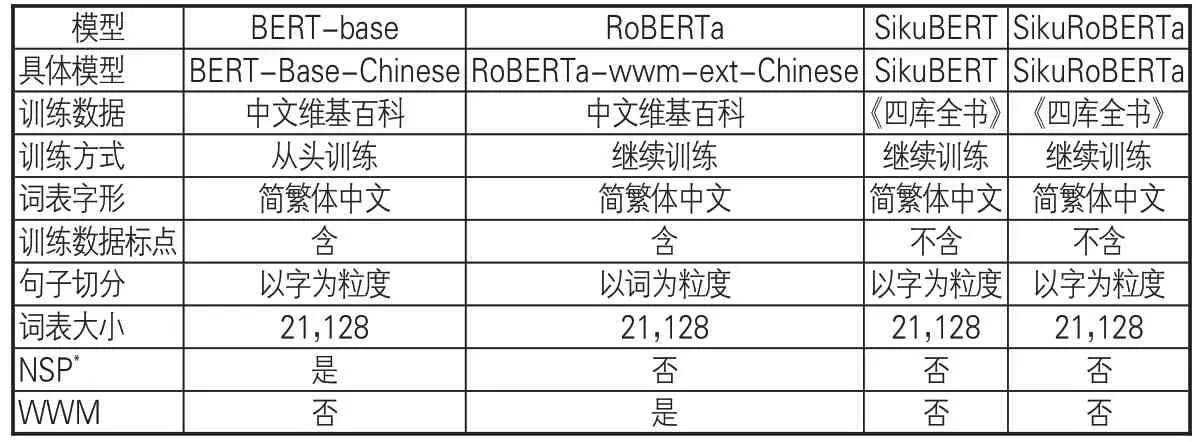
表1 古文BERT预训练模型简介
2 数据与研究框架
2.1 语料来源与数据标注
《黄帝内经》是中国最早的中医典籍,成书于先秦两汉时期,由《素问》《灵枢》两部分构成。《素问》系统阐述了中医的基础理论体系,包括病因、病证、病理、脏腑、经络、阴阳五行等,而《灵枢》则以经络腧穴、针灸治法等主题为主。《黄帝内经》是中医思想的源泉,其理论体系成为后世中医理论的先导,相关术语为后世中医广泛继承使用。在中国古代医学文献研究中,对《黄帝内经》《伤寒论》《难经》《神农本草经》等典籍的研究相对较多、相关词典资源相对丰富,但大量的其他中医古籍文献仍有待进一步深度加工处理。本文以《素问》为主要研究对象,利用词典资源完成《素问》文本内中医学概念实体的识别及标注,在此基础上通过现有BERT 古文预训练模型实现对中医命名实体术语的自动提取。BERT 预训练模型为中国古籍文献的智能化处理提供了新思路,以BERT 模型为框架、《四库全书》等典籍为全文语料进行无监督训练而获得的预训练模型,可以作为工具直接运用于特定古籍文献的分词、词性标注、命名实体识别等任务中。但对于中医这一特殊专业领域的文献,需要对领域知识词汇进行补充。现有的中医学词典可提供相关词型知识,而通过以Word2Vec为代表的词向量模型可以进一步获取领域词典的上下文特征。《黄帝内经》(特别是《素问》)对后世的中医文献影响深远,因而《黄帝内经》相关的词典资源及其在具体中医文献中的上下文信息,可以作为BERT预训练模型在中国古代医学文献处理中的有力补充。在《素问》语料的版本来源上,选择郭霭春先生校注的《黄帝内经素问校注》[27]。该版本详细梳理了《素问》的各个古籍注版,是《素问》研究集大成著作。在《黄帝内经》医学术语的词典选择上,本文选择了周海平等主编的《黄帝内经大词典》。该词典是目前收录《黄帝内经》词条最多、词义最为详尽的工具书[28],共包含词型1.9万多种。
需要说明的是,在对《素问》相关命名实体语料的加工过程中,笔者对《黄帝内经大词典》收录词型做进一步加工,如提取在词型说明中包含“病证名词”“运气学说术语”“病理名词”“穴位名词”“五行术语”“经络名词”等命名实体明确标识的词条,并对命名实体同义词条(如别称、缩略语等)进行了提取。在《黄帝内经大词典》收录的《黄帝内经》术语实体分类基础上,以其中主要命名实体词汇为研究对象,并将脉学及脉象等关联密切的术语类别进行合并,最终形成本文命名实体识别的主要分类(类目),如表2所示。
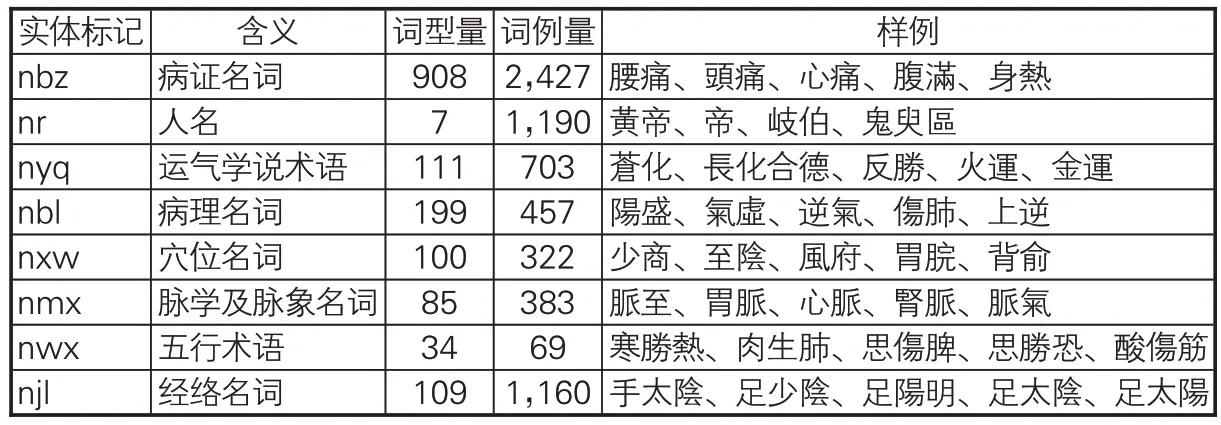
表2 《素问》主要命名实体标记集及其样例
文章以《黄帝内经大词典》收录词条为基础,通过最大匹配算法对《素问》繁体文本语句进行了分词并加以人工校对,对其中由于分词歧义引起的词汇切分错误进行了核对。比如,“則脈充大而血氣亂”可以切分为“則/脈/充大/而/血氣/亂”和“則/脈/充大/而/血/氣亂”,这里根据上下文信息选择“則/脈/充大/而/血氣/亂”。在此基础上利用词典词条内的术语分类标记对《黄帝内经》术语命名实体进行标注,样例如下:
【nbz 霍亂】/,刺/【nxw 俞】/傍/五/,【njl足陽明】 /及/上/傍/三/。
分词后,《素问》含词汇6,753个,其中术语词型1,553个、词例6,711条。在所有术语词型及词例中,病证名词最多,人名、经络名词次之,五行术语出现最少。从构词及上下文特征来看,不同术语类型有不同特点:病证名词的构词多包括“厥、聾、攣、痛、脹”等字样;经络及穴位名词,前后多出现“刺”字。《素问》分词及中医命名实体标注后的基本情况如表3所示。

表3 语料基本统计数据
在已分词、已命名实体标注的繁体《素问》文本基础上,文章将其转为序列标注格式。本实验的序列标注集合为{B,I,E,S,O},其中B代表命名实体词汇首字符,I代表命名实体中间字符,E代表命名实体词汇尾字符,S代表单字型命名实体字符,O代表非命名实体相关字符,正常实体序列由B标记开始、E标记结束。在标记BIESO的同时,文章还在相关标记记号后附上实体分类,标记样例见表4。
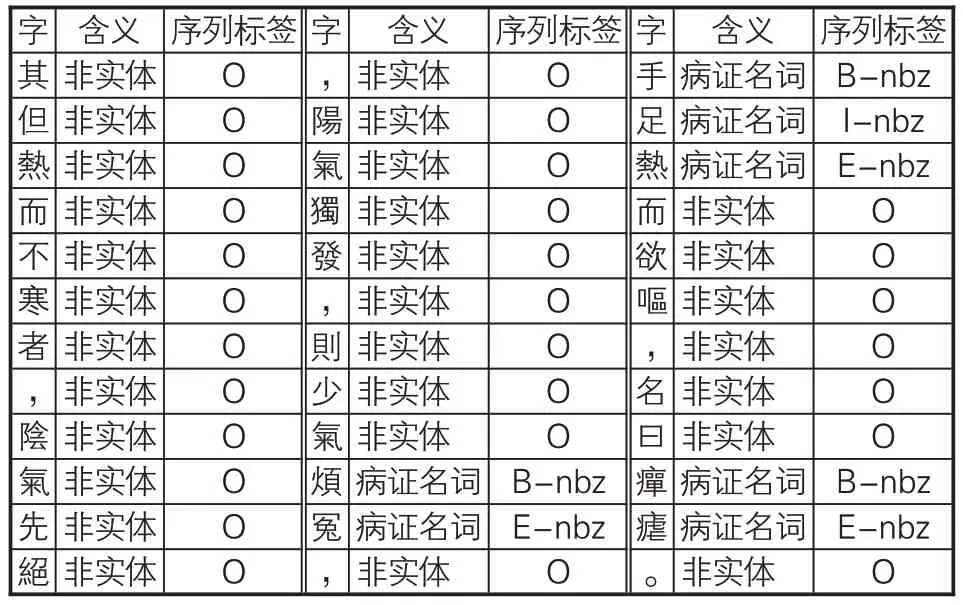
表4 《素问》命名实体数据集的标注示例
2.2 研究框架及模型微调过程
2.2.1 研究整体思路
在已切分词语及已标注术语实体的语料上,本文利用现有的4 种古文繁体BERT 预训练模型,对《素问》术语命名实体自动标注展开研究。研究主要分为3个阶段:一是直接考查现有古文繁体BERT模型对中医术语命名实体的标注效果,遴选效果较好的预训练模型进入下一阶段微调过程;二是为防止由于预训练模型词典中医学词汇缺失而导致词汇向量切分有误,选用了Flat-lattice 结构对中医学术语进行标注序列转化,并通过Word2Vec模型在“中醫笈成”[29]全文数据库收录的繁体中医典籍文本上获取《素问》中医学术语的上下文知识;三是用Flatlattice Transformer微调后的中医术语词向量结合古文繁体BERT 模型,观察“预训练+微调”模型处理后《素问》中医术语命名实体的自动标注效果。在所有命名实体识别的训练和标注中,均采用十折交叉验证的方法,即将已标注的素问语料库平均分为10份,展开10轮训练,每次选出其中9份用于训练,1份用于结果验证;在考查结果时,以通过10轮交叉验证的均值来验证效果。研究思路框架如图1所示。
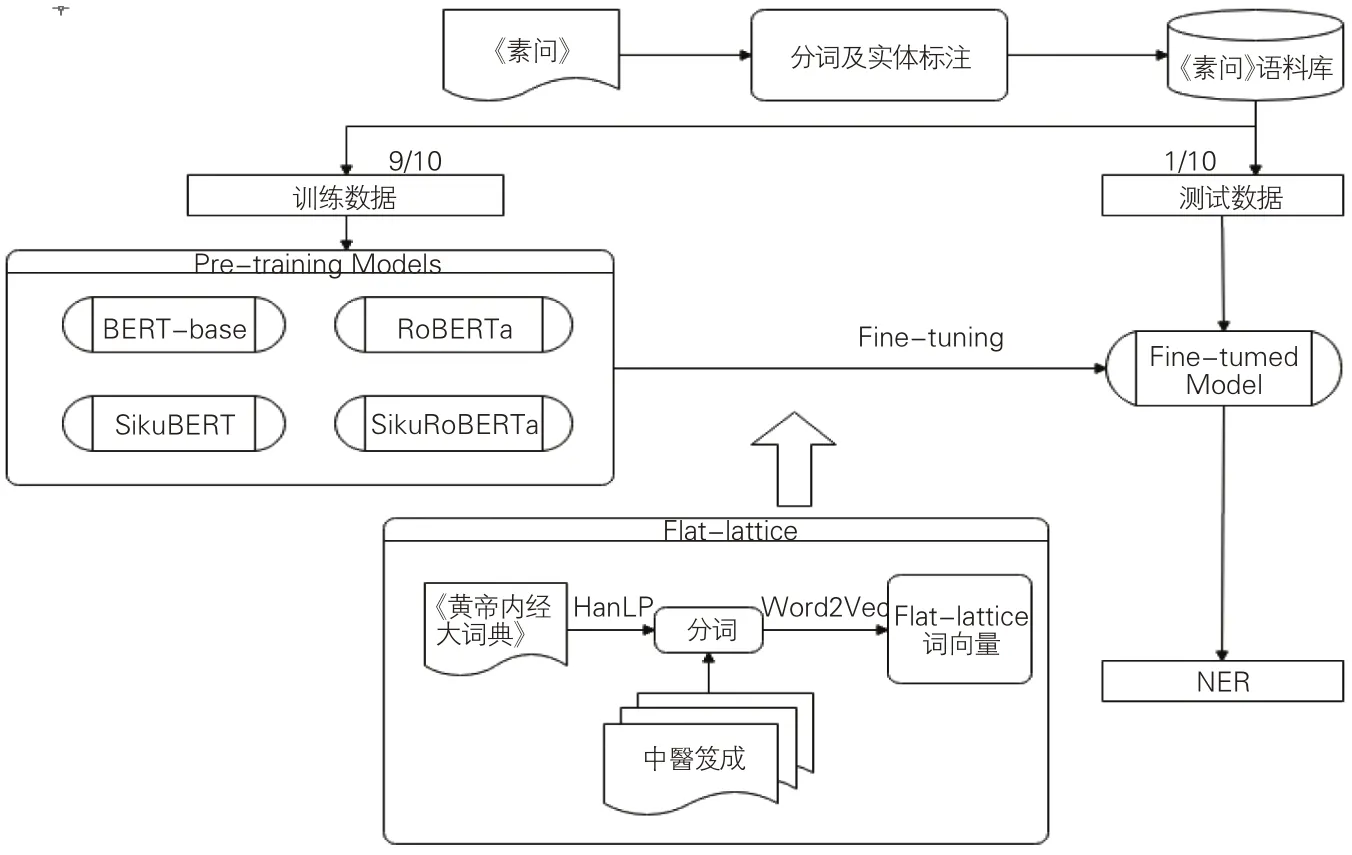
图1 研究框架
2.2.2 Flat-lattice Transformer结构转化
Flat-lattice Transformer(FLAT)结构源自对汉语词汇标识的Lattice(格)结构,该结构能避免因分词错误的传递而引起的命名实体识别问题。中文的命名实体识别与分词任务密切相关,命名实体的边界也是词汇边界,词汇切分错误会影响命名实体识别效果。在现有古文繁体BERT预训练模型中,多以字为粒度(见表1),然而古代中国医学文献含有大量的中医学术语,以字为粒度的训练并不能满足医学领域的知识表达。Lattice 结构可以利用显性的词和词序信息,且不会出现分词误差。Flatlattice结构在Lattice结构基础上标记词汇Token及其头尾位置Head、Tail。这种标记方式可以简单地将命名实体标记BIESO序列进行转换及还原。同时,Flat-lattice Transformer结构的自我注意机制使字符能够直接与任何潜在的单词交互(含自我匹配),并可有效防止标记序列出现“OIE”表达错误。本文涉及的《素问》语料Flatlattice Transformer 微调标记过程如图2 所示,包括BIESO序列标记及实体类型标记。
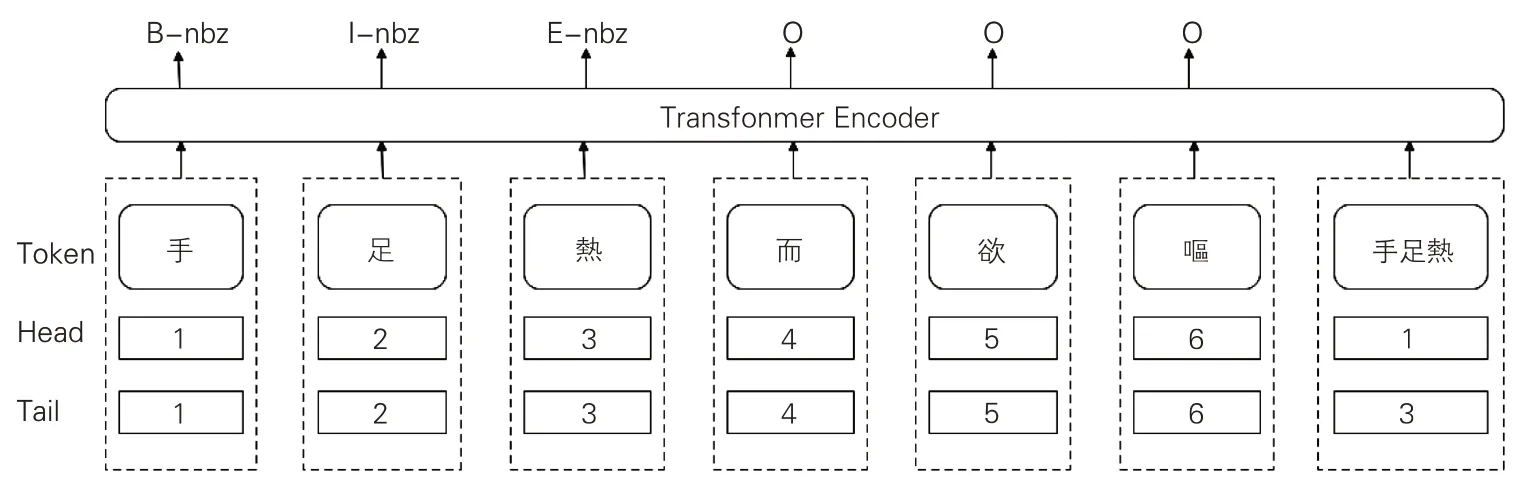
图2 Flat-lattice Transformer结构示意图
2.2.3 《素问》命名实体的词向量生成
BERT预训练模型的出现为小规模语料智能处理提供了新的解决方案:在大规模语料训练基础上,BERT模型能够快速、准确地为小规模语料提供预训练数据支持。RoBERTa、SikuBERT及SikuRoBERTa等预训练模型在大规模古汉语文本基础上进行了训练,尤其是《四库全书》语料的加入,使它们能够覆盖经、史、子、集等多种题材的古籍文本。但对于古代中医文献这个领域,由于有大量中医实体名词存在,命名实体在分词阶段就可能存在切分错误。基于词典的方式可以获取相关中医命名实体,但如何对这些实体的上下文信息进行充分获取又亟待解决。刘耀等提出,可以由医学网站定期、批量提取相关知识并建立索引[30]。文章借鉴这个思路,收集“中醫笈成”网站收录的843部中医典籍文本作为本次实验中《素问》涉及中医学术语的上下文知识补充。
在《素问》中医命名实体词向量的补充表达上,文章选择词向量生成模型Word2Vec作为解决方案。Word2Vec是谷歌公司提出的一种将词汇表达为数值向量的工具技术,以词汇作为特征并将其映射至K维向量空间,进而为文本词汇获取更深层次的上下文特征表达[31]。Word2Vec模型主要有CBOW和Skip-Gram这两种算法。CBOW算法是给定上下文预测当前词的词向量,Skip-Gram 算法是给定当前词预测上下文词向量;CBOW算法的训练速度更快且对频次较高的词汇表征较好,Skip-Gram算法则对稀有词汇和短语表征较好,因而本文选用Skip-Gram算法。王名扬等引入Word2Vec模型实现情感词及其所在微博语句的向量化表达,进而提升文本情感分类结果[32]。文章借鉴了这个思路,将《黄帝内经大词典》内收录与《素问》相关的中医命名实体作为研究对象,通过Word2Vec获取其上下文的词向量表达。这部分词向量以FLAT格子结构补充进从《四库全书》训练而来的BERT模型中。
在计算Word2Vec词向量之前,对从“中醫笈成”中采集的中医典籍文本进行数据清洗和分词。具体步骤为:(1)分词前预处理,去除文献txt文本中的异常字符和开头题录信息;(2)以《黄帝内经大词典》作为自定义词典,使用HanLP对中医典籍文本进行分词,并使用自定义词典进行最大匹配词汇切分以优化分词结果[33]。本文运用Word2Vec处理词向量过程中的相关参数见表5。
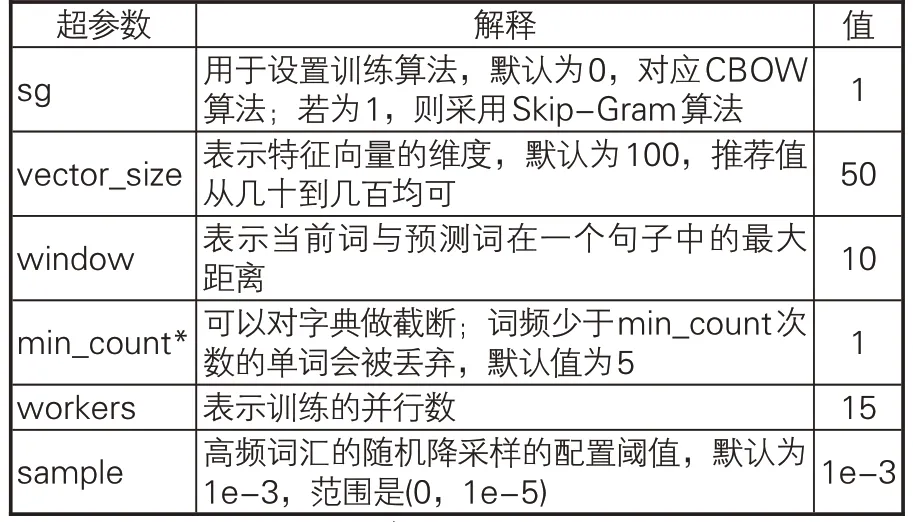
表5 Word2Vec词向量生成参数设置
3 实验环境及结果
3.1 实验环境及模型参数
本实验中,操作系统为CentOS 3.10.0;硬件配置为:CPU,Intel(R) Xeon(R) CPU E5-2650v4@2.20GHz,总核心数48;内存256GB;GPU,NVIDIA Tesla P40(6块)。在实验过程中,对于选用的4 种古文繁体BERT 预训练模型(BERT-base、 RoBERTa、 SikuBERT、 Siku-RoBERTa),文章选取了相同的结构进行训练,训练模型的超参数见表6。
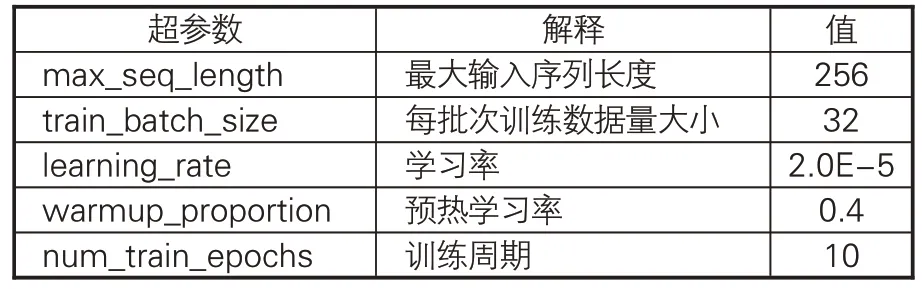
表6 实验的主要超参数设置
在Flat-lattice Transformer 的词向量训练中,相关参数的最优设置如表7所示。需要说明的是,用于观测F1值变化的数据集与4种古文繁体BERT预训练模型使用的数据集相同。表7中的部分测试指标说明如下:(1)当epochs设置较小时,直至运行结束,模型尚未完全收敛,F1 值仍然在波动中上升。经过不断尝试将epochs 分别设置为10、20、50、70,发现当模型训练至50-60轮左右时,F1值基本保持稳定,因而epochs参数选择为70;(2)batch_size越大,训练速度越快。本实验对比了batch_size为4、8、16时模型的效果,发现batch_size为4时,模型训练速度较慢;batch_size为16时,模型性能出现了可见的下降,而运行速度并未显著提升,因而batch_size最终取值为8;(3)实验对比learning_rate 学习率分别为2e-5、5e-5、6e-4 的情况,结果表明学习率为2e-5、5e-5时,训练50轮结果不及6e-4训练10轮结果,且50轮后F1值仍处于缓慢上升,因而学习率选择默认为6e-4。
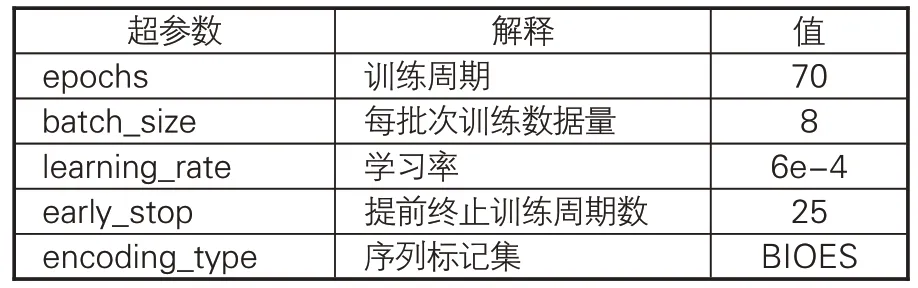
表7 本实验Flat-lattice模型最优超参数设置
3.2 实验评价指标及结果
实验以分词、命名实体标注后的《素问》为语料来源,选用交叉验证的方式考查多种中文繁体BERT预训练模型及Flat-lattice结构对中医命名实体自动标注的效果。
3.2.1 实验评价指标
文章采用命名实体识别的3个常见指标作为评价模型性能的标准:准确率P(Precision)、召回率 R(Recall)、调和平均数 F1 值(F1-score)。在实体标注结果中,会出现4种标注情况:实体数据标记为实体(正确标注,True Positive)、实体数据未能标记(错误标注,True Negative)、非实体数据标记为实体(错误标注,False Positive)及非实体数据未标记为实体(正确标注,False Negative)。相关实体识别结果说明见表8,而P、R、F1值计算公式如下:
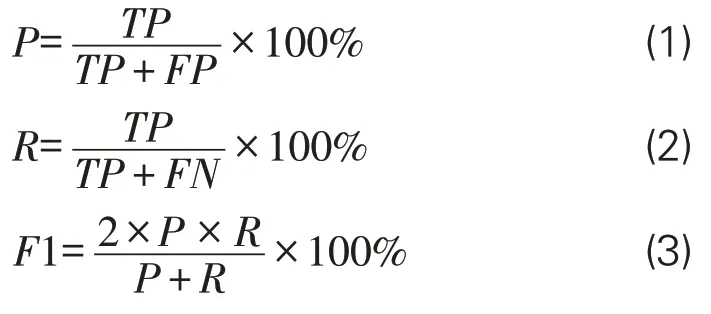
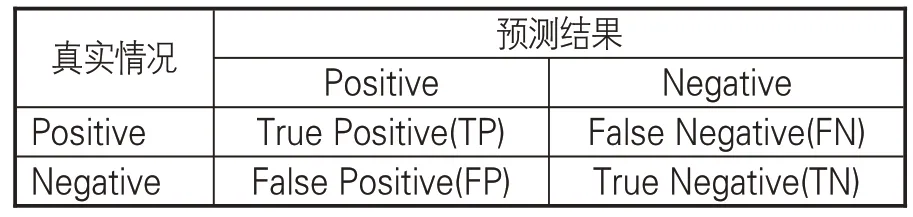
表8 实体识别结果混淆矩阵表
3.2.2 基于原始BERT预训练模型的《素问》命名实体识别
文章首先考查现有4种古文繁体BERT预训练模型在《素问》命名实体标注语料上的识别效果。在处理数据时,将实验在有标点、无标点两种情况下分别展开,具体结果如表9所示。
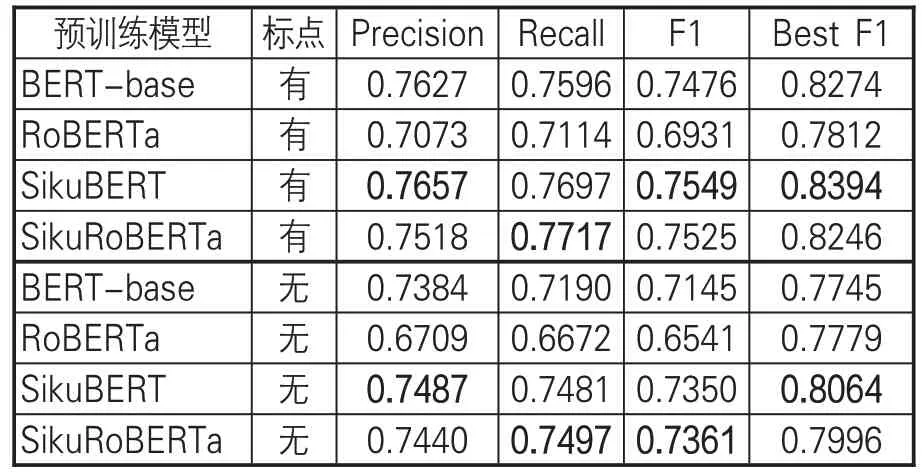
表9 4种原始BERT预训练模型的《素问》命名实体识别效果
直接使用4 种古文繁体BERT 预训练模型,考察多轮实验结果可知:(1)有标点训练和无标点训练下,有标点训练平均F1值为73.70%,无标点训练平均F1值为70.99%,有标点训练效果优于无标点训练,其中平均F1值高2.71%,最佳F1 值(Best F1)高3.3%;(2)在有标点实验中,SikuBERT预训练模型实验效果最好,在P、F1和最佳F1值上结果最佳,SikuRoBERTa预训练模型的R 值最高,而BERT-base 取得与SikuRoBERTa接近的训练效果;(3)在无标点实验中,SikuBERT 预训练模型在P 和最佳F1 值上效果最好,而SikuRoBERTa 在R、F1 值上效果最好,BERT-base 略低于SikuBERT、SikuRoBERTa 模型。从有无标点的训练结果来看,有标点的训练文本可以通过句读完成对文本句子、段落的自动分隔,从而有利于训练模型捕捉句子的自然分隔,但无标点训练集更接近中医古籍本身实际情况。综上可知,4种古文繁体BERT预训练模型对《素问》中医命名实体自动标注效果的F1值介于65%~75%,SikuBERT、SikuRoBERTa 在有标点和无标点情况下,均能取得更好的实验效果,实验效果整体优于基准BERT-base模型。因而,后续FLAT+BERT 实验只在SikuBERT、SikuRoBERTa上展开。
从训练的不同类型命名实体的识别结果来看,“脉学、经络、人名、穴位”效果最好,“病证”次之,“五行、运气”由于样本稀疏识别效果高低不定,“病理”名词识别效果也不佳。在标记序列中,由于BERT预训练模型本身不包括对标记集序列的约束,因而在结果中会出现IOE、BIO 这样的错误序列。正常结果应该由B 开头、E 结束,中间可以包含I。在相关的研究中,有学者通过BERT+CRF[34]或BERT+BiLSTM+CRF[35]来保证标注序列的合理性。考虑到中医术语命名实体的领域特殊性,为了保证相关命名实体在分词阶段不产生错误以影响识别效果,文章选择了Flat-lattice Transformer结构作为标记序列的约束,从而保证相关中医命名实体不被切分。
3.2.3 基于FLAT+BERT预训练模型的《素问》命名实体识别
Flat-lattice Transformer(FLAT)结构通过对命名实体词汇进行头尾位置标记(Head、Tail)实现由BIESO标记集的序列转换。同时,Transformer自注意力机制可以保证字符与任意潜在词汇进行交互,包括自匹配单词。在FLAT结构下,可以保证领域术语以整体形式作为词向量,参与BERT预训练模型的Mask训练,而不会产生有些命名实体的部分字符被遮掩(Masked)的情形,即FLAT 结构可以保证术语作为整体参与Mask训练。在《黄帝内经大词典》基础上,文章以“中醫笈成”为上下文语境,获取《黄帝内经》术语命名实体的Word2Vec 词向量,作为SikuBERT、SikuRoBERTa 预训练模型的中医领域知识补充。在有标点训练和无标点训练下,相关FLAT+BERT 预训练模型的实验效果如表10 所示。
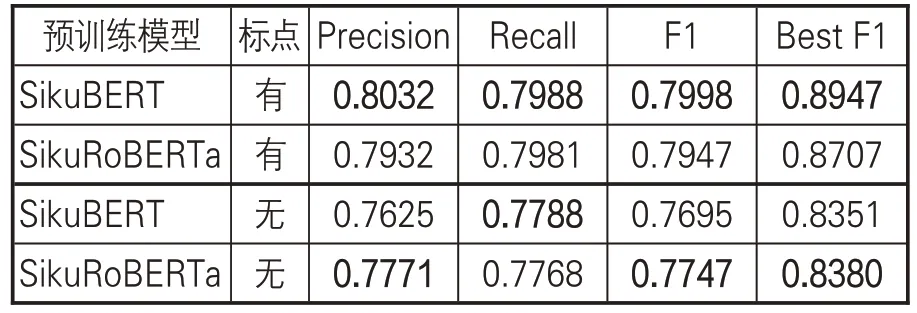
表10 FLAT+BERT预训练模型的《素问》命名实体识别效果
考察表10中的数据,并对比表9相关模型的训练结果可知:在FLAT 增强实验环境下,对《素问》中医术语命名实体的领域知识词向量做补充,有助于SikuBERT、SikuRoBERTa取得更好的实验效果。其中,在有标点和无标点情况下,P、R、F1及最佳F1值均有不小提升;在有标点训练中,FLAT+SikuBERT模型在各指标上均略优于FLAT+SikuRoBERTa,比SikuBERT、SikuRoBERTa初始实验提升了4%左右;在无标点训练中,FLAT+SikuRoBERTa 除R值外其他指 标 均 优 于 FLAT + SikuBERT 模 型 , 比SikuBERT、SikuRoBERTa初始实验约提升2%-3%。这个结果表明,有句读的古籍训练模型由于有标点的自然分隔,在捕捉上下文信息上,句读可以作为重要参考特征。但对于中国古代医学文献来说,除了《黄帝内经》《伤寒论》《难经》《金匮要略》等重要典籍已经过句读标注外,仍有很大一部分古籍(尤其是善本)以无标点的文本形式存在。在这种情况下,无标点的训练模型具有重要的实际使用价值。
4 结论与未来研究
文章以4种古文繁体BERT预训练模型为基础,验证了BERT预训练模型在古代中医文献命名实体识别中的效果,结果显示:SikuBERT及SikuRoBERTa 能够直接取得更好的结果。进一步实验结果表明,在古代中国医学领域,相关BERT古文模型在添加中医领域词向量表达后能取得较理想的实验效果。在现有中国古文繁体BERT 预训练模型基础上,FLAT+SikuBERT 及FLAT+SikuRoBERTa 两个“预训练+微调+词向量”增强模型的效果优于初始SikuBERT、SikuRoBERTa 模型,且能保证中医术语命名实体的完整性。本文探索了数字人文下我国古代医学领域文献的“预训练+微调”模式适用性,为深度挖掘古代中医药知识提供了新的思路与方法。
未来的研究主要关注两个方面。第一,对于中医学领域知识的术语实体表达应从多个层面进一步展开。本研究主要以单字术语、词汇级术语为研究对象,而中医药术语中还包括短语结构及句子级命名实体,这部分命名实体的中医学知识表达并未在词典中得到充分体现。第二,《黄帝内经》是古代中医文献的源头,《素问》更是完整、体系化地呈现了中医理论,在此基础上后世中医学家不断丰富并完善中医理论体系。因此,下一步研究将在现有语料基础上完成对更多中医理论典籍的标注,为古代中医文献这一特色领域资源积累训练语料。
