基于自然驾驶场景大数据的驾驶风格研究
2022-09-22刘迪郑建明覃斌张宇飞张建军
刘迪 郑建明 覃斌 张宇飞 张建军
(1.中国第一汽车股份有限公司 研发总院,长春 130013;2.汽车振动噪声与安全控制综合技术国家重点实验室,长春 130013)
主题词:驾驶风格辨识 大数据 主成分分析 高斯混合模型 随机森林
1 前言
作为驾驶员长期驾驶方式的综合评价指标,驾驶风格标签的确定成为汽车智能算法实现个性化的先决条件。
在驾驶风格识别领域,国内外学者开展了大量研究。在数据采集方面,一般采取填写主观问卷、在驾驶模拟器上模拟驾驶、在自然公开道路上驾驶等方式。主观评价严重依赖历史结果,驾驶模拟虽然简单快速且不受天气约束,但是难以预测并复现全部自然驾驶场景。
由于数据来源广泛,许多学者对场景进行了切片,开展了更为细致的分析。在评价指标选取方面,文献[5]考虑了车流密度的影响,文献[6]对分时租赁展开了研究,文献[7]以营运车辆的驾驶速度为评价指标进行聚类。在数据处理方面:Constantinescu 等应用主成分分析、信度和效度检验相结合的方法提取驾驶标签并进行分类;M.Gys 认为诸如无监督式学习、循环神经网络、支持向量机(Support Vector Machine,SVM)等人工智能算法具有更好的分类效果;文献[10]设计了一套基于标准化驾驶表现和像空间重构的定性评估方法;文献[11]构建多棵决策树,引入随机模型建立了辨识策略;苏琛应用最大期望算法进行模型训练,提出识别准确率和置信度的概念,计算了基于纵向激励驾驶识别模型的最优参数。
然而,已有研究往往依赖主客观对标的方法,难以获得统一的样本标签和聚类标准,且评价指标维度很高,模型复杂,同时,聚类结果较为刚性,难以识别边缘数据。为了全方位分析大数据信息,获取更为柔性的聚类结果,建立准确有效的聚类器,本文搭建自然驾驶场景数据采集平台,进行数据清洗和行列筛选,采取主成分分析和因子旋转的方法实现评价指标降维,分析驾驶员的自然驾驶工况和超速及极端工况数据,分别建立聚类模型和辨识模型用于聚类多名驾驶员风格和辨识新样本。利用无监督学习方法,训练基于K-均值聚类结果的高斯混合模型,通过迭代的方法寻找模型最佳参数,获得聚类结果。最后利用监督学习方法,训练随机森林模型并交叉验证其有效性,实现驾驶风格辨识。
2 自然驾驶场景数据采集平台及数据提取方法
本文选取某车型作为场景采集车,将GPS和惯性测量单元(Inertial Measurement Unit,IMU)组合成惯性导航系统,用来获取时间信息、本车状态和本车定位信息;搭载高清摄像头、感知摄像头、激光雷达、毫米波雷达获取视频数据、点云数据、目标种类及相对位置,如图1所示。同时,以实时经纬度坐标作为输入,匹配开源地图数据库(Open Street Map,OSM),获取实时道路类型信息。
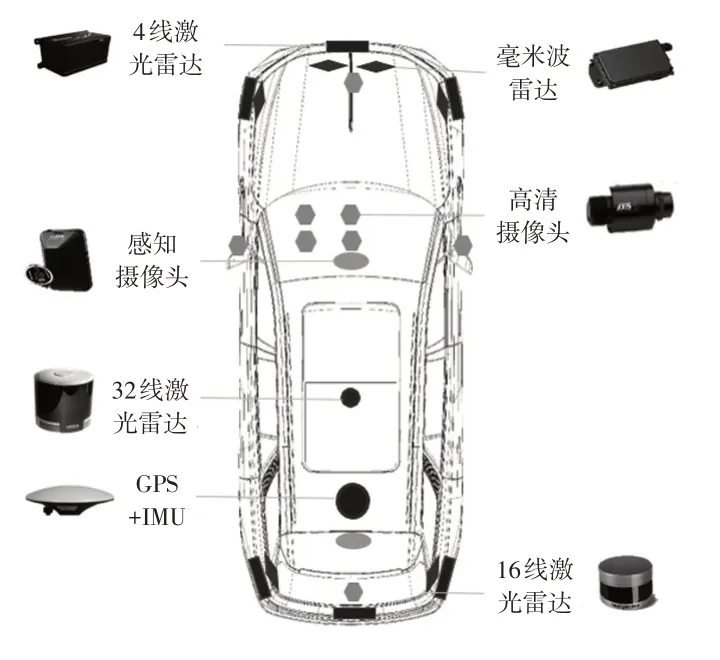
图1 传感器的分布情况
基于该采集平台,选择33 名驾驶员在全国开放道路上行驶并完成数据采集。数据采集耗时6个月,总里程5×10km,长时间的驾驶数据几乎能覆盖驾驶员在各种情况下的行为表现,具有很强的代表意义。采集过程中,可通过CAN总线和传感器获取80余类信号,数据采集结果可转化为“4 亿行×80 余列”的大型矩阵,供有效数据提取。
2.1 筛选数据行
为了激发驾驶员的差异化表现,并清洗数据,建立如下数据提取规则:
a.速度区间为30~120 km/h,避免低速情况下城市道路频繁起停、倒车的场景;
b.提取本车正前方有目标车的场景,且碰撞时间(Time to Collision,TTC)在(0,10)s范围内;
c.提取道路类型包括城市(主要道路、次要道路、居住区)、快速路(高架、机场进站、过江隧道、桥上)、高速公路。
2.2 筛选数据列
从原始数据的80余个字段中初选与驾驶风格有关的10个评价指标,包括3类信息:
a.本车状态:速度、加速度、超速比例;
b.驾驶员输入:制动踏板激活状态、节气门开度、最大节气门开度;
c.与前车相对关系:相对速度、最大相对速度、相对距离(前车车尾与本车车头的距离)、碰撞时间。
和产生的条件较为苛刻,且距离大部分样本较远,即使同一驾驶员也很难复现,缺少代表性。本文选择第90 分位点作为最大值,以剔除明显不符合实际情况的或发生次数过少的样本。
设城市道路、快速路、高速公路限速分别为70 km/h、80 km/h、120 km/h,超速比例表示车速超过当前道路限速90%所持续的时长占总驾驶时长的比例:
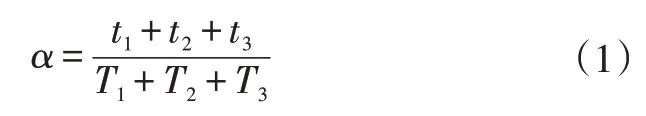
式中,、、分别为城市道路、快速路、高速公路上的超速时长;、、分别为城市道路、快速路、高速公路上的总时长。
此步骤输出“千万行×10列”的矩阵。
2.3 以速度为区段的分布式聚合方法
以每10 km/h 为一个区段,将30~120 km/h 分为9段。在每段区间内,取各评价指标的众数,即出现次数最多的值,再将9 组数据加权平均,得到单驾驶员有效数据:

式中,C、d分别为每段区间的计数和众数。
重复此步骤33 次,得到33 名驾驶员的有效数据矩阵。
以30~40 km/h为例,绘制、、、、分布情况(作为示例,此时未区分驾驶员),如图2所示。
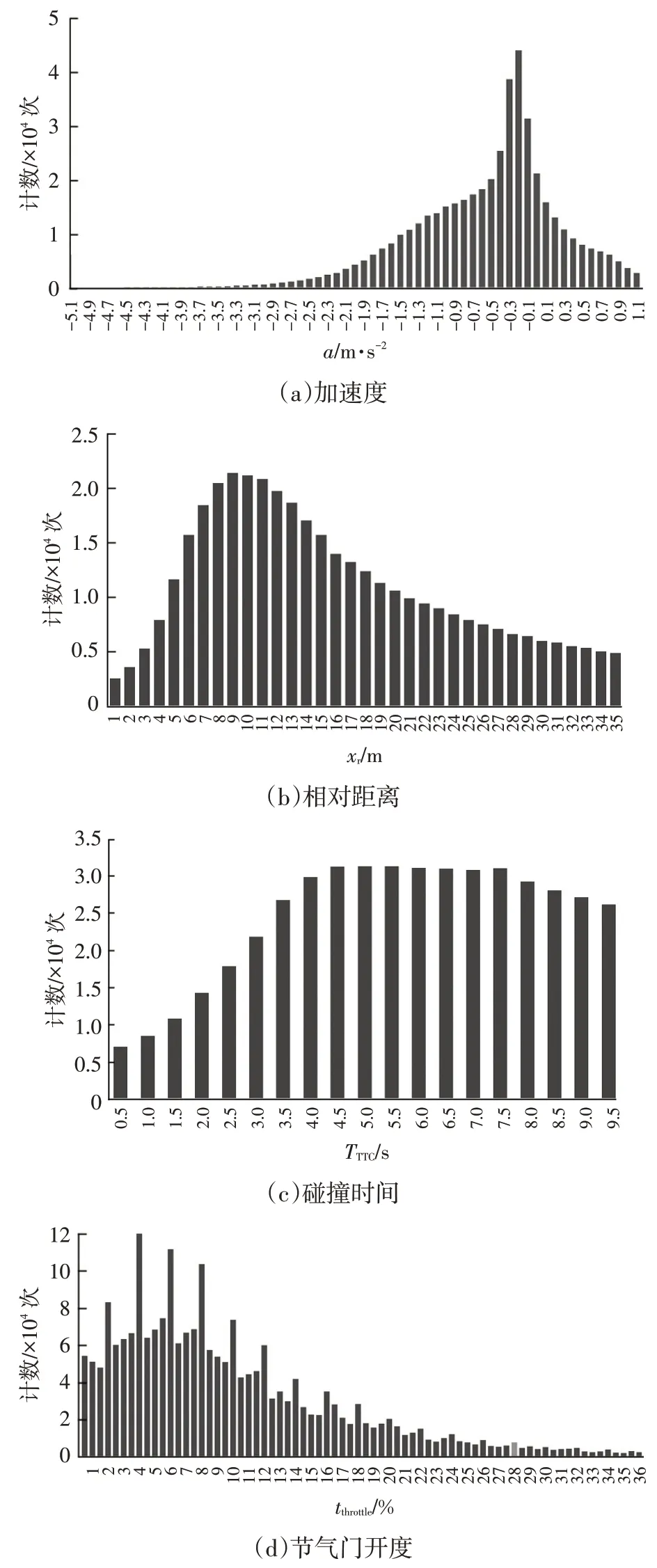
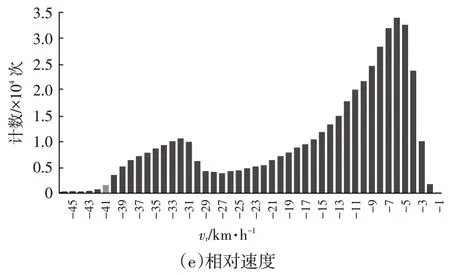
图2 30 km/h≤v<40 km/h车速范围内各参数分布情况
此步骤输出“33行×10列”的矩阵。
2.4 评价指标降维和标准化
矩阵仍包含10 个列字段。数据集不带标签,且存在线性结构,故采用主成分分析(Principal Compo⁃nent Analysis,PCA)方法降维。PCA 能降低数据空间的维度,识别最重要的指标,保证信息损失最小化,解决多重共线问题,防止过拟合,并加快算法迭代速度。
主成分的计算原理为:
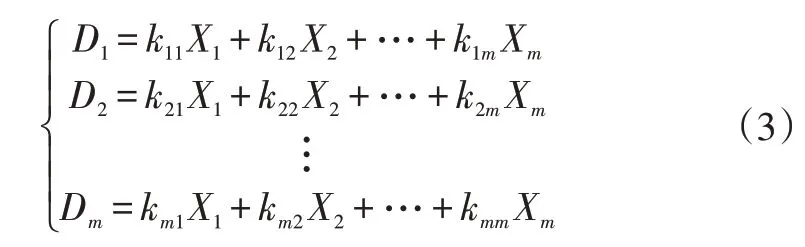
式中,D为第个主成分;X为第个原始数据;=1,2,…,;k为权重系数。
任意2 个主成分的协方差为零,方向正交,相互独立。
经分析,该样本的主成分分析效度检验指标KMO为0.718>0.6,Bartlett 检验对应值=0,比较适合进行主成分分析。表1所示为主成分提取情况。前3个主成分的特征根值均大于1,且累积方差解释率为78.856%。一般认为累计解释率达70%~80%即为有效,因此取3个主成分代表全部主成分。
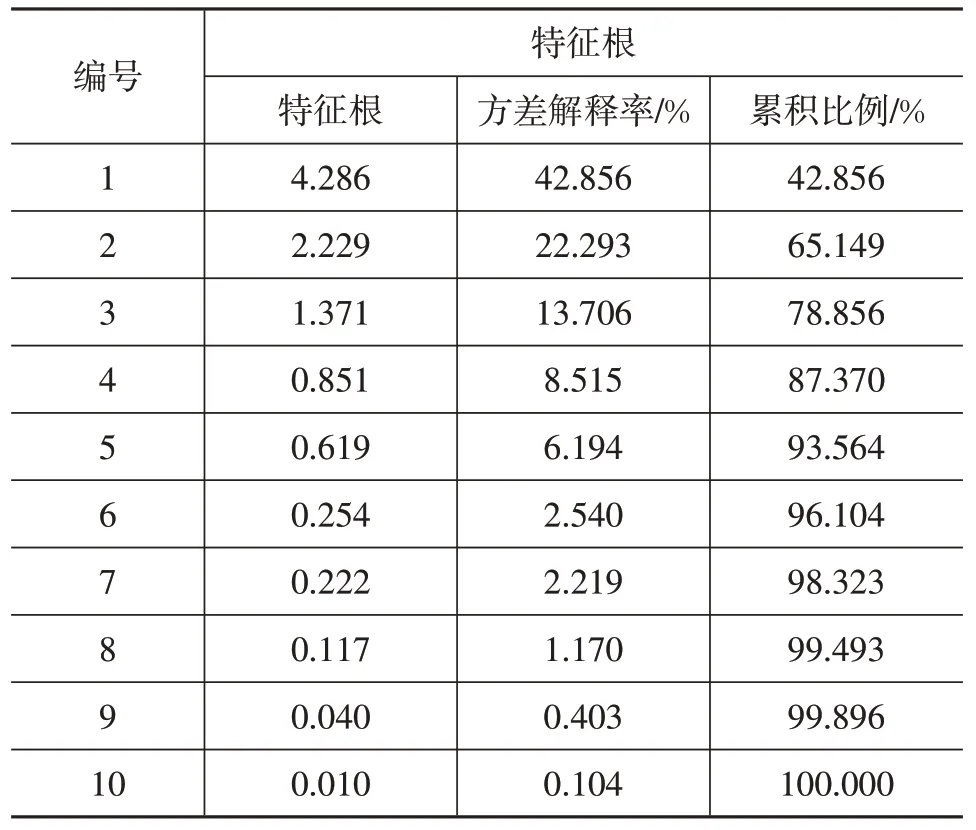
表1 主成分特征根矩阵
因子旋转可使载荷矩阵值向0 或1 靠近,使每个因子具有较高或较低的载荷。因此旋转因子能代表的驾驶行为信息比主成分更为明确,本文采用最大方差旋转法。
主成分分析和因子旋转后的载荷矩阵如表2 所示。如果载荷系数绝对值大于0.4,则说明该项与主成分有对应关系,且载荷系数越大,相关性越强。
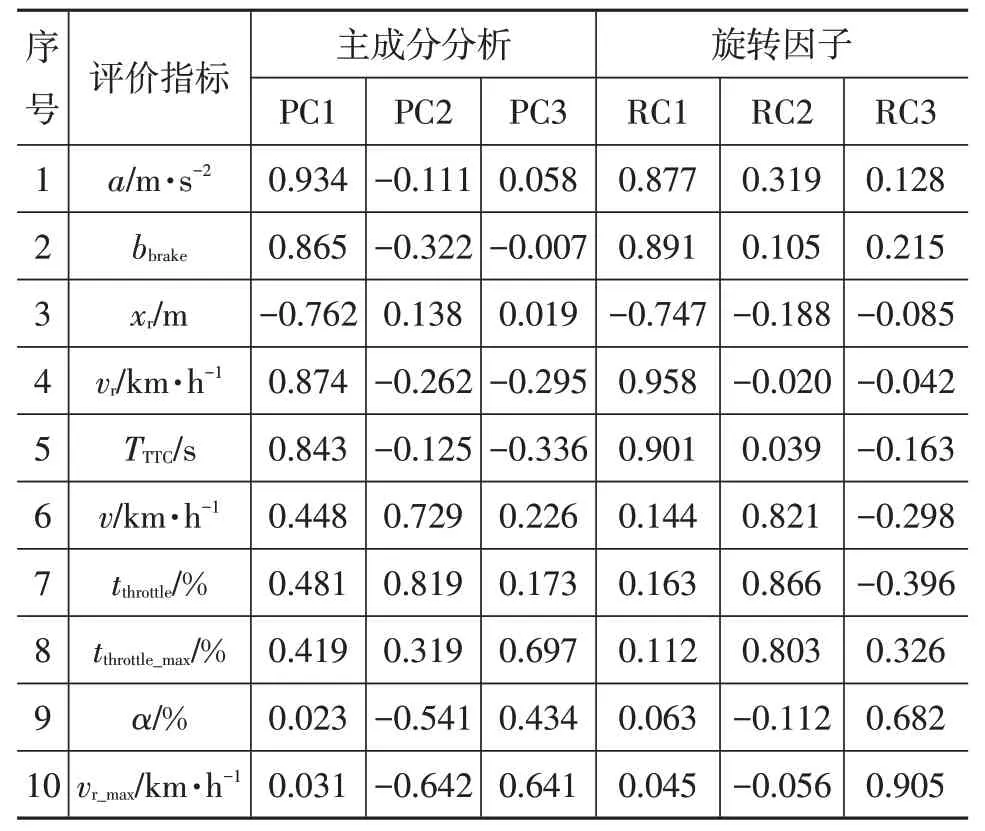
表2 载荷系数表格
主成分PC1、PC2、PC3 能代表78.856%的原始数据。旋转因子RC1 多与车辆自然状态的平均值有关,RC2 代表驾驶过程最基本属性(速度和节气门开度),RC3与发生超速及碰撞等极端工况有关。因此,以RC1和RC2为研究对象分析驾驶员在自然工况下的驾驶风格,以RC2 和RC3 为研究对象分析驾驶员超速并接近前车的倾向。
此步骤输出“33 行×3 列”的矩阵。将其标准化,得到旋转矩阵的成分得分,应用其进行聚类。
3 无监督学习聚类
数据集不带标签,因此本次聚类属于典型的无监督学习。为提高准确度,本文综合K-均值和基于K-均值结果的高斯混合模型作为最终聚类结果。
3.1 K-均值聚类
K-均值聚类具有方便快捷、鲁棒性佳、适应性好的优点。对于给定数据集=[…],K-均值聚类首先确定聚类数量,然后随机选取聚类中心δ=(=1,2,…,),最后通过迭代计算使x与其最近的δ的欧氏距离之和最小:

本文将驾驶风格分为3 类,因此取=3。代表了聚类结果的紧密程度,结果越小,聚合效果越好。
然而,K-均值聚类结果只有“是”或“否”,仅根据到簇中心点的距离划分数据,聚类结果没有边界值。如果数据维度较低,操作者可以观察边缘数据,但如果数据维度较高,则无法可视化,强行聚类可能得不到预期结果。因此,以K-均值聚类结果为基础,构建高斯混合模型(Gaussian Mixture Modeling,GMM)。
3.2 基于K-均值结果的高斯混合模型聚类
GMM 的本质是密度估计算法,它的拟合结果是描述数据分布的概率模型。GMM由多个单高斯模型组合而成,输出结果是样本占据某一聚类的概率。正如均值和方差能确定单高斯模型,均值向量和协方差矩阵能确定高维度的GMM,它的概率分布可表示为:
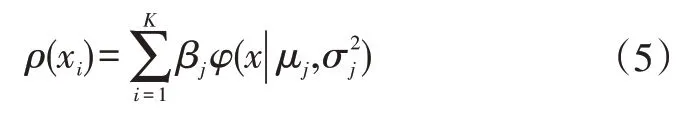

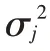
然而,GMM仅提供概率,如某个样本所属单高斯分布的概率接近,或者与K-均值聚类结果不统一,说明该样本处于簇边缘。对于此类样本,应采取主客观结合的方式进一步处理。
正因如此,在本文中GMM 不能用于辨识新的未知驾驶员的驾驶风格,其意义在于识别边缘数据。
3.3 2种聚类结果对比
3.3.1 自然驾驶工况
选取旋转因子RC1 和RC2 为研究对象,因此能可视化表达二维聚类结果,如图3~图5所示。
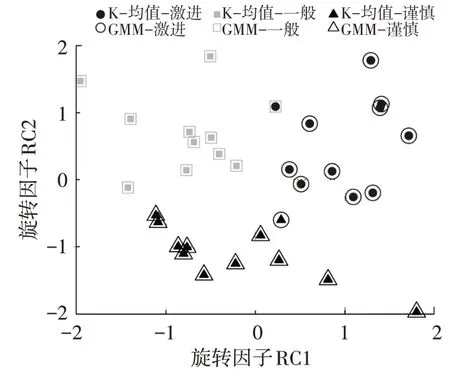
图3 自然工况中K-均值和高斯混合聚类结果比对
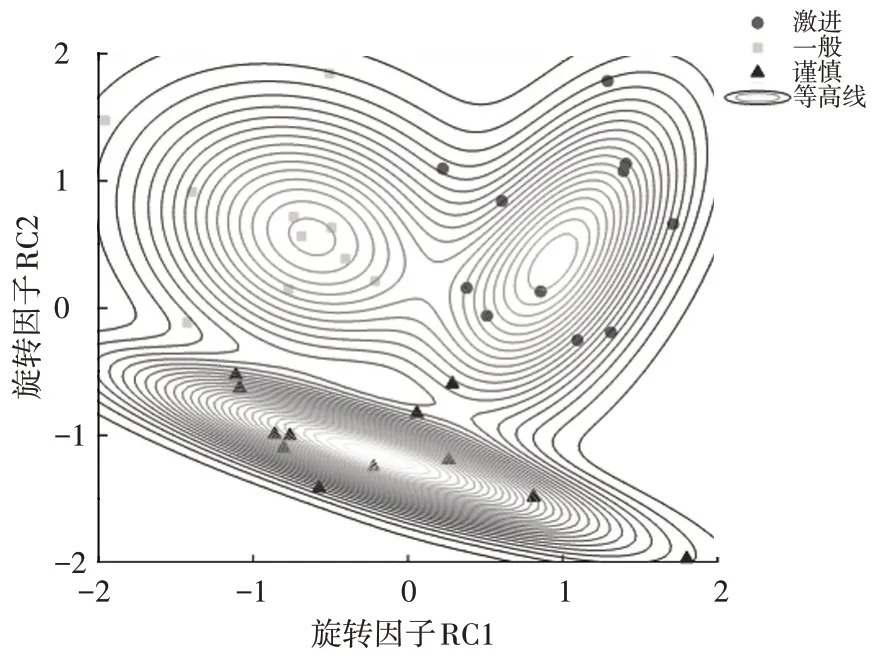
图4 自然工况中高斯模型等高线
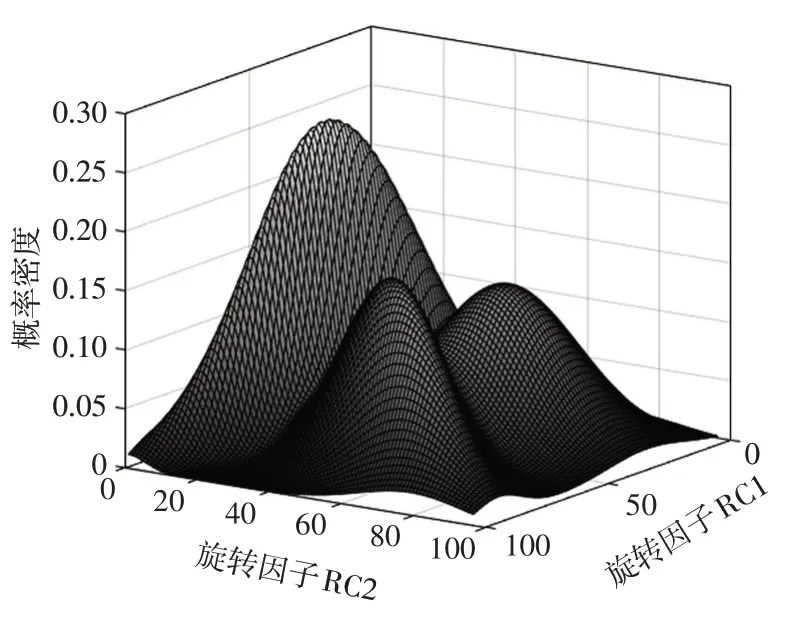
图5 自然工况中高斯模型曲面
由图3可以看出,2种方法的聚类结果大致相同,仅有2 个样本标签出现了偏差。由图4 可知,3 种标签等高线迭代结果与样本数据相符,数据均匀地分布在等高线周围。2 个出现偏差的样本恰好都在2 类等高线边缘,而且概率相差不大。如果可获取更多已知数据外的信息,则完全可以综合考虑聚类结果,GMM 仅提供参考。图5 在三维坐标系中直观地刻画了概率密度分布情况。
表3 所示为混淆矩阵,可以看出高斯模型将1 个谨慎型数据分类为激进型,将1个激进型数据分类为一般型,与上述定性分析结果一致。表4所示为33名驾驶员最终聚类结果。
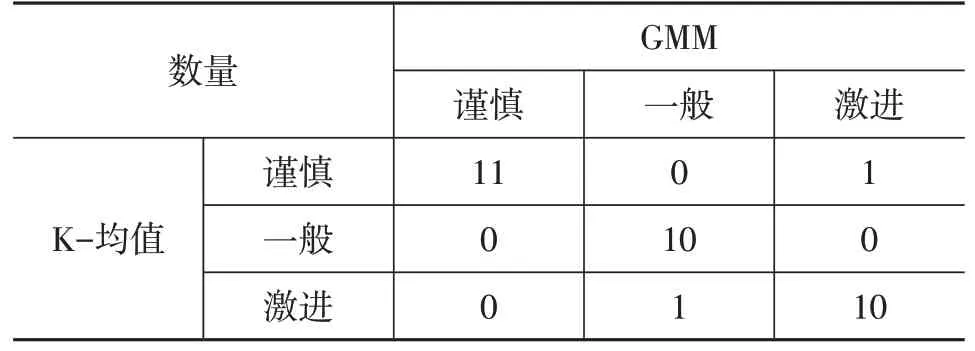
表3 2种聚类方法的混淆矩阵
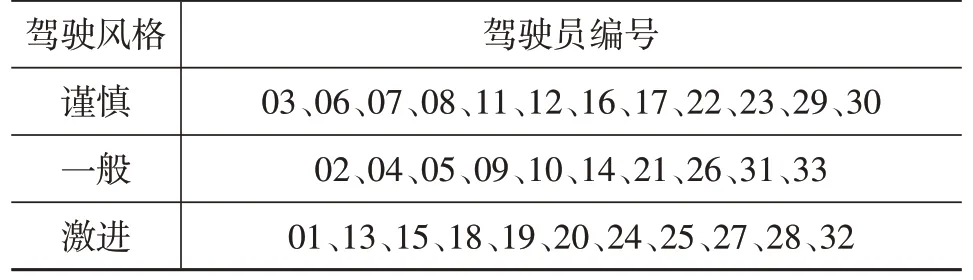
表4 驾驶员聚类结果
3.3.2 超速及极端工况
与3.3.1 节研究方法类似,选取旋转因子RC2 和RC3 为研究对象,依次绘制K-均值和高斯混合聚类结果比对图、高斯模型等高线图、高斯模型曲面图,如图6~图8所示。
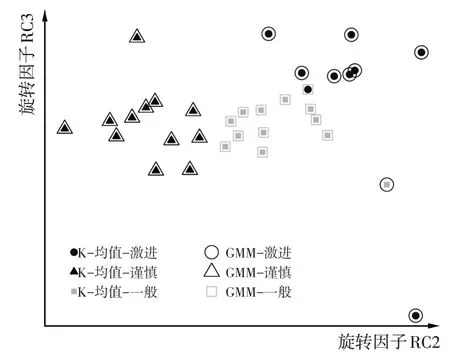
图6 极端工况K-均值和高斯混合聚类结果比对
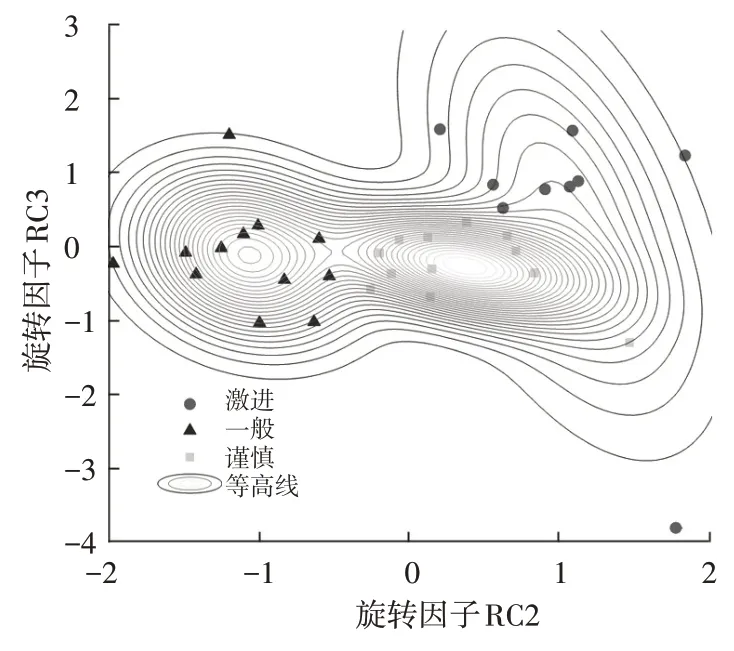
图7 极端工况高斯模型等高线
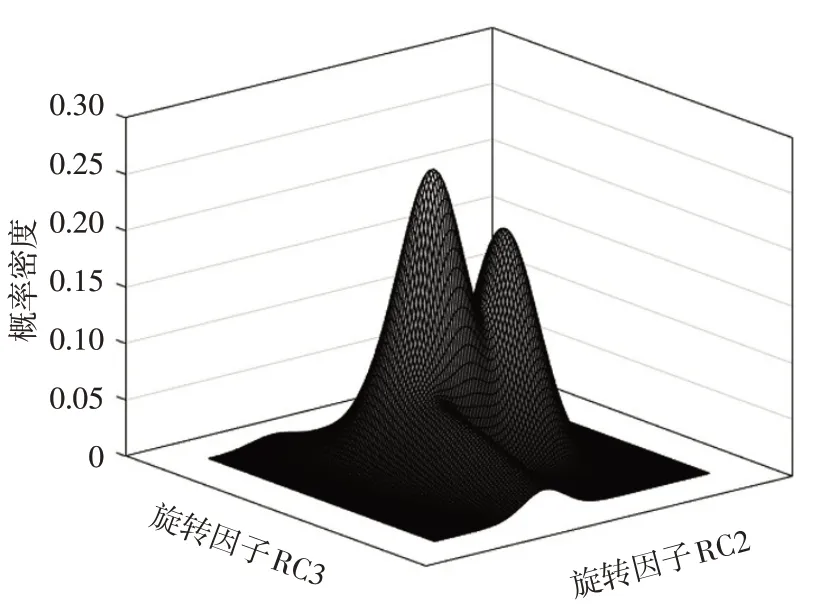
图8 极端工况高斯模型曲面
由图6~图8可知,一般型和激进型的概率密度产生了部分重叠。激进型由于有极端值存在,导致方差较大,概率密度三维图较为平缓。与3.3.1 节中的聚类结果类似,也有2个样本标签出现了偏差。最终聚类结果如表5所示。
表5 驾驶员标签集
3.3.3 样本集聚类结果
比较3.3.1和3.3.2节聚类结果,汇总至表6。有64%的驾驶员风格不变,36%的驾驶员在一般和激进间跳变。谨慎型驾驶员群体特别稳定,从未发生变化,说明谨慎型驾驶员始终表现保守,与其他2种表现行为差异明显。一般型和激进型之间存在差异,但无明显阈值,部分驾驶员在遇到危险时,会因个体原因发生风格的变化。

表6 2种工况下驾驶员标签综合分析
4 利用监督学习实现辨识
聚类结果包含数据和标签信息,因此可利用监督学习构建机器学习模型,辨识未知驾驶员的驾驶风格。本文拟采用随机森林模型作为分类器实现此功能。
每棵树的训练特征集合是从全部特征中抽取的,因此适合处理高维数据。特征较少的样本随机性降低,可能得不到最佳辨识结果。同时,随机森林能检测特征间的作用,解决共线问题。因此在训练模型时,样本集为矩阵及对应标签。
4.1 训练随机森林模型
随机森林是升级版决策树,每棵树对训练样本进行投票,最后取最高票对应的标签作为分类结果。图9所示为随机森林模型建立过程。
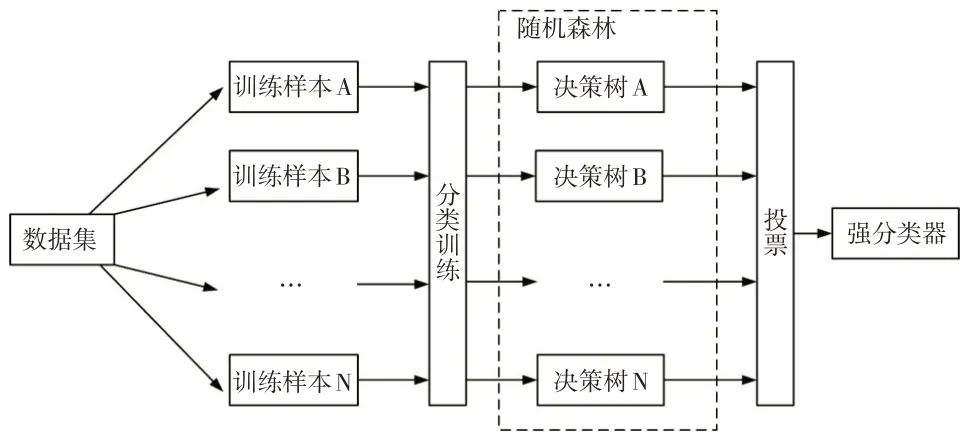
图9 随机森林模型建立过程
具体实现流程如下:
a.随机抽样,训练决策树。有放回地随机抽取多个样本(即可存在重复样本),形成样本数据集1;
b.随机选取属性作为节点分类属性。假设训练样本集包含个属性,随机在每个分裂节点处选择个属性,并且<,节点分裂属性不可重复;
c.重复步骤b,直到不能再分裂为止;
d.重复步骤a~步骤c,建立多棵决策树,形成森林。
4.2 交叉验证随机森林模型
采用留一法评估随机森林模型的有效性。将33名驾驶员样本组成的测试集划分为训练集和验证集,训练集包含32份样本,验证集包含1份样本。更换不同的验证集,进行33次交叉验证,得到组验证结果。比对聚类结果和辨识结果,分别计算3 种标签的辨识率,进而得出随机森林模型的综合辨识率。原理如图10所示。
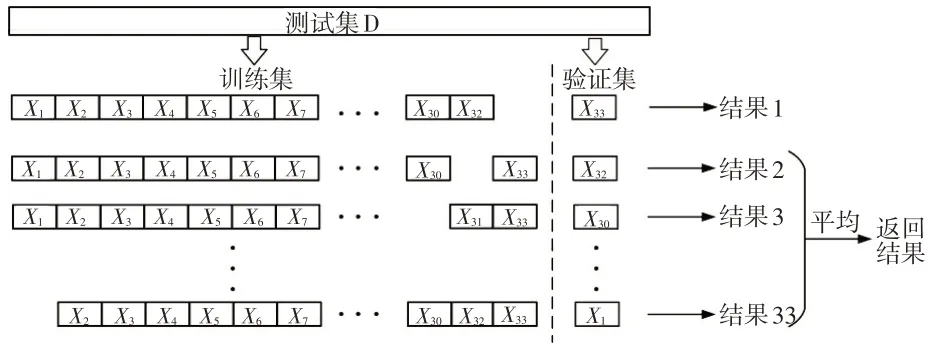
图10 交叉验证法示意
表7、表8所示为2种工况交叉验证结果。经评估,基于随机森林模型的辨识策略能正确识别100%自然工况的驾驶风格标签,正确识别90.9%超速及极端工况的驾驶风格标签。
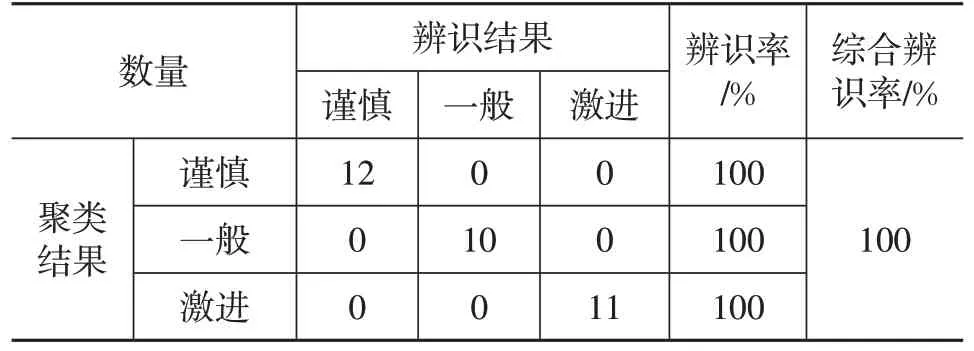
表7 随机森林模型交叉验证结果
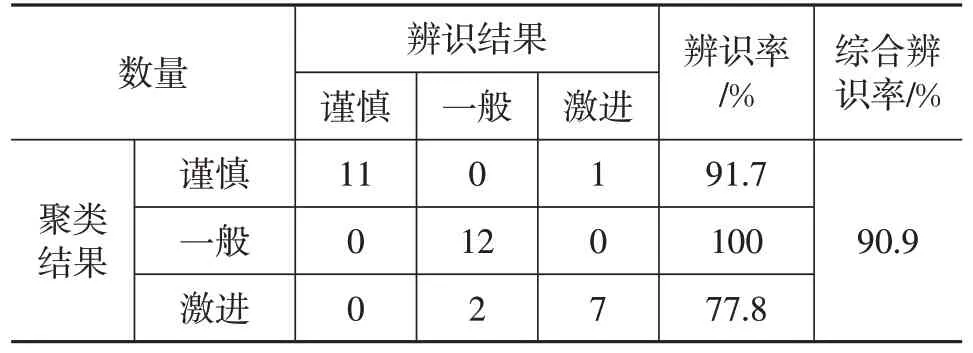
表8 随机森林模型交叉验证结果
5 结束语
本文建立了基于大数据的驾驶风格分类及辨识体系,构建了自然驾驶数据采集平台,选取评价指标并利用主成分分析实现降维,利用无监督学习方法设计K-均值聚类方法,同时训练基于K-均值聚类结果的高斯混合模型,以此获得更为柔性的分类结果。最后训练随机森林模型,用来快速辨识未知驾驶员的风格标签。当数据量不断扩大,对于这些不可预知的工况和风格标签,本文提出的方法仍具有普适性。
在实际驾驶中,不同场景(如起步、加速、减速、跟停)所表现出的风格可能不同,进一步细分场景得到多种标签应作为下一步研究的课题。
