基于深度学习的沥青路面坑槽量化方法
2022-09-14吴海军王武斌张宗堂
余 俊,吴海军,王武斌,张宗堂
(1.成都工业职业技术学院 现代轨道交通应用技术研究中心,四川 成都 610000;2.湖南省交通科学研究院有限公司,湖南 长沙 410015;3.西南交通大学 陆地交通地质灾害防治技术国家工程实验室,四川 成都 610000;4.湖南科技大学 岩土工程稳定控制与健康监测湖南省重点实验室,湖南 湘潭 411201)
1 概述
公路作为一种重要的交通方式,对我国的政治、经济、军事发展有着重大的作用,也对人民生活水平的提高有着重要的意义。但是公路路面具有使用寿命,由于超载、过度使用等外部因素,道路表面易于损坏[1-4]。因此,对路面表面进行评估是有必要的。
传统上,评估通常由经过训练的检查员进行,但该方法具有局限性,因此,SOHN[5]等提出了使用传感器和数据采集技术的方法。使用应变计引伸计[6],加速度计[7]和数值模拟[8]对某些情况下的沥青路面进行识别或损害预测。然而,这些方法成本较高且难以操纵。因此,可以使用计算机视觉传感器进行数据采集。在以往的研究中,研究者使用二维成像和高速视频来确定位移和表面变形等参数,以检测和量化潜在的路面坑槽[9]。
由于坑槽具有视觉独特性,可使用机器学习方法实现二维成像检测并量化潜在路面坑槽。郭慧[10]等实现了一种基于支持向量机的钢板表面缺陷检测方法。 CHA[11]等提出了一种能够有效检测裂纹的卷积神经网络。
由于二维成像的研究已经较为深入,三维分析逐渐得到更多研究者的关注。二维图像可以对裂缝进行检测和分类,而三维数据则可以检测和量化体积损伤,如分层,剥落等。
以往学者研究三维成像的沥青路面状况都采用了运动结构(SfM)方法[12]。其中,三维虚拟模型是通过二维RGB图像与缩放参数和其他属性合并生成的。TOROK[13]等提出了一种基于SfM的数据收集方法,从机器平台收集灾后场景数据,进行三维重建,损伤识别并记录几何数据。
另一种获取三维数据的方法是使用同时包含颜色和深度传感器的特殊相机。JAHANSHAHI[14]等提出了从普通相机中提取三维点云来检测和量化路面坑槽的方法。然而,这些研究都是对已知的病害进行量化。此外,传感器和物体之间的距离是预先测量并固定的,限制了该方法的自动化实现。此外,现有的量化方法无法独立识别剥落或其他类型的体积损伤,而只能提供相对于分析表面的体积损失量。
为了克服上述局限性,本文提出了一种全自动的沥青路面坑槽检测、定位和量化方法,通过廉价的RGB-D传感器,Microsoft Kinect V2和Faster R-CNN来检测路面坑槽。该方法不需要预先设置测量目标和传感器之间的距离,且可以在移动场景下应用。
2 研究方法
本文主要目的是通过使用基于区域的深度卷积网络(R-CNN)和廉价的深度摄像头来自动检测、定位和量化沥青路面坑槽量。该算法分为4个步骤:①基于RGB-D传感器的RGB图像和深度数据收集;②使用基于R-CNN的快速、深入的方法对损坏进行检测和定位,为检测到的损坏添加边界框;③利用添加的边界框和点云信息对元素表面进行分割;④分割和量化从表面检测的损伤。其流程如图1所示。
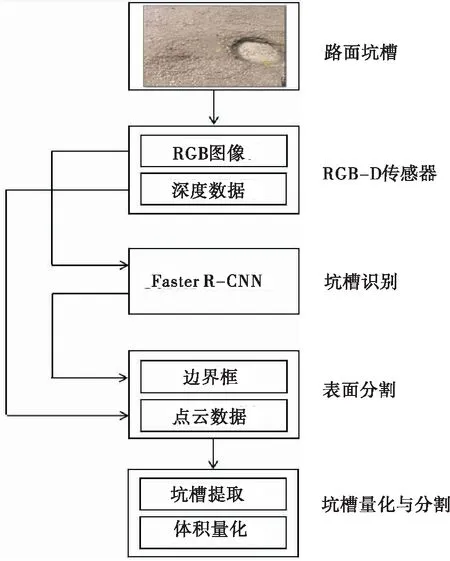
图1 算法框架流程Figure 1 The flow diagram of the algorithm framework
2.1 RGB-D传感器
Microsoft Kinect V2是一种深度相机,其参数如下:RGB摄像头1 920×1 080像素,深度摄像头512×424像素,最大深度距离4.5 m,最小深度距离0.5 m,垂直视场60°,水平视场70°。基于此相机的RGB图像数据和点云数据的分辨率分别为1 920×1 080像素和512×424像素。利用RGB-D相机可以实现飞行时间(ToF)概念。其同时具有红外发射器和红外传感器。红外发射器将红外光投射到对象上,光从表面反弹,红外传感器捕获反射的光。由于红外传感器和红外发射器之间的距离是已知的,可以根据红外光从发射器到传感器传播的时间来确定每个传感器像素的3D坐标。
2.1.1数据点云获取
MATLAB支持Microsoft Kinect V2接口,并可以获取原始深度数据。深度设备输出一个以传感器中心像素作为原点的局部三维坐标点网格。传感器的内部算法会将非数字(NaN)值转换为深度像素(x,y和z)。由此,可以区分每个点的坐标。整体深度框宽512像素,高424像素。
由于镜头失真,深度框边界的值误差率更大。YUAN[15]等提出,可以使用深度传感器的中央300×300像素来避免此问题。此外,从传感器平面到目标的距离应在1.0 m至2.5 m之间,以获得最大的精度。
2.1.2噪声过滤
为了减少深度图像上的噪声,本文采用了可以覆盖5×5像素区域的中值滤波器。中值滤波器将深度图中的每个像素替换为其相邻像素的中值。这保证了去噪深度图中不包含原数据集中不存在的值。
2.2 Faster R-CNN路面坑槽检测
为了检测和定位各种沥青路面坑槽,采用了基于Faster R-CNN的检测方法。该方法仅需使用RGB-D传感器提供的RGB图像数据。为了克服了传统R-CNN和Fast R-CNN在对象检测和定位方面的局限性,REN[16]等提出了Faster R-CNN。传统的CNN不能对图像内检测到的目标添加任何边界框或定位信息,但是R-CNN和Fast R-CNN可以。然而,这2种方法在添加边界框时存在计算效率低和运行时间长的缺点。
与R-CNN相比,Faster R-CNN采用选择性搜索方法,在计算成本和运行时间方面有所提升。但它仍无法对目标进行实时检测和定位。REN等提出了区域候选网络(RPN),以节省定位目标的计算成本。通过共享如图2所示的CNN架构,将RPN集成到现有的Fast RCNN中,可以减少计算成本。
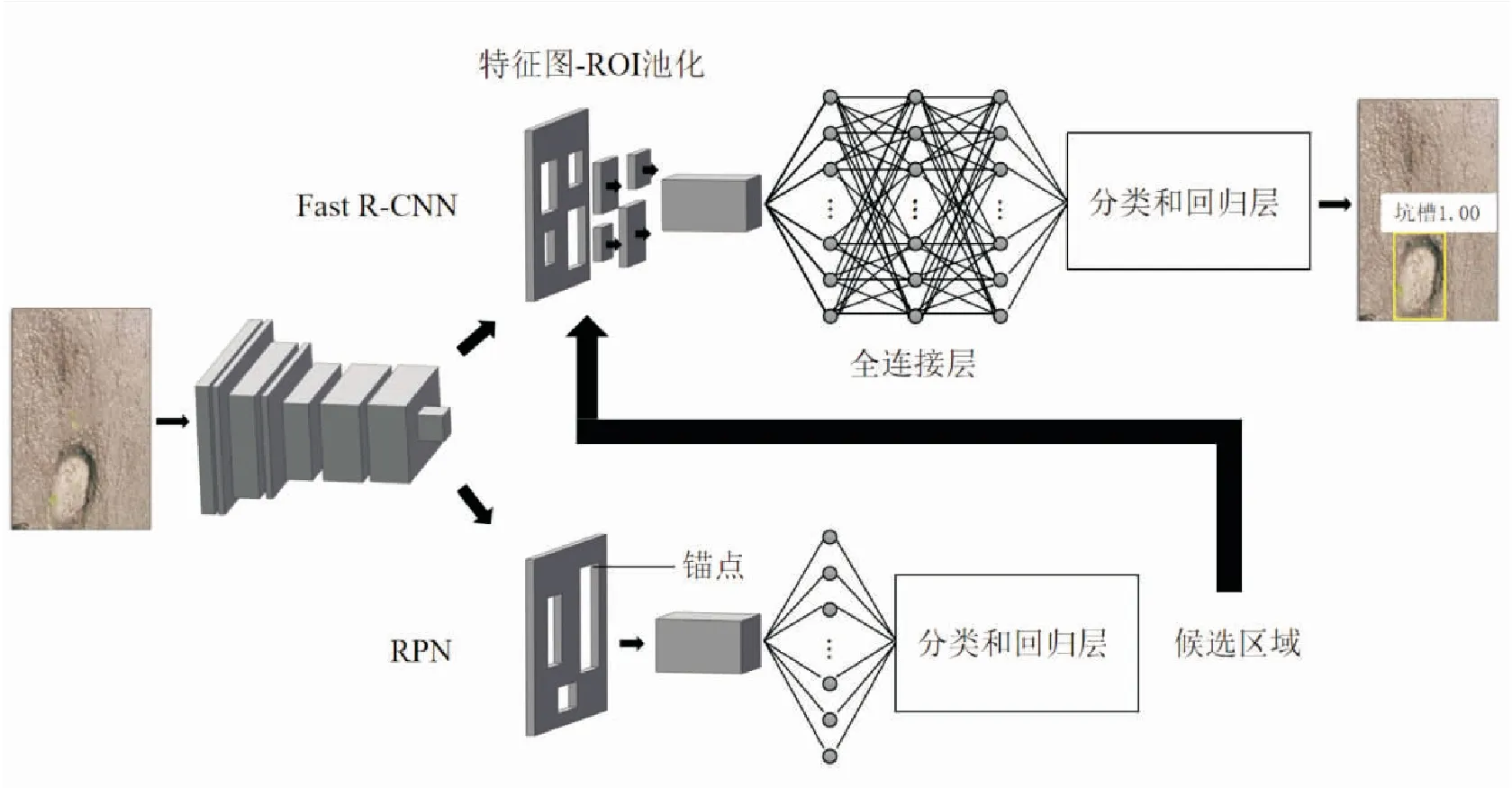
图2 基于Faster R-CNN的模型框架Figure 2 The model framework based on Faster R-CNN
2.2.1区域候选网络(RPN)
区域候选网络将图像作为输入和输出区域候选,如图2所示。每个候选都有一个对应类的分数。为了降低计算成本,Fast R-CNN和RPN共用同一组卷积层。
将图像输入卷积网络,输出一组卷积特征图。然后,在卷积特征图上运行滑动窗口算法。在每个窗口位置,根据预定义数量的锚点预测多个区域候选。锚点是具有特定比例和长宽比的参考框,其位于滑动窗口中心处。代码默认使用3种比例和3种长宽比,使每个滑动位置生成9个锚点。根据图像上的锚点和真实边界框,计算锚点的分类。重叠大于70%为正(1),重叠小于30%为负(0)。重叠在30%到70%之间则不考虑。锚点与分类结果被输入到滑动卷积层,然后是一个ReLU层,最后是一个全连接层。
将全连接层的输出输入到分类层(softmax)和回归层中。回归层确定预测的边界框,分类器输出从0到1的概率得分。将候选的边界框称为候选区域。
通过小批量采样进行分类和回归层的训练。从具有多个正锚和负锚的单个图像获得每个迷你批处理。通过随机采样256个锚,为每个图像计算迷你批处理的损失函数。其中,为了减少损失函数的负偏差,正锚的数量需大于128个。根据均值为0,标准差为0.01的高斯分布对所有层随机初始化,并通过预训练ImageNet分类模型来初始化共享卷积层。
2.2.2Fast R-CNN
Fast R-CNN网络的输入数据为RPN方法输出的一组候选区域和整个图像,如图2所示。然后,候选区域与初始CNN输出的原始特征图组合,得到近似区域(RoI)。 每个候选区域的RoI池化层从特征图中提取固定长度的特征向量。将这些向量输入全连接层、回归层和分类层,最终输出边界框的位置和分类。 由此,Fast R-CNN可以得到更精准的分类和边界框信息。
2.2.3Faster R-CNN中的ZF网络
REN[16]等在研究Faster R-CNN方法时提出了两种架构模型:Zeiler-Fergus模型(也称为ZF-Net)和Simonyan-Zisserman模型(也称为VGG-16)。对其进行比较发现,ZF-Net的训练和测试速度更快。ZF-Net最初由5个卷积层,2个全连接层和1个用于输出的回归层。REN等对原始ZF-Net进行了修改,得到Faster RCNN。对RPN和Fast R-CNN的修改如图3和图4所示。为了共享计算能力,RPN和Fast R-CNN第1层到第9层的输出相同。

图3 RPN中的修正ZF网络Figure 3 The rectified ZF-Net in RPN
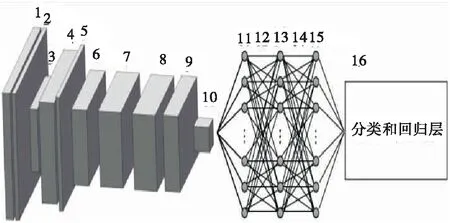
图4 Fast R-CNN中的修正ZF网络Figure 4 The rectified ZF-net in Fast R-CNN
为了加入RPN,Ren等用滑动卷积层替代了最后一个最大池化层和全连接层,然后再加入全连接层。此外,分类层由一个分类和回归层代替。卷积层后是ReLU激活函数,使每个滑动窗口映射到低维特征,并将其输入分类和回归层。对于Fast R-CNN,原网络的最大池化层由RoI池化层代替。在全连接层之间添加了dropout层,防止模型过度拟合。同样地,将RP模型的分类层替换为分类和回归层。
2.3 表面分割
为了量化路面坑槽体积,应首先确定路面标准。采用随机抽样一致性(RANSAC)算法进行路面平面拟合[14]。该算法根据预定义参数(如参考向量,距离阈值与点的法线跟参考向量的最大角距离)得到随机点,进而拟合平面。根据设置的阈值进行平面拟合,直至相似数据点达到最大值。此外,可将Faster R-CNN生成的边界框的平面用于随机抽样一致性算法以拟合平面。
在给定的情况中,采用平行于传感器法线的最大角距离为5°的参考向量。这样就无需将传感器放置在与表面完全平行的位置。设置随机抽样一致性算法的距离阈值为5 mm。不满足阈值的数据点都被视为异常值。
前述文献通常根据外部测量中获得的固定初始参数来识别道路病害。然而,对于移动的或无人的应用而言,这种方法不可行。此外,该方法没有考虑多个表面的可能性。然而,只要传感器位于设备的工作距离之内,不管传感器和目标之间的距离如何,本文提出的方法都可以拟合一个平面。该方法依赖于传感器输出的数据,无需进行任何其他人工测量。
2.4 路面坑槽分割
分析三维深度云和异常值,将位于同一平面的异常值范围内的值分类为坑槽。该过程同时可以从深度数据中过滤掉可能出现的NaN值。
为了使同一表面内的多个坑槽可以单独量化,采用层次聚类算法将异常值分割为单个坑槽。该算法首先计算输入数据中每对数据点P1,P2之间的欧氏距离d:
(1)
其中,i对应每个点的参考坐标。
然后将紧靠在一起的2对点合并为二进制集群。集群之间不断合并,形成更大的集群,直到所有数据都被分组为止。预先设置最大聚类数,然后将每个聚类索引作为相应的深度点的特征。
在本文方法中,预定义了最多10个聚类数。使得在同一表面内可以分割多达10个单独的坑槽。聚类算法是体积量化的关键,因为它根据相对于表面的深度数据对每个坑槽区域进行分割,以确保Faster R-CNN生成的位于边界框外部的像素也可以用于坑槽量化。
2.5 体积量化
拟合平面模型输出平面的法向量和常数系数a,b,c,d:
a·x+b·y+c·z+d=0
(2)
可以通过提取这些值来创建Zpn=f(x,y)函数,以确定每个数据点与拟合平面的精确距离,如图5所示。
(3)
其中,Zpn为第n个像素在深度方向上的坐标。
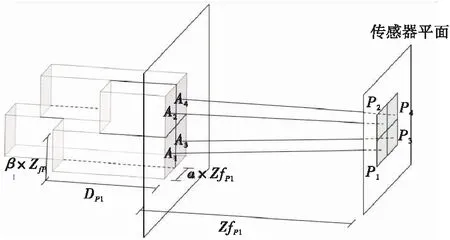
图5 体积量化示意图Figure 5 Schematic diagram of volume quantification
每个像素覆盖的面积会根据其深度平面而变化。 当距离较小时,一个像素可以覆盖1 mm2左右的面积,而随着距离增大,覆盖面积可以达到35 mm2。确定覆盖面积的公式如下:
(4)
其中,Apn为第n个像素的覆盖面积;α和β为水平和竖直方向上的Kinect常数。
为了计算每个像素覆盖的体积,需要获得像素点与式(2)得到的表面平面之间的距离。此外,可以通过式(3)计算平面内每个像素的深度。因此,将每个像素的z坐标减去拟合平面的相应z坐标,可获得像素点距离表面平面的相对深度值:
Dpn=Zpn-Zfpn
(5)
其中,Dpn为第n个像素的相对深度;Zpn为第n个像素的深度坐标;Zfpn为第n个像素在拟合表面平面上的深度坐标。
由于该方法会计算坑槽区域内每个像素的体积,因此可以对任何体积形状的路面坑槽进行量化。
对于每个分割的路面坑槽,将其覆盖面积和相对深度相乘来计算像素的体积,然后将这些像素体积相加得到每个路面坑槽的体积。最后,计算每个路面坑槽体积的总和为最终总体积。
(6)
(7)
其中,Vdi为第i个路面坑槽的计算体积;Vt为总计算体积。
3 试验过程
首先,对基于Faster R-CNN的路面坑槽检测方法进行训练、验证和测试。使用已检测的路面坑槽数据,并利用第2节所述的方法通过深度云信息进行量化。
Faster R-CNN在该方法中负责路面坑槽识别。为了进行坑槽检测,得到与Kinect RBG传感器结果相似的图像,使用智能手机相机采集了749张分辨率为2 560×1 440像素、纵横比为16∶9的图像。在不同光照条件下,调整拍摄距离为0.5 m至2.5 m对目标进行拍摄。然后,将获取的图像裁剪为1 091幅尺寸为853×1 440像素的图像,并对其添加标签构成带标签的数据库,如图6所示。

图6 带标签的数据库Figure 6 The labeled dataset
为了确保同一幅坑槽图像不会同时出现在不同数据集中,手动筛选生成训练、验证和测试数据集。其中,选择191张裁剪后的图像组成测试集,并随机选择600张图像组成训练集、300张图像组成验证集。此外,在训练和验证集上进行水平翻转和曝光调整对训练、验证集进行数据扩充。在进行数据扩充后,数据集共包含3 455张图像,且共有5 522个标记为坑槽的边界框。
深度学习模型要求对大量数据集进行准确的训练,过程非常耗时。为了克服数据集较小的局限性,对Faster R-CNN进行预训练。在RPN和Fast R-CNN网络进行训练时,将学习率设置为0.001,将动量设置为0.9,将权重衰减设置为0.000 5,分别为最终训练执行80 000和40 000迭代。
由于确定Faster R-CNN的最佳锚点数缺乏简单有效的方法,因此,采用了试错法。为了确定训练集的最佳锚点大小和比率,对12种锚点纵横比的组合和3种锚点大小的组合进行分析。共进行了37次训练,其中36次为试验。为了减少训练时间,每次试验训练中迭代次数比原始迭代次数少10倍,即RPN和Fast R-CNN分别为8 000和4 000迭代。选择具有最佳AP值的组合为最终模型,并进行完整的迭代训练。
为了增强对较小坑槽的检测,对输入图像进行缩放。保留原始长宽比将最短侧的853像素缩放到1 000像素。在该方法中,将输入图像放大来检测较小的坑槽强化网络是可行的。RPN的滑动卷积层在特征涂上的跨度为16。以上缩放和跨度参数都是通过反复试验确定的。
4 结果分析
4.1 Faster R-CNN
使用四步法对网络进行训练。由于训练集的分辨率设置,在GPU计算下的训练时间约为14 h。降低分辨率可以缩短训练时间。
Faster R-CNN在GPU计算下处理一个853×1 440像素的图像需要0.08 s,而在CPU计算下需要2.80 s。 在所有训练中,AP值最高为90.79%。对应的锚点尺寸和纵横比分别为128、480和880,以及0.5、0.85和1.85。用新的图像对最终模型进行测试,结果较好,如图8所示。其置信区间为从图7(a)的60.5%到图7(b)的85.9%。

(a) 识别1
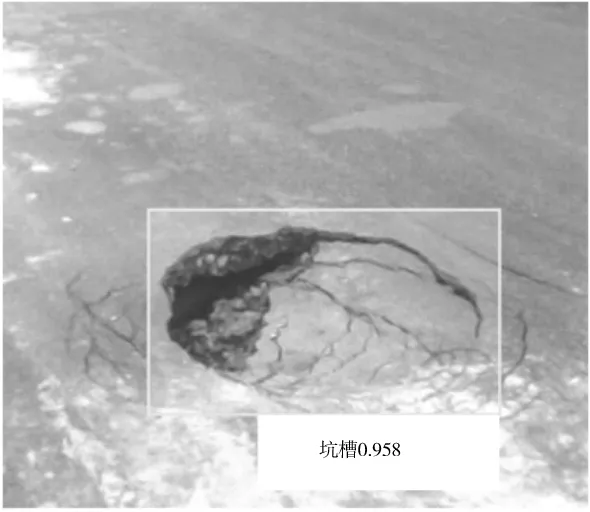
(b) 识别2
4.2 道路坑槽量化
在每种情况下,像素点体积会有3组数值,取其平均值进行计算。不论目标尺寸大小、深度和传感器距离如何,该算法都能够识别表面,并对道路坑槽进行分割和量化。边界框表示道路表面内存在坑槽,可用于分割该表面。当表面坐标已知时,即可提取对应坑槽的像素。此外,位于边界框外但仍在表面范围内的像素也计入体积量化。
体积计算结果如图 8所示。总体积的相对误差范围为:1.49%~13.83%,而每个道路坑槽的平均精度误差(MPE)为14.9%。
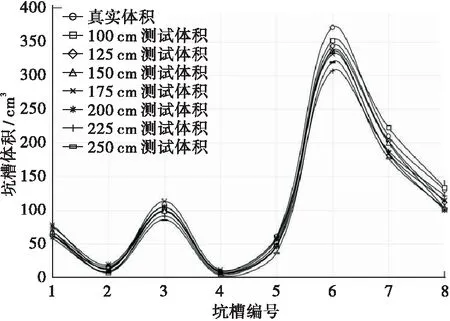
图8 路面坑槽体积计算结果Figure 8 The calculation results of volume of spalling damage
当传感器与检测目标之间的距离改变时,误差会有所变化。其中,距离为100 cm和200 cm时的准确性较高。
此外,还计算了每组坑槽的最大深度值,如表1所示。每组测试的误差率均低于10%。对于最短距离100 cm的情况,其相对误差仅为1.15%,低于KAMAL[17]提出的在80 cm下的误差率2.58%。此外,与YUAN[15]等的MPE为8%相比,本文的方法在最差条件下的MPE值也低于8%。
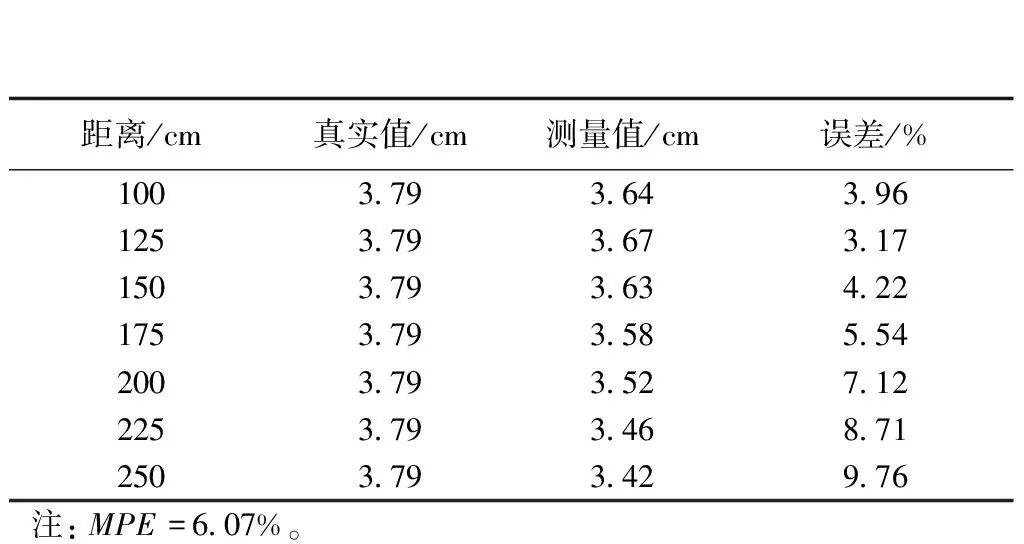
表1 坑槽最大深度Table 1 Maximun depth of spalling damage
4.3 应用实例分析
本文提出的道路坑槽量化方法具有实际应用价值。为了验证本文提出的基于深度学习的路面坑槽量化方法的有效性,本文采用距离为100 cm时的模型对长沙市长沙县多条乡镇道路进行了深度学习自动化检测。此外,为了对检测结果进行对比,同时对该路段进行了人工病害检测,并对坑槽进行量化。
2种方法的检测结果如表2所示,对比结果可得:人工检测和深度学习检测结果基本一致,坑槽体积量化误差不超过10%,效果较好。与人工检测相比,本文提出的基于深度学习的坑槽量化方法在一定精度范围内,耗时更短,计算效率更高,极大地节省了人力劳动。
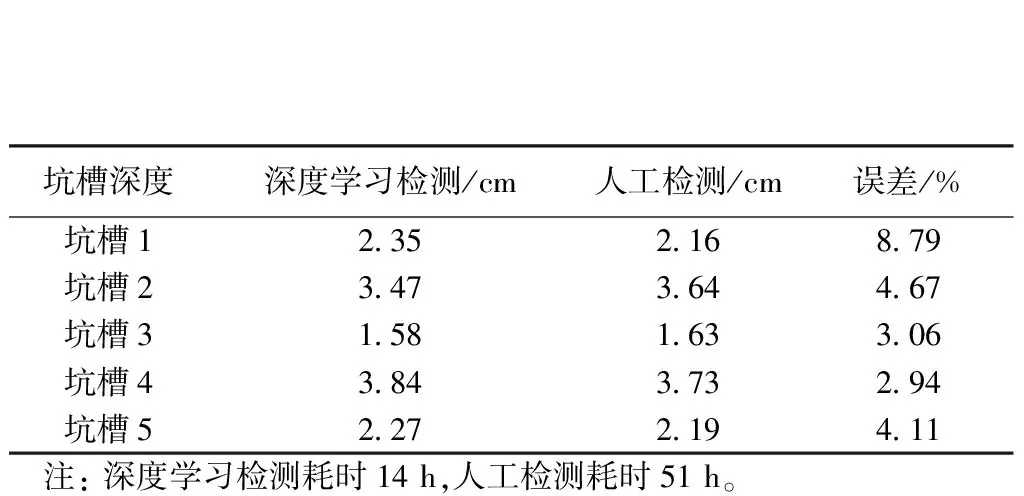
表2 两种方法检测结果对比示例Table 2 Comparison example of the detection results of the two methods
5 结论
传统上,测量道路坑槽体积是通过使用深度摄像头,3D扫描仪等方法。本文提出了一种基于深度学习的沥青路面坑槽量化方法,结合廉价的深度摄像头进行量化。首先,根据检测到的道路坑槽的位置和深度信息,使用RANSAC算法识别并分割道路表面。使用该算法可以摆脱传感器与检测目标之间距离的束缚,仅依靠RGB-D传感器的输出来识别和量化多个道路坑槽体积。此外,创建了带标签数据库,利用Faster R-CNN进行训练、验证和测试。通过深度学习网络,传感器在任何工作距离内都可以实现平面拟合,且AP值可达90.79%。对于单个坑槽测量体积,平均精度误差值低于10%。可以将该传感器安装至无人车上,对偏远或危险地区进行数据采集,得到的数据较为可靠。由于本文中使用的深度传感器较为廉价,替换为更高级的深度传感器可以进一步提高量化精度。
