多种倾向评分方法的SAS软件实现与比较
2022-09-14天津医科大学流行病与卫生统计学教研室300070
天津医科大学流行病与卫生统计学教研室(300070)
张洪璐 于泽洋 宋德胜 黄慧杰 李长平△
倾向评分(propensity score,PS)由Rosenbaum和Rubin于1983年提出,是一种对观察性研究、非随机化干预性研究或随机化失败的研究中混杂因素进行校正的方法[1],广泛应用于经济学、医学等领域[2]。本文主要介绍三种倾向评分分析方法的SAS 9.4软件实现,分别是倾向评分匹配、分层和加权,这三种方法可有效均衡混杂因素的组间分布差异,从而减少混杂偏倚,获得干预效应的有效估计[3]。既往使用SAS软件进行倾向评分分析时,需要较为复杂的程序或宏程序才可完成,代码较为繁琐[4-5]。本研究介绍的PSMATCH过程代码简洁,功能强大,可快速实现倾向评分匹配、分层和加权,为研究者在倾向评分分析中采用PSMATCH过程提供参考。
原理与方法
1.倾向评分分析的基本原理
倾向评分是指在给定一组协变量xi的情况下,每个个体i(i=1,…,N)被分配到干预组(Zi=1)的条件概率[1]:
e(xi)=P(Zi=1|xi)
xi是一组协变量,代表着许多维度,而e(xi)是xi的一个函数,将xi的所有维度简化为一个单维的值,起到了“降维”的作用,e(xi)能反映xi的综合作用。估计倾向评分的模型有很多种,如logistic回归、probit模型、判别分析以及神经网络等。其中logistic回归是最常用且简便的方式。
基于xi估计出e(xi)后,根据倾向评分选择合适的倾向评分分析方法,如倾向评分匹配、分层、加权等。由于具有相同或相似倾向评分的研究对象有相同的概率接受干预,因此根据倾向评分匹配、分层、加权后,可以认为进入模型的研究对象的组间分布均衡,达到了“事后随机化”的效果,可获得干预效应的无偏估计。
2.方法简介
(1)倾向评分匹配
常见的两类匹配方法是贪婪匹配和最佳匹配。贪婪匹配是一类“个体最优”的算法,即每个干预组成员在对照组中寻找距离最近者进行匹配,一旦配对成功就不再调整,因此匹配结果可能不是全局最优的,包括马氏距离匹配、最近邻匹配和卡尺匹配等。最佳匹配是一种“整体最优”的算法,即采用最小化总距离的方式对干预组成员和对照组成员进行匹配,配对成功后可以调整,包括固定比例匹配、可变匹配和完全匹配[6]。
①马氏距离匹配
对于干预组成员i和对照组成员j,其马氏距离定义为:
d(i,j)=(xi-xj)TC-1(xi-xj)
其中xi和xj分别是i和j的匹配变量取值;C是对照组匹配变量的协方差矩阵,也可以采用其他定义方式。
②最近邻匹配
其中ei和ej分别是干预组和对照组成员的倾向评分值。
③卡尺匹配
|ei-ej|<ε,j∈C
卡尺匹配是指干预组和对照组个体的倾向得分差值在预先设定的某个范围内(即卡尺ε)才会进行下一步匹配,这样的约束可以在一定程度上缩短总距离。通常卡尺大小设置为ε≤0.25σ,σ是由样本估计的倾向评分值的标准差。
④固定比例匹配
包括成对匹配(1∶1)和一对多匹配(1∶k,k≥2)。在不同的匹配组中,对照组成员的数量是固定的。
⑤可变匹配
一个干预组成员和一个或多个对照组成员进行匹配。在不同的匹配组中,对照组成员的数量是变化的。
⑥完全匹配
每个干预组成员和一个或多个对照组成员进行匹配,同时,每个对照组成员可以和一个或多个干预组成员进行匹配。在不同的匹配组中,干预组和对照组成员的数量都是变化的。
(2)倾向评分分层
将所有研究对象分成具有相似倾向评分的层,从而均衡各层内干预组和对照组个体的差异。研究表明,使用倾向评分将所有研究对象分为5层可以消除大约90%由测量的混杂因素引起的偏差[8]。
(3)倾向评分加权
倾向评分加权旨在对干预组和对照组成员进行加权,使其能够代表总体。PSMATCH过程提供三种计算权重的方法。
①逆概率加权(inverse probability of treatment weighting,IPTW)
采用第i个观测的倾向评分e(xi)计算IPTW权重Wi:
②稳定的逆概率加权(stabilized inverse probability of treatment weighting)
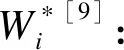
其中,Pt=Nt/(Nt+Nc),Nt为干预组人数,Nc为对照组人数。
③概率比加权
采用第i个观测的倾向评分e(xi)计算概率比权重Wi:
3.均衡效果的评价指标
在完成上述倾向评分分析后,需判断混杂因素在组间的分布是否均衡。PSMATCH过程能够输出两种常用评价指标(标准化均值差值和方差比)和图形(条形图、箱式图等)的结果。
(1)标准化均值差值(standardized mean difference)
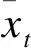
(2)方差比(variance ratio)
研究表明,d≤0.25,0.5≤VR≤2时,组间均衡效果较好[6]。而更严格的标准要求d≤0.1[10]。
4.其他概念
(1)共同支持域(common support region)
干预组和对照组倾向评分取值范围的交集[1]。
(2)干预效应
在一项评估某种干预措施效果的观察性研究中,研究对象通常有两种可能的结局[1,7]:
Y(1):干预组个体的结局
Y(0):与之情况相同的对照组个体的结局
将干预效应定义为Y(1)-Y(0),则平均干预效应(average treatment effect,ATE)为:
ATE=E(Y(1)-Y(0))
干预组的平均干预效应(average treatment effect for the treated,ATT)为:
ATT=E(Y(1)-Y(0)|Zi=1)
实例分析与SAS实现
SAS 9.4软件是一种模块化的大型应用软件系统,在最新的SAS/STAT15.1模块中PSMATCH过程可以实现倾向得分分析。本研究通过SAS 9.4模拟生成一个数据集drugs,其中包括:患者编号(Patient-ID)、用药情况[Drug:Drug_X为干预(n=113)、Drug_A为对照(n=373)]、性别(Gender,1=男,2=女)、年龄(Age,连续变量)、体质量指数(BMI,连续变量)。在进行不同用药情况的组间比较时,首先应均衡组间协变量的分布差异,本研究分别采用倾向评分匹配、分层和加权对不同用药情况的各组间协变量的分布差异进行了调整,并对三种方法进行了比较。
1.倾向评分匹配
(1)SAS代码
proc psmatch data=drugs region=cs;
class Drug Gender;
psmodel Drug(Treated=′Drug_X′)=Gender Age BMI;
match method=optimal(k=1) exact=Gender distance=lps caliper=0.25 weight=none;
assess lps allcov / plots=(barchart boxplot);
run;
(2)主要程序及其他选项说明
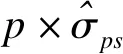
CLASS语句指定分类变量。PSMODEL语句指定计算倾向评分的logistic回归模型,TREATED选项指定干预组的值,可以用引号指定干预组的值,如本例中的′Drug_X′,也可以用FIRST或LAST分别指定第一个或最后一个类别为干预组,默认情况下,TREATED=FIRST。
MATCH语句将干预组和对照组成员进行匹配。METHOD选项指定匹配方法:①METHOD=GREEDY表示贪婪匹配,其中K选项指定匹配对照组成员的数量,order选项指定干预组成员的匹配顺序;②METHOD=FULL表示完全匹配,其中KMAX和KMEAN分别指定每个干预组成员匹配对照组成员的最大数量和平均数量,NCONTROL和PCTCONTROL分别指定要匹配的对照组成员的数量和百分比;③METHOD=OPTIMAL表示最佳固定比例匹配,K选项同上。EXACT选项指定需要精确匹配的分类变量;④METHOD=VARRAITO表示可变匹配,其中KMIN指定每个干预组成员匹配对照组成员的最小数量,KMAX、KMEAN、NCONTROL和PCTCONTROL选项同上。DISTANCE选项指定匹配时要比较的距离类型,DISTANCE=LPS/PS/MAH分别表示倾向评分的logit变换/倾向评分/马氏距离,可附加其他选项选择计算马氏距离的变量。CALIPER选项指定匹配的卡尺大小,可以附加MULT选项(指定卡尺乘数项)或MAHDISTANCE选项(上述DISTANCE=MAH时)。WEIGHT选项指定权重的类型:①WEIGHT=ATEWGT/MATCHATEWGT表示输出ATE权重;②WEIGHT=ATTWGT/MATCHATTWGT/MATCHWGT表示输出ATT权重;③WEIGHT=EQUAL/NONE表示两组权重相同。
ACCESS语句用于评估组间差异:①ALLCOV选项对PSMODEL语句中指定的协变量差异进行评估;②LPS选项对倾向评分的logit变换的差异进行评估;③PS选项对倾向评分的差异进行评估;④VAR选项对指定变量的差异进行评估,这些变量可以是PSMODEL语句中没有指定的变量。此外,可以在“/”后添加评估选项:①PLOTS选项指定评估变量均衡性的图,如条形图(BARCHART)、箱式图(BOXPLOT)等;②STDBINVAR选项指定是否对标准化均值差值图表中的二分类变量进行标化;③STDDEV选项指定标准化均值差值计算中使用的标准差类型;④VARINFO选项可显示干预组和对照组的变量信息。
(3)主要结果解释
图1为匹配后各个变量的分布情况,最终的匹配集中有113对匹配对,匹配后各个变量的分布较均衡(图1)。表1为匹配后的标准化均值差值。匹配后,干预组和对照组之间的标准化均值差值均有减少,倾向评分的logit变换值减少了98.35%,年龄减少了95.89%,BMI减少了83.19%,性别减少了100.00%。
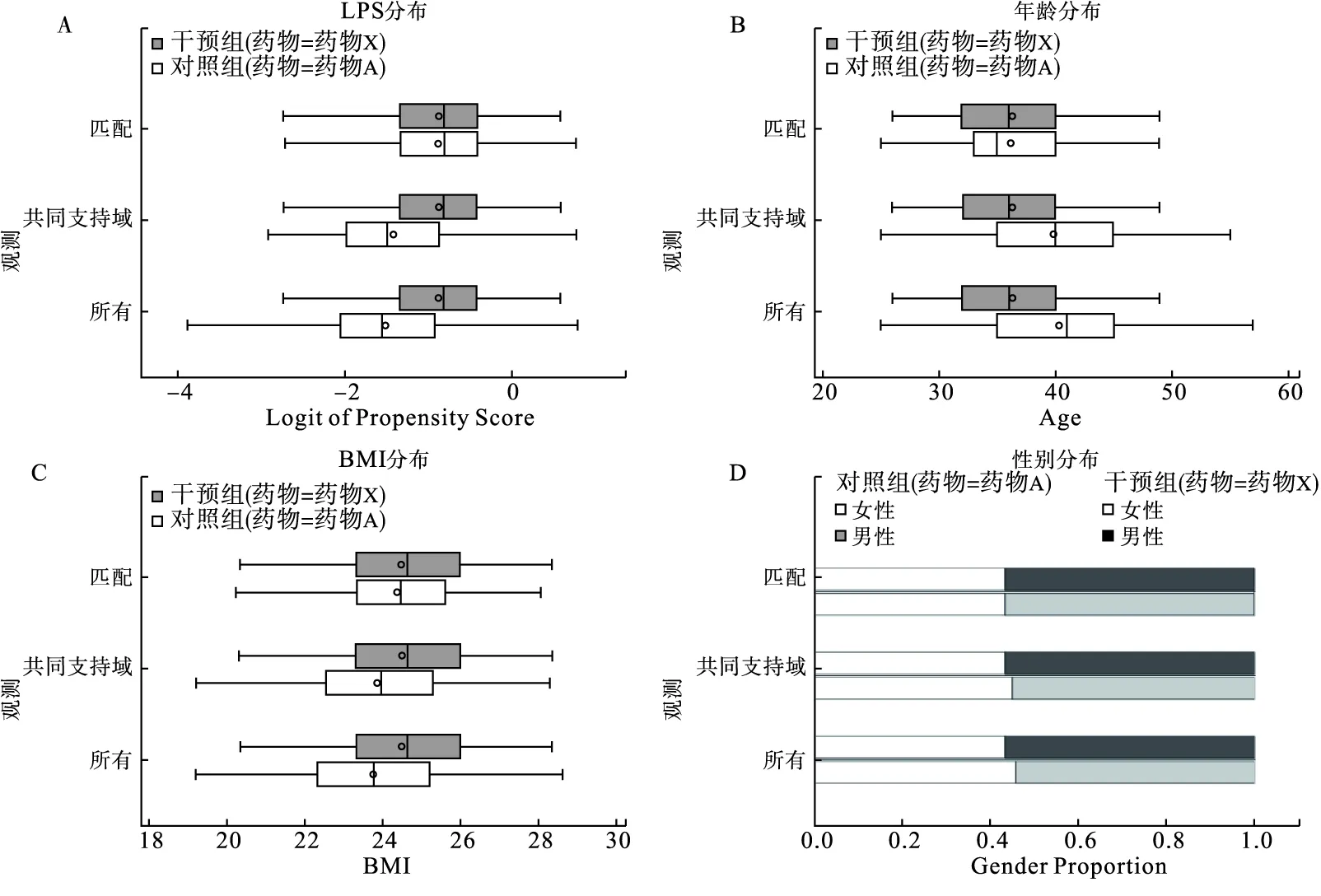
图1 匹配后各变量的分布
此时,各变量干预组和对照组之间的标准化均值差值分别为0.01375、0.02766、0.06461、0,均小于0.25,方差比分别为1.0155、1.1262、1.1967、1.0000,均处于0.5~2之间(表1)。
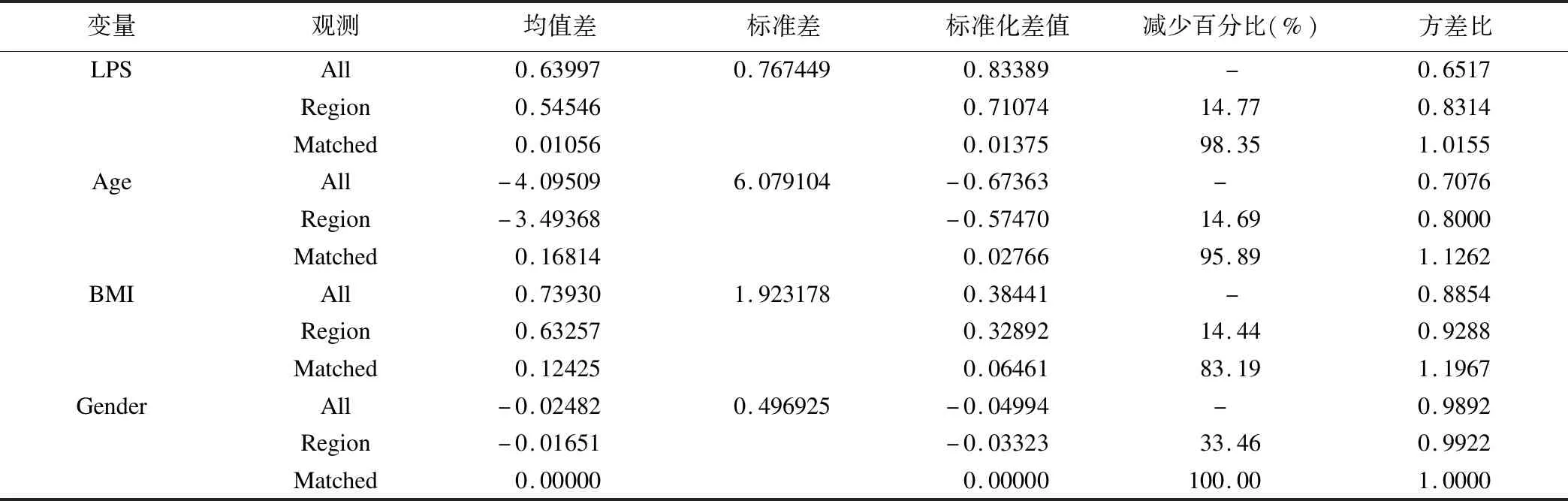
表1 匹配后标准化均值差值(干预-对照)
2.倾向评分分层
(1)SAS代码
proc psmatch data=drugs region=allobs;
class Drug Gender;
psmodel Drug(Treated=′Drug_X′)=Gender Age BMI;
strata nstrata=5 key=treated stratumwgt=total;
assess ps var=(Gender Age BMI) / varinfo plots=(barchart cdfplot);
run;
(2)程序说明
同样调用PSMATCH过程。STRATA语句将所有观测分层,NSTRATA选项指定层数。KEY 选项指定各层的构成,KEY=TOTAL/TREATED分别表示各层包含大致相同数量的成员或干预组成员。STRATUMWGT指定层权重类型,STRATUMWGT=TOTAL表示以层中所有成员比例作为权重,用于估计ATE;STRATUMWGT=TREATED表示以层中干预组成员比例为权重,用于估计ATT。其他命令与匹配相同。
(3)主要结果解释
表2为分层后SAS的输出结果。分层后,干预组和对照组之间的标准化均值差值均有减少,倾向评分减少了89.47%,年龄减少了83.79%,BMI减少了74.88%,性别减少了87.45%。此时,各变量干预组和对照组之间的标准化均值差值分别为0.08121、-0.10922、0.09656、-0.00627,均小于0.25,方差比分别为0.8678、0.7981、0.8769、0.9999,均处于0.5~2之间(表2)。
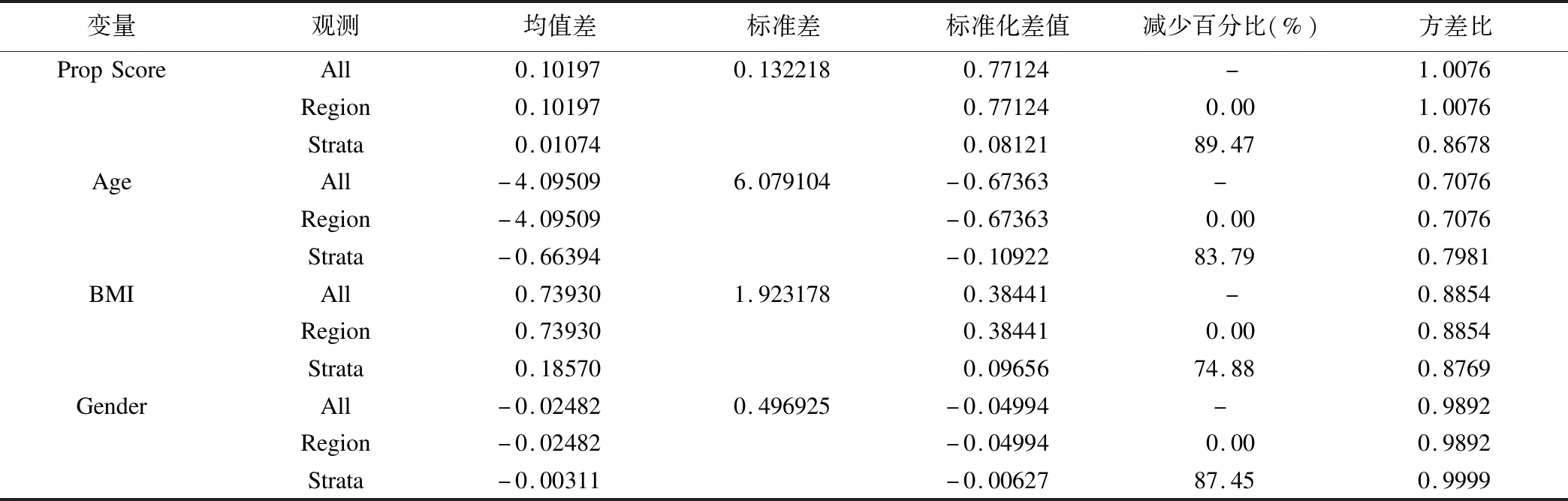
表2 分层后标准化均值差值(干预-对照)
3.倾向评分加权
(1)SAS代码
proc psmatch data=drugs region=allobs;
class Drug Gender;
psmodel Drug(Treated=′Drug_X′)=Gender Age BMI;
psweight weight=atewgt nlargestwgt=6;
assess lps var=(Gender Age BMI)/ varinfo plots=(barchart boxplot(display=(lps BMI)) wgtcloud);
run;
(2)程序说明
同样调用PSMATCH过程。PSWEIGHT语句基于倾向评分计算各个观测的权重。WEIGHT选项指定权重的类型,WEIGHT=ATEWGT表示使用逆概率权重,可以在ATEWGT选项中附加STABILIZE选项,STABILIZE=YES表示使用稳定的逆概率权重,STABILIZE=NO表示使用逆概率权重,用于估计ATE,WEIGHT=ATTWGT表示使用概率比权重,用于估计ATT。NLARGESTWGT选项可显示权重最大的观测。其他命令与匹配相同。
(3)主要结果解释
表3为加权后SAS的输出结果。加权后,干预组和对照组之间的标准化均值差值均有减少,倾向评分的logit变换值减少了84.85%,年龄减少了82.21%,BMI减少了89.14%,性别减少了25.21%。此时,各变量干预组和对照组之间的标准化均值差值分别为0.12636、-0.11985、0.04175、0.03735,均小于0.25,方差比分别为0.6874、0.7269、0.8957、1.0054,均处于0.5~2之间(表3)。
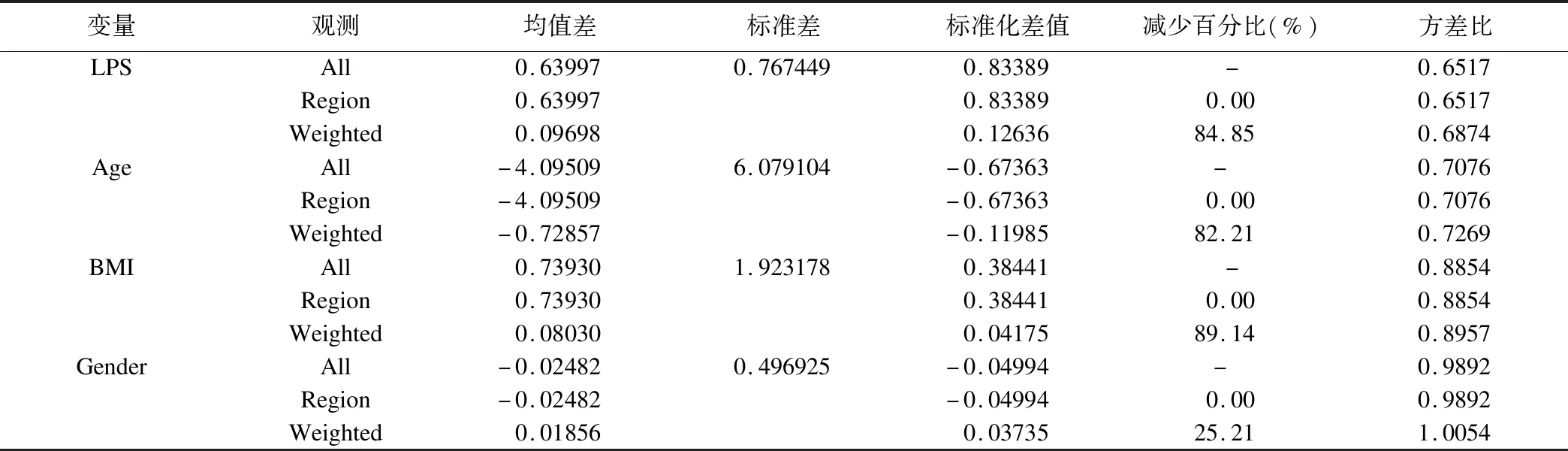
表3 加权后标准化均值差值(干预-对照)
讨 论
本研究通过调用PSMATCH过程,使用相对简单的SAS代码,实现了倾向评分匹配、分层和加权。在PSMATCH过程中,通过添加不同语句和选项,可以指定共同支持域、分类变量、计算倾向评分的logistic回归模型以及评估组间差异的方法。在MATCH语句中,可以指定匹配方法、需精确匹配的分类变量、距离类型、卡尺宽度及权重类型。在STRATA语句中,可以指定层数、各层构成及权重类型。在PSWEIGHT语句中,可以指定权重类型。
从本数据的结果可知,在匹配、分层、加权后,各个变量的标准化均值差值都低于0.25,方差比都在0.5~2之间,可以认为这三种方法在一定程度上均衡了组间差异。但以更严格的标准来说,仅在匹配后,各变量的标准化均值差值都低于0.1,而分层和加权后年龄的标准化均值差值均大于0.1,均衡的效果欠佳。这与Schroeder K[4]等人的研究结果一致,可能与匹配后总样本量的改变有关。匹配过程中由于匹配条件导致的样本剔除使得纳入分析的匹配对间差异较小,而分层和加权过程中并未改变纳入分析的总样本量。
基于上述分析结果,本研究可以得出以下三个主要结论:
1.PSMATCH过程可以实现倾向评分匹配、分层和加权,使用的SAS代码非常简单,并可以根据研究需要添加多种语句和选项来估计ATE或ATT。
2.PSMATCH过程可以在匹配、分层和加权后,使用多种方式评估混杂因素在组间分布的差异。就本数据而言,这三种方法均可以均衡混杂因素在组间分布的差异。
3.将三种方法进行比较时,匹配对组间差异的均衡效果最佳,分层和加权次之。但匹配造成了样本量损失,所以要求较大的样本例数和共同支持域。因此建议研究者在选择方法时先测试多种倾向评分方法,再根据研究目的选择合适的方法。
