基于Mobilenetv3的煤矿人脸识别方法
2022-08-30谢子殿亢健铭
谢子殿, 亢健铭
(黑龙江科技大学 电气与控制工程学院, 哈尔滨 150022)
0 引 言
近年来,随着人工智能的广泛发展,各行各业都逐步应用人工智能这一技术来解决当前行业所面临的一些困境与难题。煤炭行业作为我国的工业生产支柱产业,一直以来备受关注,随着智慧矿山的提出与推广,在煤炭生产中逐步应用智能自动化设备及智能安全保障措施。煤矿工人在出入井工作之前需要进行识别认证,过去常用的方法是使用煤矿工人识别卡,但会出现一人携带多卡的现象,当煤矿发生危险的时候,会给安全施救带来极大隐患。之后便使用生物特征识别技术,即人脸识别。由于人脸特征不同,有效防范了一人多卡带来的安全隐患。
在井下的一些危险区域中,煤矿人员不应靠近或者只允许一些特定人员进入该区域进行作业,需要设计一个安全监控装置对该区域进行监控。传统的指纹、掌纹和声纹等由于煤矿井下复杂环境,无法很好地应用于煤矿井下,使用人脸识别技术成为首选。高鑫[1]在ResNet网络特征提取过程中添加CBAM注意力机制,利用特征图的空间关系,加强面部重点区域的纹理特征信息权重,获得更多面部特征。郭秀才等[2]利用2D-Gabor小波提取归一化的输入图像特征,运用信息熵将子块乘上加权系数得到人脸特征。黄玉[3]使用基于Shealet变换的煤矿井下图像差异性特征提取方法,对特征子图赋予不同权值及编码融合,有效减低维数。笔者采用Retinaface人脸检测算法先对进入目标区域的人员进行人脸检测,截取下来的面部图片再传入Mobilenetv3主干特征提取网络特征,将传入Facenet人脸识别算法当中计算欧式空间距离,设定判别阈值进行身份识别。
1 人脸检测
Retinaface人脸检测算法是一种单阶段的算法,将图像的检测、特征提取、目标框的回归和物体分类在一个网络中实现快速准确地检测。该检测算法在特征提取部分采用深度可分离的卷积网络,深度可分离卷积是一种分解卷积的过程,其可以分解为深度卷积和点卷积。深度卷积和标准卷积不同,深度卷积针对图像的每个输入通道采用不同的卷积核,即一个卷积核对应一个输入通道;而点卷积就是普通的卷积,只不过其采用1×1的卷积核,未改变原有特征的尺寸[4]。这种先对不同输入通道分别进行卷积,然后对输出再结合的操作得到的整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
采用FPN特征金字塔网络对深度可分离卷积提取到的特征做进一步特征加强处理,Lin[5]等提出使用FPN来处理多尺度目标检测问题。使用多级特征的特征图构成特征金字塔,对在卷积网络得到的C3~C5层特征图进行FPN操作得到P3~P5,进行后续的处理。FPN算法并没有改变原有网络的结构,而是在原网络的基础上提取出额外层进行连接,这样既没有增加原有模型的计算量,而且还会增加物体检测的性能。
在Retinaface算法当中采用多任务损失函数,通过对输出的人脸预测框与五个人脸关键点等坐标的调整与优化,使多任务损失函数达到最小化,其公式为
(1)
式中:Lcls——脸部分类二值损失函数;
Lbox——脸部边框回归损失函数;
ti——预测框坐标;
Lpts——人脸关键点损失函数;
li——预测值五个人脸关键点坐标;
λ1、λ2——损失平衡参数。
2 人脸识别
Mobilenetv3网络是Howard等[6]于2019年提出的,该网络在之前的Mobilenet网络基础上进行结构优化,可在手机端的CPU实时检测,实现精度更高,速度更快的效果。该网络的结构如图1所示。其中,Bneck结构包含了深度可分离卷积、SE模块、激活函数等操作。由图1结构可以分析,Mobilenetv3继承了前代的深度可分离卷积操作,减少了模型的计算量与参数量,引入注意力机制SE模块,更新了激活函数。
2.1 SE模块
SE模块可以加强网络卷积特征通道之间的相互联系,通过学习的方式自动判别各个特征通道的重要程度,提升有用特征的权重,抑制无用特征,从而提升了特征信息的质量,SE模块操作如图2所示。
对于输入进来的特征图通道进行全局平均池化处理,得到通道的数目,再通过两个全连接层加两个不同的激活函数(ReLU与h-swish)得到最后的通道权重输出,图2中不同的颜色代表每个通道的不同权重。这样的操作就得出了每个通道的重要程度,越重要的权重越大,不重要的权重越小。
2.2 激活函数
在Mobilenetv3中使用了h-swish激活函数,它是由swish激活函数优化而来。由于swish的平滑,非单调的函数特性,在深层网络中性能优于ReLU激活函数,但其计算复杂,消耗的计算资源与求导时间较多。因此,将ReLU6作为近似函数逼近swish,用于消除sigmoid函数潜在的数值精度损失。h-swish函数的提出解决了计算与求导的时间复杂,提升了网络的推理速度和量化过程,使网络的表现效果更好。h-swish激活函数为
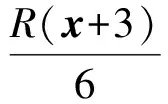
(2)
R(x)=min(max(x,0),6)。
(3)
2.3 Facenet人脸识别算法
将Mobilenetv3网络提取出的128维特征向量输入到FaceNet人脸识别算法中,进行人脸的特征判别。该向量通过Tripiet Loss三元组损失函数识别出样本间的相似性与差异性,将向量映射到欧氏空间中进行欧氏距离的计算,根据距离的同近异远原则识别出人脸,进行身份的识别。Facenet算法结构如图3所示。
(4)
式中:α——正负样本边界值;
T——数据集中可能的三元组集合;
n——集合中元素数量。
(5)
式中:i,j——参与训练的样本标识;
d——维度;
D——两种样本的欧氏距离。
3 实 验
3.1 实验环境
文中是在Windows操作系统下运行,使用CPU为Intel i5-10400F@2.9 GHz,GPU为NVIDIA GeForce RTX 3060,运行内存为2×8 GB的硬件设备,通过搭建TensorFlow2.0版本的深度学习框架,使用python3.7进行编译。
3.2 数据集
实验由于网上没有开源的矿工人脸数据集,再加上矿工井下长时间工作的特殊环境,会导致工人面部会受到煤灰与粉尘的污染。因此,搭建了一个小样本拟矿工数据集,该数据集包含了18个人的不同角度不同姿态的图片,每人包含40张图片,同时照片中包含面部正常、面部污损及井下黑暗环境等情况,经数据增强后,数据集图片总数量约6 000张。
3.3 数据增强
由于实验数据集属于小样本数据集,图片数量远远不够卷积训练的标准,易发生过拟合的现象,因此,使用图片数据增强技术既增加了数据集的图片数量,又能减小过拟合情况的发生。
数据增强的方法是在原有图片的基础上进行随机剪裁、旋转、色域变换及加入噪声等,这样会增加原有图片的多样性,并且联合正则项或dropout等方法使模型进行更有效地学习,抑制过拟合的发生。数据增强后的图片效果如图4所示。
3.4 实验过程与分析
在训练阶段采用随机梯度下降优化算法,使用冻结网络的方法训练,设置100个epoch,其中,前50个epoch冻结主干网络,对后续网络进行训练,设置batch size为32,学习率为10-3;从51个epoch开始,解冻主干网络,与后续网络一起训练,设置batch size为16,学习率为10-4。其目的可以将更多的资源放在训练后面部分的网络参数,使时间和资源利用都能得到很大改善。
将训练集、验证集与测试集按7∶1∶2的比例进行划分,对Mobilenetv1、Inception_resnetv1和Mobilenetv三种主干特征提取网络模型进行实验对比分析,图5为训练过程中的Loss曲线。
由图5可见,Mobilenetv3在训练接近70个迭代时基本收敛,而其他两个网络在90多个迭代才收敛,表明Mobilenetv3网络在较少的迭代次数,更短的时间内就能得到满意的结果,达到快速收敛的效果。
在测试集上进行精确度的测试,表1为测试结果。其中,精确度为η,阈值为β,参数量为m。
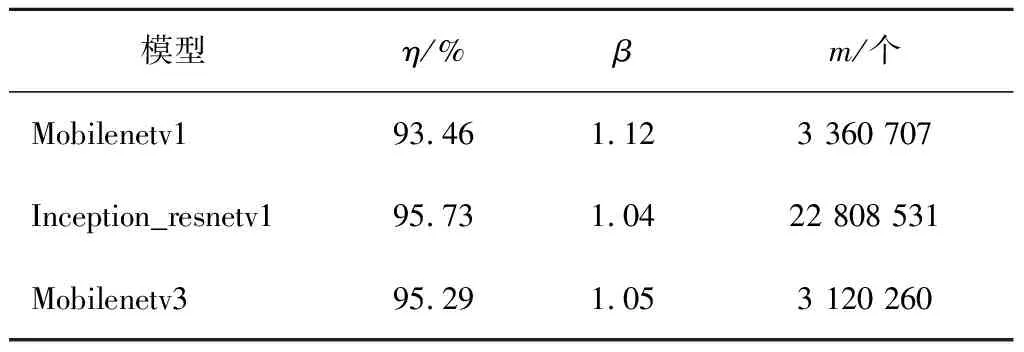
表1 测试结果
由表1可知,Inception_resnetv1模型的精确度最高,但该模型的参数量极大,网络层数达到400多层,耗用时间较多,占用较大的内存资源。而Mobilenetv3网络精确度与Inception_resnetv1网络精确度差别不大,但模型参数量是它的七分之一,识别速度较快。根据参数量、识别速度和精确度的平衡考虑,最终选择Mobilenetv3网络。同时,表中的阈值是判定界限,如果距离超过这个阈值,就判定为不同两人;反之则为同一人。
4 结 论
(1)结合深度可分离卷积和SE模块的Mobilenetv3网络作为人脸识别的主干特征提取网络,不仅提高了特征提取的速度,还增强了特征提取过程中特征通道之间的相互联系,提升了特征信息的质量。
(2)在自建拟矿工小样本数据集中,MobileNetv3网络在参数量、精确度和识别速度的综合衡量下,计算精度比MobileNetv1网络提升1.83%,比Inception_resnetv1网络下降0.44%,但计算参数量是Inception_resnetv1网络的1/7,提高了人脸识别效率。
