标签,这些标签下的文本内容才是最核心的正文部分,而这部分内容也是全网页文本密度与标签密度最大的部分,因此通过对文本和标签的密度进行计算可确定需要提取的部分。虽然不同网站的页面结构差异巨大,但通过观察仍然可以发现一些共性[15]。通过对比不同HTML页面可以发现,网页正文部分无论如何组织最终都集中在同一个祖先HTML标签下,在该祖先标签下存在大量
基于文本及HTML标签密度的网页正文提取
2022-08-11杨大为王诗念包立岩要虹吏
沈阳理工大学学报 2022年4期
杨大为,王诗念,包立岩,要虹吏,刘 畅
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
随着互联网的发展,海量的网页为互联网用户提供了源源不断的信息。然而,由于网站的商业性质,网页提供信息的同时也包含了广告内容,同时也引入了大量HTML标签和JavaScript代码用于页面的美化。这些噪声的存在一定程度上会干扰读者的阅读,也会影响搜索引擎的搜索效率[1]。正确去除网页噪音同时提取正文信息,对大数据时代的文本数据挖掘具有重大意义。
1 相关研究
1.1 基于包装器的方法
根据HTML结构的内部特征完成内容提取的方法称为包装器方法,该方法通过分析网页代码的方式手动配置HTML页面的正则表达式并采用XML路径查询语言Xpath实现程序自动或半自动内容提取[2]。陈迎仁等[3]提出一种基于特征相似度的方法使旧包装器自适应提取新的页面。曾燕清等[4]提出一种通过比对HTML源码进而自动提取Xpath代码算法,取得了较好的效果。
包装器方法针对特定的网页模版效果较好,当网页结构发生改变或面对其他模版的网页时需要重新编写提取规则,增加了维护成本。自动生成的包装器虽然减轻了人工负担,但需要样本学习,创建的成本也很高。
1.2 基于视觉的方法
基于视觉的方法是模拟人眼浏览网页的视觉特征判断信息的抽取区域。早期微软亚洲研究所提出了基于视觉信息的网页分块算法[5],基于网页视觉内容结构信息结合文档对象模型(Document Object Model,DOM)树对网页进行处理。近年来,该方法有了诸多改进。王鹏[6]提出基于视觉信息的Web数据提取系统,能将用户操作记录下来,然后自动完成页面的提取。张鑫等[7]提出一种基于视觉特征和领域本体的Web信息抽取算法,该算法利用HTML标签和层叠样式表(Cascading Style Sheets,CSS)所定义的网页字体、背景颜色、分块等页面视觉特征准确划定信息抽取区域。Zeleny J等[8]提出利用视觉结合语义分割页面DOM树的算法。
基于视觉的方法需要浏览器完全渲染一个Web页面才能进行解析,这导致提取效率大打折扣,网页数量大时需要占用大量的内存和CPU资源,且对于网页布局不同的情况缺乏通用性[9]。
1.3 基于统计的方法
基于统计的方法根据统计的标签节点信息表示其主题性,再利用主题性提取信息。朱泽德等[10]提出一种基于文本密度模型的Web正文抽取算法,通过融合网页结构和语言特征的统计模型,将网页中文档按文本行转化后,再经高斯平滑修正得到密度序列,最后采用改进的最大子序列分割序列算法抽取正文。Weninger T等[11]提出基于标签比率的内容提取算法,使用HTML标记比率实现了从不同布局的页面提取正文内容。近年来,随着人工智能的广泛应用,融合深度学习的统计方法逐步被采用。对于结构较为固定的页面,赵朗[12]提出的基于深度学习的Web信息抽取方法获得了较好的效果。
基于统计的方法能很好地应用于含大量噪声且信息量少的网页,但忽略了提取信息区域内部噪声和节点间的关系,容易将正文连同噪声一并提取。
2 TTD算法设计
早期有学者提出过正文提取(Body Text Extraction,BTE)算法[13],利用文本密度进行正文的提取。洪鸿辉等[14]提出基于文本及符号密度(Text and Symbol Density,TSD)的网页正文提取方法,文本密度计算简单且具有一定的通用性,对大部分HTML结构的网页提取具有良好的效果。本文在此基础上提出一种新的基于文本及HTML标签密度(Text and HTML Tag Density,TTD)的提取方法,将文本密度与标签密度相结合,综合判断正文所在位置并完成提取。
2.1 提取系统设计
一个典型的HTML页面基本结构如下。
页面中包含了
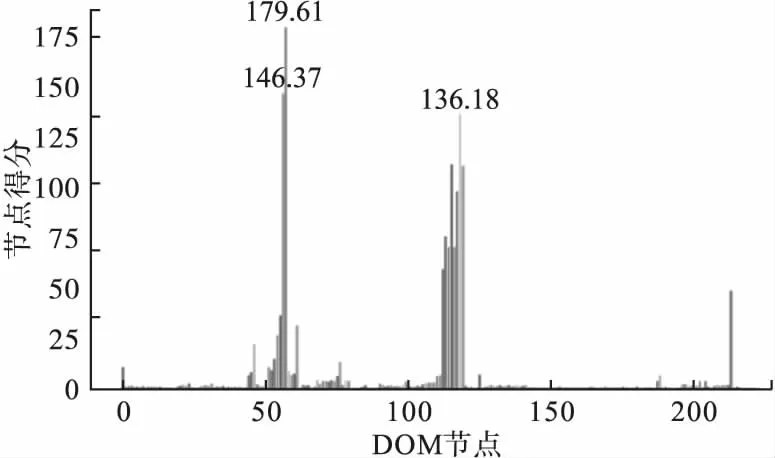
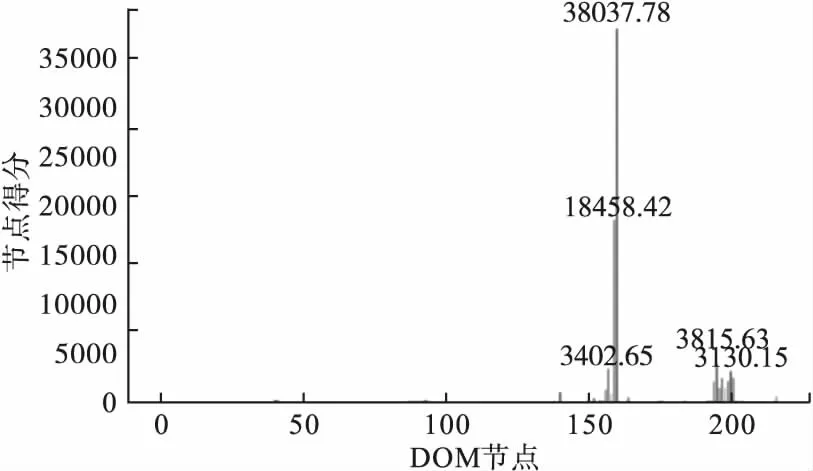
、等元素,而元素下包含了要提取的正文部分。随着Web技术的发展,网站为了定制网页的表现形式和提高网页视觉效果,在源文件中加入大量JaveScript和CSS代码,因此在提取正文之前要对网页源文件进行预处理,去除与正文内容不相关的噪音内容。其次,由于HTML语言书写的随意性,导致有些网页源代码不规范,例如标签缺失、嵌套不准确等,因此需要将缺失的HTML标签补齐、修改不正确的嵌套关系。对处理后的HTML页面使用统一码归一格式化对网页源代码进行归一化,把特殊符号转换为普通符号,并将得到的HTML文档格式化以方便Xpath提取的内容,并将得到的HTML结构转化为DOM树的形式。通过DOM的层次结构可以依次计算出各个标签层次的文本密度及标签密度,最终通过TTD算法判断出正文所在节点,进而完成提取。TTD算法流程和提取结果如图1所示。
图1 TTD算法流程和提取结果
2.2 基于文本及HTML标签密度的提取方法
典型的网页DOM树结构如图2所示。

图2 典型的网页DOM树结构
由图2可见,结构中包含大量的标签元素。真正所需的正文内容仅在标签内,而