新时期中国生育水平及相关社会发展指标再探析
2022-08-06刘旭阳王广州
刘旭阳,王广州
(中国社会科学院 人口与劳动经济研究所,北京 100010)
一、研究背景
新中国成立以来,我国已经进行了七次人口普查。普查数据作为最高质量和最具权威的全国性基础数据,不仅记载了中国人口变动的历史,也记载了中国社会发展的变化。深入研究人口普查数据对正确认识中国人口和社会发展现状及突出问题具有重大意义,同时对进一步澄清历史上的一些模糊认识,纠正可能存在的一些错误判断具有不可替代的作用。
回顾中国人口的发展历史,20世纪60年代总和生育率围绕6高位波动,70年代后受计划生育政策及社会经济发展等多重因素的影响,总和生育率大幅度下降,90年代初已经降至更替水平之下,当时人口统计数据对人口重大转变和生育水平显著变化的描述并未引起较大争议。然而,1992年以后,伴随着2000年人口普查的总和生育率1.22以及2010年人口普查的总和生育率1.18,人口统计数据受到前所未有的质疑。第七次全国人口普查(简称“七普”)数据显示总和生育率为1.30,相较于“五普”“六普”有所提升,但仍处于超低生育水平,与更替水平相比存在很大差距。经典的数理人口模型和国际经验证实,生育水平长期远低于更替水平,对未来人口规模、年龄结构乃至社会结构会产生诸多不利影响。“七普”能否结束历史上对总和生育率的争论,不仅关系到对中国生育转变过程和历史的认识,同时也关系到对目前和今后生育水平变动趋势的判断。
有学者认为,根据生育水平与社会经济发展关系的相关研究分析,新世纪之后总和生育率不可能低至普查数据所反映的水平[1],普查结果可能存在漏报以及统计误差等问题[2],时期生育率不仅没有反映而是扭曲了真实生育水平。[3]为此,不少学者通过其他来源数据,运用多种统计方法对普查数据进行调整。不同学者的研究结论并不一致,总体上认为2000年总和生育率在1.8左右,2010年在1.7左右[2],显著高于普查数据结果。尽管不同学者的分析及间接估计结果对总和生育率低于更替水平没有争议,但对总和生育率到底处在什么水平以及生育水平的变动趋势尚未达成共识。
为扭转持续低生育水平局面,2013年、2015年、2021年三次调整生育政策,从“单独二孩”到“全面两孩”再到“三孩政策”,生育限制逐步放开。生育政策的调整释放部分生育潜力,2014年、2016年出生人口规模均有所提升。据此,部分学者对生育政策调整效果持乐观态度,认为生育政策调整能扭转低生育陷阱困境,[4]使得未来总和生育率在较高水平波动;但也有学者认为生育政策调整对于提高生育水平的刺激作用有限,其政策效果基本殆尽,未来进入低生育率陷阱不可避免。[5][6]
随着“七普”相关统计数据的陆续公布,为考察2010年之后生育水平变动情况提供更加丰富、更具时效性的数据支持。国家统计局也以“七普”数据为准,重新调整了2011—2019年总人口与出生人口规模,这势必会影响对2020年之前总和生育率水平及变动规律的判断。尽管有学者已经根据调整后的出生人口数据,对2011—2019年总和生育率水平重新进行估计,[7]但是目前仍未有学者基于“七普”数据,对2000年以来总和生育率及其变动趋势进行分析。《中国统计年鉴(2021)》公布了“七普”的年龄结构数据,而年龄结构是反映人口总量、结构及其变动过程最基础、最关键的信息,而且也是人口普查有别于其他人口统计调查不可替代的重要原因和最重要的成果。年龄结构数据为深入研究育龄妇女的总和生育率和变动趋势提供了丰富的基础信息,可以根据“七普”年龄结构数据估算2020年及以前中国育龄妇女的生育率水平。同时,针对“七普”数据与历年人口变动抽样调查数据结果的差异,探讨差异产生原因,以期对出生规模、生育水平乃至相关社会发展指标进行科学分析。
二、研究方法与数据来源
尽管“七普”单岁组年龄结构数据并未公布,但《中国统计年鉴(2021)》公布了2020年五岁组年龄结构,即“七普”数据结果。为了研究总和生育率以及相关社会发展指标的变化趋势,本文需要解决三个难题:第一个难题是利用“七普”现有相对粗略的年龄结构数据推算普查时点更加详细的人口年龄结构;第二个难题是在普查时点年龄结构的基础上获得历史人口的年龄结构;第三个难题是在获得历史人口时间序列年龄结构的基础上,推算对应年份的总和生育率,从而获得生育水平的历史变化趋势。
(一)研究方法
数据和方法相辅相成,从数理人口学基本原理出发,构建相关的推算模型并计算相关指标。这一方面体现在有限数据条件下的研究方法和分析技术的科学性,另一方面也体现对关键数据的合成与分解的可行性和科学原理的可靠性。目前公开的“七普”数据仅为五岁组年龄结构数据,不能完全满足估算总和生育率的需求,因此需要在此基础上提出与基础数据相适应的研究方法,并结合其他来源数据,运用相关人口分析技术,获得所需的缺失数据。
1.年龄结构间接估计
将五岁组年龄结构分解为单岁组年龄结构有两种方法。方法一为“比例分配法”,利用第六次全国人口普查数据对2019年人口抽样调查年龄结构数据进行调整,计算各队列间规模的相对比例关系,假定这一关系不变,按照队列间比例关系和2020年人口普查公布的出生人口数将“七普”数据五岁组年龄结构分解为单岁组年龄结构,而针对低龄组缺失的问题,可利用各年出生人口规模进行补充,在按比例分配的同时,满足5个年龄组的合计与“七普”数据相等;方法二为“预测分配比例法”,以已知年龄结构年份的人口数据为基础,预测2020年人口年龄结构,并根据2020年五岁组年龄结构对预测结果进行调整。
2.总和生育率间接估计
总和生育率间接估计方法参考王广州[8]的研究,具体而言分为两步。首先,借助“逆存活”的思想,利用“七普”数据人口年龄结构与年龄别人口存活概率,通过回溯方法估算各年的年龄结构。[9][10]具体算法为:
nPt1x=nPt2x+n * (nLx / nLx+n)
其中,nPt1x和nPt2x+n分别表示t1、t2时刻x岁至x+n岁、x+n岁至x+2n岁人口数,nLx和nLx+n则分别表示确切年龄在x至x+n队列、x+n至x+2n队列存活人年数。由此可估算出2020年之前若干年的年龄结构,用以确定各年育龄妇女年龄结构和出生人口规模。
其次,确定年龄别生育率的取值范围和可接受出生人口规模偏误的最大误差。间接估计总和生育率的思想本质上是以出生人口数为目标函数,以育龄妇女年龄结构为给定条件,求解年龄别生育率最优解的过程。根据历史数据设定各年龄育龄妇女生育率的最大值和最小值,在此范围内利用全局优化的思路,以出生人口规模为目标函数计算得到生育模式的最优解,以此作为当年总和生育率间接估计结果。
(二)数据来源
此前,利用“七普”数据估算总和生育率的研究多以人口抽样调查数据或“六普”数据确定育龄妇女年龄结构,[7]这造成生育子女数用“新数”,育龄妇女数用“旧数”的问题,“七普”数据与“六普”数据、人口抽样调查数据误差大小直接影响估算结果的准确性。以“七普”五岁组年龄结构估算“七普”单岁组年龄结构,能够避免育龄妇女、生育子女数据新旧不统一的问题。采用本文提出的年龄结构分解和估算方法,“七普”单岁组年龄结构的估算结果见图1。除此之外,为了获得总和生育率的变动历史,需要在“七普”年龄结构的基础上利用年龄结构间接估计方法,得到“七普”以前各个年份的单岁年龄结构,在年龄结构间接估计的基础上估计各年份的总和生育率。为了实现历史数据的重建,还需确定生育模式、死亡模式、预期寿命、出生性别比等人口信息,本项研究相关模式的统计推断和遗传算法的搜索空间参考人口抽样变动调查数据、2010年、2015年人口(小)普查资料的相关数据。
三、总和生育率间接估计
根据2010年、2020年人口普查和2019年人口变动抽样调查数据,利用比例分配法(方法一)和预测分配比例法(方法二),得到2020年单岁组年龄结构,并以此为基础估计我国2005—2020年的总和生育率,得到以下主要结论。
(一)“七普”数据显示,总和生育率先增后减
测算结果显示,2005—2020年总和生育率整体呈现先波动上升,后波动下降的变化趋势。2005—2015年总和生育率波动上升,从2005年的1.31—1.45增至2015年的1.74—1.91,10年间增长约0.29—0.60。随后总和生育率开始下降,从峰值1.7以上下降至2020年1.3,5年间减少约0.4—0.6。两种方法的估计结果略有差别,但整体趋势接近,与以往其他学者研究结论相比,既有一致性,又存在一定的差异。
1.对总和生育率水平的估计与其他学者研究一致
从以往研究可以看到,不论运用何种方法,采用什么数据,研究结论均一致认为,2010年之后总和生育率水平高于人口变动抽样调查数据结果。例如,采用统计局调整后的出生人口规模,测算2011—2019年总和生育率均值约为1.65,[7]采用2017年生育状况抽样调查数据,测算2010—2016年总和生育率均值约为1.63,[11]本研究利用“七普”数据间接估计2010—2020年总和生育率均值约为1.61(方法一)。由于研究年限存在差别,“七普”数据结果略低于其他来源数据对总和生育率的估算,但“七普”数据估计结果与人口抽样调查数据之间的差距和冲突仍旧非常明显,与“七普”数据估计结果相比,以往调查数据有可能低估总和生育率,但具体低估多少还需要进一步讨论。
2.对总和生育率趋势的判断与其他学者研究差异
统计局调整后出生人口数据以及2017年生育状况抽样调查数据的测算结果均显示,2015年总和生育率相对较低,在全面两孩政策实施之前,2010—2015年总和生育率整体呈现下降趋势,全面两孩政策扭转了总和生育率持续走低的局面,推动生育水平攀升。[7][11]然而,本研究测算结果显示,全面两孩政策实施前,总和生育率呈现上升趋势,2013—2014年总和生育率处在1.7以上的水平,全面两孩政策实施后,总和生育率没有保持增长势头,转而开始快速下降。同时,全面两孩政策实施前,总和生育率有可能达到2010—2020年的局部峰值,且不低于全面两孩政策实施后的生育水平。根据统计学基本理论可以推断,总和生育率局部峰值具体出现的年份与五岁年龄组分解的可靠性有关,但5年的累计或平均与分解得到的平均误差不大。

表1 2005—2020年总和生育率间接估计
(二)与人口抽样调查相比,“七普”反映出更高的生育水平
根据“七普”数据间接估计得到的总和生育率与历年人口变动抽样调查数据相比显示出截然不同的变化趋势,两者存在较大差异。
1.从变动趋势考察,整体上两者变动趋势相反
绝大部分年份“七普”数据间接估计与人口变动抽样调查数据计算结果的增减趋势一致,但对2014—2015年总和生育率测算结果的差异,造成两者整体变动趋势完全相反。其中,前者测算2015年总和生育率达到1.74—1.91,为2005—2020年局部(次)峰值,而1%人口抽样调查计算2015年总和生育率为1.05,仅略高于2011年计算结果。因此,基于“七普”数据间接估计结果,认为2005—2015年总和生育率波动上升,此后快速下降;而基于人口变动抽样调查测算结果,则认为2005—2015年总和生育率波动下降,此后波动上升。
2.从相对水平分析,整体上两者水平差距较大
除个别年份两者对总和生育率水平的判断较为接近,绝大部分年份两者存在较大差异。其中2009—2016年,基于“七普”数据间接估计总和生育率比人口变动抽样调查数据测算结果高20%以上,而极个别年份两者差距更是高达60%—80%,2015年两者差距最大,“七普”数据间接估计结果比人口变动抽样调查数据测算结果高65.7%—81.8%。不论变化趋势还是相对水平,抽样调查结果与普查结果均存在较大差异。如此大的差异全部由抽样误差导致的可能性较小,有理由相信抽样调查数据受人为因素干扰等非抽样误差问题影响,造成与普查数据存在较大的偏离。同时,也不排除“七普”数据存在偏差的可能性。
四、“七普”数据与人口抽样调查存在差异原因探讨
由于“七普”数据与历年人口变动抽样调查数据有很大差异,这个差异必然影响到对社会发展状况的判断。此前基于人口变动抽样调查数据的测算结果,认为21世纪以来总和生育率持续降低,2010年之后更是低至1.30以下的低水平;然而,“七普”数据的间接估计结果则表明,在实施全面两孩政策之前,总和生育率水平并没有人口抽样调查数据那么低,相反2005—2015年总和生育率呈现波动增长的变动趋势。而对于全面两孩政策效果的判断,基于人口变动抽样调查数据结果,认为政策一定程度上扭转了低生育水平局面,推动2016年、2017年生育水平显著提高;而基于“七普”数据间接估计结果,2015年总和生育率已经维持在相对较高的水平,全面两孩政策不仅没有明显推动2016年总和生育率进一步提高,呈现的结果反而是2016年总和生育率开始下降,且此后总和生育率加速下降,政策效果完全未发挥。
“七普”数据与人口变动抽样调查数据均为统计局公布的官方数据,但两者对于近期生育水平的刻画呈现出完全不同的结论。为正确认识2005—2020年总和生育率变动规律,需要对两者存在的差异做进一步探讨。
(一)“七普”数据质量进一步分析
历年人口变动抽样调查历经多次,且各年份调查结果之间并不存在较大差异,对总体的推算结果较为稳定,这从统计学基本原理来看,历年人口变动抽样调查结果更具有一致性和可靠性。“七普”是否高估了近期总和生育率水平?取决于“七普”是否高估了低年龄人口规模或低估了年龄别育龄妇女的人口规模。
“七普”公报认为,本次人口普查漏登率仅为0.05%,相较于“六普”,数据质量显著提高。虽然漏登率明显降低,但仍有两方面隐患影响“七普”数据质量,其一是重复登记问题,“七普”公报中仅公布数据漏登情况,并未涉及数据的重登问题,实际上,数据遗漏登记和数据重复登记是衡量数据质量的两个方面,漏登率低并不能检验数据的重复登记问题;其二是漏登率在不同年龄阶段存在差异,“七普”公报中公布的漏登率为总体数据质量情况,不同年龄阶段的漏登情况可能存在较大差异,导致以“七普”数据探讨某个年龄段的人口规模时仍然不可避免存在比较大的偏差。
以“六普”与“七普”中相同队列低年龄人口规模为对象,直接对比两次人口普查数据的数据质量。理论上,相同队列在“七普”中的规模应当小于“六普”中的规模,然而分析2010年0—19岁队列(对应2020年为10—29岁队列)规模,可以发现,除了15—19岁队列人口规模出现明显下降外,其余队列规模均呈现上升趋势,且越是低龄组,规模增幅越大,0—4岁队列(对应2020年为10—14岁队列)规模10年间增长了972.34万人(见表2)。这既可能是由于“六普”数据中低年龄人口漏登严重造成,也可能是由于“七普”数据中低年龄人口存在重登情况而造成。
与此同时,“六普”数据低年龄人口规模反映出的漏登情况,也远比“六普”数据公报中的漏登率严重。公报中“六普”数据的漏登率为0.12%,根据“六普”总人口,计算相对应的漏登总人口约为160万,而比较“六普”与“七普”低龄人口规模差距,0—4岁队列、5—9岁队列、10—14岁队列(对应2020年分别为10—14岁队列、15—19岁队列、20—24岁队列)差距分别为972.34万人、180.26万人、3.32万人。这说明,各年龄组的数据质量与总体数据质量之间可能存在较大差异,总人口规模误差很小并不意味着各年龄组的数据质量均较高,存在误差相抵提升总体判断精度的情况。同样,尽管“七普”数据整体漏登率很低,但这并不意味着各年龄段的漏登情况均较低,若对于育龄妇女群体的漏登情况较为严重,则必然高估生育水平。
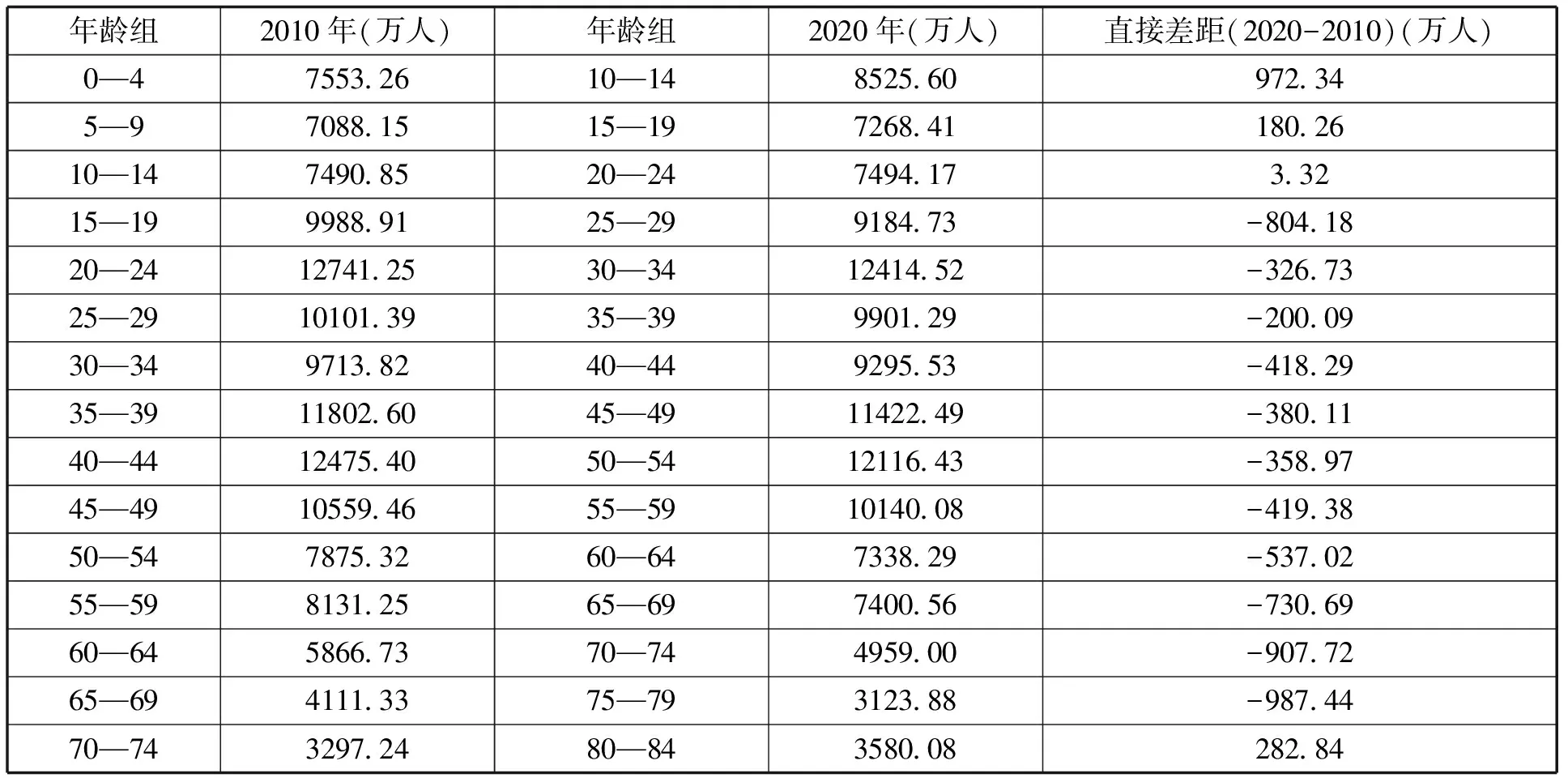
表2 “六普”与“七普”相同队列数据对比
1.高估了低龄群体规模
“七普”数据中低龄组存在较为严重的重复登记问题并非不可能。本次人口普查对技术手段进行了革新,采用电子化数据采集方式,以身份证号等多种识别字段确保不存在数据的重复录入。因此,理论上本次人口普查的重登率应非常低,但仍有一些人为因素或动机可能造成重复登记低龄组人口的问题。
第一,为保留农村基础教育资源,增加农村低年龄人口数量。2001年《国务院关于基础教育改革与发展的决定》中要求,因地制宜调整农村义务教育学校布局,整合农村义务教育资源,一批学生数量较少的农村义务教育学校被裁撤,被裁撤学校的学生只能到附近村、镇、县里的学校上学,带来了上学路程远、上学路途危险、上学成本增加等一系列问题。尽管随后“撤点并校”行动被紧急叫停,但为保留农村义务教育资源,部分地区农村存在着虚报义务教育学生数量的动机。又因此类问题可能集中存在于特定地区,在进行人口抽样调查时,这一问题并未充分暴露,虚报的学龄人口对于总体的推断未产生较大影响;而在人口普查时,普查数据直接反映人口基本情况,如果存在且虚报的学龄人口全部被加总到对应的年龄人口中,必然造成“七普”数据对低龄群体的高估。
第二,为保留农村土地利益,隐瞒子女户籍迁移情况。现行的土地制度仍以户籍制度为基础而构建,户籍制度是农村土地分配的依据,拥有农村户籍也是享受农村土地确权的基本前提。[12]而在户籍改革的过程中,并未彻底剥离附着在城乡户籍上的公共服务与社会福利,集体经济组织成员身份愈发成为农民取得农村土地要素的唯一条件。[13]为了让子女在享受城镇教育资源的同时,不丧失农村的土地利益,部分家庭采用城镇、农村各保留一个户口的手段。2010年之后,户籍制度改革步伐加快,“双户籍”问题随之愈加严重,而2011—2019年人口抽样调查,抽样框按照“六普”编制,10年间并未进行调整,[14]这可能无意间反而使得历年人口抽样调查数据并未受“双户籍”低龄群体的影响,而“七普”时,“双户籍”问题可能已经积累了数十年,在进行人口普查时充分暴露,存在高估低龄人口规模的可能性。
第三,为凸显计划生育工作成效,虚报低年龄人口规模问题由来已久。在独生子女政策时期,为了满足计划生育目标和指标要求,需要采取瞒报的手段使生育水平达到或接近政策生育水平,因此,低龄人口数据质量问题比较突出。尽管伴随着生育政策的逐步调整,“计划生育”已经成为历史,但这并非意味着计划生育工作的停止,不仅历史“欠账”需要消化,而且当前中国仍然面临新的生育和以人口规模为依据的公共资源配置问题,以生育和人口规模为考核指标的利益驱动问题并未从根本上解决。
第四,全面两孩政策低龄人口补登。2015年全面两孩政策的实施,标志着传统意义上独生子女政策的结束。这使得部分在计划生育政策背景下原“计划外”低龄人口既往不咎,因此能够被重新登记。在“补登”过程中可能存在登记失误,将登记年份记录为出生年份,造成对2011—2015年出生人口数高估的情况。在进行当年人口抽样调查时,户籍登记工作仍在继续,此类问题并不严重,而到了2020年进行“七普”时,户籍登记和清理清查工作完成,出生年份登记错误问题充分暴露,最终导致推算的2011—2015年总和生育率水平过高,对总和生育率的变化趋势产生错误判断。
总之,由于微观上利益驱动和“趋利避害”,在宏观上表现为人口统计的内在利益动机,而利益动机则可能成为选择性扭曲低龄人口数据的重要因素。此外,从人口变动内在逻辑来看,理论上生育政策调整的政策效果会有时滞,理想的状态下,生育政策释放出的生育潜力也需要10个月时间才能够显现,因此2015年全面两孩生育政策调整,其直接影响应当是对2016年的出生人口数和生育水平。而根据“七普”数据推算的总和生育率显示,2016年总和生育率相较于2011—2014年并没有显著升高,这在一定程度上也反映出,“七普”数据对于2011—2015年出生人口规模的刻画,似乎并不太符合逻辑,可能存在问题。
2.低估了育龄妇女群体规模
对于生育水平高低的测量,一方面取决于出生人口规模,另一方面取决于育龄妇女总量、结构。如“七普”数据中育龄妇女数量可能存在漏登问题,也同样会扭曲对生育水平的判断。本次普查人口漏登率很低,但不同年龄人口漏登情况不尽相同,可能存在育龄人口数量漏登情况严重的问题。比较“六普”与“七普”相同队列人口规模变动情况,“七普”数据中处于生育活跃期的育龄人群规模下降明显,特别是25—29岁队列(对应2010年为15—19岁队列),减少人数超过800万,显著高于其他育龄群体。排除死亡及“六普”数据对育龄群体规模高估的问题,育龄群体队列减少人数异于正常水平,反映出“七普”数据对于育龄群体可能存在漏登问题,其原因可能存在于以下几个方面。
第一,对于流动人口群体的遗漏登记造成低估育龄妇女群体。众所周知,流动人口由于其不确定性,在任何调查、登记过程中都是影响数据质量的关键群体。与非流动人口不同,流动人口居住本地时间、流动范围和行政登记边界等界定问题导致数据质量不高的问题一直存在。与之前历次人口普查类似,人口流动是造成育龄妇女群体漏登的原因之一,流动人口在流入地和户籍地之间的流动造成对流动人口的登记存在一定困难,导致无法正确认识中国生育水平。[15]当前,部分流动育龄妇女仍保留在户籍地生育的习惯,特别是临产阶段的流动容易造成对育龄妇女的统计遗漏。分析2012—2016年流动人口动态监测数据,在2010年发生生育行为的流动妇女中,约有45%的流动妇女生育行为发生在户籍地。这种情况很容易造成在进行第六次全国人口普查时,对流动育龄妇女的登记存在遗漏,她们既没有被流入地的人口普查登记,也没有被户籍地的人口普查登记,从而低估流动人口群体的生育水平,并最终对总和生育率的判断出现很大偏差。虽然本次普查加入了身份证识别信息,但对于流动育龄妇女的登记同样可能存在“重漏”和“落地”等扭曲生育状况的问题。
第二,育龄妇女出国比例增加造成对其规模的低估。青年女性出国留学和移民比例不断增加,长期累计的结果也可能造成育龄妇女规模“缩小”,从而高估育龄妇女的生育水平。21世纪以来中国出国留学规模呈现快速增长趋势,2009年留学生规模达到22.9万人,2011年增至34.4万人,2012年突破40万人,2015年增至52.4万人,2017年达到60.8万人,2019年增至70.4万人。留学生中女性占比逐渐增加,英国诺丁汉大学中国政策研究所网站2016年刊文指出,在一些西方国家的中国留学生群体中,女性占比渐多。其中缓解催婚压力、提高职业竞争力、为移民做准备等因素促使越来越多的女性选择出国留学,相较于男性,女性在社会科学、人文与艺术等专业有更高的留学倾向。[16]并且,由于“七普”时国外疫情相较于国内情况更为严重,对于境外人员入境实施严格管制,滞留境外人员的回国成本骤增,因此部分留学生在进行人口普查登记时是否能够完全申报尚有疑问,这在一定程度上可能造成对育龄妇女群体登记的遗漏,最终导致低估育龄妇女群体规模,高估生育水平。
(二)历年人口变动抽样调查数据质量不高
由于人口变动抽样调查是以人口普查数据为基础构建抽样框并进行抽样的,抽样误差必然存在。从样本与总体的逻辑关系来看,人口普查数据质量更高则理所当然。然而,数据质量的高低不仅是抽样误差造成的,同时非抽样误差的影响有可能更大,这取决于调查队伍的基本素质、人均工作量、质量控制及调查方式。从世界各国调查设计、实施和以往的调查经验来看,普查数据质量更高。国家统计局根据“七普”数据,重新调整了2011—2019年我国总人口和出生人口规模,说明国家统计局更认可“七普”数据。事实上,早在“七普”数据公布之前,已有大量研究根据其他来源数据、运用多种统计方法、考虑生育水平与社会经济发展关系、参考其他国家历史发展经验等多种视角,质疑人口抽样调查数据估算的总和生育率,认为2010年之后,总和生育率仍然维持在1.5之上。2017年国家卫生健康委组织开展“2017年全国生育状况抽样调查”,其数据结果直接否定了第六次全国人口普查和2015年全国1%人口抽样调查数据对生育水平的判断,认为2006—2016年中国总和生育率总体维持在1.6以上,显著高于历年人口变动抽样调查数据计算的结果,这意味着与此相对应总人口规模也一并被否定。“七普”之前,多次进行人口变动的抽样调查,均未能正确反映出真实的生育水平,反而以看似合乎规律的结果持续低估总和生育率,对“二孩”政策执行前生育水平变动趋势的判断在逻辑上也是难以自洽,其原因可能存在于以下方面。
历年人口变动抽样调查,抽样比约为1‰,样本量约为120万。这意味着每一个样本的基本信息代表了全国1000个人的基本情况,这要求对小概率事件进行统计推断的抽样和非抽样误差都非常小,如稍有偏差就可能造成对总体推断的很大偏误。在实施人口变动抽样工作时,诸多环节均可能导致抽选样本存在偏误。
第一,抽样框相对固定,并未根据人口变动进行调整。在“七普”数据公布后,针对其与2011—2019年人口抽样调查数据反映出的差异化信息,国家统计局就进行了回应,其中抽样框相对固定,未随人口变动进行调整是其解释的主要原因。[14]若这一原因成立,则说明从“六普”到“七普”,中国人口形态发生重大变化,其中生育行为变化尤为明显,在此前被认为具有同质化生育行为群体内部,也发生了较大变化。
我在城市里穿梭着,手里提着只蛇皮袋,从那些垃圾箱里寻找着可以回收的垃圾:可乐瓶、纸箱、旧衣服。差不多每次出门,我都要穿越幸福大街从门球场经过。大多数时候,我一手提着那支名牌的门球棒,一手提着蛇皮袋匆匆而过。因为翻找垃圾,门球棒已经污秽不堪,蛇皮袋也散发出臭味。那些打门球的老人疑惑地看着我,不清楚我这个住楼的怪老头拿着蛇皮袋和名牌的门球棒要做什么,毕竟这两件东西之间的差距如此之大。偶尔,我也会停下来。那是因为我想起了吴小哥,想起了我与吴小哥扯闲篇的日子,想起了他心里青山绿水的古家庄。
第二,调查工作人员调查经验不足,影响最终调查数据质量。不同于人口普查,历年人口抽样调查并无国家统一领导与管理,抽样调查工作层层下放至各基层单位,由地方自主制定调查计划,完成调查任务。[17]并且,在最终的入户环节,通常也不是由专业调查人员承担,而是由社区、街道、村镇的工作人员兼任。这就造成在确定抽样规模、选定抽样对象、制订抽样计划、实施调查工作等环节,都可能由于工作人员不够专业,造成抽样调查数据不准确,影响数据质量,以此为基础数据推算整体数据时存在偏误,导致低估生育水平。
第三,抽样调查工作量较大,难以保证抽样的准确。尽管人口抽样调查总体的抽样比并不高,但是按照比例逐级下放到基层行政单位,在城镇人口、流动人口、人户分离、城镇多套住房比例不断上升以及农村的空心化等背景下,在特定时间内按户或按人找到抽中调查对象需要进行大量的重复访问或替换样本,这种不确定性和接触调查对象难的问题造成在人口抽样调查时,基层行政单位、调查人员获得成功访问特定调查对象效率较低,工作量非常大,其结果是调查难度也来越大、样本的选择性也越来越强。[17]
第四,受访者情况复杂,调查难度加大。目前,随着社会经济快速发展,人员流动频繁,就业形式复杂多样,受访人员可能面临各种情况,对入户调查工作人员带来较大困难。同时,伴随现代社会信息传播能力的增强和信息传播影响的不确定性,受访者对于自身隐私的注重程度也越来越高,对于人口抽样调查的配合程度较差,拒访、隐瞒等情况有可能发生。特别是在实施“二孩”政策之前,不少“二孩”仍属于“计划外”生育,受访者主观上有隐瞒生育情况的动机,最终影响出生人口规模的判断,低估出生人口规模。
总之,自“计划生育”政策实施以来,生育相关数据成为敏感信息。在育龄妇女生育水平与政策生育率差距较大的时期,地方计划生育工作单位有动机瞒报当地出生人口规模,使得年末出生人口看上去被“控制”在任务目标之内,抽样调查过程中瞒报计划外生育,由此低估了真实的生育水平。
以上分析从“七普”数据与人口变动抽样调查数据两个维度,分别阐释可能对数据质量产生影响的原因。一些学者根据生育数据,对历年人口变动抽样调查数据质量存疑,认为“七普”数据质量较高,能真实反映中国“六普”到“七普”之间人口变化基本规律。然而,本文基于“七普”数据,间接估计2005—2020年总和生育率,不论是与人口变动抽样调查数据还是与其他学者的调整结果相比,均存在一定差距,排除间接估计的计算误差,这一结果表明,可能“七普”数据也存在一定的质量问题。如果承认“七普”数据质量较高,能反映中国过去人口变动真实情况,那么由于人口变动存在其规律性,基于“七普”数据逻辑推演得到之前年份的生育水平、出生人口规模等数据均与历年人口变动抽样调查数据存在一定差距,这造成在计算与出生人口相关的统计指标时,基于“七普”数据的计算结果与目前公布的结果存在差异,进而对正确认识近十年甚至更长时间中国社会发展真实情况产生影响。究竟是“七普”数据更准确,还是目前公开数据都或多或少存在一些比较明显的缺陷,要弄清这一问题,只能等到“七普”详细数据公布后,得到2020年更为详细的年龄结构数据、生育模式数据、死亡模式数据,才能进一步确认。
五、相关社会发展指标的再认识
“七普”数据的公布,改变了对“六普”以来生育水平及其变化趋势的判断,整体分析,“七普”数据结果显示历年生育水平更高、出生人口更多。如若认定“七普”数据的质量更高,更能准确反映真实情况,那么“七普”的年龄结构数据使得此前基于较小出生人口规模计算的统计指标产生相应变化,由此可能引起一系列“连锁反应”。为了防止对当前社会发展水平的误判,甚至出现认识上的偏差,有必要重新调整计算相应指标。假如完全按照国家统计局对以往出生人口、低龄人口规模的调整,则需要对相关社会发展指标也按照“七普”数据进行调整。由于实际出生人口规模比利用人口变动抽样调查数据估算的结果更大,低龄人口数量更多,相应的社会发展统计指标则必然降低。这个新情况对于正确认识当前中国社会发展状况存在影响。从研究的角度看,需要重新审视历史数据究竟是被高估还是被低估,并对实际发展情况进行科学分析,使研究结果与真实情况更加接近。
(一)小学净入学率更低
计算小学净入学率,以小学学龄的儿童规模为分母,以小学学龄的入学儿童规模为分子,剔除分子中仍在读小学,但超过小学学龄的儿童数量。因此相较于小学毛入学率,小学净入学率水平更低,与年龄的对应关系更强。
伴随教育事业的发展,义务教育普及率快速提升,小学净入学率呈现持续上升的趋势,根据《中国教育统计年鉴》(简称《教育年鉴》)数据,小学净入学率整体水平超过99%。然而,与以往教育统计年鉴掌握的基础数据不同,“七普”数据估算的2005年及以后的出生人口总量明显增加,如果在校学生人数不变,理论上相应的小学学龄儿童人口规模更大,由此推算小学入学水平必然下降。
按照“七普”数据测算结果,2005年及以后出生人口规模增加,对应小学学龄人口6—11岁的年龄范围,理应2011年及以后小学净入学率变化明显。结果显示,2011年、2012年,按照“七普”数据测算的6—11岁儿童规模反而小于《教育年鉴》公布的小学学龄的入学儿童规模,这表明“七普”数据估算2007年及以前的出生人口规模更低,相较于《教育年鉴》数据存在低估现象。
2013年及以后,根据“七普”数据计算的小学净入学率显著低于《教育年鉴》公布数据。其中后者公布2013年小学净入学率为99.71%,按“七普”数据估算结果显示小学净入学率在96.31%—97.67%之间,两者差值达到2.04—3.40个百分点。2015年“七普”数据估算的小学净入学率比《教育年鉴》低2.56—6.17个百分点,2018年两者差值为3.55个百分点。整体考察,2013年以后“七普”数据估算出生人口规模更大的效果在小学净入学率上得以充分体现,重新估算的小学净入学率平均比《教育年鉴》数据低3.18—4.61个百分点。

表3 2005—2018年小学净入学率比较
(二)婴儿死亡率更低
婴儿死亡率是测量平均预期寿命最重要的基础数据,被看作是国家卫生事业发展、人口素质提升的重要指标,婴儿死亡率越低,意味着国家卫生事业发展水平越高,人口整体健康状况越好。按照《中国卫生健康统计年鉴》(简称《卫生年鉴》)公布数据,2005—2020年,婴儿死亡率持续下降,从19.0‰降至5.4‰。但如果婴儿死亡人数不变,以“七普”数据测算,2005—2020年,婴儿死亡率持续下降趋势仍旧明显,整体维持在比《卫生年鉴》更低的水平,从14.38‰—16.01‰降至5.42%。
根据“七普”数据测算结果,2016年之后总和生育率快速下降,生育水平与人口变动抽样调查公布的水平相近。而这在计算婴儿死亡率时有所体现,2016年及以后,根据“七普”数据估算的婴儿死亡率高于《卫生年鉴》公布结果,但两者差距不断缩小,其中2016年“七普”推算数据比《卫生年鉴》数据高0.16—0.34个千分点,2020年两者仅相差0.02个千分点。整体考察,2005—2020年,根据“七普”数据结果估算婴儿死亡率更低,与《卫生年鉴》公布数据的差距不断缩小,平均整体下降1.78—1.91个千分点。
(三)住院分娩率更低
按照《卫生年鉴》公布数据,2005—2020年住院分娩率持续增加,从85.9%增至99.9%。然而“七普”数据测算结果显示,2005—2015年出生人口数更多,由此计算的住院分娩率更低,平均比《卫生年鉴》公布数据低18.89—19.53个百分点。2016年及以后,按“七普”数据估算的出生人口数低于《卫生年鉴》公布的住院分娩数,重新计算的住院分娩率超过100%,偏离实际情况。整体考察,根据“七普”数据测算结果,2005—2020年住院分娩率持续上升,但整体水平低于《卫生年鉴》公布数据,平均低12.89—13.28个百分点。

表4 2005—2020年婴儿死亡率、住院分娩率比较

表4(续)
总之,由于国家统计局根据第七次人口普查数据重新调整了过去2011—2019年的出生人口数,但并没有相应地对其他数据一并进行调整,这就形成了与以往社会发展指标之间的冲突或矛盾,对于这个问题的产生和影响还需要进一步深入研究。
六、结论与讨论
本文利用“七普”数据间接估计2005—2020年总和生育率水平。结果显示,与历年人口变动抽样调查数据以及之前人口(小)普查数据不同,在2011—2015年,总和生育率整体上处于较高水平或呈现上升趋势,全面两孩政策对生育水平的提升效果非常不明显。不论是在水平上还是在增减趋势上,均与此前数据以及学者的研究结论存在很大差异。
首先,从趋势上分析,“二孩”政策实施前,总和生育率曾短暂达峰。在此之前,不论是人口抽样调查数据还是其他学者基于不同来源数据估算生育水平均显示,自总和生育率跌破更替水平之后,到2015年全面两孩政策实施之前,生育水平整体呈现下降趋势。而“七普”数据间接估计结果则表明,2005—2015年,生育水平整体维持在1.6以上的水平,并不存在明显的下降趋势,在实施全面两孩政策之前,总和生育率达到2005—2020年的局部峰值。
其次,从水平上分析,“二孩”政策效果并不理想,未摆脱低生育陷阱。人口抽样调查数据低估生育水平已被大多数学者“证实”,并运用多种方法对总和生育率进行调整,只是这种调整结果与“七普”数据反映出来2016年之后总和生育率水平并不一致。此前学者的调整结果认为“二孩”政策扭转生育水平持续低迷局面,使得总和生育率在“二孩”政策之后依旧维持在1.5以上的水平,但“七普”数据测算结果却显示,“二孩”政策可能只发挥延缓生育水平下降的作用,其并未改变生育水平下降的趋势,政策期内未能显著提振生育水平,政策期后未能遏止生育水平加速下降趋势。
基于两者的差异,从主观与客观层面,分别探讨影响“七普”数据与人口变动抽样调查数据质量的因素,以期能确定生育水平与出生人口规模的真实水平。
第一,主观因素影响数据质量。不论是“七普”数据,还是人口变动抽样调查数据,均有可能受主观因素影响数据质量。自20世纪80年代计划生育成为基本国策始,生育问题成为各级政府的工作重心之一,生育数据的敏感程度逐步加深,其真实性受到质疑,存在着人为干预生育数据的可能性。在生育限制放宽之前,存在各方质疑生育数据的声音,即便如今生育限制已经逐步放松,但长达30多年的“计划生育”对生育数据产生的深刻影响短时间内难以摊平,为了保持数据的一致性,摊平周期可能会相当长。而在数据问题完全被稀释前,之后的人口抽样调查或人口普查数据质量均可能继续受到人为因素的影响,从这个角度分析,“七普”数据与人口抽样调查数据的真实性均存疑。
第二,客观因素影响数据质量。相较而言,客观因素对人口抽样调查数据质量的影响较大,本次人口普查采取更为先进的技术手段,借助电子设备、网络平台,最大程度提高数据质量。但仍需要注意可能针对不同群体,其数据质量可能存在差异,特别需要关注子女出生年份的错误登记,对于流动育龄妇女、境外育龄妇女的遗漏登记等问题,因其群体规模并不大,所以对于整体数据质量影响不明显,但在分析特定群体时,这种错误、遗漏可能就会带来较为明显的影响。而对于抽样调查数据,从抽样框的选取、调查工作的开展,到对整体数据的推断,每一个环节均有可能造成数据的偏误。
若不能及时厘清“七普”数据与人口变动抽样调查数据之间的矛盾,将影响与人口相关的社会发展指标的计算,难以对社会发展水平作出正确判断。按照“七普”数据估算结果,2005—2020年整体上生育水平更高,出生人口规模更大,由此计算小学净入学率更低,孕产妇住院分娩率也更低,影响对近期教育事业和卫生事业发展水平的判断。总之,考虑到“七普”数据与人口抽样调查数据之间如此之大的差异,客观原因对数据质量的影响程度可能较小,其偏误主要由主观原因造成,“七普”数据推断历史生育水平存在人为高估的可能性,而人口抽样调查数据也存在人为低估生育水平的可能,实际生育水平介于两者之间的可能性更大,而且,2011—2015年“七普”数据存在高估生育水平的可能性,2015年以后实际生育水平可能更接近由“七普”进行的统计推断。
