基于带宽优选地理加权回归模型的深圳市植被碳储量反演
2022-08-03蒋馥根王天宏陈川石
龙 依,蒋馥根,孙 华,*,王天宏,邹 琪,陈川石
1 中南林业科技大学 林业遥感信息工程研究中心,长沙 410004 2 林业遥感大数据与生态安全湖南省重点实验室,长沙 410004 3 南方森林资源经营与监测国家林业与草原局重点实验室,长沙 410004 4 国家林业和草原局中南调查规划设计院,长沙 410004
城市植被作为城市生态系统的重要组成部分,对维持城市碳氧平衡、改善城市小气候至关重要[1]。随着碳达峰、碳中和等目标的提出,城市植被在碳汇功能中的作用得到广泛关注[2—3]。植被碳储量作为评估植被碳收支的重要参数,能直接衡量植被固碳增汇能力,是生态系统服务功能的直接体现[4]。迅速、准确地估算城市植被碳储量对评估植被碳汇价值、管理城市生态环境和可持续发展具有重要意义[5]。常用的碳储量估测方式是样地清查法,即利用样地清查数据直接或间接测定生物量,再乘以相应的碳率系数推算得到碳储量[6—7]。该方法虽能得到较为准确的碳储量数据,但对植被破坏较大、费时费力且获取信息有限。遥感技术的迅速发展为大尺度、多时相的植被信息获取提供了便捷,使快速、大区域地估算城市植被碳储量成为可能[8—9]。
从现有研究来看,光学传感器、激光雷达和雷达数据均可以单独或联合用于植被碳储量估算。激光雷达和合成孔径雷达具有直接测量森林垂直结构的能力,能克服光学遥感中的光谱饱和现象,对植被生物物理和结构参数表现出更高的灵敏度,但较高的使用成本和复杂的数据处理步骤限制了其在大尺度的应用[10—11]。光学遥感数据以其长时间序列、全球区域尺度覆盖和高重访周期的特点,在大区域尺度的植被监测中有不可替代的作用。常见的光学遥感影像有空间分辨率较低的MODIS、AVHRR数据,中空间分辨率的Landsat系列以及高空间分辨率的GF、QuickBird数据[12]。其中, Landsat 8卫星数据具备全球覆盖能力,获取质量稳定、公开免费,提取植被参数及物种群落特征等信息较为准确,成为估算植被碳储量的主要光学遥感数据源之一[3,13]。
基于遥感影像的植被碳储量估测模型以参数或非参数模型为主[14—15],参数模型如多元线性回归(Multiple Linear Regression,MLR)、逻辑回归等,简单高效但通常难以应对复杂问题。常用的非参数模型有随机森林、k最近邻、支持向量机等,其模型稳健、可变性高,但需要较多训练样本且预测结果难以解释。在实际调查中,由于地形、海拔、气候等因素的影响,植被调查数据往往与其地理位置有关,在空间上表现出明显的异质性[16—17]。城市景观的复杂性使得植被分布具有更高的破碎化程度,进一步加剧了这种空间异质性。上述模型大多忽略了样地数据的空间变异,掩盖了变量间的局部差异性,从而增加实际估测中的误差,最终造成不合理的局部空间分布估测结果[18]。为了探索数据的空间特性,地理加权回归(Geographically Weighted Regression,GWR)模型应运而生[19—20]。GWR将数据的空间特性纳入模型估测中,为分析回归关系的空间特征创造了条件[21]。近年来,GWR模型被广泛用于气象学、生态学、林学等多个领域[22—24],并取得较好的应用效果。GWR模型为局部模型,它考虑了变量的空间异质性,将全局参数分解为局部参数进行估计,具有比传统全局模型获得更合理的碳储量局部空间分布的潜力。空间核函数和带宽是决定GWR模型估测效果的重要参数[25—26]。然而,在利用GWR进行植被碳储量反演时,多选用单一核函数及带宽确定方式,少有研究对比不同核函数及不同带宽选择方式在GWR模型拟合、系数估计及模型残差空间特征上的差异。
深圳市是我国7大碳排放权交易试点之一,近几年全面启动了“国家森林城市”高质量建设工作,准确估算其城市植被碳储量对深圳市城市建设、生态发展规划及实现碳达峰、碳中和目标意义重大[27—28]。研究以广东省深圳市为研究区,基于Landsat 8 OLI遥感影像和植被碳储量野外调查数据,采用多个带宽确定方法并结合不同核函数分别构建植被碳储量遥感反演GWR模型,并与MLR进行比较。最终选取最优模型进行研究区植被碳储量反演制图,以期为我国城市植被碳储量遥感估算提供方法和技术参考。
1 材料与方法
1.1 研究区概况
深圳市地处广东省中南沿海地区,位于113°43′—114°38′E,22°24′—22°52′N之间(图1)。全市面积1997.47 km2,平均海拔70—120 m。全境地势东南高、西北低,东南部主要为低山,中部和西北部为丘陵,西南部为冲击平原。境内母岩以花岗岩为主,东部和北部有较大面积砂页岩分布。研究区属亚热带海洋性气候,年平均气温22.4℃;雨量充沛,年平均降水量约1933 mm,年平均湿度72.3%;日照时间长,平均年日照时数约2120 h。热带常绿季雨林与南亚热带季风常绿阔叶林为该市的地带性植被。深圳市自然环境优美,全市建成区绿化覆盖率45%,人均公共绿地面积16.01 m2,森林面积797 km2,森林覆盖率达40.21%。
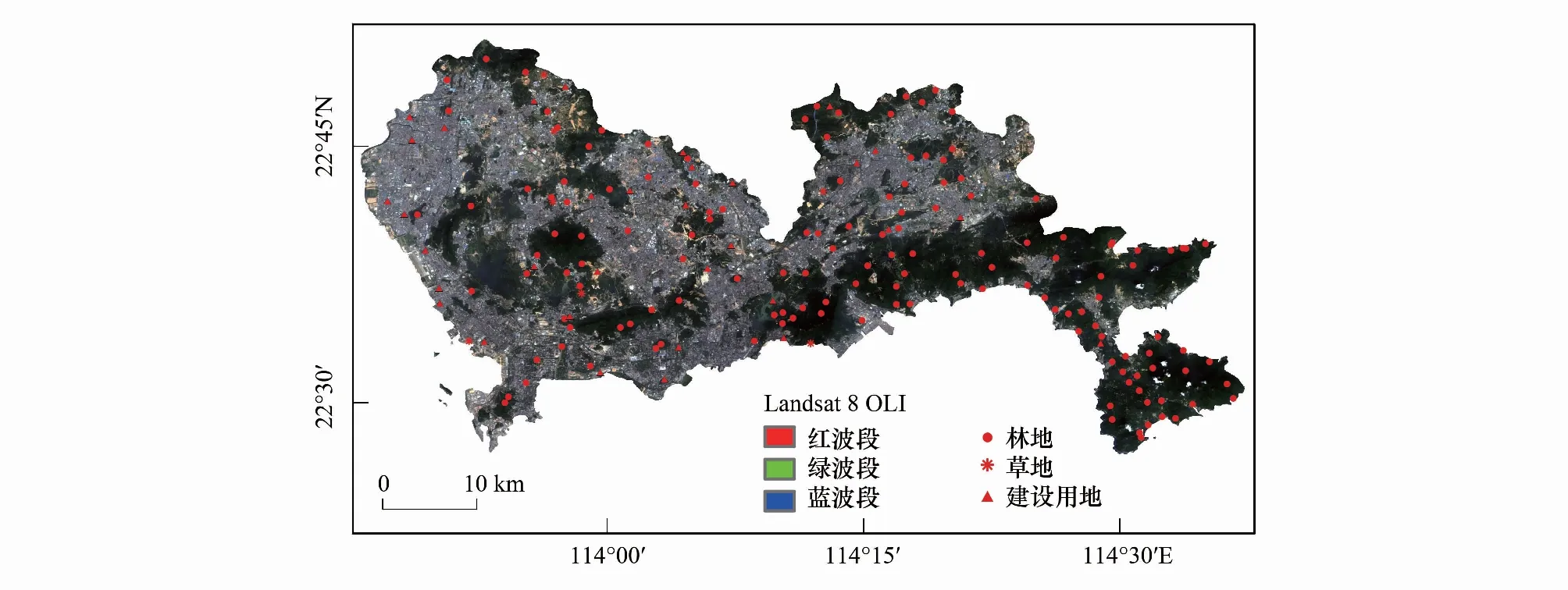
图1 研究区位置及样地分布图Fig.1 Geographical location and sample distribution of the study area
1.2 数据获取及处理
1.2.1植被调查样地数据
参考2014年深圳市森林资源规划设计调查数据,根据各地类面积及其比例,按照分层随机抽样原则,在研究区内确定大小为25.8 m×25.8 m的样地180个。其中,林地140个、草地7个及建设用地33个(图1)。外业调查分别在2014年、2016年和2018年完成。在实际调查中,地类为林地的样地分为乔木层、灌木层和草本层分别计算碳储量,最终求和得到样地碳储量。乔木层调查样方大小为25.8 m×25.8 m,对样地内胸径大于5 cm的单木进行每木检尺,测量其胸径、树高及冠幅;灌木层调查样方大小为2 m×2 m,均匀布设5个样方,记录树种、树高、地径及盖度;草本层调查样方大小为1 m×1 m,均匀布设5个样方,记录其种类、平均高及盖度。地类为草地的样地调查方法及碳储量计算方法与林地中的草本层一致。为了获得更准确的实际植被分布,建设用地中包含了部分林木,如行道树、绿化带等以及部分草本,也将被调查以及统计。
1.2.2Landsat 8 OLI遥感数据
综合考虑影像与采样时间的邻近、云量等因素,通过美国地质调查局官网(http://glovis.usgs.gov/)获取了覆盖研究区的2景Landsat 8 OLI遥感影像,其成像时间分别为2014年10月8日和2014年10月15日,轨道号分别为PATH 121/ROW 44和PATH 122/ROW 44,空间分辨率为30 m。利用ENVI 5.3软件对2景Landsat 8 OLI遥感影像进行辐射定标、FLAASH大气校正和影像镶嵌等预处理后,运用深圳市行政矢量边界裁剪得到研究区多光谱影像。
1.2.3植被类型空间分布
根据2014年深圳市森林资源规划设计调查数据(二类调查数据),结合0.5 m空间分辨率遥感影像进行人工解译,得到植被类型空间分布矢量数据。利用ArcGIS 10.6软件提取研究区林地、草地等植被覆盖区域矢量数据,用于后续制作研究区植被碳储量空间分布图。
1.3 研究方法
1.3.1样地植被碳储量估算
利用样地调查数据,结合广东省主要树种和软硬阔树种二元材积表[29]分树种计算单木材积后累加得到该树种蓄积量并转换成单位面积蓄积量;根据《全国林业碳汇计量与监测技术指南》[30]中蓄积量与生物量转换参数,采用换算因子连续函数法[18],对同一样地按不同树种(组)换算并累加求和,得到样地单位面积乔木层生物量;最后根据优势树种(组)碳含率[30]计算各样地的乔木层单位面积碳储量。
W乔=aV+b
(1)
C=W×CF
(2)
式中,W乔为乔木层生物量(Mg/hm2),V为每公顷蓄积量(m3/hm2),a和b为常数,主要优势树种(组)取值见表1;C为各层碳储量(Mg C/hm2),W为各层生物量(Mg/hm2),CF为含碳率,无量纲,灌木层取0.4672,草本层取0.3270,主要优势树种(组)取值见表1。
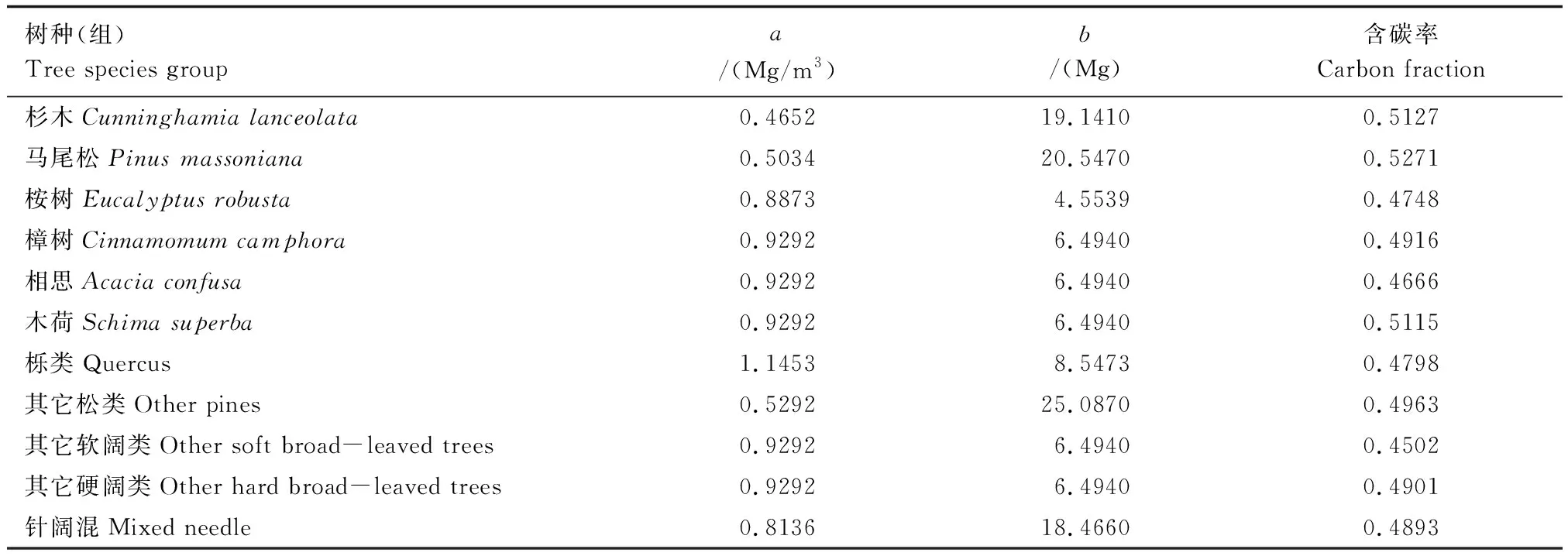
表1 主要优势树种(组)对应生物量转换参数及含碳率取值Table 1 Biomass conversion parameters and carbon fraction of main dominant tree species
采用范文义等[31]建立的不同区域灌木草本生物量与高度之间的模型计算灌木草本的生物量,乘以盖度得到样方灌草总生物量。
W灌=0.0398×h1-0.3326
(3)
W草=0.0175×h2-0.2888
(4)
式中,W灌为灌木层生物量(Mg/hm2),W草为草本层生物量(Mg/hm2),h1和h2分别表示灌木和草本的平均高度(m)。
为保证样地点与遥感影像像元的匹配,获取更准确的影像信息,分别对灌木层和草本层的5个样方总生物量取均值后乘以样地面积比,得到样地灌草总生物量并转换成样地单位面积灌草生物量。利用灌木、草本层的平均碳含率[30]换算得到各样地单位面积灌草总碳储量。最后将乔木层、灌木层及草本层碳储量相加得到样地单位面积总碳储量。
由于遥感影像成像时间和多数样地调查时间为2014年,为减少估测误差,依据树木生长方程将2016年及2018年的样地的平均胸径和树高反推至2014年的生长状态,从而将所有样地植被碳储量换算至2014年水平。
1.3.2遥感变量提取
植被指数由不同遥感光谱波段经线性或非线性组合构成,对植被具有一定指示意义,已被广泛用于定性和定量评价植被生长状况[32—33]。对预处理后的影像数据进行波段计算与提取,得到7个单波段反射率、 42个两波段比值植被指数、105个三波段比值植被指数以及土壤调节植被指数、增强植被指数、归一化植被指数、大气阻抗植被指数、修正归一化差值植被指数、红绿植被指数等常用的植被指数共160个遥感变量,其具体计算公式见表2。
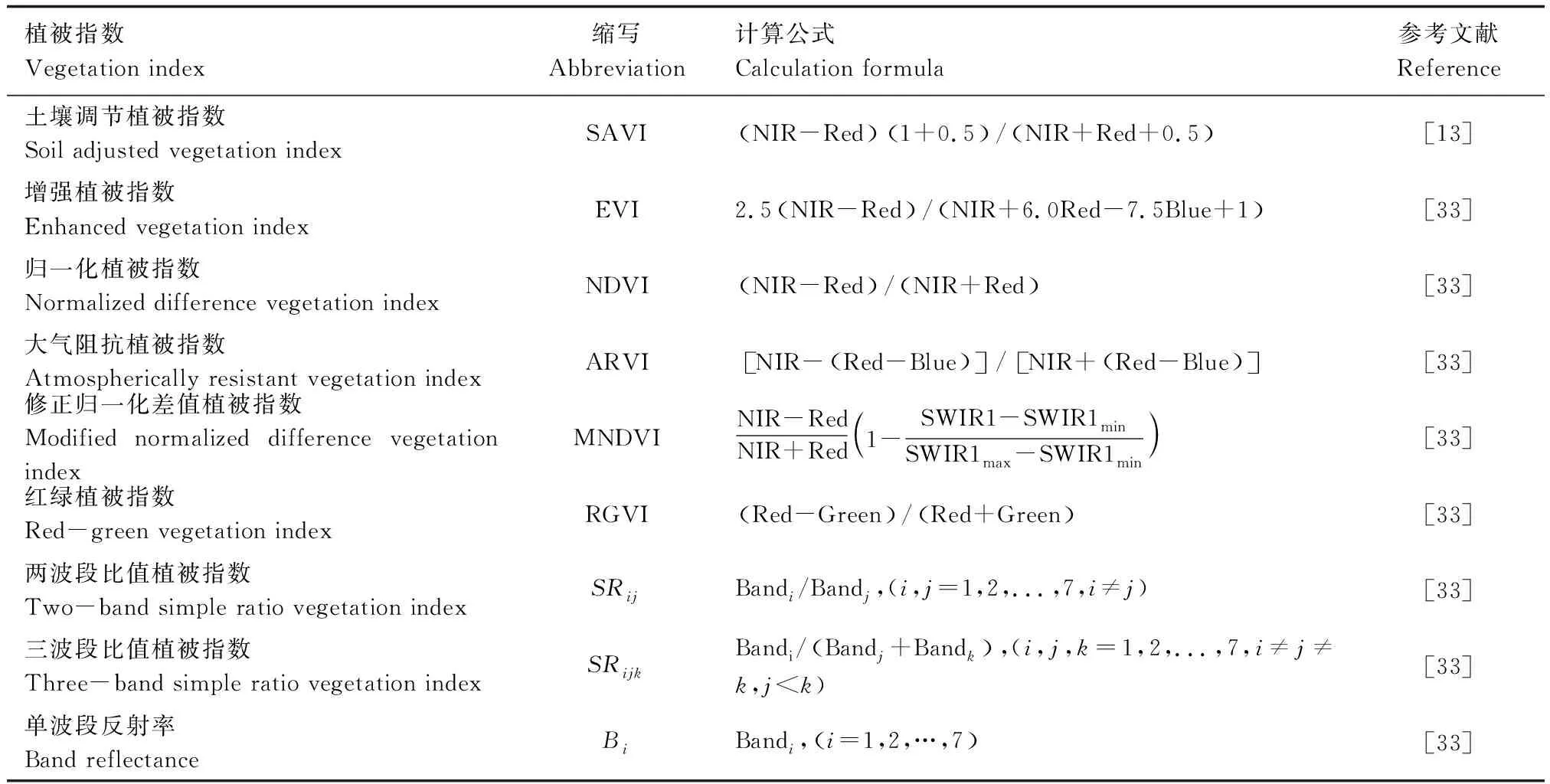
表2 所采用的遥感变量计算方法Table 2 Expressions of the adopted remote sensing variables
1.3.3遥感变量筛选
计算所有遥感变量与样地植被碳储量之间的Pearson相关系数矩阵,选择与植被碳储量显著相关的变量,采用逐步回归进行变量筛选。同时,为了消除变量之间的共线性,引入方差膨胀因子(variance inflation factor,VIF)[28]进行共线性诊断,阈值设为10。最终所得变量用于后续所有模型的构建。
1.3.4GWR模型构建
GWR模型是对普通全局回归模型的扩展,它将数据的空间特性以距离加权的方式纳入模型中,其基本形式为:
(5)
式中,(ui,vi)为第i个样本点的空间坐标;βi0为第i个样本点的常数估计值;βik(ui,vi)为第i个样本点第k个自变量系数,与其空间位置有关;xik为第k个自变量在样本i的值;εi为残差,通常假定其服从独立正态分布。空间各点回归系数的求解如下:
(6)
式中,X、y为各样本点的自变量与因变量矩阵;W(ui,vi)为样本点i的空间权重矩阵:
W(ui,vi)=diag(Wi1,Wi2,…,Win)
(7)
对于空间权重核函数,研究利用R语言GWmodel函数包,分别构建了Gaussian[19]、Bi-square[26]和Exponential[34]三种核函数。
校正Akaike信息准则(Akaike Information Criterion corrected,AICc)和最大空间自相关距离(Maximum Spatial Autocorrelation Distance,MSAD)是常用的两种带宽确定方式。校正Akaike信息准则通过选择AICc值最小时对应的带宽为最优带宽[22];最大空间自相关距离通过创建半变异函数获得[28]。交叉验证(Cross-Validation,CV)[34]是目前主流的最优带宽求解方法之一,多用于气象学、海洋学等研究[35—36],在植被碳储量反演中运用较少,其表达式如下:
(8)

最终,将三种带宽选择方式与三种核函数进行组合,构建共9种GWR模型进行植被碳储量反演和精度评价。
1.3.5精度评价
采用留一交叉验证[37]对模型结果进行精度验证,即每次只留1个样本作为验证样本,余下的样本作为建模样本,直到所有样本都做过验证样本,最后对验证结果取平均作为泛化误差的估计。选用决定系数R2(coefficient of determination)、均方根误差(root mean square error,RMSE)及平均绝对误差(mean absolute error,MAE)对模型进行精度评价[37]。
采用Moran指数(MoranI)对不同模型预测值和实测值之间所得的残差进行空间自相关分析。MoranI>0表示空间正相关,值越大空间相关性越明显;MoranI<0表示空间负相关值,值越大空间差异越大;MoranI接近0且在统计上不显著,则说明空间模式呈随机性。
1.3.6非平稳性检验
对GWR模型参数估计值的空间非平稳性进行显著性检验,以判断这种非平稳性是空间数据本身固有,还是由于随机因素干扰。利用Brunsdon等[19]提出的置信区间检验法对GWR模型各回归参数进行空间非平稳性检验,将GWR模型的局部参数与MLR模型的全局参数进行对比,若GWR模型参数估计的第1分位和第3分位值变化范围大于MLR模型的二倍标准误值,则可认为各回归参数具有显著非平稳性。
1.3.7植被碳储量空间分布制图
以Landsat 8 OLI影像为数据源,选取最优GWR模型进行碳储量反演得到碳储量空间分布,利用植被类型空间分布数据对植被区域进行掩膜提取,得到深圳市植被碳储量空间分布图。
2 结果与分析
2.1 遥感变量选择及带宽确定
遥感变量与植被碳储量之间的Pearson相关系数值在-0.378—0.383之间,共有111个变量与碳储量显著相关(P<0.05)。其中,相关性最高的前3个变量是两波段比值植被指数SR64、三波段比值植被指数SR436和三波段比值植被指数SR324,与碳储量的相关系数分别为0.383、-0.378和0.377。从各遥感变量的波段组成来看,单波段对碳储量的敏感度一般,但与红(Red)和短波红外波段(SWIR1)组合而成的比值植被指数对碳储量的敏感度相对较高。在相关性分析基础上,引入方差膨胀因子VIF,采用逐步分析,最终筛选出三波段比值植被指数SR324、SR657及两波段比值植被指数SR35共计3个遥感变量(表3)。

表3 变量筛选结果Table 3 Variable selection results
图2为分别利用AICc与CV选择带宽,结合不同核函数构建GWR模型时所得的带宽曲线图,图2中虚线所对应带宽即为基于最小AICc值或CV值的最优带宽。最终,以Gaussian、Bisquare和Exponential为核函数,利用AICc确定的最优带宽分别为11536、28131和11770,利用CV确定的最优带宽分别为6347、17081和4519。通过创建半变异函数最终确定MSAD的最优带宽均为28000,基于不同带宽选择方法所得最优带宽相差较大。
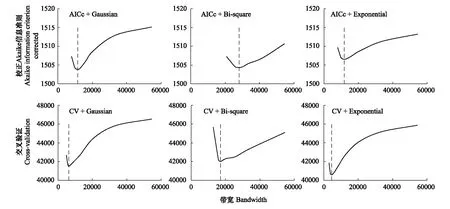
图2 AICc与CV带宽选择结果Fig.2 Bandwidth selection results of using AICc and CVAICc:校正Akaike信息准则Akaike information criterion corrected;CV:交叉验证Cross-validation
2.2 碳储量预测模型精度评价
由表4可知,MLR模型的决定系数(R2)为0.298,均方根误差(RMSE)为15.886 Mg C/hm2,平均决定误差(MAE)为11.721 Mg C/hm2,其模型残差的MoranI为0.172(P<0.01),说明模型残差在空间中的分布并非完全随机,且呈现显著正自相关。考虑局部差异的GWR预测效果均优于全局的MLR(P<0.05),但不同带宽选择方法与不同核函数组合体现出不同的效果。利用AICc确定带宽,以不同核函数分别构建的3个GWR模型在精度上无显著差异,但以Exponential为核函数构建的GWR模型残差存在显著正相关;利用MSAD确定带宽时,以Bi-square为核函数所构建的GWR模型效果最佳,且其模型残差呈随机分布;利用CV确定带宽构建的GWR模型预测效果普遍优于另两种带宽确定方法所构建的GWR模型,所构建的3个GWR模型,其MoranI绝对值均小于0.05(P>0.1),模型残差均无显著自相关。其中又以CV与Exponential核函数组合构建的GWR模型效果最佳,其R2为0.697,RMSE为10.437 Mg C/hm2,MAE为7.401 Mg C/hm2,残差MoranI为-0.036(P>0.1),模型的预测结果更接近实测值,且模型残差之间相互独立。整体来看,构建的GWR模型估计误差及残差自相关程度普遍低于MLR模型。这是由于样本地理位置信息以距离权重的方式参与了建模,使得每个样地都具有一个独立的加权回归方程,这能在一定程度上提高预测精度并有效减弱残差的空间自相关性。
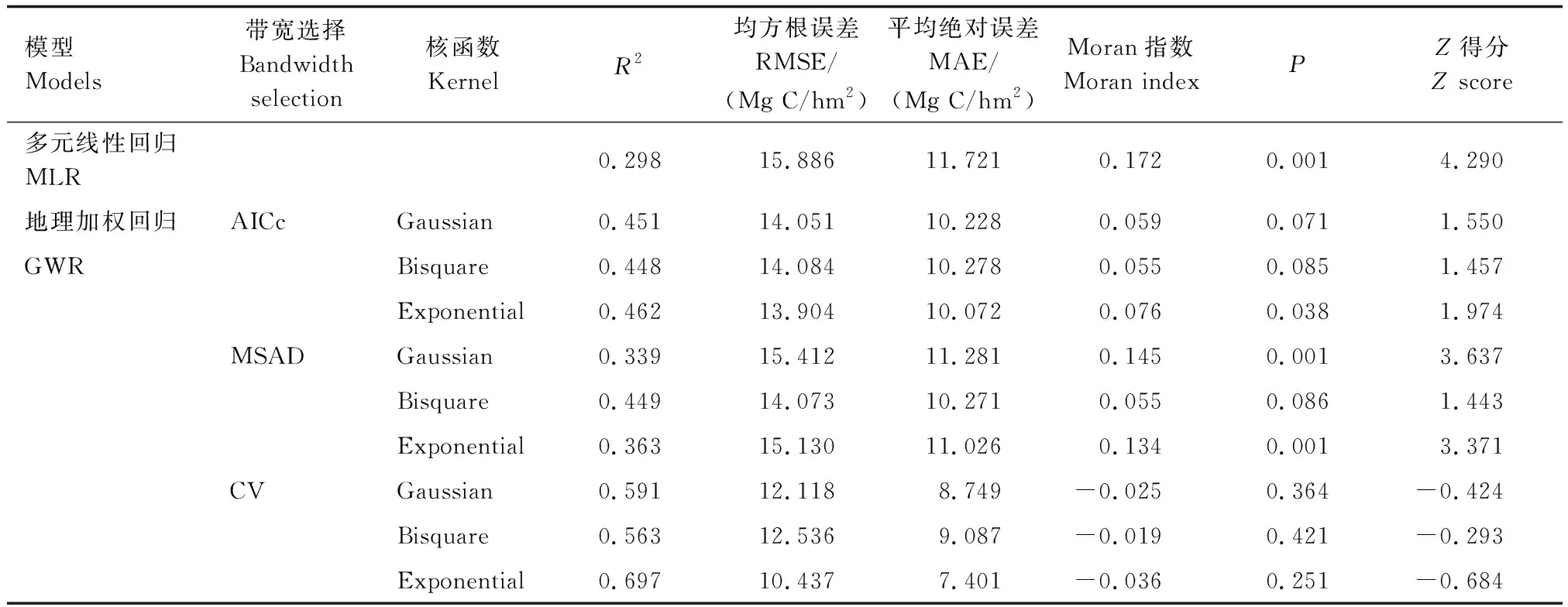
表4 模型估测精度及残差空间自相关Table 4 Estimation accuracy and residual spatial autocorrelation of models
图3为碳储量实测值与所有模型预测值的拟合图,各模型均存在一定低值高估与高值低估现象。对于碳储量大于50 Mg C/hm2的样地,各模型均存在明显的高值低估;对于碳储量低值则普遍存在高估现象,误差较大。此外,对于碳储量极低值,其模型估测结果存在少数预测值为负值。对比不同模型拟合曲线与理想曲线的偏离程度,MLR模型偏离程度远大于各GWR模型的偏离程度;从回归拟合曲线两侧的散点分布情况来看,相比于MLR模型,GWR模型的散点更为紧凑地聚集于拟合曲线的两侧。利用AICc确定带宽构建的3个GWR模型,实测值与预测值散点分布相似度较高,无显著性差异。利用MSAD确定带宽、以Gaussian和Exponential为核函数构建的GWR模型,虽R2显著高于MLR模型,但从拟合图来看,其预测结果并不存在明显的差异。利用CV确定带宽构建的GWR模型,其曲线拟合及散点分布情况明显优于其它模型。其中,又以CV与Exponential核函数组合构建的GWR模型,其散点分布最为紧凑,预测结果与实测结果偏离程度最小。
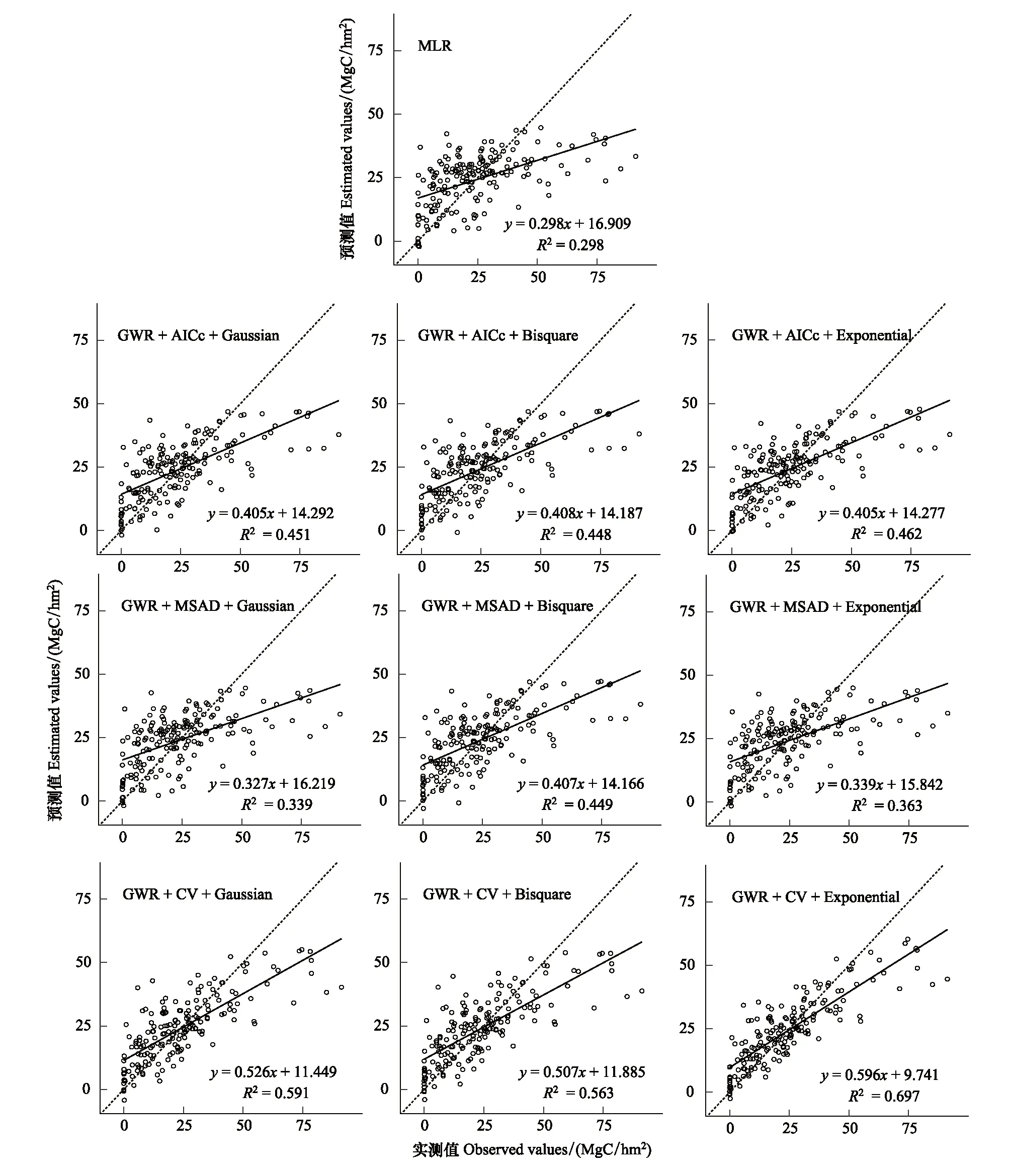
图3 植被碳储量估测模型拟合结果Fig.3 Fitting results of vegetation carbon storage estimation modelsMLR:多元线性回归 Multiple linear regression;GWR:地理加权回归 Geographically weighted regression; MSAD:最大空间自相关距离Maximum spatial autocorrelation distance
2.3 非平稳性检验
对所有GWR模型进行回归参数的空间非平稳性检验,同一带宽选择方法所构建的GWR模型,其参数非平稳性具有相似性(图4)。采用AICc确定带宽构建的GWR模型,常数项、变量SR35和变量SR324的系数估计值变化幅度均大于MLR的二倍标准误值,变量SR657虽存在一定的空间非平稳性,但并不显著;采用MSAD确定带宽,以Gaussian和Exponential为核函数构建的GWR模型,其变量均不具有显著非平稳性;采用CV选择带宽所构建的GWR模型,所有变量的系数估计第1分位和第3分位值变化幅度均大于MLR的二倍标准误值,说明它们均具有显著的空间非平稳性,能较好反映空间异质性。

图4 空间非平稳性检验Fig.4 Stationary test of relationshipSR:比值植被指数Simple ratio vegetation index
图5为最优GWR模型得到的回归参数空间分布。变量回归系数的正负和数值在空间分布上的差异性,反映了各变量在不同区域对碳储量表现出的不同影响。常数项体现的主要是地理位置的影响,地理位置对大部分地区碳储量呈现不同程度的正向影响,东南部低山地区碳储量受地理位置的影响相比其它地区较大。SR324变量回归系数大部分为负值,系数绝对值高值主要集中在东南部及北部的碳储量高值区,这表明碳储量高的地区,SR324变量回归系数相对较高,SR324变量对高碳储量地区的敏感度高于其它地区。除中部及南部地区外,SR35变量大部分回归系数为负值,且回归系数由研究区中心区域向四周逐渐递减。SR657回归系数均为负值,能负向反映植被碳储量,在保持其它条件不变时,较高植被碳储量处具有较低的SR657指数值。中部及南部的城市居民区的SR657回归系数较大,表明SR657变量更能反映低植被碳储量。
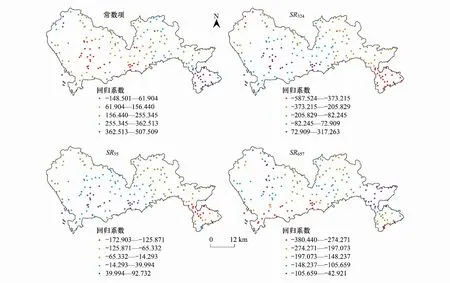
图5 最优GWR模型回归参数系数空间分布图Fig.5 The spatial distribution of regression parameter coefficients of the optimal GWR model
2.4 植被碳储量空间分布
深圳市植被碳储量空间分布值在1.63—60.95 Mg C/hm2之间(图6)。碳储量值小于10 Mg C/hm2的区域占深圳市植被区7.61%,其分布较为零散,与深圳市草地地类区域重合度较高。在城市东南部低山、中西部丘陵、中南部和北部地区,碳储量估计值大部分在10—30 Mg C/hm2之间,该部分地区植被类型主要为森林。碳储量值大于30 Mg C/hm2的区域面积约为276.7 km2,占深圳市植被区30.47%,分散分布于城市各地区,主要地类为林地,且植被类型多为阔叶林。从整体来看,反演所得的碳储量空间分布与深圳市各植被类型空间分布大体一致,与实际情况较符合。
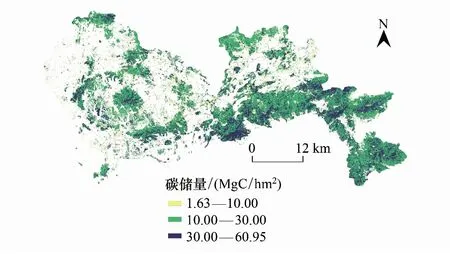
图6 研究区植被碳储量空间分布图 Fig.6 Spatial distribution of vegetation carbon stocks in the study area
3 讨论
碳储量能反映植被固碳增汇功能,快速准确地估算植被碳储量对评估区域碳汇价值具有重要意义。本研究以Landsat 8 OLI影像为数据源,构建了多个基于不同带宽选择方式及核函数的GWR模型进行深圳市植被碳储量估测研究。
结果表明GWR模型预测效果优于MLR模型,这与Hu等[23]和Kupfer等[26]的研究结果一致。由于MLR模型为全局模型,得到的回归参数估计是在整个研究区的平均值,反映碳储量空间异质特征的能力有限;而GWR模型为局部模型,它考虑了变量的空间异质性,将全局参数估计分解为局部参数进行估计,在估测精度与保留样本空间特征上都显著优于MLR,且能有效降低模型残差的空间自相关性[22,24]。Jiang等[3]利用改进GWR模型估算深圳市植被碳空间分布,获得了最小RMSE值13.280 Mg C/hm2。本研究中通过对带宽选择方式和不同核函数进行优选得到最优GWR模型RMSE为10.437 Mg C/hm2,表明估测效果有明显改善。但从建模结果来看,不同的带宽选择方式结合不同核函数所构建的GWR模型预测效果有显著差异。在实际操作中需结合具体情况综合考虑,针对不同研究区和数据,选择合适的权重函数确定最优带宽,以保证GWR模型的估测效果[38]。
由于样地调查时间跨度较大,为尽可能降低因时间差异带来的影响,依据树木生长方程将不同年度样地植被碳储量反推换算至同一水平,但难以避免造成碳储量样地调查数据与实际情况的偏差,从而影响碳储量估测。在构建碳储量估测模型时,各模型均存在少数预测值为负值,类似的问题在Sun等[13]的研究中也存在,其主要原因是植被碳储量与选定光谱变量之间的非线性关系。作为一种线性方法,GWR模型使用局部最小二乘得到局部参数估计值,虽在探索空间异质性方面具有优势,但对于非线性关系解释能力有限。罗小波等[39]提出一种局部非线性地理加权回归模型,并将其应用于地表温度研究,获得了比GWR线性模型更优的结果。可以考虑引入局部非线性地理加权回归模型用于植被碳储量等参数的反演研究。
植被碳储量空间分布图所得碳储量值在1.63—60.95 Mg C/hm2之间,这与Sun 等[13]所得的深圳市森林碳储量数值范围相似。但反演制图所得碳储量最大值与样地碳储量最大观测值91.247 Mg C/hm2相差较大,这很大程度上与样本数据的分布有关。在使用GWR作为样本外空间预测工具时,是基于先前估计的带宽从未观测位置周围借来已知样本数据,获得样本外预测。因90%以上样本数据植被碳储量值位于0—60 Mg C/hm2之间,对样本外预测结果造成了影响,使数值集中于此区间。可结合以往的碳储量调查数据综合考虑,使所布设样地尽可能包含多个地类多个级别碳储量值分布。
GWR模型的特点在于局部参数的估计,局部参数的非平稳性能体现模型反映空间异质性的能力[26,38]。通过CV选择带宽构建的GWR模型效果相对较好,其变量回归参数存在显著空间非平稳性。但通过AICc及MSAD选择带宽构建的GWR模型,均存在回归参数空间非平稳性不显著的变量,需将其作为常参数考虑。这种既包含变参数又包含常参数的GWR扩展模型,通常称为混合GWR模型[20—21]。混合GWR可提高常参数估计的精度和稳定性,从而降低因常参数估计值而造成的模型预测误差,具有获得高精度、稳定的植被碳储量估测结果的潜力。
4 结论
本研究以Landsat 8 OLI影像为数据源,结合植被碳储量样地实测数据,构建了MLR模型和多个基于不同带宽选择方式及核函数的GWR模型,对深圳市植被碳储量进行估测和空间分布制图。得出以下主要结论:
(1)局部的GWR模型优于全局的MLR模型,不同的带宽选择方式结合不同核函数所构建的GWR模型,在模型拟合效果上具有较大差别。以CV确定带宽、Exponential为核函数组合构建的GWR模型效果最佳,其R2为0.697,RMSE为10.437 Mg C/hm2,相比其他GWR模型RMSE下降了13.87%—32.28%,估测效果有明显改善。
(2)同一带宽选择方法所构建的GWR模型,其参数非平稳性具有相似性。通过CV选择带宽构建的GWR模型,其变量回归参数均存在显著空间非平稳性,能较好反映空间异质性。
(3)由最优GWR模型获得的深圳市植被碳储量空间分布表明植被碳储量高值和低值主要分布于森林和草地区域,与深圳市植被覆盖情况基本一致,能为深圳市植被碳储量遥感估算提供方法与技术参考。
