基于植被指数选择算法和决策树的生态系统识别
2019-06-27孙滨峰陈立才舒时富李艳大
孙滨峰 赵 红 陈立才 舒时富 叶 春 李艳大
(1.江西省农业科学院农业工程研究所, 南昌 330200; 2.江西省农业信息化工程技术研究中心, 南昌 330200;3.江西省交通科学研究院, 南昌 330200)
0 引言
区域生态系统的结构及其变化的识别不仅是全球变化研究关注的重要内容[1],也是资源可持续管理[2]和区域农业规划制定的重要依据[3-4]。开展区域生态系统类型的遥感监测,建立实时、快速的监测方法,获取区域生态系统变化的相关知识,对于开展区域土地资源管理具有重要的战略意义[5]。
植被指数是一种数据增强的方法,有助于增强遥感影像的解译能力,广泛应用于土地利用类型识别[6]、植被覆盖度评价[7]、作物类型识别[8]和作物长势监测与预报[9-10]等方面。植被指数能够反映不同生态系统类型的光谱特征,基于植被指数的土地利用类型识别研究一直是国内外学者研究的热点[11]。然而,受到大气、遥感器定标、遥感器观测条件、太阳入射角度、土壤湿度、颜色和亮度等因素的影响和制约[12],导致植被指数在不同环境下的效果不同,至今尚无研究明确各植被指数的适用范围[13]。对于植被指数的选择主要依据其物理意义或者借鉴相关研究结果,少有研究关注植被指数对研究区域的适应性,导致研究结果常存在争议[14]。因此,在研究生态系统类型时需要结合环境特征选择植被指数。常见的植被指数选择方法根据是否使用样本信息分为监督和非监督的方法[14]。基于样本的监督植被指数选择方法能够反映区域环境特征,较之基于统计特征的非监督的选择方法,如最佳指数(OIF)等,更易获取最能区分研究区内生态系统类型特征的植被指数。
马氏距离是由印度统计学家马哈拉诺比斯提出的,表示数据的协方差距离,是一种能够有效衡量样本数据间相似度的算法,具有既消除变量间相关性干扰且不受量纲影响的优点[15]。本文结合许明明等[16]提出的基于类别可分的高光谱图像波段选择算法(Endmember separability based band selection,ESBB),将相关系数引入植被指数选择算法中,利用马氏距离选择最适宜的植被指数集合,构建决策树模型,以江西省吉安市永丰县为研究对象,对生态系统进行自动识别。
1 材料与方法
1.1 研究区概况
永丰县地处江西省中部,隶属吉安市,区域范围在北纬26°38′~27°32′,东经115°17′~115°56′。东西窄,南北长,呈哑铃状,面积约2 710 km2(图1)。永丰全县人口约48万,下辖8个镇,13个乡,县政府驻恩江镇。全县地势由东南向西北倾斜,整个地貌山脊线形成四周高,中间低的趋势。属亚热带季风气候,四季分明,雨量充沛,年均温度18℃,年平均降水量1 627 mm。永丰县是“林业百佳县”,森林覆盖率超过70%,自然资源丰富,生态环境良好。
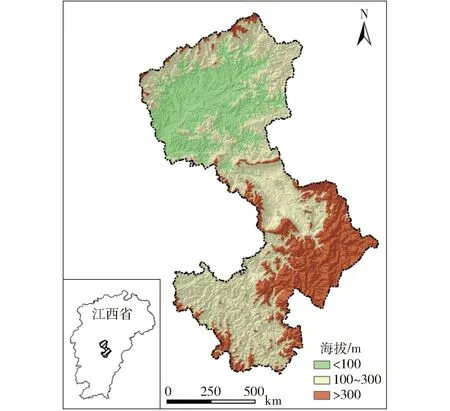
图1 研究区域Fig.1 Research area
1.2 模型与方法
1.2.1数据来源与预处理
采用的主要数据为Landsat 8 OLI遥感影像,来源于地理空间数据云(http:∥www.gscloud.cn/),成像时间为2016年9月27日,太阳高度角54°,方位角143°,空间分辨率为30 m,研究区范围内无云,原始图像共有9个波段。采用ENVI软件进行辐射定标,FLAASH大气校正模型进行大气校正,C模型进行地形校正[17],得到地表反射率。采用IDL计算主要的植被指数。影像投影为UTM(Zone50N),基准面为WGS-84;后期对影像做了不规则裁剪、波段重组等预处理。辅助数据包括2016年的《永丰统计年鉴》,用于对分类结果进行对照;Planet 3 m分辨率的遥感影像,用于目视解译、分类后精度评价。
1.2.2生态系统的植被指数选择
本文计算了包括归一化植被指数(Normalized difference vegetation index,NDVI)、改进归一化水体指数(Modified normalized difference water index,MNDWI)、增强植被指数(Enhanced vegetation index,EVI)、归一化建筑指数(Normalized difference build-up index,NDBI)以及基于通用光谱模式分解算法的植被指数(Vegetation index based on the universal pattern decomposition method,VIUPD)[18]等41种[19]常用植被指数。部分植被指数间的相关性较高,信息冗余量大(图2)。本研究将相关系数和马氏距离相结合,构建植被指数集识别生态系统的类型。

图2 植被指数相关性分析Fig.2 Correlation analysis among vegetation indices
马氏距离是一种能够有效衡量样本数据间相似度的算法[20]。假设2组样本数据i、j组成的列向量为xi、xj,则两向量间的马氏距离定义为
(1)
式中S——向量xi与xj的协方差矩阵
植被指数选择算法的描述如下:
(1)计算各植被指数间的Pearson相关系数
(2)
式中Pij——植被指数fi与fj的相关系数
COV(xi,xj)——xi与xj的协方差
D(xi)——xi的方差
D(xj)——xj的方差
(2)初始化C,计算各生态系统类型在植被指数上的马氏距离均值集合D,将D中最大值对应的植被指数fi赋给C。
fmax=fi(Di=max(D))
(3)
C=C∪{fmax}
(4)
S=S-fmax
(5)
式中C——被选择植被指数集合
S——植被指数集合
fmax——马氏距离最大的植被指数
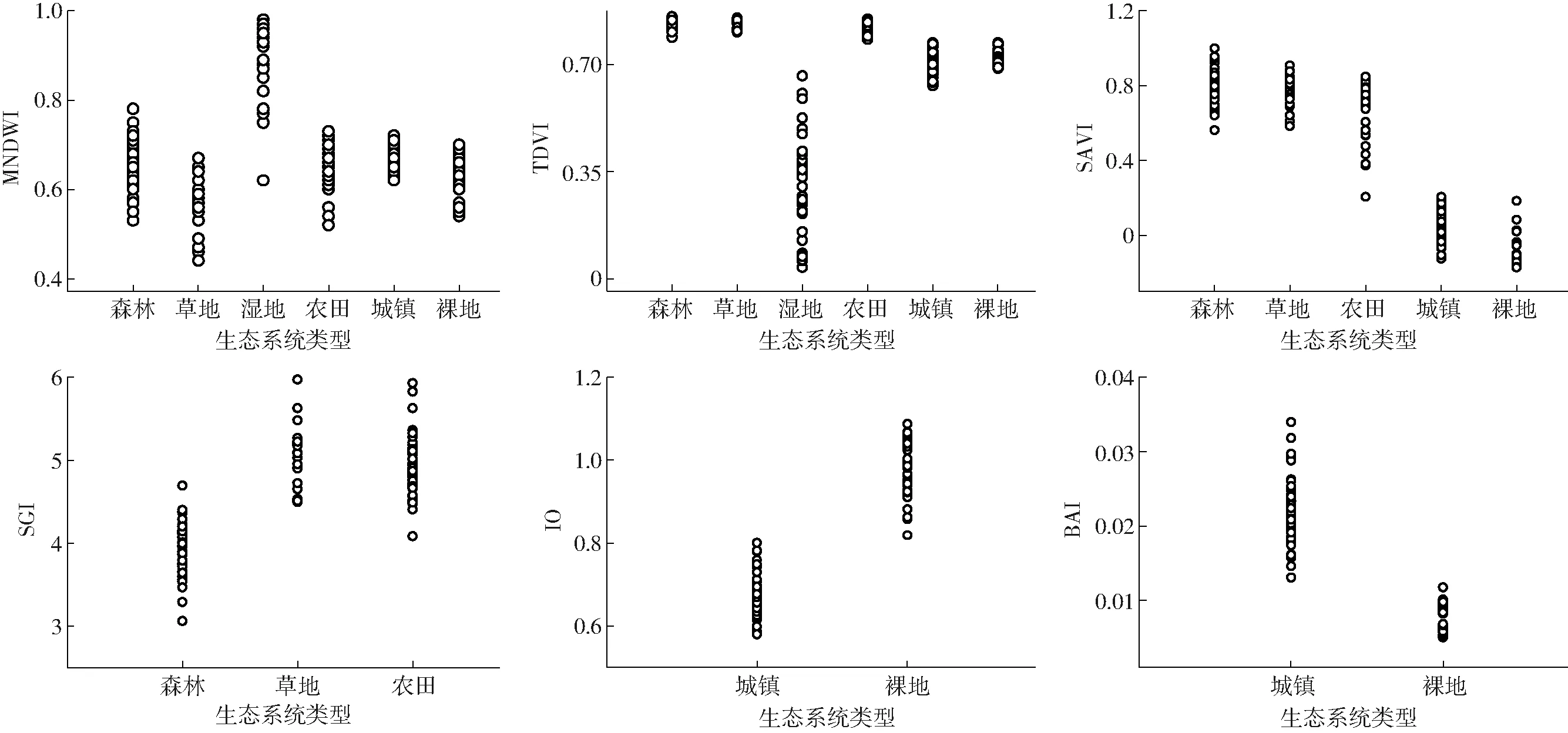
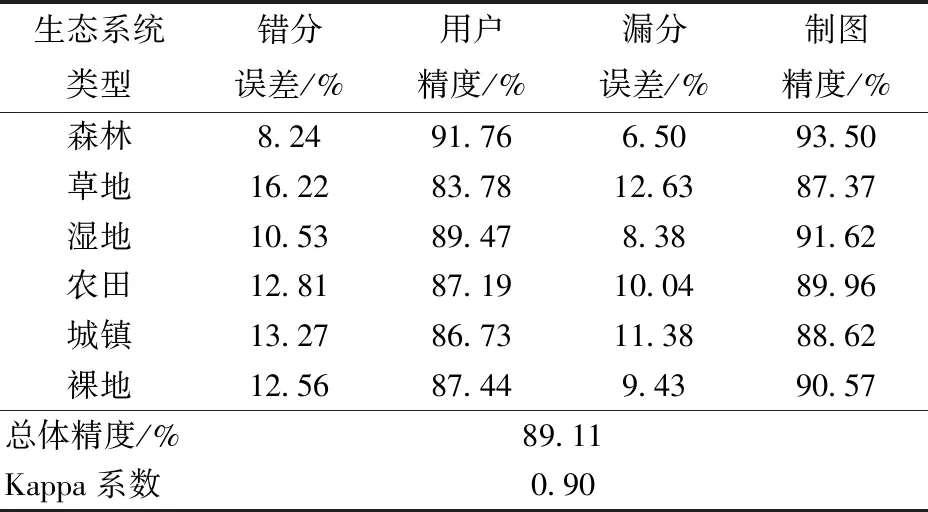
(3)将满足|Pij| Ii=C∪fi(fi∈C,|Pij| (6) C=C∪{fi} (fi=max(D)) (7) S=S-fi (8) (4)重复步骤(3),直到未选择的植被指数与C中植被指数间相关系数的绝对值大于0.34。 C=C∪fi(fi∈S,|Pij| (9) 1.2.3基于决策树规则的生态系统信息提取方法 采用本文提出的植被指数选择方法,利用ENVI和CART算法,构建决策树分类模型,识别典型生态系统类型及其分布。首先采用1.2.2节中的算法确定生态系统提取的顺序,再根据CART算法设置模型阈值,提取生态系统类型信息。 根据本文提出的植被指数选择算法,首先识别湿地生态系统和非湿地生态系统,然后区分植被和非植被。生态系统信息识别顺序和所建立的决策树模型详见图3。 图3 基于决策树的生态系统识别Fig.3 Ecosystem information extraction based on decision tree (1)湿地生态系统和非湿地生态系统信息提取 根据本文提出的植被指数选择算法,采用MNDWI和转换差值植被指数(Transformed difference vegetation index,TDVI),通过设定阈值提取湿地生态系统和非湿地信息。优先识别湿地和非湿地生态系统,可获得较高的分类精度。由图4可知,湿地生态系统的MNDWI明显高于其他生态系统类型,而其TDVI显著低于其他生态系统类型,植被指数MNDWI与TDVI相结合能够有效提取湿地信息。 (2)植被与非植被信息提取 根据植被选择算法,植被与非植被在土壤调整植被指数(Soil adjusted vegetation index,SAVI)上的马氏距离最大。裸地和城镇等非植被生态系统的SAVI值都小于0.310,植被与非植被区分明显(图4)。 (3)森林、草地与农田信息提取 森林、草地与农田在绿度总和指数(Sum green index,SGI)上的马氏距离最大,草地的含水率明显低于农田(图4)。设置SGI为4.610提取森林生态系统,将MNDWI的阈值设置为0.517,可区分草地和农田。 图4 不同生态系统植被指数对比Fig.4 Comparisons of vegetation indices of different ecosystems (4)裸地、城镇与已收割农田信息提取 已收割农田和城镇、裸地在植被指数SAVI上马氏距离最大,城镇和裸地在植被指数氧化铁比率(Iron oxide ratio,IO)、燃烧面积指数(Burn area index,BAI)上马氏距离最大,SAVI大于0.204可以提取农田信息,IO大于0.753、BAI小于0.025可以有效地分离裸地和城镇。 根据图3建立的决策树模型识别生态系统类型,并对识别精度进行评价(表1)。总体精度为89.11%,Kappa系数为0.90,较好地区分了生态系统类型。其中,森林、湿地和裸地的用户精度、制图精度较高,错分误差、漏分误差较低;草地、城镇、农田错分、漏分现象相对较多,这和遥感影像的分辨率、研究区地形密切相关,但结果可满足制图需求。 永丰县生态系统空间分布格局详见图5。森林生态系统是永丰县最主要的生态系统类型,约占全县面积的76.93%;其次是农田生态系统,面积约占全县面积的16.27%,主要分布在研究区域的北部和中部平原地区;裸地、城镇、湿地和草地生态系统分别占全县面积的3.65%、1.90%、0.81%和0.44%。 表1 决策树分类精度Tab.1 Extraction precision of decision tree 图5 永丰县生态系统类型图Fig.5 Ecosystem types map of Yongfeng County 将植被指数间的相关系数与马氏距离相结合构建植被指数选择算法,减少了数据冗余,提高了生态系统识别的精度。ESBB算法通过马氏距离最大化图像中各类地物的可分性来确定最优的波段组合,较之其他波段选择算法,该方法具有不需要大量训练样本等优点[16]。但ESBB算法没有考虑波段间的相关性,只以马氏距离作为波段选择的唯一标准,易造成分类波段相关性较高、有效信息不足等问题,导致分类精度不高。本研究所采用的41种植被指数间存在显著的相关性(图2)。以湿地生态系统提取为例,由ESBB算法得到的植被指数为MNDWI和MNLI(Modified non-linear index),本研究提出的植被指数选择算法所选植被指数为MNDWI和TDVI,湿地生态系统提取研究中常用的植被指数为MNDWI和NDVI[21-22](表2),识别精度详见表3。结果显示,MNDWI和TDVI的分类精度最高,为91.62%,MNDWI和TDVI的分类精度次之,MNDWI和NDVI的分类精度最低,为87.60%。MNDWI和NDVI的相关系数最小,但样本的马氏距离也最小,样本分离度最低,其分类精度最低。MNLI是非线性指数的改进指数,其结合了土壤调整植被指数(SAVI)消除了土壤的影响[23]。样本在MNDWI和MNLI上的马氏距离最大,但MNDWI和MNLI相关性最大,MNDWI和MNLI所表达的信息具有一定的重叠,信息冗余度最大,导致其分类精度略低。MNDWI和TDVI较之MNDWI和MNLI,相关系数小,信息冗余度低。TDVI的饱和度较之于NDVI较低[24],有利于识别湿地生态系统。样本在TDVI上的马氏距离大于在NDVI上的马氏距离,说明TDVI较之NDVI更适应研究区环境。 表2 植被指数公式Tab.2 Formula of vegetation indexes 注:N为近红外波段,R为可见光红波段,L为冠层背景调整因子,取0.5。 表3 不同植被指数湿地生态系统识别精度Tab.3 Accuracy of ecosystem identifications by different vegetation indexes 植被指数和决策树是土地利用类型识别的常规方法[25],当前研究普遍采用的植被指数包括NDVI[26]、EVI[27]、NDBI[27-28]和MNDWI[29-30]等植被指数来识别土地利用类型。然而植被指数在不同环境下反映生态系统类型光谱特征的效果存在争议,至今尚无研究明确各植被指数的适用范围,因此在使用植被指数提取生态系统类型时,需要充分考虑区域的环境特征。马氏距离能够度量两种类型在一组数据上的可分性,基于马氏距离的植被指数选择方法可获取区域最适宜植被指数,以提高生态系统的识别精度。本文将植被指数间的相关系数引入植被指数选择算法中,避免了信息冗余而导致分类精度的降低。 (1)将相关系数引入植被指数选择算法中,构建的基于马氏距离的植被指数选择方法具有很好的适用性。 (2)通过植被指数选择方法提出决策树信息提取模型,对生态系统信息层层提取,识别生态系统类型与范围的方案合理可行。 (3)基于上述的模型和方法,建立生态系统类型自动识别方案,在永丰县的结果表明,相比传统的方法本方案精度有了显著提高, 同时也证明该方法有效可行。2 结果与分析
2.1 决策树模型

2.2 生态系统类型识别及其精度

3 讨论


4 结论
