可解释机器学习方法在疾病预测中的应用:脓毒血症患者死亡风险研究
2022-07-13杨丰春
杨丰春 郑 思 李 姣
(中国医学科学院/北京协和医学院 医学信息研究所 医学智能计算研究室, 北京100020)
机器学习是指将预测模型与数据进行拟合,或者在数据中识别具有信息性的分组的过程[1]。在面对样本量巨大或拥有大量特征的数据集时,机器学习方法可以建立自动化的数据分析过程,从数据集中不断学习知识并逐渐提高对新数据的预测能力。目前,机器学习模型已广泛应用于疾病预防、诊断、治疗和预后的相关预测,如疾病风险预测[2]、患者再次入院预测[3]、死亡预测[4]、药物相互作用预测[5]和患者护理需求预测[6]等方面,并且取得了良好的预测性能[7]。
将机器学习应用于临床医学的主要目标包括:①对预测任务做出准确的预测和判断;②利用训练好的模型指导临床实践和临床研究[8]。但是在目前的机器学习应用过程中,大多数研究专注于预测准确性,而忽略了结合具体数据对预测结果进行解释。由于机器学习模型的复杂性,用于产生最终输出的过程往往缺乏透明度,模型结果通常很难解释。此外,在临床应用中,机器学习模型通常只在一个狭窄的环境中针对特定的疾病进行训练和评估,并依赖于个人的统计学和机器学习专业技术知识。为了便于医疗工作者理解机器学习模型做出预测的依据,还需要进一步对高度复杂的预测模型进行解释。模型的高解释性意味着终端用户可以更容易理解和解释未来的预测,机器学习的可解释性与实现高预测准确性同样重要[9]。
本文将概述可解释机器学习方法及其在疾病预测中的工作流程,通过利用临床结构化数据构建应用实例,并从全局和局部两个方面对预测模型进行解释。本研究不关注建立在非结构化数据(如不同类型的医学图像、文本或其他基于信号的数据)上的机器学习模型的可解释性研究。
1 可解释机器学习方法
1.1 机器学习方法的可解释性定义
数据挖掘和机器学习场景中,可解释性被定义为机器学习方法向人类解释或呈现可解释的术语的能力[10]。根据不同的机器学习模型在对预测结果的解释性方面的不同,可以分为具有内在解释性的机器学习方法和自身解释性能比较差的机器学习方法。
内在可解释性是指已训练好的模型无需额外的信息就可以理解模型的决策过程或决策依据,这类解释性发生在训练之前,也称为事前可解释性。这类模型有朴素贝叶斯、线性回归、决策树、基于规则的方法等。决策树和回归模型都只能提供有限的可解释性,特别是在捕获数据中的非线性的情况。决策树由于其图形化的表示,可以轻松地概览它复杂的模型运算过程;影响模型预测的最重要的特征往往显示在树的顶部,这也可以表示特征在预测中的相对重要性。
不可解释模型或黑箱模型通常是只关注结果的复杂模型,例如,分类器集成模型或深度神经网络,这类模型往往可以取得较高的预测准确率。针对这类模型的解释,往往是在模型训练好之后进行的,所以也称之为事后可解释性。
1.2 机器学习方法可解释性的分类
对于不可解释机器学习模型的可解释方法,可以分为局部可解释性和全局可解释性[8]。传统上,机器学习研究的重点是全局可解释性,以帮助理解机器学习模型的所有可能输入和模型所做的所有预测空间之间的关系,相比之下局部可解释性是帮助理解对特定样本或训练后的预测函数的一个小的、特定区域的预测。
模型的局部解释方法[11]旨在帮助人们理解学习模型针对每一个特定输入病例的决策过程和决策依据。模型的局部可解释性以输入样本为导向,通过分析输入样本的每一维特征对模型最终决策结果的贡献来实现对决策的解释。局部解释技术直到最近才被频繁使用,它们适合用于没有解释性或弱解释性模型的个性化水平上对预测结果进行特征重要性分析。
局部可解释性技术(interpretable model-agnostic explanation, LIME)是一种使用简单的模型来对复杂的模型进行解释的方法,常用于在解释黑盒机器学习模型的单个样本的预测。LIME的原理是产生一个新的数据集(这个数据集是通过对某一个样本量的数据集合进行变换得到),然后在这个新的数据集上训练一个可解释的模型。目标是可解释的模型在新数据集上的预测结果和复杂模型在该数据集上的预测结果是相似的。该方法表述如下式所示:
f表示原始的模型, 即需要解释的模型;g表示简单模型,G是可解释模型的一个集合, 如所有可能的线性模型;πx表示新数据集中的数据x’与原始数据x的距离;Ω(g)表示模型g的复杂程度。
Shaply值是基于博弈论思想的一种局部解释方法[12]。其基本的设计思想是:首先计算一个特征加入到模型当中时的边际贡献,然后计算该特征在所有特征序列中不同的边际贡献,最后计算该特征的Shaply值,即该特征所有边际贡献的均值。Shaply值计算的优势在于能够反映出样本中每一个特征对预测结果的影响力,而且还可以指出其影响程度的正负性。
全局可解释性[13]是指在全局层面上为模型内部的情况提供解析,帮助人们从整体上理解模型背后的复杂逻辑以及内部的工作机制。例如,模型是如何学习的、模型从训练数据中学到了什么、模型是如何进行决策的等,这要求研究人员能以人类可理解的方式来表示一个复杂模型的训练过程。有研究[14]显示,特定群体可解释性方法应被称为群体特异可解释性,在这种方法中,他们只关注与预测结果相关的人口亚群体的特征。全局可解释性技术[15]:包括置换特征重要性[16]、部分依赖图[17]和个人条件期望[18]、全局代理模型[19]等。
置换特征重要性:通过计算置换特征后模型预测误差的增加来衡量特征的重要性。如果置换某特征值会增加模型预测的误差,则该特征是“重要的”,说明模型依赖于该特征进行预测,如果模型的预测误差不变则该特征是“不重要的”。部分依赖图:显示了单个特征对先前拟合模型预测的结局的边际效应,预测函数固定在所选特征的值上,并在其他特征上取平均值。部分依赖图的解释方式与回归模型相同。个体条件期望:通过显示数据集中每个实例的估计功能关系,可以将个体条件期望图视为部分依赖图的分解视图。其中每个实例显示一条线,显示当特征发生变化时该实例的预测如何变化。全局代理模型:使用简单的可解释机器学习模型(如线性回归、决策树)来拟合复杂机器学习模型的预测,它们不需要有关黑盒模型的内部工作过程和超参数设置等信息。使用用于训练弱解释性模型的数据集(或具有相同分布的数据集)作为训练集、该模型的预测结果作为预测值来训练可解释模型。评价代理模型与被解释模型的相似性的计算方式如下:
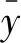
2 可解释机器学习方法应用流程
机器学习方法在疾病预测中的应用,可以归纳为如图1所示的工作流程。
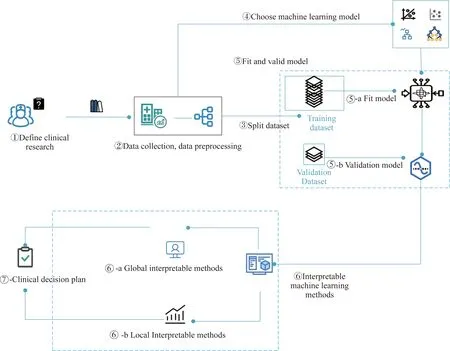
图1 可解释机器学习方法在疾病预测过程中的工作流程Fig.1 Workflow of interpretable machine learning methods in disease prediction
①疾病预测问题定义:确定需要待研究的疾病预测问题并进行定义,主要包括确定研究所关注的结局变量以及临床所关心的与该结局相关的临床指标;
②数据采集和数据清洗:根据所确定的研究问题来确定需要获取的数据。对数据进行预处理,使其可以供模型输入,该过程主要包括对数据进行缺失值的处理、非连续性变量的处理等;③数据集划分:在机器学习方法中,需要对数据进行划分,设置训练集用于机器学习模型的训练,设置测试集用于机器学习模型性能的验证;④机器学习模型选择:依据研究的临床问题以及获取的临床数据,选择合适的机器学习模型用于临床任务;⑤模型构建与评估:基于训练数据集进行模型构建,并在测试集上进行模型性能的评估;⑥机器学习模型解释:对训练后的模型决策进行解释与分析;⑦形成临床决策参考方案:获得模型决策方案和模型决策相关的因素,为临床决策提供参考。
3 应用实例:脓毒血症患者死亡风险预测研究
3.1 数据来源及模型构建
数据来源于重症监护医学数据库(Medical Information Mart for Intensive Care, MIMIC)-Ⅳ数据库,MIMIC-Ⅳ数据库是由麻省理工学院计算生理学实验室及其合作研究机构创建并维护的大型公开数据库,收集了2008年至2019年间美国马萨诸塞州(Massachusetts)波士顿市三级学术医疗中心住院患者的临床信息,主要包括患者的人口学信息、实验室检查值、药物治疗记录、记录的生命体征等。在获得数据使用权限后,笔者从MIMIC-Ⅳ数据库中获取脓毒血症患者的临床数据,并按照以下标准纳入19 903名研究对象:①年龄大于18岁且小于89岁;②重症加强护理病房(intensive care unit, ICU)住院时间超过24 h;③对于存在多条ICU住院记录的患者,仅选取最后一条记录。每名患者包含18个属性,具体属性特征名称及含义如表1所示。本研究利用的研究信息不含有使受试者的身份被直接识别或通过与其相关的识别物识别的信息,属于免除伦理审查。作为历史性研究可免除研究对象知情同意。
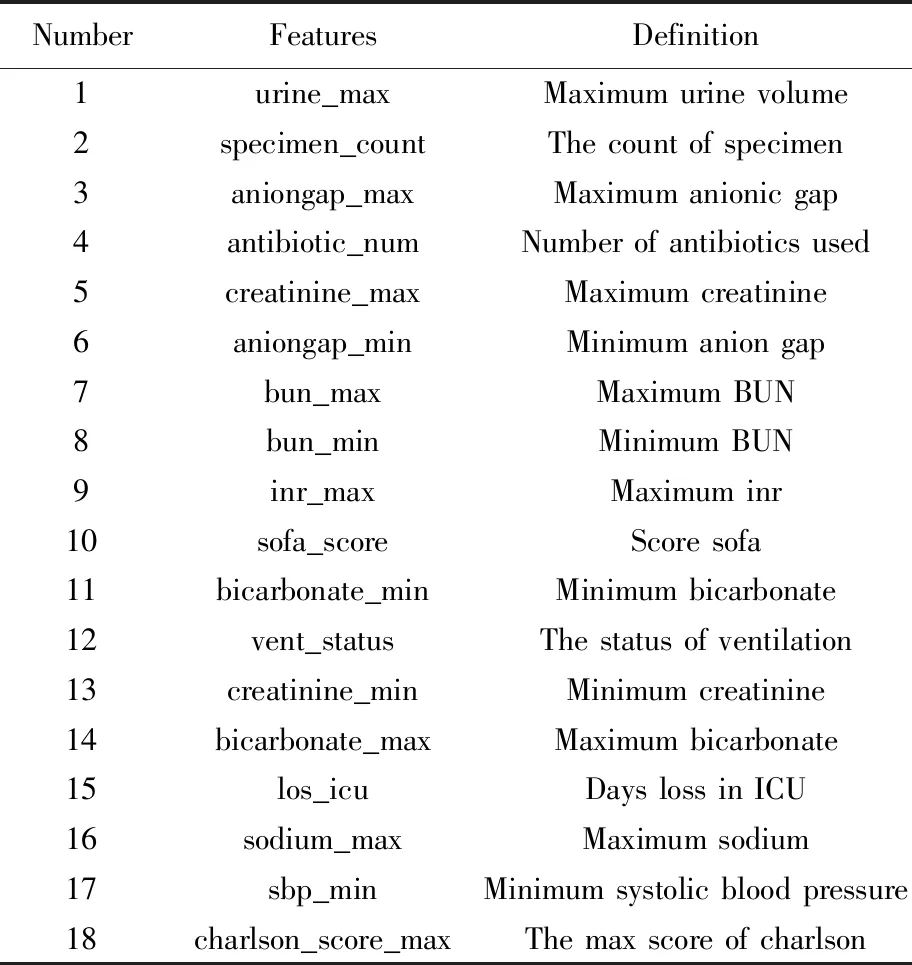
表1 患者特征名称及其含义Tab. 1 Patient features and their definition
对于处理好的样本数据,采用具有内在解释性的模型(决策树[20]、逻辑回归[21])以及不可解释的集成模型[随机森林[22],XGBoost[23],轻量梯度提升机(light gradient boosting machine,LightGBM)[15]]来构建脓毒血症死亡风险预测模型,并对不同模型预测性能进行比较。本文算法使用Python(version 3.8)编程语言基于sklearn(version 1.1.0)机器学习工具包实现。模型评价采用十折交叉验证得到的准确性(accuracy)、灵敏度(sensitivity)、特异度(specificity)、受试者工作特征曲线下面积(area under curve,AUC)等指标(表2)。相对而言,与具有内在可解释性的机器学习方法(逻辑回归模型, 决策树模型的AUC值分别为0.78,0.79)相比,解释性较差的集成模型预测性能更好,其中性能最好的是利用LightGBM构建的预测模型(AUC值为0.91),详见图2。
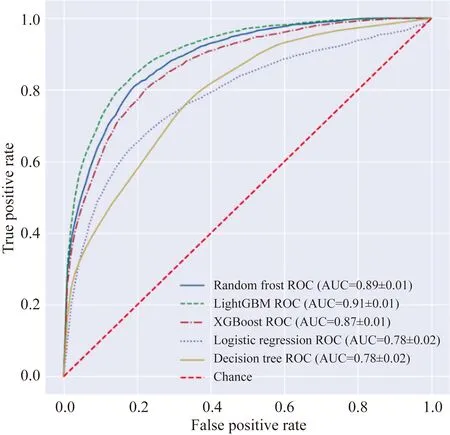
图2 算法模型性能对比Fig.2 Algorithm performance comparison
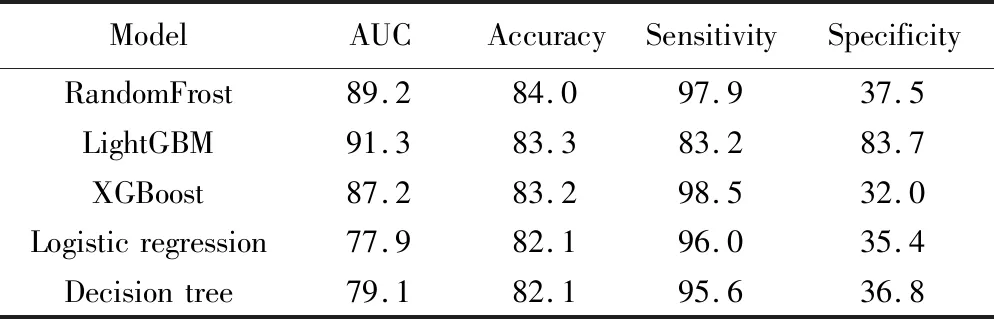
表2 模型预测性能对比Tab. 2 Comparison of model prediction performance (%)
3.2 模型的可解释性分析
对预测性能最好的LightGBM模型,分别利用四种全局可解释性技术(特征重要性、部分依赖图、个体条件期望、全局代理模型)和两种局部解释技术(LIME和Shapley值)对预测结果进行解释。
3.2.1 全局可解释技术
1)特征重要性
图 3显示了所有输入特征在脓毒血症死亡风险预测中的置换特征重要性排名[24]。如图所示,医院住院时长是影响脓毒血症患者死亡风险最重要的特征,其次是重症监护室看护时间。Charlson合并症指数、最大排尿量[25]、服用抗生素药物数量等也是比较重要的影响因素。
2)部分依赖图和个体条件期望图
选取特征重要性靠前的四个特征进行分析。图4显示了重要特征的部分依赖图和个体条件期望图,黄线显示了住院时间、ICU住院时间、Charlson合并症指数、最大排尿量对脓毒血症死亡风险概率的部分依赖图。图4中蓝线显示的是该特征个体死亡风险概率的条件期望图(本实验随机挑选50个样本展示)。图4A显示住院时间的特征部分依赖图可以看出,在总住院时长为20 d以内时,随着住院时长的增加,脓毒血症的死亡风险从0.8降低到0.25,然后处于稳定状态。图4B显示ICU住院时长的部分依赖图呈现出相反的趋势,在ICU住院时长15 d内,脓毒
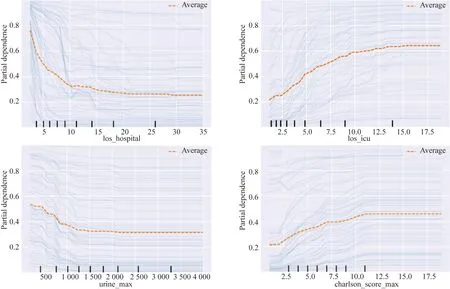
图4 重要特征的部分依赖图和个体条件期望Fig.4 Partial dependence plots for the highly ranked features
血症的死亡风险增加,之后保持平稳。图4C显示日最大排尿量在2 000 mL之内时,表现出随着最大排尿量增加,患者死亡风险降低的趋势。图4D显示代表合并症评分的Charlson合并症指数,在10分以内也表现出增加死亡风险的趋势。
3)全局代理模型
使用原始数据集训练具有内在解释性的决策树模型,以LightGBM模型的预测结果作为该模型的结局。本研究通过设置决策树模型的深度参数(在一定程度上反映了决策的复杂度)来评价不同深度条件下决策树模型对LightGBM模型的拟合能力。结果显示(表3),随着决策树深度的增加,代理模型的预测能力不断增加,但达到一定深度后拟合能力不再提升。

表3 代理模型复杂度和与被代理模型相似性的关系Tab. 3 The relationship between global surrogate model complexity and interpretability
3.2.2 局部可解释技术
由于LIME和Shapley值解释器是基于实例的解释器,因此在下文中,基于从测试数据集中随机选择的两个实例来评估这两个解释器。展示两个已被预测模型正确预测的实例,一个来自正确预测为死亡高风险(true positive)组的实例,另一个实例来自正确预测为死亡的低风险(true negative)组。
正确预测的真阳性案例的描述如下:ICU住院时长=14.33 d,普通住院时长=14.42 d,最大尿量=558 mL,通气状态等级=4,服用抗生素数量=13,最大吸入量=5。图5A显示了利用LIME对该实例的解释,绿色的特征表示该特征支持预测结果为阳性即死亡,红色的特征表示该特征不支持预测为死亡。该实例中ICU住院时长大于7.56 d,排尿量小于905 mL,通气状态为4,抗生素使用量大于8种,最大吸入量大于1.7,这些特征值会增加死亡概率。图5B显示了利用Shaply值对该病例的解释,也提示该病例的ICU住院天数、最大排尿量、最大吸入量、抗生素使用数量等特征增加了该病例的死亡风险。并且两个解释器都认为该病例的住院时长特征不支持预测为死亡。
正确预测的真阴性案例:用LIME解释时,该实例的描述如下:ICU住院时长=1.5 d,最高体温=36.67 ℃,最大尿量=2 585 mL,通气状态等级=4,最大呼吸频率=24,Charlson合并症指数=5。图5C显示了利用LIME对该实例的解释,ICU住院时长、最大排尿量、呼吸频率、Charlson合并症指数等特征支持预测死亡风险低。图5D显示了利用Shaply值对该病例的解释,也提示这些特征支持预测结局为低风险。
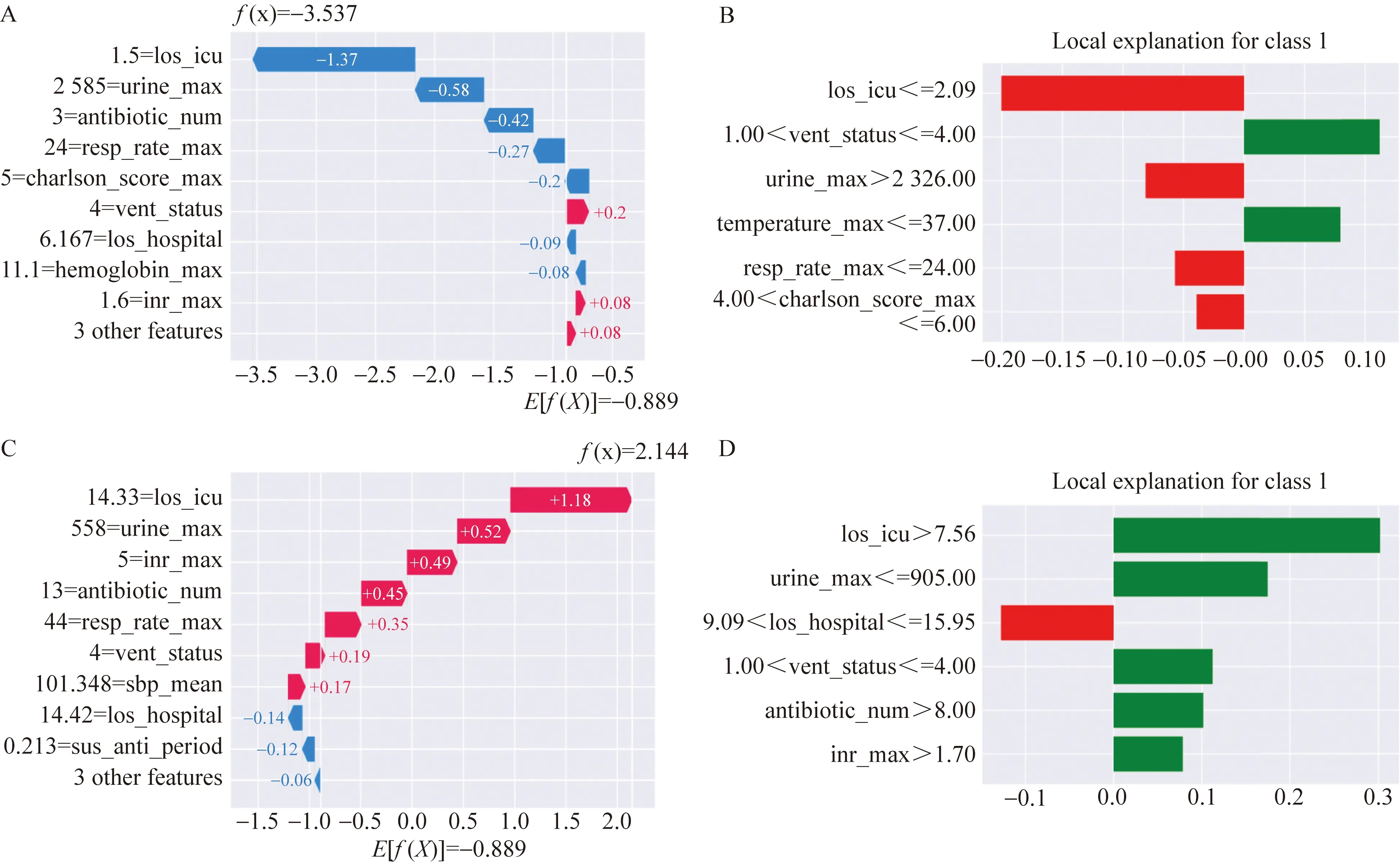
图5 模型正确预测案例基于局部可解释性的可视化解释Fig.5 Local interpretable of the model’s correct prediction cases
总结两类模型解释方法可以得出:从基于LightGBM的脓毒血症死亡风险预测模型的全局模型解释分析中可以看出,住院天数、ICU住院天数、Charlson合并症指数、最大排尿量、抗生素使用数量等是对模型预测结果比较重要的特征。依据部分依赖图和个体期望可以进一步分析出患者的死亡风险随着不同特征的具体变化趋势而变化。例如,ICU住院时长越长、查尔斯死亡指数越高,死亡风险也越高;随着个体日最大排尿量的增加、住院天数的增加,死亡风险降低。局部可解释性技术则可以从样本级别给出个体死亡风险预测的详细解释。
全局解释方法可以使临床医生了解在整个特征空间内模型的响应趋势。相比之下,局部解释方法可以对特定个体进行基于特征的决策解释。在实践中,这两种方法都可以协助临床医生进行医疗过程的有效决策。
4 讨论
本文讨论了现在临床环境中使用的机器学习方法的解释性,根据是否存在内在解释性,将模型分为具有内在解释性的模型(事前解释性)和解释性差的事后模型。并以脓毒血症患者死亡风险研究作为研究实例比较不同类型的机器学习方法的预测性能,复杂集成模型拥有较高的预测性能,但是解释性较差,然后使用机器学习解释方法分别对模型进行基于人群和个体的解释。
理解机器学习的工作原理,研究透明的、可解释且可证明的机器学习技术有助于推动其在各领域的扩展应用。虽然目前的解释方法可以在人群和个体层面上对机器学习模型的预测结局进行分析解释,但是解释结果依然不够清晰,并且存在因为模型是基于特定人群训练产生,在模型迁移能力方面往往受限于训练人群。现有的解释方法的决策依据多为统计学方法,依赖对机器学习模型的结果再分析解读,缺乏结合具体临床意义进行推理的解释方法。随着因果推断技术的发展,该技术被用于临床数据分析,可以提高决策可解释性[26]。并且基于图神经网络的机器学习方法在临床结构化数据分析中的应用,提供了基于领域知识图谱进行机器学习方法解释的可能性。
利益冲突所有作者均声明不存在利益冲突。
作者贡献声明杨丰春:负责研究设计,数据获取与分析,论文撰写;郑思:负责算法设计、论文撰写与修改;李姣:负责研究设计,研究方案实施,论文撰写与修改。
