基于联邦学习的移动通信资源管理:方法、进展与展望
2022-07-11孙恩昌何若兰张冬英张延华
孙恩昌,张 卉,何若兰,张冬英,张延华,3
(1.北京工业大学信息学部,北京 100124;2.北京工业大学信息化建设与管理中心,北京 100124;3.先进信息网络北京实验室,北京 100124)
随着数字化进入高速发展时期,大数据和人工智能(artificial intelligence,AI)等技术迎来爆发式增长的同时移动网络也更加自主化、异构化和动态化,这使得网络资源的有效分配愈加复杂和困难.因此,快捷且高效地分配和管理通信网络资源愈发迫切.另外,加之人们信息保护意识的增强以及数据传输效率要求的提高,联邦学习(federated learning,FL)[1]成为解决上述问题的有效技术之一.
FL于2016年由谷歌提出,已经成为AI研究与应用领域的焦点,有望成为下一代AI协作网络架构的基础[2].它作为一个较新的机器学习范例,一经推出便受到了广泛的关注.与传统的机器学习相比,FL能够提高学习效率,保护数据隐私,并且解决数据孤岛问题.国内外FL的相关研究主要针对学习算法设计、激励机制设计与安全算法和计算与通信资源优化等.目前,FL在移动通信领域的研究进展主要侧重于在保护数据安全与隐私的同时对移动通信资源进行智能和有效的管理.
在移动通信中引入FL,带来诸多便利的同时也面临着挑战,例如能量分配、功率控制、计算与通信开销的优化等.与已有的FL资源管理方法综述不同,本文首先重点介绍了FL在不同网络场景,如分布式无线网络、移动边缘网络、车联网、雾无线接入网络(fog radio access network,F-RAN)和超密集网络等场景中的资源管理方法,纵向总结和横向比较各种方法的性能与不足;然后,给出了FL资源管理相关研究的主要挑战;最后,对FL资源管理未来潜在的研究方向进行了展望.
1 FL基础知识
1.1 FL概念
目前,对于FL概念有诸多描述,具有代表性的有:FL是一种在不共享数据的情况下完成联合建模的技术[1];FL是一种用加密机制完成数据传输从而在客户端建立高质量模型的框架[2];FL是设备与中央服务器协作以进行分布式机器学习设置的方法[3];等等.综上分析,本文认为FL是一种分布式机器学习方法,用于建立终端设备与服务器之间的共享模型,即各个参与者利用本地数据进行训练并将获得的模型训练参数上传至服务器,再由服务器进行聚合,更新得到总体参数,然后不断迭代直至达到给定精度的学习方法.
1.2 FL分类
根据数据集分布情况的不同,FL一般分为横向FL(horizontal federated learning,HFL)、纵向FL(vertical federated learning,VFL)和联邦迁移学习(federated transfer learning,FTL)[1].
1) HFL:在数据集间不同用户具有相同业务需求的情况下引入,将数据集按照横向(用户维度)划分(见图1),取出具有相同业务需求的用户数据进行联合训练以扩大训练的样本空间.由于数据集间具有相同业务需求的用户是不完全相同的,故数据集间用户相似度少,用户业务需求相似度多.
2) VFL:在数据集间相同用户具有不同业务需求的情况下引入,将数据集按照纵向(用户业务需求维度)划分(见图2),取出具有不同业务需求的用户数据进行联合训练以增强用户训练模型的效果.由于数据集间相同用户分别有不完全相同的业务需求,故数据集间用户相似度多,用户业务需求相似度少.

图2 纵向联邦学习[1]Fig.2 Vertical federated learning[1]
3) FTL:在数据集间不同用户具有不同业务需求的情况下引入,不对数据集进行切分,如图3所示.因数据集间不同用户具有不同的业务需求,故数据集间用户和用户业务需求相似度都较少,利用迁移学习辅助FL训练以克服数据集间用户和用户业务需求相似度少引起的训练数据不足的问题[4].

图3 联邦迁移学习[1]Fig.3 Federated transfer learning[1]
本文对比了3类FL的主要特征,如表1所示.HFL、VFL和FTL三者的本质区别在于不同数据集之间用户和用户业务需求的相似度.

表1 3类FL对比Table 1 Comparison of three types of FL
1.3 FL主要特点
与其他机器学习相比,FL主要具有如下特点:
1) 保护用户隐私.数据存储在本地,各个参与方数据不共享,保证了用户数据隐私[1].
2) 参与方享有平等地位.各参与方享有对等地位,实现共同繁荣[2].
3) 保证训练出的模型效果无损.FL模型训练过程中不会出现负迁移,保证联邦模型比独立模型效果好[5].
4) 低延迟.仅将模型更新参数上传至服务器进行全局聚合[6].
本文对FL与传统分布式机器学习[7]进行了对比,如表2所示.FL相较于传统分布式机器学习最大的优点是FL在保护用户隐私的同时,还可以完成数据参数的高效传输.

表2 FL与传统分布式机器学习对比Table 2 Comparison between FL and traditional distributed machine learning
2 基于FL的通信资源管理方法
FL主要包括2个核心过程(见图4):1) 设备在本地训练完成后,将模型训练参数上传至服务器;2) 服务器对各个设备的模型训练参数进行聚合和更新.为了提高移动通信资源管理的效率,一些研究已经在相关领域场景中探索将FL与其他算法或技术相结合.本节详细介绍FL在分布式无线网络、移动边缘网络、车联网、F-RAN和超密集网络场景中资源管理方法的研究进展.
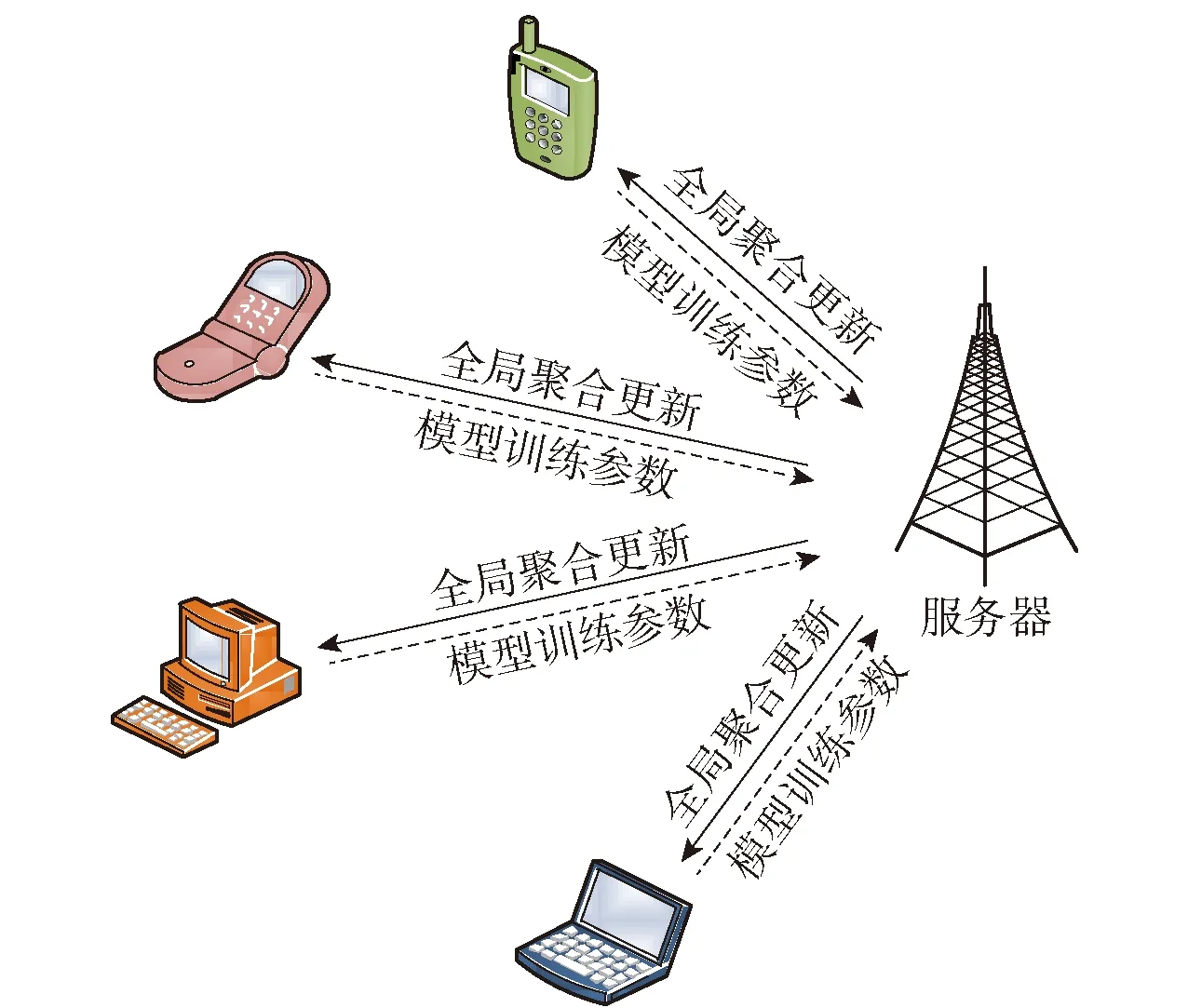
图4 FL工作过程Fig.4 Working process of FL
2.1 FL与分布式无线网络
分布式无线网络是由分布在不同地点的终端节点互联而成的网状结构.随着网络中新兴应用的增加,设备在进行数据处理时容易受到能量有限的制约.为此,有学者利用FL以分布式方式训练模型的特点将上述问题优化为FL训练时间和设备能耗最小化问题[8-9].在能量有限情况下,文献[8]以FL模型训练时间最小化为目标,利用在线逐次凸逼近方法来解决FL训练时间与计算之间的随机非凸优化问题.在每次FL迭代过程中,利用网络接入点作为设备和中心服务器的中继点以提高系统更新参数的性能,根据设备能耗和信道估计不完全的实际条件与网络接入点和服务器之间实际能耗需求进行功率分配,在减少FL训练时间的同时,优化服务器聚合参数的频率.受此启发,文献[9]提出低复杂度的迭代算法,利用FL低延迟的特点,在每一次迭代时实时推导出新的功率分配和带宽分配的封闭解,根据每一次迭代过程的封闭解调整和优化下一迭代过程中模型的参数,达到了消耗总能量少、资源利用率高的目标.当参与设备较多时,能量利用率会急剧下降.针对这一缺陷,文献[10]考虑到在无线网络中执行FL有时会受到能量限制,提出光波传输功率方案,每个设备通过红外光和可见光收集能量,利用所收集的能量执行计算和参数传输任务.因为设备进行计算时比参数传输时消耗的能量多,所以Tran等[10]指出应尽可能地为计算过程分配更多的能量.为了进一步优化传输功率,文献[11]提出度量参数更新时效性(age of update,AoU)算法,首先将需要向中心服务器发送的训练数据分离,使其保留在本地设备训练,然后将模型训练参数上传至服务器,服务器根据设备更新参数快慢进行功率分配,得到了在给定资源块约束下的最佳传输功率,但是该方法延迟较大.对此不足,文献[12-13]做出改进.与文献[11]相比,文献[12]同时考虑了资源块和设备能量的约束,提出一种启发式算法,利用FL支持服务器与设备共享模型参数的特点,研究了优化资源块分配和设备功率选择问题,相较于AoU算法,该算法有效降低了延迟.文献[13]基于FL提出数字孪生(digital twin,DT)算法并将其应用于分布式无线网络,设备通过DT将局部模型参数直接映射到服务器,实现设备与服务器之间几乎实时的连接.
特别地,利用FL还可以实现分布式无线网络中带宽和功率的有效管理.在带宽有限的条件下,文献[14]发现在不同的信噪比阈值下FL达到给定收敛域的速度不同,根据FL不同的收敛速度自适应调整用户设备的调度策略,然后利用最优化理论和随机几何推导分析得出用户设备数量和信道带宽之间的权衡.进一步,文献[15]提出设备调度和带宽分配的具体策略,首先FL系统地协调服务器和设备上的模型训练以更快适应设备的计算能力和状态,从而保证设备的学习性能,然后根据上述状态优先调度计算能力或信道优先级高的用户设备,对于计算能力较差或信道较弱的设备,分配给其更多的带宽,这样可以在避免带宽浪费的同时降低能量消耗,但其受到延迟制约.为了尽可能降低延迟,Shi等[16]同样从用户设备调度和带宽分配问题出发进行研究,带宽分配同样采用文献[15]的策略,而设备调度则采用贪婪策略.服务器根据各网络节点中分布的数据,快速地选择模型更新中消耗资源最少的用户设备执行任务,直到每轮学习效率和延迟之间取得较好的平衡.与文献[14-16]所述不同的是,文献[17]提出自适应压缩FL共享参数算法,该算法在服务器获取各设备共享参数的基础之上,根据设备数量自适应调整FL共享参数信息的压缩率来适应动态带宽,但参数压缩率较低时,其在不可靠的网络条件下表现不佳.针对此不足,文献[18]提出基于FL的动态缓存分配(federated learning-based dynamic cache allocation,FedCache)方案.FedCache使用FL学习低通信开销的缓存分配,使边缘节点在本地学习以适应不同的网络条件并协作共享这些信息,服务器根据网络中设备的缓存效率,将带宽公平地分配给这些相互竞争的设备.关于功率的有效分配,文献[19]提出基于支持向量机(support vector machine,SVM)的FL,该方案使服务器和用户设备关联并建立全局SVM模型,服务器收集关联用户设备的相关任务信息,而SVM模型则用来分析未来关联设备与当前时隙中每个设备要处理的任务,然后结合梯度下降方法优化每个设备的功率和任务分配,使任务计算和参数传输时消耗能量最小.文献[20]优先考虑设备服务质量(quality of service,QoS)要求,提出采用动作评价(actor-critic,AC)算法.FL将AC模型作为局部训练模型,每个设备通过FL训练本地AC模型,将产生的梯度和权重上传到服务器聚合,实现边缘用户协作的同时获得功率分配策略.相较于基于FL的SVM算法,该算法具有较好的收敛性、鲁棒性和更高的功率分配精度.
综上所述,基于FL的分布式无线网络资源管理方法,实现了能量、带宽和功率的有效管理.其不需要将原始模型数据上传至服务器,仅将模型训练参数上传,为设备的训练过程提供了安全可靠的训练机制,有效地代替了传统分布式机器学习训练模型的方法,大大降低了系统的能耗,避免了资源浪费,提升了分布式无线网络的安全隐私性.
本文总结了基于FL的分布式无线网络资源管理方法,如表3所示.上述方法在FL的辅助下,为分布式无线网络提供了动态的资源管理方案,使能量管理、带宽分配和功率分配等的效率有所提升.然而,如何利用FL的分布式架构在保证收敛性和低延迟的前提下解决更为复杂的分布式无线网络资源管理问题,同样值得深入研究.

表3 基于FL的分布式无线网络资源管理方法Table 3 Distributed wireless network resource management methods based on FL
2.2 FL与移动边缘网络
移动边缘网络是采用分布式移动边缘计算(mobile edge computing,MEC)[21]的边缘接入网络,具有低延迟和高带宽等优势.但是随着移动边缘网络复杂性的提高,当面临的数据量很大时,移动边缘网络的资源管理效率不佳.为此,有学者基于FL研究了移动边缘网络计算和通信的联合优化问题[22-25].Wang等[22]为了兼顾计算与通信开销之间的权衡提出“In-Edge AI”框架,该框架利用FL认知性、鲁棒性和灵活性的特点,在FL优化移动边缘网络计算和通信的同时,使设备和边缘节点协作来交换学习参数,智能部署资源,而当其业务种类较多时,业务处理效率下降.针对这一不足,文献[23-24]以细粒度方式对业务进行精细划分.文献[23]根据边缘网络上FL的非凸性,将移动边缘网络中的业务以细粒度方式分解为共享资源分配、局部模型精度调整和中央处理器(central processing unit,CPU)频率调整3个子业务来寻找最佳学习精度,然后FL系统将这些业务根据轻重缓急分时更新参数传输,提高了业务处理效率,实现了计算与通信开销之间的平衡.文献[24]则根据FL处理数据的灵活性和精度可调的优势,利用李雅普诺夫理论设计了具有成本效益的跨边缘节点的FL框架,它可以灵活扩展,简化业务处理方式,实现在资源分配、模型精度调整、负载均衡等业务中做出接近最优的决策.但上述研究都未考虑业务量和用户终端电池状态的关联问题,对此文献[25]将FL和MEC联合构成移动边缘系统,该系统一方面使服务器从相关边缘设备收集模型参数,降低延迟,另一方面用以缓解边缘用户设备的电池消耗和计算资源异构问题,然后根据设备的业务量、通信质量和剩余电池电量选择系统要处理的业务,提高了业务的处理效率和用户设备之间的公平性.
FL还可以实现移动边缘网络中设备频率的有效管理[26-29].文献[26]提出自适应同步算法,使每个参与设备同时进入FL迭代过程执行局部模型更新,服务器定期对设备迭代过程快慢进行评估,为速度慢的设备增加通信频率,使整个FL系统趋近于平衡.但是,同步算法中快速完成训练的设备必须等待其他速度较慢的设备完成训练后才能进入下一迭代过程,这会增加迭代过程的时间,引起资源浪费.针对这一不足,文献[27]基于FL提出了异步频率聚合算法,在初期FL进行局部模型训练获得共享参数信息,服务器根据共享参数信息推断出设备的训练速度,然后根据不同的训练速度为设备分配不同的频率以实现异步聚合,在减少FL迭代过程收敛时间的同时,保护了各个用户设备的隐私.但文献[26-27]都未考虑全局聚合频率的适应性,文献[28]提出确定全局聚合频率的算法,通过服务器在不同的边缘节点获得模型参数,从而确定FL训练过程局部更新参数和全局参数聚合之间的最佳折中,实时动态自适应设备全局聚合的频率以最大程度地减少固定资源下的学习损失预算,不幸的是其在异构场景中效果较差.针对这一缺陷,Zhan等[29]从实际出发考虑了移动设备和网络连接的异构性提出基于深度强化学习(deep reinforcement learning,DRL)的经验驱动算法,使其更适于异构场景.该方法采用AC训练DRL代理,然后代理根据设备的工作状态为其分配合适的CPU频率.此外,DRL代理通过适当降低参与设备中数据处理速度快的设备的CPU频率来提高系统的能量利用率.
Mills等[30]、Sattler等[31]对移动边缘网络的链路参数传输进行了研究.文献[30]提出高效联邦聚合算法(communication-efficient federated averaging,CE-FedAvg).该算法由分布式优化和上传模型压缩算法两部分构成:分布式优化算法可以使FL以较少的迭代过程达到学习精度,降低通信开销;上传模型压缩算法通过适当压缩FL系统中设备的模型参数减少上行链路参数传输的大小.文献[31]指出仅对上行链路参数传输进行调整存在着一定的局限性,针对此不足,提出稀疏三进制压缩(sparse ternary compression,STC)算法.STC算法扩展了Top-k梯度稀疏化,通过分散分层的方法压缩上行链路和下行链路共享模型参数以及权重更新,实现向高频低带宽通信模式的转变.与CE-FedAvg算法相比,该算法更适用于带宽受限的环境,同时以更少的迭代次数达到FL的学习精度.
综上所述,基于FL的移动边缘网络资源管理方法,实现了移动边缘网络中资源管理的优化,使FL成为移动边缘网络资源管理的使能技术.因为它不仅可以实现机器学习模型的协同训练,也可以利用边缘邻近的中心服务器进行全局参数聚合更新,减轻远程云服务器的负担.
本文总结了基于FL的移动边缘网络资源管理方法,如表4所示.FL与移动边缘网络资源管理的相关研究进展主要集中于计算与通信开销联合优化、频率管理和链路资源管理.虽然FL的快速发展与广泛运用为移动边缘网络的资源管理提供了新思路,但是如何在移动边缘网络中深度融合FL来实现高稳定性、低成本的保障隐私安全的资源管理方案,仍然是值得思考的问题.

表4 基于FL的移动边缘网络资源管理方法Table 4 Mobile edge network resource management methods based on FL
2.3 FL与其他新兴网络
FL不仅可以在分布式无线网络和移动边缘网络中进行高效的资源管理,它还广泛应用于各类动态且复杂的网络场景.本节以FL在车联网、F-RAN和超密集网络中资源管理方法的研究进展为例进行介绍.
在车联网中,文献[32]将联合功率控制和资源分配表述为全网功率最小化问题,结合FL和极限值理论,提出基于李雅普诺夫的车辆用户分布式发射功率和资源分配算法.FL不依赖于车载用户之间实际队列长度样本的信息同步,便可学习网络范围队列的统计信息,而李雅普诺夫优化算法利用统计信息得出车辆用户的队列长度,然后根据队列长度进行合理的功率和资源分配.与集中式解决方案相比,该方案能耗低、效率高,但是该方案无法适应具有多种潜在车辆用户的场景.为了弥补文献[32]的不足,文献[33]提出车联网MEC方案,该方案自适应地将车辆用户和路边单元作为代理,利用FL优化参数集成来提高数据处理效率和降低延迟,使其适用于复杂的车辆用户场景,但是当车辆用户较多时,代理可信度骤降.文献[34]提出异步FL,将FL与DRL相结合,利用DRL对可信度高的代理进行选择.同时,为了保证车辆用户间共享数据的可靠性,又提出将FL与区块链集成到车联网中,开发了混合区块链算法,FL用于保护车辆用户的隐私,区块链为不可信车辆用户提供有保证的协作方案,从而实现信息的高效、安全、共享.
在F-RAN中,文献[35]基于FL提出交替方向算法(alternative direction algorithm,ALTD),研究了设备的CPU频率和无线传输功率控制问题,将控制问题联合优化为非线性规划问题来平衡F-RAN中设备能耗与FL计算和通信延迟之间的权衡.在该研究中利用FL在物联网设备中进行局部模型训练,仅在F-RAN节点中共享模型参数信息,以减少网络流量的使用,而ALTD算法则根据网络带宽适当调整设备无线传输功率,通过动态电压控制CPU工作频率,实现FL在时间约束下设备能耗最小的目标.文献[36-37]均采用自适应智能联合算法来提高资源利用率.具体来讲,文献[36]基于FL提出上下文感知流行度预测策略,运用FL分布式训练模型的特点来构建全局预测模型以降低计算复杂度,节省传输本地数据参数的带宽.预测模型的输入是集群用户内容的平均受欢迎程度参数,该参数通过用户偏好学习和自适应上下文空间划分进行预处理,准确地预测内容(受欢迎程度)可以有效地降低通信开销.为了进一步提高用户QoS,文献[37]基于FL提出采用遗传算法来解决由于本地过载而导致的QoS下降的问题,该方法允许FL在共享资源的多个雾程序之间分配负载,使设备用户享受无延迟体验的同时,FL保证了用户的隐私安全.
此外,在超密集网络中,Yu等[38]联合FL和DRL提出两时标DRL算法,实现了低开销的资源分配.该研究包括2个过程,分别是快速时间尺度和慢速时间尺度学习过程,参与这2个过程的设备都进行FL训练,以保护边缘用户的敏感服务请求信息.其中:快速时间过程用来处理对延迟敏感的任务,如计算卸载和资源分配策略;慢速时间过程用来处理对延迟不敏感的任务,即服务缓存.通过2个过程的联合来最小化总卸载延迟和节省网络资源.
综上所述,FL在车联网、F-RAN和超密集网络中的资源管理方案,大都以FL分布式训练模型的特点为出发点展开研究,也即FL机器学习模型分布在不同的本地设备进行训练,将模型参数上传至中心服务器进行共享,然后聚合生成鲁棒性强的学习模型参数,达到一方面降低中心服务器的压力,提高数据处理效率,另一方面保证通信效率和数据隐私性.
本文总结了基于FL的其他新兴网络场景中的资源管理方法,如表5所示.FL与MEC、DRL和区块链等方法进行融合,获得了可靠性高、延迟小的车联网信息共享方案.此外,基于FL的F-RAN资源管理方案在能耗低、收敛快等方面取得创新性进展,基于FL的超密集网络资源管理方案在开销低和可靠性高方面表现优异,这些成果均体现了FL的可扩展性与灵活性.同时将FL与区块链等技术进行协作与配合实现更为完备与可靠的资源管理方案,可能成为未来通信网络的重要发展方向.

表5 基于FL的其他新兴网络资源管理方法Table 5 Other emerging network resource management methods based on FL
综上,FL凭借其自适应性和可靠性,实现了分布式无线网络、移动边缘网络、车联网和F-RAN等场景中有效的资源管理,同时也存在着不足,如鲁棒性差,存在过拟合等问题.因此,如何在网络环境中自适应地调整不同资源管理方法的学习结构和网络参数来优化FL的网络架构与训练过程,进而提高算法在复杂度与计算量方面的性能,使其更适于多用户和异构网络场景是解决高维且动态资源管理问题的关键任务,因此,还需进一步研究,从而为上述网络场景提供性能最优的资源管理方案.
3 挑战与展望
下面对基于FL的移动通信资源管理方法存在的挑战以及可行的解决方案进行探讨,并进一步展望FL与移动通信资源管理的未来研究方向.
3.1 挑战
基于FL的资源管理方法虽有其独特优势,但是仍然存在如下问题:
1) 多个性能指标协同优化效率低的问题.当前基于FL移动通信资源管理的研究,只针对能量、带宽、功率和频率等其中一个性能指标进行优化,以分布式无线网络中的迭代算法与AoU算法、移动边缘网络中的自适应同步算法与STC算法、车联网中基于FL和极值理论的资源分配算法和F-RAN中的ALTD算法为例,上述算法只针对能量、带宽、功率和频率等其中一个指标进行优化时效率较高,而当同时兼顾这其中多个性能指标时,很难确定算法的最优解.
针对不同系统性能提出的解决方案可以相互结合,实现多个系统性能协同优化的目标,如多任务学习便运用了该思想.具体来讲,可以在系统的预训练过程中,同时训练多个学习任务.例如,在上述任一网络场景中,同时进行能量、带宽、功率和频率分配的训练学习.在同一个训练过程中,多个任务间共享的模型结构和参数信息是相同的,通过共同训练实现参数信息共享,与分别优化单个性能指标相比,这不仅可以加速模型收敛速度、减少模型训练次数,还可以实现对能量、带宽、功率和频率进行同步管理,有效提升算法性能.
2) 设备的有效连接问题.FL参与的网络场景由大量的设备互联而成,它们需要占用一定的带宽频繁地与中心服务器交互以在网络环境中保持最佳工作状态.由于设备的电源电量有限以及网络连接等不稳定性因素,会使设备从FL系统中脱离,这在一定程度上会减弱FL算法的泛化能力、降低系统训练模型的精度等.以车联网为例,由于车辆高度动态、电源电量有限及网络连接不稳定等因素,车辆可能会从FL系统脱离,导致FL系统处理数据能力下降、增加系统模型训练时间.
因此,在未来研究中可考虑采用AI算法辅助的有源设备采样技术[39]或提高现有基于FL研究算法的鲁棒性,保障部分设备退出时,FL系统仍能维持其原有精度和收敛能力.用AI算法辅助有源设备采样可以通过AI算法使设备与环境不断交互,例如,将电量充足和网络连接状态好的设备选择出来,以供FL系统进行有效训练.
3) 安全与隐私问题.当前多数相关文献的研究假设FL的参与者和服务器是安全和可信任的,然而在实际应用中,由于场景的复杂性和动态性,存在着将训练过程中获得具有用户敏感的模型参数信息暴露给服务器或第三方的可能,而且恶意的参与者可以从共享的参数中推断出其他参与方的敏感信息,这会造成隐私泄露,降低FL系统的安全性.
关于安全与隐私问题可以考虑采用安全聚合算法或合适的检测机制来改善.安全聚合算法一方面在参数聚合前先加密单个设备的参数信息,这有效降低了数据隐私泄露的风险;另一方面还可以防止不明身份的参与者访问服务器.同时,未来研究中需要一种合适的检测机制来检测FL系统中恶意窃取敏感信息的参与者.例如,采用区块链、智能合约和差分隐私相结合的技术,由区块链构建可靠平台提供安全的环境,在智能合约中加入准确度检测算法来识别恶意和不可靠的参与者,以防范投毒攻击[40],而差分隐私技术则用来防止参与者推理攻击[41].
3.2 展望
鉴于此,本文根据FL与移动通信资源管理方法的进展,对未来FL与移动通信资源管理潜在的研究方向进行展望.
1) 边缘智能技术.边缘智能技术与FL架构类似,都是计算资源与服务的下沉和分散化.然而,FL系统需要不断地进行迭代训练以达到给定的模型训练精度,这可能会导致训练时间增加.边缘智能技术通过融合计算和存储,使边缘设备执行智能算法,从而为系统提供智能服务并满足时延率低、能耗量小、精确度高和安全可靠的要求[42].融合AI算法的边缘智能技术可以快速分析和训练网络边缘产生的大量数据.若将边缘智能技术融合至FL,能够做到对数据实时训练和控制,快速完成给定精度下的迭代训练,使整个系统具有较高的泛化能力.因此,将边缘智能技术应用于FL是移动通信资源管理领域极具前景的研究方向.
2) FL与区块链协同.数据隐私性的保证是FL的关键理念之一.区块链是一种分散的、分布式的和公共的数字分类账本,用于在各个节点中保存事务,具有安全性、公开透明性和不可篡改性等优点.FL与区块链具有天然契合的优势,通过FL与区块链的融合,可以提供安全可靠的资源管理方案.例如,设备在本地完成训练后借助区块链中的智能合约执行FL更新步骤,通过共识验证分批次地将参数信息保存在区块链中,保证所有上链的模型参数都有据可查,从而构建高效智慧的移动通信资源管理方案.
3) FL赋能第6代移动通信网络(6th generation mobile networks,6G).随着无线通信技术的迅速发展,6G等未来通信网络技术被相继提出.6G旨在实现空天地海一体化和全球无缝覆盖连接[43],其应用场景的多样性及网络的开放性,使用户的敏感隐私信息从相对封闭安全的平台转移到开放的平台,这可能会造成隐私泄露.因此,需要FL这样的技术对与用户行为相关的数据进行加密处理,FL基于对数据进行分布式存储和训练,仅将模型训练参数上传至中心服务器的特点,可以很大程度上减少隐私泄露的风险.若将FL独特的数据处理方式应用于6G及未来通信网络,一方面可以为6G及未来通信网络提供安全可靠的数据处理方式,另一方面可以加强6G及未来通信网络的安全性和可信度,为基于FL的移动通信资源管理研究的发展带来新机遇.
