基于姿态估计的人体异常行为识别算法
2022-07-11李建更谢海征
李建更,谢海征
(北京工业大学信息学部,北京 100124)
21世纪以来,随着硬件技术以及机器视觉技术的发展,监控行业在我国如雨后春笋般快速崛起,如今在众多的公共场所,例如火车站、商场、校园、银行等人口流动量大的地方,都安装了用于安防监控的摄像头.这样的措施不仅有效地保障了人民的人身财产安全,同时对于维护社会治安、打击违法犯罪做出了突出的贡献.然而,传统的监控行业主要是人为监控判断,实时不间断的监控方式不切实际,会出现异常发现不及时的情况,并且现实情况是监控的数量远远大于相关的配置人员,如果配置相应的工作人员进行监控,是对人力资源的极大浪费.因此,为了减少人力的浪费以及更快地发现异常以便更好地保障群众的生命财产安全,设计开发一套实时监控下的异常行为识别系统是非常必要的,具有广泛的应用前景.
视频序列中的异常行为识别是计算机视觉中最具挑战性和长期存在的问题之一[1-4].在早期普遍使用基于人体几何特征的识别方法[5],文献[6]将人体关节组合成的外观作为特征点进行行为识别.由于提取几何图形特征的方法在很大程度上受人体姿态形状的影响,而在实际中人体姿态形状会随着运动状态产生较大形变,行为识别不能通过简单的几何模型就做出判断,所以就有了提取视频中运动信息特征的方法,重点分析时间维度上的人体运动过程.文献[7]将运动目标垂直和水平方向的光流场信息按照坐标系聚合成多方向的矢量图,再将矢量图归一化后处理为人体运动信息的特征.Bobick等[8]采用动作能量图像和动作历史图像描述视频序列中人体的行为.随着尺度不变特征变换(scale invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、局部二值模式(local binary patterns,LBP)等多尺度特征提取算法,以及使用三维HOG提取视频特征信息的HOG3D算法的提出,文献[9]分别在时间域和空间域中提取行为的特征值,根据特征值计算图像直方图来识别行为.之后,随着支持向量机(support vector machine,SVM)等模式识别算法的提出,利用SVM具有坚实的理论基础、良好的鲁棒性、泛化能力强等优点[10],人体行为识别技术得到了长足的发展.
近年来,随着深度学习在图像分类上的不断进步[11-12],越来越多的研究者采用深度学习网络来解决视频理解方面的问题.文献[13]利用弱监督的方式对视频中的异常行为进行检测.文献[14]使用双流卷积神经网络(convolutional neural networks,CNN)分别捕获空间和时序信息,在RGB基础上堆叠光流帧,RGB提供轮廓信息,光流帧提供时序信息,随后出现了各种基于双流网络的改进[15-16],极大地提高了动作识别的性能.由于双流网络一般需要事先提取光流且耗时,不适宜进行端到端的学习,所以三维CNN应运而生.文献[17]最先提出使用三维卷积提取时空特征进行人体行为识别.文献[18]进一步提出了深度三维卷积(convolution 3 dimension,C3D)网络,C3D的各种改进[19-21]随之出现.
对于视频中的人进行行为识别,通常将视频信息分为时域信息和空域信息,时域信息对行为判断具有重要作用,研究者提出通过追踪骨架关节点的轨迹获取动作的轨迹曲线和行为的动态信息.人体的骨骼和关节轨迹对光照和场景变化具有较强的鲁棒性,易于获得,并且图CNN将图应用到基于骨架的动作识别任务中,利用图卷积的局域性和时间动力学来隐式地学习部位信息,模型容易设计,能够更好地学习动作表示.
当前大部分的异常行为识别算法更偏重于算法的准确性,实时性较差,而一个实用的异常行为检测系统的作用是在监控下一旦发生异常情况,能够及时检测识别该异常的类别[22]并发出信号,确保突发事件的及时发现与处理.监控视频的异常检测就是视频理解,对异常行为进行识别分类.深度学习的出现,给视频理解带来了显著的提升.本文利用深度学习的方法对监控视频中的异常行为进行实时检测.首先,对监控视频进行实时的人体姿态估计以获得人体骨骼关键点坐标序列,利用骨骼关键点序列构建时空图模型.其次,对时空图模型应用多层时空图卷积操作,获得更高级的特征图.然后,利用标准的Softmax分类器对行为类别进行分类,判断异常行为是否发生,若出现异常行为则进行本地和远程客户端的报警提示,客户端可通过相应软件进行监控视频的实时查看.本文所描述系统的主要环节是基于人体骨骼关键点的行为识别算法的研究,采用图卷积网络进行异常行为的训练与判别.
1 异常行为检测算法
1.1 算法概述
异常行为识别系统流程如图1所示.其中,为了获取人体骨骼关键点坐标序列,首先需要进行人体姿态估计.目前,姿态估计面临诸多挑战,例如,人数未知、部分遮挡、人数增加造成效率降低.单人姿态估计较为简单,因为单人情况只要精确地找到关键点位置即可,而多人姿态估计在精确定位关键点位置的基础上,还需要判断出关键点分别属于哪一个目标人物.多人姿态估计算法主要有2种方式:1) 自顶向下.首先,从图像中检测出所有目标人物;然后,利用单人姿态估计方法对所有单目标分别进行姿态估计.该方式的缺点是算法运行效率随着人数增加而降低,并且部分被遮挡的人无法被检测时,导致姿态估计精度降低.2) 自底向上.首先,估计出所有人的骨骼关键点;然后,将关键点进行连接,形成图;最后,通过图优化的方法剔除错误连接,实现多人姿态估计.该方法的优点在于将运行时的复杂性与图像中的人数分离,更有利于实现实时多人姿态估计.最初的自底向上方法没有保留效率的提高,因为最终的多人解析需要全局推理,每张图像需要几分钟.本文中的多人姿态估计基于自底向上的方法,使用Cao等[23]提出的实时多人2D姿态估计算法openpose实时获取身体和足部骨骼关键点,该方法编码图像中肢体的位置和方向,使用部分亲和场将身体部位与图像中的个体相关联,提高了精度,并且同时进行关键点检测与关联,以一小部分计算成本获得高质量的结果,降低了时间复杂度.在进行多人解析时,加入2个贪婪的松弛算法,很好地解决了全局推理高昂的时间成本问题.得到的25个关键点如图2所示.25个关键点与人体关节对应位置如表1所示.

图1 基于监控摄像头的异常行为识别报警系统Fig.1 Abnormal behavior recognition and alarm system based on surveillance camera

表1 25个骨骼关节标注对应关系Table 1 Corresponding relations of 25 bone joints labeling

图2 openpose算法获取的25个关键点Fig.2 25 key points obtained by openpose
本文在提取到25个关键点之后,选择其中的18个关键点并重新定义构图规则,构成新的图模型,如图3所示.图3为一帧图像的骨骼关键点,在获取多帧图像的骨骼关键点数据的基础上,充分利用视频序列的空间信息和时间信息,使用多层时空图卷积网络[24]对异常行为进行识别.18个关键点与人体关节对应位置如表2所示.
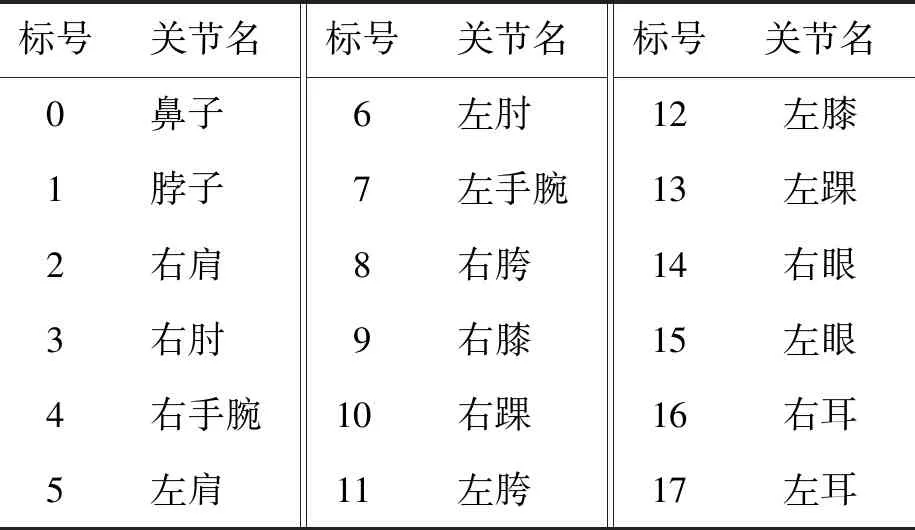
表2 18个骨骼关节标注对应关系Table 2 Corresponding relations of 18 bone joints labeling
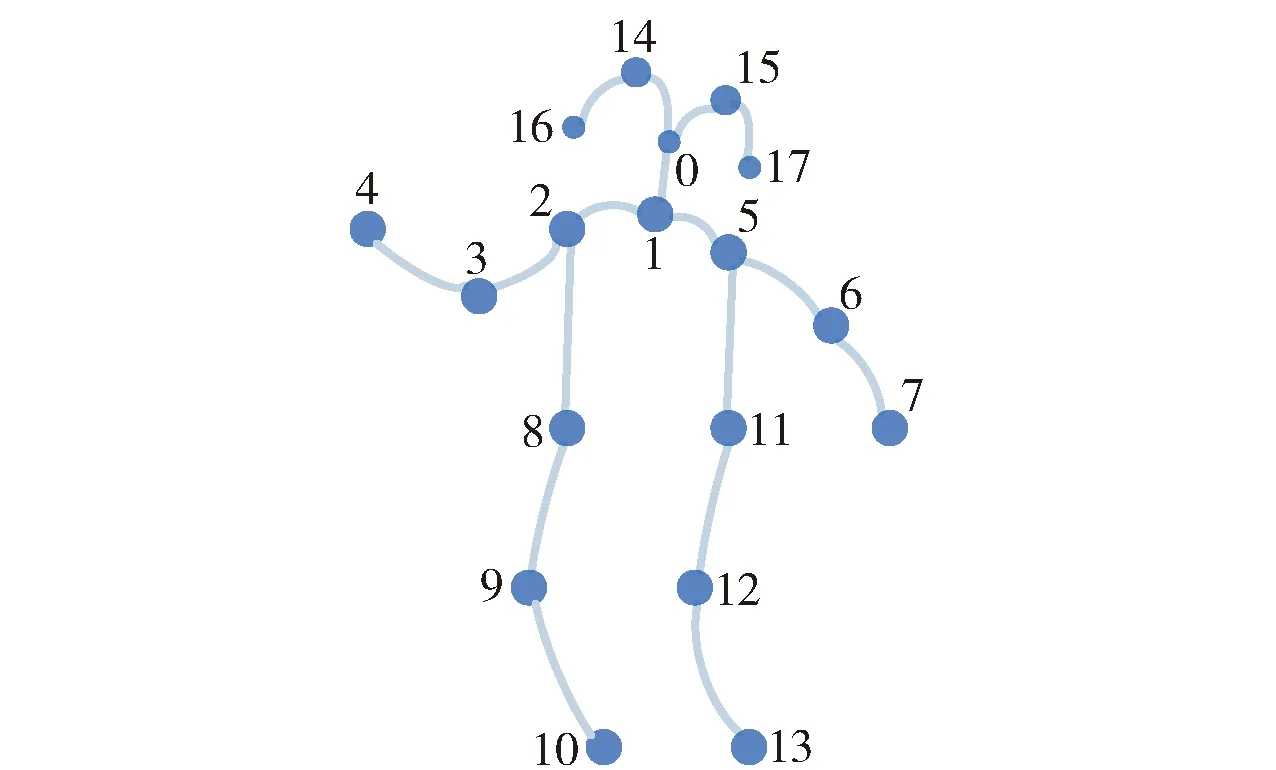
图3 18个关键点结构Fig.3 18 key points structure
异常行为检测算法网络结构如图4所示,可以分为2个阶段.第1个阶段进行特征提取与人体姿态估计,第2个阶段进行行为识别与异常行为判断.

图4 网络结构Fig.4 Network structure
第1阶段,以视频流的形式获取到监控视频,对视频中每一帧进行人体姿态估计.首先使用VGG-19模型提取图像特征,提取的特征经一个六阶段的深度神经网络的迭代,其中前一个阶段的预测结果融合原有图像特征作为下一个阶段的输入,最终得到所有人的25个关键点的坐标.该阶段的网络仅使用了3×3的卷积核,增加非线性变换数量的同时,提升了网络深度,减少了参数数量,对于特征的学习能力更强,在一定程度上提升了神经网络的效果.
第2阶段,应用第1阶段的姿态数据构建图模型,对图模型进行时空图卷积,识别出行为类别,判断是否出现异常.首先,获取第1阶段姿态估计结果中所有人的25个关键点坐标,抽取其中身体的18个关键点坐标作为输入矩阵,对输入矩阵进行归一化操作,归一化可提升模型的训练速度.其次,利用归一化的数据重新定义构图规则,构建骨架图模型,对构建的骨架图模型进行边缘重要性加权,区分不同躯干的重要性.然后,对骨架图进行9个阶段的时空图卷积,卷积操作增加关节维度,降低关键帧维度,分解动作,其中每个阶段包含1个图卷积和3个时间卷积.最后,对卷积操作的结果进行平均池化和全连接,通过Softmax分类器得到相应的动作分类,并根据对异常行为的定义判断是否为异常行为.
1.2 骨架图结构
对于骨架图序列来说,一种行为包含一系列的帧,每一帧都包含一组关节点的坐标,多组坐标构成一个时空骨架图模型.定义一个具有N个关节和T帧的骨架序列时空图G(V,E),其中节点集合为V={vti|t=1,2,…,T;i=1,2,…,N},第t帧第i个关节点的特征向量为F(vti).根据人体结构的自然连通性,可以将一帧内的关节相连,在T帧连续的坐标系中,同一关节连接到一起,2个连接边缘构成边缘集,其一为描述每一帧内骨架连接的ES={vtivtj|(i,j)∈H},其中,H为自然连接的人体关节集,另一个EF={vtivt+1,i}为连续帧间相同关节的连接.构成的骨架图模型如图5所示.

图5 骨架图模型Fig.5 Skeleton graph model
1.3 图卷积网络结构
在单帧图卷积网络模型Vt中,t时刻,有N个关键点,帧内连接的集合为Es={vtivtj|(i,j)∈H}.类比图像的卷积操作,将图像看作二维网络,设置步长为1,给定卷积核大小为K×K,输入图像为fin,c个通道,那么在空间位置为x的单通道的图像卷积输出值为
(1)
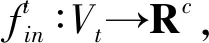
p(vti,vtj)=vtj
(2)
相较于采样函数,权重函数较为复杂.因为在二维的卷积中,中心位置周围会存在一个刚性网格,所以邻域像素的空间顺序是固定的,权重函数可以通过根据空间顺序建立的(c,K,K)维张量来实现,而对于刚刚构建的一般图,没有这样的隐式排列.为了解决这一问题,遵循Niepert等[25]提出的由根节点周围的邻域在图标记过程定义空间顺序的思路来构建权重函数.没有给每一个邻域节点一个独特的标签,而是通过将一个骨骼点vti的邻居集B(vti)划分成固定数量的K个子集来简化过程,每个子集都有一个数字标签.因此,可以有一个映射lti∶B(vti)→{0,1,…,K-1}将邻域的一个节点映射到它的子集标签,权重函数为
w(vti,vtj)=w′(lti(vtj))
(3)
使用改进的采样函数和权重函数,可以将式(1)重写为
(4)
式中Zti(vtj)=|{vtk|lti(vtk)=lti(vtj)}|为正则化项,等价于相应子集的基数,平衡了不同子集对输出的贡献.将式(2)(3)代入式(4)可得空间图卷积公式为
(5)
利用时间卷积学习时间序列中关节变化的局部特征.由于形状固定,可以使用传统的卷积层完成时间卷积操作.类比图像卷积操作,时间图卷积特征图的最后3个维度形状为(C,T,V),与图像特征图的形状(C,W,H)相对应.图像的通道数C对应关节的特征数C,图像的宽W对应关键帧数T,图像的高H对应关节数V.在图像卷积中,卷积核的大小为w×1,则每次完成w行、1列像素的卷积,步长为s像素,完成一行后进行下一行像素的卷积.在时间卷积中,卷积核的大小为temporal_kernel_size×1,则每次完成1个节点、temporal_kernel_size个关键帧的卷积.步长为1,则每次移动1帧,完成1个节点后进行下一个节点的卷积.时间卷积如图6所示.
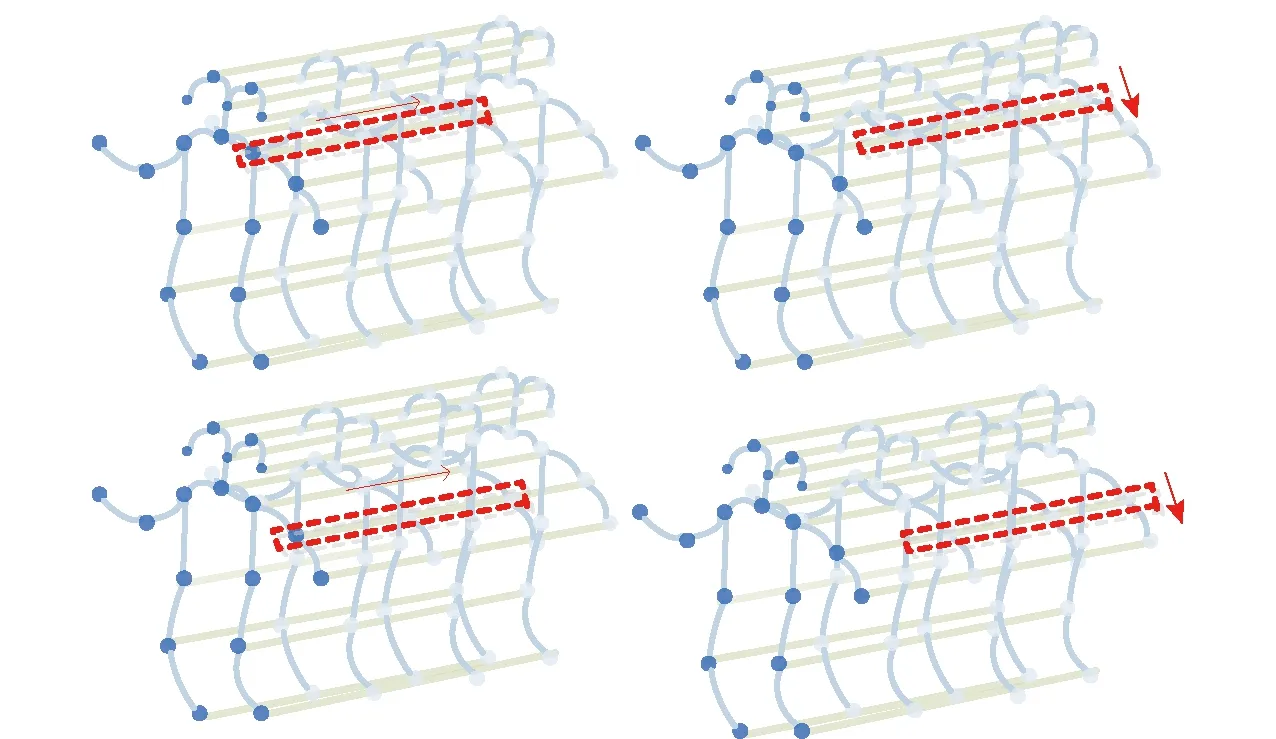
图6 时间卷积Fig.6 Temporal convolution
在式(5)构建的空间图卷积网络的基础上,进行时空图卷积网络建模.因为使用同一关键点的连续帧构建骨骼图的时间序列,故可以在空间图卷积网络的基础上加入时间卷积构建时空图卷积网络,将空间邻域扩展到时间邻域,邻域定义为
B(vti)={vqj|d(vtj,vti)≤K,|q-t|≤⎣Γ/2」}
(6)
式中取K=1,参数Γ称为时间内核大小,控制包含在邻域图中的时间范围.时空图卷积网络的采样函数与空间图卷积网络一致,对于权重函数,由于时间是有序的,更新映射为
lst(vqj)=lti(vtj)+(q-t+⎣Γ/2」)×K
(7)
综上,完整的时空图卷积网络为
(8)
1.4 划分子集的方式
因为单个骨架图可以扩展到时空域,下面以单个骨架图来描述划分策略.由于人体骨架在空间上的局域性,在划分过程中利用这种特定的空间配置,将邻域划分成3个子集,划分结果如图7所示.

图7 子图划分方法Fig.7 Subgraph division method
对于1个根节点,与它相连的边可以分为3个部分:第1部分是空间位置比根节点更远离骨架重心的邻居节点(黄色),包含了离心运动的特征;第2部分是更为靠近重心的邻居节点(蓝色),包含了向心运动的特征;第3部分是根节点本身(绿色),包含了静止的特征.
在简单的图卷积中,卷积公式可描述为

(9)
式中:D为图的度矩阵;N=1,2,…,n代表所有节点的编号;X代表所有节点的特征;Xi代表节点i的特征;Xj代表节点j的特征;A代表临界矩阵;Aij代表节点i和节点j之间的边的权值.
式(9)以边为权重对节点特征求加权平均.其中=D-1A可以理解为卷积核.考虑到动作识别的特点,使用上述图划分策略,将分解为1、2、3,如图8(a)所示,2个节点之间有一条双向边,节点自身有一个自环.使用这样的分解方法将1个图分解成了3个子图,如图8(b)(c)(d)所示,卷积核也从1个变为了3个.要得到卷积的结果,只需使用每个卷积核分别进行卷积,再进行加权平均.

图8 子图划分结果Fig.8 Results of subgraph division
1.5 边缘重要性加权
在运动过程中,不同的部位重要性是不同的.例如腿的动作可能比脖子更重要,通过腿部的运动可以判断出跑步、走路和跳跃,但是脖子的动作中可能并不包含多少有效信息.在大规模图中由于节点较多,复杂的背景噪声会对图卷积性能产生不良影响.边缘重要性加权巧妙地利用图节点之间的相互联系,区分联系的层级,能够增强任务中需要的有效信息.表现在数学上就是某些属性拥有更高的权重,是一种加权平均.图卷积的核心思想是利用边的信息对节点进行聚合,从而生成新的节点表示.具体来说,给定一个图G(V,E),其中,V={1,2,…,n}为节点集合,E={a(1,2),a(1,3),…}是边的集合,节点的特征用X={x1,x2,…,xn}表示.因此,可以使用图卷积公式生成新的节点的特征表示X′,其中x′i是节点i的邻居节点特征的加权平均.在图卷积中,权重直接用边上的权重替代,公式为
(10)
式中:a(i,j)代表图G的邻接矩阵中第i行第j列的值,即(i,j)边的权重;j∈neigh(i)表示j节点属于i节点的邻域.
2 实验结果和分析
2.1 实验数据库和算法评价方法
本实验将Kinetics视频数据集的子集作为异常行为识别数据集,包括正常行为(normal)和掰手腕(arm wrestling)、劈砍(chopping)、暴跌(tumbling)、击打(hitting)、刺(lung)、挥拳(pumping fist)6类异常行为.每类行为由2组视频构成,每类行为包括550~600段视频,共包括4 096段视频.Kinetics数据集由Google的deepmind团队开源提供[26],是一个大规模、高质量的数据集,大约65万个视频片段,其中包括700个人体动作类,包括人与物之间的交互(如演奏乐器),以及人与人之间的交互(如握手和拥抱).每个动作类至少有600个视频剪辑,每个剪辑持续约10 s.用openpose批量处理每段视频,获取25个关键点并从中提取18个关键点进行保存,文件保存为键值对(JavaScript object notation,JSON)格式,用来进行异常行为识别网络的训练和测试.数据集的划分如表3所示.

表3 数据集划分Table 3 Dataset partition
本文对测试集的每一个JSON文件进行测试,测试结果为多分类,取Top-1准确率为评判标准.Top-1准确率和Top-5准确率是深度学习过程中较为常用的2个评判标准.其中Top-1准确率=所有测试视频中分类正确的个数/总的测试视频的数量,Top-5准确率=所有测试视频中正确标签包含在前5个分类概率中的个数/总的测试视频的数量,通常状况下,选择Top-1准确率为评判结果的标准.
2.2 算法训练与结果分析
本文训练使用的硬件设备均为Intel(R) Core(TM) i7-4770K CPU @ 3.5 GHz,8 GB内存(RAM),显卡型号为GeForce GTX 1080.操作系统为Ubuntu 16.04 LTS,CUDA版本为10.0,使用的深度学习框架为pytorch.
训练参数设置为:学习率(base_lr)为0.1,迭代次数(num_epoch)为100,在迭代次数40、60、80、100时学习率下降0.1,优化器(optimizer)使用梯度下降算法(stochastic gradient descent,SGD),批次大小(batch_size)为32.
测试集共有347个JSON文件,整体测试结果为:Top-1准确率80.47%、Top-5准确率97.98%.分类测试结果如表4所示.
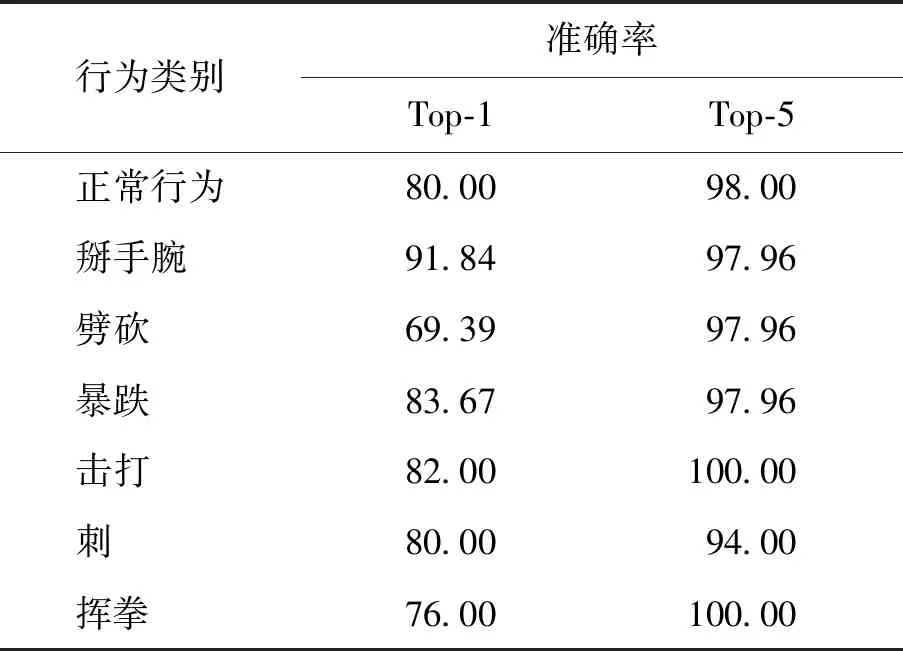
表4 分类测试结果Table 4 Results of classification test %
本文选取整个测试集的Top-1的准确率为最终的准确率,即为评判结果的标准.由以上实验结果可知,本文的方法对于异常行为的识别实现了80.47%的检测精度.
为了验证本文算法的有效性,本文在KTH数据集[27]和HMDB51数据集[28]上分别进行了测试,并与其他有代表性的算法进行对比.对比实验所使用的硬件设备仍为Intel(R) Core(TM) i7-4770K CPU @ 3.5 GHz,8 GB内存(RAM),显卡型号为GeForce GTX 1080.
KTH数据集是计算机视觉领域的一个里程碑,该数据集包括4个不同场景(户外S1、户外远近尺度变化S2、户外不同衣着S3、室内S4)下25个人完成的6类动作(拳击(boxing)、拍手(handclapping)、挥手(handwaving)、散步(walking)、慢跑(jogging)、奔跑(running)),选取拳击为异常行为,其余5类动作为正常行为,共600个视频,视频中每一帧都是一张160×120像素的图像,图像背景均匀且均为单人运动,部分图像如图9所示.

图9 KTH数据集子集Fig.9 KTH data set subset
本文随机抽取19名实验对象的视频作为训练数据集,剩余6名人员的视频作为验证集,总体识别率为97.99%.本文的算法与其他文献中的算法在KTH数据集上进行比较,结果如表5、6所示.

表5 识别率对比Table 5 Comparison of recognition rate %
文献[29]在基于光流特征和密集加速鲁棒特征(speeded-up robust features,SURF) 算法检测运动的人的基础上,融合运动、轨迹和视觉描述,利用词袋法提取特征,提出基于兴趣点轨迹的人体动作检测与识别.文献[30]提出一种强调与每个动作相关联的关键姿态的表示方法,从RGB视频流中获得运动特征作为深度神经网络的输入来进行行为识别.在大规模数据集上学习到的基于CNN的表示可以迁移到数据集有限的动作识别任务中.文献[31]则是在预训练的深度CNN模型上进行特征提取和表示,然后使用混合SVM和K近邻(K-nearest neighbors,KNN)分类器进行动作识别.文献[32]提出全局上下文感知注意力长短期记忆网络,用于基于骨骼关键点的动作识别.使用全局上下文记忆单元选择性地关注每一帧中的关节,同时引入循环注意力机制,提高网络性能.文献[33]提出一种在使用YOLO(You only look once)进行目标检测与定位的基础上融合长短期记忆网络(long short-term memory,LSTM)和CNN的行为识别方法.文献[29]为传统识别方法,文献[30-33]是深度学习领域进行单人行为识别具有代表性的方法.

表6 各动作识别率对比Table 6 Comparison of recognition rate of each action %
HMDB51数据集来源于美国布朗大学.数据集包含6 849个视频剪辑,51类动作,每个动作至少有101个剪辑,来源方式多样,其中大部分来自于电影,还有一小部分来自于公共数据库,例如YouTube和Google视频.操作类别可以分为5种类型:一般面部动作、通过物体操纵进行面部识别、全身动作、与物体互动的身体动作、与人体互动的身体动作.因为本文需要提取人体的骨骼关键点,进而判别是否存在异常行为,所以面部动作就没有实际的意义,最终本文选择其中的28种行为进行识别,按照7∶3的比例将每种动作分为训练集和测试集.HMDB51数据集与KTH数据集的区别主要体现在KTH数据集采集场景简单且为单人动作,无交互行为.HMDB51数据集场景复杂多样且包含单人行为、多人交互行为,故选取的对比方法与仅有单人行为的KTH数据集对比方法不同,选取的方法在交互行为识别方面表现更为突出.将本文的方法与近年来经典的方法进行识别率比较,结果如表7所示.

表7 本文方法与近几年经典识别方法对比Table 7 Comparison between the method in this paper and the classic recognition methods in recent years %
文献[16]将残差网络(residual network,ResNet)作为双流网络的基础网络架构,同时从光流分支到图像分支有信息传递,提出基于时空特征相互作用的通用卷积网络体系结构来进行端到端的行为识别.文献[34]提出时空金字塔网络来融合金字塔结构中的时空特征,使得时间特征与空间特征相互增强,相互融合,进行行为识别.文献[35]提出一种网络架构,通过堆叠多个通用构建块来构建外观与关系网络(appearance and relation networks,ARTNet)进行行为识别,其中通用构建块能同时对外观和关系进行建模.文献[36]提出一种通用且有效的时间转移模块(temporal shift module,TSM),将部分信道沿时间维度进行移位,便于相邻帧之间的信息交换,可以达到3D CNN的性能,但保持2D CNN复杂度.
作为文献[24]的改进算法,本文提出提取身体加足部25个关键点并抽取18个关键点作为行为识别阶段时空图网络的输入,相较于文献[24]只提取身体的18个关键点作为时空图网络的输入,在处理速度方面的对比实验数据如表8所示,表中视频来自于HMDB51数据集与KTH数据集.由表中数据可知本文的识别速度相较于文献[24]提升了1倍.
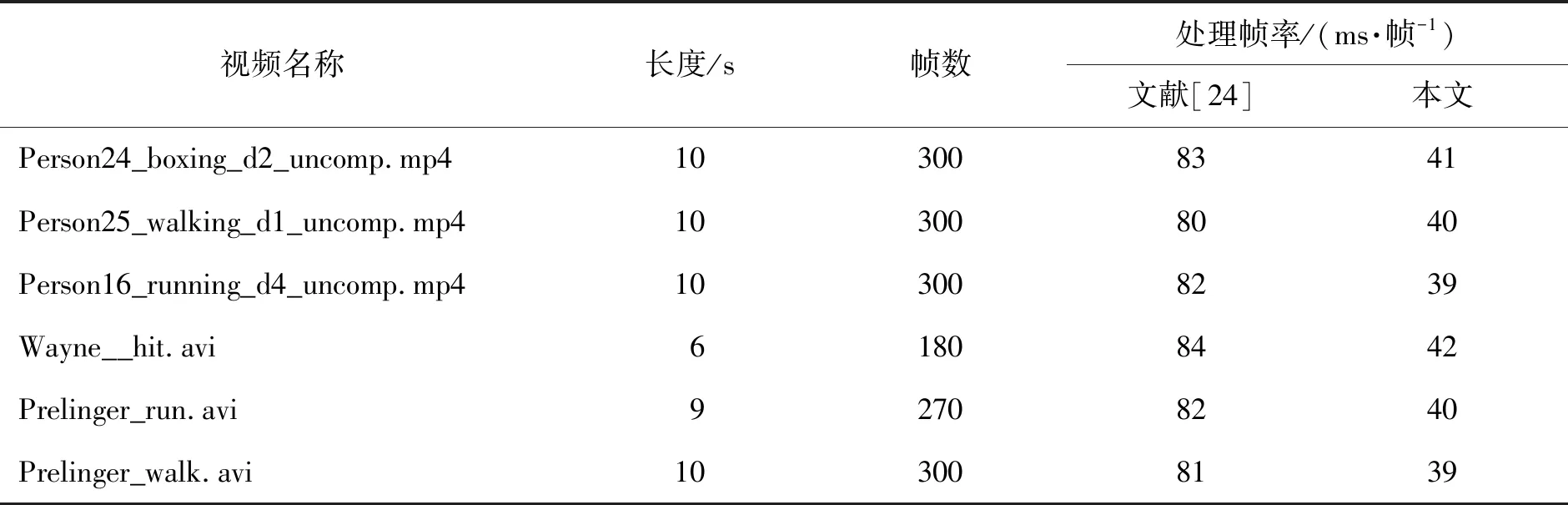
表8 每帧消耗时间对比Table 8 Comparison of consumption time per frame
受限于实时监控的权限获取困难,同时由于实时监控下的异常行为发生的不确定性,为了验证算法的实时性效果,采取2种方式模拟真实的视频监控下异常行为的发生.其一为从网络渠道获取有异常行为发生的视频,对其采用视频推流的形式,模拟真实的实时监控.现阶段的监控摄像头基本上都是遵循实时流传输协议(real time streaming protocol,RTSP)或实时消息传输协议(real time messaging protocol,RTMP)输出,本文采用RTSP视频流的形式模拟真实监控场景.实时处理的结果如图10所示,分别对5段视频进行以上处理,处理结果如表9所示,分别统计消耗时间以及每帧消耗时间,可得每帧的平均处理时间为41.26 ms,转换为处理帧率为24帧/s.其二为采用摄像头实时监测固定场景下的人为指导的异常行为的发生,实时处理结果如图11所示,处理帧率为25帧/s.当前国内处于领先地位的监控设备厂家海康威视监控设备的输出帧率在20~30帧/s且可用监控设备匹配软件进行设置.本文算法的处理速率处于设备可用区间,故满足实时处理监控视频的要求.2种场景下均能在异常行为发生的4 s内检测出异常行为并进行警报预警,证明了本文算法在真实场景下的及时性与有效性.

图10 推流模拟实时识别结果Fig.10 Real-time recognition result of push streaming simulation

表9 处理推流视频消耗时间Table 9 Processing time for push streaming video

图11 摄像头实时监测识别结果Fig.11 Recognition results of camera real-time monitoring
现阶段,开源的人体异常行为数据库种类繁多,来源广泛,但因缺乏统一的标准,没有形成体系,在一定程度上限制了异常行为识别研究的发展.因此,标准人体行为数据库的建立是整个研究环境的重中之重.
3 结论
1) 针对现有的人力监控系统,本文提出了基于姿态估计的实时异常行为识别算法.实时检测提取人的骨骼关键点,然后利用关键点坐标的空间和时间信息构建时空图并进行时空图卷积,最终判断异常行为是否发生.
2) 通过在单人数据集KTH和多人数据集HMDB51中实验验证,分别与相对应算法比较,准确率有所提升,表明了本文算法的有效性.
3) 对实时视频进行测试,帧率可达到25帧/s,满足实时处理监控视频的要求.
4) 本文算法改善了传统监控系统需要24 h执勤的情况,提升了异常行为识别的效率,提高了安全系数.
