基于高相关区域上最小角回归的华南初夏暴雨日数预测
2022-07-01闫文杰刘圣军刘新儒彭谦胡娅敏
闫文杰 刘圣军 刘新儒 彭谦 胡娅敏
(1. 中南大学数学与统计学院,长沙,410075;2. 中国人民大学统计学院,北京,100872;3. 广东省气候中心,广州,510080)
1 引言
华南地区地处中国南部,属热带、亚热带季风气候区,具有非常显著的季风气候特征,形成暴雨的天然条件位居我国前列[1],故暴雨发生较为频繁,其中初夏为暴雨频数最多的时段之一. 研究华南地区暴雨日数的时空分布特征,并选取合适模型进行暴雨日数的预测,在极端天气时间预测方面具有重要的应用价值.
对于暴雨日数预测问题,前人已进行过许多相关研究. 在因子选取方面,简茂球等[2]在2013 年利用相关系数法指出海南持续性暴雨天气与热带大气的准双周振荡有关,并将海温纳入分析范畴,发现2010 年在赤道中东太平洋发生的La Niña 现象有利于产生大气准双周低频振荡. 在抽样方法方面,为解决暴雨预测中类别不平衡问题,杨艳等[3]将减抽样的思想应用于AdaBoost 综合学习算法[4]中. 实验结果表明,相对于传统的AdaBoost 算法[5],该算法对铜川暴雨日数的预报准确率显著提高. 在预测方法方面,刘绿柳等[6]应用一步法和两步法两种统计降尺度方法预测暴雨日数,并提出了用标准差作为评估暴雨日数异常等级的评分标准.文中交叉检验的结果显示这两种方法对于月尺度降水与暴雨日数的预测都具有较好的效果.
除了以上传统的方法, 近年来人工神经网络在气象领域也得到了广泛应用. 葛彩莲等[7]在2010 年应用BP 神经网络对降雨量进行预测, 发现使用前5 年降雨量来预测后1 年的降雨量的效果与用气象资料预测降雨量的效果相近,让这种新预测模式应用于降水预测成为可能. 黎玥君等[8]在2017 年基于BP 神经网络预测浙北夏季降水,发现神经网络隐藏层节点数量为2 时,拟合降水量的效果最佳. 关鹏洲等[9]在2017 年提出了基于梯度提升决策树(GBDT)特征选择的改进AdaBoost 回归模型、基于多个强回归器组合的stacking 回归模型,和Inception 卷积神经网络对数据集进行分类和回归,获得了对短期降雨较好的预测效果.
前人的研究成果从数据处理到模型构建,都为本文提供了宝贵的思路,但也存在亟待改善的地方. 大多数研究工作采用EOF 分解、独立分量分析等传统机器学习方法提取特征,选用常用的平均绝对误差、相对偏差[8]、Ts 评分[3]等指标进行模型检验.然而,传统方法算法简单,更适合于线性关系建模,且常用检验指标不能全面有效地对结果进行评估.为改善上述问题,本文引入新的特征提取方法与检验方法.
2 研究方法
2.1 数据
降水数据来源于中国气象局国家气象信息中心和广东省气候中心数据库. 本文选用1981 年至2018 年华南地区192 个站点的数据. 选取的5 个环流要素场来自于NCEP/NCAR 再分析资料的月数据,分别为: 高度场(hgt),经向风场(vwnd),纬向风场(uwnd),比湿(shum),海平面气压(slp),其中水平分辨率为2.5°×2.5°;海温数据选用NOAA ERSST V3b 海表温度(SST),水平分辨率为2.0°×2.0°;海冰数据来自NOAA 北半球逐月海冰资料;积雪逐月数据由Rutgers University Global Snow Lab 提供(包括北美洲、北半球、欧亚大陆积雪数据). 数据如表1所示.
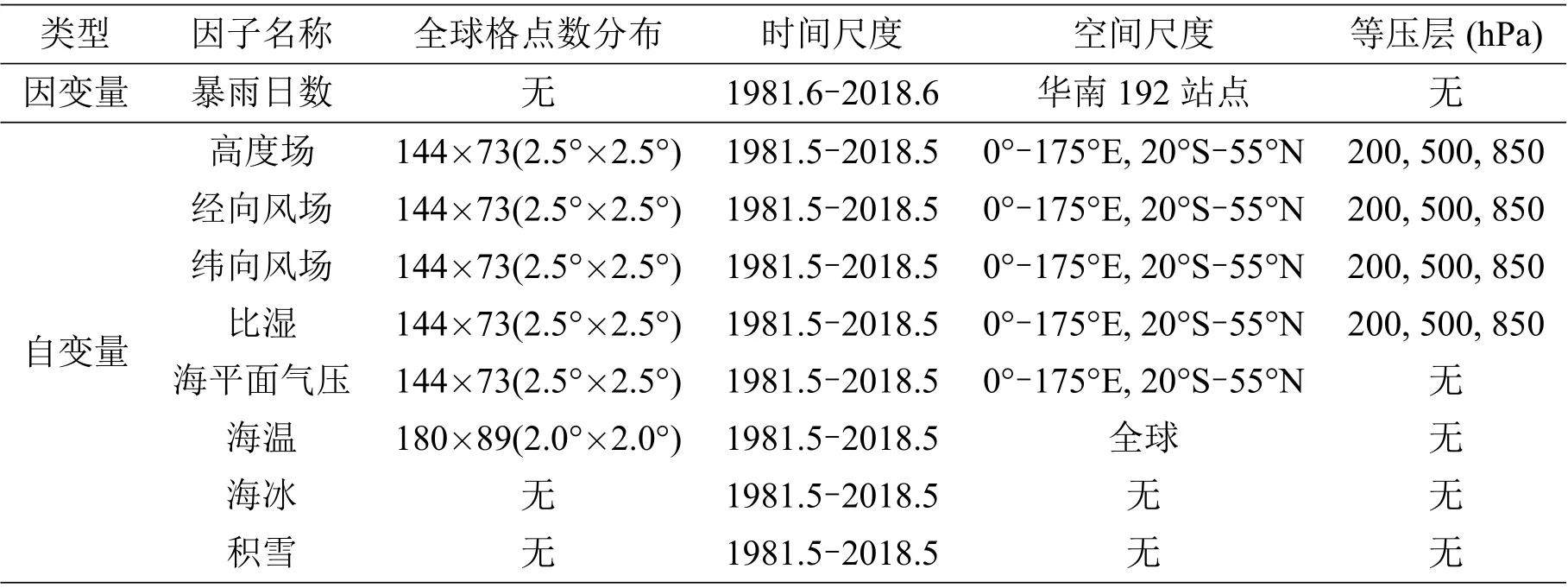
表1 详细数据表格
根据广东省气候中心暴雨阈值标准,24 小时单站降水量超过50mm 的日数定义为暴雨日数.本文主要研究提前一个月的要素场对华南地区初夏暴雨日数的影响,因此选取当年5 月的要素作为预报因子来预测华南地区初夏暴雨日数.
对于部分预测因子,由于缺测或无法测量(如海温数据只能在海洋区域测出,陆地区域无法测量)等原因,会在某些格点或时间点出现异常数据. 本文对异常值直接剔除. 为了消除预报因子之间的量纲影响,本文采用z score 方法对数据进行标准化处理:

其中,zij为对每个格点(第i行,第j列)数据求标准化后的值,xij为初始值, ¯xi为第i行数据的平均值,si为第i行数据的标准差.
2.2 统计降尺度方法框架
统计降尺度法是利用大气环流的观测资料建立大尺度气候要素和区域气候要素之间的统计关系,并把这种关系应用于大气环流模式中输出大尺度气候信息,进而预测区域未来气候变化的一种常用方法[10]. 其基本思路是建立大尺度预报因子和区域气候预报量之间的统计关系函数[11]:

其中,y是区域气候预报量(气温,降水等),x是大尺度预报因子,F(·)为建立的统计关系函数,使用最广泛的是转换函数. 统计降尺度基本流程如图1所示: 在暴雨日数预报问题中,由于选取的预报因子较多,且环流预报因子为二维格点数据,样本数量有限,传统机器学习模型会存在严重的过拟合现象. 缓解过拟合的方法主要有两种[12]:
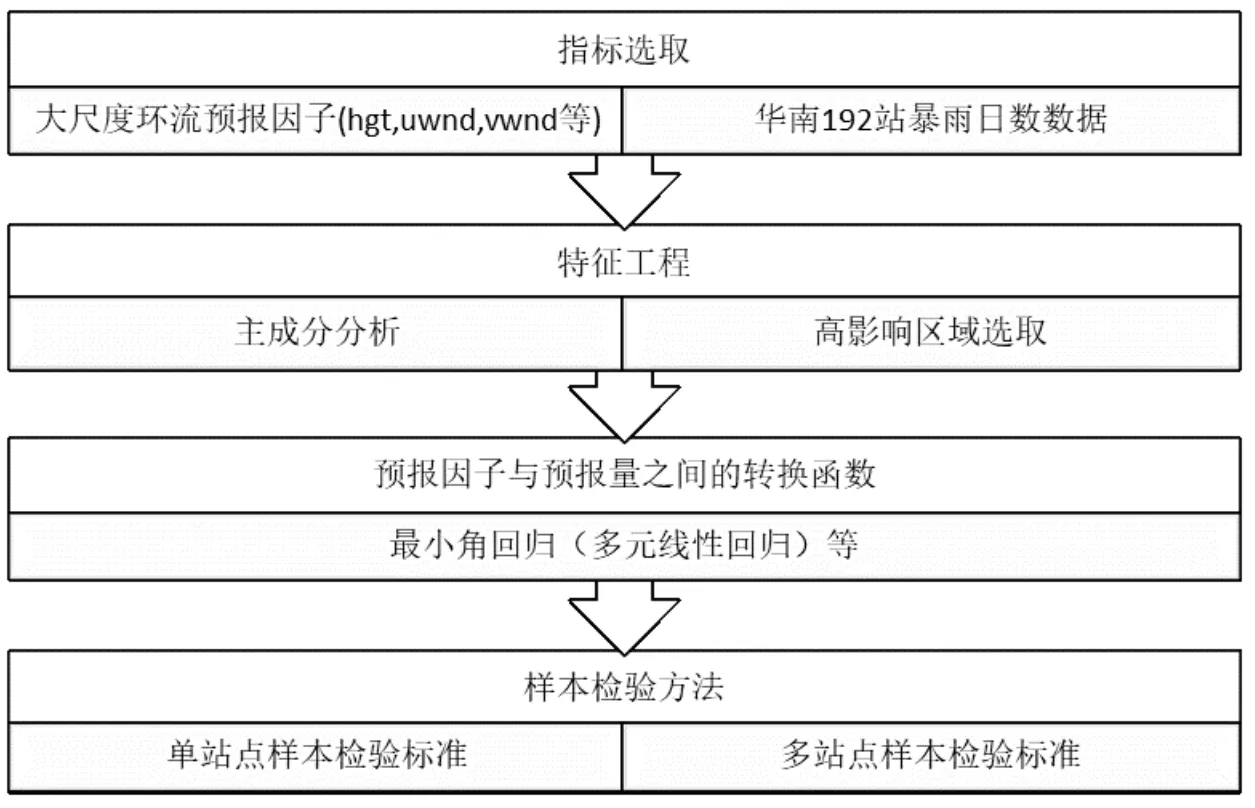
图1 统计降尺度方法框架图
(1)降低预报因子维度. 可通过筛选显著相关因子和选取高相关区域格点数据并取区域平均值的方法来减少维度.
(2)将模型正则化,减少特征参数的数量级.
本文采用高相关区域选取的方法来提取特征,使用最小角回归的方法获取预报因子与预报量之间的转换函数. 接下来分别详细讨论这两个方法.
2.3 高相关区域提取方法
再分析资料数据是包含时间和空间信息的多维格点数据. 预测过程中我们只关注与华南初夏暴雨有相关性的格点数据,因此通常会将某个时间点的空间数据重组成一维数据. 例如,由于本文中环流场的经纬度范围分别为0°–175°E,20°S–55°N,分辨率为2.5×2.5,某一时间点的200hPa 高度场数据经度方向71 个数据,纬度方向31 个数据,进行一维重组后,成为维度为2201 的一维向量.但由于相邻格点数据相关性很高,必然导致模型产生严重的多重共线性及过拟合现象. 因此,我们需要对数据进行预处理. 提取高相关区域是一种有效的数据降维方法. 本文使用预报因子各格点与单站点时间序列数据的线性相关系数来提取预报因子的高相关区域,其选取操作流程如图2所示.

图2 高相关区域选择操作流程
以高度场数据与广东佛冈站点的初夏暴雨日数的相关性分析为例,我们选择时间范围为1981年5 月至2018 年5 月,空间范围为0°–175°E,20°S–55°N 的500hPa 高度场格点数据与广东佛冈站点初夏暴雨日数进行相关性分析,得到空间相关情况如图3所示. 设定显著性水平为0.05,可得高相关区域数为6,即有6 个区域的格点数据与因变量的相关系数较大. 由此可得,自变量的维数由原来的2201 维变成6 维.

图3 500hPa 高度场与暴雨日数相关情况(以佛冈站点为例)
2.4 最小角回归预测模型
在常用逐步回归方法中,参数选择可采用前向选择算法和前向梯度算法. 然而,这两种算法比较暴力,效率较低. Bradly Efron 在2004 年发表的文章中提出了一种新的算法——最小角回归(LAR)算法[13]. 该算法保留了前向梯度算法的精确性,同时简化了迭代的过程,步骤如下[13,14]:
Step 1: 设有n个经过了标准化的自变量xk(k= 1,2,··· ,n),中心化的因变量y. 计算所有自变量与y的相关系数并排序,选出相关系数最大的一个自变量,不妨设为x1,满足

其中r(x,y)表示x与y之间的相关系数. 此时将x1加入逼近y的特征集合中.
Step 2: 在x1方向上用x1逼近y,选择步长θ1,得到下列回归方程

其中θ1表示回归系数, ¯y表示y在x1方向上的斜向投影,且

定义残差

选取θ1使得存在一个未被选取的自变量,不妨设为x2,满足

此时,残差yres位于x1和x2的角平分线上. 将x2加入逼近y的特征集合中.
Step 3: 在Step 2 得到的角平分线方向上前进步长θ2,按上述方法更新残差yres,使得存在另一个未被选取的自变量,不妨设为x3,满足

Step 4: 循环上述步骤, 直到残差‖yres‖2小于给定的值; 或者已经遍历了所有自变量xk(k=1,2,··· ,n),算法停止.
从几何角度分析,每一步选择的前进路径必须保证已选入模型的变量xk与残差yres的角度最小(即“最小角”). 因此算法每一次都选择原路径与新变量夹角的角平分线方向作为新的前进路径方向.
最小角回归算法是一个适用于高维数据的回归算法. 该算法的最坏时间复杂度和最小二乘法类似,但计算速度却能与前向选择算法一样快. 同时,该方法可以产生分段线性结果的完整路径,在模型的交叉验证中极为方便.
2.5 评价检验
2.5.1 单站点预测结果检验评估指标
气象学中有许多检验评估指标,包括时间距平相关系数(TCC)、空间距平相关系数(ACC)、相对操作特征(ROC)等. 其中TCC原理简单,运用广泛,且适用于本文研究问题的单站点输出结果分析,因此可以作为主要的检验指标. 符号一致率,也称同号率(SS),能够把握距平值的变化趋势(升高或者降低). 训练集决定系数()可以检验模型训练集的拟合情况.测试集决定系数()与训练集决定系数原理类似,可以检验测试集的拟合情况,同时验证TCC指标的合理性,但标准较为严苛.

时间距平相关系数的公式为其中,n1为模型测试集的样本数量,TESTi为测试集中第i个测试数据,OBSi为与测试数据对应的第i个真实数据,为测试集数据的平均值,为与测试集对应的真实数据的平均值.TCC取值范围是[−1,1],越接近1,说明预测效果越好.
同号率公式为
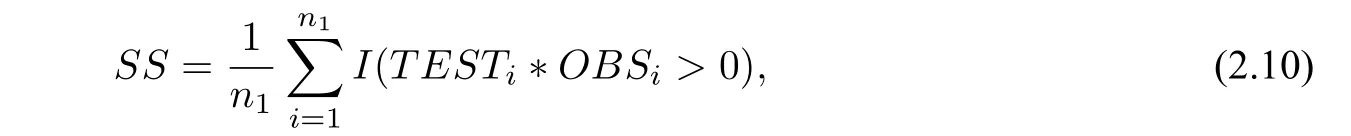
其中,I(·)表示示性函数.
测试集决定系数为

训练集决定系数为

其中,n2为模型训练集的样本数量,TRAINj为训练集中第j个测试数据.
2.5.2 区域预测结果检验评估指标
趋势异常综合评分(Ps)是国内气象领域常用的评价标准,它综合考虑了同号率、拟合能力以及异常值(偏离平均值较多的观测值)预报能力. 本文在保留Ps评分部分标准的同时,针对华南地区暴雨日数预测问题,对评分标准进行调整,将不连续的分段常数函数调整为连续函数,得到调整Ps评分(APs).Ps评分标准基于距平百分率进行操作,APs 评分沿用这种模式. 本小节涉及的变量均为对应数据的距平百分率.
设共有m个站点, 每个站点都有n个测试样本, 即n年的月平均暴雨日数数据. 当OBS(i,k)*TEST(i,k)< 0, 即第i年第k个站点的观测值与对应预测值符号相反时, 定义第i年,第k个站点的得分为零

当OBS(i,k)*TEST(i,k)≥0,即第i年第k个站点的观测值与对应预测值符号相同时(包含其中某项为0 的情况),定义第i年,第k个站点的得分公式为
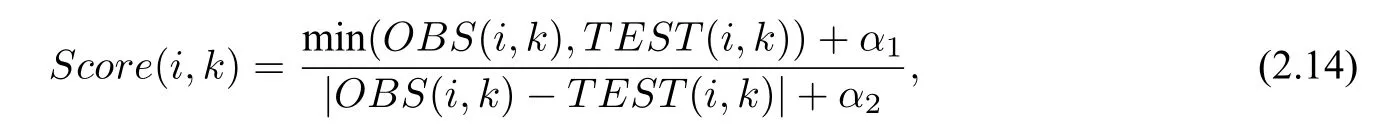
其中,α1,α2为经验参数,用于避免出现分子或分母为0 的情况(本文通过多次实验比较,将α1与α2均设为0.05). 上式分子部分用于对异常值的预报能力,分母部分衡量模型对观测值的拟合程度.
与Ps评分准则类似,构造第i年所有站点的综合APs评分
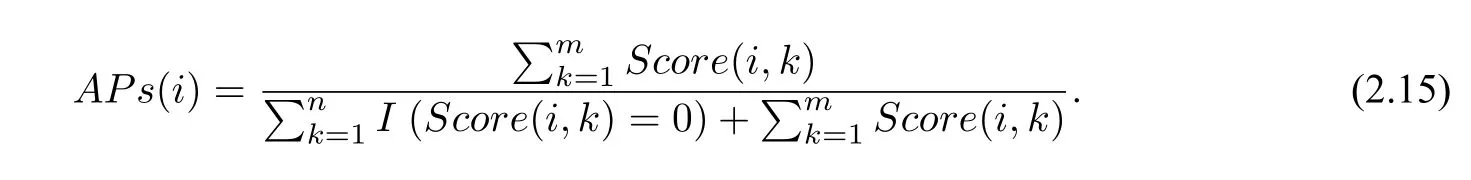
3 实验结果
在模型训练过程中,本文将数据按7:3 的比例分为训练集和测试集. 时间距平相关系数,同号率和测试集决定系数用于评估测试集上的预测效果,训练集决定系数是训练集上的检验标准. 本小节涉及到的变量均为距平值.
3.1 单站点预测结果比较
本文分别基于主成分分析法和高相关区域选取法对数据降维和提取特征,并使用最小角回归算法对站点暴雨日数进行预测.
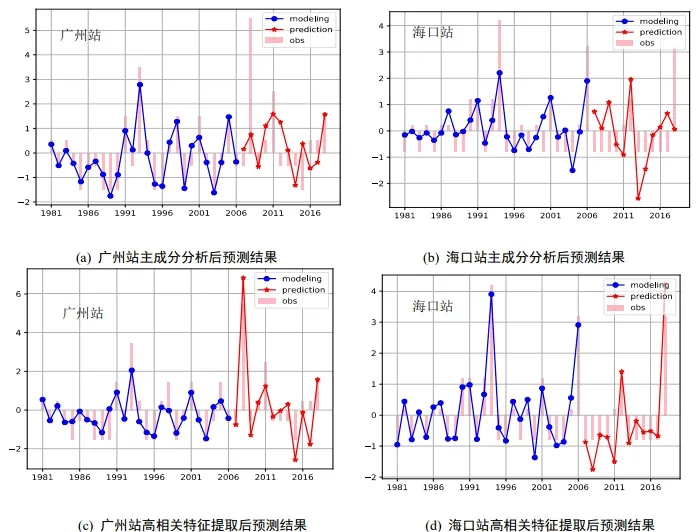
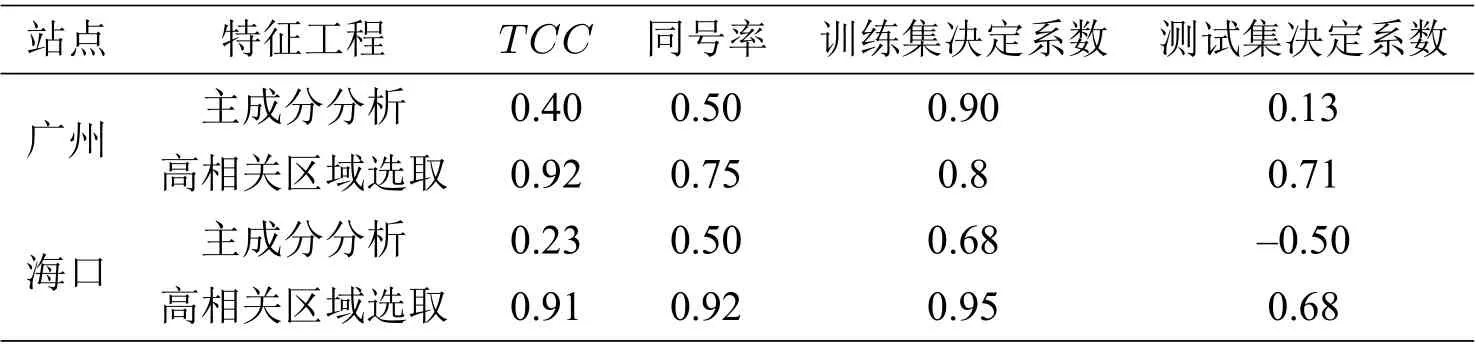
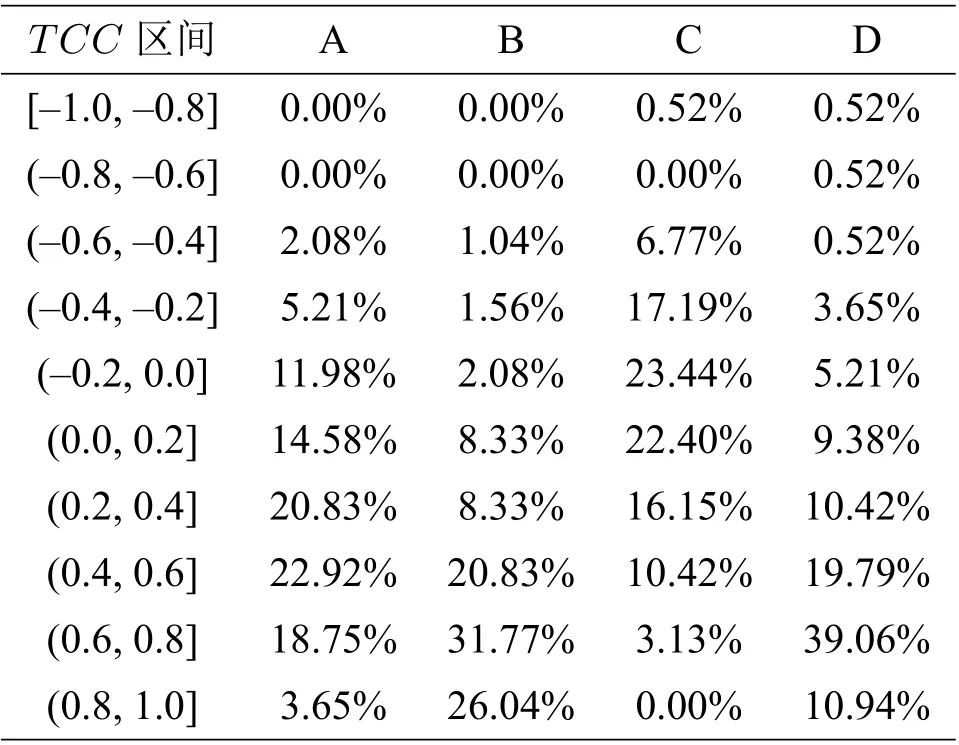
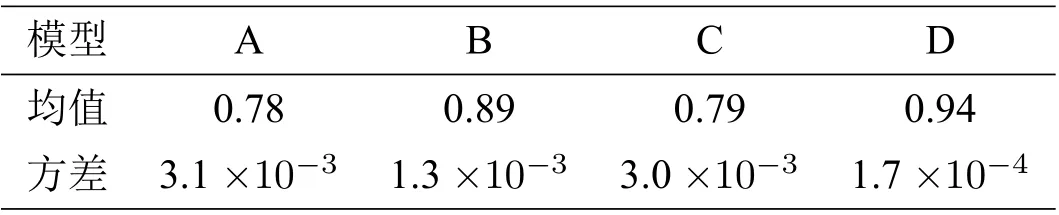
我们将提取高相关区域和主成分分析两种提取特征的方法进行对比分析. 主成分分析是一种使用最广泛的数据降维算法,其基本思想是将n维特征映射到k(k< 对自变量进行主成分分析,用协方差矩阵的特征值计算累计方差贡献率,从而得到累计贡献率与主成分数量关系,如图4所示.可以看出,累计贡献率Ψm与主成分数量m的函数关系为凹函数,累计贡献率的增长速度随着主成分数量逐步引入而降低. 当引入第11 个主成分后,累计贡献率高于0.7;当引入第16 个主成分后,累计贡献率高于0.8;当引入第23 个主成分后,累计贡献率高于0.9;累计贡献率在主成分数量为37 时达到最大值1. 本文选用23 个主成分,样本贡献率高于0.9. 图4 累计样本贡献率与主成分数量关系 对预报因子进行高相关区域提取时,根据最小角回归算法特性,相关系数检验的显著性水平设为0.05,以增强自变量集的解释能力. 我们使用1981 年至2006 年的数据进行训练,将2007 年至2018 年的数据进行测试,再与观测值比对. 设置残差上限为2×10−16,非零参数数量设置为15. 实验结果如图5所示. 图5 最小角回归预测初夏暴雨日数距平 用时间距平相关系数(TCC),同号率,训练集决定系数和测试集决定系数,分别对基于两种特征提取方法的最小角回归算法结果进行检验,并将得到的四个结果进行对比分析,结果如表2所示,其中红色的表示最好结果、蓝色的表示次好结果. 由表2 的数据可得,对于两个站点的模型输出结果,除广州站点的训练集决定系数,使用主成 表2 广州站点与海口站点初夏暴雨日数预测结果检验 分分析的方法略优于高相关区域提取的方法外,其他所有的检验指标都是高相关区域提取方法明显占优. 这说明基于高相关区域提取的最小角回归算法具有较高的预测精度. 本节从整个华南区域的角度对预测结果进行分析. 为了更好地分析最小角回归算法的预测效果,与分别采用基于主成分分析和高相关区域提取两种特征选择的多元线性回归方法进行对比. 为了方便表示,将两种特征选择方法下的两种预测模型分别用代号A,B,C,D 进行表示,具体对应规则见表3. 表3 代号及对应模型 选取气象学中常用的检验指标TCC,分析比较A,B,C,D 四种模型在测试集上的得分. 将所有站点TCC得分分布情况列出如表4所示. 表中第一列表示TCC的划分区间,第二至五列的数据表示TCC得分落在对应区间的站点数占总站点数的百分比. 表4 四种模型下华南地区192 站点TCC 得分分布百分比 统计数据表明,模型A,C 的分布百分比随着TCC的增加,呈现先增后减的分布趋势;模型A中站点的TCC主要集中于区间[−0.2,0.8],模型C 中站点的TCC主要集中于区间[−0.2,0.6],说明基于主成分分析方法选择特征的模型预测效果整体较差. 模型B,D 的站点百分比随着TCC增加大致呈递增趋势,两种模型中站点的TCC均集中于效果最佳的[0.6,1]区间,且占比均为50%左右,不同的是模型B 在[0.8,1]区间的占比更高,而模型D 在[0.6,0.8]区间的占比更高. 这表明基于高相关区域提取方法的两种预测模型在TCC上的表现接近. 上表从空间尺度上比较了模型的预测效果. 为了进一步从时间尺度上比较分析,对四种模型2011 年到2018 年的测试集进行APs评分,结果如图6所示. 由图6可知,整体而言模型B,D 处于更高的评分区间. 模型D 的APs评分均值最高为0.9359,所有年份均显著地高于其他模型,且方差最小(1.7×10−4),测试集的预测结果能稳定地位于较小的区间内,整体效果均显著优于其他模型. 模型B 预测效果次之,APs评分均值为0.8871,方差为1.3×10−3. 模型A,C 的测试集评分均值最低,方差最大,说明这两种模型对华南站点初夏暴雨日数预测精度不足,且稳定性较差. 四种模型的APs评分对应均值与方差如表5所示. 表5 四种模型APs 评分对应均值与方差 图6 四种模型测试集APs 评分对比 本文旨在研究前期的大气环流因子(高度场(hgt), 经向风场(vwnd), 纬向风场(uwnd), 比湿(shum),海平面气压(slp))及海温、海冰和积雪数据对华南地区初夏暴雨的影响,从而实现对华南地区初夏暴雨日数的预测. 本文首先使用高相关区域提取的方法对数据降维,并与常用的主成分分析方法进行比较. 然后用两种方法选择的特征分别构建华南地区初夏暴雨日数的机器学习预测模型,并运用以时间距平相关系数为主的单站点预测结果检验标准和以APs评分为主的区域性检验标准对混合构建的四种模型进行检验分析,得到以下两点结论. (1)在特征提取方面,从单站点预测结果分析,基于高相关区域提取方法的模型结果基本反映了真实距平值的变化,基于主成分分析方法的模型结果与真实情况偏差较大. 其他4 种评价指数也验证了基于高相关区域提取的最小角回归预测模型的明显优势. 从区域预测结果分析可见,基于高相关区域提取的两种模型的时间相关系数分布在区间[0.6,1],基于主成分分析方法的两种模型的时间相关系数近似正态分布,主要位于区间[0.2,0.6]. 且高相关区域提取方法的两种模型的APs评分主要在区间[0.88,0.96],而基于主成分分析方法的两种模型的APs评分主要在区间[0.70,0.89]. (2)在预测模型方面,基于高相关区域提取方法的最小角回归算法预测结果的时间相关系数分布在区间[0.6,0.8],而相应的多元线性回归模型的时间相关系数相对均匀地分布在区间[0.6,1],分布相差不明显. 但高相关区域提取方法的最小角回归算法的APs评分主要在区间[0.91,0.96]上,而对应的多元线性回归模型的APs评分主要在区间[0.81,0.93]. 综上,基于高相关区域提取方法的最小角回归算法能较好地预测华南初夏暴雨日数.
3.2 区域的分析比较


4 结论
