SikuBERT与SikuRoBERTa:面向数字人文的《四库全书》预训练模型构建及应用研究*
2022-06-17王东波朱子赫刘江峰胡昊天
王东波,刘 畅,朱子赫,刘江峰,胡昊天,沈 思,李 斌
0 引言
近年在人文社会科学领域中,数字人文研究异军突起。有关数字人文概念、研究范式等的探究相对全面与成熟,而有关语料库、知识库、计算模型等构建与应用的研究相对较少。面向汉语言文献学的数字人文研究,其最大特征和优势在于拥有海量的汉语古代典籍数据,而最具有代表性的图书典籍数据源为《四库全书》。如何利用《四库全书》这一宽广而全面的历史文献集?这一问题在深度学习背景下有了全新的解决方案。基于BERT语言模型框架,构建面向古籍文献的预训练模型,对推动古文智能化处理以及数字人文研究的深入具有独特价值。据此,本文基于BERT(Bidirectional Encoder Representation from Transformers)预训练模型技术,利用《四库全书》正文语料,构建SikuBERT和SikuRoBERTa预训练模型,在多层次的古文处理任务上进行验证,并构建SIKU-BERT典籍智能处理平台,为人文领域学者提供一种便利化的古文知识组织与挖掘选择。
1 文献综述
1.1 预训练语言模型
自然语言处理(Natural Language Processing,NLP)和文本的研究包括序列标注、自动分类、文本生成等各类有监督任务。这些任务往往需要构建大规模标注训练集,以让深度学习模型充分学习词汇、句法与语义的特征,从而使得其人力与时间成本非常昂贵。而通过自监督的方式,让语言模型在大量未标记语料上进行训练,对自然语言的内在特征进行建模与表征,可得到具有通用语言表示[1]的预训练模型(Pre-trained Model,PLM)。在进行下游任务时,直接将预训练模型作为初始化参数,不仅使模型具备更强的泛化能力与更快的收敛速度[2],且仅需要输入少量的标记数据进行微调,即可在避免过拟合的同时显著提升NLP任务性能。
早期以Word2Vec[3]、GloVe[4]等为代表的预训练模型基于词嵌入技术,将词汇表征为低维稠密的分布式向量。这些嵌入方式虽然考虑了词义与词汇间的共现关系,但所构建的词向量为缺乏上下文依赖的静态向量,词义不会因语境的更改而变化,因此无法解决一词多义问题。自ELMo[5]模型提出以后,基于上下文语境信息动态嵌入的预训练模型解决了静态词向量词义固定的问题,实现了对词义、语法、语言结构的联合深层建模。
预训练模型根据建模思想的不同,主要可以分为3类。第一类是以GPT[6]为代表的自回归模型。由于本质上为单向语言模型,虽然在生成式任务中表现优异,但是无法同时学习上下文信息。第二类是以BERT[7]为代表的自编码模型,通过掩码语言模型(Masked Language Model,MLM)实现两个方向信息的同时获取,但也因此导致预训练和微调阶段不匹配的问题。第三类是以XLNet[8]为代表的排序语言模型。此类模型融合了上述两类模型的优势,通过对输入序列的随机排序,使单向语言模型学习到双向文本表示的同时,还保证了两阶段的一致性。
以下为当前较为主流的预训练模型。ELMo(Embedding from Language Models)[5]模型:通过两层双向LSTM神经网络在大规模语料库上进行预训练,学习词汇在不同语境下的句法与语义信息,并在下游任务中动态调整多义词的嵌入表示,从而确定多义词在特定上下文中的含义。由于其简单拼接前后两个方向独立训练的单向语言模型,特征融合能力相对较弱。GPT(Generative Pre-Training)[6]模型:将ELMo模型中的LSTM架构替换为特征提取能力更强的单向Transformer[9],从而捕捉更长距离的语境信息。然而,由于其仅使用上文信息预测当前词汇,因此更适合于机器翻译、自动摘要等前向生成式任务。其后续的改进型GPT2.0[10]与GPT3.0[11]模型,采用了更大的Transformer结构,基于规模更大、质量更高、类型更广的WebText、Common Crawl等数据集,预训练了更加通用、泛化能力更强的语言模型,并无需微调、完全无监督地进行文本生成等下游任务。BERT模型:该模型的出现极大地推动了预训练模型的发展[12],催生一系列改进的预训练模型,也使得预训练结合下游任务微调逐渐成为当前预训练模型的主流模式[1]。BERT是一种基于Transformer架构的自监督深层双向语言表示模型,它通过掩码语言模型迫使模型根据前后文全向信息进行预测,从而实现深层双向文本表示。此外,BERT还通过下一句预测(Next Sentence Prediction,NSP)任务,学习前后两个句子是否为连续关系,从而更好地实现自动问答和自然语言推理。
由于BERT模型中MLM遮蔽机制仅作用于单个字符,对词间关系与中文词义的学习并不友好,因此后续学者提出的一些预训练模型对遮蔽机制进行了改进。一是ERNIE(Baidu,Enhanced Representation through Knowledge Integration)[13]在原始对单个字符(汉字)遮蔽的基础上,增加了实体层面遮蔽和短语层面遮蔽,从而使预训练模型学习到丰富的外部实体和短语知识。该模型还构建了对话语言模型(Dialogue Language Model,DLM)任务,基于百度贴吧的对话数据学习多轮对话中的隐式语义关系。二是BERT-wwm[14]模型提出了更适合中文文本的全词遮蔽。不同于ERNIE(Baidu)仅遮蔽实体和短语,该模型进一步放宽了遮蔽的条件,即只要一个中文词汇中的部分汉字被遮蔽,就把该词汇中的所有汉字全部遮蔽,从而使预训练模型学习到中文词汇的词义信息。三是SpanBERT[15]采用Span Masking 方法,从几何分布中采样Span 的长度,并随机选择遮蔽的初始位置,让模型仅根据Span的边界词和Span中词汇位置信息预测被遮蔽词汇。实验证明该方法表现优于对实体和短语进行遮蔽。四是RoBERTa(a Robustly Optimized BERT Pretraining Approach)[16]模型将词汇静态遮蔽(static mask)替换成动态遮蔽(dynamic mask),在每次输入前均对句子进行一次随机遮蔽,从而提升训练数据的利用率。此外,该模型在预训练过程删去NSP任务,改用FULL-SENTENCES方法,每次输入指定长度的连续句子,进一步优化模型在句子关系推理方面的表现。五是StructBERT[17]模型增加了词汇结构预测(Word Structural Objective)任务,对于输入句中未被遮蔽的词汇,随机选择3个连续的词(Trigram)打乱循序,要求模型重构并恢复先前的顺序;然后将NSP任务替换为句子结构预测,将判断是否为连续句子的二元分类问题改进为预测下一个句子与当前句子位置关系的三元分类任务,从而显式学习词汇和句子层面的语义关系与语言结构。
部分预训练模型对BERT的模型架构进行了修改。为了让结构化的外部知识增强语言表征,ERNIE(THU,Enhanced Language Representation with Informative Entities)[18]模型将知识图谱中的命名实体作为先验知识引入BERT的预训练中。该模型分别采用T-Encoder和K-Encoder对文本和实体知识进行编码与特征融合,并在预训练过程引入词汇-实体对齐任务,从而更好地将实体知识注入文本表示中。为了解决BERT忽略了被遮蔽词汇间相关性这一问题,XLNet提出了双流自注意力机制,采用排序语言模型的思想,通过因式分解序列所有可能的排列方式,每个词汇都可学习到两边所有词汇的信息,使得单向的自回归模型也具备了同时学习上下文特征的能力;此外,引入自回归模型Transformer-XL中的片段循环机制和相对位置编码,实现对长期依赖关系的学习。由于整个预训练过程并不将人为遮蔽纳入计算,因此XLNet不存在预训练与微调两阶段不匹配的情况。ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)[19]引入了替换标记检测任务,在对输入句进行随机词汇遮蔽后,通过生成器预测词汇并替代标记,随后采用鉴别器分辨生成器产生的词汇是否与原始输入词汇相同,最终仅使用预训练的鉴别器开展下游任务。ELECTRA 解决了预训练任务与下游任务中[MASK]不匹配的问题,在提升计算效率的同时取得更优的表现。DeBERTa(Decoding-enhanced BERT with Disentangled Attention)[20]模型提出分解注意力机制,在计算词间注意力权值时,采用解耦矩阵同时考虑词汇间的内容和相对位置信息,融入了词汇间依赖关系;即通过增强的掩码解码器嵌入词汇在句子中的绝对位置信息,获得词汇的句法特征。此外,该模型还提出了虚拟对抗训练算法SiFT(Scale-invariant-Fine-Tuning),用于提升微调下游任务时模型的泛化能力。与动辄含有上亿个参数的预训练模型相比,ALBERT[21]模型通过嵌入参数矩阵分解以及跨层参数共享的方式显著压缩了参数数量,并将BERT 中的NSP 替换为SOP(Sentence-Order Prediction)任务,用于学习相邻句子间连贯性与衔接关系。
还有一些模型仅部分采用了BERT 的架构或思想。MT-DNN(Multi-Task Deep Neural Networks)[22]模型是一种用于自然语言理解的预训练模型。它采用多任务学习的思想,在预训练阶段通过共享层基于BERT 进行词汇与语境嵌入,在微调阶段引入单句分类、文本相似度、配对文本分类和相关性排序等多个任务联合学习,减少模型在特定任务上的过拟合,更适用于一些缺少标注数据的下游任务。受此启发,基于持续多任务学习的思想,百度在2020年发布了预训练模型ERNIE 2.0(Baidu)[23]。在保留BERT的字符嵌入、句子嵌入和位置嵌入3种嵌入方式的同时引入任务嵌入,通过增量学习的方法使模型逐步学习词法、句法、语义层面的7种任务,不断提升语言表征能力。T5(Text-To-Text Transfer Transformer)[24]模型基于迁移学习思想,构建文本到文本的NLP任务统一框架,从而使用相同的模型、损失函数、超参数设置等开展机器翻译、自动问答、文本分类等任务。
从上述相关研究发现:第一,目前大多数预训练模型都是基于大量通用语料训练的;第二,相当一部分预训练模型都是基于BERT的改进版本。这些模型普适性虽强,但在面对特定领域文本的自然语言处理任务时,其功能的发挥容易受限。而古代汉语在语法、语义、语用上与现代汉语存在较大差异,即使是面向中文构建的Chinese-BERT-wwm,在古汉语处理上也难以达到其在中文通用语料上的性能。此外,虽然已经出现了面向生物医学(BioBERT)[25]、临床医学 (ClinicalBERT)[26]、 科 学 (SciBERT)[27]、 专 利(PatentBERT)[28]等特定领域的预训练模型,但目前仅有GuwenBERT①基于继续训练将BERT 迁移至古汉语语言建模中,且由于语料规模、简繁转换等因素的限制,效果不尽如人意。在古汉语领域,由于缺乏大规模纯净的古文数据,构建古文标注训练集成本高昂,对标注人员具有较高要求。因此,构建高质量无监督古文数据集,训练面向古文自然语言处理任务的预训练模型,对高效开展古文信息处理下游任务研究,拓展数字人文研究内涵,增强社会主义文化自信具有重要意义。
1.2 人文计算与四库学
中国拥有卷帙浩繁的古代文献典籍,它们蕴含着中华民族特有的精神价值与文化知识。1980年代以来,古籍数字化建设取得了不俗的实绩。然而,数字化古籍研究仍面临三重困境:一是古籍数字化仍囿于整理范畴,对深层知识的研究尚不充分[29];二是现有古籍利用仍以检索浏览为主,深度利用率低[30];三是国内学界虽占有大量数据,却难以引领古籍的数字研究范式[31]。在数字化时代,古籍研究亟待实现范式革新。源自“人文计算”的数字人文理念与古籍数字化研究之间的深度融合正引起学界的广泛关注。数字人文是“一种代表性实践”,“这种代表性的实践可一分为二,一端是高效的计算,另一端是人文沟通”,其主要范畴是“改变人文知识的发现(Discovering)、 标 注 (Annotating)、 比 较 (Comparing)、引用(Referring)、取样(Sampling)、阐释(Illustrating)与呈现(Representing)”[32]。数字人文的理论逻辑与技术体系“能够为古籍文献的组织、标引、检索与利用提供新的方法与模式”[29],“协助学者进行多维度的统计、比较、分析,产生新的知识和思想”[32],为古籍研究与利用提供新的范式。
《四库全书》作为珍贵的文化遗产,其开发与利用历来受到研究人员的重视,围绕《四库全书》的文献体系,学术界产生“四库学”这一崭新学科。何宗美[33]把“四库学”的研究内容分为九大部分,其中与《四库全书》本身密切相关的是《四库全书》及其子系列的文献研究和《四库全书》的“总目学”研究,图情领域的学者对后者尤为侧重。邓洪波等[34]分析2010-2015年间国内“四库学”研究状况,指出《四库全书》研究以中国语言文学和史学为主体,而图情档学科有关《四库全书》研究的硕博论文仅占1.9%,强调《四库全书》的研究应当更加注重学科背景的多元化。在与数据挖掘结合的研究中,崔丹丹等[35]利用甲言分词工具切分的《四库全书》文本训练词向量,结合Lattice-LSTM模型抽取《四库全书》中的人名、地名、朝代名和官职名4类实体,取得了良好效果。王倩等[36]使用《四库全书》全文数据基于迭代学习的方法构建自动断句模型,并开发标注平台加以推广。这些研究成果多局限于具体的下游任务,缺乏上游的顶层设计,虽然在一定程度上采用了预训练技术生成词向量以辅助训练,但所开发的模型仍有普适性和可迁移性较低的问题。
相较而言,本文的研究更侧重语言模型训练,旨在通过利用未经人工标注的海量数据构建高通用性和易用性的语言模型,充分发掘《四库全书》这座文化宝藏的价值。而且,本研究所构建的预训练语言模型不需要对古籍文本重新分词,避免词向量训练需依赖精确中文分词文本的缺陷,最大程度地保留古籍文本的原始特征,确保实验成果更贴近古籍原文的处理。以《四库全书》数字化为研究对象,本研究还构建了一种全新的SIKU-BERT典籍智能处理平台,重点开发其在典籍自动处理、检索和自动翻译三方面的功能,在数字人文理念引领下提升深度学习模型对古文语料的准确理解,助力基于古文语料的NLP研究。
2 《四库全书》预训练模型构建
2.1 数据源简介
《四库全书》是清代乾隆时期编修的大型丛书。本文使用的《四库全书》为文渊阁版本。本次实验的训练集共有汉字536,097,588个,去除重复字后得到28,803个,均为繁体字。数据集较《四库全书》全文字数少的原因在于,本实验去除了原本中的注释部分,仅纳入正文部分。之所以删除注释信息,是由BERT模型预训练的本质所决定的。BERT 模型基于双向Transformer编码器结构,是一种典型的自编码(Autoencoder)语言模型。不同于传统的自回归(Autoregressive)模型自左向右预测下一个字符的训练方式,此类语言模型的训练思想依靠并综合上下文的内容预测被遮罩的字符。古文中同样的句子在留有注释信息和删除注释信息的情况下,模型对遮罩词的预测结果可能大相径庭,直接影响到最终的训练成果。考虑到当前古籍处理任务多关注古籍原文的挖掘和利用,不加入古籍注释信息的训练必然更适用于一般性下游任务。若有针对古籍注释资源的研究需要,可以另行构建基于注释语料的预训练模型。
《四库全书》数据集主要有4个部分:经部、史部、子部、集部,分别由679、568、897、1,262 本书组成。表 1 展示《四库全书》各部各书的字数概况。史部每本书的平均字数最多,子部和集部次之,经部最少。从字数分布差异上来看,经部的差异最小,而史部最大。从单本字数极值来看,子部的最大值最大,而经部的最小值最小。从去重后的字数统计结果来看,集部、史部的用字较多。集部主要包括文学作品,用字往往比较丰富,用词比较凝练,因而其总体字数不多,但去重后用字数反而处于相对高位水平。史部主要包括各类历史著作,这类描述历史人物事件的书籍通常篇幅较大,而由于其中经常出现的人名、地名中会包含一些生僻字,因而其去重后用字依然相对较多。
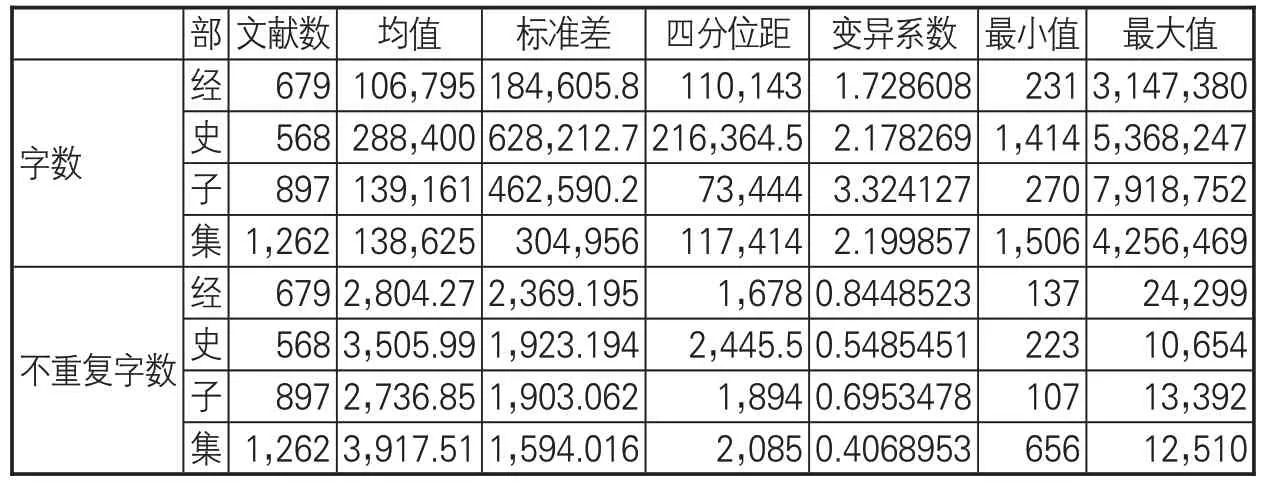
表1 《四库全书》各部字数及不重复字数概况
2.2 预训练模型构建
2.2.1 预训练模型的构建流程
图1展示了从语料预处理到下游任务验证的模型预训练及其评测全过程。实验分为4个部分:语料预处理,模型预训练,模型效果评测和下游任务测试。实验先根据清洗后的《四库全书》全文语料,按“99∶1”划分训练集与验证集。模型预训练阶段,在总结多次预实验结果后对训练参数进行调优,选取Huggingface提供的Pytorch 版 BERT-base-Chinese 和 Chinese-RoBERTa-wwm-ext模型在训练集上使用掩码语言模型(MLM)任务完成模型的预训练。在模型效果评测阶段,使用困惑度(Perplexity)为基本指标初步判断预训练效果,最后通过设置4种下游任务进一步分析对比5种预训练模型的表现。
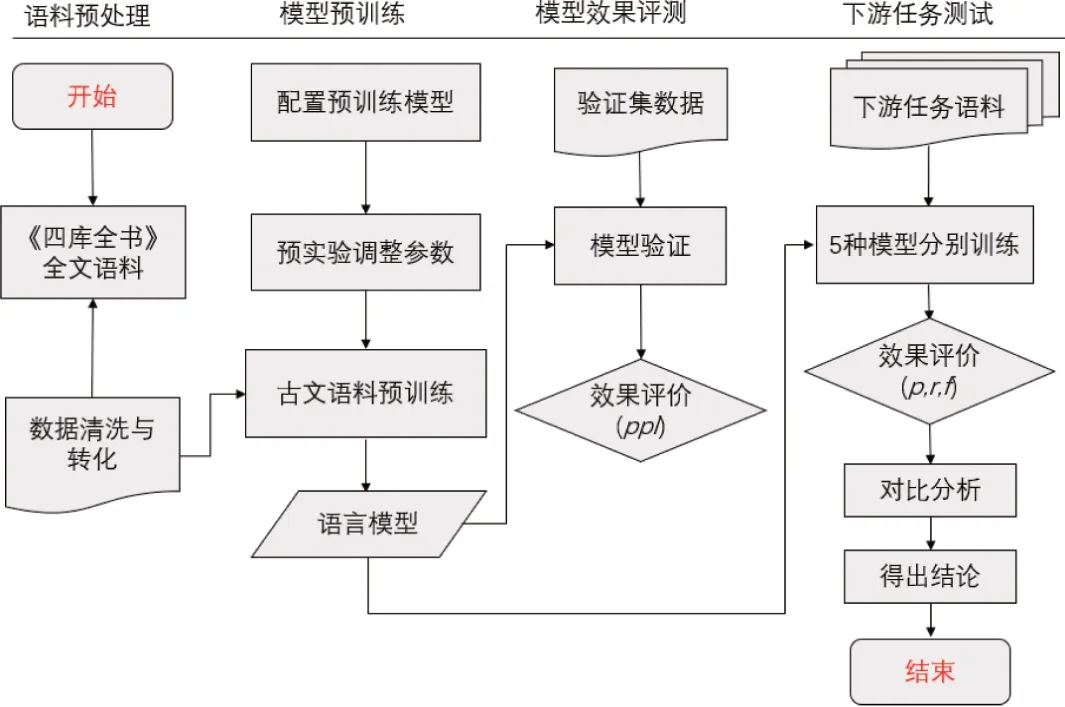
图1 预训练模型构建实验流程
2.2.2 预训练模型选取
(1)BERT 预 训 练 模 型。 2018 年 10 月 谷 歌AI 团队公布新的语言表征模型——BERT[7],刷新11 项NLP 任务记录。BERT的基本结构建立在双向Transformer编码器上,通过掩码语言模型(MLM)和下一句预测(NSP)两个无监督任务完成模型的预训练。在MLM任务中,按比例随机遮蔽输入序列中的部分字符,使模型根据上下文预测被遮蔽的单词,以完成深度双向表征的训练。而在NSP任务中,BERT模型成对地读入句子,并判断给定的两个句子是否相邻,从而获得句子之间的关系。BERT模型的微调过程则建立在预训练得到的模型上,仅需对模型的高层参数进行调整,即可适应不同的下游任务。本实验选取12 层、768个隐藏单元、12个自注意力头、1.1亿个参数的BERT中文预训练模型用于预训练。
(2)RoBERTa中文预训练模型。Liu等[16]认为BERT模型并没有得到充分的训练,为此,他们总结了BERT 模型训练中存在的不足,提出了RoBERTa预训练模型,在BERT模型训练的每个部分都进行了轻微改进。这些改进包括使用动态掩码替代静态掩码,扩大训练批次与数据集大小,提升输入序列长度以移除NSP任务等。这些调整使BERT模型的调参达到了最优。实验选取12 层、768个隐藏单元、12个自注意力头的RoBERTa中文预训练模型作为基础模型,该模型基于全词遮罩(Whole Word Mask)的训练策略,在30G大小的中文语料上完成了预训练。在全词遮罩中,如果一个词的部分子词被遮罩,则同属该词的其他部分也被遮罩。此方法有助于模型学习中文文本的词汇特征。
2.2.3 语言模型预训练方法
本实验选用掩码语言模型(MLM)任务完成SikuBERT与SikuRoBERTa的预训练。BERT模型的预训练使用了MLM 和NSP 两个无监督任务,其中设计NSP任务的目的在于提升对需要推理句间关系下游任务的效果。但是,在后续研究中有学者发现,NSP任务对BERT模型预训练和下游任务性能的提升几乎无效。RoBERTa模型的开发者对NSP任务的效果表达了质疑,并通过更改输入句子对的模式设计了4组实验,证实了该猜想。Lan 等[21]认为NSP 任务的设计过于简单,即将主题预测与相干性预测合并在同一个任务中,主题预测功能使NSP的损失函数与MLM的损失函数发生了大量重叠。基于上述研究的结果,本实验移除BERT预训练中的NSP任务,仅使用MLM任务完成SikuBERT与SikuRoBERTa的预训练。在实验中随机遮罩15%的词汇,通过预测被遮罩字符的方式完成参数更新,并使用MLM损失函数判断模型预训练的完成度。全部实验均依靠Huggingface 公司的Transformers框架而进行。
2.2.4 预训练模型效果的评价指标
在模型效果评测阶段,使用困惑度(PPL,Perplexity)来衡量语言模型的优劣。困惑度的定义如下:对一个给定的序列S:S=w1w2…wn-1wn,表示序列中第n个词,则该序列的似然概率定义为:

则困惑度可以定义为:
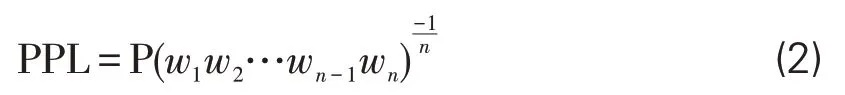
困惑度的大小反映了语言模型的好坏,一般情况下,困惑度越低,代表语言模型效果越好。本实验通过调整训练轮次,使得SikuRoBERTa在验证集上的困惑度达到1.410,SikuBERT的困惑度达到16.787,达到相对较低水平。初步验证表明,经过领域化语料上的二次微调,SikuBERT和SikuRoBERTa具有较低的困惑度。从语言模型的评价角度来看,在《四库全书》语料下,相比原始BERT模型和RoBERTa模型,其性能有所提升,可以保证模型充分学习到《四库全书》的语言信息。
2.3 预训练模型性能验证
为检验SikuBERT 和SikuRoBERTa 预训练模型的性能,本研究设置4项NLP任务做进一步的验证:古文命名实体识别任务、古文词性识别任务、古文分词任务、古文自动断句和标点任务。在语料选择上,基于经过人工校对过的《左传》语料,构造4种实验所需要的训练和测试数据。在基线模型的选择上,除BERT-base 和RoBERTa外,还引入GuwenBERT预训练模型。
2.3.1 验证实验的语料和任务
验证实验所使用的语料为南京师范大学文学院(以下简称“南师大文学院”)校对过的繁体《左传》,全文18万字。该语料库是以南师大文学院制定的古汉语分词与词性标注规范为依据,使用自动分析工具结合人工校对而成的精加工语料库[37]。《左传》数字人文数据库语料经过处理后,除词性识别任务外,还可用于古文分词、古文实体识别、古文断句和古文标点等任务。本文选取《左传》数据集作为验证实验数据,一方面统一了选用语料的来源,避免多种古文语料间差异带来的验证上的误差。《左传》数据集是高质量的公开数据集,使用公开数据集作为基本语料,不仅可以体现实验结果的公开性、透明性,也降低了其他研究者复现实验的难度,从而为实验结论提供更有力的佐证。另一方面,《左传》数据集经过高质量的人工校对,语料标注的规范程度更高,能有效降低引入不同语料的误差,从而更好地比对预训练模型之间的差异。本文中,验证实验的主要目的是为SikuBERT 和SikuRoBERTa 模型的性能提供一个除困惑度之外的判断指标,关于模型在多源语料以及多种不同任务上的具体表现可参见本系列的其他相关论文。基于《左传》语料的4个任务及其内容见表2。
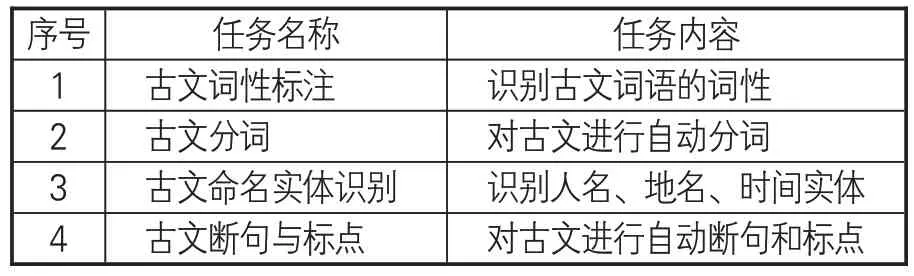
表2 下游任务语料描述
(1)古文词性标注任务。古籍文本中没有词界,以词为粒度切分古籍文本是进行更多古文应用的基础,如古文词典编撰、古文检索等。在训练数据预处理上,因为《左传》数字人文数据库是经过人工校对过的词性标签语料集,所以可以直接作为古文词性标注的训练数据进行使用。
(2)古文分词任务。《左传》数字人文数据库以词为单位进行词性标注,经过词性标签的清洗后,可获得古文的分词数据。该分词数据是词性标注数据的子集,同样可用于序列标注任务。
(4)古文自动断句和标点任务。首先,在《左传》数字人文数据库语料的基础上,去除分词和词性标签,保留标点符号。其次,将每个标点符号作为标记,构造断句和标点训练语料,以希望模型能够为原始古文语料进行断句和标点的操作。
2.3.2 验证模型
验证实验选用的预训练模型如表3所示。为验证SikuBERT 和SikuRoBERTa 性能,实验选用的基线模型为BERT-base-Chinese预训练模型②和Chinese-RoBERTa-wwm-ext预训练模型③,还引入GuwenBERT 预训练模型进行验证。GuwenBERT基于“殆知阁古代文献语料”在中文BERT-wwm预训练模型上进行训练,将所有繁体字经过简体转换处理后用于训练,模型在古文数据的任务中具有良好的表现。此外,为使验证结果具有一致性,在4项任务验证中,只对上游预训练模型进行更换,对下游任务的模型参数保持统一。
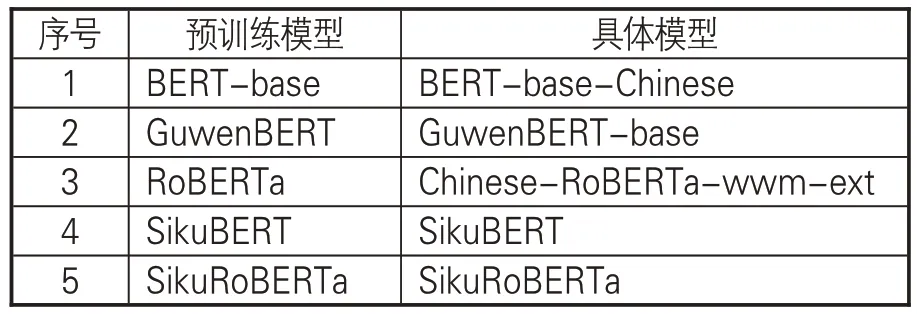
表3 验证实验选用的预训练模型一览表
2.3.3 模型验证性能指标
结合分词性能评价常用指标体系,对BERT-base、RoBERTa、GuwenBERT、SikuBERT 和SikuRoBERTa预训练模型使用以下3个指标来衡量,即准确率(Precision,P)、召回率(Recall,R)、调和平均值(F1-measure,F1)。各指标具体计算公式如下:
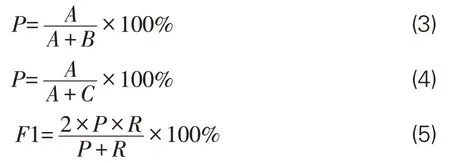
在上述公式中,A、B、C分别代表模型预测出的正样本数、模型预测错误的样本数以及模型未预测出的正样本数。选用繁体中文版的《四库全书》全文数据进行预训练模型的领域学习实验,并将其应用在繁体中文的《左传》语料上,进行古文自动分词实验。
2.3.4 基于预训练模型的分词结果比较
表4为模型指标的平均值,从这些数据可以看到,实验中SikuBERT 和SikuRoBERTa 的性能表现最佳,分词的准确率、召回率和调和平均值均较基线模型BERT-base、RoBERTa 和GuwenBERT 有明显改进。在准确率和召回率上,SikuBERT预训练模型的表现效果最佳,分别为88.62%和89.08%;而SikuRoBERTa得到最好的调和平均值,为88.88%。所有模型中GuwenBERT 预训练模型的分词表现最差,精确率、召回率和调和平均值分别为46.11%、57.04%、50.86%。以调和平均值为基准,在分词任务中原始BERT模型表现优于RoBERTa模型,识别效果约高出5%。整体上,SikuBERT预训练模型效果最优。
工况1—2计算结果分析:工况1,混凝土强度及板厚按照设计取值,地下车库底板回填土和顶板回填土同样按照原设计要求考虑,结果表明,地下车库整体无明显上浮,且无明显起拱现象.工况2,混凝土强度、底板和顶板厚度按照实测取值,结合现场工程实际发生情况,该工况不考虑地下车库底板回填土和顶板回填土,结果表明,地下车库出现整体上浮起拱现象,地下车库底板最大起拱高度达250 mm,顶板起拱高度达238 mm.地下车库底板最大弯矩为219 kN·m,柱端剪力为545 kN,地下车库底板开裂,柱两端发生剪切破坏.
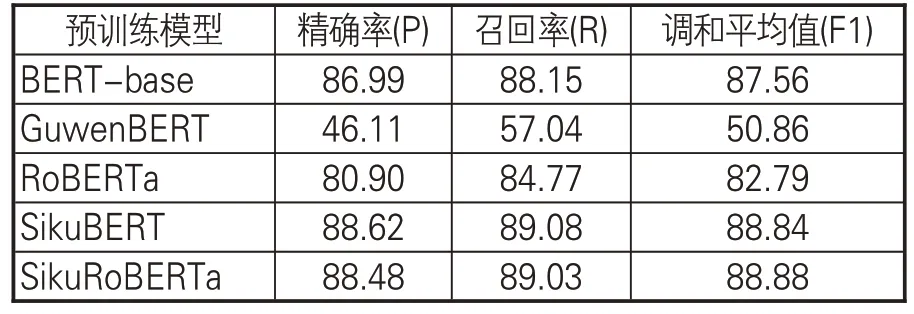
表4 模型分词结果指标平均值(%)
2.3.5 基于预训练模型的词性标注结果比较
基于预训练模型的词性标注实验所用数据集来自《左传》,同样以领域内较常使用的准确率(P)、召回率(R)和调和平均值(F1)作为实验结果的评价指标。从实验结果(详见表5)中可以看出,针对《左传》数据的古文词性标注实验表现均不错,但SikuBERT 和SikuRoBERTa 模型的调和平均值要明显高于其他3个识别模型,二者的F1值均超过了90%,SikuBERT识别效果更是达到了90.10%;而GuwenBERT模型的识别效果最差,调和平均值只有74.82%,不及最为基础的BERT-base 模型。此外,原始BERT 模型(BERT-base)的效果要优于RoBERTa模型,且基于《四库全书》数据训练得到的SikuBERT模型效果同样优于SikuRoBERTa模型。实验结果值得进一步分析和探讨。
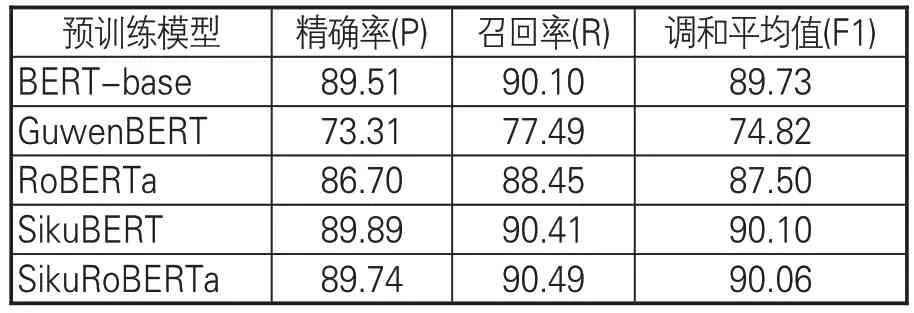
表5 模型词性识别结果指标平均值(%)
2.3.6 基于预训练模型的断句结果比较
为验证SikuBERT 和SikuRoBERTa 预训练模型对古文断句的识别效果,在《左氏春秋传》《春秋公羊传》《春秋谷梁传》3本古文著作数据集中进行断句识别实验。实验结果(见表6)显示,SikuBERT 和SikuRoBERTa 模型的效果均超过85%,SikuBERT 的F1 值最优,达到87.53%,这也是多组对比实验中的最好实验结果;GuwenBERT模型的识别调和平均值在各组实验中表现最差,仅有28.32%,远低于其他模型;基础的BERT-base和基于原始BERT模型训练得到的RoBERTa识别效果一般,调和平均值分别只有78.70%和66.54%,低于本文自主预训练的识别模型SikuBERT和SikuRoBERTa,但高于GuwenBERT模型。

表6 模型断句识别结果指标平均值(%)
2.3.7 基于预训练模型的实体识别结果比较
对长文本中实体的有效识别,是判断该模型能否有效解决自然语言理解问题的重要评价标准之一。本组对比实验的数据来自《左传》典籍数据,识别实体对象为数据集中的“人名”“地名”“时间”3类实体,模型识别效果评价标准仍为最常用的准确率(P)、召回率(R)、调和平均值(F1)。从实验结果(见表7)可看出,SikuBERT和SikuRoBERTa 模型的3 类实体识别效果均高于其他3 种模型,尤其是在时间实体的识别中,SikuBERT和SikuRoBERTa模型识别的调和平均值均超过了96%。而GuwenBERT模型在3类实体识别实验中的表现均最差,其中人名和地名实体识别的调和平均值均低于50%,且远低于其他组的识别效果,这可能是由于其训练语料为简体中文的缘故。BERT-base模型和RoBERTa在3组实验中的表现较为中庸,没有展示特别突出的识别性能。
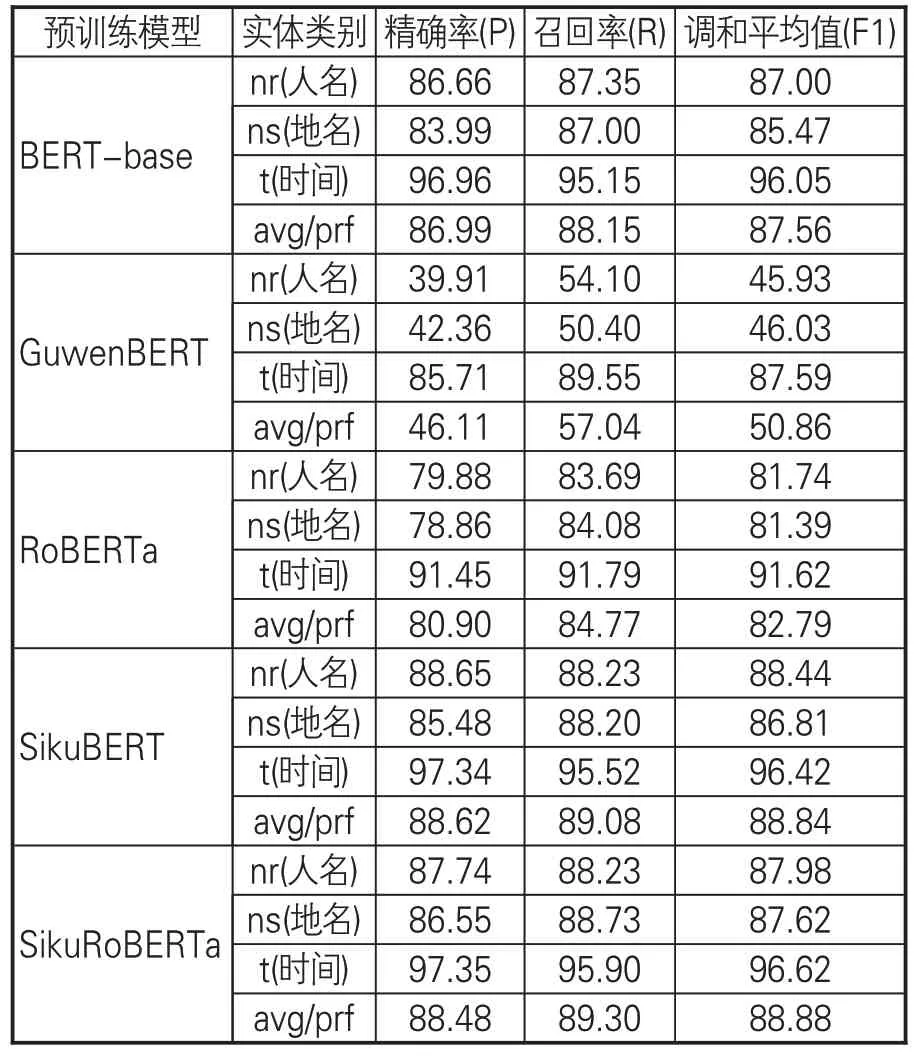
表7 模型实体识别结果指标平均值(%)
3 基于预训练模型的典籍智能处理平台搭建
3.1 构建流程
上述验证结果表明,SikuBERT和SikuRo-BERTa预训练模型能够有效提升繁体中文语料的智能处理效果。为进一步展示本实验的研究成果,课题组构建“SIKU-BERT典籍智能处理平台”,其功能结构框架见图2。该平台有3种主要功能:典籍智能处理、典籍检索和典籍自动翻译。首页提供SIKU-BERT 相关背景的详细介绍、3种主要功能的简介以及平台的基本信息。用户可根据自身需求选择不同的功能,进入平台的相应界面。例如,用户希望使用典籍智能处理功能,则可以点击相应界面,选择相关子功能操作(文本断句、分词、词性标注或实体标注),在结果返回框中获取处理结果。在针对典籍的自动翻译功能中,用户可以选择“语内翻译”或“语际翻译”,平台将根据用户的选择返回结果。古文相似检索功能实现了将输入的古文句子与语料库中候选句的相似度进行计算,并返回相似古文语句。
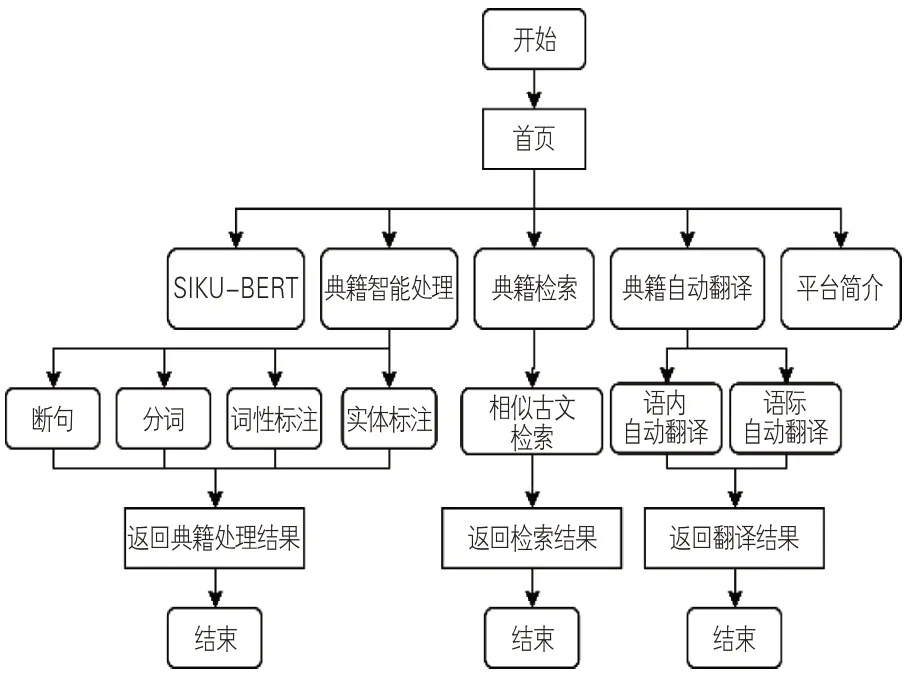
图2 SIKU-BERT典籍智能处理平台系统构建流程
3.2 实现方法和工具
3.2.1 系统数据和工具
本研究搭建的面向典籍智能处理的应用平台,在构建方式选择上,基于平台建设方便性和用户使用简便性两方面的考量,采用网站的架构;选择Python 为主要的编程语言,使用Django 作为网站后端构建的主体框架,以HTML、CSS、JS作为构建工具来实现网站前端呈现。Django框架是利用Python开发的免费开源Web框架,涵盖绝大多数web应用所需要的功能。在数据存储方面,选择SQLite数据库存储多层级平行语料库,以节省物理存储资源。
3.2.2 系统功能设计
本研究构建的SIKU-BERT典籍智能处理平台设计了典籍自动处理、典籍检索和典籍自动翻译三大基本模块,分别对应古文断句、分词、词性标注、实体标注,涵盖相似古文检索以及段落、句子、词汇的语内和语际翻译等功能。
3.2.3 系统应用展示
SIKU-BERT典籍智能处理平台包含首页(见图3)、典籍智能处理、典籍检索和典籍自动翻译4个界面。首页展示平台简介和三大核心功能的快捷入口。

图3 SIKU-BERT典籍智能处理平台网站首页
(1)网站首页。以“典籍智能处理”功能为例,该功能主要实现典籍的自动断句、分词、词性标注和实体标注。首页有该功能的运行示例图和详细介绍,点击“FIND OUT MORE”进入功能界面(见图4)。同时,继续往下翻动页面可以看到平台的主要功能简介,见图5。
图4 SIKU-BERT典籍智能处理平台首页“典籍智能处理”功能介绍

图5 SIKU-BERT典籍智能处理平台首页“平台简介”
(2)典籍智能处理功能界面。如图6所示,在SIKU-BERT 典籍智能处理平台的“典籍智能处理”功能界面,用户可以根据自身需求通过上方按钮分别选择对应的典籍处理功能,包括断句、分词、词性标注和实体标注。用户在界面左侧的文本框中输入需要进行处理的原始典籍文本,选择功能按钮后,点击“开始处理”按钮,即可返回经平台处理后的句子。比如,在图6中输入“子墨子曰:‘今若有能以义名立于天下,以德求诸侯者,天下之服可立而待也。’”,选择“词性标注”功能,点击“开始处理”,那么在右侧便会输出返回的结果:“子墨子/nr曰/v:/w“/w今/t若/c有/v能/v 以/p 义/v 名/n 立/v 于/p 天下/n,/w 以/p德/n求/v诸侯/nr者/r,/w天下/n之/u服/n可/v 立/v 而/c 待/v 也/y。/w”。该功能实现了典籍文本快速且规范化的处理。作为古文NLP研究工具,平台为哲学、文学、历史学等学科研究人员的工作带来极大方便。
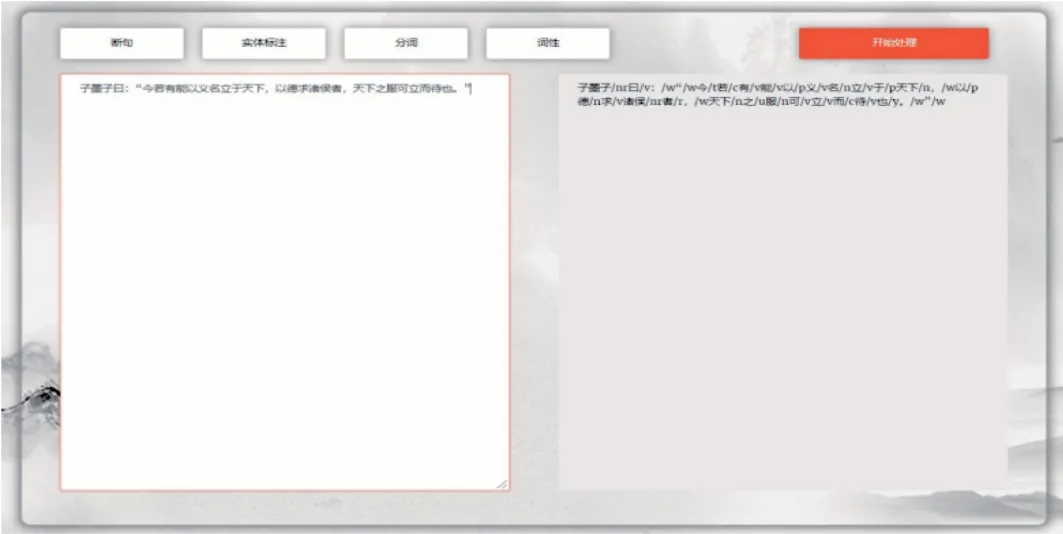
图6 SIKU-BERT典籍智能处理平台“典籍智能处理”功能界面
4 结语
在基于古文语料的NLP任务中,考虑到异体字和“一简对多繁”等现象,采用简繁转换功能必然会导致古籍中原本语义信息的部分丢失,使用繁体中文的原始语料仍然是古文自然语言处理的主流。但是,随着预训练模型技术兴起,面向古文语料的预训练模型并没有得到充分开发。因此,训练一种能够贴合古文语料的预训练模型,能为基于古文语料的人文计算研究提供重要支撑。本文基于BERT-base、RoBERTa、GuwenBERT、SikuBERT和SikuRoBERTa预训练模型,分别在4种不同的古文任务中进行性能验证。验证实验结果表明,SikuBERT与SikuRoBERTa相较于基线(准)模型的识别效果有一定程度上的提升,SikuRoBERTa 的性能最好;SikuBERT、SikuRoBERTa在分词、词性标注上的提升幅度较小,在断句、实体识别等任务中的提升幅度较大。
综上所述,SikuBERT和SikuRoBERTa预训练模型能够有效提升繁体中文语料处理的效果,对于古文NLP研究具有重要意义。下一步的模型效能提升研究将着重于构建更适合古籍智能处理任务的预训练模型词表,从而获得性能更好的词表示特征。将来的相关应用研究还会着眼于上述各层级智能处理任务在不同典籍文献上的具体应用。
注释
①参见:https://github.com/ethan-yt/guwenbert.
②参见:https://huggingface.co/bert-base-chinese.
③参见:https://huggingface.co/hfl/chinese-roberta-wwmext.
