类间数据不均衡条件下基于平衡随机森林的轴向柱塞泵故障诊断方法
2022-06-09马歆宇岳毅赵亚鹏
马歆宇岳 毅赵亚鹏
(1.燕山大学 河北省重型机械流体动力传输与控制重点实验室,河北 秦皇岛 066004;2.燕山大学 先进锻压成形技术与科学教育部重点实验室,河北 秦皇岛 066004)
引言
作为液压系统的主要动力元件,液压泵的性能直接影响液压系统的正常工作[1-4],其状态监测与故障诊断是液压系统运维的重要环节。轴向柱塞泵常见故障有泵发热、配流盘磨损、滑靴与斜盘磨损、松靴以及输出流量不足等[5-7]。
在实际的液压泵故障诊断过程中,正常样本的数量远大于故障样本的数量,即不同类别的样本数量极度不均衡。这时,传统的分类方法就难以取得好的分类效果。因为不同类别样本数量差距很大,在分类时分类器会将少数类样本误判为多数类样本从而无法达到较高的分类准确率。目前非均衡数据处理方法一般分为两类:一是数据层面,通过欠采样或过采样方法改变数据的原始分布,将非均衡数据转变为均衡数据;二是算法层面,通过改进分类器提高少数类样本的识别准确率。
从数据层面处理非均衡数据的方法是重构数据集,使非均衡数据趋向均衡,然后进行处理[8]。重构数据集的方法是重采样,有欠采样与过采样两种。
欠采样算法通过除去一部分多数类样本使其与少数类样本数量一致或相近来实现数据均衡。常见的欠采样算法有随机欠采样算法、Tomek links方法[9]、压缩最近邻规则、单边选择方法[10]、近邻清理方法[10-11]等。因为欠采样算法会除去部分样本,所以被除去样本的属性也会一并除去,因此会影响原始数据的分布进而影响分类器的性能。
过采样通过人为增加少数类样本使少数类样本数目与多数类样本数目一致或相近,从而达到数据均衡。常见的过采样方法有随机过采样、合成少数类过采样(Synthetic Minority Over-sampling Technique,SMOTE)[12]。ESTABROOKS A等[13]提出根据数据集情况自适应地选择重采样率的多重采样方法;TAEHO J等[14]提出根据聚类改进的同时能够处理非均衡数据类间问题和类内问题的采样方法;HAN Hui等[15]对SMOTE方法进行了改进,提出了仅对边界附近少数类样本进行过采样的Borderline-SMOTE过采样方法;HE Haibo等[16]提出性能优于SMOTE和随机过采样的自适应合成采样算法。由于过采样方法是增加样本数量,这有可能会造成样本重复,若样本特征较少则会导致过拟合。
从算法层面处理非均衡数据的方法是对数据集内不同类别的样本设置不同的特征权重,或改变算法的结构。目前使用较多的方法有集成学习算法、代价敏感算法等。
将多个弱分类器组合成1个强分类器,是集成方法中被广泛使用的技术。常见的集成学习方法有Bagging算法、Boosting算法以及随机森林(Random Forest,RF)算法等。AdaBoost算法是一种提高集成方法性能的算法,通过多次迭代,在每次迭代中修改正确分类样本与错误分类样本的权重来提高分类效果。SUN Yanmin等[17]改进了AdaBoost算法,提出了AdaC1算法、AdaC2算法以及AdaC3算法;CHAWLA N V等[18]结合AdaBoost与SMOTE两种算法,提出了提升泛化能力的SMOTEBoost算法; CHEN Chao等[19]改进了随机森林算法,提出了集数据均衡与分类为一体的平衡随机森林(Balanced Random Forest,BRF)算法。
此外,深度学习作为一种端到端的数据驱动方法,在处理数据非均衡问题方面也有着广泛的应用。SOHONY I等[20]采用神经网络集成算法处理类不均衡问题;KAZEMI Z等[21]提出使用深度自编码器从样本中提取特征,并使用Softmax网络进行样本分类以解决非均衡问题。上述方法虽能在一定程度上解决数据非均衡问题,但仍存在评价指标不完善、在极度不均衡数据集上表现较差的缺点。
综上所述,为解决轴向柱塞泵故障诊断中出现的正常数据与各类故障数据不均衡的问题,本研究将BRF算法应用于轴向柱塞泵故障诊断领域;通过与传统的SMOTE-RF算法、RF算法进行比较,验证了BRF算法处理类间数据不均衡条件下轴向柱塞泵故障诊断问题的优越性。
1 相关算法原理
1.1 SMOTE算法
SMOTE算法避免了随机过采样带来的过拟合风险,其并非复制现有的样本,而是生成人造样本,原理如图1所示,X为样本点,通过对随机选择的少数类样本及其相邻的少数类样本之间进行线性插值来实现样本生成。SMOTE执行3个步骤来生成合成样本:首先,选择1个随机的少数类样本a;在k个最近的少数类邻域中选择样本b;最后,在2个样本之间随机插值,得到新的样本,插值公式如下:
x=a+w(b-a)
(1)
式中,x—— 新生成的样本
w—— [0,1]之间的随机权重
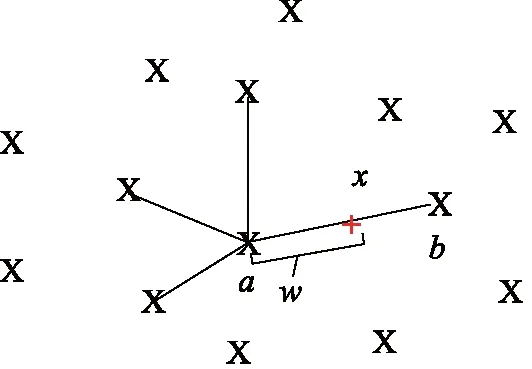
图1 SMOTE算法样本合成原理Fig.1 Sample synthesis principle of SMOTE algorithm
1.2 RF算法
RF算法是一种以决策树为基本分类器的集成算法。RF算法使用自助抽样,从原始样本中选取若干样本组成样本集,决策树对每个样本集进行建模,组合多个决策树的预测,并通过投票获得最终的预测结果[22],该算法的理论方法描述如下:
(1) 假设原始训练集中有N个样本,采用随机且有放回的自助抽样选取自助样本集,建立决策树,每次未选取的样本构成袋外(Out of Bag,OOB)数据;
(2) 假设属性总数为M,在每个决策树的每个节点上随机抽样提取m(远小于M)个属性,之后再采用某种策略(如信息增益等),从m个属性中选择一个最优属性作为分支和生长的分裂变量;
(3) 分割节点按照步骤(2)处理,每棵决策树都将生长置于修剪之上(即生长优先于修剪);
(4) 生成的多个决策树形成随机森林,新的数据通过随机森林分类器进行鉴别和分类,最终的分类结果通过简单的投票获得。
一般情况下,随机森林是由大量分类回归树(Classification and Regression Tree,CART)构建而成的,CART决策树以基尼系数为属性选择的标准。在理想状态下,随着节点不断分裂,决策树分支节点中的样本也应尽可能属于同一类[22],即保持节点的高“纯度”。假设当前数据集D中第k类样本所占的比例为pk(k=1,2,……,K),数据集D的纯度可以用式(2)来体现:
(2)
Gini(D)代表从数据集D中随机选取2个样本,其类别不相同的概率。Gini(D)越小,数据集的纯度越高。
设离散属性a有Y个可能的取值,A={a1,a2,a3,…,aY},使用A对数据集D进行划分,就会生成Y个分支节点,其中第i个分支节点囊括了D中所有在A上取值为ai的样本,记为Di。
属性a的基尼系数为:
(3)
式中,|D| —— 数据集D中样本的数量
|Di| —— 数据集D在第i个分支节点中的样本数量
在属性选择时,选择属性集合A中基尼系数最小的属性即可:
a*=arg min (Gini(D,A)),a*∈A
(4)
式中,a*—— 属性集合中基尼系数最小的属性。
在构建决策树时,对于每棵树(以第k棵树为例),大约1/3的样本不参与第k棵树的生成。这些样本是第k棵树的OOB样本。OOB样本可以估计训练集之外的样本的误差率,该误差被称为模型的推广误差。OOB误差是随机森林泛化误差的无偏估计,其结果类似于k折交叉验证。
RF算法可以根据OOB样本评估特征的重要性。对于随机森林模型,假设其1个属性变成1个随机数;这个属性在模型中的重要性是通过比较变化前后的OOB误差来评估的。属性重要性的度量被定义为平均递减精度(Mean Decreasing Accuracy,MDA)其表达式如下:
(5)
式中,Hn—— 改变特征后的OOB误差
Qo—— 改变特征前的OOB误差
Nt—— 决策树的数量
OOB误差下降程度越大,对应属性的重要性也越高。
将属性按重要性高低降序排列,再根据重要性剔除1个或多个属性,从而得到1个新的属性集。使用新的属性集重复上述步骤,直到剩余属性个数达到设定值。最后比较步骤中所得到的各个属性集对应的OOB误差率,选出OOB误差率最小的属性集,该属性集中属性的数量即为最佳决策树节点属性数量。
该算法在保持单棵树精度不变的前提下,通过引入随机性来降低决策树之间的相关性。因此,RF算法可以提高预测的准确性,而不会显著增加计算量。鉴于这种优异的性能,RF算法得到了广泛的应用。
1.3 BRF算法
在学习极不平衡的数据时,自助抽样很少甚至不会对少数类样本进行抽取,这就导致决策树在少数类的预测方面表现很差。改善这一问题的一个简单方法是使用分层自助抽样,即在每个类别中都进行抽样,但这种方法效果不佳。以往的研究表明,通过对多数类进行欠采样或对非多数类进行过采样来人为地使样本均衡,对于给定的性能度量来说,这种方法更有效,并且欠采样比过采样具有优势。BRF算法从平衡的欠采样数据中归纳出系统树, BRF算法的理论方法如下:
(1) 在每轮自助抽样中加入随机欠采样方法,从少数类中随机抽取若干样本,随后从多数类中随机抽取相同数量的样本组成均衡数据集,使用均衡数据集作为每次迭代的数据集;
(2) 在不修剪的情况下,从数据中归纳出最大规模的决策树,该树由CART算法归纳而成,并做出以下修改: 在每个节点上,不是搜索所有属性以获得最佳分裂变量,而是仅随机选取一个属性作为分裂变量;
(3) 重复上述步骤,生成的多棵决策树形成平衡随机森林,新的数据通过平衡随机森林分类器进行鉴别和分类,最终的分类结果通过简单的投票获得。
设非均衡数据集中各类别样本数量的比例为n1∶n2∶n3∶…∶nk。在RF算法的自助抽样中,少数类样本很少被纳入抽取范围,此时决策树中可能存在样本类别不全的现象;若使用分层自助抽样,则各类别样本的权重是默认相等的,即每轮自助抽样中从训练集抽取的各类别样本数量的比例趋近于n1∶n2∶n3∶…∶nk,此时每棵决策树中的重组数据集依旧是不均衡的。
BRF算法对此进行了优化,在自助抽样过程中添加了随机欠采样环节。随机欠采样可以在随机的条件下设定各类别样本的抽取数量,在自助抽样时既可以做到充分利用少数类样本,又能对样本数量较多的类别进行欠采样处理,使每棵决策树中不同类别样本的数量趋向均衡。
BRF算法的流程如下:首先,将原始数据集按照比例划分为训练集与测试集,测试集不做任何处理,对任意一决策树ti,都会使用随机欠采样方法从训练集中随机抽取(有放回抽取)与各少数类样本数量相近或相等的多数类样本,随后将抽取出的各多数类样本与少数类样本混合组成均衡数据集;在节点分裂时随机选取一个属性作为分裂变量,之后流程与RF算法相同,每棵决策树会对各自的均衡数据集进行分类并得出一个结果;当算法中的每棵树都产生结果之后,再根据bagging原则投票选出最理想的一个作为最终结果并生成模型,最后将测试集数据导入生成的模型中即可得出结果,BRF算法的流程图如图2所示。
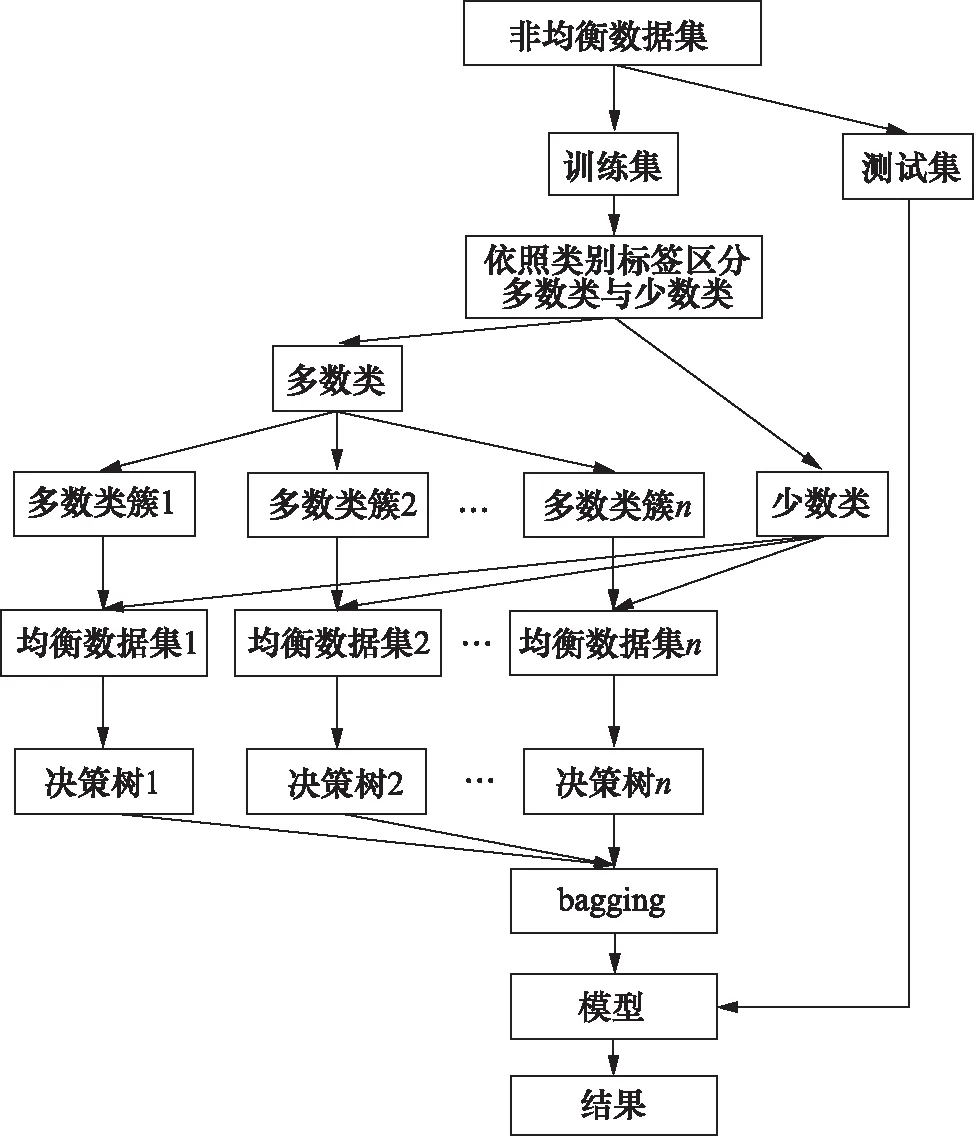
图2 BRF算法流程图Fig.2 Flow chart of BRF algorithm
2 BRF算法的性能研究
2.1 BRF算法参数选择
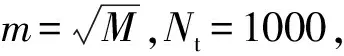
2.2 BRF算法性能评价指标
一般情况下,在分类结束后会出现如表1所示4种情况。通过混淆矩阵可以计算出一些评价指标,例如精确率、召回率、准确率等。对于非均衡数据,分类器在分类时大概率会将少数类划分为多数类,使用准确率作为评价标准不适用于非均衡数据分类。因此,引入G-mean,F-measure与精确率P共同作为评判指标。

表1 混淆矩阵Tab.1 Confusion matrix
G-mean结合了特异度和召回率,表示只有当分类器对样本中少数类和多数类的分类效果都很好的情况下,G-mean的值最大;F-measure 同时结合了精确率和召回率,是两者的加权调和平均,用于评价分类器对某一类样本分类性能的优劣,因此可用于测量分类器在少数类样本上的分类性能[24]。
G-mean与F-measure的计算公式如下:
(6)
(7)
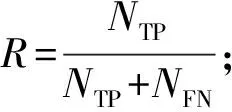
若是多分类问题,在计算时将所要计算的类别视为正类,其余类别视为负类,计算每个少数类的G-mean,F-measure与精确率,然后分别取平均值作为整个少数类的结果。
设非均衡数据集中有n类样本,其中类别1为多数类,其余类别为少数类。则少数类整体的G-mean,F-measure与少数类平均精确率计算方式如下:
(8)
(9)
(10)
式中,G2到Gn分别为类别2到类别n的G-mean值,Ga为少数类整体的G-mean值;F2到Fn分别为类别2到类别n的F-measure值,Fa为少数类整体的F-measure值;P2到Pn分别为类别2到类别n的精确率,Pa为少数类平均精确率。
2.3 BRF算法性能分析
为证明BRF算法的优势与泛化能力,先使用公开数据集对其进行验证。验证所选数据集为UCI开源数据集,4组数据集均为多分类非均衡数据,具体信息如表2所示。
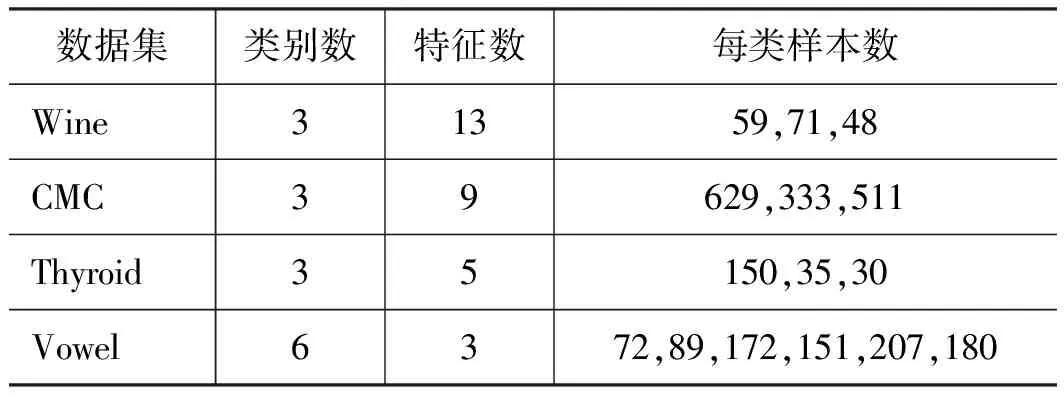
表2 所用数据集信息Tab.2 Datasets information used
数据集中样本数量最多的类别为多数类,其余类别为少数类。为保证结果准确,每个数据集都进行了10次计算,每次计算都会改变随机数种子以保证每次训练集与测试集都不相同,取10次结果的均值作为最终结果,分类结果如表3所示。
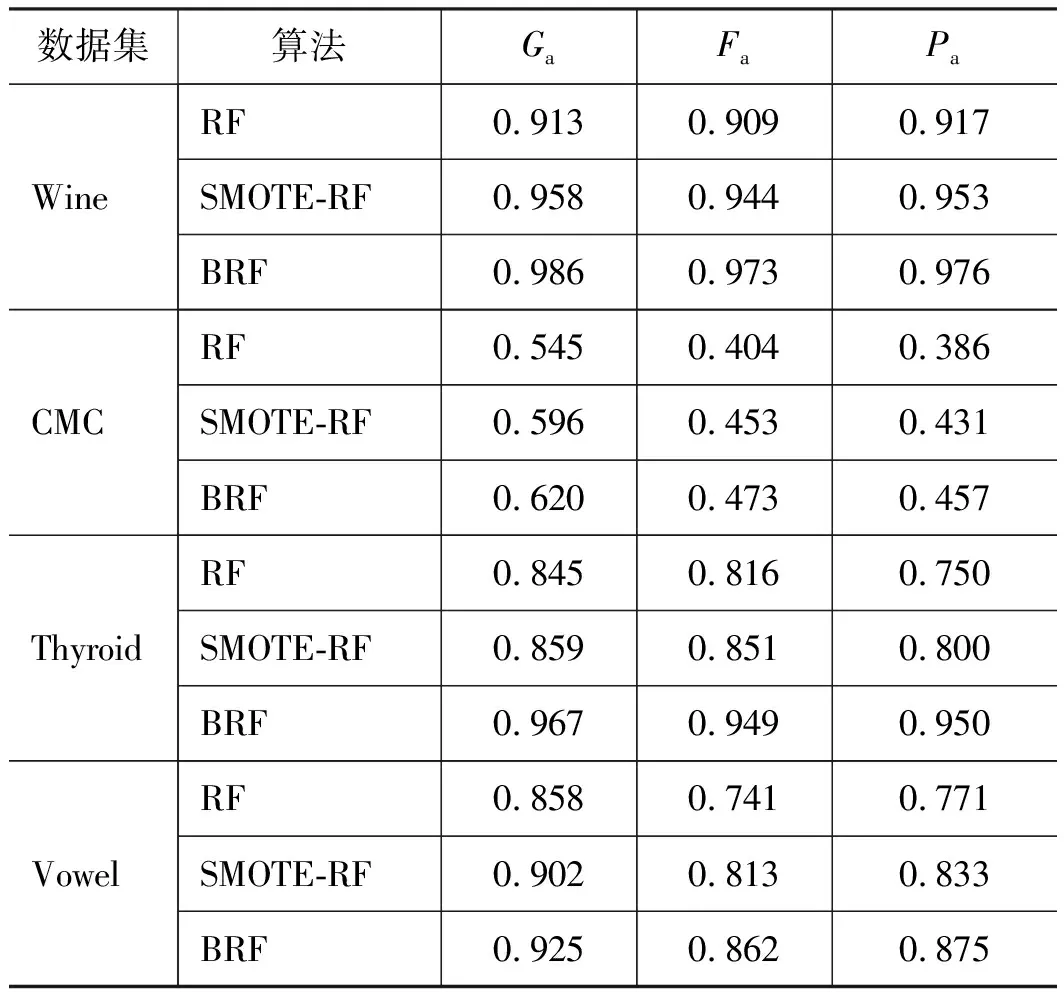
表3 各数据集分类结果Tab.3 Classification results of each dataset
由表3可知,在4种数据集中,BRF算法的Ga,Fa,Pa均高于RF算法和SMOTE-RF算法。
其中,Thyroid数据集不均衡程度最高,BRF算法的Pa,Ga,Fa相较于RF算法分别提升了20%,0.122,0.133;相较于SMOTE-RF算法分别提升了15%,0.108,0.098。
其次为Vowel数据集,BRF算法的Pa,Ga,Fa相较于RF算法分别提升了10.4%,0.067,0.121;相较于SMOTE-RF算法分别提升了4.2%,0.023,0.049。
在CMC数据集上,BRF算法的Pa,Ga,Fa,相较于RF算法分别提升了7.1%,0.075,0.069;相较于SMOTE-RF算法分别提升了2.6%,0.024,0.020。
Wine数据集不均衡程度最低,BRF算法的Pa,Ga,Fa相较于RF算法提升了5.9%,0.073,0.064;相较于SMOTE-RF算法分别提升了2.3%,0.028,0.029。
通过上述分析可得,数据集的不均衡程度越高,BRF算法对少数类的分类精确率提升越大。
3 基于BRF算法的轴向柱塞泵故障诊断
3.1 故障注入及故障数据采集
本研究采用硬件设备与软件程序相结合的方法采集实验数据。软件采用LabVIEW2018,以此来监控柱塞泵的工作状态,同时进行数据采集。实验系统原理如图3所示,柱塞泵振动信号采自液压泵故障模拟实验台,实验台照片如图4所示。

图3 实验系统原理图Fig.3 Schematic diagram of experimental system

图4 实验台照片Fig.4 Experimental bench photo
液压泵为MCY14-1B型斜盘式轴向柱塞泵,柱塞数目为7,理论排量10 mL/r,额定工作压力31.5 MPa;电机型号为Y132M-4,额定转速为1480 r/min;加速度传感型号为YD72D,频率范围1~18 kHz。对液压泵端盖的振动信号进行采集,试验时调定主溢流阀将系统压力设置为5 MPa,采样频率设为10 kHz,每次采样时长为10 s。
试验共模拟4类故障,分别为滑靴磨损、松靴、斜盘磨损、中心弹簧磨损。故障是使用故障元件代替正常元件注入的,故障元件是从液压泵维修单位收集的磨损废弃元件。数据采集结束后对原始振动信号进行小波包能量特征提取,小波包函数选用db5小波,分解层数为4,由16个子频带能量占比作为特征组成特征向量。各子频带B的频率范围如表4所示,故障元件照片与各类别子带能量谱分别如图5、图6所示。

表4 子频带及频率范围Tab.4 Sub-band and frequency range Hz

图5 故障元件照片Fig.5 Faulty component photos
图6中能量占比与子频带分别用PE与B表示,且二者均无量纲。由图6可知,5种状态下各子频带的能量占比区分度大,差异明显,使用小波包能量特征提取方法能够清晰有效地将5种状态进行区分。
选取不同状态的柱塞泵端盖的振动信号,经小波包能量特征提取后制作成数据集。数据类别包括正常、滑靴磨损、松靴、斜盘磨损、中心弹簧磨损。所得到的轴向柱塞泵故障数据集如表5所示,正常类/单个故障类比例为20∶1。
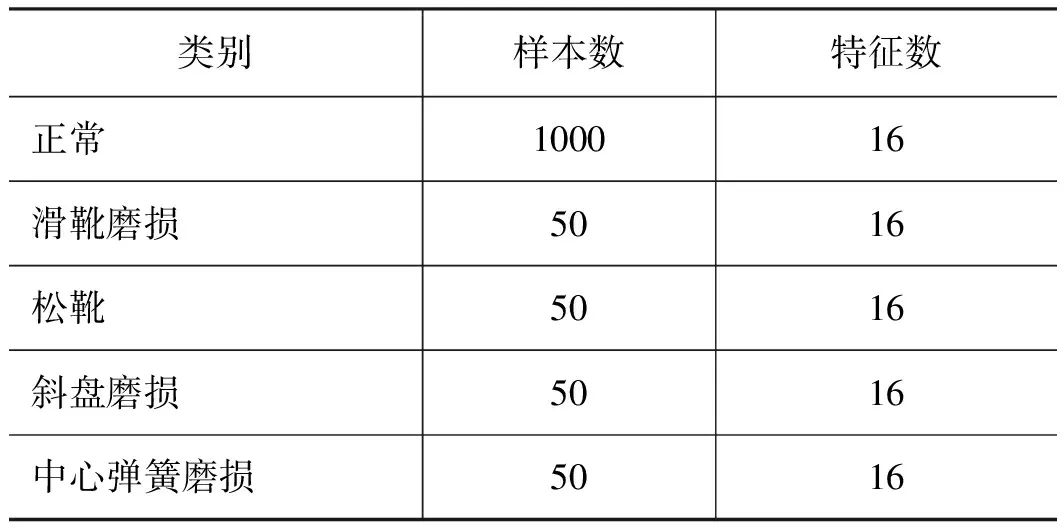
表5 轴向柱塞泵故障数据集Tab.5 Axial piston pump failure dataset

图6 各状态类别下的子带能量谱Fig.6 Sub-band energy spectrum of each state category
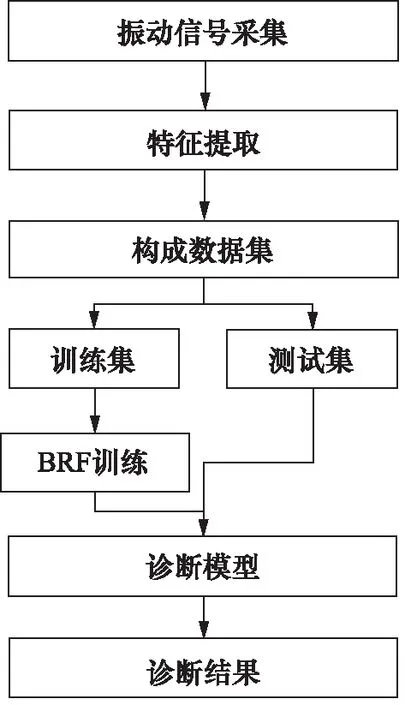
图7 基于BRF的轴向柱塞泵故障诊断流程图Fig.7 Fault diagnosis flowchart of axial piston pump based on BRF
完整的基于BRF的轴向柱塞泵故障诊断流程图如图7所示。
3.2 基于BRF的轴向柱塞泵故障诊断及结果分析
划分轴向柱塞泵数据集时,设置训练集与测试集比例为7∶3,设置轴向柱塞泵数据集中属性总数M为16,RF算法与SMOTE-RF算法中的参数m为4,Nt为1000;BRF算法中Nt为1000。
数据集中正常样本为多数类样本,滑靴磨损、松靴、斜盘磨损、中心弹簧磨损的样本为少数类样本。为使结果准确,进行10次计算并对结果进行平均。每次计算时都设置不同的随机数种子,以确保每次的训练集与测试集都不相同,取均值作为最终结果,诊断结果如表6所示,表中7项评价指标均无量纲。
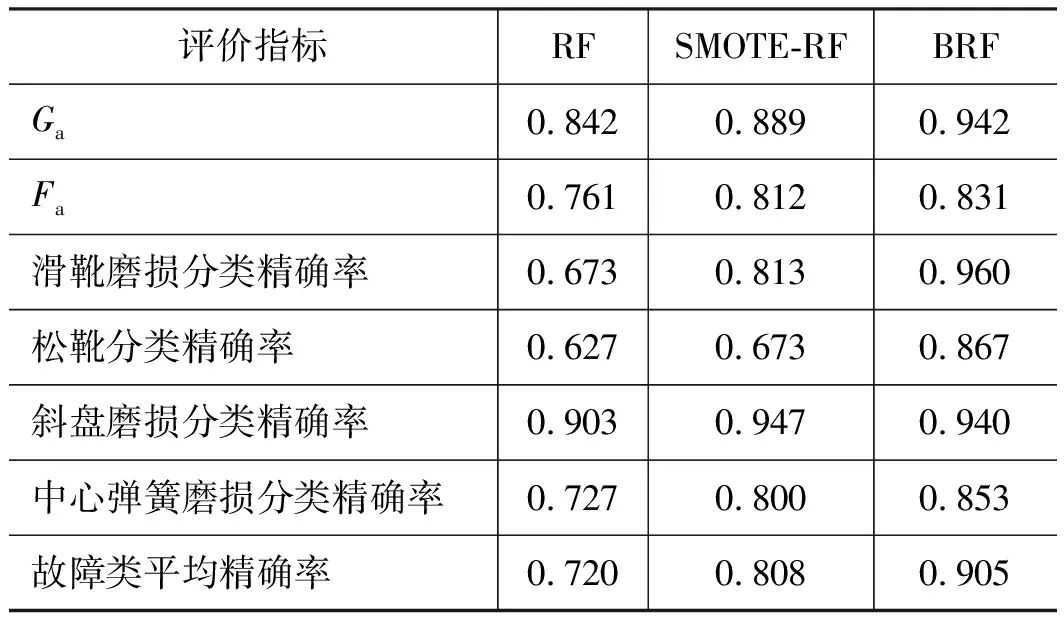
表6 轴向柱塞泵故障数据集的诊断结果Tab.6 Diagnosis results of axial piston pump fault dataset
由表6可知,BRF算法的滑靴磨损、松靴、中心弹簧磨损的分类精确率相较于RF算法、SOMTE-RF算法有着较大的提升,BRF算法对斜盘磨损的分类精确率虽不是最高,但也达到了0.94,仅比SMOTE-RF算法低0.7%,说明BRF算法的整体性能优于RF和SMOTE-RF算法。
在非均衡问题中,不均衡程度没有明确的度量标准。通常当数据集中不同类别样本的比例超过5∶1时[8],数据不均衡所带来的问题就会凸显出来。
为进一步分析BRF的性能,将正常类/单个故障类比例分别调整至15∶1,10∶1,5∶1,随后再次使用3种算法进行计算。3种算法在不同不均衡比例下的Ga,Fa,Pa如图8所示,图中结果皆为10次计算结果的均值。
图8为3种算法在不同不均衡比例下的性能,其中横坐标pns为正常类/单个故障类的比例。
由图8可得,在4种不均衡比例下BRF算法的性能均优于RF算法和SMOTE-RF算法。BRF的Ga,Fa,Pa始终高于其他2种算法,在比例为20∶1时提升最大,相比于RF算法分别提升了0.10,0.07,18.5%,相比于SMOTE-RF算法分别提升了0.053,0.019,9.7%。
4 结论
将BRF算法引入轴向柱塞泵故障诊断领域,提出了在类间数据不均衡条件下基于BRF的轴向柱塞泵故障诊断方法:
(1) 利用开源UCI数据对BRF,RF,SMOTE-RF 3种算法的性能进行了比较,结果表明BRF算法的Ga,Fa,Pa均高于其他2种算法,且在非均衡程度最高的数据集上性能提升最大;
(2) 对轴向柱塞泵不同类型故障进行模拟,采集了正常、滑靴磨损、松靴、斜盘磨损、中心弹簧磨损5种状态的数据,使用上述3种算法在不同的不均衡比例下进行对比分析,结果表明,BRF算法性能始终优于RF算法与SMOTE-RF算法,并且在数据不均衡比例最高时BRF的性能提升最大,满足实际需要;
(3) 对于类间数据不均衡的轴向柱塞泵故障诊断问题,BRF能够在符合实际(即数据处于高度不均衡状态)的前提下有效提升故障类的分类性能,该方法在处理类间数据不均衡的轴向柱塞泵故障分类问题方面相较于传统分类算法具有明显优势。

图8 3种算法在不同不均衡比例下的Ga,Fa,PaFig.8 Ga, Fa, Pa for three algorithms under different imbalance ratios
