深度可分离卷积和标准卷积相结合的高效行人检测器
2022-05-09张运波易鹏飞周东生魏小鹏
张运波,易鹏飞,周东生,,张 强,,魏小鹏
深度可分离卷积和标准卷积相结合的高效行人检测器
张运波1,易鹏飞1,周东生1,2,张 强1,2,魏小鹏2
(1.大连大学软件工程学院先进设计与智能计算省部共建教育部重点实验室,辽宁 大连 116622;2.大连理工大学计算机科学与技术学院,辽宁 大连 116024)
行人检测器对算法的速度和精确度有很高的要求。虽然基于深度卷积神经网络(DCNN)的行人检测器具有较高的检测精度,但是这类检测器对硬件设备的计算能力要求较高,因此,这类行人检测器无法很好地部署到诸如移动设备、嵌入式设备和自动驾驶系统等轻量化系统中。基于此,提出了一种更好地平衡速度和精度的轻量级行人检测器(EPDNet)。首先,主干网络的浅层卷积使用深度可分离卷积以压缩模型的参数量,深层卷积使用标准卷积以提取高级语义特征。另外,为了进一步提高模型的性能,主干网络采用特征融合方法来增强其输出特征的表达能力。通过实验对比分析,EPDNet在2个具有挑战性的行人数据集Caltech和CityPersons上表现出了优越的性能,与基准模型相比,EPDNet在速度和精确度之间获得了更好的权衡,EPDNet的速度和精确度同时得到了提高。
标准卷积;深度可分离卷积;特征融合;轻量化;行人检测
行人检测在诸如自动驾驶、智能监控和机器人等计算机视觉应用中,扮演着举足轻重的作用。随着深度学习的兴起,尽管近年来的一些行人检测算法已获得了显著成效[1-2],但最先进的行人检测器仍然达不到人类的认知水平[3],在行人遮挡、模糊、尺度多变等具有挑战性的情况下,其检测效果通常会受到严重影响。为了解决这些问题,诸多研究学者已经提出了处理特定情况的机制。这些机制包括在检测之前使用分割[4]和分别为不同的行人遮挡模式设计对应的模型[5-6]等。CAO等[7]提出了位置指导和语义转换2个模块,以提取对象更多的上下文信息。但是,上述方法的检测速度较慢,并且与实时检测目标相距甚远。文献[6]提出的Faster-RCNN+ATT检测器,利用通道注意力模块加强算法对遮挡行人的检测性能,但需要添加额外的模块才能从数据集中获取注意力信息,计算复杂度较高。文献[2]提出了行人检测和语义分割进行联合监督的框架——SDS-RCNN,但是仅添加了语义分割分支,并将获得的语义特征输入到主干网络中,而未将语义分割结果直接用于行人检测。LIU等[8]提出了差分矩阵投影(difference matrix projection,DMP),使用全局矩阵运算计算聚合的多方向像素差异。上述的两阶段行人检测器主要致力于检测精度的研究。重要的是,行人检测对速度的要求也是很高的。与两阶段行人检测器相比,单阶段检测器具有更高的检测速度[9-10]。单阶段行人检测器通常使用轻量级的卷积神经网络(convolutional neural networks,CNN)作为主干网络,例如MobileNet[11]和YOLOv3[12]。ZHAO等[13]提出了一种行人检测的新思路,即利用人体姿态估计来提高行人检测的检测和定位精度。实际上,缺乏多样化的行人数据集也限制了行人检测器的性能,ZHANG等[14]提出了一个具有丰富场景的高分辨率行人数据集,可以在一定程度上提高模型的泛化能力。为了进一步促进未来的行人检测研究,其团队发布了一个名为WiderPerson[15]的大规模多样化数据集,用于野外环境下的密集行人检测。虽检测速度快,但是检测精度不高,无法在速度和精度之间取得更好的折衷。LIU等[16]提出一种无锚点框的行人检测新方法,即利用行人的关键点和尺度获得回归框,在速度和精度之间取得了新的权衡。但是,在这项工作中,使用MobileNet作为主干网络时,行人检测器的检测精度较低。
本文针对使用关键点与轻量级主干网络相结合对行人检测时精度较低的问题,提出了一种基于标准卷积和深度可分离卷积相结合的主干网络构造方法。其主要思想是在模型的浅层使用深度可分离卷积来压缩DCNN模型的参数,在模型的深层采用标准卷积以增强特征的语义表达能力。为了进一步提高轻量级行人检测器(effective pedestrian detector network,EPDNet)的检测精度,本文采用特征融合方法将浅层和深层特征融合在一起,以增强输出特征的语义表达能力。另外,基于所设计的主干网络,在Caltech[17]和CityPersons[14]2个行人数据集上评估了EPDNet的性能。评估过程主要包括消融实验和基准模型比较实验。与基准模型相比,EPDNet在保持更快的检测速度同时,在Caltech和CityPersons数据集上均实现了更高的检测精度。
1 相关工作
1.1 有锚点框检测
目前,大多数高性能行人检测器主要由主干网络和特定的检测头组成。早期的目标检测算法主要使用CNN作为主干网络,例如VGG[18]和ResNet[19]。Faster R-CNN[20]是两阶段目标检测框架,该算法的主干网络使用ResNet50。RPN+BF[21]采用了区域建议网络——RPN,并通过人工对这些建议框进行了重新评分,研究团队对Faster R-CNN在行人检测中的效果做出了相应的研究和改进。TESEMA等[22]提出了一种新的行人检测框架,成功地扩展了RPN + BF框架,将手动提取的特征和CNN提取的特征相结合。文献[21]工作成为了两阶段行人检测器的先例。例如,在LI等[23]的工作中,基于CNN的两阶段框架在小尺度行人检测方面取得了重大进展;在MS-CNN[24]中也应用了Faster R-CNN框架,但是该算法是在多尺度特征图上生成候选建议框;Faster RCNN+ATT[6]的作者建议采用通道注意力模块来处理行人检测的遮挡问题;上述方法在基于CNN的有锚点框行人检测方向获得了重要进展,充分证明了CNN在两阶段行人检测器中的有效性和可行性。
1.2 无锚点框检测
与有锚点框目标检测器的设计思路相反,近年来流行采用无锚点框进行目标检测,该方法摒弃了候选建议框的生成过程,直接从图像中检测目标。CornerNet[25]是将无锚点框检测思想推向高潮的杰作,其摒弃了传统的目标检测思想,直接从图像中检测出目标的左上角和右下角关键点,根据这一对关键点确定目标框。受无锚点检测思想的启发,SONG等[26]将此思想引入了行人检测之中,提出的拓扑线性定位(topological line localization,TLL)算法大幅提高了行人检测的性能,尤其是在小尺度行人检测方面的成效尤为突出。此后,文献[16]提出通过直接检测行人的中心点和尺度来对图像中的特征进行分类和回归。该方法将行人检测转换为分类和回归2类问题,并在Caltech数据集上获得了先进的检测性能,为行人检测提供了新思路。为了设计更为轻量的行人检测器,文献[16]还使用MobileNet[11]作为主干网络,并设计了一种检测速度更快的行人检测模型。
本文工作主要是基于无锚点框的行人检测,但与上述所有方法均有显著差异。本文尝试通过设计高效、轻量的主干网络来压缩行人检测器的参数,以获得更快、更准确的行人检测器。EPDNet提供了一种基于标准卷积和深度可分离卷积构建主干网络和特征融合方法。
2 方 法
2.1 整体框架
EPDNet的总体框架如图1所示,总体架构主要由主干网络和检测头模块组成。
2.1.1 主干网络
主干网络主要负责图像特征提取,是深度可分离卷积块和深度残差块的组合。该设计将整个主干网络分为6个阶段进行描述。首先,将原始图像输入到步长为2的卷积块中,对原始图像进行下采样,滤波器数量为32,将3通道的RGB图像提取成具有32通道的特征图。为了减少模型的计算量,第2到第4阶段采用深度可分离卷积的卷积方法,这是整个检测器模型轻量化的关键。为了提取图像的高级语义信息并提高模型的可训练性,该网络结合了深度残差网络的优点和原理,在第5和第6阶段使用残差块,以提高分类精度。从第1阶段到第6阶段,下采样率分别为2,4,8,16,16和16。在加深模型深度的同时,考虑到分辨率对行人目标定位的重要性,最终输出特征图的分辨率为原始特征图的1/16。
2.1.2 检测头
检测头模块负责目标检测中特征的分类和回归,在检测任务中起着重要的作用[27]。首先,将主干网络提取的特征图输入到一个滤波器个数为256的卷积层,将特征图的特征维度压缩为256,然后将压缩后的特征图输入到3个卷积层预测分支中,分别生成中心点特征图、尺度图和中心点偏置。特征图的下采样过程将引起关键点偏移的问题,不利于行人的定位。增加偏移量的预测分支可以微调下采样过程中的中心位置预测精度的损失,中心点的偏移量预测可以定义为
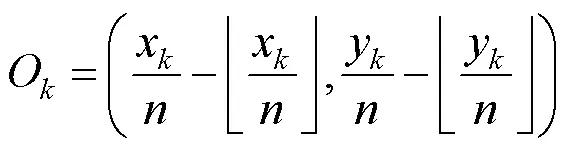
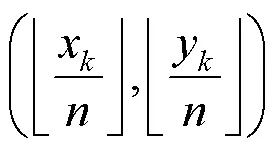
2.2 整体架构
表1给出了EPDNet的详细信息,包括卷积块的类型(Type)、步长(Stride)、滤波器个数(Filter Shape)和输入图像大小(Input size)。例如,Conv/s2表示标准卷积块,卷积核移动步长为2。深度可分离卷积是将标准卷积分解为深度卷积(Conv dw/s1)和点卷积(Conv/s1)。Conv_block Res/s1表示步长为1的卷积块,Identity_block Res/s1表示恒等块。
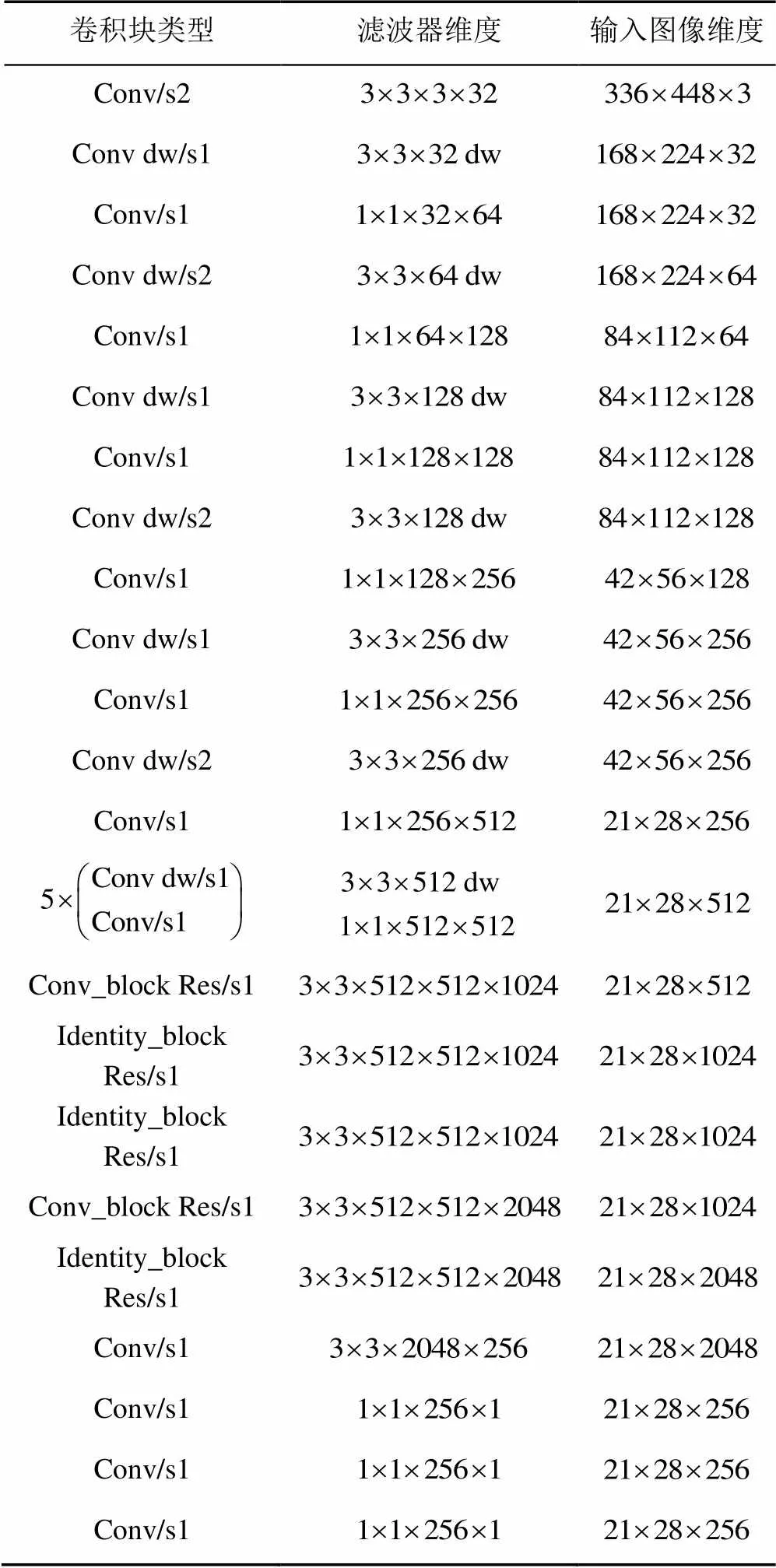
表1 EPDNet主干的架构
3 实 验
3.1 实验设置
3.1.1 数据集
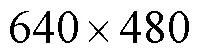
CityPersons数据集源自Cityscapes[28],具有多个遮挡级别的行人注释。本文实验使用2 975张图像的训练集和500张图像的测试集。评估指标遵循Caltech中的评估标准[17],即在[10-2, 100]范围内,每幅图像平均误报率的对数值(false positive per image,FPPI)表示为-2,数值越小表示性能越好。
3.1.2 训练参数
本文实验在Keras框架中实现的。训练和测试在单个GTX 1080Ti GPU显卡上进行。主干网络使用基于深度可分离卷积和深度残差网络设计。当使用Caltech数据集训练模型时,批量设置为16,学习率为10-4。训练过程中加载MobileNet的预训练权重[11],网络训练在200代后停止。Caltech数据集上的训练模型还包括从CityPersons数据集初始化的模型。此外,当使用CityPersons数据集训练模型时,批量大小(batch_size)设置为3,学习率为2×10-4,在训练过程中加载MobileNet的预训练权重,并且训练150代后停止训练。
3.2 消融实验
消融实验在Caltech数据集上进行,并将阈值设置为官方标准,即IoU=0.5。本文从4个方面展开实验和讨论:①结合深度可分离卷积和标准卷积的重要性;②可分离卷积输出特征与残差块输出特征融合的重要性;③模型的卷积层数和特征尺度对模型性能的影响;④深度卷积层使用空洞卷积的对模型性能的影响。
3.2.1 结合深度可分离卷积和标准卷积的重要性
本文提出的主干网络分为深度可分离卷积和标准卷积2部分。深度可分离卷积可以成倍地压缩模型参数,残差网络可以增加模型的可训练性。通过增加模型的深度,可以提取图像的高级语义特征。结合两者的优势,构建了轻量级的主干网络,并且进一步设计的行人检测器可以提高速度和精度。这组实验证明了深度可分离卷积和标准卷积相结合的模型压缩方法的有效性。实验结果见表2。
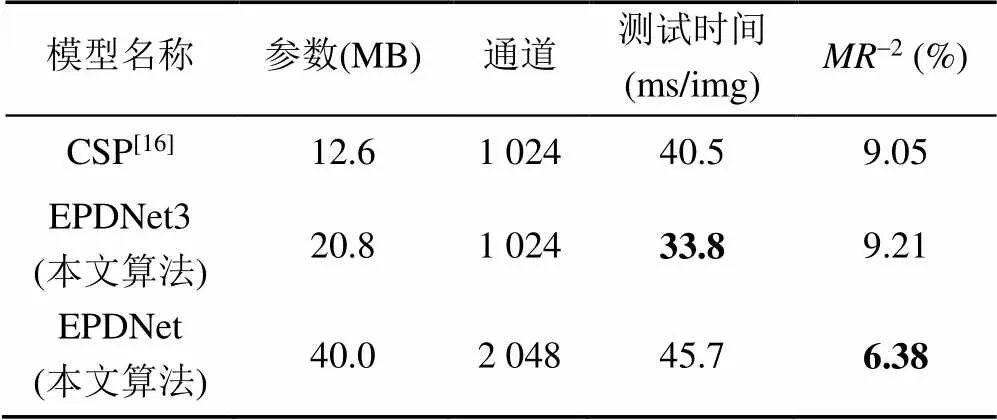
表2 不同检测器的比较
注:加粗数据为最优值
表2展示了不同检测器之间的性能对比结果。CSP[16]使用MobileNet作为主干网络的模型。EPDNet是本文设计的行人检测器模型,其融合了第3到第6阶段的输出特征图。EPDNet3使用残差块将输出特征图扩展到1 024维,并融合了第3到第5阶段的输出特征图,融合后的特征图作为主干网的最终输出。通过与CSP比较,可以发现EPDNet3模型的检测速度提高了约16%,而检测精度仅仅下降了1.8%,由此可知,在确保检测精度的同时,EPDNet3在检测速度上有了显著提高。
3.2.2 特征融合的重要性
为了分析EPDNet融合的有效,及证明融合高级与低级特征图的重要性,本文做了对比实验,整个实验集均在Caltech数据集上进行,并且将阈值设置为官方标准IoU=0.5。实验结果见表3,其中2~6分别表示第2到第6阶段的输出特征图。
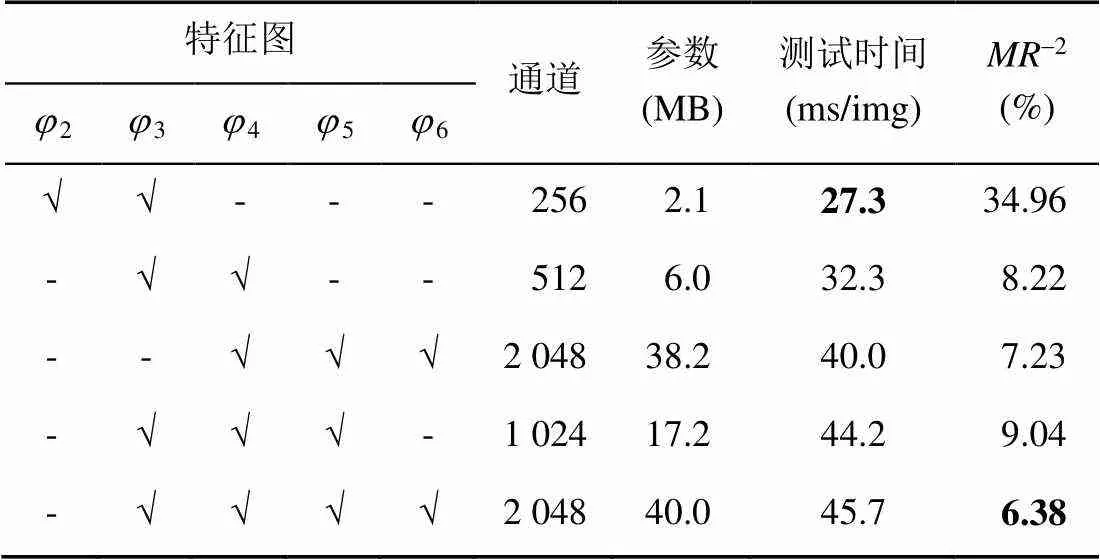
表3 融合不同特征图的模型对比
注:加粗数据为最优值
由表3可看出,融合不同阶段输出特征图的模型在检测时间和准确性上存在很大差异。融合了3,4,5和6阶段的特征图的模型具有6.38-2。此模型具有最佳的检测精度。尽管该模型在检测速度上没有优势,但仍然可以达到约22 FPS。此外,融合了2和3阶段特征图的模型具有最快的检测速度(约40 FPS)和最小的参数,但是该模型的检测精度非常低。因此可以看出,浅层模型具有较高的检测速度,但代价是检测精度的损失,这种模型不适合处理背景复杂的高分辨率图像,也不适合处理复杂的检测任务。
3.2.3 卷积层数和特征图维度的影响
在图1所示的主干网络中,除下采样层外,第4阶段的可分离卷积块数为4,5和6。另外,卷积层数和输出特征图维度也对模型的性能有很大影响。为了讨论第4阶段中卷积层数对模型性能的影响,本文通过对比实验展示不同模型的性能,包括模型参数量、测试时间和损失率的比较。整个实验是在IoU=0.5的条件下进行。实验结果见表4。
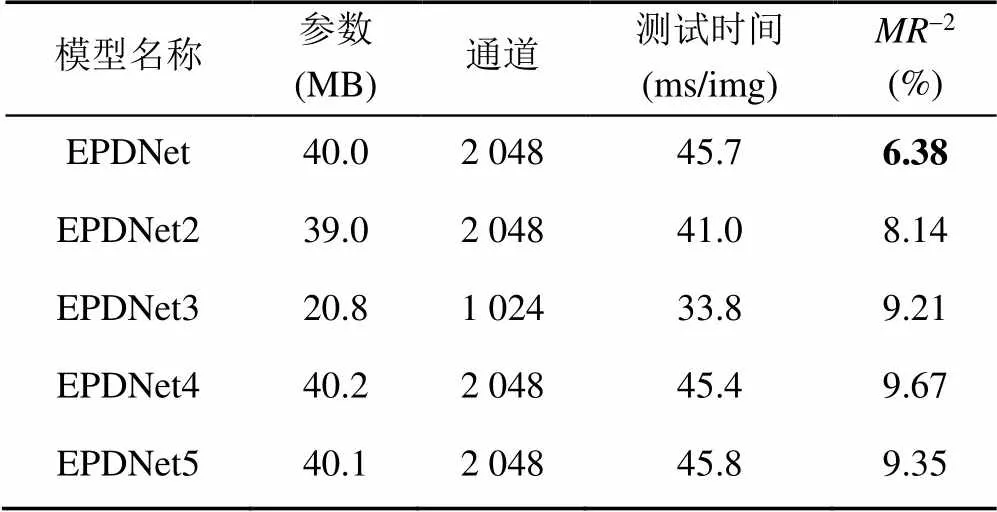
表4 不同卷积层数的模型性能对比
注:加粗数据为最优值
由表4数据可知,对于输出特征图维度相同的可分离卷积层,卷积层数较多的模型具有更好的检测精度,但是该类模型在检测时间上略高于卷积层数少的模型。其中,在EPDNet的第4阶段中设6个深度可分离的卷积块,主干网通道维数为2 048。EPDNet2在EPDNet的基础上将4阶段的卷积块数减少到3个,EPDNet4在EPDNet的基础上将第4阶段的卷积块数减少到4个,EPDNet5在第4阶段的基础上将卷积块的数量减少到5个。EPDNet3是在EPDNet的基础上将主干网络的特征输出维度减少到1 024。实验结果表明,无论是减少标准卷积的层数还是可分离卷积的层数,浅层网络都会导致模型检测的准确性下降。但是,与EPDNet相比,简化后的模型提高了检测速度,EPDNet2将模型的检测速度提高了约10%,但损失了约28%的精度。EPDNet3将模型速度提高约26%,但损失了约44%的精度。与EPDNet,EPDNet3,EPDNet4和EPDNet5相比,EPDNet具有最佳性能。因此,可以看出,过度压缩模型参数以提高算法的效率是不可取的。只有合适的卷积层数和特征图维度才能达到最优的性能。
3.2.4 空洞卷积对模型性能的影响
扩大卷积核的感受野对检测任务是有帮助的。但是,通过增加卷积层数来增加感受野的做法,不可避免地会增加模型的参数量,导致模型的计算效率下降。另外一种扩大感受野的方法是使用空洞卷积,该方法不会增加参数量。本组实验比较了使用空洞卷积与否的模型的性能,对比结果包括模型参数、测试时间和丢失率。整个实验均在IoU=0.5的条件下进行,实验结果见表5。
注:加粗数据为最优值
由表5可知,在第5和第6阶段中的卷积层使用空洞卷积。从实验结果可以看出,在其他条件不变的情况下,不使用空洞卷积模型的精度会大大降低。由于感受野变小,计算量增大,因此模型测试时间也稍微变长。从本组实验可以看出,在必要的卷积层中引入空洞卷积可以有效提高模型精度。
3.3 基线模型对比试验
本文将在Caltech和CityPersons数据集上,对比EPDNet模型与其他行人检测器模型之间的性能。在本文实验中,EPDNet和EPDNet+City分别表示初始化权重来自ImageNet[29]和CityPersons数据集上训练的模型。
3.3.1 Caltech数据集上对比结果
本组实验对比了基线模型的性能参数,在几个检测精度相当的行人检测器模型中,对比模型的检测速度。本文方法与几种基准模型进行对比,包括DeepParts[30],MS-CNN[24],FasterRCN+ATT[6],SA-FasterRCNN[31],RPN+BF[21],SDS-RCNN[2],EPDNet1 (本文算法),EPDNet (本文算法),EPDNet+City (本文算法)和CSP[16]。分别在IoU=0.5和IoU=0.75时进行了比较,FPPI曲线分别如图2和图3所示。
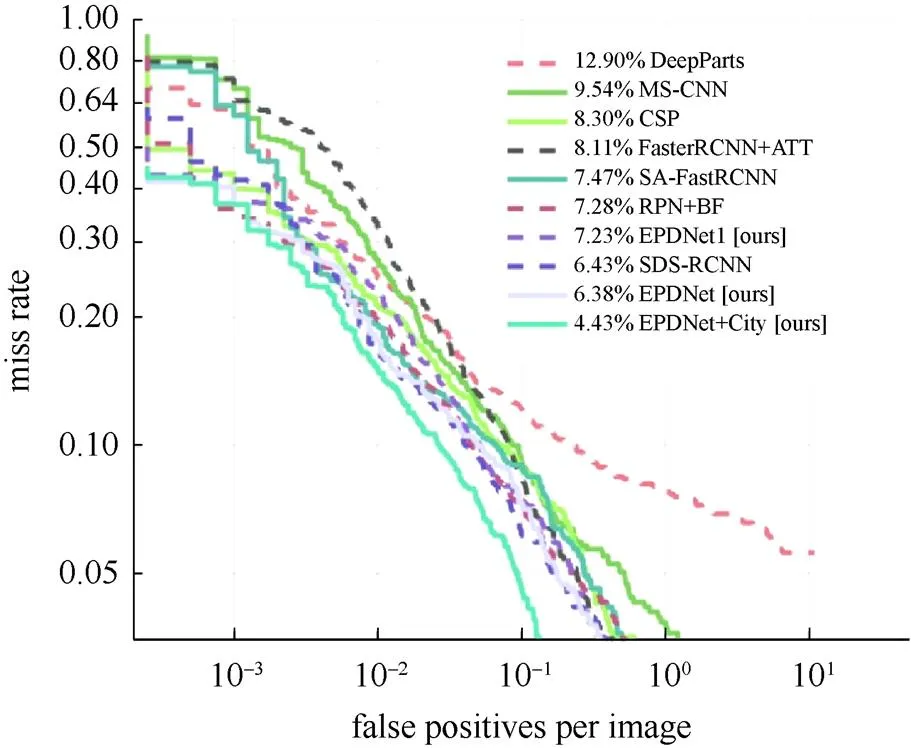
图2 IoU=0.5时,Caltech数据集上的比较
图2显示了当IoU=0.5时各个模型的FPPI曲线。从图中可以看出,EPDNet模型在基准模型中具有更好的准确性。从检测精度比较可见,EPDNet1和RPN + BF的检测结果相当。与CSP相比,EPDNet的检测精度提高了2个百分点;与DeepParts相比,EPDNet的检测精度提高了6.52个百分点,性能提高了约50%。如图3所示,当IoU=0.75时,EPDNet显示的检测结果也明显要好于基准模型。
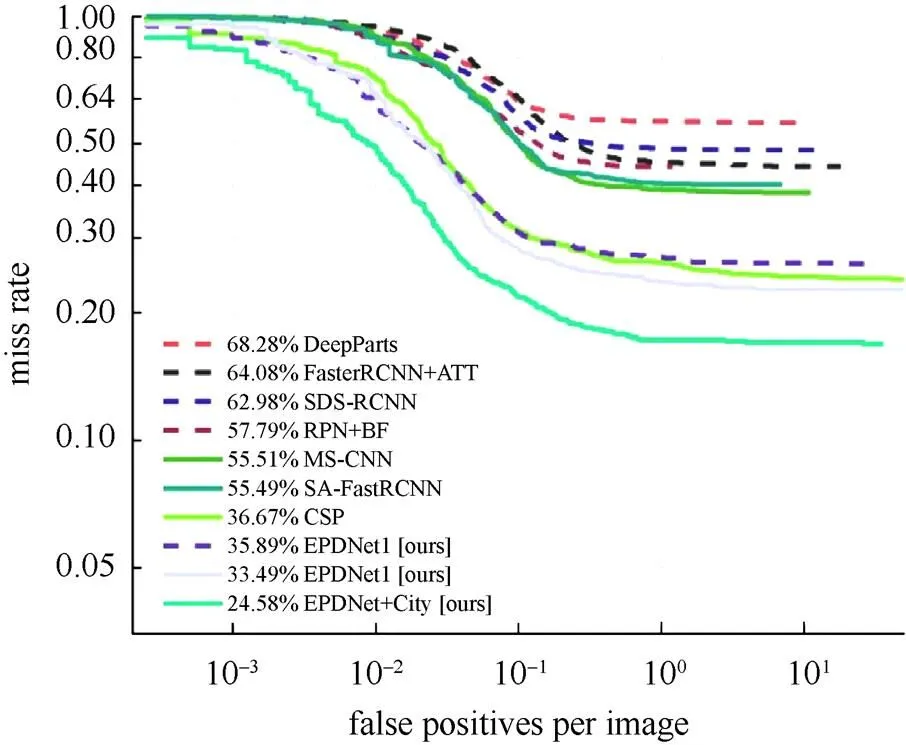
图3 IoU=0.75时,Caltech的数据集上的比较
为了更详细地对比模型的运行速度,在表6中报告了包括模型训练和测试的硬件设备、测试时间和丢失率。对比分析发现,CSP1达到了最好的检测速度,但是其丢失率为8.33%,排名比较靠后。与CSP2相比,EPDNet1在速度和精度上均占有优势,在检测精度上提高了20个百分点。EPDNet也在保持检测速度的同时,达到了新的精度。使用CityPersons数据集训练的模型EPDNet+ City在2个阈值下均达到了最好的检测结果,分别为4.43%和23.32%,性能均较之前模型有大幅度地提升。综合来看,EPDNet在各个方面的性能均超过了其他的两阶段检测器。通过对比实验,使用可分离卷积和标准卷积相结合的思想,能够更好地对模型进行优化,是目前平衡速度与精度的一种有效方法。
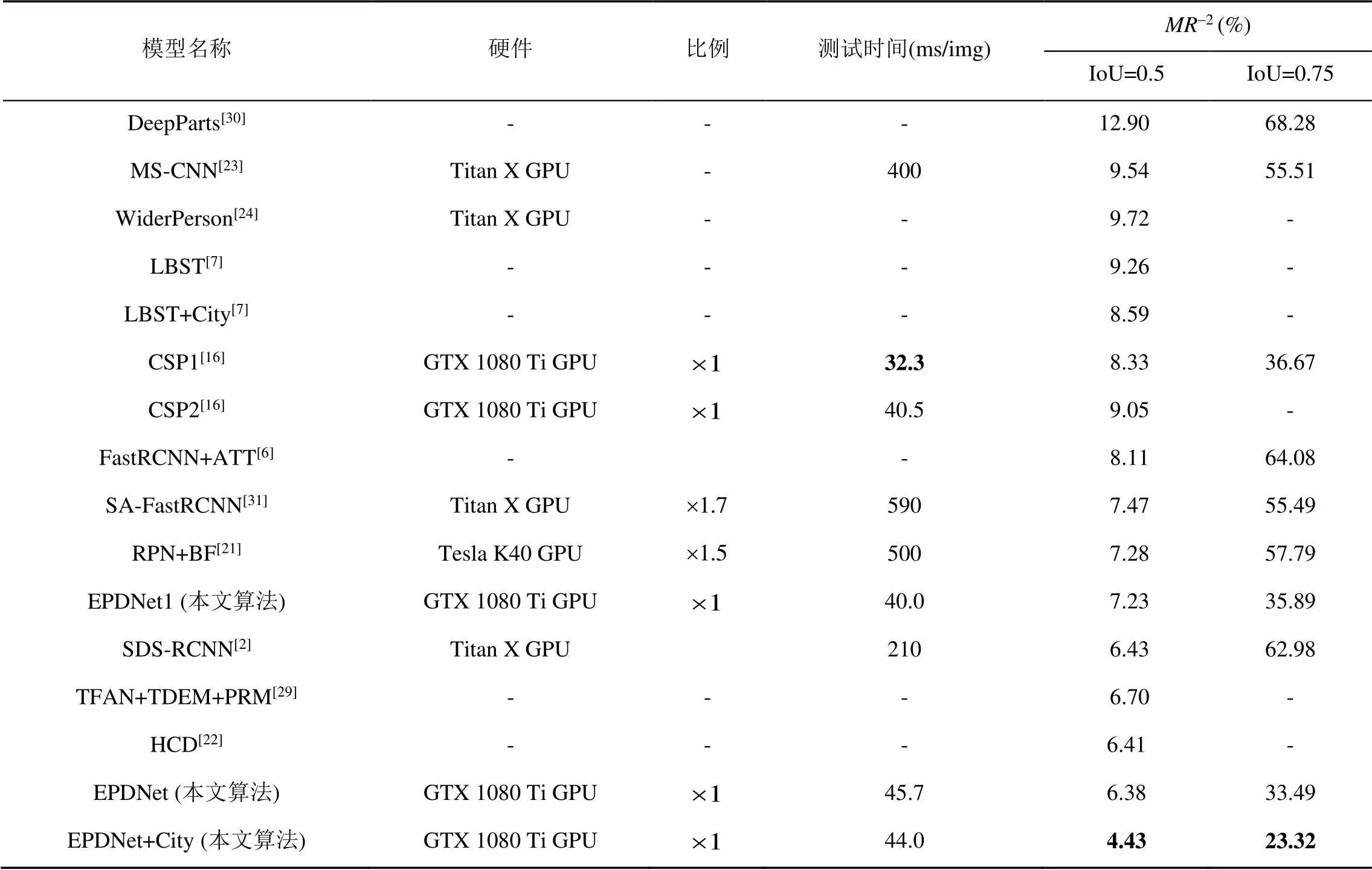
表6 Caltech数据集上检测器性能对比
注:加粗数据为最优值
3.3.2 CityPersons数据集上对比结果
本文实验展示了EPDNet和基准模型在CityPersons数据集上的性能对比结果。对于CityPersons数据集的训练,本文实验采用单张GTX 1080Ti型号的GPU进行,批量设置为3。表7数据显示EPDNet在CityPersons的数据集上,获得了12.6%的检测丢失率和288 ms/img的检测速度,在大分辨率图片的检测速度中具有突出的优势。在部分遮挡子集上,EPDNet相比基线模型在精度方面提高的更多,相比于TLL(MRF)模型提高超过3个百分点。特别是在无遮挡子集上,EPDNet达到了8.37%的-2。从严重遮挡子集上的检测结果看,EPDNet在高遮挡的数据集上的性能仍然有待提高。受限于现阶段计算机硬件设备的性能,对于大分辨率图像的处理只能设置较小的批量。以计算机硬件的发展趋势看,未来硬件设备能够满足大分辨率图像的处理需求,设置更大的批量,可以进一步提高模型的精度。

表7 CityPersons数据集上检测器性能对比
注:加粗数据为最优值
4 结论及展望
本文通过对行人检测实时性能的研究,提出了一种深度可分卷积和标准卷积相结合的方法,并设计了深度卷积神经网络模型作为主干网络来提取图像特征,然后结合无锚点框的检测思想,将主干网络提取的特征图直接输入到检测头中,直接对特征进行分类和回归。此外,为了增强特征图的表达能力,本文通过特征融合方法,将2种卷积方式提取的特征图进行了融合,以进一步提高模型的性能。实验结果表明,结合标准卷积和深度可分离卷积可有效提高模型的性能;不同阶段的特征图融合可以进一步提高网络性能。
在未来的工作中,将致力于进一步研究轻量化模型的构建方法,获取更为高效的行人检测器模型,在检测精度和检测速度方面达到新的权衡。
[1] 陈宁, 李梦璐, 袁皓, 等. 遮挡情形下的行人检测方法综述[J]. 计算机工程与应用, 2020, 56(16): 13-20.
CHEN N, LI M L, YUAN H, et al. Review of pedestrian detection with occlusion[J]. Computer Engineering and Applications, 2020, 56(16): 13-20 (in Chinese).
[2] BRAZIL G, YIN X, LIU X M. Illuminating pedestrians via simultaneous detection and segmentation[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 4960-4969.
[3] ZHANG S S, BENENSON R, OMRAN M, et al. How far are we from solving pedestrian detection?[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 1259-1267.
[4] HARIHARAN B, ARBELAEZ P, GIRSHICK R, et al. Simultaneous Detection and Segmentation[C]//European Conference on Computer Vision. Heidelberg: Springer, 2014: 297-312.
[5] PANG Y W, XIE J, KHAN M H, et al. Mask-guided attention network for occluded pedestrian detection[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 4966-4974.
[6] ZHANG S S, YANG J, SCHIELE B. Occluded pedestrian detection through guided attention in CNNs[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6995-7003.
[7] CAO J L, PANG Y W, HAN J G, et al. Taking a look at small-scale pedestrians and occluded pedestrians[J]. IEEE Transactions on Image Processing, 2020, 29: 3143-3152.
[8] LIU X, TOH K A, ALLEBACH J P. Pedestrian detection using pixel difference matrix projection[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(4): 1441-1454.
[9] ZHANG W J, TIAN L H, LI C, et al. A SSD-based crowded pedestrian detection method[C]//2018 International Conference on Control, Automation and Information Sciences. New York: IEEE Press, 2018: 222-226.
[10] LAN W B, DANG J W, WANG Y P, et al. Pedestrian detection based on YOLO network model[C]//2018 IEEE International Conference on Mechatronics and Automation. New York: IEEE Press, 2018: 1547-1551.
[11] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704. 04861.
[12] REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. [2018-04-08]. https://arxiv.org/abs/ 1804.02767.
[13] ZHAO Y, YUAN Z J, CHEN B D. Accurate pedestrian detection by human pose regression[J]. IEEE Transactions on Image Processing, 2020, 29: 1591-1605.
[14] ZHANG S S, BENENSON R, SCHIELE B. CityPersons: a diverse dataset for pedestrian detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 4457-4465.
[15] ZHANG S F, XIE Y L, WAN J, et al. WiderPerson: a diverse dataset for dense pedestrian detection in the wild[J]. IEEE Transactions on Multimedia, 2020, 22(2): 380-393.
[16] LIU W, LIAO S C, REN W Q, et al. High-level semantic feature detection: a new perspective for pedestrian detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 5182-5191.
[17] DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: an evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761.
[18] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2014-09-04]. https://arxiv.org/abs/1409.1556.
[19] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[20] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[21] ZHANG L L, LIN L, LIANG X D, et al. Is faster R-CNN doing well for pedestrian detection?[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 443-457.
[22] TESEMA F B, WU H, CHEN M J, et al. Hybrid channel based pedestrian detection[J]. Neurocomputing, 2020, 389: 1-8.
[23] LI J N, LIANG X D, SHEN S M, et al. Scale-aware fast R-CNN for pedestrian detection[J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996.
[24] CAI Z W, FAN Q F, FERIS R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C]// European Conference on Computer Vision. Heidelberg: Springer, 2016: 354-370.
[25] LAW H, DENG J. CornerNet: detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128(3): 642-656.
[26] SONG T, SUN L Y, XIE D, et al. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 554-569.
[27] LIU S T, HUANG D, WANG Y H. Receptive field block net for accurate and fast object detection[C]//European Conference on Computer Vision. Heidelberg: Springer, 2018: 404-419.
[28] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 3213-3223.
[29] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 248-255.
[30] TIAN Y L, LUO P, WANG X G, et al. Deep learning strong parts for pedestrian detection[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1904-1912.
[31] LI J N, LIANG X D, SHEN S M, et al. Scale-aware fast R-CNN for pedestrian detection[J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996.
[32] WANG X L, XIAO T T, JIANG Y N, et al. Repulsion loss: detecting pedestrians in a crowd[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7774-7783.
Efficient pedestrian detector combining depthwise separable convolution and standard convolution
ZHANG Yun-bo1, YI Peng-fei1, ZHOU Dong-sheng1,2, ZHANG Qiang1,2, WEI Xiao-peng2
(1. Key Laboratory of Advanced Design and Intelligent Computing (Dalian University), Ministry of Education, Dalian Liaoning, 116622, China; 2. School of Computer Science and Technology, Dalian University of Technology, Dalian Liaoning, 116024, China)
Pedestrian detectors require the algorithm to be fast and accurate. Although pedestrian detectors based on deep convolutional neural networks (DCNN) have high detection accuracy, such detectors require higher capacity of calculation. Therefore, such pedestrian detectors cannot be deployed well on lightweight systems, such as mobile devices, embedded devices, and autonomous driving systems. Considering these problems, a lightweight and effective pedestrian detector (EPDNet) was proposed, which can better balance speed and accuracy. First, the shallow convolution layers of the backbone network employed depthwise separable convolution to compress the parameters of model, and the deeper convolution layers utilized standard convolution to extract high-level semantic features. In addition, in order to further improve the performance of the model, the backbone network adopted a feature fusion method to enhance the expression ability of its output features. Through comparative experiments, EPDNet has shown superior performance on two challenging pedestrian datasets, Caltech and CityPersons. Compared with the benchmark model, EPDNet has obtained a better trade-off between speed and accuracy, improving the speed and accuracy of EPDNet at the same time.
standardconvolution; depthwise separable convolution; feature fusion; lightweight; pedestrian detection
TP 391
10.11996/JG.j.2095-302X.2022020230
A
2095-302X(2022)02-0230-09
2021-07-21;
2021-10-21
国家自然科学基金重点项目(U1908214);辽宁特聘教授资助计划;辽宁省中央指导地方科技发展专项(2021JH6/10500140);辽宁省高等学校、大连市及大连大学创新团队资助计划;大连市双重项目(2020JJ25CY001)
张运波(1993–),男,硕士研究生。主要研究方向为数字图像处理与模式识别。E-mail:zhangyunbo1993@163.com
周东生(1978–),男,教授,博士。主要研究方向为计算机图形学、人机交互、人工智能和机器人等。E-mail:zhouds@dlu.edu.cn
21 July,2021;
21 October,2021
Key Program of Natural Science Foundation of China (U1908214); Program for the Liaoning Distinguished Professor; Special Project of Central Government Guiding Local Science and Technology Development (2021JH6/10500140); Program for Innovative Research Team in University of Liaoning Province; Dalian and Dalian University, and in Part by the Science and Technology Innovation Fund of Dalian (2020JJ25CY001)
ZHANG Yun-bo (1993–), master student. His main research interests cover digital image processing and pattern recognition. E-mail:zhangyunbo1993@163.com
ZHOU Dong-sheng (1978–), professor, Ph.D. His main research interests cover computer graphics, HRI, AI and robotics, etc. E-mail:zhouds@dlu.edu.cn
