两阶段可调节感知蒸馏网络的虚拟试衣方法
2022-05-09陈宝玉于冰冰刘秀平
陈宝玉,张 怡,于冰冰,刘秀平
两阶段可调节感知蒸馏网络的虚拟试衣方法
陈宝玉,张 怡,于冰冰,刘秀平
(大连理工大学数学科学学院,辽宁 大连 116024)
基于图像的虚拟试衣能将目标服装图像合成到人物图像上,此任务近年来因其在电子商务和时装图像编辑上广泛应用而备受关注。针对该任务的特点和已有方法的缺陷,提出一种两阶段可调节感知蒸馏方法(TS-APD)。该方法包括3个步骤:①分别对服装图像和人物图像预训练2个语义分割网络,生成更准确的服装前景分割和上衣分割;②利用这2个语义分割和其他解析信息训练基于解析器的“导师”网络;③以“导师”网络生成的假图像作为输入,以原始真实人物图像作为监督,采用一种TS-APD方案训练无解析器的“学生”网络。最终经过蒸馏的“学生”网络能在不需要人体解析的情况下,生成高质量的试衣图像。在VITON数据集上的实验结果表明,该算法在FID、1和PCKh的评分分别可达9.10,0.015 3,0.985 6,均优于现有方法。用户研究结果也表明,与已有方法相比,所提方法生成的图像更加逼真,所有偏好得分均达77%以上。
虚拟试衣;知识蒸馏;图像分割;图像生成;可调节因子
随着越来越多的消费者在网上购买服装和配饰,购物方式为消费者提供互动体验,使在线商务变得尤为重要。虚拟试衣是时装产品在个性化背景下的可视化,提供了智能、直观的在线体验,能够帮助用户判断喜好和购买意向,为此得到了广泛的关注。现有的虚拟试衣分为基于三维人体建模[1-5]和基于二维图像2类方法[6-13]。基于三维模型的方法往往依赖于三维测量或表示,需要昂贵的三维扫描设备和大量的计算资源,不适合在线用户。相比之下,基于图像的生成模型提供了一种更经济、计算效率更高的解决方案。
近年来,基于图像的虚拟试衣在图像合成领域快速发展的推动下取得了相当大的进展。大部分最先进的虚拟试衣方法[6-11]依赖于人体解析信息,例如上衣、裤子、手臂、人脸和头发等,其信息能指导虚拟试衣网络关注特定的服装区域且有针对性地进行内容的保留和生成。但是通常需要基于解析器来获取高质量的人体解析,当解析结果不准确时,该方法将生成明显失真的试衣图像。
文献[12]提出了无解析器“教师-学生”网络(warping U-net for a virtual try-on,WUTON),但是设计上的缺陷导致“学生”网络的图像质量受基于解析器模型的限制。文献[13]提出了无解析器的外观流网络(parser free appearance flow network,PF-AFN),不直接利用基于解析器模型生成的假图像,而是采用了自监督学习的方式训练“学生”模仿原始的真实图像,其在一定程度上弥补了WUTON的不足。但是PF-AFN采用的知识蒸馏[14]只体现在扭曲模块的外观流蒸馏,忽略了试衣模块的重要性,导致试衣结果仍然存在纹理模糊和像素溢出等问题。
本文提出一种两阶段可调节感知蒸馏方法(two-stage adjustable perceptual distillation,TS-APD),有针对性地设计了2个可调节因子,分别对扭曲和试衣模块进行自调节感知蒸馏。本文方法改进了PF-AFN方法单一模块知识蒸馏的不足,大大改善了生成图像的感知质量。另外,现有方法在服装扭曲阶段使用的目标服装前景和上衣分割往往存在大量的噪声,严重影响服装扭曲效果。本文提出2个语义分割网络,进行精准的服装前景和上衣分割,实验结果表明,在新的语义分割下服装扭曲效果大大改善,试衣图像真实感得到明显提升。
1 PF-AFN方法
PF-AFN方法流程如图1所示,采用一种新颖的“教师-导师-学生”知识蒸馏方案。基于解析器模型生成的假图像不直接作为“学生”网络(无解析器模型)的监督,而是作为“学生”网络的输入(导师知识),在真实图像(教师知识)的监督下,使学生模仿原始真实图像。为了进一步提高生成质量,当“导师”生成的图像质量好于“学生”模型时(可调节因子为1),对扭曲模块进行外观流蒸馏。PF-AFN的外观流蒸馏使“学生”网络在扭曲模块学习了有用的知识,但却忽略了试衣模块,在试衣过程中没有“导师”网络的语义信息参与指导,使试衣结果仍然存在小范围伪影和边界模糊等问题。此外,PF-AFN的服装分割未去除衣领等背景区域,上衣分割存在大量噪声,这些均影响了扭曲服装的真实感,进而降低了最终的试衣质量。
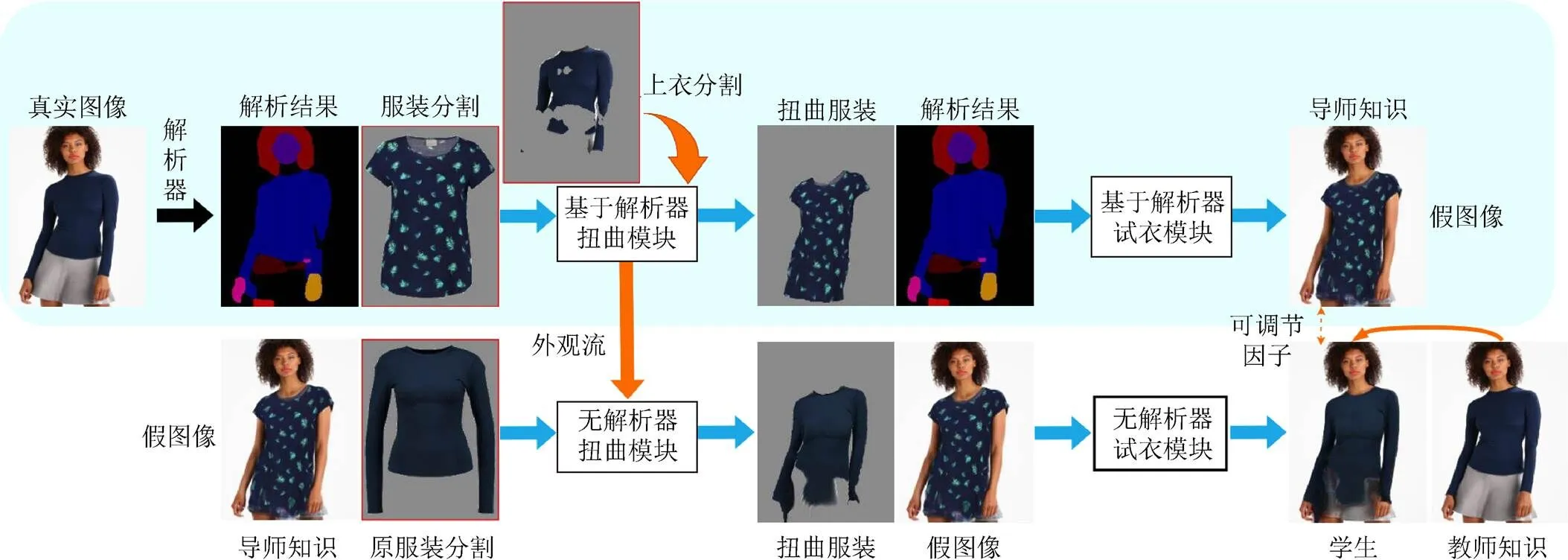
图1 PF-AFN方法流程图
2 TS-APD方法
针对以上问题,本文提出了TS-APD方法,如图2所示。首先,通过2个预训练的语义分割网络生成准确的服装前景和上衣分割;然后,将服装前景和上衣分割连同其他解析信息作为输入,训练基于解析器的导师网络;最后,利用本文方法,在真实图像的监督下,训练无解析器的学生网络。
2.1 语义分割网络
虚拟试衣的目标是将服装图像合成到人物图像上,通过提取服装图像的服装区域,再经过服装扭曲后匹配到人物图像的上衣区域来实现。现有方法对于服装图像和上衣的分割均存在大量的噪声,易导致训练的不稳定和扭曲服装的不可信。为此,本文预训练2个语义分割网络,即服装前景和上衣分割,其均采用传统的10层U-net结构[15]。如图2(b)所示,服装前景分割去除了衣领等服装背景区域,避免了服装背景对试衣结果造成的失真;上衣分割精准且完整地保留了人物图像的上衣区域,为扭曲网络提供了可靠的上衣真值。

图2 本文方法的网络结构和训练流程((a)两阶段可调节感知蒸馏网络;(b) 2个预训练的语义分割网络)
2.2 TS-APD方法训练流程
如图2(a)所示,本文方法包含一个导师和一个学生网络。首先用配对的服装和人物图像(I,)训练导师网络,具体流程如下:

(2) 将2个金字塔特征送入外观流估计网络,预测*和I之间的外观流T,用其扭曲I得到扭曲服装T;
(3) 串联扭曲服装T和扭曲服装掩膜、人物图像保留区域和手臂皮肤的密集姿势作为试衣网络的输入,在真值监督下合成试衣图像。
2.3 扭曲模块
扭曲模块由金字塔特征提取网络(pyramid feature extraction network,PFEN)和外观流估计网络(appearance flow estimation network,AFEN)组成,用于预测服装与人物之间的像素级对应关系。

扭曲模块的目标函数L包括扭曲服装与上衣真值之间的像素级1损失、感知损失L、总变分损失L和二阶平滑损失L,即




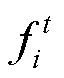
2.4 试衣模块
试衣模块采用Res-UNet[23],也是一个10层U-net结构,只是在每个卷积后添加了2个残差块,其设计使试衣网络能够保留更多的扭曲服装和人物细节。试衣模块采用端到端训练,在试衣模块训练的同时对扭曲模块进行微调,使扭曲模块的扭曲效果更利于合成真实感的试衣图像。试衣模块的目标函数L包括试衣图像与真实图像之间的像素级1和感知损失L,即


对于学生网络的试衣模块,本文还引入了额外的皮肤生成损失,即
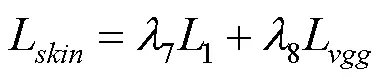

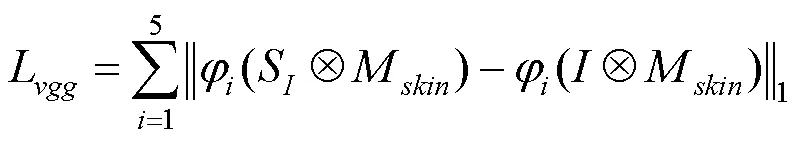

综上所述,试衣模块端到端训练的总损失为扭曲损失L和试衣损失L的加权和,即

2.5 两阶段可调节感知蒸馏
由于导师网络的输入包含人体语义分割、密集姿势和姿势热图等解析信息,而学生网络的输入仅是人物图像和服装图像。因此,在一般情况下,导师网络提取的特征通常包含更丰富的语义信息,估计的外观流和输出的感知代码也更准确,其均可用于指导学生网络的训练。但是,如前文所述,当解析结果不准确时,导师网络可能提供错误的指导。为此,本文设计了可调节扭曲蒸馏损失L和试衣蒸馏损失L。L还包括金字塔特征蒸馏损失L和外观流特征蒸馏损失L,即
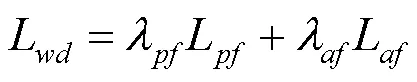
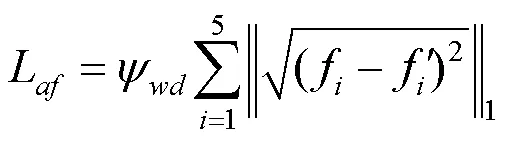
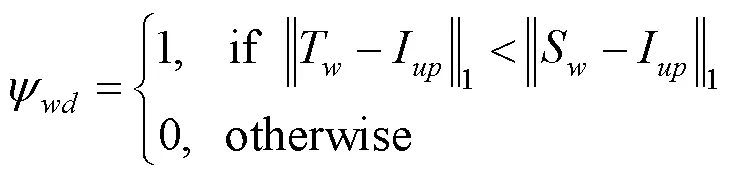
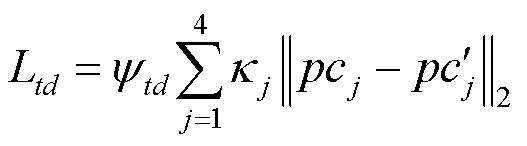


在学生网络中,扭曲模块的训练使用L,试衣模块的端到端训练使用L和L。2种蒸馏损失均以提升扭曲服装和试衣图像的感知质量为目的,因此称之为TS-APD。所谓可调节蒸馏,是当导师网络的输出质量高于学生网络时(即T与I之间的1损失小于S与I之间的1损失,T与之间的1损失小于S与之间的1损失),才对导师网络进行知识蒸馏。这种蒸馏方式使学生网络不仅能准确学习导师网络的先进知识,且能避免导师网络的错误指导。
3 实验结果和分析
3.1 实验设置
3.1.1 数据集
在常用的VITON数据集上对最新方法(CP- VTON[9],CP-VTON+[10],ACGPN[11]和PF-AFN[13])及本文算法的不同版本进行了实验。VITON包含14 221个图像对的训练集和2 032个测试集,每个图像对包含一张人物图像和一张服装图像,分辨率为256×192。此外,数据集中还包含密集姿势、人体语义标签、姿势关键点等解析信息,用于基于解析器方法的训练和测试。
3.1.2 训练参数
本文方法包括4个训练阶段网络:导师扭曲、导师试衣、学生扭曲和学生试衣。其训练周期分别为100,100,200,100,初始学习率为10-5,在分别训练50,50,100,50个周期后逐步衰减到0。损失函数的权重分别设置为:=0.5,=0.2,2=6=8=0.2,1=5=1,3=0.01,4=7=6,=0.04,=1。
3.1.3 评价指标
本文采用FID (Fréchet inception distance)[24]作为评价指标,捕捉试衣图像与参考人物的相似性距离,FID评分越低,表明生成质量越高。此外,本文引入了试衣图像的姿势关键点正确率PCKh指标[25],通过计算试衣图像的姿势关键点与参考人物的姿势关键点匹配程度,间接反映试衣图像的生成质量,其评分越高则质量越好。
为了评价试衣图像对原人物细节的保留能力,本文还提出了试衣保留区域的1指标。首先,使用预训练网络对参考人物和试衣图像进行上衣分割;然后,对试衣图像和参考人物进行掩膜,得到试衣和原图像保留区域进行2个上衣分割,其保留区域完全去除了试衣前后的上衣区域;最后,将2个保留区域的1误差作为试衣图像保留能力的评价指标,其评分越低误差效果则越清晰。
尽管上述指标在一定程度上反映了图像生成质量,但是不能反映目标服装是否进行了自然的扭曲,因此本文进一步进行了用户研究。首先,从VITON测试集中随机选取300对图像,由CP-VTON,CP-VTON+,ACGPN,PF-AFN和本文方法各生成300张图像;然后,将这些图像组合成4组,每组包含各300张本文和另一种方法生成的图像,再加上对应的目标服装和参考人物;最后,邀请30位专业的计算机视觉研究者,通过在线问卷的方式进行调研,给定参考人物和目标服装,要求用户选择视觉质量更好的试衣图像。
3.2 定性分析
本文方法与其他方法在VITON数据集上的定性结果如图3所示。当服装形状差异较大时,基于解析器的方法(CP-VTON,CP-VTON+,ACGPN)往往倾向于生成原服装形状的试衣结果,如图3(a)第1排和图3(b)第3排,试衣图像的服装边缘与原服装形状相似,造成图像失真。这种对解析信息的依赖性也影响身体区域的合成和底层服装的保留,如手臂的缺失和裙子上的伪影。由于PF-AFN方法只对扭曲模块的外观流进行知识蒸馏,忽略了试衣模块,其试衣结果也出现像素溢出和纹理模糊,一些小的服装图案难以合成。本文方法采用更加精准的语义分割,能够有效避免上述问题,生成高度逼真的试衣图像。即使遇到复杂的服装形状,面对衣领、纽扣或斑点纹理等小目标,本文方法也能够做到有效地生成。
3.3 本文与PF-AFN方法视觉比较
图4显示了本文和PF-AFN方法的更多视觉比较。与PF-AFN方法相比,本文方法具有以下优势:①准确合理的服装分割去除了衣领和下摆的服装背景,避免了浅色服装的分割噪声,是生成真实感试衣图像的前期保障;②精确细致的上衣分割为服装扭曲提供了高质量监督,防止原服装残留和像素溢出,也提高了模型对复杂服装形状的合成能力;③弥补了单一模块知识蒸馏的不足,使模型有能力生成更好感知质量和丰富的细节试衣图像(如皮肤和手指)。
3.4 定量分析
不同算法的定量结果和用户评价结果见表1。与其他方法相比,本文方法具有明显的优势,且获得了FID,1和PCKh最高评分。即使对比最先进的PF-AFN方法,也有77.02%的用户认为本文生成图像质量更好,这充分证明了本文方法的优越性。

图3 本文与其他方法的定性比较((a)本文方法;(b)其他方法)

图4 本文与PF-AFN方法的更多视觉比较((a)本文方法;(b) PF-AFN方法)
3.5 消融研究
为了评价本文方法各部分的有效性,本文设计了一组消融实验:去除服装分割(采用原服装分割)、去除上衣分割(采用原上衣分割)、去除蒸馏和使用固定蒸馏。图5展示了消融研究的定性结果。将服装前景分割替换为原服装分割时,生成的图像保留服装背景信息,造成失真。替换上衣分割为原上衣标签时,出现服装边界模糊问题。去除蒸馏或使用固定蒸馏都会影响图像的感知质量,造成局部纹理模糊或部分皮肤像素溢出。

图5 本文方法消融研究的定性结果比较((a)本文方法;(b)消融方法)
在不同的定量指标上,各个消融版本均出现不同程度的分数下降,说明本文方法的每个设计均起着重要作用,即使是评分略低的消融版本也好于目前最先进的PF-AFN方法(表2)。
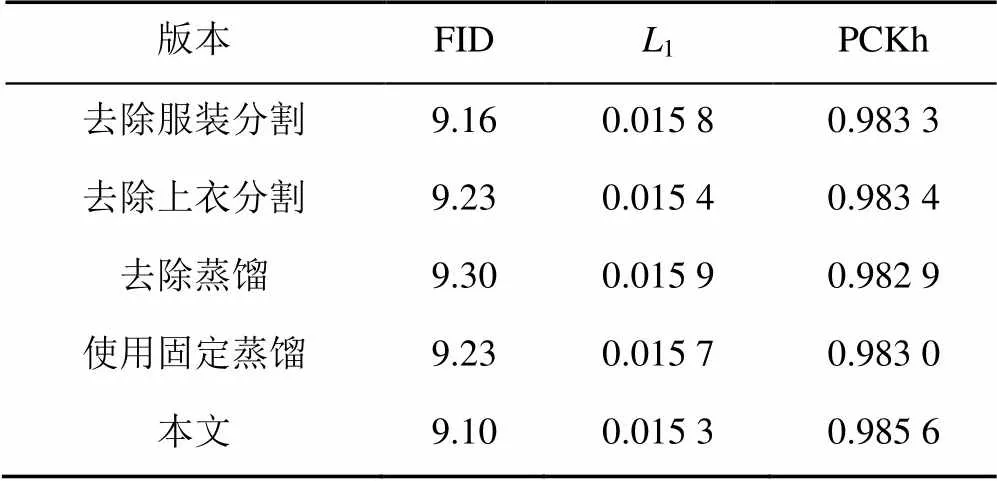
表1 本文方法消融研究的定量结果比较
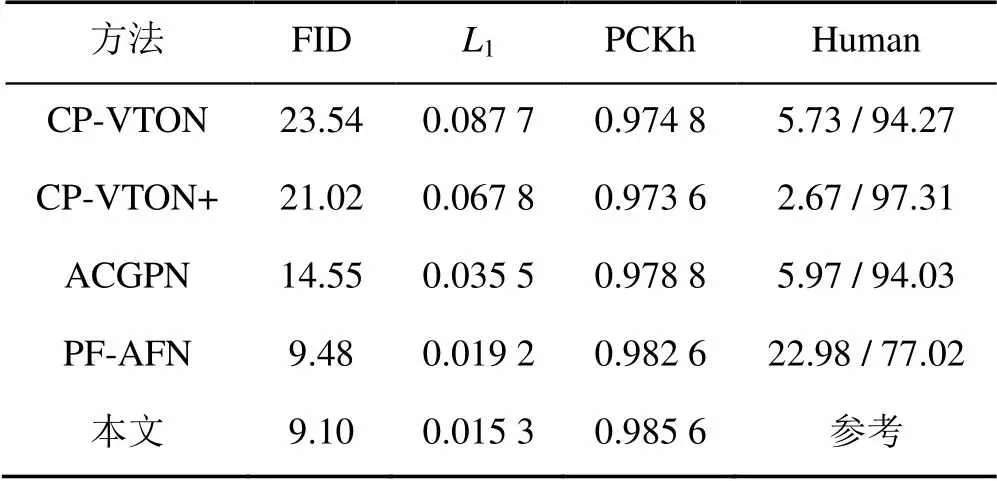
表2 不同方法的定量结果比较和人类评价百分比(%)
4 结束语
本文方法在不需要人体解析的情况下能生成高度逼真的试衣图像。首先预训练服装前景和上衣2个语义分割网络;然后用生成的服装和上衣分割训练基于解析器的“导师”网络;最后将“导师”网络输出的假图像作为“学生”网络的输入,在真实图像的监督下,本文方法训练无解析器的“学生”网络。在VITON上的大量实验结果表明,本文方法在定量指标、视觉质量和用户研究方面均显著优于其他方法。
[1] GUAN P, REISS L, HIRSHBERG D A, et al. Drape[J]. ACM Transactions on Graphics, 2012, 31(4): 1-10.
[2] CHEN W Z, WANG H, LI Y Y, et al. Synthesizing training images for boosting human 3D pose estimation[C]//2016 Fourth International Conference on 3D Vision. New York: IEEE Press, 2016: 479-488.
[3] YANG S, AMBERT T, PAN Z R, et al. Detailed garment recovery from a single-view image[EB/OL]. [2021-07-30]. https://arxiv.org/abs/1608.01250.abs/1608.01250.
[4] PONS-MOLL G, PUJADES S, HU S, et al. ClothCap[J]. ACM Transactions on Graphics, 2017, 36(4): 1-15.
[5] 石敏, 魏育坤, 王俊铮, 等. 面向不同体型特征的服装款式迁移方法[J]. 图学学报, 2019, 40(5): 866-871.
SHI M, WEI Y K, WANG J Z, et al. Transfer method of body shape-oriented garment style[J]. Journal of Graphics, 2019, 40(5): 866-871 (in Chinese).
[6] JETCHEV N, BERGMANN U. The conditional analogy GAN: swapping fashion articles on people images[C]//2017 IEEE International Conference on Computer Vision Workshops. New York: IEEE Press, 2017: 2287-2292.
[7] HAN X T, WU Z X, WU Z, et al. VITON: an image-based virtual try-on network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7543-7552.
[8] HAN X T, HUANG W L, HU X J, et al. ClothFlow: a flow-based model for clothed person generation[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 10470-10479.
[9] WANG B C, ZHENG H B, LIANG X D, et al. Toward characteristic-preserving image-based virtual try-on network[C]//Computer Vision - ECCV 2018. Heidelberg: Springer, 2018: 607-623.
[10] MINAR M R, TUAN T T, AHN H, et al. CP-VTON+: clothing shape and texture preserving image-based virtual try-on[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop. New York: IEEE Press, 2020: 1-4.
[11] YANG H, ZHANG R M, GUO X B, et al. Towards photo-realistic virtual try-on by adaptively generating- preserving image content[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 7847-7856.
[12] ISSENHUTH T, MARY J, CALAUZÈNES C. Do not mask what you do not need to mask: a parser-free virtual try-on[C]// 2020 European Conference on Computer Vision. Heidelberg: Springer, 2020: 619-635.
[13] GE Y Y, SONG Y B, ZHANG R M, et al. Parser-free virtual try-on via distilling appearance flows[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 8481-8489.
[14] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. [2021-07-30]. https://arxiv.org/ abs/1503.02531.
[15] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Medical image computing and computer-assisted intervention. Heidelberg: Springer, 2015: 234-241.
[16] GÜLER R A, NEVEROVA N, KOKKINOS I. DensePose: dense human pose estimation in the wild[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7297-7306.
[17] CAO Z, SIMON T, WEI S H, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1302-1310.
[18] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[19] DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2758-2766.
[20] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 248-255.
[21] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2021-07-30]. https://arxiv.org/abs/1409.1556.
[22] SUN D Q, ROTH S, BLACK M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them[J]. International Journal of Computer Vision, 2014, 106(2): 115-137.
[23] DIAKOGIANNIS F I, WALDNER F, CACCETTA P, et al. ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162: 94-114.
[24] HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]//NIPS’17: The 31th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2017: 6629-6640.
[25] ZHU Z, HUANG T T, SHI B G, et al. Progressive pose attention transfer for person image generation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 2342-2351.
Two-stage adjustable perceptual distillation network for virtual try-on
CHEN Bao-yu, ZHANG Yi, YU Bing-bing, LIU Xiu-ping
(School of Mathematical Sciences, Dalian University of Technology, Dalian Liaoning 116024, China)
It is known that image-based virtual try-on can fit a target garment image to a person image, and that this task has gained much attention in recent years for its wide applications in e-commerce and fashion image editing. In response to the characteristics of the task and the shortcomings of existing approaches, a method of two-stage adjustable perceptual distillation (TS-APD) was proposed in this paper. This method consisted of 3 steps. Firstly, two semantic segmentation networks were pre-trained on garment image and person image respectively, thus generating more accurate garment foreground segmentation and upper garment segmentation. Then, these two semantic segmentations and other parsing information were employed to train a parser-based “tutor” network. Finally, a parser-free “student” network was trained through a two-stage adjustable perceptual distillation scheme, taking the fake image generated by the “tutor” network as input and the original real person images as supervision. It can be perceived that the “student” model with distillation is able to produce high-quality try-on images without human parsing. The experimental results on VITON datasets show that this algorithm can achieve 9.10 FID score, 0.015 31score, and 0.985 6 PCKh score, outperforming the existing methods. The user survey also shows that compared with other methods, the images generated by the proposed method are more photo-realistic, with all the preference scores reaching more than 77%.
virtual try-on; knowledge distillation; image segmentation; image generation; adjustable factor
TP 391
10.11996/JG.j.2095-302X.2022020316
A
2095-302X(2022)02-0316-08
2021-08-31;
2021-09-17
国家自然科学基金项目(61976040)
陈宝玉(1992–),男,博士研究生。主要研究方向为人类姿势转移和虚拟试衣。E-mail:chenby047@mail.dlut.edu.cn
刘秀平(1964–),女,教授,博士。主要研究方向为计算机图形学、计算机视觉等。E-mail:xpliu@dlut.edu.cn
31 August,2021;
17 September,2021
National Natural Science Foundation of China (61976040)
CHEN Bao-yu (1992–), PhD candidate. His main research interests cover human pose transfer and virtually try-on. E-mail:chenby047@mail.dlut.edu.cn
LIU Xiu-ping (1964–), professor, Ph.D. Her main research interests cover computer graphics, computer vision, etc. E-mail:xpliu@dlut.edu.cn
