基于XLCLS模型的法条多标签分类方法
2022-05-06张青王肖霞杨风暴
张青, 王肖霞, 杨风暴
(中北大学信息与通信工程学院, 太原 030051)
社公益诉讼案件作为一种新型的权益救济方式,保障着国家与人民的利益生活。近年来,随着法律的不断普及,越来越多的人运用法律维护自身利益以及社会的公共利益。随着公益诉讼案件的不断增多,“案多人少”逐渐成为急需解决的问题之一。
近年来,随着智能司法[1-2]不断推进,越来越多的研究人员致力于智能司法的研究。智能司法将人工智能[3-4]与司法领域相结合,通过预测法条、罪名、量刑等因素提供给专业人员进行参考,辅助专业人员进行审判,提升办案效率。法条多标签分类作为智能司法研究任务当中的一个重要子任务,是构成智能司法的关键组成部分。为了能够提升法条分类的合理性,满足实际情况需求,本文中选择法条多标签分类任务进行研究。
目前法条多标签分类任务是采用文本分类技术[5]来实现的。随着深度学习的发展,越来越多的研究人员将深度学习引入分类任务当中,通过选取合适的模型对案件文本进行向量表示获取文本的语义信息以及提取特征信息,从而实现法条多标签分类。如Yang等[6]在多核卷积神经网络[7](convolutional neural networks,CNN)模型上融合了BERT[8](bidirectional encoder representation from transformers)句向量来提取文本的语义信息,最后添加了一种阈值方法来实现法条多标签的分类。该方法从获取案件语义信息的角度去实现多标签分类任务,却忽略了标签之间的关联性,在不平衡数据上的分类效果表现却并不理想。并且BERT模型输入最长字数为512字,当文本长与512字时,多余的字数会被截断,不会参与模型的训练,容易造成相关信息的丢失。唐光远等[9]在刑事案件中引入法条知识,并融入案情描述中实现法条的分类。该虽然方法引入了法条知识,加强了案情描述表示能力,但是该方法聚焦于法条的单标签分类,未能考虑法条之间的相关性,不符合实际情况。赵慧等[10]在临床场景中提出了一种合并证的多标签分类模型,通过疾病标签关联信息量化合并证并发关系,并基于样本K邻域内标签的概率分布以后验概率的方式计算样本对每个疾病标签的隶属概率,通过引入标签间的相关性来提升多标签分类效果。
基于此,在公益诉讼领域,结合法条司法解释,提出了一种基于XLCLS模型的法条多标签分类方法。为了能够更好地捕获法律案件中的语义信息,采用XLNET预模型进行训练,来获取案件丰富的语义信息,同时还能解决由于BERT模型512字数的限制而导致长案件文本相关信息丢失的问题;在此基础上,引入法条的司法解释来丰富案件向量表征,再通过CNN模型来提取案件与法条的特征信息,加深案件与法条之间的潜在联系,最后通过余弦相似距离方法来计算法条之间的相似性,解决不常见法条容易被忽略的问题,提升法条多标签分类效果。
1 法条多标签分类模型的构建
该模型主要由4个部分组成:预处理、文本表示、特征提取以及输出部分,原理框图如图1所示。
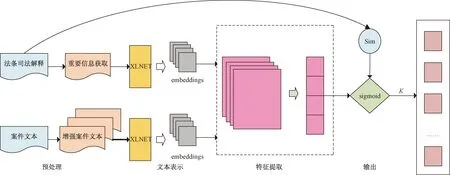
图1 法条多标签分类原理框图Fig.1 Schematic diagram of multi-label classification
1.1 预处理
由于公益诉讼领域在自然语言处理中属于新领域,且涉及国家行政机关以及相关单位或公民的隐私,相关案例信息无法公开,难以获取大规模数据集。为了解决公益诉讼案件文本数量不足的问题,本文采用数据增强的方法对公益诉讼案件文本进行处理,通过扩大训练样本的规模,降低模型对某些属性的依赖,在有效降低人工成本的基础上提升模型性能。
本文中采取EDA与回译数据增强方法,利用同义词替换、随机插入方法对原始数据集进行处理,以及通过回译将原始数据集通过百度翻译变成英文再翻译成中文。通过引入一定的噪声来提升模型的鲁棒性,同时通过同义词替换与随机插入引入了新词,将模型推广到不在训练集中的单词,提升案件文本表示能力。数据增强后的数据如表1所示。
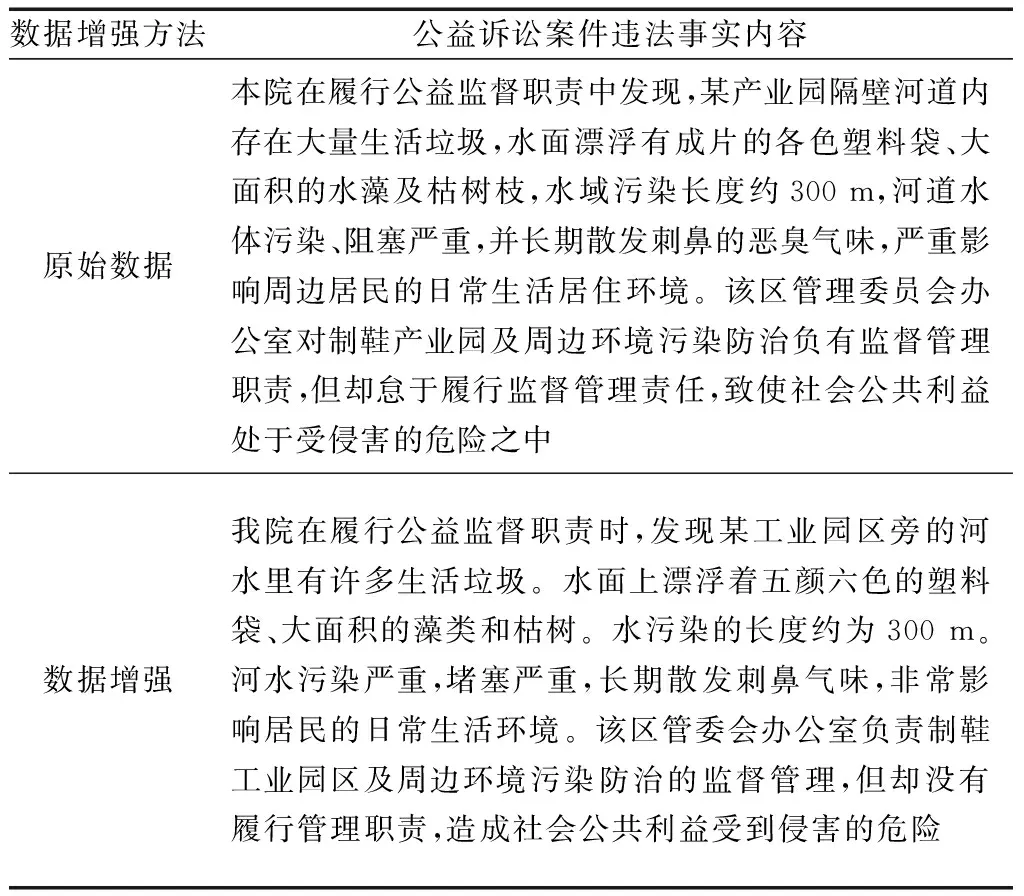
表1 数据增强部分样例Table 1 Example of data enhancement
1.2 文本表示
为了更好地获得案件丰富语义的向量表示,本文引入XLNET[10]语言模型对案件进行训练,通过广义自回归预训练方法对文本进行双向编码。
XLNET模型采用了随机排列机制的自回归语言来对句子进行建模,在排列后的组合中选取一部分作为模型的输入,如图2所示。
图2中,假设原始输入句子为[严,染,体,重,污,水],这样将原本在“污”后面的下文“染”“严”“重”通过重新排序后变成“污”的上文,再利用这些字以及对应的隐藏状态memh对目标字进行预测,通过这种随机排列方法来融合目标单词的上下文信息,解决了自回归语言模型无法双向预测的缺点。

图2 排列机制Fig.2 Arrangement mechanism
由于微调阶段无法对原始输入进行重新排列,这种随机排列机制会导致前后阶段不一致,因此需要预训练阶段的输入部分仍然是原始语句顺序。为了解决该类问题,XLNET模型采用注意力机制掩码方法,通过mask去掩盖无用的单词,使其在预测目标词的时候不发生作用,最终得到不同的排列组合,实现双向预测。注意力机制掩码如图3所示。
在图3当中,对于排列后的“体”来说,能够利用到“严”与“染”两个字,因此在第二行当中保留这两个字,其余均用mask掩盖。再如预测排列后的“严”字,没有可以利用的信息,因此在第五行当中全用mask掩盖。排列机制的计算式为

图3 注意力机制掩码Fig.3 The attentional mechanism mask
(1)
式(1)中:θ为预测目标词最大概率的参数;T为输入句子的长度;Z~ZT表示句子的重新排列组合方式;EZ~ZT为期望,pθ(xzt|xz 为了在内存的限制下学到更长的依赖关系,XLNET模型在transformer[11]基础上提出了transformer-xl,采用段循环机制,使得当前段在建模的时候能够利用之前段的记忆信息来实现长期依赖性。如图4所示。 图4 段循环Fig.4 Segment cycle 图4为段循环的信息传递方式,在处理段2时,每个隐藏层都会接受两个输入,分别为该段前面隐藏层的输出(实线部分)与前一段隐藏层的输出(虚线部分),其中虚线表示前一段的记忆信息,能够建立创建长期依赖关系。同时,解决了transformer仅限于处理512个字符的问题,能够处理更长的案件文本。 XLNET采用排列机制的自回归语言训练与transformer-xl,解决了自回归语言无法双向训练的缺点,能够充分的捕获文本的上下文关系,获得包含丰富语义信息的案件向量表示。 为了更好地提取案件和法条司法解释的特征信息,通过构建相应的CNN模型,加深案件与法条之间的潜在联系。将案件向量与法条司法解释向量拼接后输入CNN模型当中,通过设置卷积核尺寸来提取不同粒度的特征信息,如图5所示。 图5 CNN特征提取Fig.5 CNN feature extraction 从图5中可以看出原始输入数据为案件经过XLNET模型后获得的向量表示,记为X,这里引入法条司法解释,将法条司法解释转化为向量表示,记为I,将法条司法解释向量与案件向量进行拼接,如图5第二模块中所示,实线表示案件向量,虚线表示融合的法条知识向量,其计算公式为 V=[X;I] (2) 为了提取案件与法条司法解释的特征信,将融合后的向量进行卷积,通过设定不同大小的卷积核,来获取不同尺寸的特征信息,然后将卷积后的向量进行最大池化,来提取重要特征信息,同时能够抑制网络参数误差造成估计均值偏移的现象,最后输入全连接层当中,计算公式为 C=f(WV+b) (3) 式(3)中:f是非线性函数;W表示可以训练的权重矩阵;b表示偏置。 由于实际案例当中,法条与法条间总是存在某种相似性,如案例“本院在办案中发现,xx诊所无证行医,产生的医疗废弃物与生活垃圾混同,没有进行定点投放,下雨天经过雨水冲刷流入河流,造成水体污染。且诊所当中医疗污水未进行处理直接排入污水管流入河流当中,造成水污染。”中,由于医疗废弃物与医疗废水的随意倾倒造成河流的水污染,但是该案例当中也涉及了医疗废物管理条例,然而该类属于罕见案例,因此可能无法预测该法条,为了解决该类问题,引入法条相似性计算,通过余弦距离方法来计算法条之间的相似性,考察与其最相关的法条是否符合该案件当中的情形,以此来提高法条多标签分类的准确性。相似性计算公式为 (4) 式(4)中:ai、bi分别为法条a与b的司法解释向量表示。 最终的输出为多标签分类任务,采用sigmoid函数来计算每一个法条相应的概率,计算公式为 (5) 最后选取一个合适的阈值k,当通过上述公式计算得到法条概率大于该阈值时,对应法条则为预测法条类别。 本文实验使用的数据部分由两部分组成,一部分有高检部门所提供,另一部分来自于裁判文书网,利用爬虫技术,在裁判文书网上进行爬取,获取以环境保护为例的数据信息,两部分数据均为真实案例,具有科学合理性。最后对获取的数据进行初清洗,获得总共可用数据15 984条。最后,按7∶3将数据划分为训练集与测试集,得训练集与测试集分别为11 188条与4 796条。 打压试验。采取分级打压,每级升压0.2 MPa,保持稳压不小于10 min,检查管身、接口、镇墩、后背、支撑及构筑物有无异常现象,有无破损、漏水现象,确认情况正常后,方可继续升压。在升压过程中,如有压力下降,且水压降不得超过0.03 MPa,应及时向管道内补水,保证管道设计试验压力稳定,稳压延续时间不得小于2 h。计算稳压时间内管道补入的水量,即是实测渗水量,当小于允许渗水量时,管道密实性为合格。 在多标签分类任务中,通常采用宏观与微观精确率P(正确预测为正的样本占全部预测为正的比例)、召回率R(正确预测为正的样本占全部实际为正的比例)、F1值(P与R的调和平均数)作为实验结果的评价指标,公式为 (6) (7) (8) (9) (10) (11) 式中:下标ma与mi分别表示宏观与微观指标;Pi与Ri分别表示类别为i的精确率与召回率;TPi表示正类类别i预测正确的个数;FNi表示正类类别i预测错误的个数;FPi表示将负类i预测错误的个数。 2.3.1 各模型结果对比 本文实验在公益诉讼案件数据集上进行测试,为了验证本文方法的有效性,分别与以下8种神经网络模型在法条多标签分类任务上进行了实验对比。 (1)w2c-CNN:以word2vec为词嵌入训练模型,CNN为主体网络。 (2)w2c-CNN-L:以word2vec为词嵌入训练模型,CNN为主体网络,在词嵌入训练模型当中增加法条司法解释。 (3)w2c-CNN-L-S:以word2vec为词嵌入训练模型,CNN为主体网络,在词嵌入训练模型中增加法条司法解释,在输出层中引入法条相似性。 (4)BERT-CNN:以BERT为词嵌入训练模型,CNN为主体网络。 (5)BERT-CNN-L:以BERT为词嵌入训练模型,CNN为主体网络,在词嵌入训练模型当中增加法条司法解释。 (6)BERT-CNN-L-S:以BERT为词嵌入训练模型,CNN为主体网络,在词嵌入训练模型中增加法条司法解释,在输出层中引入法条相似性。 (7)XLNET-CNN:以XLNET为词嵌入训练模型,CNN为主体网络。 (8)XLNET-CNN-L:以XLNET为词嵌入训练模型,CNN为主体网络,在词嵌入训练模型当中增加法条司法解释。 具体实验结果如表2所示。 由表2的实验结果当中可以观察到3个方面。 (1)对比表2中CNN、BERT-CNN以及 XLNET-CNN模型,可以发现XLNET-CNN模型的分类效果达到最优,其中F1,ma与F1,mi达到了86.68%和88.12%。说明了多标签分类任务中,引入语言预训练模型能够获取丰富的文本语义信息,同时双向编码也能捕获文本的上下文信息,提升分类效果。其中XLNET的分类效果优于BERT模型,这是因为BERT模型的输入文本长度本限制在512,但是在公益诉讼案件当中,绝大数案件文本长度大于512,这导致了BERT模型在对文本进行训练时,会造成一部分信息丢失,影响了分类效果。 (2)对比表2当中有无引入法条司法解释的模型,即CNN与CNN-L、BERT-CNN与BERT-CNN-L、XLNET-CNN与XLNET-CNN-L 3组模型,可以发现,与未引入法条司法解释的3个模型相比,引入了法条司法解释的模型在F1,ma与F1,mi上分别提高了1.65%与2.40%、2.13%与1.68%、0.77%与1.13%,这是因为法条司法解释包含了法条本身规定的相关信息,在模型当中通过引入法条司法解释信息,一方面能够增加文本的语义信息,另一方面可以增强案件与法条之间的联系,从而能够提升多法条预测效果。 (3)对比表2当中有无加入法条相似性的模型,即CNN-L与CNN-L-S、BERT-CNN-L与BERT-CNN-L-S、XLNET-CNN-L与XLCLS 3组模型,可以发现,与未加入法条相似性的模型相比,加入了法条相似性模型在F1,ma与F1,mi上分别提高了2.98%与2.64%、1.40%与0.95%、0.92%与0.67%,其中本文的所采用的XLCLS模型,在各项指标上都取得了最优表现。对比法条相似性的指标F1,ma与F1,mi可以看出,F1,ma的指标提升效果较大,这是因为F1,ma更加考虑不常见类别的影响,而添加了法条相似性的模型,通过融入法条之间的相似性,来提升不常见法条的准确性。 表2 不同模型的分类结果Table 2 Classification results of different model 2.3.2 阈值的确定 在法条多标签分类任务当中,最后计算案件对于每一个法条的概率,通过选取合适的阈值,当概率大于该阈值的则为预测的法条。为了能够使得法条多标签分类方法达到最优效果,考虑了不同阈值的选择对模型的影响情况,如图6所示。 图6 阈值的影响Fig.6 Effect of thresholds 在图6当中,选取了两组模型BERT-CNN-L-S与XLCLS进行测试,阈值的范围划分为0.1~0.9,在两组模型上对比不同的阈值对分类指标F1,ma与F1,mi的影响。由图8可以看出,在两组模型上,当阈值选择为0.6时,F1,ma与F1,mi的值表现最好,这可能是由于法条多标签任务当中,由于法条相似问题以致法条难以区分,当阈值选取为传统的0.5时,会造成法条推送过多的情况发生,影响分类的准确性,因此最终确定阈值为0.6。 2.3.3 模型的收敛性分析 为了进一步的提升该模型的有效性与稳定性,绘制了两组模型的收敛曲线进行对比,通过比较损失在不同选代次数下的变化情况来选择稳定的法条多标签分类模型,如图7所示。 图7 收敛曲线Fig.7 Convergence curves 图7中,在BERT-CNN-L-S与XLCLS两组模型上验证了损失在迭代次数上的变化情况,在有限的硬件与时间条件限制下,选择迭代次数的范围为1~15。从图7中可以看出,在BERT-CNN-L-S模型上,当迭代次数达到11,模型开始收敛,而在XLNET-CNN-L-S模型上,迭代次数达到8以后,损失开始趋于稳定,模型逐渐达到收敛状态。在模型训练过程中,合适的迭代次数能够提升模型的有效性与稳定性,且随着迭代次数的不断增大,模型训练需要花费更多的时间,甚至会导致模型过拟合,影响模型的分类效果。对以上情况进行分析,最终确定迭代次数为10。 本文中结合法条司法解释,提出了一种基于XLCLS模型的法条多标签分类模型。该方法采用XLNET模型对案件进行向量化表示,同时在模型当中引入法条司法解释,提升文本向量化表征能力,同时构建卷积神经网络模型提取案件与法条司法解释的特征信息,最后引入法条间的相关性分析,结合sigmoid函数计算个法条的概率,通过阈值的选取实现法条多标签分类。实验证明,本文提出的模型在公益诉讼案件数据上表现较好。
1.3 特征提取

1.4 输出
2 实验结果与分析
2.1 数据集
2.2 评价指标
2.3 实验对比与分析



3 结论
