针对城市道路的图像语义分割
2022-04-18樊天宇张瑞菊
樊天宇 张瑞菊

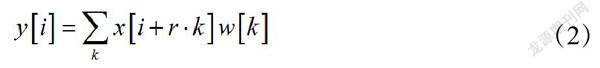



(北京建筑大学,北京 102627)
摘要 城市道路图像的语义分割具有很多的应用场景,如自动驾驶、图片或视频中广告的插入等。这些应用场景都要求分割算法具有較高的精确度,城市道路图像中具有很多尺度大小不一的目标,不同尺度的目标特别是小尺度的目标,会给精细化分割带来更多困难。针对以上问题,提出了一种基于编码器—解码器结构的语义分割网络。使用该模型以改进不同尺度目标边缘的分割精确性。针对城市道路场景的Cityscapes数据集设计相关的对比实验,实验结果证明了所提方法的有效性。
关键词 图像语义分割;城市道路;深度学习
中图分类号 U463.6;TP391.41 文献标识码 A 文章编号 2096-8949(2022)06-0011-03
引言
图像语义分割一直是计算机视觉领域非常重要的研究方向,伴随着深度学习在计算机视觉中目标识别领域率破纪录,大放光彩,深度学习也在计算机视觉其他子领域应用开来,如目标跟踪、图像去噪、场景重建、图像风格转换。图像语义分割是将像素按照图像中表达语义含义的不同进行分组(Grouping)和分割(Segmentation),在 2012 年之前,传统方法从“阈值法”逐步发展到基于像素聚类的分割方法,2012 年后,基于深度学习的图像语义分割方法开始逐渐应用自动驾驶领域。自动驾驶通过环境感知、自主决策和运动控制等一系列关键技术,实现道路交通部分甚至完全自动化运行,是对传统运输模式和出行方式的一次深刻的变革。现如今,主要发达国家纷纷将其列为下一阶段重要的发展领域。据不完全统计,截至2020年末,我国汽车保有量约为28 087万辆(包括三轮汽车和低速货车748万辆),比上年末增加1 937万辆,是名副其实的汽车大国。然而我国的自动驾驶技术专利虽然申请活跃,但总体的质量偏低,产业核心竞争力也有待提升。在《“十三五”国家战略性新兴产业发展规划》中指出,要加速电动汽车智能化技术应用创新,发展自动驾驶。自动驾驶系统作为智能驾驶汽车的“心脏”,其主要包括智能交通系统(Intelligent Traffic System,ITS)、先进驾驶辅助系统(Advanced Driver Assistance System,ADAS)。城市道路图像的语义分割是智能交通系统以及先进辅助驾驶系统中的重要一环,是实现辅助驾驶甚至完全自动化驾驶必不可少的关键技术。目前交通事故主要是人为失误造成的,其主要包括注意力不集中、行为不端等。道路感知和道路图像的语义分割作为先进驾驶辅助系统的基础,在帮助驾驶员避免错误方面起着至关重要的作用。一些成功的自动驾驶辅助系统或汽车企业,如Mobileye、宝马、特斯拉等,都开发了自己的产品,在研究和现实应用方面都取得了显著的成就。目前成熟的自动驾驶方案几乎都采用了基于视觉的技术,例如工业高清摄像头、双目相机等。它相比于激光雷达具有更低的获取成本以及更接近于人眼的感知效果。这是因为在车辆行驶过程中,摄像头采集到的图像数据具有极大的信息量。图像语义分割将图像中每一个像素按照标签进行分类,从而可以从图像中提取出丰富的驾驶环境信息,辅助决策。例如在摄像头采集到的数据中,区分出道路与绿化带,行人与车辆,判定出可行驶区域,区分出道路路面与地面交通标示,判定出道路边缘与车道线。图像语义分割是自动驾驶中的重要环节,通过对摄像头传感器采集到的信息进行特征提取分类,才能获得有利于决策模块进行决策的信息[1]。在现阶段的自动驾驶技术中,处理好图像中道路路面的关键性信息,将有助于提高车辆行驶决策的准确度。
1 全卷积神经网络
道路图像是自动驾驶中视觉传感器收集到的重要信息,是汽车行驶环境的重要建模依据。在传感器收集到的大量图像信息中,自动驾驶感知模块依据语义信息将图像中不同分类的目标分割开来,帮助决策模块理解场景。随着深度学习在计算机视觉领域大规模应用,卷积神经网络也自然而然地成功应用到语义分割中。目前基于深度学习语义分割模型种类很多,全卷积神经网络是目前最成功的分割模型之一,传统深度神经网络模型中,在分类器前常接一个全连接层,全连接层因为要接受固定大小的输入维度,故当卷积层输出更大维度的特征图时,无法使用全连接层进行处理,对目标尺度变化大的特征难以学习[2]。
加州大学伯克利分校的 Jonathan Long等人提出了全卷积神经网络模型,该模型使用卷积层取代了全连接层,接受任意尺寸的图像信息作为输入,经过多层卷积与池化进行特征抽取和降维操作后,引入反卷积对最后一层卷积层上输出的特征图执行上采样操作,使特征图恢复到与输入图像相同的尺寸,从而对输入图像中每个位置的像素产生一个预测,预测像素属于哪个类别[1]。全卷积神经网络模型的结构由于池化对每次卷积结果的降维操作,造成图像分辨率降低,当执行到 pool5 时,图像的分辨率较之输入时已经变得非常低,若从该层执行上采样操作,得到的分割结果也非常粗糙。从该层执行上采样操作后,获得与输入图像一样大小的输出模型,须放大 32 倍,故称为 FCN-32s。这样的模型由于缺少大量细节信息,分割效果很差。如果将该层池化后的结果仅上采样并放大两倍,与 pool4 层的池化结果相加,得到新的特征图再进行上采样操作,放到 16 倍得到和输入图像尺寸相同的结果,这该模型称为 FCN-16s。而 FCN 网络中效果最好的是 FCN-8s,顾名思义,该网络将 pool3 层的结果与pool4、pool5 上采样后的结果相加,将浅层特征与深层特征进行了融合,故分割结果的效果是最好的。
2 深度图像分割网络
针对自动驾驶中的图像语义分割任务,提出了一种基于深度学习的深度图像分割网络。该网络较全卷积神经网络,做了很多改进,吸取了全卷积神经网络中的思想,例如跨层融合、上采样等,也针对该网络采用池化降维导致图像像素丢失的缺点进行了改进。网络整体结构使用了 3 个残差模块、3 个非对称分离卷积模块、1 个空洞卷积层、3 个反卷积层和 1 个 softmax 分类层。网络整体采用对称结构设计,左半部分为编码网络(Encoder),右半部分为解码网络。在编码网络,使用残差模块,不断提取图像特征,在这个过程中,不使用池化操作,执行三次残差模块操作后,对特征图进行空洞卷积获得尺寸最小的特征图。每个卷积层操作采用 ReLU 激活函数,每个卷积层后有批归一化层,防止学习过程中,误差梯度弥散或爆炸。在解码网络中,深度网络将空洞卷积层获得的特征图,经过反卷积操作,不断进行上采样,将图像尺寸恢复到输入时大小。借用 FCN 网络中特征融合思想,将编码网络和解码网络进行特征融合,由于编码网络中,浅层抽取的特征较为丰富,合理利用浅层信息能有效提高图像分割时精度。解码过程中,反卷积进行 2 倍上采样后的特征图,与对应位置处编码网络残差模块处理结果进行融合,利用浅层网络的特征。编码网络残差模块使用非对称分离卷积模块进行降维操作,使两者的特征图具有相同维数[2]。
2.1 残差网络
深度神经网络层数越多,提取的特征也就越丰富,但如果简单地增加深度,会使学习过程中误差函数传播出现梯度弥散或者梯度爆炸,即准确率先随着深度的增加而提高,随后又减低的过程。何凯明将深度神经网络中接收到的信息通过短连接传递到后面的层中,有效地解决了深度网络难以训练的问题。在深度图像分割网络中,采样残差结构提取特征,既能保证网络深度来获取更多的特征,还能避免网络过拟合,降低训练难度。残差网络在设计时,当输入和输出维度不一致时,需要给输入的特征图 x 执行一个线性映射来匹配维度,如下式:
文中采用大小为1×1,步长为2的卷积核来执行映射。
2.2 空洞卷积
编码网络中,对最后一个残差抽取的特征图执行空洞卷积来取代池化操作。在传统的卷积神经网络中,池化操作虽然能够降维,但会使特征图上的像素尺度较低产生信息丢失,这样经过上采样会降低分割精度。空洞卷积是一种通过增加感受野范围的卷积方式,采用下式计算特征图的空洞卷积结果,i为像素索引,r为孔的比例。随着孔比例增加,空洞卷积感受野的范围也随之增加,但参数数量并未增加。
空洞卷积在普通卷积核中插入孔来达到增加感受野面积的目的,将一个原本感受野大小为3×3的卷积核变为了7×7,并且没有增加训练参数。
2.3 非对称卷积
解码网络中非对称卷积模块将残差模块输出的特征图降维到与反卷积上采样后的得到的特征图一样的维度。非对称卷积最早出现在InceptionV3深度网络中,Inception系列网络是使用不同大小的卷积核对输入的图像进行卷积,然后将结果融合。广泛地使用的Inception模型中,通过1×1,3×3,5×5等不同大小的卷积核采用depthconcat方式连接,这样一方面增加了单层网络的宽度,同时也保留了不同尺度下的输入信息特征,增加了深度神经网络对尺度的适应性。非对称卷积是在Inception网络中,使用1×N和N×1大小的卷积核,取代N×N大小的卷积核。这种运算下,二者的卷积结果是一致的,但通过非对称卷积,有效地减少了运算量,减少了卷积核参数。
2.4 反置卷积
在解码网络中,使用反卷积进行上采样操作。反卷积也称转置卷积,实质上依然是卷积操作,只是将输入图像进行填边或在像素间填零后,进行卷积操作。
2.5 批归一化层
在深层神经网络的应用中,深度网络的训练一直是难以攻克的难题。当使用梯度下降算法反向传播误差时,经常出现梯度消失和梯度爆炸现象,是因为误差在传播过程中,由于多层神经网络的级联,参数微小的变化会将计算结果在层间传递中不断地放大或缩小。因此,需要将数值在不同层间传递时,维系在一个合理范围内。归一化则是机器学习中常见的数据预处理操作,数据的不同特征或维度中具有不同的量纲和量纲单位,其差异会影响到机器学习的效果,为消除不同特征间的量纲差异,常常对特征进行归一化处理,让不同的特征处于同一个数量级中。而批归一化层则是对神经网络层间数据进行归一化处理。
2.6 损失函数
针对图像语义分割任务,模型的优化目标函数选择交叉熵代价函数。深度神经网络最后输出的是W*H*C维的张量,用C维向量表征原图上每一个像素属于的分类。在训练中,使用One-HotEncoding的编码方式将训练集中的像素的分类表征为一个只由0和1构成的C维向量。深度神经网络输出的C维向量表征此处像素属于C个分类的概率。当输出与期望结果无限接近时,交叉熵损失函数无限接近于0。
3 Cityscapes数据集
Citysacpes数据集是自动驾驶领域权威数据集之一,该数据集专注于城市街道场景下的图像分割,其采集了德国境内的50个城市的街道在春、夏、秋三个季节中的照片,数据均在天气条件好的白天下采集,分辨率为
1 024 dpi×2 048 dpi。对其中5 000张照片进行了细标注,20 000张照片进行了粗标注。2016年,图森在Citysacpes公开数据集测试上获得世界第一。Cityscapes数据集在城市道路图像上分割出30个分类,数据集中每个像素属于某个分类,这30个分类被分为8组,并被标注不同的颜色。在Cityscapes的benchmark上,只采用19个种类进行模型性能评价。Citysacpes 数据集和 PASCAL VOC 数据集一样使用 intersection-over-union(IoU)作为性能评估的指标。在深度神经网络计算出的分割结果中,某一分类的像素集合记作 P,原始图像中属于该分类的像素集合记作GT。则该类的IoU的计算如下:
在此基础上,计算各个分类的IoU的平均值,可得到mIoU作为模型综合性能的评价指标。
4 实验与结果分析
在Cityscapes数据集上训练了深度图像分割模型,验证该算法的效果,并与Cityscapes的Benchmarks中存留的FCN-8s图像分割网络的结果进行对比。
训练使用的深度学习服务器,软硬件配置为:
CPU:双路 Intel Xeon E5-2683 V3 2.0 GHz ;
内存:128G DDR4;
GPU:双路 Nvidia GTX1080Ti 2x12G;
硬盘:Inetl 240G SSD;
OS:windows 10;Tensorflow:1.7;CUDA:9.0。
4.1 實验参数
实验中将Cityscapes数据集中5 000张细标注的数据分为三类,其中训练集3 000张,验证集500张,测试集1 500张。学习30个分类中的19类,并将其余的分类归并到未标记类。为加快深度学习收敛速度,将训练集中的图像裁剪为800 dpi×800 dpi。算法采用mini-batch随机梯度下降算法,batch-size设置为12,初始学习率为0.01,动量系数为0.9,每迭代10个epoch后,学习率变为先前的1/3,总共迭代100个epoch。
4.2 结果分析
表1计算了部分分类的 IoU 评价标注。与 FCN-8s 比较,可以看出,在天空、道路等大像素分类目标上,二者在分割上的性能差异并不大。但在人的分割方面,取得了比较好的成绩,Rider 和 Person 都取得了比 FCN-8s 网络更好的成绩。
这是由于FCN网络中使用池化层进行降维操作,不可避免在图像像素上造成损失。深度分割网络取消了池化层,采用空洞卷积进行最后一步降维,保留了像素在小尺度上的特征,因为在小尺度像素目标上分割效果更好。为进一步测试模型在城市道路上语义分割效果,在采集到的城市道路数据集上进行了测试。一般而言,不同的数据间之间训练测试结果有差异性,这是因为不同的数据集存在空间分布上的差异,通过在采集到的华中科技大学附近城市道路数据集的测试表明,两者在空间上的分布具有一致性,故Cityscapes数据集能较好地表征城市道路场景的图像数据特征。
5 结论
该文针对城市道路图像分割所面临的多目标、多尺度、边界复杂等问题,提出了一种高精度、高效率、占用资源合理且行之有效的语义分割方法。该模型由特征编码器和特征解码器两部分组成。在解码器部分,使用新的基于学习的上采样方法,提高用于预测的特征图的精度,改善图像分割的边缘分割精确度,有效提高深度图的获取精度。实验结果表明,优化后的深度图在视觉效果上与标准深度图更加接近。定量评价显示,优化后深度图较原始深度图PSNR值更高,MSE、BP值更低。
参考文献
[1]孙志军, 薛磊, 许阳明, 等. 深度学习研究综述[J]. 计算机应用研究, 2012(8):2806-2810.
[2]张冬忠. 基于模糊神经网络的智能车辆自动驾驶方法研究[D]. 西安:长安大学, 2017.
收稿日期:2022-02-21
作者简介:樊天宇(1997—),男,硕士,研究方向:深度学习与自动驾驶。
