基于交叉熵的1位DAC大规模MIMO预编码方案
2022-02-13张航宇廖方圆李勇朝
张航宇,张 锐,廖方圆,2,李勇朝
(1.西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2.中国电子科技网络信息安全有限公司,四川 成都 610093)
作为未来移动通信关键技术之一的大规模多进多出(Multiple-Input Multiple-Output,MIMO),通过在基站端配备几十甚至上百个天线单元,可大幅度地提升系统的空间分辨率,显著地提升频谱效率、能量效率和可靠性,并扩展网络覆盖范围[1-2]。然而每根天线需通过射频链路与基带相连,大量的射频链路导致系统的功率消耗和硬件成本急剧增加[3],对大规模多进多出系统的实际部署与应用带来了巨大的挑战。
针对射频链数多导致能耗和成本过高这一问题,可采用模拟数字混合处理的系统架构以大量减少射频链路的数目[4]。但该系统下,能够同时服务的用户数量与射频链路数目相同,使系统的服务能力降低;而且在宽带的情况下,所有子带的信号都要经过相同的模拟端处理,自由度低,无法充分发挥宽带信号的优势[5]。同时,大规模多进多出系统的功耗主要来源于高精度的模数转换器(Analog-to-Digital Converter,ADC)、数模转换器(Digital-to-Analog Converter,DAC)及基带数字处理部分[6]。一方面,模数转换器、数模转换器的功耗与其量化位数呈指数关系[7];另一方面,基带数字处理的功耗近似与模数转换器、数模转换器量化位数的平方呈线性关系[8]。由此可见,模数转换器、数模转换器的量化位数在很大程度上决定了系统的功率消耗。而大规模多进多出系统每个射频链路的上下行分别都要装配一对量化器,如果都采用高精度的模数转换器、数模转换器(典型值为10位或更高),将会极大地增加系统的功耗。因此,装配低精度的模数转换器与数模转换器可以大幅度地降低大规模多进多出系统的功耗和硬件成本,尤其是采用1位量化的模数转换器、数模转换器[9-10]。
对于装配低精度数模转换器的大规模多进多出系统下行传输,低精度数模转换器的量化误差大,导致预编码后符号失真严重,降低了系统的性能。为了保证下行传输的性能同时降低能耗,研究低精度数模转换器对系统的性能影响及相应的预编码方案设计至关重要。考虑装配低精度数模转换器的多进多出系统,文献[11]中基于最小均方误差准则设计了线性预编码方案,仿真结果表明,在高信噪比、小到中规模的多进多出系统、4到6位的数模转换器精度下,该方案优于传统的线性预编码方案。采用1位数模转换器的大规模多进多出多用户场景下,文献[12]指出采用最大比值传输预编码时,当发送天线数目远大于数据流数时,能够实现以较低的失真水平进行信号检测;文献[13]分析了采用迫零预编码时系统的性能,结果表明,当天线数量和用户数量的比值比较大时,由1位数模转换器引起的每根天线上符号的失真将会被平均化;文献[14]表明,在基站端装配大约2.5倍的天线数目可以达到与装配理想数模转换器相同的和速率。文献[15]推导出了低精度数模转换器下迫零、最小均方误差及最大比值传输3种线性预编码的可达速率与数模转换器量化位数的近似表达式,在1位数模转换器的情况下,所得结论与文献[13]相同,即1位数模转换器所能达到的性能取决于天线和用户设备数量的比值。上述文献分析了大规模多进多出系统装配1位数模转换器的可行性,并给出线性预编码下系统性能的理论分析结果,为系统的参数选取提供了理论依据。线性预编码算法的复杂度低,但由于没有考虑低精度数模转换器量化的影响,导致量化后符号失真严重,误比特率极度下降,且误比特率随着信噪比增加而过早地达到饱和。
非线性预编码将低精度数模转换器量化的影响考虑到预编码的设计中,结合信道信息和发送符号对量化后的结果直接进行设计,可实现误比特率性能的大幅度提升。文献[15]提出了基于半正定松弛、均方无穷范数松弛以及球形解码的非线性预编码求解算法,这3种方法的性能都优于线性预编码,但这些算法的复杂度高。文献[16]中考虑公平性,以最小化所有用户中最大的符号均方误差为求解目标,并采用了半正定松弛法进行求解。文献[17-18]中均采用了基于交替最小化框架进行预编码向量的求解方法,其中文献[18]中为非线性预编码后的符号加了可以为零功率的约束,从而最终使用小于天线数目的射频链进行数据发送,以实现能耗的进一步降低。
考虑到1位数模转换器下预编码向量中的各个元素经过量化后属于固定的集合,且集合元素数目少,为了降低非线性预编码算法的复杂度,笔者从组合优化的角度将1位数模转换器下的非线性预编码问题重新建模,提出了基于交叉熵的求解算法。首先,基于概率分布函数产生初始样本;然后,通过选取精英样本并提取其参数特征进行概率分布的更新;最后,逐步迭代直至收敛得到预编码向量。这种方案的误比特率性能在高信噪比下优于现有方案,且对信道估计错误具有鲁棒性。所提算法与文献[17]中基于交替最小化框架的算法具有相同数量级的复杂度,但易扩展至装配多位数模转换器的大规模多进多出系统。此外,对于中小规模多进多出系统,所提方案的误比特率性能增益明显,尤其适用于由多个分布式部署的低成本、低功耗接入点所组成的无蜂窝大规模多进多出系统[19]。
1 系统模型
图1所示的是单小区多用户大规模多进多出系统,基站用M个天线在相同的时频资源为U个单天线用户服务,每个射频链路均装配一对1位量化的数模转换器。考虑瑞利衰落信道,即信道状态信息H∈CU×M中的各元素独立且每个元素均为服从零均值、单位方差的循环对称复高斯变量。

图1 1位数模转换器大规模多进多出系统模型
假设发送给用户的符号给定,表示为s∈CU×1且满足E(ssH)=IM。基站利用下行信道状态信息H将发送符号s预编码为M维的复向量z=[z1,…,zM]T∈CM×1:
z=F(H,s) ,
(1)
其中,E(·)表示求期望运算;F表示预编码映射,具体指预编码后的符号z与发送符号s和下行信道H间的映射关系。预编码后的符号z需满足平均功率约束:
E(zHz)≤P,
(2)
其中,P表示预编码后符号z的最大平均功率。
预编码后符号z经过1位数模转换器量化的处理,可被表示为
x=Q(z)=Q(Re{z})+jQ(Im{z})=(P/(2M))1/2(sgn(Re{z})+j sgn(Im{z})) ,
(3)
其中,经过1位量化后的符号x=[x1,…,xM]T,Q(·)表示1位量化操作,Re{·}表示取实部,Im{·}表示取虚部,sgn(·)表示符号函数。可以看出,z中的任一元素zm的实部和虚部分别被量化,因此1位量化对应输出xm的集合可被定义为
(4)
用户接收的信号y=[y1,…,yU]T可被表示为
y=Hx+n,
(5)

文中关于矩阵及其运算采用如下符号定义:IM表示维度为M的单位矩阵;CU×M表示U行M列的复矩阵域;(·)T表示向量或者矩阵的转置;(·)H表示向量或者矩阵的共轭转置。
2 非线性预编码设计
装配1位数模转换器可以大幅度地降低大规模多进多出系统基站的功率消耗,简化发射端的硬件配置。然而,由于没有考虑量化影响,线性预编码后的符号经过1位量化数模转换器后会严重失真,导致系统性能下降。由上节描述的系统模型中可知,经过1位量化后的输出属于固定集合,因此可以直接对1位量化后的符号进行选择设计,将量化影响考虑在内,提升系统的性能。这个结果可通过非线性预编码算法来实现,其主要思想是建立并求解最小化接收信号和1位量化后信号的均方误差问题。但是,现有的基于凸松弛和交替框架的非线性预编码算法的复杂度高。笔者从组合优化的角度对该问题重新建模,提出了基于交叉熵的非线性预编码算法,可快速地收敛。
2.1 基于交叉熵算法的非线性预编码方案
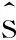
(6)
其中,‖·‖2表示二范数。此时,非线性预编码问题可以被表示为
(7)
其中,L(x,β)表示要求解的目标函数,R表示实数域。当预编码后的符号向量x给定时,式(7)为关于β的二次函数,经过求导求解,得到β的最优解为
(8)
将式(8)带入式(7),得
(9)
由于x中元素取自集合χ1,该问题可以看成是一个离散组合优化问题,共有4M种可能的组合,属于NP(Non-deterministic Polynomial)难问题。这意味着对于天线数目比较多的情况,没有有效的算法求解。交叉熵算法针对组合优化问题可以快速求解[20]。笔者采用交叉熵算法来求解预编码向量,为了方便表示,将该复值问题转化为一个等效的实值问题,并进行如下定义:
(10)
此时式(9)的优化问题转化为
(11)

交叉熵算法求解预编码向量的具体流程如方案1所示。
方案1基于交叉熵算法的非线性预编码方案。
输入:发送信号s,实数化的信道矩阵HR,候选的数量K,精英的数量Kelite。




(12)
第5步更新概率分布p(i+1),其是交叉熵算法的关键步骤,更新方法如下所示。
在交叉熵算法中,其主要思想是利用得到的精英样本最小化交叉熵的值去更新下一次迭代的概率分布p(i+1),以使算法达到收敛。该过程可以被表示为[21]
(13)

(14)

(15)
令式(15)为零,得第5步更新概率分布的计算式为
(16)
对于装配多位数模转换器的系统,由于量化后的标签属于有限集合,根据文献[20]可将量化输出进行编码,将预编码问题建模为组合优化问题。与1位数模转换器类似,可首先根据量化的输出集合建立与交叉熵算法迭代所需概率向量的映射关系,然后采用交叉熵算法进行求解。针对装配a位数模转换器的系统,第i个预编码后的符号经过数模转换器量化的输出可以表示为
xi=lRe+jlIm,
(17)

(18)
其中,Δa表示a位量化时的量化间隔,应满足式(2)中的功率约束。量化后的标签li可通过式(19)线性组合:
li=[2-1Δa,…,2a-2Δa][λ1,…,λa]T,
(19)
其中,λ1,…λa∈{1,1}。此时,可以看出[λ1,…,λa]为交叉熵算法迭代所需的概率向量,求解非线性预编码问题便转化为求解向量[λ1,…,λa]的组合优化问题。与1位数模转换器下的情况相同,可采用交叉熵算法进行求解。
2.2 收敛性及复杂度分析

(20)

对于所提方案的复杂度,由方案1的迭代过程可以看出其复杂度主要来源于步骤(2)、步骤(4)和步骤(5)。其中,步骤(2)计算均方误差的复杂度主要是矩阵向量的乘法复杂度,为O(KM2);步骤(4)计算权重的复杂度为O(Kelite);步骤(5)进行概率更新的复杂度为O(2MKelite)。假设总共进行了I次迭代,则总的复杂度为O(I(KM2+Kelite+2MKelite)),一般交叉熵算法中K不需要很大且快速收敛[22]。
而文献[15]中的半正定松弛法的复杂度为O((2M+1)4.5),均方无穷范数松弛的复杂度为O(2(k1M3+k2M2)),其中k1,k2分别为其算法两步迭代的次数。文献[17]交替方向乘子法的复杂度为O(IADMMM2),其中IADMM表示迭代次数。可以看出所提方案的复杂度低于半正定松弛法和均方无穷范数松弛,与交替方向乘子法的算法相当。
3 仿真结果与分析
本节先分别在中规模和大规模多进多出场景下,仿真比较所提出的基于交叉熵的预编码算法、最大比合并量化预编码算法、最小均方误差量化预编码算法、迫零量化预编码算法、文献[15]中提出的基于半正定松弛预编码算法和均方无穷范数松弛预编码算法、文献[17]提出的交替方向乘子法的预编码算法在装配1位数模转换器时系统的误比特率性能,并以无限精度迫零预编码算法作为性能上界;接下来同样在1位数模转换器下仿真比较了各预编码方案对信道估计错误的鲁棒性;最后仿真了所提交叉熵算法在1位、2位和3位数模转换器下系统的误比特率性能。
在基站端16根天线、4个用户及QPSK调制下,当K=200,Kelite=40时,误比特率曲线如图2所示。可以看出,在1位量化的影响下,线性量化预编码的误比特率随着信噪比的增加逐渐趋于饱和。由于针对1位量化后的符号进行设计,非线性预编码的性能优于线性预编码。在中规模多进多出场景下,所提预编码方案的性能在高信噪比时优于现有方案,而复杂度与交替方向乘子法相当。

图2 16根天线4个用户下误比特率曲线
在基站端128根天线、20个用户及QPSK调制下,当K=500,Kelite=200时,误比特率曲线如图3所示。可以看出,与中小规模多进多出系统相似,当信噪比增大时,线性量化预编码性能也逐渐趋于饱和。随着信噪比的增加,非线性预编码有显著的性能提升,且各非线性预编码方案性能一致。这是由于随着天线数目的增加,1位量化的影响变弱且可通过非线性预编码算法有效地补偿。所提方案的迭代次数较少,且随着天线数目的增加,所提出算法所需的样本数K不会大幅度增加,一般取值为200~500。

图3 128根天线20个用户下误比特率曲线

在基站端128根天线、20个用户信噪比为5 dB及QPSK调制下,误比特率随信道估计错误曲线如图4所示。可以看出,非线性预编码优于线性预编码,在非完美信道状态信息下非线性量化预编码也适用,且所提方案对信道估计错误的鲁棒性与现有非线性预编码方案相当,具有稳定性。

图4 128根天线20个用户下鲁棒性曲线
在基站端16根天线、4个用户QPSK调制下,系统分别装配1位、2位、3位数模转换器时,误比特率曲线如图5所示。可以看出,随着量化位数增加误比特率逐步降低,所提方案可扩展至装配多位数模转换器的系统。
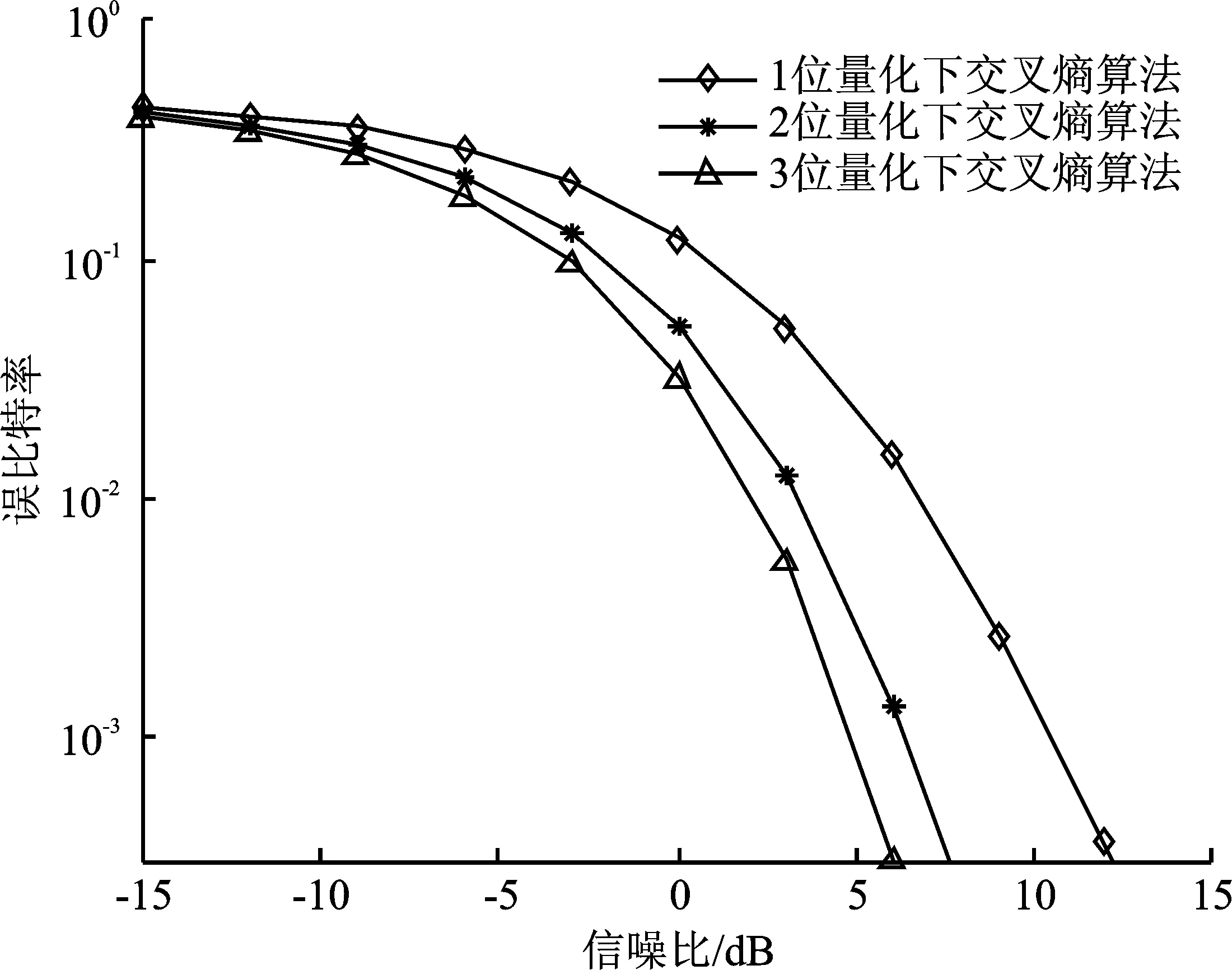
图5 不同量化精度DAC下误比特率曲线
4 结束语
针对1位数模转换器下大规模多进多出系统非线性预编码问题,笔者提出了基于交叉熵的预编码方案。该方案在每次迭代中,通过更新预编码向量各元素的概率分布,快速收敛得到预编码结果。该方案在高信噪比下具有性能优势,性能稳定,且易扩展至采用多位数模转换器的系统。
