机器生成语言的质量评价方法综述*
2022-01-24秦颖
秦 颖
(北京外国语大学人工智能与人类语言实验室,北京 100089)
1 引言
生成可被理解的、流畅且符合语言环境和要求的自然语言是人工智能的重要体现。自然语言生成NLG(Natural Language Generation)广义上包含了所有机器生成语言的任务,涵盖机器翻译、自动文摘、对话系统、故事和新闻写作、图像与视频标题生成等。根据生成语言时是否有参照,本文将NLG任务分为参照型和开放型2大类,如图1所示。

Figure 1 Main research directions of general natural language generation图1 广义自然语言生成任务的主要研究方向
参照型任务依据给定的文本或图像等生成语言。常见的生成需求有:(1)形式转换任务,例如机器翻译、图像/视频标题生成等。机器翻译将原文转换为另一种语言的译文;图像/视频标题生成任务为图像/视频生成相应的描述文字,即从图像语义表达变为文字语义表达。(2)语义压缩任务,主要包括自动文摘和句子简化等文本到文本的生成任务,在保持给定原文核心内容不变的情况下,实现语义压缩,生成更简短的文本。
开放型生成任务往往没有明确的生成参照,目的是实现基于自然语言的交流或创作,包括人机对话、机器写作和文本扩展等典型任务。
不难看出,从机器翻译、自动文摘、图像标题生成到人机对话、机器写作,生成任务的开放性逐渐增大。
近年来语言生成技术取得了令人瞩目的进展,而生成语言的质量评价问题越来越突出。首先,代价高、周期长、重用性差的人工评价仍作为各个任务的黄金标准(Gold Standard),自动评价的性能较差,无法代替人工。其次,语言质量评价的研究发展缓慢,已经成为制约NLG发展的、亟待解决的难点和瓶颈问题[1 - 4]。下面以机器翻译评测平台WMT(Workshop of Machine Translation)近15年的人工与自动评价方法的变化为例。2006年人工评价标准是译文流利度和充分性的5段打分,自动评价采用的是BLEU (BiLingual Evaluation Understudy)算法[5,6]。之后增加了人工排序和句法成分等更细粒度的评价,自动评价增加了METEOR、TER(Translation Error Rate)和GTM(Graph Theory Matching)等10种算法[7]。为保证人工评价的可信度,增加了多人评价的一致性衡量指标。2009年后不再对译文打分,只对不同系统译文进行排序,同时增加人工对机器译文的编辑,采取HTER(Human-mediated Translation Edit Rate)指标反映译文的质量[8]。为扩大人工评价的范围,2010年开始采取众包方式(Crowd-sourced)评估各个机器翻译系统。自动评价方面,2012年增加了无参考译文的质量估计[9]。之后又在人工排序评价前,加入了对系统译文的聚类处理。质量估计的粒度从句子级扩展到词汇级。2014年提出了新的排序模型,以更好地利用人工排序结果,质量评估的粒度也更多更细。2016年提出了单语直接评测法(Direct Assessment)[10],以避免参考译文对人工评价的影响。
生成语言质量评价是研发过程的重要反馈,不但反映生成系统性能,很大程度还能指导生成技术的研究,并且在训练时用于生成模型的参数调整[11]。
本文对近年来NLG任务的有关文献梳理后发现,不同任务的评价方法差异较大,同时又有很强的关联性,存在诸多可相互借鉴的思想和方法,有必要从整体上分析机器生成语言的质量评价问题,通过不同任务评价的对比,实现相互借鉴和融合,探索新的评价方法。
下文中,首先介绍人工评价的特点及关注的主要问题。然后是自动评价算法的介绍和优缺点分析,介绍开放的评价资源,并总结各算法之间的联系和交叉应用情况;最后是对机器生成语言质量评价的总结和展望。
2 人工评价
人工评价机器生成语言的质量具有主观性,尽管存在代价高、周期长、不一致和不确定等问题,人工评价目前仍是各个生成任务最准确、最认可的方式。人工评价主要有以下几个关注的问题:
2.1 评价者与评价结果的选择
常见的评价者有系统研发人员、语言专业人士和评价志愿者。评价者的选择影响评价的结果,选择不同的评价者时对评价质量的控制方法也不同。一般而言,系统研发人员和语言专业人士具有较好的背景知识,可信度相对较高。评价可由一人完成,也可多人评价。一人评价容易受个人主观因素的影响而不稳定[12]。多人评价的结果也会存在波动性。为保证多人评价的可信度,需要检查评价结果的一致性(Agreement)。衡量一致性的指标常用Kappa系数[13]。Kappa系数K的计算方法如式(1)所示:
(1)
其中,P(A)代表2个评价结果相同的概率,P(E)为基于随机猜测时2个评价结果相同的概率。Kappa系数越大说明一致性越高。Kappa系数在0.2以下,说明几乎没有一致性;0.2~0.4表示一致性较低;0.4~0.6表示一致性中等程度;0.6~0.8表示一致性较高;0.8以上代表几乎完全一致[14]。
基于众包平台如Mechanical Turk(MTurk)[15]和CrowdFlower(www. crowdflower.com)的志愿者评价是较为廉价的人工评价方式。众包评价的关键是评价结果的质量控制,著名的有MACE(Multi-Annotator Competence Estimation)工具[16]。针对评价者的投机取巧等作弊行为,基于MTurk平台也提出了多种控制质量的方法[17]。
2.2 内部评价与外部评价
内部评价(Intrinsic Evaluation)不涉及语言生成系统的设置和使用效果,是针对生成语言内在质量进行的评价,如语言的流利度、正确性和合理性等。而外部评价(Extrinsic Evaluation)考查的是生成系统达成目标的效度,是从系统的外部表现或系统作为其他应用的组成时对其他部分的影响角度进行的评价。显然,效度与系统应用和设计目的密切相关[18]。例如评价京东客服机器人对话系统Alphasales时,使用了客服电话转人工率、72小时内再次拨打的比例等与任务相关的外部评价指标。
2.3 评价方式
生成语言质量评价方式主要有分类(Classification)、评分(Scoring)和排序(Ranking)3种。一般认为,排序的评价难度低于分类和评分,且一致性也比评价分高,更适用于系统之间的比较[19]。此外,还有基于阅读时间的测量法(Reading-Time Measure),是根据评价者做出判断所需要的阅读时间来区分不同的文本质量[20],一般来讲,评阅时间越长,生成语言的质量越差,因此是一种间接的评价方式。
2.4 评价参考和事先培训
人工评价结果作为黄金标准也不是完美的,经常会出现评价者曲解评价任务,或给出不合逻辑的、异常的评价。为了让评价者更好地理解评价任务和评价标准,可通过事先培训来提高评价的一致性。另一种提高人工评价一致性的方式是给出参考答案,比如评价机器翻译时提供专家译文作为评价的参考,但这样的代价会更高,评价者的判断也容易受参考答案的影响。
还有很多复杂的因素会影响人工评价的一致性,如评价文本的长度和复杂度、评价的数目等。
2.5 人工评价标准
内部评价常根据不同任务从不同的语言质量维度进行,主要指标有连贯性、内容性、结构性、正确性、风格和整体质量等。任务不同,维度也有所不同,比如机器翻译一般不去评价译文的语言风格和内容的丰富性,重点关注译文的流利度和准确度。而评价幽默写作的质量时,则会增加文档的趣味性这一维度。评价基于多篇文档的机器文摘时,会增加信息冗余度这一指标。以下是机器翻译、自动文摘和人机对话任务常见的人工评价标准。
2.5.1 机器翻译
1964年美国语言自动处理咨询委员会ALPAC(Automatic Language Processing Advisory Committee)人工评价机器译文包括2个角度:一是译文的忠实度(Fidelity),二是译文的可理解度(Intelligibility)。我国863机器翻译评测中的人工评分标准包括充分性(Adequacy)和流利度(Fluency),评分共分6个等级。充分性衡量译文多大程度体现了原文的语义,流利度反映译文的可读性。
从2009年开始,WMT开始采取众包方式对参赛系统译文进行质量排序,并且在亚马逊网站上开发了著名的MTurk评价平台。基于该平台,可计算人工干预的翻译编辑率HTER,即人工修订机器译文成为可接受的译文需要进行的编辑量[15],值越小质量越高。
以上是内部评价机器译文质量的标准。外部评价机器翻译的质量,可让评价者基于机器译文进行阅读理解测试[15]。
2.5.2 自动文摘
自动文摘任务有多种类型[21]:根据文摘的来源文档数目可分为单文档文摘(Single Document Summarization)和多文档文摘(Multi-Document Summarization);根据文摘的策略可分为抽取式文摘(Extractive Summarization)和抽象式文摘(Abstractive Summarization)。而查询文摘(Query-Focused)和通用文摘(Generic)的区别是前者围绕查询相关的内容组成文摘,后者是以核心内容构成的文摘。从输出风格上又可分为标示型文摘(Indicative Summary)和信息型文摘(Informative Summary)。标示型文摘只需要给出文档最核心的主题,而信息型文摘则要列出全部主题的内容。针对不同的文摘类型,质量评价指标也各不相同。通用型文摘强调摘要内容的重要性(查询文摘重点是主题的相关性)、内容的覆盖面、句子的连贯性和信息冗余度等。
内部评价文摘质量的标准主要包括:无冗余(Non-Redundancy)、结构和连贯(Structure and Coherence)、重点突出(Focus)和整体质量(Quality)状况[22]。有的标准还包括文摘的语法性(Grammaticality)和参照清晰度(Referential Clarity)等指标[21]。
在文档理解会议DUC(Document Understanding Conference)上,评价者以句子为单位评价机器文摘的内容和语言质量,其中语言质量指标又进一步分为语法性(Grammaticality)、内敛性(Cohesion)和连贯性(Coherence)3个方面[23]。后来在文本分析会议TAC(Text Analysis Confe- rence)上,人工评价机器文摘采用了金字塔(Pyramid)法和反应度(Responsiveness)2种标准[24]。金字塔法要求人工标注文摘的内容单元(Content Unit),基于文摘中包含内容单元的多少和权重计算得分。反应度是根据用户信息需求对机器文摘进行的直观印象评分。
外部评价将文摘置于特定的应用中来评价文摘对系统的影响,如将文摘置于类似游戏场景下,利用猜测下一个词的游戏来评价文摘的信息含量[25];以及基于问答方式测试读者对文摘的理解程度[21]等方法。
2.5.3 对话系统
对话系统的类型很多(如图1所示),不同类型的对话系统功能和目的不同,评价标准差异较大[26]:(1)任务型对话系统强调对话的内容和策略,评价主要从任务实现(Task-Success)和对话效率(Dialogue Efficiency)2个方面进行,可分为用户满意(User Satisfaction Modeling)和用户模拟(User Simulation)2种评价模型。(2)社会型对话属于开放的、非结构化的交谈,传统的评价方式是图灵测试(Turing Test)。粗粒度的评价标准包括对话应答的恰当性(Appropriateness)和类人性(Human Likeness)。细粒度的评价标准涉及具体的语言特征,如对话的连贯性和主题的维持(Maintaining)、主题的深度(Topic Depth)、对话的广度(Conversational Breadth)等。(3)问答型对话的质量评价经常借鉴信息检索的评价标准,如准确率和召回率等。
文献[27]针对一个口语对话系统的生成话语设计了3项人工评价的内容:对话的信息度(Informativeness)、自然度(Naturalness)和总体质量(Quality)。可控聊天机器人的关键是对话的可控性,文献[28]提出的评价生成话语可控制性的指标有:重复性(Repetition)、特异性(Specificity)、应答相关性(Response-Relatedness)和提问能力(Question-Asking)。最近谷歌公司开放域多轮对话系统Meena的人工评价标准是回复的合理性(Sensibleness)和内容的具体性(Specificity)2个指标的平均值,即SSA(Sensibleness and Specificity Average)评价指标[29]。实验表明,SSA与人们对对话系统的喜好程度正相关。
人工评价聊天机器人的对话质量目前尚没有确定统一的标准。评价时通常会设计很多问题进行问卷调查,比如“对话进行是否顺畅?参与对话的程度如何?你认为对方是人还是机器人?是否愿意再聊一次?”等,这些问题主观性强,答案与受访者对系统的期望值有关。开放型对话系统的质量与多种因素有关,这些因素的权衡和比较在评价时十分重要。
为研究多轮对话中对整体对话质量有贡献的重要因素,文献[28]发现:(1)控制对话的重复率对所有人工判断极其重要;(2)问更多的问题能提升对话系统的吸引力;(3)控制特异性即减少使用通用话语,能提高聊天的吸引力、兴趣和感知;(4)评价者对非通用机器人的错误容忍度较低,当出现不流利或无意义的语句时评分通常较低。整体上,与用户体验关系密切的因素包括聊天内容的趣味性、对话的流利度、倾听性和少问问题等。
3 自动评价
廉价、快速、一致和可重用是自动评价的优势。自动评价算法通常与不同语言生成任务相适应。自动评价也分外部评价和内部评价。内部评价研究最多的是基于参考答案的评价,即将机器生成文本与人工参考答案进行相似度的比较,越相似的认为质量越高。
3.1 对自动评价算法的要求
根据NLG研究文献,本文归纳了自动评价算法通常要满足的要求:(1)算法有足够的质量区分度,能够区分不同质量的机器生成文本,或者能识别人工文本与机器生成文本。(2)可解释性,也就是区分不同质量的文本的依据要合理。(3)对评价系统和数据的依赖度,一般要求评价算法独立于系统和评价数据。(4)健壮性,即算法对评价数据变动的敏感程度[30],健壮的算法应能适应评价内容和领域的变化。(5)可重用性,算法应能重复使用,并保持多次评价结果不变。(6)可靠性,评价结果具有较高的可信度和准确度。
常用与人工评价的相关度来衡量自动评价算法的性能,如皮尔逊相关系数(Pearson Coefficient)、斯皮尔曼相关系数(Spearman Coefficient)和Kendall tau等指标,并用威廉姆斯测试(Williams’ test)[31]判断相关的显著程度。
3.2 不同任务的自动评价算法分析与资源
3.2.1 机器翻译
机器翻译中经典的、影响深远的自动评价算法是BLEU。评价的思想是比较参考译文和机器译文在语言形式上的相似度,计算单位是共现的n-gram数目。BLEU得分的计算如式(2)所示:
(2)
其中,pn是不同n-gram的钳位匹配率,wn是相应n-gram的权重,N一般取到4。BP是对长度小于参考译文r的机器译文c的惩罚因子。
BLEU算法的优点是与语言无关(Language Independent),简单易行。尽管一直作为WMT平台的官方评价标准(https://github.com/jhclark/multeval),BLEU评价还有很多问题,如当n较大时匹配的几率很小,n-gram得分经常为0,因此目前采取的是Smoothed BLEU[32],处理了n-gram为0的情况。但是,Smoothed BLEU仍未能改变机械匹配和n-gram稀疏带来的问题[33,34]。尽管算法可基于多个参考译文进行评价,但正确的译文往往是多样的,机械匹配难以评价同义或近义的译法。BLEU算法实际上是一种准确率评价指标。算法中译文长度的惩罚因子设定也具有主观性。针对上述问题,有不少改进研究,如EBLEU(Enhanced BLEU)算法[35]综合了准确率和召回率、调和平均以及多种长度惩罚因子指标;AMBER(A Modified Bleu,Enhanced Ranking)评价[36]则是对比了10种惩罚因子、4种匹配策略和多种译文输入类型而提出的。这些工作一定程度上提升了BLEU算法的性能,但评价结果还是受到不少质疑[37],很多文献指出BLEU得分并不足以反映译文质量的细微差异。
与BLEU类似的、基于语言形式匹配的评价算法还有不少,如NIST(National Institute of Standards and Technology)[38]和METEOR[39]等,这类自动评价算法的困难都是无法深入到译文的句法和语义层面进行相似度的比较,基于词汇或n-gram的匹配只能在较浅的层面上检查译文的充分性和流利度。
无参考译文时,自动评价算法一般要提取原文和机器译文的语言特征并结合外部资源进行译文质量的估计,判定词汇级、句子级的翻译质量等级或进行排序。WMT目前使用的机器翻译质量估计平台是QuEst[40]。QuEst+ +提取的语言特征已多达172种[41],但整体上质量估计的性能低于有参考译文的评价性能,更多的应用是检查机器译文中的特异点,进行译后编辑。
3.2.2 自动文摘
外部评价文摘质量时关注的是文摘对其他任务的影响。文献[42]提出了关联相关度(Relevance Correlation)评价方法,将生成文摘置于检索任务中,根据摘要而不是原文进行检索时,检索性能相对下降的度量被定义为关联相关度。
内部评价算法主要评价文摘的语言质量和信息度[21]。基于人工参考文摘的自动评价算法以内容的重叠程度为依据计算文摘的信息度[43]。常用的指标有句子共选(Sentence Co-selection)率、准确率、召回率、F1值和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[44]。其中,ROUGE是DUC会议的官方评价标准。与BLEU类似,ROUGE也是一种求n-gram重叠率的算法。ROUGE有很多变体,包括ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S和ROUGE-SU等[45]。基本ROUGE-N的通用计算如式(3)所示,评价工具也是公开的(https://github.com/summanlp/evaluation/tree/master/ROUGE-RELEASE-1.5.5)。
(3)
其中,N表示n-gram的长度,{ReferenceSummaries}表示参考文摘构成的集合,S代表字符串,Countmatch(gramn)表示生成文摘与参考文摘共现的n-gram最大数目;Count(gramn)的含义是参考文摘中全部n-gram的数目。ROUGE给出每一个n-gram的得分,是一种召回率指标。因此,ROUGE评价主要反映的是文摘涵盖信息的丰富程度。
ROUGE的优点是它是一种独立于语言的评价方法,实现简单。不同的变体体现了不同的评价侧重点,比如ROUGE-N能够反映词序关系,但当N值较大时,ROUGE得分通常很低,影响了评价的区分度;ROUGE-S计算的是skip-gram,即不要求连续的n-gram匹配,因而能更好地关注句子的内容而不是其中词汇的顺序,但是不连续区间的大小又不容易确定。
ROUGE比较适用于抽取式文摘,而不太适合抽象式文摘的评价。抽象式文摘强调的是核心观点和概念的抽取,可用不同于原文的句子使摘要内容更清晰[21],但ROUGE基于简单匹配难以反映生成句子的准确率和流利度。实际上,文章中承载信息的形式很多,包括事实词(Factoids)、相同意义单位和重述等,ROUGE只是从n-gram重叠率这个角度反映文摘的信息,算法同样不能深入到语义层面分析摘要的意义。
自动文摘任务较开放,人工参考文摘的变化较多。研究者们开发了多种基于相似度比较的评价算法,著名的有QARLA评价框架[46]。如果没有参考文摘做参照,评价算法往往通过比较机器文摘和原文档的语义相似度、核心内容的相似度来判断文摘的质量,例如求原文与文摘的主题相似度和词汇意义相似度的潜在语义分析法LSA(Latent Semantic Analysis)[47],以及基于词中心度的评价算法[48],中心词代表的是向量空间文档簇的中心。
3.2.3 图像标题生成
图像标题生成(Image Captioning)是计算机视觉领域的一个重要方向,属于跨模态的语言生成任务,也称图像标注(Image Labeling)。
针对同一幅图像,不同人给出的描述可能完全不同,但可能都是好的标题,因此图像标题生成任务的开放性更大。研究者们也尝试用BLEU、ROUGE等算法评价生成的标题,结果发现,基于人工标题和生成标题匹配的自动评价算法和人工评价结果很难有较高的一致性[49-51]。近年来出现了针对图像标题生成特有的评价算法,如CIDEr(Consensus-based Image Description Evaluation)[49]、SPICE(Semantic Propositional Image Caption Evalution)和神经网络判别模型等。CIDEr算法对n-gram利用TF-IDF(Term Frequency- Inversed Document Frequency)加权的方式计算生成标题与多个参考标题的一致性,力求得到不同参考标题共同关注的内容。
设第i幅图像的参考标题句子集合为Si={si1,si2,…,sim},m是句子数目,n-gramwk在参考标题的句子sij以及在生成标题句子ci中出现的次数分别为hk(sij)和hk(ci),基于TF-IDF对n-gramwk的加权值gk(sij)如式(4)所示:
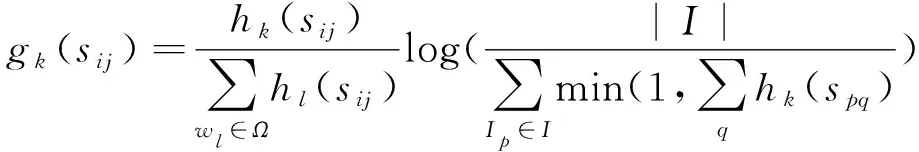
(4)
其中,Ω表示n-gram词表,I是图像集合。
长度为n的n-gram的CIDEr得分如式(5)所示:
(5)
其中,gn()为n-gram函数。
再结合n-gram的权重,最终CIDEr得分形式如式(6)所示:
(6)
CIDEr算法开源了评价工具包(https://github.com/tylin/coco-caption)和评价服务器[50]。算法与语言无关,评价思想也是比较n-gram的相似度,其特点是利用了加权方式反映出多样化的人工标题中共同关注的图像要素,其优缺点基本与BLEU和ROUGE的相同,不再赘述。
SPICE是从语义命题内容角度提出的评价图像标题质量的方法[1]。将标题解析为场景图(Scene Graphs),场景图对对象、属性和关系进行编码。图中的语义关系被视为逻辑命题的连接。基于图中对象类别、关系和属性构成的三元组判断生成标题和参考标题的语义相似度,最终以F1值表示标题质量的高低。SPICE算法也有公开的工具(http://panderson.me/spice)。SPICE借助于场景图解析标题所描述的对象、关系和属性,更能从图像内容层面实现评价,因此取得了较好的评价性能。SPICE算法适用于图像标题类较简短句子的评价,在机器翻译等复杂评价任务上的尝试还没有开展。
图像标题的质量评价还可以采用判别器模型[52]:输入图像、人工标题和生成标题,训练一个模型,根据概率得分判别是人工标题还是机器生成的标题。计算如式(7)所示:
(7)

3.2.4 对话系统
与机器翻译等有参照的生成任务相比,对话有以下的特点:首先生成语言的内容由系统决定,而不是参照文本或图像;其次对话语言多呈现口语化,句子相对简单,语言的复杂度比机器翻译小。自动评价对话质量的主要困难来自任务的开放性内容。
如果有人工应答做参考,可借用机器翻译、信息检索等评价指标如BLEU、DISTINCT1/2、Hits@K和knowledgeprecision/recall/F1等评价应答的质量[53]。不同指标反映了生成应答在不同层面的质量:F1反映的是应答在字级别的性能,BLEU得分主要反映词汇级的性能,而DISTINCT指标用于衡量应答的多样性。针对知识型对话的应答质量,文献[54]将生成的句子和系统知识在unigram层面计算准确率、召回率和F1值。也有基于多种距离函数来定义准确率、召回率和F1值的方法评价应答质量的研究[55]。
但是文献[27]指出,F1、BLEU和DISTINCT等指标用于评价基于数据驱动的、端到端方式的对话系统生成的应答时,只能略微地反映出人工评价的思想。算法评价在系统级有较高的可信度,但在句子级的可信度很差。不同算法的性能还与特定的数据和系统有关。
神经网络也被用于对对话质量进行评价,文献[56]尝试了对抗学习(Adversarial Learning)的评价方法:训练一个生成对抗网络,以判别器的性能反映对话的质量。但是,作者没有评估判别器的评分能否作为评价对话质量的可行性。有研究者指出,利用对抗学习评价对话质量的可行性并不乐观[57]。
针对开放性很强的生成任务,语言生成模型的困惑度PPL(PerPLexity)被用于评价人对于对话系统的喜欢程度。研究发现,PPL与人类喜欢程度负相关[29]。PPL其实是语言模型的评价指标,只能从统计意义上间接地体现生成应答的质量。PPL是一个指数值,模型的微小改变可能引起PPL的较大改变,PPL值的改变和人们对生成语言质量的感知并不成比例。
机器无法做到真正理解语言。对话系统所做的努力是让机器产出的结果看起来像是理解了人类语言后才发出的响应,越是接近自然人的响应结果,越能体现智能性,对话应答的质量也越高。因此,对话的外部评价主要从应答的适宜程度和类人程度角度进行。
3.2.5 其他语言生成任务
句子简化(Sentence Simplification)通过替换复杂单词、简化复杂的句法结构、删去次要成分等方式重写给定的句子,生成简单短小的句子。句子简化属于文本到文本的生成任务之一[58]。为衡量简短句的质量,文献[58]采用了可读性标准Flesch-Kincaid得分和SARI得分(可读性得分的计算工具 https://github.com/mmautner/readability)。BLEU得分也被用于评价,但文献[59]发现BLEU得分与人工流利度评分的相关度低,但正相关;与充分性评分的相关度更低,且负相关。
故事生成(Storytelling)属于创意写作。给定故事的开头等提示信息,由机器自动生成后续的故事内容。故事生成也是开放域的生成任务,质量评价十分困难。文献[60]用语言分析法评价故事生成的连续性。评价内容分为2项,第1项是独立于故事的质量评价,语言特征包括句子长度、语法、词汇多样性、词频和句法复杂度等8项。第2项是与故事有关句子的质量评价,语言特征包括词汇选择、风格匹配度和实体共指等。文献[61]基于一个常识故事结尾续写的语料库,提出了一个基于故事理解的自动评价框架——故事完型测试(Story Cloze Test):系统根据故事前面的句子完成最后一句的续写,实际上是从正反2种故事结尾答案中做出选择,类似完形填空,从而实现自动评价。文献[62]提出的自动评价无需和人工故事进行比较,而是用故事生成模型的困惑度和提示排名精确度(Prompt Ranking Accuracy)来评估流利度和输出对输入的依赖程度。
机器新闻写作的质量主要从读者的接受程度考虑。由于机器新闻写作同时有负面的应用,即假新闻(Fake News)的生成,因此,新闻写作方面较多的研究是检测新闻的真假[63],而不是评价生成新闻的质量。
文献[64]指出,一个能很好地预测机器写作与人工写作相似性的评价方法并不一定能成为一个好的预测器,好的预测器能够站在读者角度预测写作的有效性和有用性。
3.2.6 不同任务算法之间的联系与应用
NLG各任务评价之间有较强的相关性,一些自动评价算法实现了跨任务应用。本文汇总了经典自动评价算法在多种不同生成任务上的应用情况,如表1所示。其中,MT表示机器翻译,AS表示自动文摘,HD表示人机对话,IC表示图像标题生成,ST表示故事生成。

Table 1 Application of automatic evaluation algorithms in different tasks
基于参考答案和生成文本相似度的评价算法如BLEU、ROUGE等获得了最广泛的应用,成为多数自动评价算法的基础。尽管BLEU和ROUGE等在生成语言质量评价方面的结果并不理想,但仍然是官方认可的标准之一。图像标题的CIDEr评价算法需要很多人工参考标题来获得一致的评价内容,SPICE因为需要将句子解析为场景图,在复杂句子上的应用有限。PPL是一种统计算法,主要反映模型的多样性,并不能真正反映生成语言的质量,一般在缺少或不便提供参考答案时用困惑度来评价机器生成的语言的质量。
3.3 自动评价性能的影响因素与特点
自动评价的稳定性和可靠性影响因素与算法参数有关。与参考答案进行相似度比较的评价方法中,参考答案的数目是一个影响因素。研究表明[38],BLEU和NIST对参考译文的数目并不敏感,多个参考答案对评价性能的提升并不明显。同样的结论也出现在自动文摘的评价ROUGE算法中[12];文献[38]同时指出,评价样本的数量其实对评价结果的稳定性和可靠性影响更大,要得到具有统计意义的结果,样本要足够多。
算法性能还与特定的数据和系统有关。自动评价区分一般质量与高质量的生成文本比较困难。对于质量较差的生成文本,自动评价似乎与人工评价的评价结果更趋一致,但对高质量的文本和中等质量的文本,自动评价与人工的评价相关度较差[27]。文献[65]研究了多种评价算法的健壮性,更换场景、更换人物、共享场景和共享人物4种情况都对图像标题的评价结果产生影响。
最后,自动评价往往高估(Overestimate)生成文本的质量,部分得分较高的系统实际生成语言的质量并不好[27,66]。
4 结束语
机器正在以各种方式大量生成自然语言,生成语言的质量评价不可或缺又异常复杂。人工对生成语言的质量评价相对准确可靠,具有可解释性和诊断性等特点,但是代价高、周期长,且评价结果不可重用、不可扩展,从而严重制约了NLG的研发,迫切需要高性能的自动评价算法[67]。但是,现在还没有任何自动评价算法可以充分捕捉到文本质量的全貌,即能够代理人类的判断。一个好的评价算法不但能评价生成文本的质量,还能够兼顾答案的多样性(Diversity),这对于带有创造性、开放领域的生成任务而言尤其重要[67]。
语言质量评价应与文本生成任务分离,独立于生成任务的质量预测是更好的选择[4]。自动评价的研究遇到瓶颈,其主要困难从根本上看是评价模型的问题,如果自动评价采取模拟人工评价的思想和方法,模型的实现将十分复杂。因此,多数评价采取了与人工答案比较相似度的模型。利用相似度模型评价时,难点问题变成了相似度与语言质量的关系。一般性假设是,与人工答案越相似的质量越高,但这对于开放型评价任务并不总是成立。人工答案不是唯一的,数目也有限,质量评价时真正需要比较的应该是语义层面的相似度,语言形式的相似并不等于语义的相似,所以基于形式比较的自动评测都无法深入到参考答案的语义和语用层面。传统的语言学特征是研究语言形式相似的主要手段。另一种观点认为,文本质量是非构成式的,不是各个语言特征的叠加,而是文本的附属属性,是只能在特定上下文中对文本特征进行整体评估后才能获得的一种属性[68]。自动评价模型有待于提升。
第2个困难是评价机器生成语言的质量是一个动态的、源源不断的需求,并且与任务相关。加上多文档、多语种、多模态评价任务的出现,以及复杂评价因素如文本风格、个性化、情感倾向等的加入,无论是对自动评价还是人工评价而言,都面临巨大的挑战。各种评价算法一直是被动地去适应这些需求,领域适用性和稳定性不好,都未能从根本上解决语言质量评价的核心问题。
最近的自动评价研究体现出解决这些难题的一些思路。在相似度研究方面,除了利用传统的语言特征,也开始尝试新的语义表示方法,例如基于词嵌入的相似度比较,相比机械匹配而言,词嵌入能更多地捕捉语义,实现连续空间中的内容比较[65]。也有将文档之间的距离视为旅行代价,基于词汇移动距离WMD(Word Mover’s Distance)[69]求相似度的评价方法[22]。针对不同领域的评价,迁移学习的思想也受到关注,例如谷歌最近推出的评价机器翻译的BLEURT(github.com/google-research/bleurt)算法,可提高BLEU在不同领域的适应性和稳定性。
本文认为,自动评价研究的大致趋势可分为3个具体的方向:(1)新的评价模型的研究,最新的工作是利用深度学习的框架实现自动评价[70]。(2)不同评价方式的整合研究[18,24,46],由于不同的算法从不同角度捕捉了语言质量的不同方面,综合的模型可更全面地反映生成语言的质量状况。(3)定义更聚焦的评价算法以捕捉生成文本的特定方面,而不是进行笼统的质量评价,这样可以帮助我们追踪所关心的生成文本的某些重要的质量因素,比如流利度、多样性和重复率等。
本质上,机器生成语言的质量评价属于自然语言理解任务,全面准确地评价语言质量涉及的因素非常复杂,生成语言的质量评价比语言生成任务本身更有挑战性。
