基于残差密集网络层次信息的图像标题生成*
2022-01-24李军辉
王 习,张 凯,李军辉,孔 芳
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
1 引言
自然语言处理NLP(Natural Language Processing)和计算机视觉CV(Computer Vision)是人工智能领域研究的2大热点。当前,跨领域研究已经成为未来研究的一种趋势,引起了研究者极大的兴趣。图像标题(Image Caption)正是结合计算机视觉和自然语言处理的一种跨领域研究,该技术最早由Farhadi等人[1]提出,给定二元组(I,S),其中,I表示图像,S表示对该图像的描述,模型要完成I→S的映射,基于深度学习网络获取图像特征,然后输出该图像的标题内容。“看图说话”对正常人来说非常简单,但对于计算机来说是一项极具挑战的任务,计算机不仅仅要识别图像的内容,还要用人类的逻辑思维描述出人类可读的句子。
当前生成图像标题的主要方法是基于神经网络的方法,特别地,基于自注意力机制的生成模型取得了较好的性能,其中Liu等人[2]提出的双向注意力机制具有较好的性能。但是,在传统的深层网络中,层之间以线性方式进行堆叠,不同的层能够捕获不同的语义信息,导致低层语义信息无法在高层中体现,没有得到充分利用。
因此,本文把Vaswani 等人[3]提出的Transformer(tf)模型作为基准模型,在此基础上融入残差密集网络,以捕获图像标题的浅层语义信息。具体地,首先,为了能够充分利用深层网络的层次信息,以及提取深层网络中的各个层的局部特征,本文提出LayerRDense(Layer Residual Dense)网络,实现在层与层之间的残差密集连接。其次,为了更好地融合图像特征和图像的描述信息,在解码端每层网络中的子层之间运用残差密集网络。在图像标题任务MSCOCO 2014数据集上的实验结果表明,本文提出的LayerRDense和SubRDense网络均能进一步提高模型的性能。
2 相关工作
生成图像标题的传统做法是利用图像处理的一些算子提取图像的特征,经过支持向量机SVM(Support Vector Machine)等分类得到图像中可能存在的目标对象[4]。然后根据提取到的对象及其属性,利用条件随机场CRF(Conditional Random Field)或者是一些指定的规则来生成对图像的描述。不难看出,这种做法非常依赖于图像特征的提取以及生成句子时所需要的规则,效果也并不理想。
受神经机器翻译的启发,将机器翻译中编码源文字的循环神经网络RNN(Recurrent Neural Network)替换成卷积神经网络CNN(Convolutional Neural Network)来编码图像,图像标题生成问题便可转化为机器翻译问题。从翻译的角度来看,此处的源文字就是图像,目标文字就是生成的标题。因此,图像标题生成采用的神经网络模型通常由编码器和解码器2部分组成。编码器使用CNN将图像转化为一个固定长度的向量,也称图像的隐层表示;解码器使用RNN将编码器输出的固定长度的向量解析为目标语言句子。Vinyals等人[5]提出了神经图像标题NIC(Neural Image Caption)模型,该模型将图像和单词投影到多模态空间,并使用长短时记忆网络LSTM(Long Short-Term Memory)生成英文描述。Karpathy等人[6]利用片段图像生成局部区域的标题。Mao等人[7]在基于传统CNN编码器-RNN解码器的神经网络模型的基础上,提出使用多模态空间为图像和文本建立联系。Jia等人[8]提出了gLSTM模型,该模型使用语义信息指导长短时记忆网络生成标题,解决了图像仅在开始时传入LSTM的问题。在此基础上Wu等人[9]提出了att-LSTM模型,该模型通过图像多标签分类来提取图像中可能存在的属性,解决了总是使用全局特征作为图像特征的问题。Xu等人[10]将注意力机制引入解码过程,使得标题生成网络能够捕捉图像的局部信息。然而,这种加入注意力的方法也存在一些缺点,即每个词都会对应一个图像区域,但是有些介词、动词等并不能对应实体,除此之外注意力机制是基于卷积层的加权,映射到图像特征,会使得图像变得模糊且不能准确定位图中对应区域。为了解决这些问题,Lu等人[11]提出了一种自适应的注意力机制,使模型自主决定根据先验知识(模板)还是根据图像中的区域来生成单词。
前面所有工作都是针对解码器RNN进行研究,然而CNN也是不可忽略的一个重点,Chen等人[12]使用卷积层的不同通道做注意力计算,同时还利用空间注意力机制。Li等人[13]构建了首个中文图像摘要数据集 Flickr8kCN,并提出中文摘要生成模型 CS-NIC(Crowd Sourced-Neural Image Caption),作者使用GoogleNet[14]对图像进行编码,并使用LSTM对图像描述生成过程建模。Rennie等人[15]提出SCST(Self-Critical Sequence Training)模型,利用强化学习生成有区别度的标题。Anderson等人[16]提出了Bottom-Up and Top-Down模型,该模型结合Bottom-Up和Top-Down视觉注意力机制,Bottom-Up机制用来提取视觉特征,Top-Down机制用于关注词向量特征。
上述模型均属于使用CNN编码器-RNN解码器的框架,虽然RNN解码器基于视觉特征并且使用注意力机制生成标题,但是这种方法只是考虑了图像和标题多模态间的相互作用,没有考虑图像特征以及标题内部间的交互作用。本文使用的基准模型Transformer是一个深层的神经网络模型,能够在统一的注意力区域内同时捕获模态内和模态间的相互作用的优点来弥补RNN的缺陷。本文参考Zhang等人[17]将残差密集网络运用到图像处理问题中以解决像素分辨率问题,以及Shen等人[18]将密集运用到机器翻译模型的Encoder端和Decoder端以获取密集信息流,提出2种方法将Dense加入到基准模型中,探索层次信息之间的融合,以充分利用层次的特征信息。
3 基准模型:Transformer
3.1 模型架构
Transformer是基于自注意力机制的图像标题生成模型,由编码器和解码器构成,如图1 所示。编码器由L个相同层堆叠组成(实际中设置L=6),每层都有2个子层,第1个是多头自注意力MHA(Multi-Head self-Attention)机制子层,第2个是前馈网络子层。2个子层的输出采用残差连接并进行归一化,即LayerNorm(x+Sublayer(x)),其中x为上一个子层的输出。
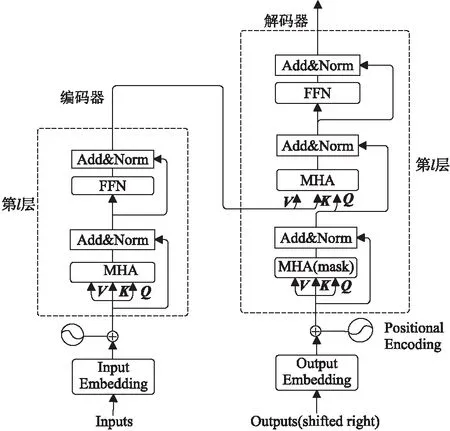
Figure 1 Structure of Transformer图1 Transformer 模型结构
Transfomer模型的编码器-解码器由若干个多头自注意力机制堆叠而成,单个“多头注意力机制”又由多个点积注意力机制组成,如式(1)所示,最后将h头的注意力计算结果进行拼接,再进行1次变换得到的值便是多头自注意力机制提取的特征值,如式(2)所示。
(1)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(2)
1≤i≤h
(3)

3.2 Transformer在图像生成标题中的应用
为了将Transformer模型更好地应用在图像处理中,类似于Transformer在机器翻译任务中的应用,本文将二元组(I,S)中的I看作源端,S看作目标端。Transformer模型的结构高度契合目标任务,其注意力机制能够同时捕捉图像特征内部间的相互作用、图像和标题间的相互作用以及标题序列内部的相互作用。
图像标题生成的Transformer结构如图2所示,整个网络结构由图像编码器和标题序列解码器组成。图像编码器将图像作为输入,使用CNN网络提取视觉特征,然后将视觉特征经过线性层转换之后输入给编码器,通过自注意学习获得有意义的视觉特征。解码器循环接收编码段输出的视觉特征和前一个单词来预测下一个单词,同时通过自注意力机制学习标题序列间的相互作用。为了使整个网络结构看上去更简洁,本文使用Encoder和Decoder分别表示图1中的编码器和解码器。

Figure 2 Structure of Image caption generation model图2 图像标题生成模型结构
4 基于残差密集网络的图像标题生成
本节分别描述在图像标题生成模型中融合残差密集网络的2种方式。
4.1 LayerRDense网络结构
第3节中提到,Transformer的Encoder和Decoder都由L个独立层组成,为了更好地融入层次特征信息,本文提出残差密集网络Layer RDense,将每层的输出融合起来,如图3所示。其中,Hl表示第l层的输出,1≤l≤L;X为位置编码和词向量相加的输出;Layer(·)为每层包含的函数,包括Multihead(MHA)、Feed-Forward(FFN)和Layer Normerlization(Norm)等。
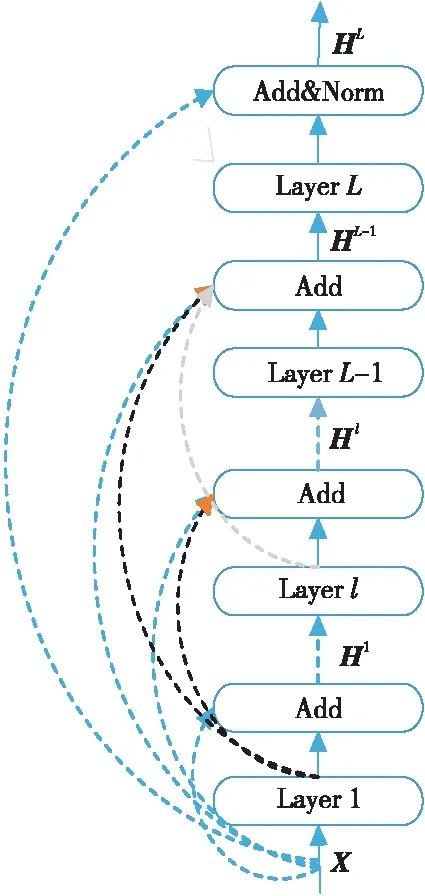
Figure 3 Structure of LayerRDense图3 LayerRDense结构
尽管本文提出的Layer RDense会带来与网络的额外连接,每层的特性数量更少,但该结构鼓励特征重用,并且模型每层特征可以更紧凑、更具有表现力,更容易进行特征融合以及残差学习。特征融合是将所有层的输出和原始输入自适应地融合在一起。原始输入可以直接和所有层的输出加在一起,对于减少特征数是很重要的。融合公式如式(4)所示:
Hl=Layer(Hl-1)+Hl-2+…+H1+X
(4)
残差学习在残差密集网络中更近一步地改善了信息流。原始输入和每一层的输出直接连接到后一层,既保留了原始输入的性质,又提取了局部的密集特征。最终残差密集部分的输出如式(5)所示:
HL=LayerNorm(Layer(HL-1)+X)
(5)
其中LayerNorm(·)为层归一化。
本文将残差密集网络融入到Transformer中,主要在Encoder与Decoder端的L=6个独立层使用残差密集网络来充分利用层次特征。具体地,在第L层之前的所有层的输出进行密集连接;而在第L层,将此层的输出和原始输入进行残差连接,与以往不同的是,因在所有层进行密集连接会导致额外增加一些网络连接操作,在每层的子层中只做残差连接,即保持基准模型的其它操作不变。
4.2 SubRDense网络结构
本文所做的图像标题生成实验,训练的输入包含视觉特征和图像标题信息2个关键的输入信息。为了将图像标题的信息与图像特征更好地融合起来,本文提出在Decoder端加入残差密集网络SubRDense,如图4所示。

Figure 4 Structure of SubRDense图4 SubRDense 结构
每个子层的输出如式(6)~式(8)所示:
S1=LayerNorm(MultiHead(X,X,X)+X)
(6)
S2=LayerNorm(MultiHead(S1,E,Z)+S1+X)
(7)
S3=LayerNorm(FFN(S2)+S1+X)
(8)
其中,S1,S2分别表示各个子层的输出;S3∈Rn*dmodel,n为句子长度,dmodel为模型输出维度;FFN表示Feed-Forward;E和Z表示来自Encoder端的输出。
从图4中可以看出,Decoder端中第1个子层计算句子Self-Attention,第2个子层计算Context-Attention,在此层中,视觉特征所对应的句子标题信息第1次进行融合处理。第3个子层计算Feed-Forward。由此可以看出,在Decoder端,图像的标题信息特征与图像特征会进行融合处理,为进一步强化两者的融合,在此基础上,加入残差密集网络,将图像特征与图像所对应的标题信息更进一步融合。
5 实验与结果分析
5.1 数据集
实验使用的数据集为MSCOCO 2014[19],本文使用Karpathy等人[6]的方法将MSCOCO 2014数据集分成训练集、验证集和测试集,其中训练集共有113 287幅图像,验证集和测试集各自有5 000幅图像,每幅图像都提供5句不同的英文标题。
本文使用BLEU-1~BLEU-4[20]、METEOR[21]、ROUGE_L[22]、CIDEr[23]和SPICE[24]共5种指标来衡量生成的图像标题的质量。其中,BLEU一般用于评测机器翻译的翻译质量,反映了生成结果与参考答案之间的N元文法准确率。METEOR测量基于单精度加权调和平均数和单字召回率。ROUGE_L与BLEU类似,它是基于召回率的相似度衡量方法。CIDEr是基于共识的评价方法,该指标将每个句子都看成文档,并将其表示为向量的形式,然后计算参考的标题与模型生成的标题的余弦相似度。SPICE是一种语义命题图像标题评估方法,评测有些句子虽然根据N元文法规则重叠度很低,但是表达的意思相近的情况,尽可能多地考虑到每句话的语义命题。通过将候选标题和参考标题转换为一种称为场景图的基于图的语义表示来评估标题质量。场景图显式地对图像标题中的对象、属性和关系进行编码,在此过程中抽象出自然语言的大部分词汇和句法特性。
5.2 实验设置
5.2.1 图像特征提取网络设置
视觉特征提取网络CNN(I)完成I→V(I)的特征映射,其中I为输入图像,输出为视觉特征。本文采用2种视觉特征。其中一种视觉特征使用ResNet-101结构[25]提取,此网络在大规模单标签分类任务ImageNet[26]上训练获得。实验使用ResNet-101的最后一层卷积层的输出经过平均池化层,将图像特征映射为(50,14×14,2048)的矩阵,再经过隐藏单元数为512的全连接层,将视觉特征映射为(50,14×14,512)的矩阵作为最终的视觉特征输入参数, 并且在整个训练模型的过程中,ResNet-101的模型参数不更新。另外一种视觉特征使用Faster-RCNN[27]提取。Faster-RCNN结构是在目标区域检测任务上进行训练生成的。本文同样使用Faster-RCNN最后一个卷积层的输出作为提取到的视觉特征。对于Faster-RCNN模型,本文使用和Anderson等人[16]相同的特征输入方式。
5.2.2 图像标题生成模型设置
图像标题生成使用Transformer模型,模型的隐藏状态长度均为512,词向量的长度为512,层数L=6,英文词汇表的大小为9 487,未登录词用〈UNK〉表示,词向量和模型参数的初始值在[-0.1,0.1]按均匀分布得到,优化器选用自适应估计(Adam)算法[28],学习率为5×10-4,批处理的大小为50,测试时批处理大小为10,测试时使用大小为4的柱状搜索算法[29]。训练过程中,每一层使用Dropout正则化来提高模型的泛化能力[30],训练使用交叉熵损失函数,采用最大步长为20个epoch 的早停策略。
5.3 结果分析
本节分别展示与分析本文提出的LayerRDense和SubRDense的实验结果。
5.3.1 LayerRDense的实验结果
表1给出的视觉特征是使用Faster-RCNN提取的。表1中*_En指LayerRDense只在Encoder上使用,*_De指LayerRDense只在Decoder端使用;*_ED指在Encoder端和Decoder端都使用LayerRDense。表2给出的视觉特征是使用ResNet-101提取的。从表1和表2中可以发现,无论视觉特征的提取采用哪一种网络,只要在Encoder端和Decoder端都使用残差密集网络,评测值相比于Base均有提升,说明层与层之间信息重用,能够使信息更具有表现力,而且各层之间的信息传递能力有所增强。当视觉特征的提取使用Faster-RCNN网络时,评测值的提高程度要比使用ResNet-101网络时高,例如使用Faster-RCNN网络提取时CIDEr值从114.2提高到115.5。而使用另一种网络,CIDEr从107.1提高到107.7,说明视觉特征的提取使用不同的网络也会导致效果的提升程度不同。
为了更进一步地探索层次信息,把在层之间融入残差密集网络的实验分解开。第1个实验仅仅在Encoder端使用残差密集网络,Decoder端不使用;第2个实验只在Decoder端使用残差密集网络,Encoder端不使用。当使用Faster-RCNN网络提取视觉特征时,从表1中可以发现,只在Decoder端使用残差密集网络,效果可以与在Encoder端和Decoder端都使用残差密集网络相当。当使用Resnet-101提取视觉特征时,只在Decoder端使用残差密集网络,从表2中可以发现,CIDEr值从107.1提高到107.8,BLEU值也均有一定的提升。从以上分析可以看出,在Decoder端进行低阶特征和高阶特征的融合,比在Encoder端和Decoder 端都使用残差密集网络的效果好,说明Decoder端图像特征和标题特征的融合更容易提取到丰富的层次信息,而且除去了在Encoder端额外的网络连接,训练的时间也会缩短。

Table 1 Experimental results of LayerRDense extracting visual features using Faster-RCNN

Table 2 Experimental results of LayerRDense extracting visual features using ResNet-101
5.3.2 SubRDense的实验结果
当使用Faster-RCNN网络提取视觉特征时,从表3和表4中可以发现SubRDense的效果,CIDEr值相比Base从114.2提高到115.8,其它的评测值也均有提升。其次,在每层中的子层之间使用SubRDense,评测的效果可以达到只在Decoder 端使用LayerRDense的效果。

Table 3 Experimental results of SubRDense extracting visual features using Faster-RCNN

Table 4 Experimental results of SubRDense extracting visual features using ResNet-101
综上,本文提出的2种网络,从实验的效果来看,2种网络的效果相当。但是,从直观的角度看,第2种网络明显比第1种的额外网络连接操作数少,训练时长也有所缩短。
5.4 图像标题质量分析
图 5 所示是标题模型的预测结果,从图5中可以看出,基准系统预测出来的标题,丢失了图像中所拥有的‘car’这个单词的对象,并将其误预测成‘meter’。而加入残差密集网络进行图像特征与图像标题的融合所得到的预测结果很显然能够把‘car’预测出来,且句子比较通顺。

Figure 5 Image and prediction result by model proposed in this paper prediction result图5 图像和本文所提的模型预测结果
6 结束语
本文将残差密集网络融合到基准模型中,探索了层与层之间的信息融合。从图像标题生成任务的角度,考虑将图像的描述信息和图像特征更好地融合起来,增强信息的传递能力。在LayerRDense中,当前的特征能够自适应地从先前和当前层的输出中学习到更有效的特征,并稳定地训练网络。本文从图像特征和图像标题信息更进一步地融合以及缩短加入LayerRDense的训练时长的角度出发,提出在基准模型中加入SubRDense,实验结果也表明,效果有一定的提升,训练时长相比于LayerRDense只在Decoder 端使用的训练时长也缩短了。
受注意力机制的启发,在未来的工作中,可以去探索对每层的输出信息的重视程度,比如给每层的输出信息分配一个权重,这样在训练过程中,可以了解每层信息对整个训练的影响程度,并进行增强或者削弱。
