装甲兵虚拟兵力战术对抗动作参数建模方法
2022-01-22田红亮董志明
田红亮,董志明,高 昂
(陆军装甲兵学院,北京100072)
1 引言
目前,装甲兵战术分队在与虚拟兵力进行对抗训练过程中,虚拟兵力战术对抗动作建模的参数主要有动作延迟和动作准确率,动作延迟和准确率可以作为衡量蓝军部队战斗力的两个有效指标(动作延迟越小,动作准确率越高,部队战斗力越强),可以通过调节动作延迟时间和准确率参数,来调节对抗对象的战斗力水平,进而可以循序渐进提升红军部队训练水平[1]。
现有技术中动作延迟主要采用两种方法进行仿真,一是完全不考虑动作延迟,即动作延迟Δt=0,二是随机生成动作延迟。动作准确率仿真中除火力打击环节采用蒙特卡洛方法仿真射击命中概率外,其余动作均没有考虑准确率。在不考虑动作延迟情况下,虚拟兵力的反应时间等于计算机的处理时间,远远超出人类的反应时间,导致虚拟兵力实力过于强大,而随机生成动作延迟,又与真实战术对抗中的动作延迟不相符,没有意义[2]。不考虑动作的准确率,会使虚拟兵力做出的所有动作都是准确的,而蒙特卡洛法仿真射击命中概率过于简单,没有考虑人的操作水平、战斗经验、目标的距离、速度、隐蔽性。
虚拟兵力战术对抗动作参数建模过程中动作延迟时间以及动作准确率设置不合理,导致装甲兵战术分队在与虚拟兵力对抗训练过程中训练场景不真实,实际训练效果不理想[1]。本文提出了一种基于神经网络的装甲兵虚拟兵力战术对抗动作参数建模方法,解决现有技术中虚拟兵力战术对抗动作延迟时间及动作准确度设置不合理的问题。
2 基本理论
根据OODA环理论,战术对抗动作可分解为感知类动作、共享类动作、决策类动作、指挥类动作、打击类动作,如图1所示[3]。其中感知类动作是指车长在装甲车内观察到敌目标并完成目标识别;共享类动作是指车长利用电台或指控信息终端将敌目标信息发送给上级;决策类动作是指上级车长接收下级发送过来的战术情况后进行判断并定下决心;指挥类动作是指上级车长利用电台或指控信息终端完成对下级下达指挥命令;打击类动作是指车长发现敌目标并指挥一炮手对敌目标完成火力打击[4]。
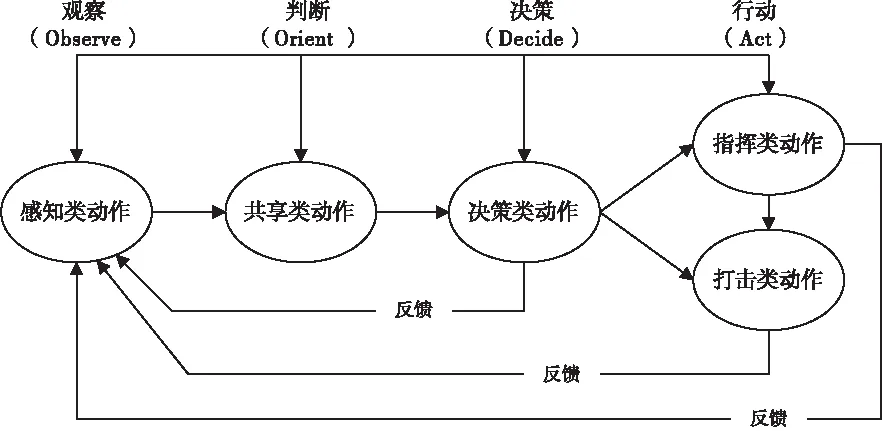
图1 按照OODA理论将战术对抗动作分解示意图
每类动作参数包括延迟时间和准确率两个参数,每类动作的延迟时间和准确率的影响因素表达式为:Xin(i=1,2,…,5;n=1,2,…,Ni)(Ni为第i类动作的延迟时间或准确率影响因素的个数)。
2.1 感知类动作影响因素
感知类动作影响因素包括车长等级、天气可见度、目标类型、车长行驶车速、距离目标的距离、目标的隐蔽方式等6种,表达式为X1n(n=1,2,…,6)。其中车长等级X11={特级,一级,二级,三级,初级}、天气可见度X12={(0m,500m),(500m,1000m),(1000m,5000m)}、目标类型X13={坦克,装甲车,无座力炮,地堡,机枪发射点,火箭筒}、车长行驶车速X14={(0km/h,20km/h),(20km/h,40km/h),(40km/h,60km/h)}、距离目标的距离X15={(0m,500m),(500m,1000m),(1000m,5000m)}、目标的隐蔽方式X16={暴露,利用掩体隐蔽,伪装,利用掩体隐蔽与伪装结合}。
2.2 共享类动作影响因素
共享类动作影响因素包括车长等级、通信设备操作友好程度、目标类型等3种,表达式为X2n(n=1,2,3)。其中车长等级X21={特级,一级,二级,三级,初级}、通信设备操作友好程度X22={非常容易,容易,难度适中,困难,非常困难}、目标类型X23={坦克,装甲车,无座力炮,地堡,机枪发射点,火箭筒}。
2.3 决策类动作影响因素
决策类动作影响因素包括车长等级、战术情况复杂程度等2种,表达式为X3n(n=1,2)。其中车长等级X31={特级,一级,二级,三级,初级},战术情况复杂程度X32={非常简单,简单,适中,复杂,非常复杂}。
2.4 指挥类动作影响因素
指挥类动作影响因素包括车长等级、战术情况复杂程度等2种,表达式为X4n(n=1,2)。其中车长等级X41={特级,一级,二级,三级,初级},战术情况复杂程度X42={非常简单,简单,适中,复杂,非常复杂}。
2.5 打击类动作影响因素
打击类动作影响因素包括车长等级、天气可见度、目标类型、车长行驶车速、距离目标的距离、目标的隐蔽方式等6种,表达式为X5n(n=1,2,…,6)。其中车长等级X51={特级,一级,二级,三级,初级},天气可见度X52={(0m,500m),(500m,1000m),(1000m,5000m)}、目标类型X53={坦克,装甲车,无座力炮,地堡,机枪发射点,火箭筒}、车长行驶车速X54={(0km/h,20km/h),(20km/h,40km/h),(40km/h,60km/h)}、距离目标的距离X55={(0m,500m),(500m,1000m),(1000m,5000m)}、目标的隐蔽方式X56={暴露,利用掩体隐蔽,伪装,利用掩体隐蔽与伪装结合}。
为使虚拟兵力更贴近实际,根据每类动作参数的影响因素,采集真实环境中各影响因素下战术对抗动作的延迟时间和准确率数据,构建样本库,建立并训练BP神经网络模型,进行参数数值计算,将计算得到的动作参数数值加载到虚拟兵力动作参数中,完成对虚拟兵力动作的建模。
3 方法步骤
基于神经网络的装甲兵虚拟兵力战术对抗动作参数建模方法,如图2所示,包括如下步骤。
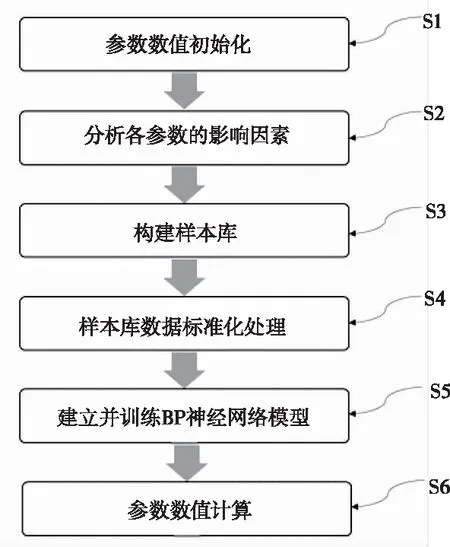
图2 装甲兵虚拟兵力战术对抗动作参数建模流程图
步骤S1:参数数值初始化:将装甲兵虚拟兵力对抗动作延迟时间T初始化为T=[T1=0,T2=0,T3=0,T4=0,T5=0],动作准确率A初始化为A=[A1=100%,A2=100%,A3=100%,A4=100%,A5=100%],其中Ti,Ai(i=1,2,…,5)分别表示战术对抗过程中的感知、共享、决策、指挥、打击五类动作的延迟时间和准确率。
步骤S2:分析各参数的影响因素:列出五类动作的延迟时间和准确率的影响Xin(i=1,2,…,5;n=1,2,…,Ni)(Ni为第i类动作的延迟时间或准确率影响因素的个数)。将具有连续值的影响因素划分为若干个区间,将具有离散值的影响因素划分为若干个等级。
步骤S3:构建样本库:采集真实环境中各影响因素下所述五类动作的延迟时间和准确率数据Yi(i=1,2,…,5),将具有连续值的动作延迟时间、动作准确率分别划分为若干个区间,与影响因素一同构建样本库{Yi|Xij(i=1,2,…,5;j=1,2,…,Nj)}。
步骤S4:样本库数据标准化处理:将样本库中的数据进行01编码处理,构建标准化的数据集。
步骤S5:建立并训练BP神经网络模型:利用标准化的数据集训练BP神经网络;BP神经网络模型通过交叉验证的方法确定网络模型的层数[5]。
步骤S6:参数数值计算,包括如下分步骤:
S6-1:遍历所述五类动作参数的所有影响因素;
S6-2:将各动作参数的影响因素值标准化后作为输入数据输入训练好的所述BP神经网络模型;
S6-3:将所述BP神经网络模型的输出向量(输出结果为动作参数各区间的概率值向量)归一化后分别与对应的区间中值进行相乘后求和,得到不同因素影响下的所述五类动作的延迟时间Δti(i=1,2,…,5)及准确率ai(i=1,2,…,5);
S6-4:将装甲兵虚拟兵力战术对抗动作延迟事件T设置为T=[T1+Δt1,T2+Δt2,T3+Δt3,T4+Δt4,T5+Δt5],动作准确率A设置为A=[a1,a2,a3,a4,a5]。
4 实例分析
以装甲兵虚拟兵力战术对抗动作中的感知类动作延迟时间建模为例,按照上述方法进行参数建模。
步骤一:进行参数数值初始化,令装甲兵虚拟兵力战术对抗动作中的感知类动作延迟时间T1=0。
步骤二:列出感知类动作的延迟时间的影响因素X1n(n=1,2,…,6),包括车长等级X11、天气可见度X12、目标类型X13、车长行驶车速X14、距离目标的距离X15、目标的隐蔽方式X16,将具有连续值的影响因素划分为若干个区间,将具有离散值的影响因素划分为若干个等级。
步骤三:采集真实环境中上述6个影响因素下感知类动作的延迟时间数据,将具有连续值的动作延迟时间划分为若干个区间,与影响因素一同构建样本库,数据格式如表1所示。
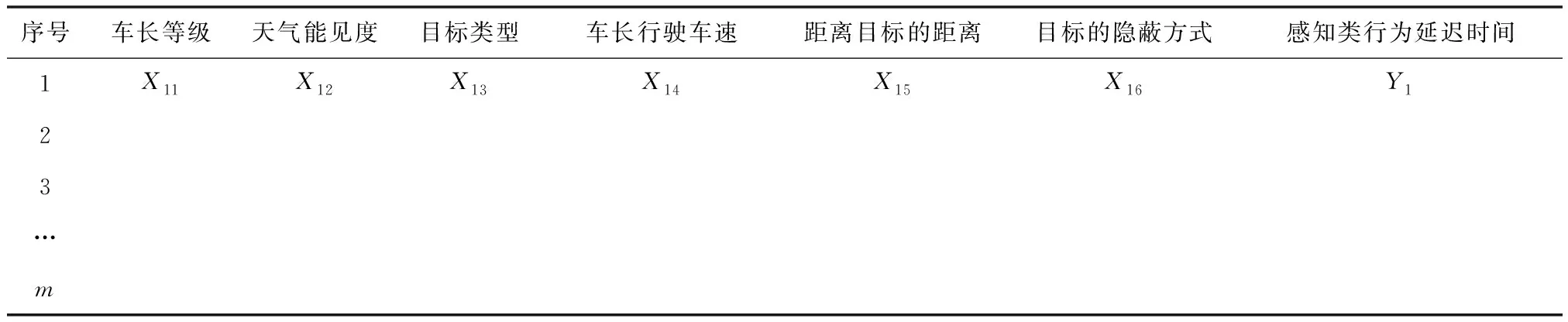
表1 样本库数据格式
步骤四:将样本库中的数据进行01编码处理,构建标准化的数据集。
将感知类动作延迟时间的影响因素离散化处理并进行01编码,包括:车长等级X11={"10000":特级,"01000":一级,"00100":二级,"00010":三级,"00001":初级},天气可见度X12={"100":(0m,500m),"010":(500m,1000m),"001":(1000m,5000m)},目标类型X13={"100000":坦克,"010000":装甲车,"001000":无座力炮,"000100":地堡,"000010":机枪发射点,"000001":火箭筒},车长行驶车速X14={"100":(0km/h,20km/h),"010":(20km/h,40km/h),"001":(40km/h,60km/h)}距离目标的距离X15={"100":(0m,500m),"010":(500m,1000m),"001":(1000m,5000m)},目标的隐蔽方式X16={"1000":暴露,"0100":利用掩体隐蔽,"0010":伪装,"0001":利用掩体隐蔽与伪装结合}。
将感知类动作延迟时间的实测值离散化处理并进行01编码,得Y1={"100000":(0s,10s),"010000":(10s,20s),"001000":(20s,30s),"000100":(30s,40s),"000010":(40s,50s),"000001":(50s,60s)}。
步骤五:建立并训练BP神经网络模型,如图3所示[5],[6],利用标准化的数据集训练BP神经网络,显然输入向量[X11,X12,X13,X14,X15,X16]为24维向量,输出向量为一个6维向量,网络模型的层数可以通过交叉验证的方法预测准确度从而确定。

图3 决策类动作参数及影响因素构建的多层BP神经网络示意图
步骤六:参数数值计算,首先遍历感知类动作延迟时间的所有影响因素;其次,将各影响因素值标准化后作为输入数据输入训练好的所述BP神经网络模型;再次,将所述BP神经网络模型的输出向量归一化后分别与对应的区间中值进行相乘后求和,得到不同因素影响下的感知类动作的延迟时间Δt1。
例如求车长等级为特级、天气可见度为300m,目标类型为装甲车,车长行驶速度为55km/h,距离目标的距离为1200m,目标的隐蔽方式为利用掩体隐蔽条件下的感知类动作延迟时间,则可以将影响因素标准化为[1,0,0,0,0,1,0,0,0,1,0,0,0,0,0,0,1,0,0,1,0,1,0,0,],输入上述训练好的BP神经网络模型,求得输出向量为[0.001,0.002,0.005,0.0092,0.04,0.003],将输出向量归一化后分别与对应的区间中值进行相乘后求和,即(0.001×5s+0.002×15s+0.005×25s+0.0092×35s+0.04×45s+0.003×55s)/(0.001+0.002+0.005+0.0092+0.04+0.003)≈34.89s,即在上述影响因素下的感知类动作的延迟时间为34.98s。
以此类推,即可按照上述方法完成对装甲兵虚拟兵力战术对抗动作参数(包括动作延迟时间、动作准确率)建模。
5 结束语
虚拟兵力是军事仿真系统中必不可少的元素,其行为的表述是否准确,参数设置是否符合实际,是直接影响军事问题研究结论的重要因素。本文以对装甲兵虚拟兵力战术对抗动作参数的建模为例,提出了一种方法,可以解决现有技术中虚拟兵力战术对抗动作延迟时间及动作准确度设置不合理的问题,使虚拟兵力动作参数建模更符合实际,对抗训练过程中训练场景更加贴近实际。实际情况下,虚拟兵力的种类繁多,对抗动作纷繁复杂,不同类动作影响因素不一,对动作参数建模要求各不相同,本方法可为虚拟兵力行为建模方法及虚拟兵力的个性化生成提供借鉴。
