大数据平台下LDA-ALS智能推荐算法研究
2022-01-05陈丽芳陈宏松孙海民
陈丽芳,陈宏松,孙海民
(1. 华北理工大学 理学院,河北 唐山 063210;2. 河北省文化旅游大数据技术创新中心,河北 承德 067000;3. 河北民族师范学院,河北 承德 067000)
高速发展的万维网使得各行各业都呈现出大数据状态,人们逐渐从信息匮乏的时代步入信息过载的时代[1]。最初,人们无法从海量的数据当中搜索定位精确的信息,在这样的网络环境下,搜索引擎应运而生。
搜索引擎为用户的明确需求进行搜索查询,然而当用户对于自身需求并不明确时,搜索引擎的查询结果往往不够准确。作为搜索引擎的上位替换,推荐系统是一种特殊的技术和工具,通过管理和分析海量数据为用户提供基于兴趣的个性化推荐。
对于大部分用户来说,传统的推荐系统有着搜索结果单一固定的特点,为此研究人员一直致力于开发出新的算法优化推荐结果。目前,常用的算法主要有基于关联规则的推荐[2]、基于用户的协同过滤推荐[3]、基于项目的协同过滤推荐[4]和基于模型的协同过滤推荐[5]。此外,混合推荐算法的提出使得推荐结果更好。Wang等人[6]提出了与联邦学习相结合的推荐算法,实现了更加全面的精确计费点推荐。杨彦荣等人[7]提出了基于内容的推荐算法与矩阵分解推荐算法结合的融合算法,更加精确地获得项目的特征表示。
通常意义上的用户冷启动问题指的是对一个几乎没有行为或者行为极少的用户进行推荐,此时若进行矩阵分解来预测该用户的评分就会出现冷启动问题。基于内容的推荐算法可以很好解决该问题,根据用户的年龄、性别、爱好等来推测用户的兴趣主题,研究中用LDA对用户的评论进行一个主题提取,可以揣测用户喜好的主题对其进行推荐。
该研究融合基于内容的推荐和基于模型的协同过滤推荐2种算法的优势,提出LDA-ALS混合推荐算法,解决冷启动和数据稀疏性问题,以旅游评分数据集为背景,采用分布式文件系统HDFS的伪分布式存储,在搭建的Spark平台下实现推荐算法的并行化处理。
1 基础理论
构建推荐系统可以采用多种方法:协同过滤推荐算法,利用集体智慧,探索用户的偏好来提供定制的推荐;关联规则挖掘算法中,通过面包-牛奶关联规则进行推荐;基于内容的推荐算法,通过使用用户先前喜欢的项目相似特征来构建建议。不同的推荐系统方法都有各自的优缺点。因此,采用混合推荐算法结合多种不同算法的优势来改进推荐结果是目前的一个研究热点。
1.1 智能推荐算法
1.1.1基于模型的协同过滤推荐算法
基于模型的协同过滤算法是通过已观察到的用户给产品打分,是基于用户的协同过滤算法和基于项目的协同过滤算法的混合[8],基于模型的协同过滤推荐算法无需借助评分数据进行相似度计算和评分预测,用机器学习、统计学习和数据挖掘等算法建立评分模型,再根据模型完成目标用户对目标项目的评分进行预测。常用的基于用户的协同过滤算法主要有:
(1)奇异值分解方法,将用户—项目评分矩阵投影到一个低维空间中,在这个低维空间上计算相似度并进行推荐。
(2)交替最小二乘算法,将用户和项目的评分矩阵分解为2个矩阵,交替最小二乘算法有显式反馈模型和隐式反馈模型,分解的2个矩阵其中一个是用户对项目的隐含特征的显式偏好矩阵,另一个是项目本身的隐含特征的隐式矩阵。
1.1.2基于内容的推荐算法
基于内容的推荐算法依靠人工经验来获取项目特征,针对一个项目,即一段文本,用信息检索中TF-IDF算法来计算文本中每个词的权重,将权重靠前的几个词汇抽出,作为文本的特征向量表示。将同一用户的多个向量表示作为用户的属性,计算多个用户属性的关联度,基于关联度计算得出相关性,将关联度最高的项目推荐给用户。在特征选择这一步可以通过人工经验选择,然而人工选择的特征往往比较单一,无法精准描述文档内容。
1.2 算法核心
1.2.1 LDA
文档主题算法是一种统计文档当中主题出现个数的统计模型,LDA主题模型是其中的代表。LDA(Latent Dirichlet Allocation),又称为潜在迪利克雷分布,是由David M.Blei等人于2003年提出的一种文档主题算法[9],是3层结构的贝叶斯概率模型,属于无监督的机器学习方法,可以用来识别大型文档集和语料库中隐藏的主题信息[10]。该算法将一篇文档视作多个词汇的组合,删去其中的人称和助词等与文档内容关系不大的词汇,采用词袋模型的方法对文档中包含的词汇进行划分主题,即每篇文档代表了一些主题所构成的概率分布,从而将随机词汇组成的文档转换成各种主题的随机集合。
假设文档集合W有m个文档,每篇文档包含n个词语,集合W包含k个主题,使用μ和η分别表示文档—主题和主题—词语的概率分布,则LDA的结构如图所示:
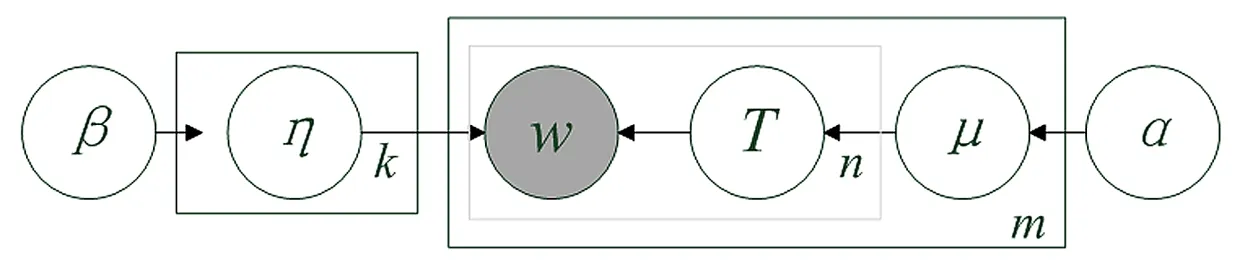
图1 LDA生成模型
如图1所示,k维向量α为μ的先验分布参数;β是η的先验参数分布,且α和β服从迪利克雷分布。
LDA文档主题算法生成文档的流程如下:
Step 1:通过采样先验分布参数α得到文档—主题分布μi,μi是k维向量,表示文档Wi与主题k之间的分布,μi服从迪利克雷分布;
Step 2:从文档—主题多项式分布μi中取样生成文档i的第n个词语的主题Ti,n;
Step 3:在先验分布β中采样主题Ti,n对应的主题—词语分布ηk;
Step 4:从主题—词语多项式分布ηk取样得到第i个文档的第n个词语Wi,n,重复上述过程直至遍历文档中所有词语。
1.2.2 ALS
矩阵分解(MF)是将单个矩阵拆分成多个矩阵的乘积,在推荐算法中有Koren,D.D.Lee等人提出的基于奇异值分解(SVD)的协同过滤算法[11-13],Zhou,Wilkinson等人提出了基于交替最小二乘(ALS)的协同过滤算法[14],这2种算法是主流的矩阵分解算法。
ALS将用户(User)对项目(Item)的评分矩阵分为2个矩阵,即将用户—项目的评分矩阵 分解成用户对项目隐含特征的偏好矩阵P和项目所包含的隐含特征矩阵Q。即对于m×n矩阵 ,ALS算法可以找到2个低维的矩阵,一个是m×k的矩阵P,另一个是n×k的矩阵Q,从而得到R的近似矩阵R′,如公式(1):

(1)
通常k≪min(m,n),是对矩阵R的降维,对每个用户i得到隐性特征向量ui∈R′,每一个项目j得到隐性特征向量vi∈R′。最后通过用户和项目的潜在特征向量内积拟合用户评分,由公式(2)可得:
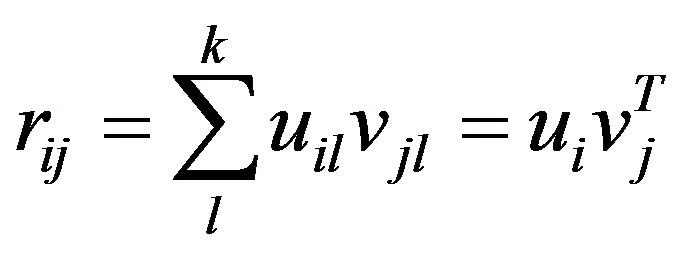
(2)
为了保证矩阵P和矩阵Q的乘积尽可能拟合目标矩阵R,用拉格朗日乘数法构建最小化目标损失函数:
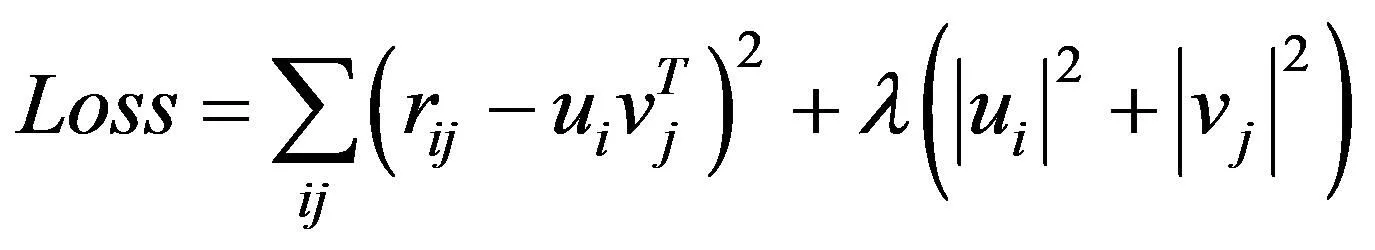
(3)

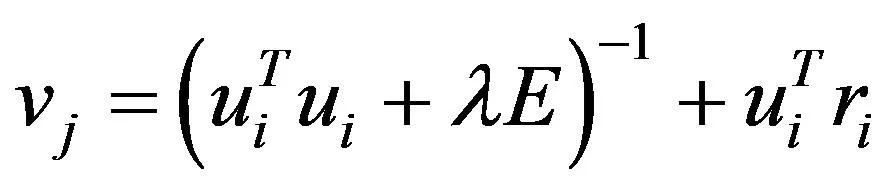
(4)
同理可得公式(5):
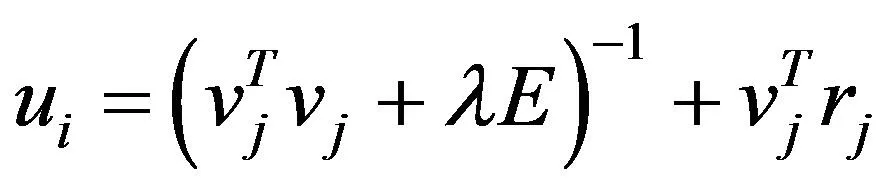
(5)
其中ui是rij的第i行,vi是rij的第j列,E是k×k的单位矩阵。迭代步骤就是对公式(4)和公式(5)不断进行更新,反复迭代直至收敛或是达到最大迭代次数。
1.2.3 LDA-ALS
单一的ALS算法对于解决数据稀疏性具有良好的效果,然而在处理冷启动的问题上效果不明显,因此把LDA算法引入ALS矩阵分解算法中来优化算法性能,通常冷启动指的是系统中新用户数据较少甚至没有。
该研究推荐系统采用LDA算法解决冷启动问题,针对大多数游客,具有旅游景点单一,景点分布分散的特点,这就导致通常某一个用户或某一群用户的旅游地区的分布性广泛,即景点分布不集中。获取适当文本量的评论文本,采用LDA算法对用户的评论文本进行文档主题提取。该算法流程图如图2所示。

图2 算法流程图
Step 1:通过网络爬虫和数据挖掘的方式获取原始数据集。
Step 2:使用LDA文档主题算法对爬取的评论文本进行分析,提取出文档主题,遍历文档中所有词语。
Step 3:基于人工经验对文档主题进行分类,根据划分类别对原始数据集进行增删,从而得到高评分的数据集。
Step 4:计算出用户—评分矩阵,使用8:2的比例划分训练集和测试集,通过ALS交替最小二乘算法将数据集对评分矩阵进行降维,分别构建显性反馈模型和隐性反馈模型,通过用户—项目的潜在特征向量内积拟合用户预测评分。
Step 5:重复进行步骤三和步骤四,迭代直到最后获取最佳的推荐结果,按从大到小的排序选取前K评分最高的项目对用户进行推荐。
2 相关工作
2.1 系统架构
该研究在Win10的系统下安装Oracle VM VirtualBox虚拟机,在虚拟机上安装Ubuntu操作系统,在Ubuntu系统上配置Hadoop和Spark的运行环境。表1所示为虚拟机的主要配置。

表1 虚拟机配置
2.2 Linux系统架构
Ubuntu是一个以桌面应用为主的开源DebianGun/Linux操作系统。实验中选择Ubuntu 16.04系统,相较于Windows10,Ubuntu16.04系统安全稳定,漏洞修复快,权限管理严格,可以有效避免用户误操作,强大的命令行输入操作使得Linux比Windows更加偏向专业化。
2.3 Hadoop
Hadoop作为Apache旗下开发的分布式系统基础架构,能够对大数据进行分布式处理。Hadoop实现了分布式的文件系统(Hadoop Distributed File System),适用于数据吞吐量较高的应用程序,适合用于存储超大的数据集[15]。
Hadoop有3种安装模式:单机模式、伪分布式模式和分布式模式,其中分布式模式对环境的要求比较高,要选定一台计算机作为Master节点,和几台计算机作为Slave节点。该研究采用的是伪分布式模式,这种模式下对单台计算机的配置要求比较高。
2.4 Spark
Apache Spark作为一种通用分析引擎,用于大规模的数据处理和过于分散的数据,它是一个计算引擎,用于分析通常无法放入单台计算机或节点内存的大规模数据集。
Spark是与Hadoop相似的开源集群计算环境,但它的处理速度是Hadoop的100倍。它通过物理执行引擎、查询优化器和最先进的有向无环图(DAG)调度器来获得流处理和批处理数据的高性能。
Spark核心能力能够跨工作程序节点进行工作分配,并进行其他基本工作(故障恢复)。在Spark核心引擎之上还有更高级别的库,例如用于机器学习的MLlib,用于图形并行计算的GraphX,用于处理结构化数据的Spark SQL和用于应用程序流的Spark Streaming等。这些库可以在一个应用程序中顺利整合。
Spark有4种部署模式:Local模式(单机模式)、Standalone(集群模式并且使用Spark自带的简单集群管理器)、YARN模式(集群模式并且使用YARN作为集群管理器)和Mesos模式(集群模式并且使用Mesos作为集群管理器)。研究中,使用本地部署模式。在本地部署模式下,Spark中的作业在单台计算机上运行,并通过使用多线程技术以并行方式实施。在这种类型的部署模型中,并行性存在局限性。
Spark和Hadoop可以部署在一起,相互协作,由Hadoop的HDFS等组件负责数据的存储和管理,由Spark负责数据的计算。
3 实验结果与分析
3.1 实验数据集
实验选用携程网河北省的旅游数据,对于用户数据,通常意义上的用户冷启动问题指的是对一个几乎没有行为或者行为极少的用户进行推荐,比如说用户只在河北省某个知名的旅游景点旅游过。此时若进行矩阵分解来预测用户的评分就会出现冷启动问题,采用基于内容的推荐算法规避该问题,根据用户的年龄、性别、爱好等来推测用户的兴趣主题,研究中用LDA对用户的评论进行主题提取,可以揣测用户喜好的主题对其进行推荐。
在该研究中选取携程网上河北省前100的景点进行推荐,对于有着评论的用户进行LDA主题提取,生成推荐数据集。作为样例的数据集,该数据集包括了30个用户对河北省的前100个景点进行评分。所有的评分值都是1到5的整数值,评分越高代表用户对景点的满意度也越高。
实验过程中通过数据清洗和一系列数据预处理操作后得到实验数据集。原始规范数据如表2所示,数据表包括用户ID、景点ID、评分和时间戳,30个用户都注册了携程网站的账户并在景点评论区进行简短的评论,评论都是短文本的文字评述,因此评分基本上都比较高。

表2 原始规范化数据集
该数据集的具体信息如表3所示:

表3 旅游数据集信息
3.2 实验的评价标准
实验采用均方根误差(RMSE)和平均绝对误差(MAE)作为模型评估的评价标准[16],RMSE是计算用户的预测评分与用户的实际评分之间的偏差来度量预测的准确性,MAE是计算用户预测评分和实际评分之间的误差来衡量模型预测的准确度。RMSE和 MAE为推荐质量提供了直观的度量方法,是2种比较常用的评估模型方法之一。
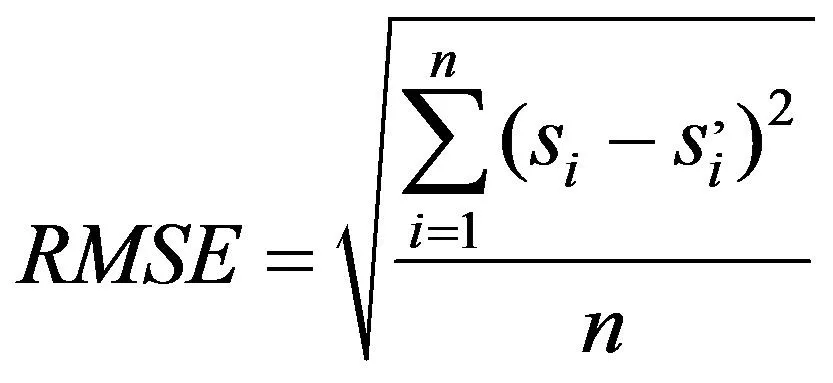
(6)
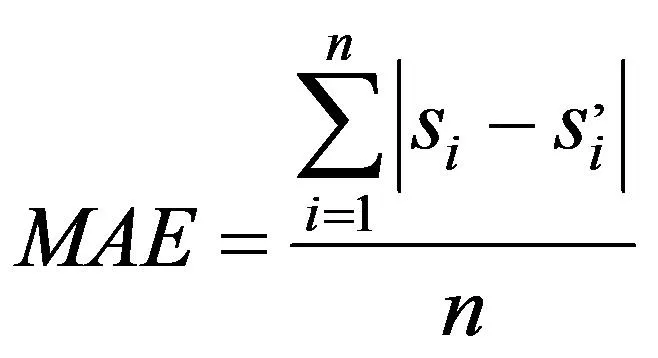
(7)

3.3 模型分析
采用Spark平台下spark-shell与Hadoop的交互行为实现对数据的存储和并行化计算。在Hadoop的伪分布式下的3个节点(namenode,secondnode,datanode)运行。设定并行化计算的用户和商品的分块个数的参数值10,训练集和测试集的比例为8:2。该研究主要采用显式反馈数据作为LDA-ALS算法的实验结果。实验设置了不同的最大迭代次数和正则化参数,寻找RMSE最低时的参数。
如图3所示,横坐标表示算法的迭代次数K,纵坐标表示不同K值下不同算法的RMSE取值,LDA-ALS、SVD和SVD++算法初始值分别为1.963、1.353和1.399,随着迭代次数K的增加,各个算法的RMSE呈现下降的趋势;该研究提出的LDA-ALS相比SVD和SVD++算法,整体RMSE下降29.2%;SVD和SVD++算法的RMSE数值相差2.88%;当K取[4,10]之间时,LDA-ALS算法变化率在2.11%。该研究提出的LDA-ALS算法稳定性更高且推荐准确度更优。
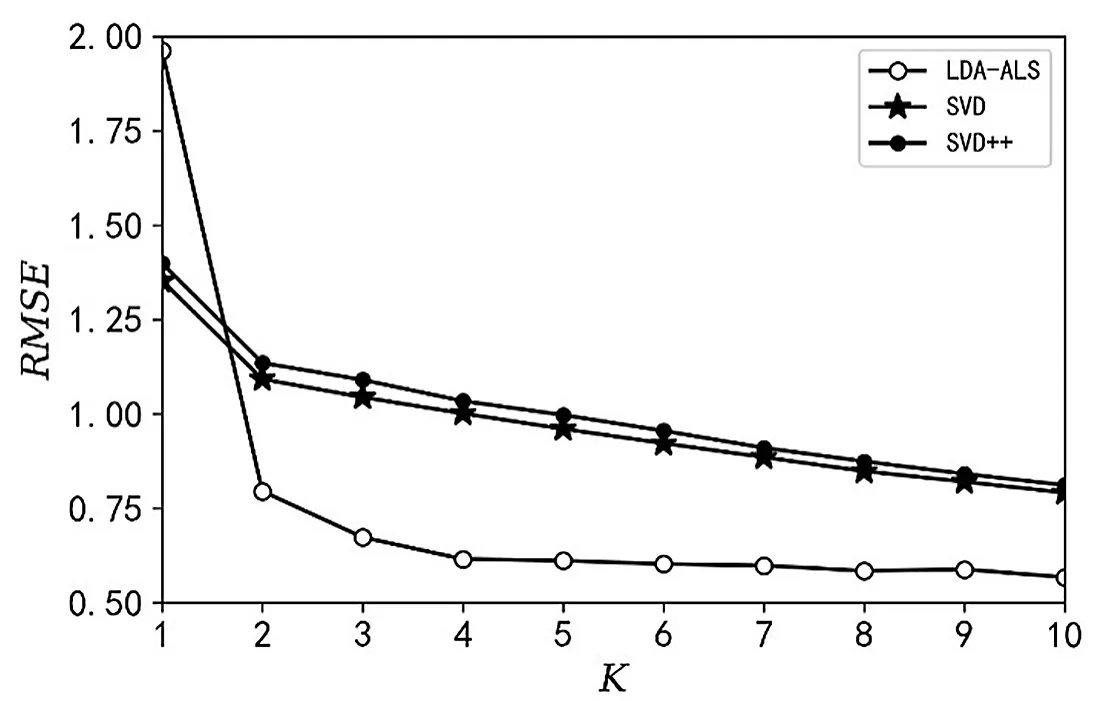
图3 RMSE结果图
如图4所示,横坐标表示算法的迭代次数K,纵坐标表示不同K值下不同算法的RMSE取值,LDA-ALS、SVD和SVD++算法初始值分别为1.578、1.118和1.094,随着迭代次数K的增加,各个算法的MAE呈现下降的趋势;该研究提出的LDA-ALS相比其他的算法,整体MAE下降21.09%;SVD和SVD++算法的MAE数值相差2.64%;当K取[4,10]之间时,LDA-ALS算法综合表现更好。为了寻找更加准确的相似用户MAE随着K的变化而变化,排除对预测结果的干扰。当迭代次数为10时,LDA-ALS算法的MAE取值为0.497。

图4 MAE结果图
3.4 结果分析
表4为不同用户—项目实例数据,对于用户11和12,分别对不同旅游项目13和41进行评分,与预测评分相比,用户11的误差为1.48%,而用户12的误差为0.25%。对于评分为4.0的不同用户的不同项目,其误差比差距不大。用户24对不同项目进行评分,实际评分与预测评分的误差相差2.1%。用户19和21对于同一项目进行评分,实际评分与预测评分的误差相差0.08%。预测评分表中,同一评分的预测评分其误差比不大,且评分越高其误差越大。

表4 预测评分表
如表5所示,LDA-ALS算法的RMSE值比SVD低了11.6%,LDA-ALS算法相比传统的矩阵分解算法SVD推荐效果稍好,该研究的旅游数据集达到99.89%,SVD算法在对稠密矩阵的处理上表现比ALS算法好,在稀疏矩阵上ALS算法表现更为出色。

表5 算法运行结果
综上所述,LDA-ALS算法在RMSE和MAE算法相比其他算法表现的更为优秀也更为稳定,而且找到的相似用户更准确。提出的LDA-ALS算法在处理冷启动问题和数据稀疏上有很好的效果,在推荐精度上也有一定提升。
4 结论
(1)该研究结合主题模型算法LDA和交替最小二乘算法ALS,提出了一种LDA-ALS的智能推荐算法,该算法融合了LDA算法和ALS算法的优点,从评论主题分析的角度增加新用户的数据,RMSE值比传统的SVD算法降低2.4%的误差。
(2)通过河北省的旅游数据对该算法进行模型评估,对比SVD算法、LDA-ALS算法在处理稀疏矩阵上有优势,填充的缺失值缓解了数据不足的问题。LDA-ALS显式反馈模型的准确度比SVD算法更高。
