基于PSO-BP神经网络的转炉炼钢碳含量预测
2022-01-05董晶张利民张燕超张彩军韩阳
董晶,张利民,张燕超,张彩军,韩阳
(1. 华北理工大学 理学院,河北 唐山 063210;2. 衡水学院,河北 衡水 053000;3. 华北理工大学 冶金与能源学院,河北 唐山 063210)
转炉炼钢是以铁水、废钢(生铁块)、铁合金为主要原料,在不借助外加能源的情况下,依靠铁水本身的物理热和铁水中的碳、硅等组分间发生化学反应产生的热量在转炉中完成炼钢的过程。伴随现代钢铁生产工艺的进步,在冶炼过程中,一般采用铁水预处理工艺对难以脱除的硫、磷等杂质进行处理。目前,转炉冶炼终点碳含量的准确预测成为现代工艺流程中转炉终点控制的核心。国内绝大多数钢厂主要依据现场操作人员操作经验对转炉炼钢终点进行人为控制,而现场操作人员的操作经验仅仅是通过对现场生产以及生产控制数据的总结分析得到,难以达到稳定准确的效果[1]。
伴随智能控制技术的发展,使转炉炼钢生产过程中产生的数据信息检测和采集得以实现,进而形成庞大的转炉炼钢生产数据资源。转炉炼钢是复杂的非线性过程,仅使用单纯的机理分析、统计回归等方法难以建立起精准的模型[2]。因此,有学者尝试将神经网络等智能方法引入转炉炼钢终点预报模型的建立过程中。许刚等人建立神经网络模型,对转炉炼钢终点进行模拟预测[3];赵辉等人为提高预测精度,提出采用极限学习机来建立转炉炼钢耗氧量预测模型,利用遗传算法对对极限学习机的权值和阈值随机确定所导致的网络结构稳定性差的问题进行优化,对神经网络隐含层数量和隐含层激励函数的不同选择对仿真结果的影响做出了具体的分析[4]。基于此,该项研究将BP神经网络与PSO算法相结合应用于转炉炼钢终点碳含量预测研究,通过PSO算法的鲁棒性高效优化BP神经网络,以实现对转炉炼钢终点碳含量精准预测的目的,为转炉炼钢实际生产提供一定的指导。
1 转炉炉口火焰光谱信息预处理
在经验炼钢中,现场操作工长将转炉炉口火焰的视觉特征作为炼钢终点判定的依据,虽然命中率低,但在一定时期里有很强的实用价值。基于上述启发,该项研究采用USB4000光谱仪,实时采集炼钢过程中的转炉炉口火焰光谱信息,用以量化炉口火焰的视觉特征。光谱仪每0.5 s采集一次火焰在2 048个光的波长序列下的光强值,中小型转炉炼钢的吹炼周期为15 min左右,周期内产生数据量360余万,为消除光谱信息的冗余,采用阿特曼z-score模型和主成分分析方法对这些数据进行预处理,以获取有效的、用于炼钢后期钢水碳含量连续预报的样本集。
1.1 基于阿特曼Z-score模型的数据标准化
为消除光强对光谱信号预测结果的影响,首先对数据进行标准化处理,该项目采用Z-score方法[5]对光谱数据进行标准化处理,标准化变量如下:
假设xij作为时间i,频率j下的光强强度:

(1)

1.2 基于主成分分析的选择模型
(1) 标准化数据的相关系数矩阵
j和j′频率之间,相关系数rrj,j′为:
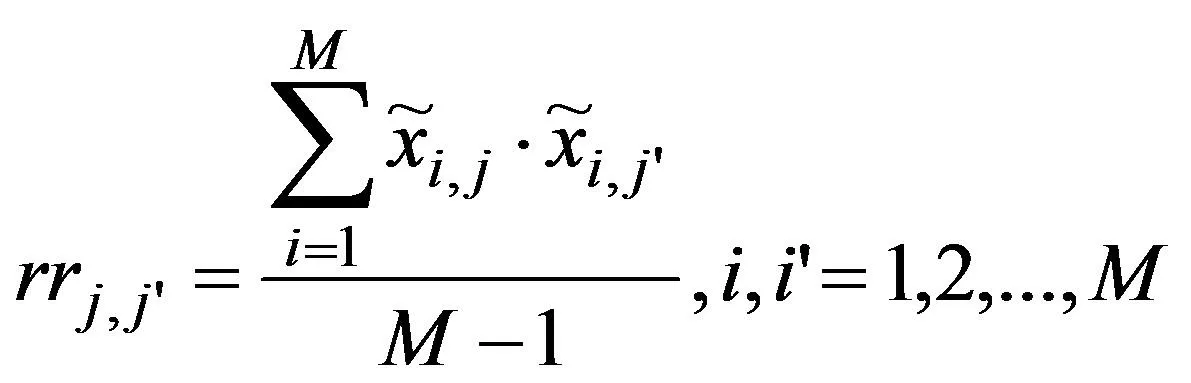
(2)
其中,M在冶炼过程1中为404,在冶炼过程2中为288,在冶炼过程3中为286。
因此,相关系数矩阵[6,7]为:

(3)
其中,rrj,j′=1,rrj,j′=rrj′,j。
(2) 特征值和特征向量
计算特征数据λ1λ2…λ20480和相关系数矩阵RR的对应的特征向量ζ1=(u1,j,u2,j,u2048,j)T,由特征向量形成的2 048个新的指标变量[8,9]如下:

(4)
其中,Yi是主成分,i=1,2,…2048。
1.3 模型的结果
步骤1:导入和归一化数据;
步骤2:计算标准化数据的相关系数矩阵;
步骤3:计算相关系数矩阵的特征值和特征向量;
步骤4:获得主成分分析结果和贡献率;
步骤5:从主要成分1的正交解决方案中选择13个指标之前的最大正交解,作为模型的特征。
根据上述步骤,利用SPSS分别从冶炼过程1、2、3中的135,124和132个主要成分中的计算出各个成分的贡献率。每个过程的主要成分的累积贡献率如表1、表2.和表3所示:

表1 过程1中主要成分的累积贡献率

表2 过程2中主要成分的累积贡献率

表3 过程3中主要成分的累积贡献率
从表1、表2.和表3的直观结果可知,1号成分在1、2、3冶炼过程中的贡献率均为78%以上,其他成分几乎全部低于1%,呈逐渐减少趋势。所以该项研究只选择成分1作为指标。从主要成分1的正交解中选择13个指标中最大正交解,作为模型的特征。
3个冶炼过程的最终特征和正交解决方案如表4所示。
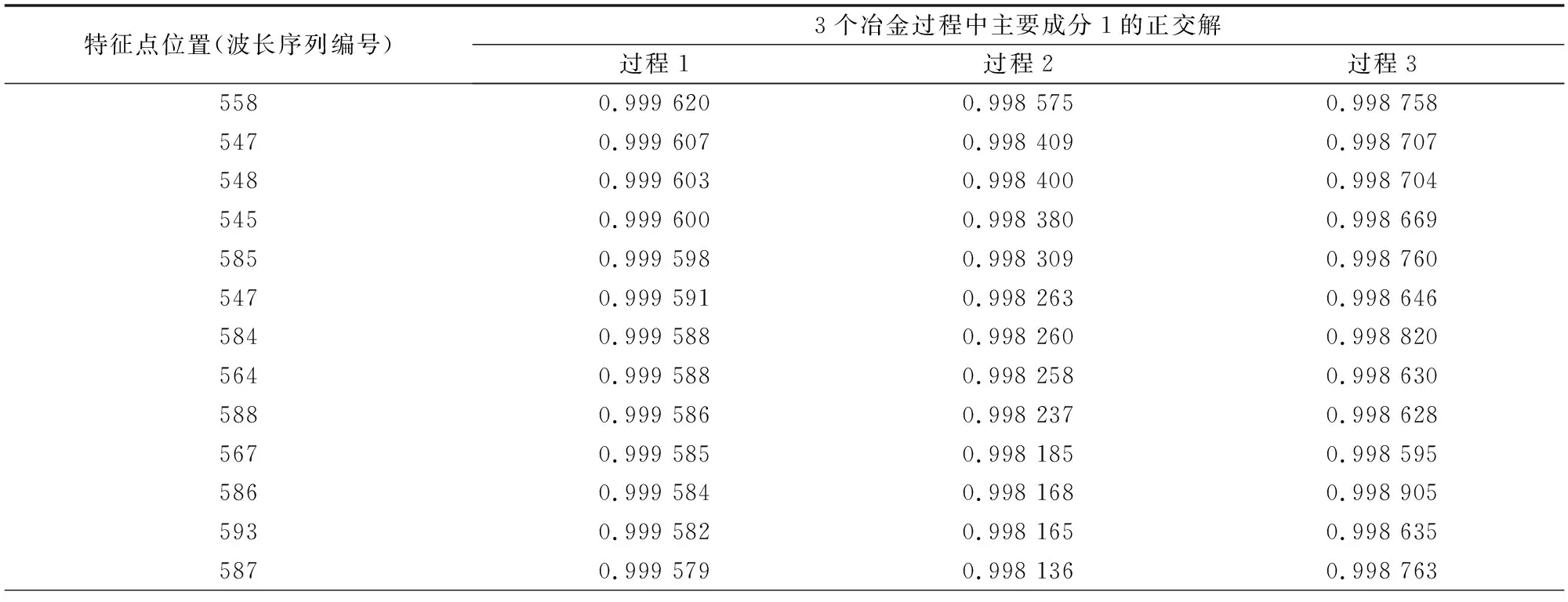
表4 过程1、2、3最终特征和正交解决方案
2 转炉炼钢中碳含量的预测模型
在研究转炉炼钢过程中火焰光谱的特征与钢水C含量的关系时,发现两者之间存在着模糊的联系,采用一般的线性关系模型难以明确得出两者的复杂关系,因此构建基于粒子群的BP神经网络智能算法分别寻找光谱特征与C含量的函数映射关系,从而预测钢水的C含量变化。
2.1 BP神经网络算法
BP神经网络[10-12]是一种多层前馈神经网络,在多层感知器的基础上增加误差逆向传播信号,用以处理非线性连续函数,该网络由输入层、隐含层、输出层构成,其主要特点是信号前向传递,误差反向传播,可以用在系统模型辨识、预测或控制中。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出,其拓扑结构图如图1所示。

图1 BP神经网络拓扑结构图
将提取光谱特征信息后的各频率强度λ1,λ2,λ3,…λn作为输入层,钢水的C含量y1,y2,y3,…ym,作为输出层,Wij和Wjk为BP神经网络权值。由拓扑结构图得到,可将BP神经网络近似为一个非线性函数,网络输入值为该函数的自变量,预测值为该函数的因变量。当输入节点数为n,输出节点数为m时,BP神经网络呈现了从n个自变量到m个因变量的函数映射关系。
2.2 粒子群优化算法
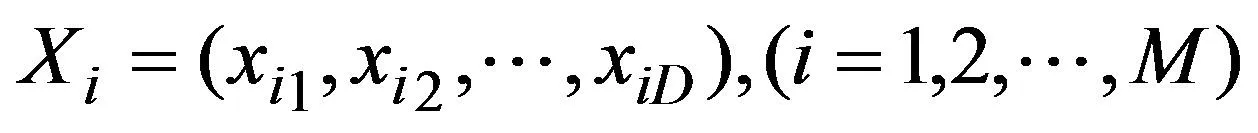

(5)
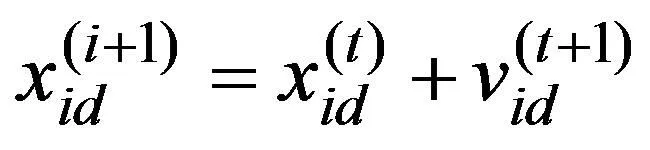
(6)
在表达式中:u是惯性权重,PSO可以通过引入惯性权重的算法来调整全局和局部的优化能力,一般采用线性惯性权重;c1和c2是常量,被称为加速因子,r1和r2是2个在[0,1]范围内的随机数。
2.3 基于粒子群算法的BP神经网络预测模型
BP神经网络的隐藏节点通常由重复的前向传递和反向传播的方式来决定,通过修改或构造训练方式改变隐藏的节点数,相应的初始权重和阈值也会随之变化,从而影响网络的收敛和学习效率。为了减少影响,通过采用基于粒子群算法的BP神经网络模型对权重和阈值的调整进行优化,从而加快网络的收敛速度和提高网络的学习效率[15]。
假设神经网络训练后得到具有不同权重和阈值的网络L(L=1,2,3,…m)。每一次训练后样本根据式(7)、式(8)计算测试样本 的训练误差 和测试样本 的测试误差 :
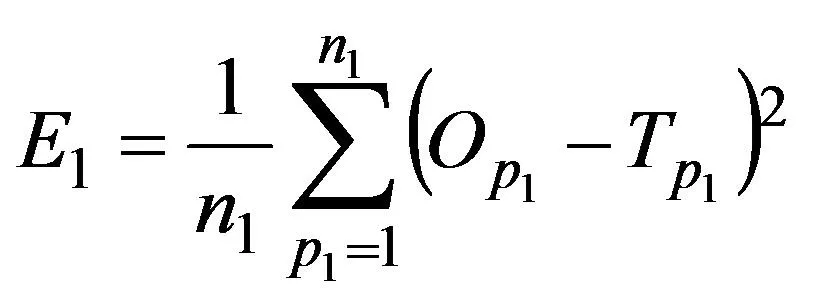
(7)

(8)
在公式(7)和公式(8)中,n1和n2分别是测试样本和训练样本数量;OP1和TP1是培训样品P1的实际输出和预期输出。OP2和TP2是测试样品P2的实际输出和预期输出。PSO算法中速度的迭代公式(9)如下所示。
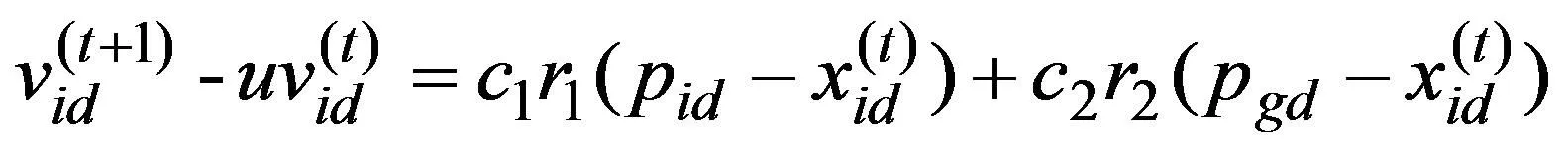
(9)
公式(9)表明,粒子2个速度之间的变化由粒子当前位置随着粒子自身历史最佳位置和全局粒子最佳位置的改变决定。因此,如果网络的权重被看作粒子群算法中粒子的速度,在2次训练过程中的权重变化可以看作粒子的速度变化[16]。
权重调整公式见式(10)和式(11)。

(10)
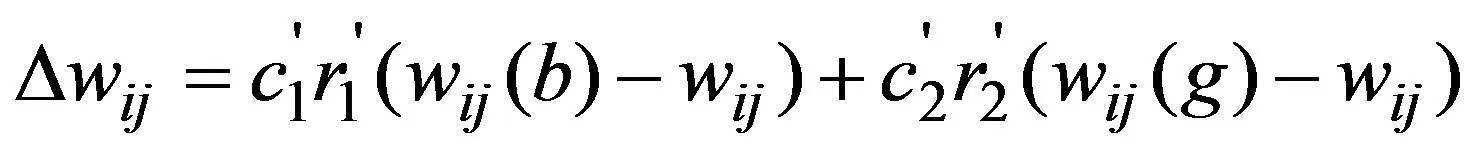
(11)
每一次训练后,BP算法和粒子群优化算法将共同影响权重的调整。因此,基本的BP网络权值调整公式还应分别增加一个权重调整公式,网络权值调整计算,见式(12)和式(13)。
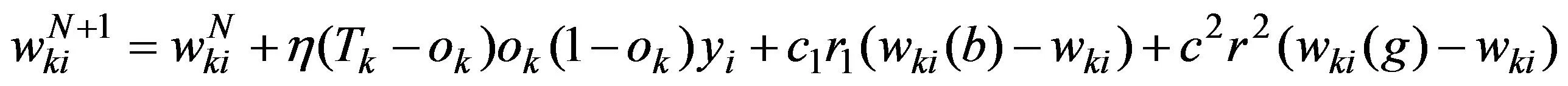
(12)

(13)
训练停止条件:当MAX(E1,E2)停止训练时,网络权重和最终权重的阈值,算法流程见图2。

图2 程序流程图
3 实证分析
3.1 模型求解
将经过主成分算法提取的光谱特征分为3个数据组,每个数据包含13个光谱特征指标输入数据即λ1,λ2,…λ13,…λn和每次收集光谱信息时的C含量。首先选取一个1号数据组代入模型得到BP神经网络的预测值结果见图3。
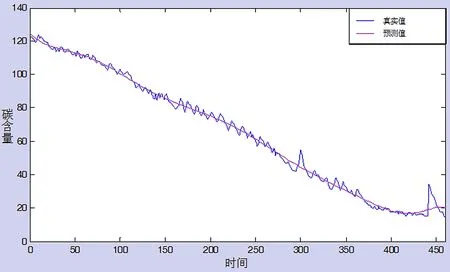
图3 C含量的预测值和实际值
从图3中可以得到2条曲线,一条为钢水中碳含量的实际变化值,另一条是通过基于粒子群算法的神经网络模型得到的C含量预测值。从实际变化线中可以发现,随着时间的推移,钢水中的C含量急剧的降低,呈波浪状变化;从预测值变化曲线中可以发现当时间达到400 s左右时,钢水的C含量减小趋势变缓。为了检验预测结果的好坏,对模型进行误差分析。
3.2 误差分析
将第一组数据的光谱特征和C含量作为输入,采用MATLAB编程模拟神经网络的训练过程,分析图4所示的算法学习性能。
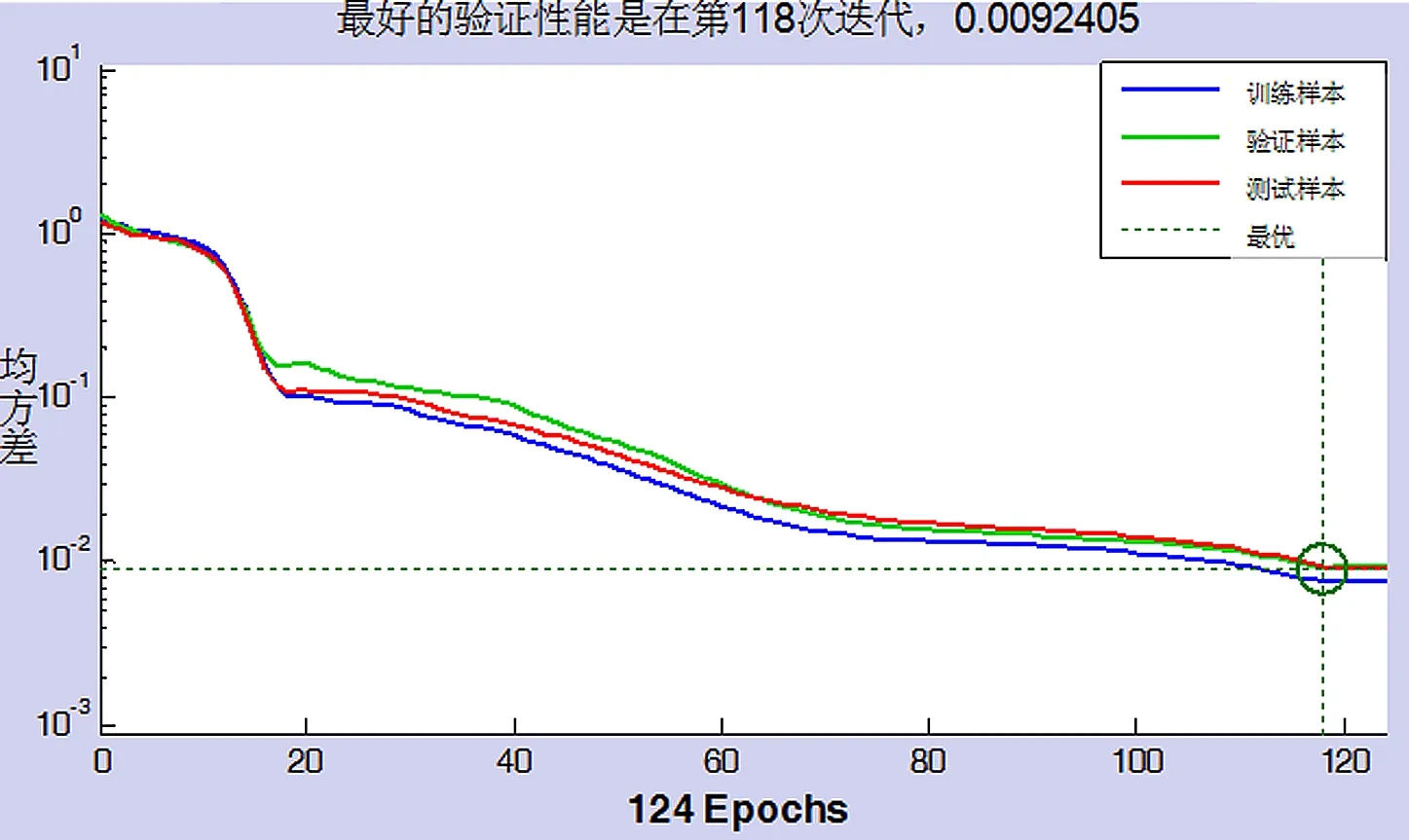
图4 BP神经网络性能
图4得到3条不同颜色的曲线,分别为训练样本数据、验证样本数据及测试样本数据,该数据集是没有重叠的训练,在前20步中3条误差线几乎重合,在20步之后误差线之间开始逐渐分开,最终得到的训练误差为0.009 240 5,这表明预测的效果较好,实际值与预测值的误差较小。
为了检验基于粒子群的神经网络模型的准确性、稳定性以及适用度,采用交叉实验的方法对模型的预测结果进行误差分析。首先将训练后的第1组神经网络保存下来,将另外2组的数据作为新的测试组,即可得到2组数据的C含量的预测值;其次,采用标准误差公式估算模型的误差;最后采用同样的方法分别将第2、3组作为训练组,构建神经网络结构即可获得交叉实验结果如表5所示。

表5 C含量交叉验证
表7是3组数据的正交试验表,从表7中可以看出,采用模型训练出的神经网络隐式关系得出的C含量的预测值与实际值的最大相对误差为2.37%,在采用第三组数据作为训练集,测试第一组数据的误差相对最大为4.14%,但整体上测试的误差都小于0.05,这表明该模型具有适用性,得到的结果误差较小。
4 结论
(1)预测转炉炼钢过程中钢水C含量和温度的目的是实现炼钢过程的自动控制,用智能化控制代替人为经验判断。
(2)采用主成分分析提取出13个光谱特征频率,利用粒子群算法改进神经网络模型的权重调整公式,最后采用正交试验对基于粒子群的神经网络的预测结果进行测试,结果表明:基于粒子群算法的神经网络模型具有高准确性、稳定性以及适用度,可以为钢铁企业提供指导建议。
