边缘网络中一种VNF需求预测方法*
2022-01-04黄宏程鲍晓萌
黄宏程,鲍晓萌,胡 敏
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
万物互联时代,边缘计算和网络功能虚拟化(Network Function Virtualization,NFV)等技术迅速发展,使得海量边缘智能终端设备以及相关网络业务涌现,同时也促进了网络逐步向智能化和虚拟化的方式转变。通过NFV、软件定义网络(Software Defined Network,SDN)等技术实现软件和硬件的解耦,能够解决当前网络布局复杂、僵化的问题,提高网络的敏捷性和扩展性[1]。且随着边缘智能、智慧城市等的逐步推动,愈来愈多的网络业务迁移至网络边缘,利用边缘基础设施虚拟化的计算、存储和网络资源就近进行处理,可以降低计算时延,从而为终端用户提供更加优质的服务。
随着互联网的高速发展,用户对网络资源的需求持续增加,因此精确规划网络资源使用已成为运营商的首要任务[2]。网络流量预测技术可以帮助运营商准确预估网络的使用情况,合理分配并高效利用网络资源[3]。文献[4]考虑到用户请求业务的 动态性和信息反馈的延迟引起不合理的虚拟网络资源分配或缓存溢出概率增大等问题,提出了一种基于长短期记忆神经网络的流量感知算法,通过各个切片业务的历史队列信息来预测未来的负载情况,从而实现了网络的在线监测。文献[5]提出了一种基于软化灵活性和NFV环境中大量监视数据的新颖学习模型,以使用网络服务功能链(Service Function Chain,SFC)数据预测VNF资源需求,但是网络边缘流量凸显的复杂特征,单一的模型很难准确地刻画。
文献[6]使用序列到序列(Sequence-to-Sequence,S2S)学习范例和卷积长短期记忆来解决多服务移动流量预测问题,以便有效地提取移动网络流量的复杂时空特征,并高精度地预测城市规模内单个服务的未来需求。文献[7]使用SDN中基于流的转发思想从数据平面提取流量统计信息,基于流量的时间特性,利用时间相关理论对流量进行建模,提出了基于流的转发流量预测算法,以预测SDN流量。文献[8]研究了基于基线自回归移动平均(Autoregressive Moving Average,ARMA)方法的移动服务需求预测,该方法以分钟为单位粒度使用相对较短的历史数据,并考虑了多个数据处理之间的相关性,以无监督的方式利用了每种服务流量需求的功能特性,但是这种方法并不完全适应于VNF需求的预测。文献[9]提出了一种基于机器学习的新颖解决方案,用于在虚拟化环境中横向扩展访问和移动性管理功能(Action Message Format,AMF)资源,但是只是考虑了一种VNF即AMF的预测且没有考虑网络边缘流量具有突发性等特点。文献[10]提出了一种在适当的时间预测所需资源以维持NFV真正弹性的方法,并提出了离线调度和在线调度策略在不同情境下来预测日前CPU利用率,但是提出的解决方法是通过例如CPU使用率或内存使用率等系统级信息,而没有考虑到服务级的信息。
为满足各种网络实时业务、应用智能的快速响应,运营商将各种不同VNF部署网络边缘侧,从而降低时延,提高服务质量。而边缘侧的资源是非常有限的,在服务器节点上放置过少的VNF会导致服务质量下降,放置过多的VNF则会造成资源的浪费。准确预测未来一段时间内的VNF需求,能够降低运营成本并提升网络服务质量。
以往研究中并未考虑边缘网络与核心网络服务流量特点的差别、预测模型复杂度高以及边缘网络资源的限制等问题,因此,在核心网络中的流量预测方法并不完全适用于边缘网络。本文针对目前单一模型难以刻画出边缘网络流量特征、VNF需求预测不够准确等问题,考虑边缘网络中网络服务数据凸显的波动性大、突发性强等特征,提出了一种适用于边缘网络的VNF需求预测方法,能降低误差,提升预测效果,实现VNF的提前放置,提高网络服务体验质量。
1 基于SVR与GRU的组合预测模型
当前,边缘的各类网络功能设备由各个设备独立实现,很难进行互相操作,无法满足基于某种商业规则控制用户的各类业务,例如机顶盒(Set Top Box,STB)、接入网关设备和数据包深度监测(Deep Packet Inspection,DPI)等,而边缘计算的兴起与网络功能虚拟化技术的迅速发展带来了一系列的改革,网络运营商借助NFV技术可以在在网络边缘放置不同类型的VNF,为用户提供相关的网络服务,以在降低系统成本的同时提供高效的服务质量,其中VNF是以软件的方式实现以往运行在专有硬件设备上的网络功能实例。但是,在网络边缘实例化各种VNF是需要时间的,且放置相应VNF实例的数量是非常重要的,放置过多的VNF实例会造成系统资源的浪费,增加成本,而放置的VNF实例过少时会导致用户任务计算时延增大,降低用户的服务体验质量。为实现VNF的提前放置以及可伸缩,本文提出了一种新颖的VNF需求预测方法,系统模型如图1所示。

图1 系统模型
在边缘节点中,依据历史服务数据,通过构建一个预测模型,提取历史数据的相关特征,预测未来一段时间内的网络服务流量,进一步分析VNF的需求,从而可以提前放置相应的VNF,实现VNF及网络服务的弹性部署,降低系统的成本并提高资源利用率。
1.1 边缘网络业务流量特征
随着大量移动设备、各种实时网络业务的增多,导致边缘网络流量的不确定性。依据文献[11-12]的描述,大量接入边缘网络的用户会直接影响网络流量的特征,在边缘网中会产生突发性强、波动性大的流量,导致网络时延,网络流量越来越表现出自相似的特征,且通过对大量网络流量的测量和分析,人们发现网络业务长期以来具有范围依赖性,即网络业务流量具有长期依赖性。其中自相似性是一种统计特征,描述流量在不同的时间尺度上流量时间序列存在突发性,并且不会随着网络的规模、拓扑及应用的变化而变化。这对研究边缘VNF需求预测的解决方案有一定启发。
1.2 SVR模型
支持向量机(Support Vector Machine,SVM)于1995年被提出,最初主要用于解决两组分类问题。近几年来,SVM也被用于解决一些回归问题。支持向量回归(Support Vector Regression,SVR)可用于非线性的短期时间序列预测,且可不需要大量的样本就能够较为准确地预测,也不容易陷入局部最优解,泛化能力强,但是在分析大量的时间序列数据上并不能够很好地提取到这些时间序列长期依赖的某些特征。
1.3 GRU模型
循环神经网络(Recurrent Neural Network,RNN)是基于普通多层的BP(Back Propagation)神经网络,通过一个权重矩阵将隐藏层的各单元间进行横向联系,可以将前一个神经单元的输出值传递至当前的神经单元,从而使RNN模型在处理时间序列上以及自然语言处理等方面具有很大的优势。
而门控循环单元(Gated Recurrent Unit,GRU)作为循环神经网络中的一种,本身就具备记忆功能,能够较好地分析大量的具有长期依赖性的时间序列,在神经网络层数可控范围内又能够消除RNN存在的梯度消失和爆炸的问题,且GRU相对LSTM来说结构简单,适合在计算资源有限的网络边缘节点进行放置运行,但对于短期内的突发性特征不能够很好地处理。
1.4 SVR-GRU模型构建
为提升预测效果,一方面通过SVR对少量历史数据进行学习,较好地提取网络业务流量的短期数据特征;另一方面,利用GRU模型处理长期时序数据,提取网络业务流量的长期特征,而且两种模型都具有较低的复杂度,适合在资源有限的边缘网络中运行。通过有效结合SVR和GRU,为其赋予不同的权重,构建SVR-GRU模型,提取数据短期内的突发性特征和长期特征,以提升VNF需求预测效果。
若FS表示支持向量回归的预测结果,FG表示门控循环神经网络的预测结果,则SVR-GRU模型预测结果FS-G可表示为
FS-G=αi×FS+αj×FG。
(1)
式中:αi、αj分别为SVR模型和GRU模型的权重且满足
(2)
采用方差倒数法即误差平方和倒数法,旨在依据不同模型预测精度的不同确定相应模型的权重。预测模型精度越高,则其在组合预测中所占有的权重越大,反之越小。于是不同预测模型的权重可进一步表示为
(3)
式中:Dk为第k个模型的误差平方和。
进一步可计算SVR模型与GRU模型权重为
(4)
由于不同测试数据组计算出的权重会有不同,为避免单组测试数据组计算导致的偶然性,通过计算多组权重的平均值,将均值作为最终SVR-GRU模型的权重。于是,SVR模型与GRU模型权重进一步表示为
(5)
式中:αi表示由单组测试数据计算的SVR模型权重,αj表示由单组测试数据计算的GRU模型权重。
最终预测效果用均方根误差(Root Mean Squard Error,RMSE)表示,它是误差的平方期望值,RMSE值越小则代表预测效果越好。
若未来n个时刻的预测值之和为
(6)
则SVR-GRU组合模型预测的均方根误差为
(7)
式中:y(t)为实际值。
其中模型权重确定的过程如下:
输入:训练完成的SVR模型;训练完成的GRU模型;N组测试数据;初始化索引i=1,j=1。
输出:权重αSVR和αGRU。
Step1 根据SVR模型与测试数据进行预测得到预测结果FSVR。
Step2 根据GRU模型与测试数据进行预测得到预测结果FGRU。
Step3 由SVR模型预测结果FSVR计算得到方差DSVR,由GRU模型预测结果FGRU计算得到方差DGRU。
Step4 由公式(3)和(4)计算出SVR模型的权重αi和GRU模型的权重αj,并保存相应的结果。
Step5 若满足i==j==N,则停止循环,执行Step 7;若不满足i==j==N,则执行Step 6。
Step6 令i=i+1,j=j+1,重新执行Step 1。
Step7 依据公式(11)计算出SVR模型的权重αSVR和GRU模型的权重αGRU并输出。
1.5 模型复杂度分析
对于神经网络模型的复杂度来说,计算复杂度影响着模型训练的时间,模型复杂度过高则会模型训练耗费大量的时间,无法快速预测。
由文献[13-14]可知,一般情况下,SVR使用精确搜索算法的时间复杂度为O(l3),使用不精确算法的时间复杂度则是O(l2),在实践中选择满足一定要求的不精确的搜索算法可以使时间复杂度保持在O(l2),其中l为训练样本数量。RNN执行n次序列操作后的总时间复杂度为O(nd2),其中d表示维度。由于SVR和GRU模型可以并行训练,时间复杂度可以认为是O(nd2)。
对于空间复杂度来说,支持向量回归空间复杂度一般为O(2×l×(m+1)+2×(l+1)2+2×(l+1)),m为样本输入维数。LSTM单元拥有输入门、输出门、遗忘门和候选态,若隐藏层单元数目为n,则LSTM的空间复杂度为O(4×(n×m+n2+n))。GRU内部单元则拥有比LSTM少的参数,通过维护一个参量控制信息的遗忘与更新,因此,空间复杂度可表示为O(n×m+n2+n)。由于时间序列输入样本的维度m≪l,将常量m作为常数1消除,SVR的空间复杂度可进一步表示为O(2×l2+6l)。同理,LSTM和GRU的空间复杂度分别为O(4×n2+8×n)和O(n2+2×n)。于是,SVR-GRU组合预测模型的空间复杂度可表示为O(n2+2×n+2×l2+6×l)。由于SVR模型的训练样本数量较少,一般情况下LSTM模型隐藏层单元数目较于SVR训练样本数量近似相等或比其更大,此时,SVR-GRU模型的空间复杂度会更低一些。SVR训练样本数量为l,n为LSTM隐藏层单元数量,则SVR-GRU模型与LSTM模型空间复杂度对比如表1所示。

表1 SVR-GTU与LSTM的空间复杂度对比
2 需求分析
通过SVR-GRU模型对边缘节点未来一段时间内不同网络服务需要处理的请求进行预测,为VNF需求分析提供相应的数据支撑。
不同的网络服务有不同VNF组合,也即由不同的VNF按照业务逻辑组合成不同的网络服务功能链,且不同网络服务可能包含相同类型的VNF。因此,利用预测出的不同网络服务需要处理的请求,能够计算出每种VNF需要处理的请求。
若集合S={s1,s2,…,sm}为通过SVR-GRU模型预测出的m种网络服务需要处理的请求量,对于m种网络服务,每种网络服务由不同的VNF组成,若组成每种网络服务的VNF类型集合为Fk={Vi,Vi+1,…,Vj},而所有网络服务所包含的VNF类型集合为V={V1,V2,…,Vn},每种VNF单位时间内处理请求的数量为h={h1,h2,…,hn},则每种VNF在某段时间内要处理的请求数量Rn为
(8)
在边缘节点资源足够时,若v={v1,v2,…,vn}为每种VNF的所需数量,则每种VNF需求量为
(9)
由于网络服务中同类型的VNF可能是多个,与具体业务逻辑相关,可以进一步通过不同网络服务功能链中同种VNF数量占比进行计算,即
(10)
式中:vn-sk为网络服务k中类型为n的VNF数量。利用相应的分析结果可以在边缘节点提前进行部署VNF,以降低系统成本,提高网络服务质量。
若边缘节点上的计算、网络和存储资源不足以支撑其覆盖范围下的所有用户请求,则需将部分VNF放置在至周围其他边缘节点,才能保证所有任务能够被及时处理。
3 仿真分析
3.1 实验设计
由于需要验证组合预测模型预测的效果,本文实验中设置了传统方法、RNN以及LSTM模型与SVR-GRU模型预测的预测效果对比以及相应预测模型的RSME指标对比等。
3.1.1 数据集
模型训练的数据集来自意大利米兰市公开电信数据集,该数据集收集了从2013年11月1日到2014年1月1日两个月内有关米兰市和特伦蒂诺省电信活动的数据,数据是经过一定缩放处理的[15]。将采集数据的地区分为若干个地区,且每隔10 min采集一次数据,收集的数据主要包括短信服务(SMS)、通话服务(Tel)以及互联网服务(Net)数据。
依据文献[15]中数据详细说明,每当用户产生电信活动时,都会为其分配一个附近的无线电基站,由基站进行网络传输,并记录详细的数据。由于基站接近用户端,处于网络边缘,每个基站所包含的范围可以看作是一个边缘节点,因此,记录的数据具有网络边缘侧流量数据波动性大、突发性强等特征,可以作为验证本文方法的数据集。
3.1.2 数据预处理
由于区域内不同服务涉及与其他不同区域的交互,需要预先对某块区域内的服务交互数据进行整理。由于数据采集时间间隔10 min,对于每种网络业务服务每天有24×6个数据,两周数据为24×6×14即2 016个数据,则两个月有24×6×60即8 640个数据。两周的数据集记为DS,作为支持向量回归模型的训练及测试;两个月的数据集记为DL。DS用于SVR模型的训练及测试,DL用于GRU模型的训练及测试。整理的数据格式如表2所示。

表2 数据预处理格式
分别对整理的数据集进行标准化处理,加快模型的收敛及最优解的寻优过程。标准化后的数据均值为和方差为常数,模型的训练集数据与测试集数据的比例为3∶1。此外,随机选取12组数据(12×144个)作为训练好的SVR和GRU模型的输入数据,从而进一步依据方差并计算出不同测试数据得到的权重均值,确定模型的权重。
3.1.3 仿真流程
在数据预处理完成之后需要构建SVR-GRU模型并对该模型的预测效果进行有效分析,实验仿真流程如图3示。
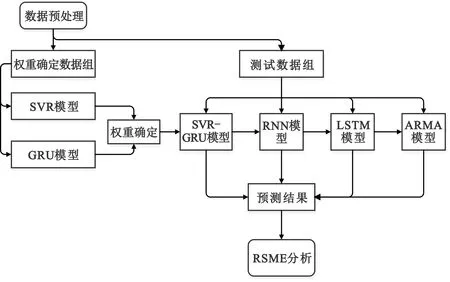
图2 实验仿真流程
对于每一种的网络服务数据,将预处理之后的数据分为两组,分别为权重确定数据组和测试数据组。其中权重确定数据组作为SVR模型与GRU模型的输入,计算出相应的误差,通过方差倒数法得到多组权重值,分别取权重的均值作为最终两种模型的权重。测试数据组是为验证与自回归移动平均模型(ARMA)、RNN和LSTM模型的对比,输入多组测试数据,得到相应模型的预测结果,计算相应的RMSE参数并进行分析。
3.2 结果分析
文献[5]通过分析预测值和实际值对比了文中提出的CAT-LSTM和基本LSTM的模型,也分析了其准确性和误差。文献[4]通过实验分析不同网络切片预测MAPE误差参数以及LSTM平均误差。文献[16]通过计算预测值与实际值之间的RMSE参数说明其预测精度。文献[12]基于ARMA的方法对资源需求进行了预测。为保证不同预测模型预测误差分析是有效合理的,选取多组数据作为测试数据,且每组数据有144个数据。最后,通过对比不同模型的计算得到的RMSE参数,验证本文提出的SVR-GRU组合模型效果。实验参数设置为如表3所示。

表3 不同模型相关参数
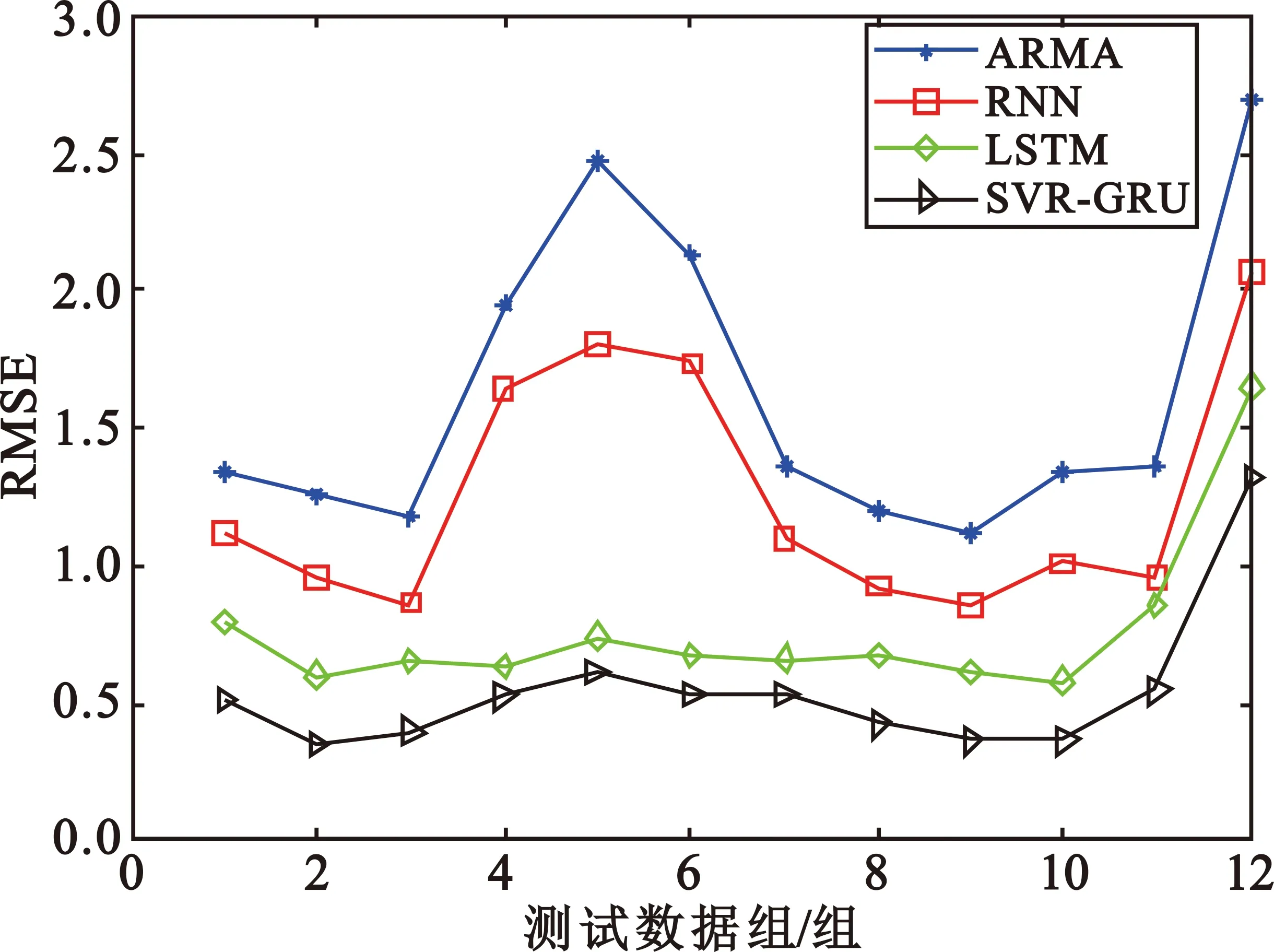
图3是SVR-GRU模型对SMS网络服务流量的预测值与实际值对比图,可以看出,模型除却波动极大的时刻有一定的误差,其他时刻能够比较准确地预测。

图3 SVR-GRU模型预测效果图
RMSE参数越小,代表模型预测效果越好。图4是由6组数据计算权重、其他测试数据相同的条件下计算得到的RMSE参数,可以看出SVR-GRU模型的RMSE总是最小,也即SVR-GRU模型预测的误差最小,在这几种模型中预测效果最好。
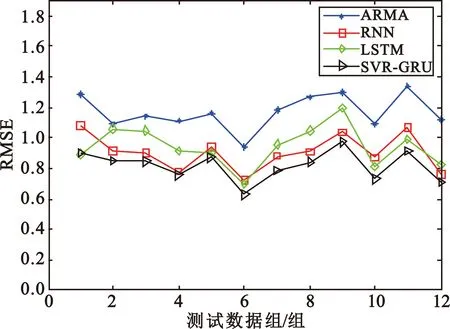
(a)SMS服务中四种算法预测误差

(b)通话服务中四种算法预测误差
(c)互联网服务中四种算法预测误差图4 由6组数据计算权重时不同模型的RMSE
为探讨权重值与测试数据组数的关系,依次增多确定权重的数据组,分别对短信服务、通话服务及互联网服务进行了实验,实验结果如图5所示。由图可以看出,在其他条件相同时,SVR-GRU模型的RSME参数随着权重确定的数据组的增加而一定程度的降低,也即预测效果会有所提升,在数据组数增加到10组之后,RMSE参数会逐渐趋于平缓。实验结果表明,多的数据组确定权重,可以避免单组数据确定权重造成的偶然性,降低RMSE值,提升预测效果。
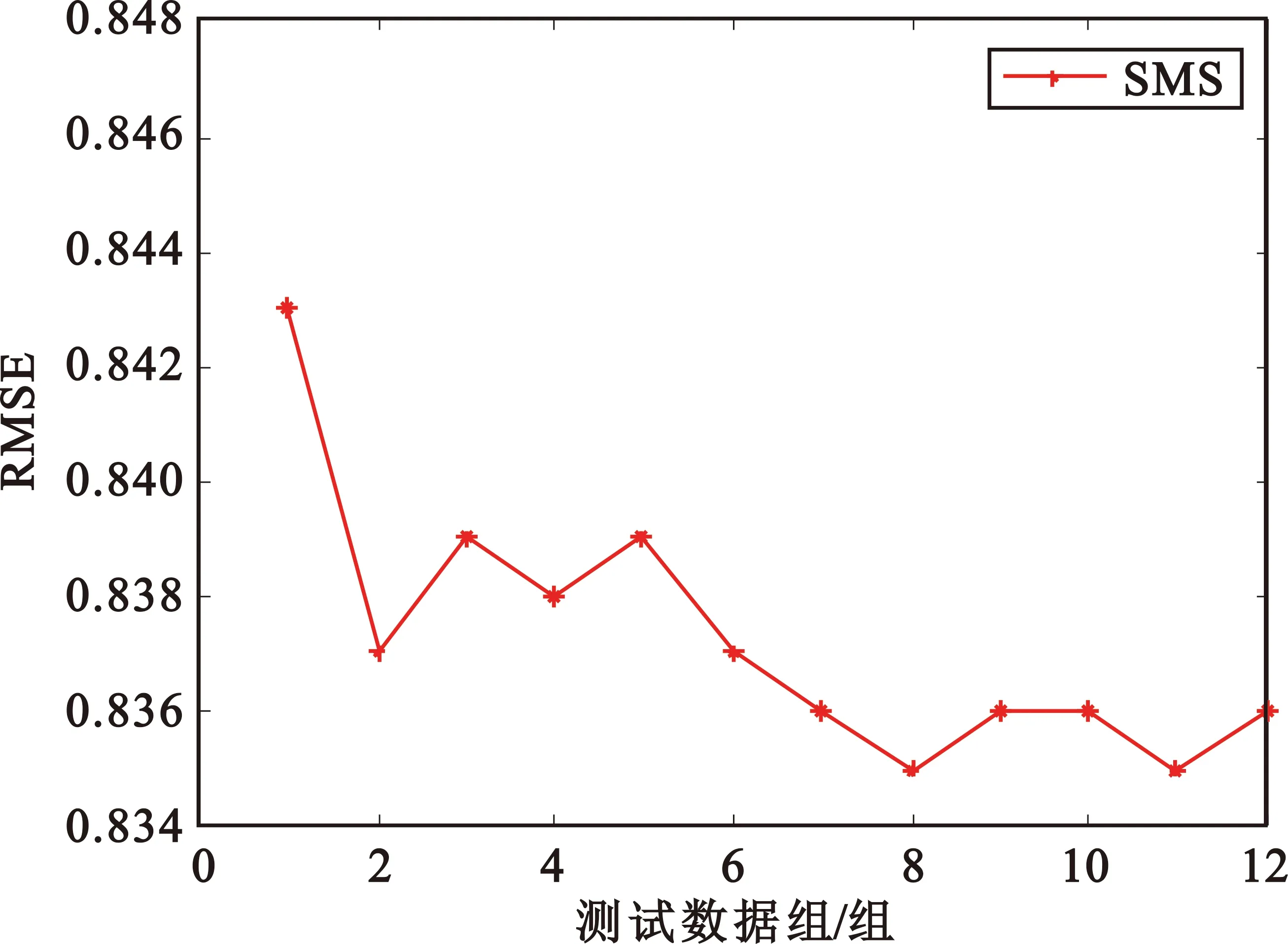
(a)SMS服务RMSE与测试数据组的关系

(b)通话服务RMSE与测试数据组的关系

(c)互联网服务RMSE与测试数据组的关系图5 测试数据组与RMSE的关系
图6是与图5相对应的权重值变化过程,可以看出,随着测试数据组数的增加,两种模型的权重值会逐渐达到一个相对稳定的值。权重的大小也与模型预测效果相对应,模型预测效果越好,对应的赋予的权重值就会越大,反之越小。此外,由于不同网络服务产生的流量数据特征的不同,会影响不同模型的权重分配,随着测试数据组的增加,SVR模型和GRU模型的权重会逐渐达到一个相对稳定的范围。
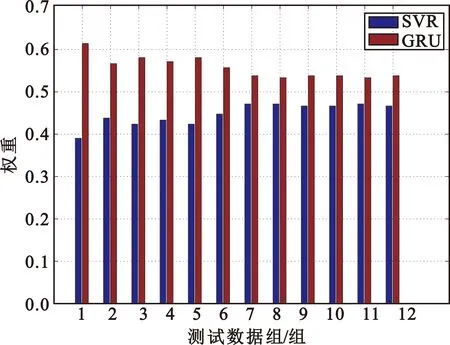
(a)SMS服务重权重与测试数据组的关系

(b)通话服务中权重与测试数据组的关系

(c)互联网服务中权重与测试数据组的关系图6 测试数据组对应的权重
4 结束语
本文针对当前VNF需求预测方法准确率较低且不适用于边缘网络的问题,提出了一种适用于边缘网络的VNF需求预测方法。该方法考虑到边缘网络中网络服务流量的特点,利用真实的网络服务历史数据将SVR和GRU模型组合,通过仿真证明了该方法能够适当降低误差,提高预测准确率。但本文对于边缘资源不足时VNF的放置以及边缘节点之间的协作策略并未透彻分析,后续将展开深入研究。
