基于隐函数的三维纹理网格重建
2021-12-28韩煌达张海翔马汉杰蒋明峰冯杰
韩煌达 张海翔 马汉杰 蒋明峰 冯杰



摘 要: 目前,面向实景图像的单图三维重建算法大多无法重建或者只能重建出已知拓扑结构类型的带纹理三维网格。文章结合目标检测网络,构建了基于隐函数的纹理推断网络“ColorNet”,用于预测三维网格顶点的RGB值,并且为Pix3D数据集的三维模型添加UV纹理映射,并进行渲染、颜色采样。网络在经预处理后的数据集上训练并测试。实验表明,“ColorNet”可以预测出三维网格顶点的RGB值,并通过与三维重建网络“IM-RCNN”相结合,实现从单张实景图像中自动地重建接近真实纹理的三维模型。
关键词: 三维重建; 纹理推断; UV纹理映射; 目标检测
中图分类号:TP3 文献标识码:A 文章编号:1006-8228(2021)12-01-05
Abstract: At present, most of the three-dimensional reconstruction algorithms for real-world images cannot reconstruct the 3D models with texture or can only reconstruct the 3D textured mesh with known topology types. In this paper, combined with object detecting network, a texture inference network "ColorNet" based on implicit function is proposed to predict RGB values of vertices of 3D mesh. UV texture mapping is added to the 3D model of Pix3d dataset by the network, and then the 3D model is rendered and color sampled. The network is trained and tested on the pre-processed dataset. The experiment shows that the RGB values of vertices of 3D mesh can be predicted by "ColorNet", and the 3D mesh model close to the real texture can be automatically predicted from single real world image by combining with "IM-RCNN".
Key words: 3D reconstruction; texture inference; UV texture mapping; object detecting
0 引言
近年来,随着卷积神经网络的普及应用和大规模三维模型数据集的出现,基于深度学习的单图三维重建取得了较大的进展,通过这些单图三维重建网络,可以有效地从图像中重建出物体的三维模型。然而,这些算法仍然存在一些不足。
首先,目前的网络大多将研究重心放在三维形状重建上。然而,在现实世界中,物体不仅有三维形状,而且有纹理,有色彩。他们互相关联互相补充,使人们对三维物体的理解更为全面。因此,从图像中重建带有纹理的三维模型具有理论意义和实用价值,可以应用于虚拟现实、增强现实等诸多领域。
其次,这些网络大多从渲染图像中重建三维形状,所用图像只有单一的物体处在图像中心并且没有背景。而面向实景图像的单图三维重建网络所重建的三维形状大多没有纹理,或者只能重建出已知拓扑结构类型的三维网格。
针对这些问题,本文提出了“ColorNet”,该网络可以从实景图像中预测出物体三维网格顶点的RGB值。本文的主要贡献在于①结合目标检测网络,提出一种基于隐函数的纹理推断网络,并且通过与实景图像三维重建网络“IM-RCNN”[1]相结合,使得网络能够从单张实景图像中重建出带纹理的三维模型;②实景图像三维模型数据集Pix3D[2]缺少UV紋理映射,使用三维建模软件Blender为所有的三维模型添加UV映射并增加纹理,并筛选整理了每个三维模型所对应的实景图像使得网络更容易训练,形成了可用于纹理推断网络的实景图像三维模型数据集。
1 相关工作
1.1 基于深度学习的实景图像三维重建
针对实景图像的三维重建,Yao S等人[3]首先利用目标检测网络预测得到物体的掩膜,将它和图像叠加得到去除背景后的物体,再预测物体的三维属性,对已有的三维网格模板形变,以此重建三维模型。WU J[4]等人使用经裁剪后物体处于中心位置的图像,训练了“3D-VAE-GAN”网络来重建三维模型,该网络只能生成低分辨率的三维模型。GKIOXARI G等人提出了“Mesh R-CNN”[5],该网络结合目标检测网络,首先预测一个粗糙的体素模型,并将其转化为初始网格模型,再使用图卷积[6]网络将其形变,获得最终的三维网格。在我们之前的工作中[1],提出了基于隐函数表示法的单图三维重建网络“IM-RCNN”,该网络结合Mask RCNN[7],能够从实景图像中重建出高分辨率的三维模型,并且具有更好的视觉效果,是目前较为有效的方法。然而,所重建的三维模型仍然不具有纹理。KANAZAWA A等人[8]对预定义的三维网格进行形变,实现了从实景图像中重建鸟类的三维模型。
1.2 基于深度学习的纹理推断
针对三维物体的纹理推断,Tulsiani S等人[9]使用多个视图和光线一致性作为监督,提出了一个基于体素的纹理表示法,重建出了带有纹理的三维体素模型。SUN Y等人[10]将三维形状估计和体素颜色回归结合起来,从单张图像中重建出带有纹理的三维体素模型。然而,由于体素表示法不具备内存效率,他们只能重建出分辨率较低的三维纹理模型。NATSUME R等人[11]将视图生成方法用于从图像中重建出带纹理的三维人体模型。他们提出的视图生成方法,可以从前视图中预测后视图,再将前视图和后视图一起用于为三维人体模型添加纹理。KANAZAWA A等人[8]首先预测UV纹理映射图的RGB值,再将该图进行UV映射,为三维网格添加纹理。SAITO S等人[12]提出了像素对齐隐函数表示法用于三维人体重建,并对该表示法作了扩展,使用隐函数来回归RGB值,从而能够推断出每个顶点的颜色,最终实现从图像中重建带纹理的三维人体模型。
2 网络设计
目前,基于隐函数的三维形状表示法受到越来越多研究者的关注[12-15],在隐函数表示法下,三维形状可以由一个连续函数[f]的[k]等值面来表示,例如:
SAITO S等人[12]将隐函数作了推广,通过一个连续函数[f]将一个三维空间点[X]映射成一个RGB向量,即:
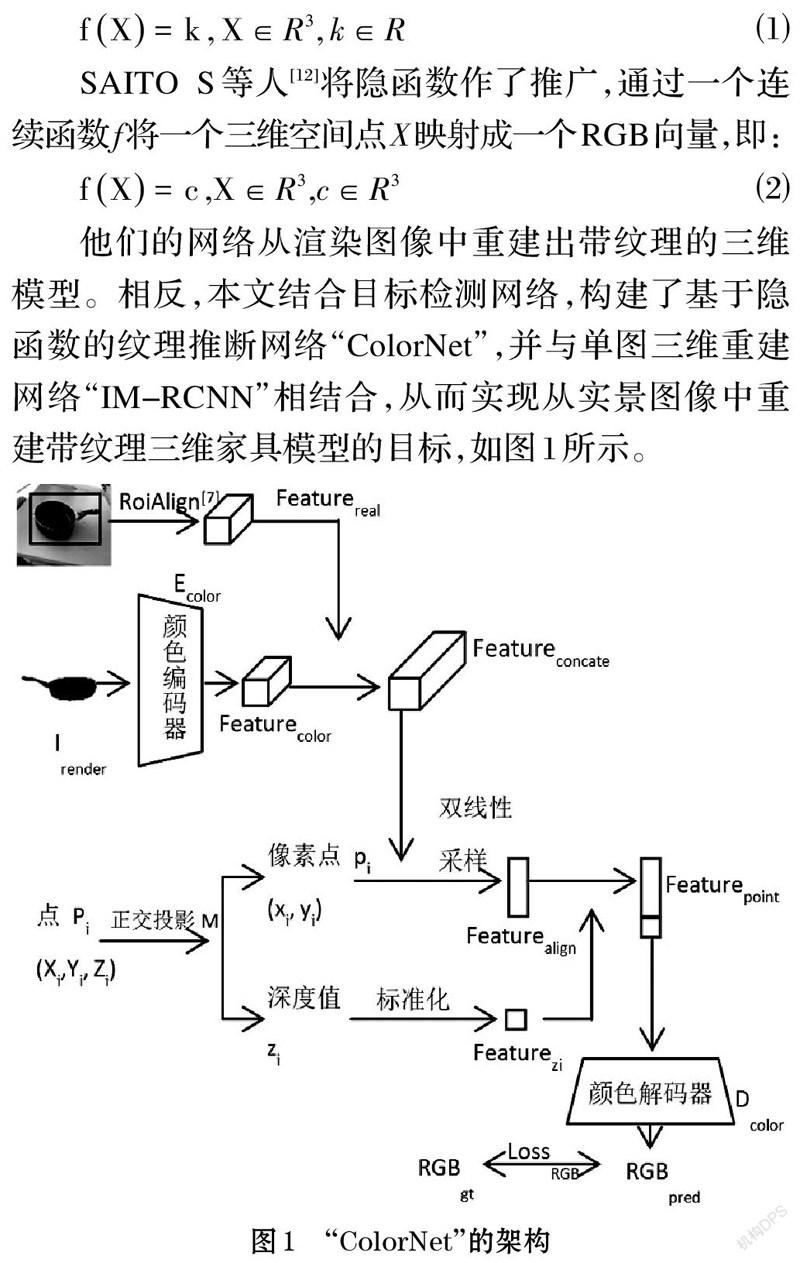
他们的网络从渲染图像中重建出带纹理的三维模型。相反,本文结合目标检测网络,构建了基于隐函数的纹理推断网络“ColorNet”,并与单图三维重建网络“IM-RCNN”相结合,从而实现从实景图像中重建带纹理三维家具模型的目标,如图1所示。
2.1 纹理推断及损失函数
图1展示了“ColorNet”的架构。由于本文面对的是实景图像,因此需要获得物体在整幅图像中所处位置的特征图。在目标检测网络的相关工作中,REN S等人[16]提出了“ROI Pooling”,用于获取与输入图像对齐的区域特征图,之后He K等人[7]使用双线性差值提升了对齐精度。因此,“ColorNet”使用RoiAlign[7]操作,从输入的单张实景图像中得到区域对齐特征图[Featurereal∈RC×H×W]。同时,网络随机输入一张该三维模型的渲染图像[Irender],利用一个由残差网络组成的颜色编码器[Ecolor]对它进行映射,即:
经过映射,将[Featurecolor]和[Featurereal]在通道维度上相连接,得到[Featureconcate∈R2C×H×W]。
另一边,有[N]个用于训练的三维采样点集[P],以其中一个点[Pi]为例,使用正交投影矩阵[M]将它投影到图像平面上得到像素点[pi=M(Pi)],并获得在相机坐标系上的深度值[zi]。之后,使用双线性采样获得与该像素点对齐的特征[Featurealign∈R2C×N],同时将深度值[zi]标准化作为深度特征[Featurezi∈R1×N],将两者在维度上相连接,得到该采样点最终的特征[Featurepoint]。最后,将该采样点的特征送入颜色解码器[Dcolor],得到预测的颜色向量[RGBpred∈R3×N],即:
损失函数[LossRGB]是所有三维采样点对应的预测RGB值和标注RGB值之间的均方误差,即:
2.2 顏色编码器和颜色解码器的结构
目前,通过残差网络可以有效地提取图像特征。本文对ResNet-18[17]网络结构进行微调,移除原有的池化层,使用卷积核大小为9×9,步长为2的卷积层进行替代,并使用LeakyReLU作为激活函数,得到用于提取图像颜色特征的编码器。
颜色解码器用于学习一个连续的函数来预测出三维网格每个顶点对应的RGB值。由于多层的前向网络可以在任何精确度上拟合出一个连续的形状函数[18],本文采用八个全连接层搭建颜色解码器,并且除第一个全连接层,其余各层均将上层的输出特征与第一层的输入特征在维度上相连接,作为本层的输入特征。另外,除最后一层的激活函数为Tanh以外,其余各层均采用LeakyReLU激活函数。
3 数据预处理
实验在Pix3D[2]数据集上进行,该数据集包含9个类别的物体,共有10069张实景图像、395个三维家具模型。然而该数据集中,某个三维模型在不同的实景图像中可能拥有不同的纹理,并且这些三维模型不具有UV纹理映射。因此,网络训练前,我们对三维模型进行预处理,并且筛选每个模型对应的实景图像,使得每个三维模型在不同的实景图像中都有相近的纹理,便于网络进行收敛。
3.1 添加UV纹理映射
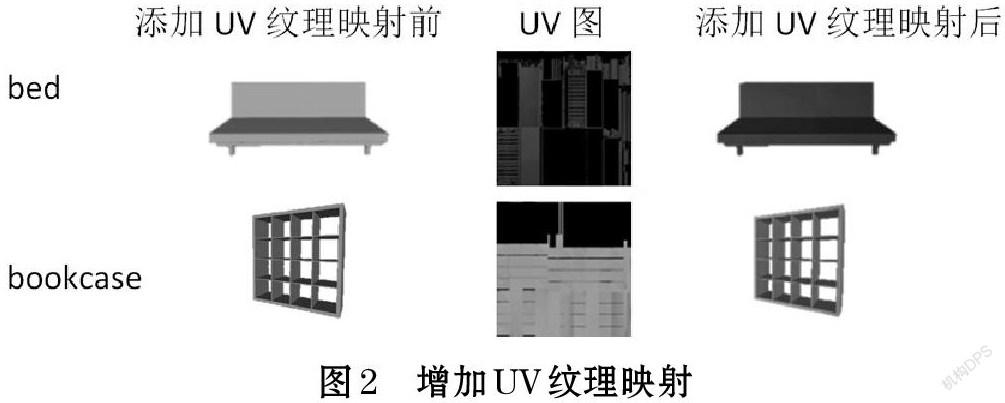
为了进行三维模型的渲染以及网格表面点的RGB值采样,需要使用带有UV纹理映射图的三维模型。由于原始的Pix3D数据集中的三维模型不具备UV纹理映射图,在实验中需要为395个三维网格模型手工添加纹理。本文使用三维建模软件Blender,依次为三维模型添加UV映射图、绘制纹理以及着色,图2为添加纹理映射后的模型效果。
3.2 三维模型渲染
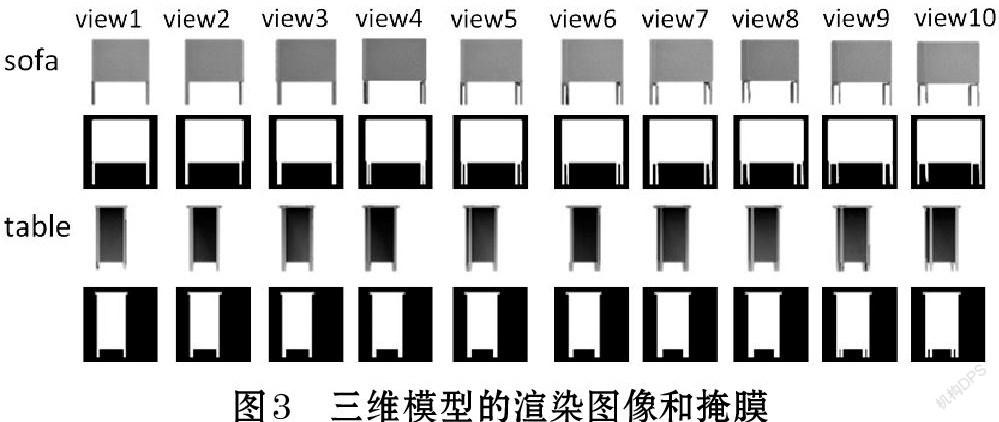
在为三维模型添加纹理映射之后,对它们进行渲染。使用弱透视相机模型将三维模型与图像中心对齐,并将每个三维家具模型围绕偏航轴旋转360度进行渲染,共生成142,200张512×512分辨率的渲染图像。图3展示了前10个旋转角度的渲染图像和掩膜,所生成的渲染图像没有背景。
3.3 三维表面纹理采样
在对三维模型进行渲染后,也可得到UV纹理映射图对应的法向量图、掩膜和渲染图像,如图4所示。
在对表面纹理进行采样时,本文使用UV掩膜来索引UV渲染图像、UV法向量图中对应的纹理区域,再从这些区域中随机采样指定数量的点,获得每个采样点对应的颜色值,作为标注RGB值。
4 实验
4.1 实验环境及参数配置
实验在单张GeForce RTX 2080 Ti GPU上进行,由于目标是生成带有纹理的三维形状,本文使用“IM-RCNN”训练后的模型作为纹理推断网络“ColorNet”的预训练模型,网络共迭代315000次。网络训练采用带动量的随机梯度下降算法,在前32000次迭代中,学习率从0.0025到0.02线性增加,之后在256000到315000次迭代中,以10倍数进行衰减。RGB值损失的权重是1,使用的权重衰减率是10−4。
4.2 带纹理的三维网格推断
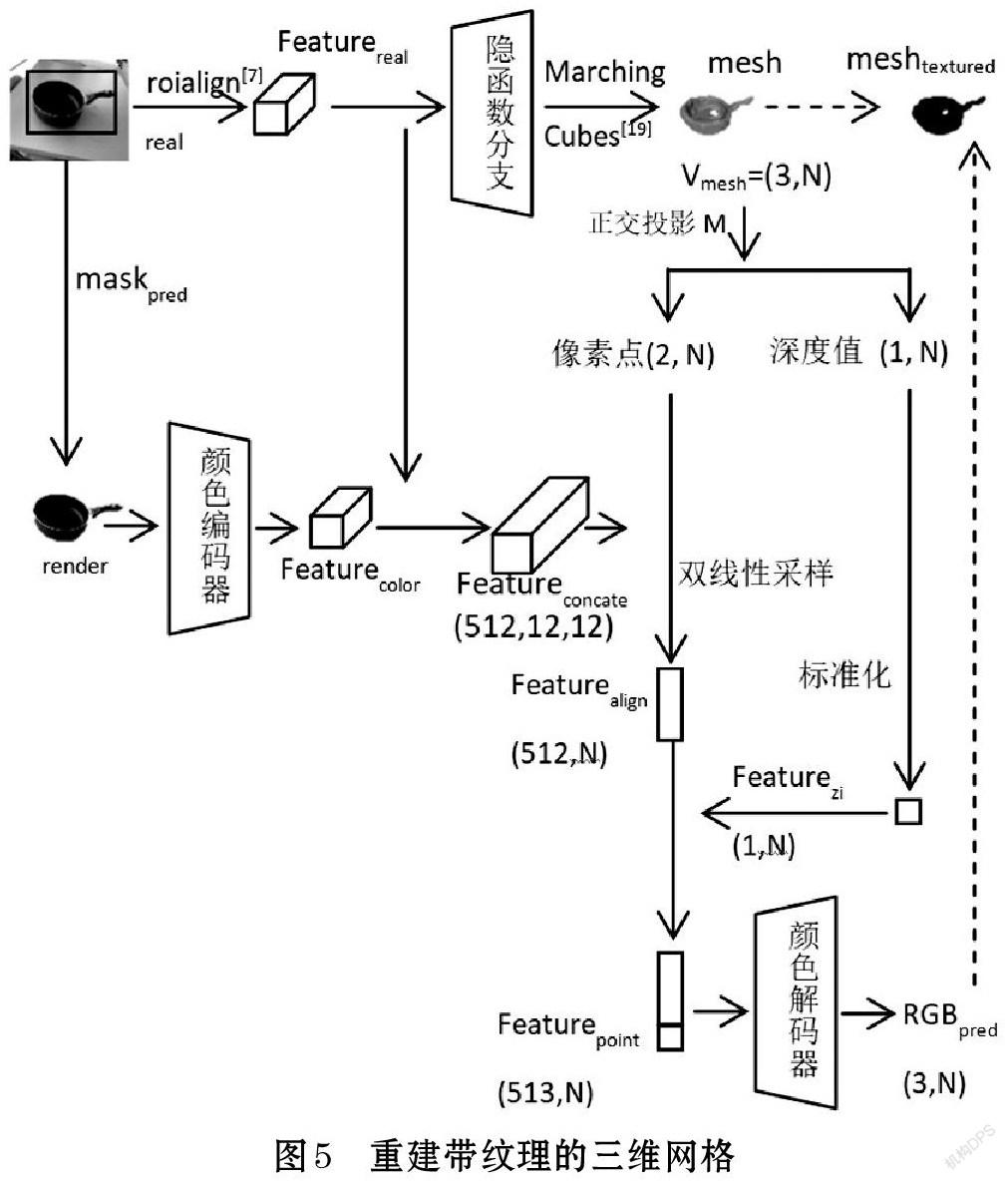
为了从实景图像中预测出带有纹理的三维模型,本文将纹理推断网络“ColorNet”与单图三维重建网络“IM-RCNN”[1]相结合,如图5所示。“IM-RCNN”的隐函数分支可以从单张图像中预测出物体的三维形状,它的掩膜分支和包围框分支可以输出物体的掩膜和包围框。
在推断时,网络结构与训练阶段略有不同。首先,网络从一张实景图像[Ireal]开始,通过RoiAlign操作获得区域对齐特征[Featurereal],再通过“IM-RCNN”的隐函数分支以及等值面提取[19]操作得到预测的三维网格[mesh]([Vmesh=(3,N)])。之后,“ColorNet”对[mesh]的[N]个顶点计算预测的RGB值。另外,网络通过“IM-RCNN”的掩膜分支得到物体的掩膜[maskpred],并与实景图像[Ireal]相叠加,得到去除背景的图像[Irender],并将其送入颜色编码器计算图像特征。
通过“ColorNet”得到每个顶点的颜色预测值[RGBpred]后,与预测网格[mesh]相结合得到最终带有纹理的网格[meshtextured]。
图6分别展示了“IM-RCNN”预测的无纹理三维模型、“ColorNet”与它结合后预测的带纹理三维模型以及真实的带纹理三维模型。从图6中可以发现,“ColorNet”可以有效地预测出三维网格顶点的RGB值,通过与“IM-RCNN”的结合,可以实现从单张实景图像中预测出接近真实纹理的三维网格。
4.3 与其他方法的对比分析
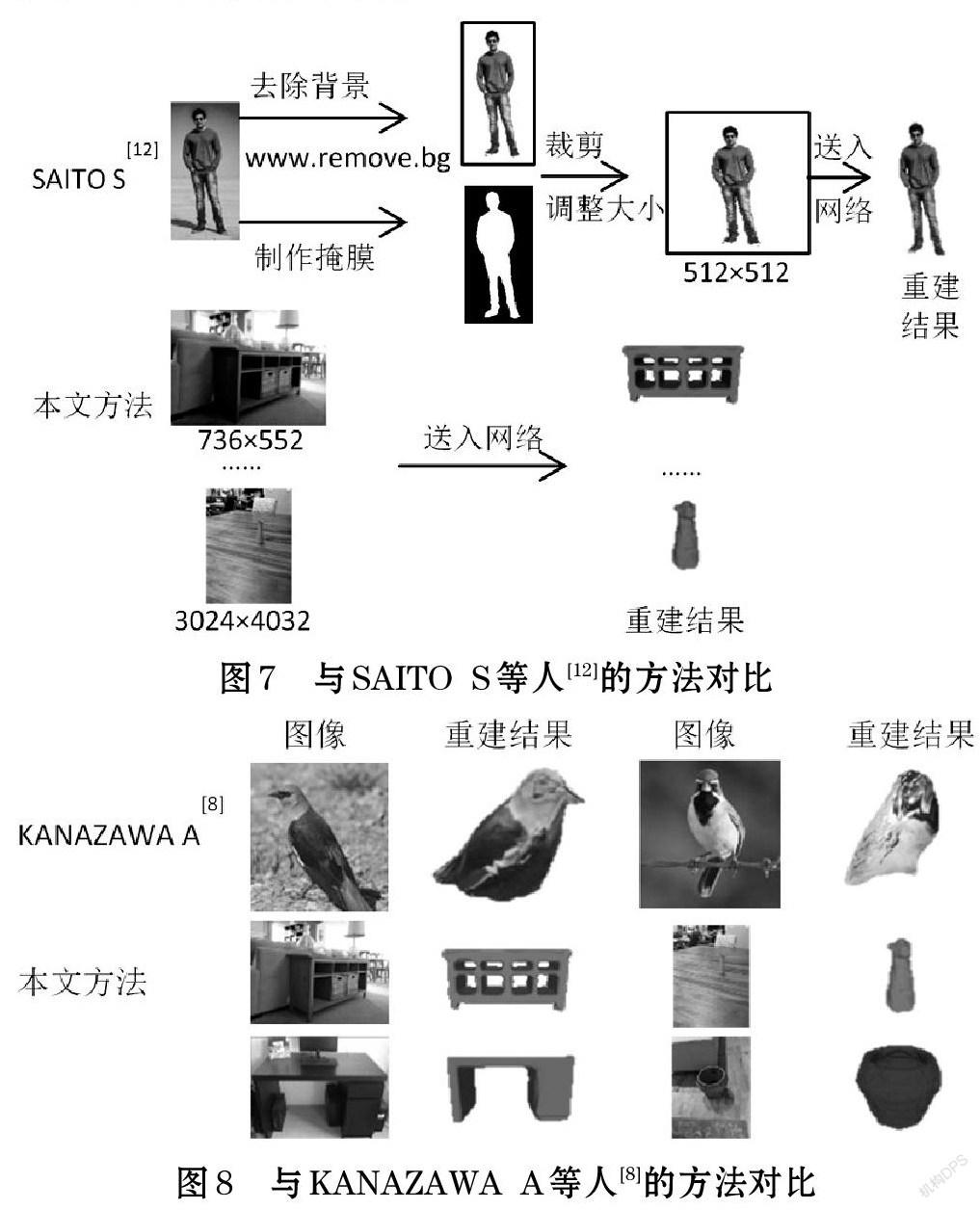
如图7所示,SAITO S等人[12]首先通过人工手段将实景图像去除背景,再制作与目标对应的掩膜,之后通过裁剪、调整尺寸等操作,获得目标位于中心、大小固定的圖像。他们的网络使用该图像作为输入,重建出带纹理的三维人体。相反,本文的方法直接使用实景图像作为输入,通过网络自动地重建出带纹理的三维模型。同时,输入图像可以拥有不同的尺寸大小,图像中的物体可以位于不同的位置。
如图8所示,KANAZAWA A等人[8]从实景图像中重建出了带纹理的三维鸟类模型。然而,由于使用固定的三维网格模板,通过对网格模板形变来重建模型,因此只能对某个特定类别的物体进行训练,获得已知拓扑结构范围内的重建结果。相反,本文的方法可以同时对多个类别的物体进行训练,并且可以处理任何类型的拓扑结构。
以上是对三维纹理模型推断方法的定性分析。对于纹理推断效果的定量评估,在目前已有的研究工作中仍然缺少一个合适的指标,需要做进一步的研究。
5 结束语
针对当前面向实景图像的单图三维重建网络所重建的三维形状大多没有纹理,或者只能重建出已知拓扑结构类型的三维网格等不足,本文结合目标检测网络,将隐函数方法用于预测三维网格顶点的颜色值,提出了纹理推断网络“ColorNet”,并且将它与单图三维重建网络“IM-RCNN”相结合,实现了从单张实景图像中自动地重建带纹理的三维网格。但在实验中为三维模型添加UV纹理映射图需要操作人员有一定的三维建模软件使用技能和熟练度。因此,探索其他方便有效的纹理采样方式是下一步的研究重点。
参考文献(References):
[1] 韩煌达,张海翔,马汉杰,蒋明峰,冯杰.面向实景的单图三维重建算法研究[J].软件导刊,2021.
[2] SUN X, WU J, ZHANG X, et al. Pix3d: Dataset and methods for single-image 3d shape modeling: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C], 2018.
[3] YAO S, HSU T M, ZHU J, et al. 3d-aware scene manipulation via inverse graphics: Advances in neural information processing systems[C], 2018.
[4] WU J, ZHANG C, XUE T, et al. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling[J]. Advances in neural information processing systems,2016.29:82-90
[5] GKIOXARI G, MALIK J, JOHNSON J. Mesh r-cnn: Proceedings of the IEEE International Conference on Computer Vision[C], 2019.
[6] SCARSELLI F, GORI M, TSOI A C, et al. The graphneural network model[J]. IEEE Transactions on Neural Networks, 2008,20(1): 61-80.
[7] HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn:Proceedings of the IEEE international conference on computer vision[C], 2017.
[8] KANAZAWA A, TULSIANI S, EFROS A A, et al. Learning category-specific mesh reconstruction from image collections: Proceedings of the European Conference on Computer Vision (ECCV)[C], 2018.
[9] TULSIANI S, ZHOU T, EFROS A A, et al. Multi-view supervision for single-view reconstruction via differentiable ray consistency: Proceedings of the IEEE conference on computer vision and pattern recognition[C], 2017.
[10] SUN Y, LIU Z, WANG Y, et al. Im2avatar: Colorful 3dreconstruction from a single image[J]. arXiv preprint arXiv:1804.06375, 2018.
[11] NATSUME R, SAITO S, HUANG Z, et al. Siclope:Silhouette-based clothed people: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C], 2019.
[12] SAITO S, HUANG Z, NATSUME R, et al. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization: Proceedings of the IEEE/CVF International Conference on Computer Vision[C], 2019.
[13] MESCHEDER L, OECHSLE M, NIEMEYER M, et al.Occupancy networks: Learning 3d reconstruction in function space: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C], 2019.
[14] CHEN Z, ZHANG H. Learning implicit fields for generative shape modeling: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C], 2019.
[15] PARK J J, FLORENCE P, STRAUB J, et al. Deepsdf: Learning continuous signed distance functions for shape representation: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C], 2019.
[16] REN S, HE K, GIRSHICK R, et al. Faster r-cnn:Towards real-time object detection with region proposal networks[J].IEEE transactions on pattern analysis and machine intelligence,2016.39(6):1137-1149
[17] HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition:IEEE Conference on Computer Vision & Pattern Recognition[C]: IEEE,2016.
[18] HORNIK K, STINCHCOMBE M, WHITE H. Multilayer feedforward networks are universal approximators[J]. Neural networks,1989.2(5): 359-366
[19] LORENSEN W E, CLINE H E. Marching cubes: A high resolution 3D surface construction algorithm[J]. ACM siggraph computer graphics,1987.21(4):163-169
