基于深度学习的中药材饮片图像识别
2021-12-18刘加峰高子啸段元民李海云石宏理
刘加峰 高子啸 段元民 李海云 石宏理
0 引言
中药饮片是中药材经过切片、晒制、烘焙等过程加工而成,其中绝大多数来自草本植物,它们在颜色、形状等天然属性上具有相似的特点,再经过加工后更使得它们原本的颜色、形状等特异性差异减弱,以至于对它们进行识别和分类时易出错,而这又直接关系到中药治疗疾病的效果,因此中药饮片的识别与分类是一项繁重又极其重要的工作[1]。
目前,中药材鉴别的传统方法多是基于临床药剂师的经验进行人工鉴别,有着诸多缺点,比如速度慢、准确率不高等,无法实现自动化操作。研究组将近些年来新兴的人工智能神经网络与深度学习应用于中药材鉴别,在有多种饮片复杂场景下,能快速准确地智能识别,提高了该技术在中药领域的实用性[2-3]。
1 计算机视觉目标识别系统设计
如图1所示,目标识别系统从输入图像开始,使用窗格扫描,进行特征选择和提取,之后经过分类器进行分类,得出最后的分类结果输出。在获得训练样本之前,所有图片都被归一化处理为固定分辨率的图片输入至网络中,然后对其进行特征选择和提取。在训练时,将真实框与先验框配对,与之匹配的边界值将会预测对应的真实框,从而达到预测目标的任务[4-5]。
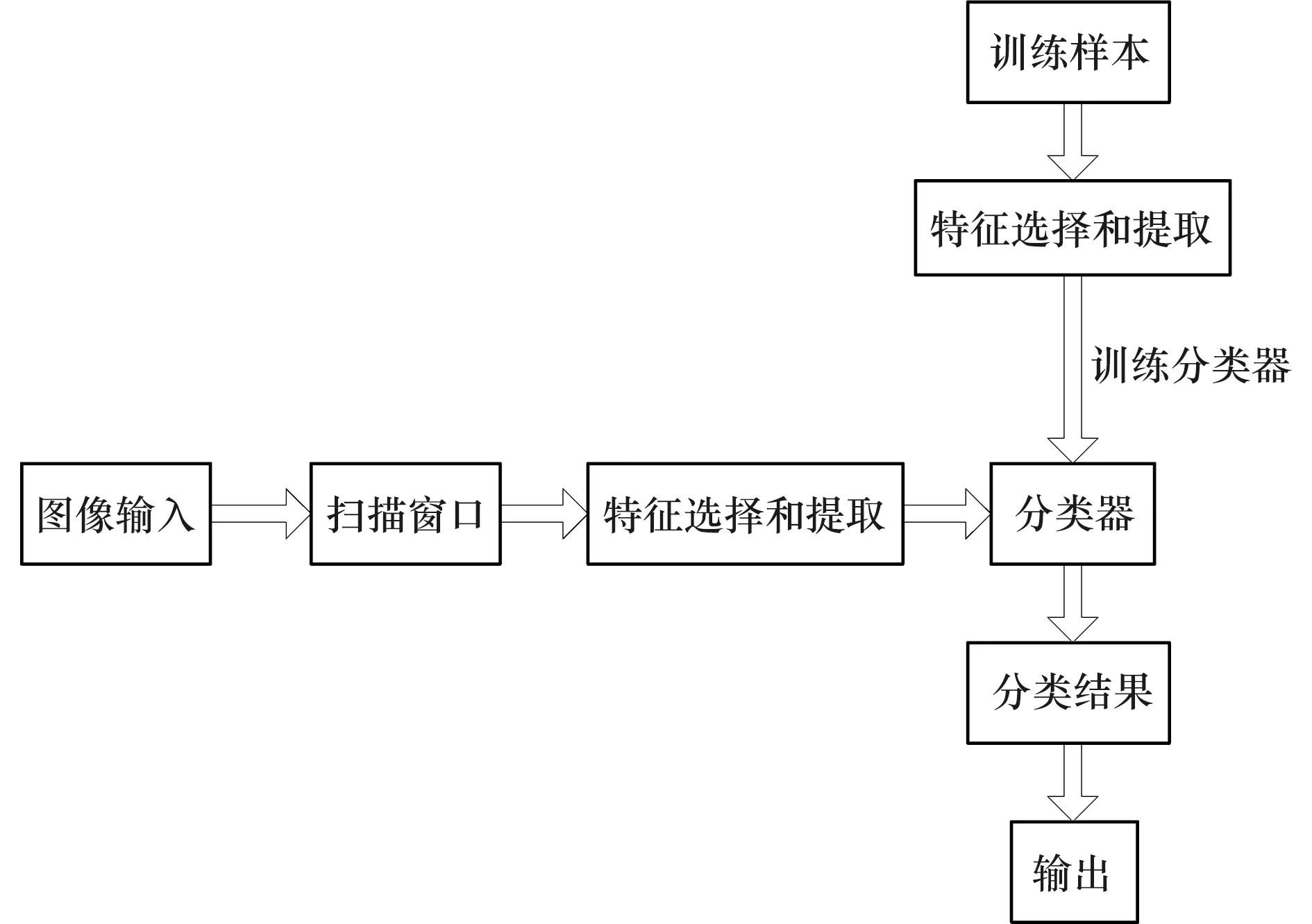
图1 目标识别系统图Figure 1 Target recognition system diagram
其中训练样本包括正样本和负样本,所谓的正样本指包含感兴趣的目标类别的样本(比如枸杞,甘草等),负样本指其他不包含目标的任意图片(如背景等)。在训练样本的过程中,通过平衡正负样本来达到选择和提取特征的目的,以此来提前训练好分类器,正负样本的比例设定为1∶3左右。
1.1 SSD模型网络架构
本文采用深度学习-卷积神经网络中的SSD(single-shot multibox detector)模型,设计了一个针对中药饮片的定位分类识别软件,能够识别输入图片中的多类药材,并框选出其在图片中的位置,可广泛应用于中药饮片的分拣。
识别过程分为两步。(1)图像中物体检测定位,即用手动标注出所有感兴趣的目标并定位其位置,从而得到真实框。(2)目标识别分类,对于手动框出的目标可自动判断出它属于何种中药材。
SSD模型是一种one-stage目标检测模型,含有多层卷积层,每层卷积层都会分别输出一次特征映射(feature map),这些特征映射具有不同的大小,会分别独自经过不同长宽比的检验框的检验,获得一定的位置数据与置信度,最后进行多层次融合,通过非极大值抑制(non maximum suppression,NMS)得出最后的目标检测结果。这样做的好处是足够快捷而且适用于不同大小的感兴趣目标的定位。
SSD的网络结构,使用VGG16作为前置网络,将原本的VGG预训练网络的全连接层去掉,加上后续的卷积网络,在每一层卷积后都输出一遍特征映射,在最后,将每一层卷积输出的带有预测定位和置信度的特征映射融合,进行检测定位[6-7]。
设定需要单像素图片先验框数量为n(n一般取值3),如果图片规格是m×p,则生成的先验框数量是n×m×p个,SSD网络通过对每个先验框进行定位回归,并在之后通过NMS得到最终的检测结果。
1.2 先验框匹配
SSD模型的先验框与真实框的匹配遵循以下原则。(1)图2中的真实框一定比先验框少很多,所以应先找与真实框交互比(intersection over union,IoU)最大的先验框,先把每个真实框都匹配上一个先验框。(2)匹配以后,对于剩下的许多未匹配的先验框,找出其中与附近真实框IoU值大于一定阈值的先验框,把这些先验框也与对应的真实框进行匹配,这样就有多个先验框与同一个真实框进行了配对。如果某个先验框与多个真实框匹配,则先验框只会和IoU最大的真实框进行配对。

图2 SSD匹配策略示意图Figure 2 SSD matching strategy diagram
第2个原则优先于第1个原则,因为如果出现真实框与之对应的先验框最大IoU也小于阈值,但是这个小于阈值的先验框还与另外一个真实框相匹配了,则第1个原则不生效,这是因为一定要保证每个真实框有一个与之匹配的先验框。
2 训练实践及结果分析
2.1 构建数据集
考虑到药材存在形式的多样性,在样本量很小的数据集中,很难将草本形式与烘干焙烤之后的同种药材归为一类,在这里本实验只针对中药饮片形式的药材进行分类,构建数据集,寻找材料进行拍摄,一张图片包含3种中药材(枸杞、甘草、陈皮),这之后同样使用标注工具手动进行标注。目前没有大规模公开的中药饮片的数据库或部分机构的数据库内容量太少,无法找到足以支撑深度学习网络要求的数据量的已有数据集,在本实验中数据集全为自己构建,共采集了超过1 000张相关药材的图片,随后把图片按比例6∶2∶2分割为训练集、验证集、测试集。
使用labeling标注图像,见图3。

图3 标注过程Figure 3 Labeling process
要求真实框的标注一定要大小合适,边缘紧凑,要一个个的分类并框出所有的目标物体,打上标签,而且标注框不能靠近图片的边沿。
2.2 网络模型选择
初步考虑为VGG-16卷积识别网络,采用了多层卷积层与池化层的组合,进行了随机光影变换的数据增强步骤,添加了dropout层以及数千次的循环,在训练集上进行训练,在测试集上进行测试,平均识别率可以高于80%。
本文使用的2个数据集,训练集测试集验证集都不是足够多的情况下,应采用预训练网络来构造模型。因此,对于本次实践这种样本数量不充分的模型来说,采用VGG16预训练网络模型进行训练[8-11]。
2.3 测试及验证
选择在Google云盘上的Colab上进行训练。硬件加速器选择GPU,然后挂载Google Drive云端硬盘。拷贝github代码到所需的文件夹下,修改相关参数并上传VGG16预训练权重文件,开始训练。开始loss为28左右,训练直至loss接近1,停止。
上述过程结束后,将数据集读入系统模型得到识别框,使用验证集进行验证,获得各药材的识别准确度,见图4。

图4 中药饮片识别验证结果Figure 4 Verification result of identification of Chinese herb slices
使用测试集测试,得到陈皮、甘草、枸杞的识别率分别为75.87%、90.79%、89.74%,总的平均识别率为86.80%。在前述运行环境下一次处理10张图片总共耗时小于0.05 s。测试时只需要读入图片就能出结果,无需考虑分辨率。
3 讨论与结论
本文采用SSD目标识别算法,通过对模型的训练、测试、验证工作,对于采集的包含多种类的中药饮片图像完成了检测分类,达到了很高的识别准确率,而且识别速度快,操作方便。
但是在研究中也发现了一些问题,为以后能够实际应用于生产作业中,需要有对于一些实际应用的考量。(1)若想要提高识别率,则提供的训练集一定要大量、精确;(2)对于不规则物体的判断,例如陈皮,一面白色一面黄色,训练集中这两面都要有而且数量要大,训练集需要包含要识别物体的所有形态的信息;(3)数据扩增技术很重要,对于均值平均精度(mean average precision,mAP)的提升很大;(4)使用不同长宽比的先验框可以得到更好的识别率;(5)采用多尺度的特征图用于检测也是至关重要的,即,提高卷积层数。
