一种基于空洞卷积组合的轻量级语义分割方法
2021-12-08张晓庆刘伟科
张晓庆,刘伟科
(1.山东科技大学 计算机科学与工程学院,山东 青岛 266590;2.山东科技大学 网络安全与信息化办公室,山东 青岛 266590)
图像语义分割对自动驾驶[1]、机器人传感等技术具有潜在应用价值,通过对每个像素赋予具体意义的语义标签并根据语义标签信息分割图像,是机器视觉中场景理解与分析的一个重要研究课题。近年来,随着计算机软硬件技术的快速发展,以卷积网络为代表的深度学习方法取得了较大的突破。2014年,Long等[2]提出利用深度学习方法进行图像语义分割的网络—全卷积神经网络(fully convolutional networks,FCN),随后SegNet[3]、U-Net[4]、DeepLab[5]系列、ESP-Net[6]系列等先进的语义分割网络[7]相继被提出。2015年,以U-Net为代表的编码-解码结构[8]的网络,因为分割准确率高而受到广大学者的重视,但是这类网络体量大、参数多,对算力的要求高。为降低算力,提高网络训练速度,多种轻量级的语义分割网络被提出,如Refine Net-LW[9]、LiteSeg[10]、PSPNet[11]、ESPNet系列[12-13],但这类网络的准确率相比非轻量级的网络较低。针对这一问题,本研究在保证准确率的前提下,以提高卷积效率、降低网络参数量为目标,提出一个级联多分枝的空洞卷积组合NG-APC模块,通过规范空洞卷积组合中的空洞率,解决空洞卷积中出现的栅格问题,并结合深度可分离卷积降低网络的参数量,搭建编-解码结构的NA-U-Net,得到一种高效的轻量级语义分割方法。
1 相关工作
1.1 XU-Net
以U-Net为代表的编-解码的卷积神经网络在分割精确度方面表现出色,其中U-Net中的长连接(图1中的Concat部分)将对应层的特征直接连接,保留了分割结果的边界细节,提高了较难分割的边缘像素的分割准确率。U-Net++[14]、Refine-Net、SegNet、Deeplab-v3+[15]等语义分割新方法中均同样使用了编-解码结构。然而,编-解码结构网络的缺点是卷积层数多、参数多、训练时间长、优化难,不能满足移动端的轻量级需求。利用深度可分离卷积将卷积层通道间相关性和空间相关性的映射去耦合后分开映射,能达到同样的卷积效果,同时参数量可以大幅降低。Xception[16]、MobileNet[17]、Shuffle-Net[18]、Squeeze-Net[19]等轻量级语义分割方法中均使用了深度可分离卷积。据此,本研究将深度可分离卷积融合到U-Net,提出XU-Net[20],其网络结构如图1所示。

图1 XU-Net结构图Fig. 1 XU-Net structure chart
具体地,将U-Net中的标准卷积(如图2(a))(输入层除外)改进为可分离的两步卷积结构(如图2(b)),首先对每一个输入通道的特征图做空间卷积,通过卷积核参数值的训练获取一个输入通道的特征组合,然后以通道维为单位利用1×1的小卷积核做混淆,获取通道维的组合特征。在图像的卷积过程中,输入和输出通道数通常数值较大(通常为64~1 024),因此在标准卷积中做全混淆参数量巨大,通过深度可分离卷积,在空间维(输入通道数)和通道维(输出通道数)分别做混淆操作,总参数量比标准卷积大幅降低,参数量降低幅度的比值为:

图2 可分离卷积示意图Fig. 2 Separable convolution diagram
(1)
其中:M为输入通道数,N为输出通道数,n2为卷积核尺寸。式(1)中左侧分子表示可分离卷积的参数量,分母为标准卷积参数量。
1.2 空洞卷积组合与栅格问题
空洞卷积[21](atrous convolution)也称为膨胀卷积(dilated convolution),是在标准卷积核中注入空洞,将小的卷积核尺寸变大同时保持卷积的参数量不变,扩大的幅度称为空洞率(dilation rate)。其优点是在不使用大卷积核、不增加参数量、不增加卷积深度的基础上扩大感受野,获取更大范围内独立的特征信息,可以提高对大目标的分割准确率;缺点是由于卷积核内有空洞会造成采样特征不连续,形成特征漏采,即栅格问题(gridding problem)[22],且级联的空洞卷积可能会因为感受野过大而造成不相关目标的特征组合。
为解决栅格问题,可通过空洞卷积的组合方式:一是不同空洞率的空洞卷积做级联;二是在多个分枝中使用不同空洞率的空洞卷积做并联。DeepLabv3[23]中使用多分枝并联的空洞卷积组合,称为空间金字塔空洞卷积池化层(atrous spatial pyramid pooling,ASPP),空洞率分别为6、12、18、24,同时提出级联的空洞卷积组合,空洞率分别为2、4、8、16;在ESPNet中使用多分枝并联的空洞卷积组合,空洞率分别为1、2、4、8、16。后来,发现使用空洞率大的空洞卷积虽然能大幅扩大感受野,但并不是感受野越大越好,因此在ESPNetv2中将空洞率更新为1、2、3、4的多分支并联;HDC网络[22]为解决栅格问题使用了空洞率为1、2、3的空洞卷积级联。
虽然通过级联的空洞卷积组合可解决栅格问题,但对如何通过最优的空洞卷积组合在解决栅格问题的同时又体现空洞卷积扩大感受野的优势没有深入研究。针对此问题,本研究提出一种并联和级联结合的空洞卷积组合方式,并规范了空洞率的组合,在解决栅格问题的前提下,达到感受野的最大化。
2 NA-U-Net
本研究提出的编-解码结构的神经网络结构为:在编码部分针对空洞卷积组合结构中的栅格问题,通过规范空洞率的组合,得到感受野最大化的级联多分支的空洞卷积组合模块—NG-APC模块,通过模块级联构成编码部分;在解码部分使用深度可分离卷积,大幅度降低了网络的参数量,搭建一个轻量级的编码-解码结构的卷积神经网络—NA-U-Net,并以该网络为基础,提出一种图像语义分割方法。
2.1 NG-APC模块
空洞卷积组合的级联与多分支并联两种方式在感受野、参数量与栅格问题的解决3个方面各有所长:
1) 感受野方面。级联的空洞卷积组合的感受野是根据级联的层数倍数递增,递增速度快;多分支并联的空洞卷积组合的感受野是多分支中感受野最大的一个分支。
2) 参数量方面。级联的空洞卷积组合的参数量与级联的标准卷积参数量相同,是根据级联的层数倍数递增;由于卷积核总数量不变,只是分成多个分支,因此多分支并联的空洞卷积组合的参数量没有增加。
3) 解决栅格问题方面。级联的空洞卷积组合解决栅格问题是通过上一层的特征组合与本层卷积核的参数相连,层层扩张,减少特征漏采;多分支并联的空洞卷积组合解决栅格问题是通过小空洞率的特征补充大空洞率的特征漏采部分,但若达到完全解决栅格问题,需要使用连续的空洞率,即退化成一个大核标准卷积,失去了空洞卷积的优势。
基于以上分析,在解决栅格问题的前提下,为了达到感受野最大,同时兼顾参数量,本研究设计了三层的级联与多分枝并联结合的空洞卷积组合,模块结构如图3所示。
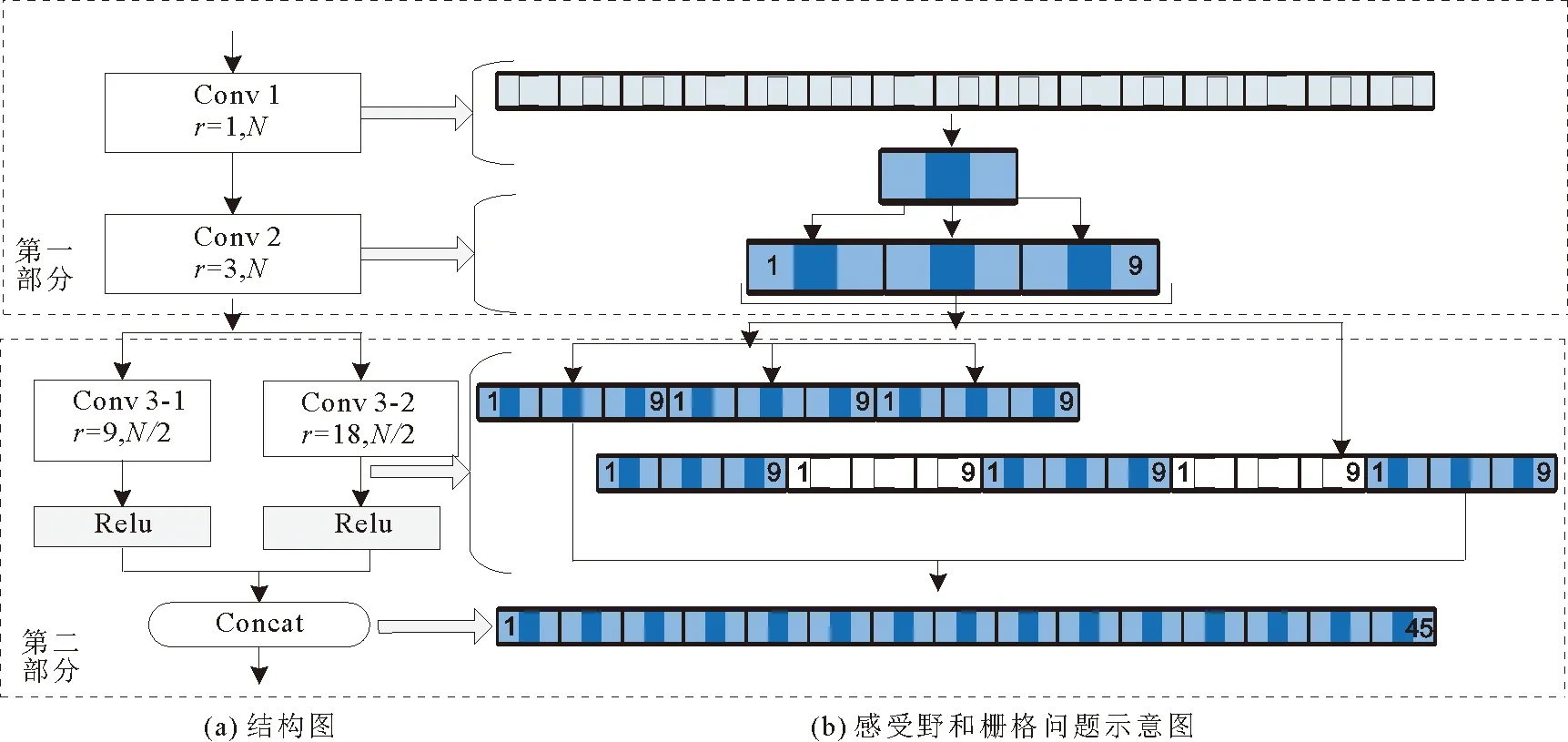
图3 NG-APC模块图Fig. 3 NG-APC module diagram
第一部分为级联部分,为标准卷积后级联空洞率为3的空洞卷积,第一层设计为标准卷积,因此如将第一层选用空洞卷积,会造成采样中心点周围特征被漏采,通过级联后,这种漏采现象会加剧,无法做到完全去栅格;第二层设计为空洞率为3的空洞卷积,其漏采部分正好由上一层的特征组合补齐,获得感受野为9的特征组合。
第二部分的多分枝并联是在第一部分的基础上进行分组卷积,每一个采样点可以采样第一部分的感受野为9的特征组合,因此设计第一分支的空洞率为9可以做到无特征漏采,感受野为27。为了进一步扩大感受野,第二分支设计为空洞率为18的空洞卷积,其漏采部分的特征由第一分支补全,由此可以做到解决栅格问题的最大化感受野的空洞卷积组合,其感受野为45,感受野和栅格问题如图3(b)所示。第二部分紧接激活函数和特征拼接,形成一个空洞卷积模块。模块为无栅格的金字塔空洞卷积组合(non-gridding atrous pyramid convolution),称为NG-APC模块。
NG-APC模块在达到感受野最大化的同时,采样点是无重叠的,但对不同的应用场景,并不意味着感受野越大越好,空洞率减小的同时可以提升采样的冗余,采样保持一定的冗余度有助于特征提取。因此模块的层数、分支数、空洞率可以调整,但为了保证去栅格问题的空洞卷积组合,空洞率的取值应不大于式(4)、(5)中的rmax,其中NG-APC模块中使用的是3×3的卷积核,卷积步长为1,感受野的计算公式为:
F=(k-1)×r+1,
(2)
其中:F为感受野,k为卷积核尺寸,r为空洞率。
除了三层二分支的NG-APC模块之外,本研究设计了普适性的NG-APC模块:
第一部分为空洞卷积级联。第一层为标准卷积,其中r1=1,F1=3;第二层为空洞卷积,r2max=3。若级联为d层,空洞率和感受野的取值分别由公式(3)、(4)得到,即由上一层的感受野确定下一层的空洞率。
rdmax=Fd-1,
(3)
Fd=Fd-1+2rd。
(4)
第二部分为多分支并联的空洞卷积。若为二分支,分支1的r3.1=9,F3.1=27;分支2的r3.2=18,F3.2=45。若为多个分支并联,分支数为b,输出通道数为N,则每个分支的卷积核数量为N/b,每个分支使用不同的空洞率进行卷积,空洞率如式(5)所示,每个分支卷积后使用Relu激活函数,再将多个分支进行特征拼接后输出。
(5)
为了在提高网络获取图像特征能力的同时保证较小的参数量与计算量,根据2.1节,将NG-APC模块中的标准卷积用深度可分离卷积代替,在保证网络分割能力的同时可以将NA-U-Net的参数量由16.9 M降至2.35 M。
3.2 NA-U-Net
利用NG-APC模块与深度可分离卷积搭建的编-解码结构的NA-U-Net的结构如图4所示。以该网络为基础,提出一种轻量级的图像语义分割方法。本方法属于利用深度学习方法完成图像语义分割,关键在于利用NA-U-Net训练自动获取图像语义特征。在网络训练过程中,将图像送入网络,与标签对比后通过损失函数计算与真值的差距,通过反馈逐层调整网络参数,直至准确率稳定。得到精确到像素的图像语义分割结果。

图4 NA-U-Net结构图Fig. 4 Structure diagram of NA-U-Net
实现语义分割的NA-U-Net编码部分由多个NG-APC模块级联,经过多次实验,使用三层二分支的NG-APC模块,根据编码部分下采样过程中卷积核数量倍增的特点,修改了NG-APC模块第三层的卷积核数量,由N/2改为N,达到卷积核倍增的结果。经过最大池化下采样后,恰好与编码部分特征通道数量的要求相符。解码部分将逐层编码的结果与上采样的结果连接后,经过逐层解码,使用XU-Net模型的解码部分,以降低参数量与计算量,最后经过一层Softmax分类器,完成网络的设计与搭建。
3 实验验证与分析
为了验证本方法的有效性,使用Pytorch开源深度学习库编写代码,利用公开的大型街景数据集—Cityscapes[24]进行训练及测试。
3.1 实验数据集介绍
Cityscapes数据集采集了18个城市的5 000张2 048×1 024像素的精细标注的街景图像,其中2 975张作为训练图,500张为验证图,1 525张为测试图。数据集中的图像是以汽车驾驶员视角拍摄的道路街景图像,包含行人、道路、汽车等19个语义类别,加上背景,共20个类别。图5为Cityscapes数据集中的一幅典型图像,图5(a)为示例原图,图5(b)为示例图的语义标签,标签分类如图5(c)所示。
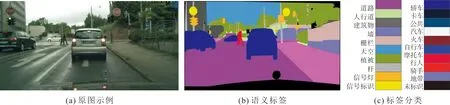
图5 Cityscapes数据集示例及分类标签Fig. 5 Example and classification label of Cityscaps dataset
3.2 实验过程及参数设置
首先使用小分辨率的图像(512×256像素)进行训练得到粗略的训练结果,然后提高训练图像的分辨率(1 024×512像素),训练得到最终分类结果。初始学习率初值为0.1,逐次递减5%;激活函数为Relu;Batch=8;Epoch=300;损失函数使用交叉熵;优化策略使用随机梯度下降法。使用的GPU为NVIDIA GTX 1080。评价标准使用语义分割领域的通用评价指标mIoU,即图像内各类标签IoU的平均值。
3.3 实验结果及分析
NA-U-Net在Cityscapes数据集上经过300次迭代循环,与经典的FCN-8s[2]、改进前的U-Net[4]、先进且轻量级的ESP-Netv2[13]以及轻量级LiteSeg[10]、RefineNet-LW[9]进行准确率与mIoU值对比,如表1所示。

表1 本文方法与其他方法在Cityscapes测试集上的准确率与mIoU值对比Tab. 1 Comparison of accuracy and mIoU value cityscapes dataset between the proposed method and other methods
由表1中不同种类物体的分割结果可以看出,各类分割方法对Cityscapes测试集中背景类的物体,如天空、植被、墙、道路、轿车等特征变化小或者目标大的物体识别准确率都比较高,但对特征变化大的物体(如自行车、行人等)以及目标小的物体(如信号灯、杆子等)识别准确率差别较大。本方法对特征变化大的物体区分较好,对目标小的物体仅次于U-Net模型,但均优于其他轻量级的模型。另外,与轻量级的ESP-Netv2、LiteSeg以及Refine Net-LW模型相比,本方法的mIoU值分别提高了8.03%、6.75%以及5.98%,验证了本方法在算法准确率方面的优势。
从表2的参数量、GFLOPs、准确率(OA)对比情况可见,本方法的参数量和GFLOPs比改进前的U-Net有大幅降低,同时还小于轻量级编-解码结构的Refine Net-LW、ESP-Netv2和LiteSeg方法;从准确率可以看出,本方法准确率达92.5%,比改进前的U-Net高5.6%,高于三种编-解码结构的轻量级语义分割方法,是多种对比方法中最好的。
综上,在Cityscapes的测试集中,本方法不仅在参数量与计算量方面具有一定的优势,而且分割的准确率与mIoU也高于经典的FCN-8s、U-Ne与轻量级编-解码结构的Refine Net-LW、ESP-Netv2和LiteSeg。
为了更细致地展示分割效果,在Cityscapes数据集里选取两张具有代表性的图像jena_000110_000019_leftImg8bit(用原图1表示)和jena_000070_000019_leftImg8bit(用原图2表示),并分别给出U-Net、ESP-Netv2、LiteSeg、Refine Net-LW以及NA-U-Net的语义分割效果如图6。原图1(图6(a))为街景中的典型图像,包含建筑物、道路、轿车、自行车、骑手、植被等。原图2(图6(c))为街景中较少出现的特殊场景,不仅包含典型场景中建筑物、人群、汽车,还包括特殊着装的消防员与特殊车辆消防车,有栅栏、特征复杂的广告墙以及标识牌。通过两幅图像的实验说明本方法在典型图像和非典型图像中的分割效果。
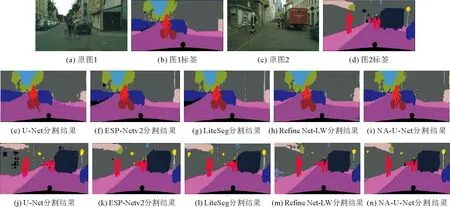
图6 U-Net、ESP-Netv2、LiteSeg、RefineNet-LW以及NA-U-Net方法的分割效果图Fig. 6 Segmentation results of U-Net、ESP-Netv2、LiteSeg、RefineNet-LW and NA-U-Net
由分割效果图6(e)~6(n)可以看出:
1) 本方法对自行车、骑手、轿车的分割结果明显优于其他方法,尤其是对树木和骑手双脚的轮廓分辨较为清晰;
2) 各方法对特殊着装的消防员识别结果差距较大,本方法对近处消防员以及较远处的行人分割准确,对远处4个行人的分割精度甚至超过了标签;
3) 各方法对杆子、栅栏等分割准确度较低;
4) 所有方法均将消防车识别为货车。
产生结果1)、2)的原因是NG-APC模块在扩大感受野的同时,解决了栅格问题,提高了卷积的效率,更好地获取了图像的特征;产生结果3)的原因是扩大感受野对目标小的物体分割效果不明显;产生结果4)的原因是标签中没有设置消防车类别,所以所有方法均将消防车识别为货车,说明标签的准确性直接影响分割结果的准确性。选取图像中不同种类的物体边界分割清晰。
表3为本文方法在Cityscapes数据集上部分数据测试结果的准确率与mIoU值的情况, 从表3可见:分割方法整体的mIoU值分别为73.8%和67.7%,其中,对道路、建筑物、植被的分割效果较好,但是杆子的识别准确率较低,说明本文方法对易混淆物体的准确率仍有待提高。

表3 本文方法在Cityscapes数据集上部分数据测试结果的准确率与mIoU值Tab. 3 The accuracy and mIoU value of test results with part of data of Cityscaps by this thesis method
4 结论
本研究首先通过规范空洞卷积组合中的空洞率,在解决空洞卷积组合中的栅格问题同时保证感受野最大化,并设计了一种级联多分支的空洞卷积组合模块,然后结合深度可分离卷积搭建了编-解码结构的NA-U-Net网络,基于该网络,提出了一种轻量级的图像语义分割方法。通过在Cityscapes数据集上进行实验验证,该网络mIoU达73.73%,OA达92.5%;参数量仅为2.35 M,小于多种轻量级卷积神经网络。结果表明本方法是一种轻量且高效的图像语义分割方法。虽然本文方法在参数量与计算量方面有一定幅度的降低,但是仍有下降的空间,将进一步进行网络轻量级方面的研究。
