文本风格转换模型的平衡性改进方法研究
2021-12-03刘延飞何玉杰
刘延飞,李 慧,何玉杰
(火箭军工程大学 电子信息技术教研室, 西安 710025)
1 引言
文本风格转换属于一种特殊的自然语言生成技术,是指在保留原句内容的同时,重新措辞生成包含特定风格属性(词汇、句法等)的文本。不同场景下不同人群的表达方式不同,例如小说和科学论文、语言在个性年龄方面具有显著差异[1]等,使得信息交换中存在一定领域性的表述门槛和理解偏差。文本风格转换通过将语句转换成目标风格,能更好促进信息的接收,对于科学论文成功、信息的广泛传播、维护社交媒体的良好交流氛围、减轻现有自然语言技术中存在的偏差、语言风格控制生成技术等有重要意义[2-5],近年在文本领域的研究已经成为热点,引起学者们关注和研究。
根据研究数据是否为内容一致而风格不同的平行数据,文本风格转换主要有监督的传统方法和无监督的深度学习方法。有监督的传统方法主要针对在平行数据下实现,基本以单语机器翻译为思路,将不同风格视为不同语言,形同释义。例如,文献[6]基于短语的机器翻译完成现代语言-莎士比亚文本风格转换。Mizukami[7]等利用统计机器翻译模型,结合语言模型实现说话人的个性翻译,但规则复杂且内容保留程度较低。然而,由于内容一致而风格不同的平行数据难以获取,该领域当前工作主要集中实现无监督的文本风格转换。主要有以下3种实现思路:隐式分离风格和内容[8-11],用对抗网络或回译等方法对语句潜在表示强制分离内容和风格,存在训练困难、风格和内容难以平衡等问题;显式分离风格和内容[12-14],对包含风格属性强的短语进行删除替换,模型简单,但难以识别并转换隐式风格;不分离风格和内容[15-22],对特征高度纠缠的潜在空间信息进行处理,较好地平衡风格和内容表示,值得进一步探索。
综上考虑,本文对文献[18]的文本属性可控转换模型CTAT进行深入研究。该模型不分离内容和风格,对语句的潜在表示添加风格扰动,较为简单直观地实现文本风格转换,具有良好性能。然而,该模型存在性能不稳定的问题,特别是较大程度风格转换时易添加复杂信息,使得生成语句较为混乱。针对此不足,本文在算法上进行了改进,对风格干扰添加显著性操作,增大优化梯度方差,局部加强风格干扰效果,以加强内容保留约束。同时,在结构上,受文献[23]的启发,修改解码器模型对干扰前后的潜在表示进行渐进式融合,实现进一步的内容保留约束,从而在风格和内容上产生更好的平衡。为此,创新性地渐进式融合思想应用于文本风格转换,用多头注意力代替卷积,融合不同层次的语句信息。通过显著性风格干扰和渐进式风格融合实现转换句的内容与风格平衡表示,在Yelp数据集上验证了提出的方法的有效性,提出的方法有效提高内容保留度和流畅度,实现较好的综合性能。
2 Balance-CTAT模型
CTAT模型通过自编码器重建语句,并且利用对抗样例生成技术,以此实现无监督文本风格转换。模型由3部分组成,分别是编码器、解码器和风格分类器,如图1所示。编码器和解码器都是由2层具有4头注意力的Transformer堆叠而成,编码器将原句编码为潜在表示,解码器对其解码输出语句;风格分类器由两个全连接层和一个sigmoid层组成,判断潜在表示的标签。训练阶段的目标是尽量减小将自编码器重建损失和分类器损失,使得模型具有基本的生成能力和风格判断能力。
风格转换任务主要是利用快速梯度迭代算法(fast gradient iterative modification,FGIM)实现,通过对抗样例生成技术对潜在表示进行风格干扰,使之能欺骗分类器达到其拥有目标风格的目的。具体实现中,风格分类器C根据原句潜在表示z预测标签s,并计算其与目标标签s′的损失L得到风格优化梯度,以风格干扰系数λ调整转换程度,生成具有目标风格属性的z′:
z′=z-λ▽zL(C(z),s′)
(1)
然而,CTAT模型存在性能不稳定的问题,特别是较大程度风格转换时易添加复杂信息,使得生成语句较为混乱。针对CTAT模型存在的不足,本文在传统的CTAT模型上进行改进,构造了Balance-CTAT模型,如图2所示。对比图1和图2,提出的模型做了两方面的改进,在算法上对风格迁移算法进行显著性优化,在结构上,修改Transformer[24]解码器各层注意力头数进行不同层次的信息融合。

图2 Balance-CTAT模型的组成示意图Fig.2 Balance-CTAT model
在算法上,利用快速梯度优化算法FGIM进行显著性优化,结合注意力机制,增大梯度值方差,局部化风格干扰影响。快速梯度迭代优化算法FGIM是CTAT模型中实现风格转换的核心算法。该算法受对抗样本生成工作[25-26]启发,用对抗性扰动全局化编辑原句的潜在表示来改变分类器预测结果,使之拥有目标风格特性,从而达到风格转换的目的。而语句的潜在表示中特征高度纠缠,全局化编辑会一定程度上影响句子的其他属性(语序、词汇等)。因此,本文对该算法进行显著性优化,增大梯度值方差,局部化风格干扰影响。
设n维的句子潜在表示zn通过分类器计算得到风格优化梯度gn,梯度保留系数为μ,显著性权重为wn。将梯度取绝对值,其中前「μn⎤个最大值乘以显著性梯度wn,并将剩余的n-「μn⎤个梯度值置为零,以此实现显著性梯度的局部性优化。其中,显著性权重wn=[w1,w2,…,wn]中第k项的计算公式如下:
(2)

原梯度优化值与显著化后的梯度优化值如图3所示。图中为了便于描述,将句中每个token视为不同梯度项。以句子“the food was great.”为例,梯度维数为5,梯度保留系数为0.6。原梯度值越高则显著性权重越大,显著化梯度值后越突出,并且将最小的两个梯度值置为零。

图3 原梯度优化值与显著性梯度优化值直方图
同时,本文固定FGIM算法的风格干扰系数并舍弃迭代过程。该算法十分依赖于分类器性能,通过有效计算预测标签和目标标签之间的损失得到优化梯度,实现风格转换。而当分类器性能足够好时,潜在表示第一次梯度优化后往往已被分类器判定为目标风格,这使得后续迭代梯度基本为零。本文认为迭代并不能提供更好效果,因此舍弃。显著性快速梯度优化算法的伪代码如下:
算法1 显著性快速梯度优化算法
输入:原句n维潜在表示z;预训练好分类器C;风格干扰系数λ;梯度保留系数μ;目标风格标签s′;
输出:梯度优化后的潜在表示z′;
1: 计算显著性权重w=1+softmax(|▽zL(C(z),s′)|);
2: 计算显著性优化梯度
g=[g1,g2,…,gn]=λw▽zL(C(z),s′);
3: foriin int((1-μ)n);
4: min{|g1|,|g2|,…,|gn|}=0;
5:i=i+1;
6: end for;
7:z′=z-g;
8: returnz′;
潜在空间的特征高度纠缠,风格干扰的优化梯度过大时易带来内容的改变,需要进行一定的内容约束。受文献[23]工作启发,本文对解码器的结构进行修改。解码器通过渐进式的语句融合,整合原句的简单层次信息和风格干扰后的复杂层次信息,在确保风格转换精度的同时有效提高内容保留度。
文献[23]提出的StyleGAN模型以渐进式的方式从低像素到高像素逐步生成图像信息。低像素上主要影响粗粒度特征,例如脸型、发型、眼镜等;高像素上主要影响细粒度特征,例如发色、肤色等。通过affjne变换和卷积在不同像素进行影响,从而有效控制图像属性。模型渐进式生成器结构如图4所示。

图4 StyleGan渐进式生成器结构框图Fig.4 Architecture of StyleGan generator
本文结合Transformer的多头注意力机制特性,即不同头注意力关注不同的空间层次信息,模仿StyleGAN模型的生成器结构将解码器改为单头注意力Transformer层和4头注意力Transformer层的堆叠。解码器结构如图5所示。在单头注意力Transformer层上,对原句潜在表示进行内容级别的低层信息提取;在4头注意力Transformer层上,对风格干扰后潜在表示进行多层次信息提取。以渐进式风格融合的方式,在低层次加强内容约束,并且在高层次保留了风格干扰效果,实现较好的内容与风格平衡的文本风格转换。
图5中,以“the salad was fresh.”为例进行积极-消极的情绪风格转换。在显著化风格干扰算法后,对具有目标风格的潜在表示z′解码对应得到生成句“the food was terrible.”,损失了部分主语信息。因此,我们在第一层Transformer中输入原潜在表示z,获取简单语义信息,同时在第二层Transformer中获取具有目标风格的复杂语义信息。通过这种渐进式的解码提高对原句内容的保留程度,输出性能更好的风格转换句“the salad was terrible.”。

图5 Balance-CTAT渐进式解码器结构框图
3 实验
为了检验提出算法的有效性,本文在一台计算资源相对丰富的服务器上进行了验证实验。该服务器的硬件配置为Intel®CoreTM i7-8750HQ的CPU,GTX1060的GPU,以及 8 GB的运行内存。软件配置为Windows 10家庭中文版操作系统,配有CUDA10.2,CUDNN 8.0.1 RC2的深度学习驱动,并使用对应的编程框架Pytorch 0.4。
为了有效对比优化效果,采用的模型参数与文献[18]相同。在基于Transformer的自编码器中,嵌入维度、潜在表示维度均设置为256,簇大小为128。Transformer中前馈网络的内部维数设置为1 024。标签平滑参数ε设置为0.1。分类器由两个线性层搭建而成,尺寸分别为100和50。显著性快速梯度优化算法的风格干扰系数、梯度保留系数分别为6和0.6。采用优化器Adam,初始学习率是0.001。训练周期数为200。
这里,采用Yelp数据集来进行验证。Yelp餐厅评论数据集,包含积极、消极和中立情感。将情感视为一种风格,作为正负情感转换任务的语料库。文本风格转换领域的经典数据集,便于对比各模型性能。
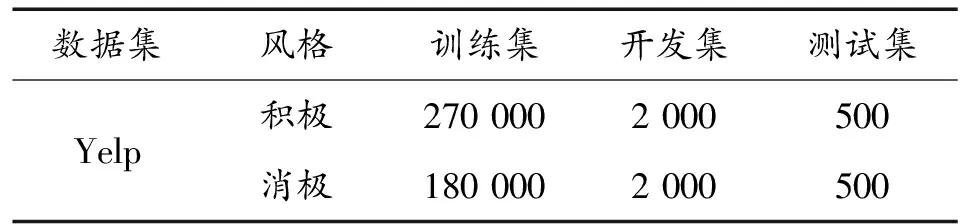
表1 Yelp数据集统计信息 /句
为了评价提出的方法的有效性,在此采用以下3个指标来评价:
1) 风格转换精度Acc。衡量语句转换到目标风格的准确性,数值越大性能越好。本文用训练集数据对FastText[27]分类器进行训练,用于测试模型生成句的风格准确性。
2) 内容保留度BLEU。衡量模型生成语句与目标句的相似性,数值越大性能越好。本文用multi-bleu计算模型生成句和人工编写的参考句之间的相似度。
3) 几何平均值GM。衡量模型的整体性能,用acc、bleu的几何平均数综合评估模型,数值越大性能越好。
同时,提出的方法还与Cross[8]、CTAT[18]、FGST[28]模型进行对比研究。实验结果如表2所示。其中粗体表示指标相对最优值。

表2 Yelp数据集实验结果(%)
由表2可知,相较于Cross模型,CTAT、FGST、Balance-CTAT模型的综合性能更好,特别是在风格转换精度上有很大提升。主要是对抗网络强制分离风格和内容不能很好地处理复杂语义信息,而对潜在表示整体进行处理更易保留原句语义。在风格分类器性能良好的情况下,风格的表现力强,转换的针对性也相对较强。
对比CTAT模型,FGST、Balance-CTAT模型显著提高了内容保留度,有较好的综合性能。两个模型都是以可接受的程度牺牲部分风格转换精度,提高了内容保留程度。说明语句信息高度纠缠,风格和内容作为其中的两个特征关系紧密、难以简单分割,仍存在对风格转换精度和内容保留度间的取舍问题。
对比FGST模型,Balance-CTAT模型在内容保留度提升效果有限,3-gram、4-gram BLEU分数表现更好,如表3所示。FGST模型通过内容判别器预测输出词的字包(Bag-of-Word)特征进行内容约束,对长距离的单词预测表现较弱。而本文模型对潜在表示整体信息进行处理,受语句长度的影响较小,在较长的句子上表现较好。

表3 FGST和Balance-CTAT模型的N-gram BLEU分数(%)
4 结论
针对传统CTAT模型模型存在性能不稳定的问题,特别是较大程度风格转换时易添加复杂信息,使得生成语句较为混乱,构建了Balance-CTAT模型。在提出的模型中,创新型渐进式融合思想应用于文本风格转换,用多头注意力代替卷积,融合不同层次的语句信息。同时,通过显著性风格干扰和渐进式风格融合实现转换句的内容与风格平衡表示。提出的模型与Cross、CTAT、FGST模型进行对比,并以风格转换精度Acc、内容保留度BLEU、几何平均值GM进行了评价。实验结果表明:在Yelp数据集上,提出的方法具有明显的优势。可以有效提高内容保留度和流畅度,实现较好的综合性能。
