基于密度聚类的海量数字化档案信息模糊检索研究
2021-11-24许德斌
许德斌
(1.武汉大学 信息管理学院,湖北 武汉 430072;2.合肥职业技术学院,安徽 合肥 238000)
随着智慧数字化档案馆建设技术的发展,在信息化体系架构下,非常有必要进行海量数字化档案信息模糊检索设计[1]。在进行海量数字化档案设计和检索过程中,受到海量数字化档案信息分布差异性的影响,导致对海量数字化档案信息检索的精准度不高,所以对于相关的海量数字化档案信息模糊检索方法研究受到人们极大的关注[2]。
现阶段对于此方面的研究很多,并取得了一定的研究成果。例如文献[3]中提出基于大数据分析的多媒体信息检索系统设计方法,该方法结合耦合参数匹配和信息重组方法,从数据源追踪组件、数据挖掘组件、系统预警组件对检索系统进行优化设计,实现对海量数字化档案多媒体信息语义参数分析,但该方法在进行多媒体档案信息检索时时间较长,实际应用效果并不好。文献[4]中提出基于图结构优化的自适应多度量非监督特征选择的档案信息检索方法,采用联合关联规则性挖掘的方法,实现海量数字化档案信息检索的特征分析,建立海量数字化档案信息检索的联合特征匹配模型,通过模糊度检测实现海量数字化档案信息检索,并对相似矩阵的秩进行约束,在优化图局部结构的同时简化了计算,但该方法进行海量数字化档案信息检索的精准度不高。
针对上述问题,本文提出基于密度聚类的海量数字化档案信息模糊检索方法。分析海量数字化档案信息存储结构,根据分析结果对档案信息进行检索特征匹配。在此基础上建立海量数字化档案信息融合模型,并对融合结果进行密度聚类。根据平稳时间序列之间线性相关性,对海量数字化档案信息聚类结果进行模糊检索。最后进行仿真测试分析,证明了本文方法在海量数字化档案信息模糊检索能力方面的优越性能。
1 海量数字化档案信息数据结构分析
1.1 海量数字化档案信息存储结构
为了实现海量数字化档案信息检索,结合高层语义之间的语义特征分析和密度聚类分析,构建海量数字化档案信息检索的特征匹配模型,采用关联规则融合和相似度特征检测,进行海量数字化档案信息检索的数据管理[5],根据结果对新增海量数字化档案进行学习,实现海量数字化档案检索库的增量扩容,结合密度聚类分析,实现对海量数字化档案信息的检索,检索模型的总体结构如图1所示。
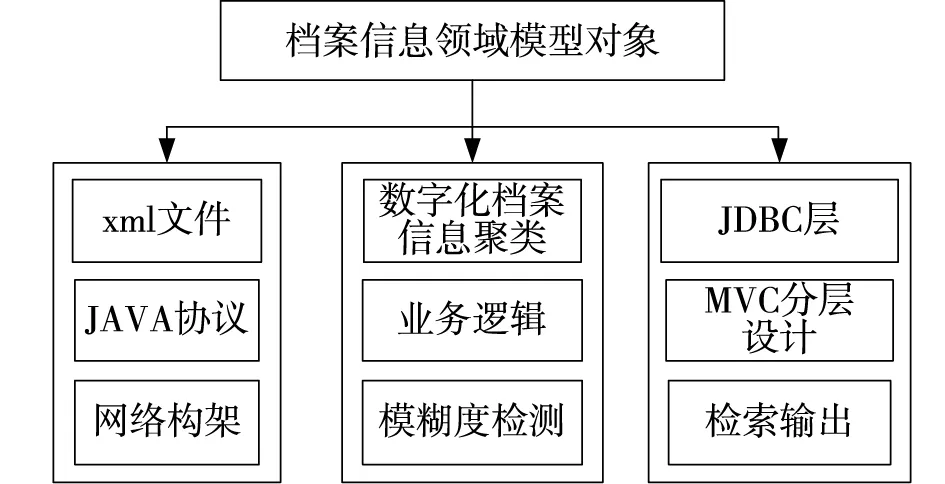
图1 数字化档案信息模糊检索的总体结构模型
根据图1所示的海量数字化档案信息模糊检索总体结构模型,提取海量数字化档案的HOG特征,结合粗糙模糊集特征匹配技术,构建海量数字化档案信息检索的梯度学习模型[6],构建海量数字化档案信息检索的语义关联分布特征集,得到海量数字化档案信息分布的粗糙样本集为:
(1)
公式(1)中,PT-elec为海量数字化档案的语义属性,R为语义本体特征,LDATA为自由度,LACK为联合概率密度特征分量,设定海量数字化档案信息检索的时间长度为t,采用海量数字化档案信息的联合分布式融合方法,计算给定数据集S={x1,x1x2,x1x2x3,…,xm+1}的特征,用向量x=[x1,x1x2,…,xk+1]表示海量数字化档案信息检索的统计特征量,根据M1,M2,…,MN的聚类性,得到海量数字化档案信息检索的数字化特征密度聚类问题描述为:
(2)
其中
(3)
(4)
上式中,DIFS为数字化档案的描述统计特征量,tDATA为数据的检索时间间隔,tslot为锁定周期时间,tT-start为检索开始时间,SIFS为差异化概率密度[7]。对海量数字化档案信息的存储结构分析后,下一步需要对海量数字化档案进行检索特征匹配,以期为后续检索方法的设计奠定坚实的基础。
1.2 海量数字化档案检索特征匹配
根据海量数字化档案信息检索饱和度差异值,搭建海量数字化档案信息梯度幅值加权的梯度聚类函数为:
(5)
其中,l为数字化档案低层特征,Ecomm为档案的文本特征差异度[8],pdrop为档案检索的联合分布集,根据海量数字化档案信息检索的分层检测结果,通过模糊字节特征匹配方法得到海量数字化档案信息的模糊集分布为:
(6)
其中,v表示检索过程中特征匹配的速度,c(v)为梯度方向直方图分布维数[9],结合海量数字化档案信息模糊聚类分布,得到数字化档案信息检索的区域划分单元格为:
(7)

(8)
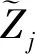
2 海量数字化档案信息检索优化
2.1 海量数字化档案信息融合处理
基于层次化海量数字化档案语义检索的决策模型,建立海量数字化档案信息检索的资源负载均衡模型,得到海量数字化档案信息检索的排序列表,由此得到海量数字化档案信息检索的语义特征提取更新公式如式(9)所示。
(9)
其中,N为语义序列长度,x为检索时间序列,τ为时间延迟。
采用神经网络的方法,将海量数字化档案按语义组成目录,采用非层次化的分类进行海量数字化档案检索[12],得到层次聚类中心为Mi+1与Mj+1,采用粗糙集特征匹配的方法,得到海量数字化档案信息检索的层次密度聚类输出为Clustdist(Mi+1,Mj+1,当(i=j,1≤i≤q,1≤j≤q),得到数字化档案语义属性的聚类输出的时间概率密度函数表示为:
(10)
其中,Xp为海量数字化档案信息语义分布的源信息,u为数字化档案的粗糙度,v为档案信息的匹配度特征量。

(11)
其中,σs为海量数字化档案信息检索的待估参数,E为能量泛函,X1为初始化聚类中心,H为信息熵。通过上述海量数字化档案信息融合处理,结合层次化的密度聚类,实现档案信息模糊检索研究。
2.2 数字化档案信息的密度聚类及检索输出
通过分块特征检测和语义相关分析,实现对海量数字化档案信息的关联规则调度和专家系统识别,结合机器语义的可靠性识别算法,实现对海量数字化档案信息模糊检索过程中的密度聚类,根据信息聚类结果,得到分块特征检测最优决策函数如式(12)所示。
(12)

(13)
其中,R为检索半径,c为细粒度,φ(xi)为空间检测函数。层次密度聚类的最佳寻优函数为:
(14)
其中,pi为形状命名语义属性,σx12为均方根误差,β2为有歧义的语句描述语义属性分量,结合机器语义的可靠性识别算法,实现对海量数字化档案信息模糊检索过程中的密度聚类,根据信息聚类结果,得到海量数字化档案信息检索的输出结果描述如式(15)-式(19)所示。
(15)
(16)
(17)
xij=0
(18)
st=1
(19)
其中,xij=1表示海量数字化档案信息检索的输出满足收敛性,xij=0表示海量数字化档案信息检索输出发散,综上分析,计算密度分布的差异性,根据平稳时间序列之间线性相关性,实现对海量数字化档案信息的优化检索。实验流程如图2所示。

图2 检索实验流程
3 仿真测试(增加检索时间和检索精度相关的对比实验)
通过仿真实验验证本文方法在实现海量数字化档案信息检索的应用性能,对数字化档案信息检索的统计特征量分布集为1206,时间序列的长度为200,测试集为120,数字化档案信息分布的统计特征信息见表1。

表1 数字化档案信息分布的统计特征信息
根据表1的参数分布,进行海量数字化档案信息检索,得到海量数字化档案信息的样本特征分布如图3所示。

图3 海量数字化档案信息的样本特征分布
分析图3中的数据可知,海量数字化档案信息测试集的分散程度较低,海量数字化档案信息样本集的分散程度适中,海量数字化档案信息训练集的分散程度较高,原因是利用更为分散的数据进行训练,可以提升训练精度,而后续测试过程中可以使用分散程度较低的数据进行测试,使所得结果具有普适性。
根据图3的样本分布构造,进行数字化档案信息检索,得到检索的频域分布如图4所示。
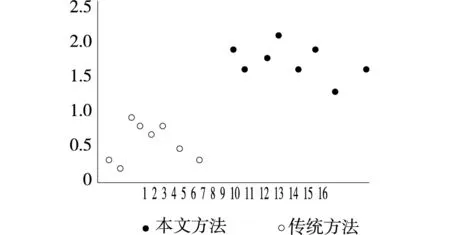
图4 数字化档案信息检索频域分布
分析图4中的数据可知,传统方法的数字化档案信息检索频域分布较为集中,而与传统方法相比,本文方法的数字化档案信息检索频域分布较为分散,所以检索出结果的查全率与查准率均较高,验证了该方法的优越性。
根据频域分布特征,进行数字化档案信息的密度聚类,得到聚类结果如图5所示。
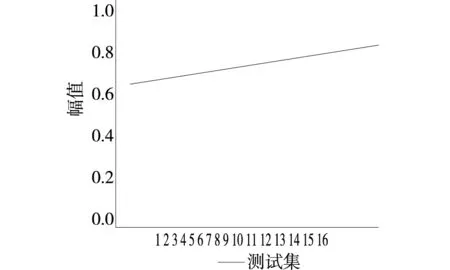
图5 密度聚类结果
分析图5得知,本文方法的数字化档案信息密度聚类幅值变化大约在0.2左右,说明该方法的聚类过程比较稳定,数字化档案信息检索的聚类性较好。
为了验证本文方法的检索性能,对比大数据分析检索方法和图结构优化检索方法,进行数字化档案信息检索的查全率,得到对比结果如图6所示。
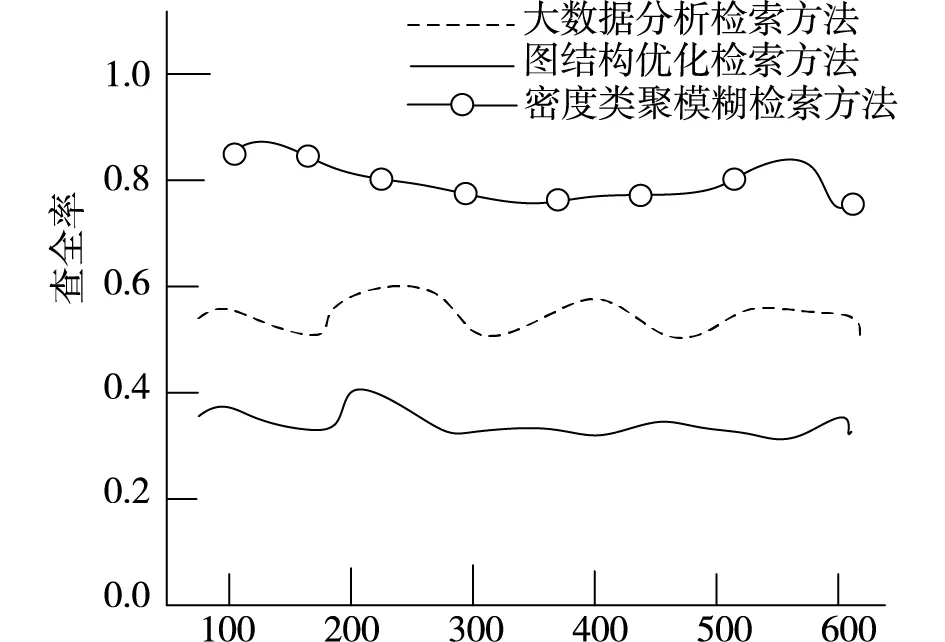
图6 检索性能对比
分析图6得知,本文方法进行数字化档案信息检索的查全率高于另两种检索方法,证明本文方法的检索性能较好。
为了验证本文方法的实用性,对比大数据分析检索方法和图结构优化检索方法测试检索时间和检索精度,如图7、图8所示。

图7 检索时间对比

图8 检索精度对比
通过图7可以看出,图结构优化检索方法的检索时间在1.2s以上,大数据分析检索方法的检索时间在1.8s以上,而本文方法的检索时间始终低于0.6s,检索时间较短。通过图8可以看出,图结构优化检索方法的检索精度低于-0.1,大数据分析检索方法的检索精度低于-0.2,而本文方法的检索精度始终保持在-0.05与0.05之间,检索精度较高。
由此可以得出,本文方法相比于另外两种方法使用的检索时间相对较短,检索精度较高,检索性能好,在实际应用中有较好的效果,实用性强。
结语
构建数字化档案信息和文献资源的数据分析模型,采用模糊信息聚类和大数据特征重组,实现对海量数字化档案信息模糊检索识别,提高档案信息检索的识别能力。本文提出基于密度聚类的海量数字化档案信息模糊检索方法。根据海量数字化档案信息的样本特征分布,提取海量数字化档案的HOG特征,结合粗糙模糊集特征匹配技术,构建海量数字化档案信息检索的梯度学习模型,实现检索算法优化设计。分析得知,本文方法进行数字化档案信息检的查全率较高,检索聚类性较好,检索时间短,检索精度高,在数字化档案信息检索的实际应用上效果好。
