基于准确性和多样性的在线动态选择集成建模方法
2021-11-17陈双叶符寒光高建琛
陈双叶,赵 荣,符寒光,高建琛
(1.北京工业大学信息学部,北京 100124;2.北京工业大学材料科学与工程学院,北京 100124)
在复杂的工业生产过程中,产品质量的好坏往往需要抽取部分产品,经过离线的实验室检验才能得到结果,需要投入大量的人力、物力,而且具有很强的滞后性.这些滞后性较大的变量往往采用软测量模型进行预测.但是,在实际应用中,由于工业设备的磨损、电子器件的老化、原料属性的差异等,会造成工艺参数的动态变化,这在机器学习领域称为概念漂移[1].基于历史数据训练的软测量模型的预测性能会随着概念漂移的出现而下降,其不再适用于概念漂移发生后的数据,即模型与动态的系统不匹配.
研究表明,集成学习具有较好的概念漂移处理能力.集成学习是一种通过组合多个子模型以提高整体泛化性能的有效算法,该方法能很好地适应数据分布的变化.准确性和多样性是集成的2个重要特征[2],目前研究大多只关注集成子模型的准确性,忽视了子模型之间的差异选取[3].高慧云等[4]、Tumer等[5]指出子模型之间的差异性和子模型自身的准确性是决定集成模型泛化性能的2个重要因素.为了提高集成模型的泛化性能,许多选择性集成方法被提出,这些方法可分为基于排序的方法、基于聚类的方法和基于优化的方法[6].基于排序的方法是比较直观的选择性集成算法[7],按照某种标准对子模型进行排序,依次挑选子模型.Zhang等[8]通过计算子模型的精度、多样性和泛化能力,采用多目标排序算法对其进行排序;Lu等[9]提出了一种兼顾准确性和多样性的启发式度量方法以评估子模型对整个集成模型的贡献量,按照贡献量选取部分子模型用于集成.基于聚类的方法,通过聚类挑选有代表性的子模型用于集成.Fu等[10]对数据集中的预测值进行聚类,挑选出每个集群中准确性最高的模型用于集成;Lin等[11]基于k-均值聚类对初始集成子模型进行剪枝,利用多层序列搜索策略动态循环地挑选用于集成的子模型.基于优化的方法将挑选子模型看作优化问题,挑选出成本最小或结果最优的集成子模型.Zhou等[12]采用旋转森林算法产生多样性较高的候选子模型,利用遗传算法来进化并挑选集成池的最优子集;Zhu等[13]采用改进的离散人工鱼群算法,挑选精度更高、差异性更大的子模型.
基于排序的选择性集成方法是一种最简单、计算成本最少的方法.本文使用排序法,提出了一种基于精度排序的选择性集成建模方法.该方法采用在线极限学习机(online sequential extreme learning machine,OS_ELM)构建子模型,每个子模型分类的各性能指标代表子模型的特征属性,利用近似线性依靠(approximate linear dependence,ALD)条件挑选出差异性较大的子模型用于集成.
1 选择集成在线极限学习机
本文通过改进集成在线极限学习机(ensemble online sequential extreme learning machine,EOS_ELM),挑选出多样性较大的子模型用于集成,提升了模型的泛化性能.该方法如图1所示,共分为3个阶段:学习阶段、选择阶段和集成阶段.
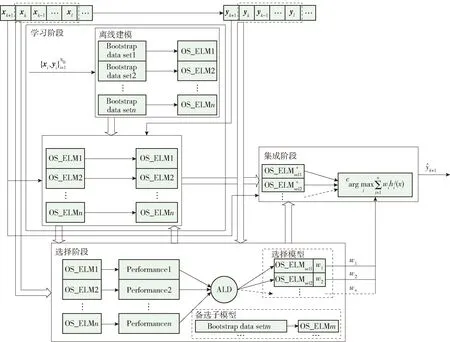
图1 SEOS_ELM建模策略Fig.1 Modeling strategy of SEOS_ELM
1.1 学习阶段
学习阶段分为离线建模和模型在线更新.离线建模是指利用静态数据集训练初始模型;模型在线更新是指在数据流场景中,模型不断地利用一个接一个到来的数据进行参数的更新.
1.1.1 离线建模

yi=φ(xiWd×L+b1×L)βL×1,i=1,…,N0
(1)
式中:φ(·)为激活函数;Wd×L和b1×L分别为输入权重矩阵和偏移量向量;L为隐含层神经元节点个数;βL×1为输出权重向量.Wd×L和b1×L由计算机产生的随机数组成,因此,确定OS_ELM模型只需计算出输出权重向量βL×1.设隐含层的输出为H0,则式(1)可重写为
Y0=H0β0
(2)
式中
则输出权重向量可确定为
(3)

在集成学习中,根据各子模型的预测精度A,计算各子模型的权重
(4)
式中:wt为第t个子模型的权重,t=1,…,m;m为子模型的总个数.
1.1.2 模型在线更新
在线场景中,离线建立的模型可能不能适应数据流的变化,导致模型的整体性能变低,通过模型的在线更新,即更新输出权重向量来应对概念漂移带来的影响.

(5)
式中H1为当前数据块的隐含层输出.令
则式(4)可重写为
(6)
采用递归的思想,当第Nk+1个样本到达时,中间参数Kk+1和输出权重向量βk+1可表示为
(7)
(8)
1.2 选择阶段
在线场景中,随着集成中子模型的不断更新,各子模型越来越趋向于一致性,导致子模型的多样性降低.为保证集成中子模型的多样性,本文提出了一种基于精度排序的选择性集成建模方法.当滑动窗口中的数据达到一定数量时,按照各子模型在该窗口数据的预测精度对其进行排序,将子模型在该窗口数据的其他性能指标作为特征属性,利用ALD条件依次挑选出用于集成的子模型.被挑选的子模型称为基准子模型,未被挑选的子模型将会用该窗口数据训练的新子模型替代,新训练的子模型称为备选子模型.备选子模型参与下一个数据样本的预测和参数更新,但不参与最终的集成输出,用于下次子模型的挑选.下面具体介绍如何选择子模型.
在线场景中,ft代表第t个子模型在某个窗口数据上的一系列性能指标的向量,t∈{1,…,m}.子模型的ALD程度的描述为
(9)
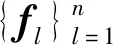
(10)

在挑选子模型时,精度最高的子模型默认为第1个基准子模型,按精度的顺序依次判断子模型是否能被挑选为基准子模型.采用文献[15]的方法,可得到递推形式的ALD值,即
(11)

(12)
在此基础上引入核函数,将基准子模型原始特征空间映射到更高维的特征空间,则基于核函数的递推ALD值表示为
(13)
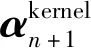
(14)
1.3 集成阶段
集成阶段是将1.2节挑选的基准子模型根据子模型权值进行加权输出,则集成输出的结果为权重和最大的类别,即
(15)

2 实验与分析
针对本文所提的算法,为了验证其有效性,采用3组合成数据集和3组真实数据集进行实验,实验结果表明所提算法能有效提高分类精度.
2.1 数据集描述
2.1.1 合成数据集
为了验证模型处理概念漂移的能力,在实验中测试了3组不同类型的数据集.在使用合成数据集时,能确切知道概念漂移的类型以及数据分布变化的剧烈程度[16].3组合成数据集如表1所示,描述如下.

表1 合成数据集Table 1 Synthetic data sets
1)SEA Moving Hyperplane Concepts (SEA)包含3个特征属性,只有前2个属性(x1和x2)是相关的[16],3个属性值都由0~10的整数随机产生.根据不等式ax1+bx2≤θ来定义数据标签,若满足不等式则类别为1,否则为0.为了模拟概念漂移,θ每隔1 000个数据就会发生变化.
2)Sine Concepts (SIN)根据三角函数不等式asin(bx1+θ)+c≤x2确定数据标签,若满足不等式则为1,否则为0.其中x1和x2由取值范围为[-5,5]的整数随机产生,通过改变θ的值来模拟概念漂移,θ每隔200个数据变化一次.
3)Circle Concepts (CIR)通过圆的表达式(x1-a)2+(x2-b)2≤θ2确定数据集,若点(x1,x2)在以圆心为(a,b)、半径为θ确定的圆内或圆上,则标签为1,否则为0.其中x1和x2是由取值范围为[-5,5]的整数随机产生,θ每隔1 000个数据变化一次.
2.1.2 真实数据集
为了验证模型在实际应用中能非常有效地提升分类精度,在实验中选用了3组流行的数据集进行测试,结果表明,在真实数据上模型的性能也有很好的提升.3组真实数据集如表2所示,具体描述如下.
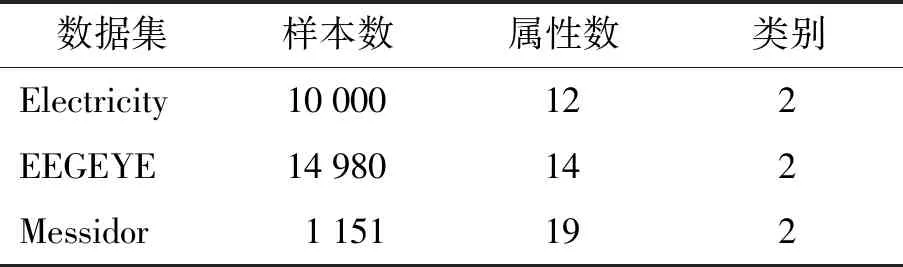
表2 真实数据集Table 2 Real-world data sets
1)Electricity数据集是被广泛使用的数据集,包括10 000个样本,12个属性变量,每个样本标签根据价格的变化来确定.
2)EEGEYE数据集来自使用Emotiv脑电图(electroencephalogram,EEG)神经耳机进行的一次连续EEG测量.通过相机检测到眼睛状态,“1”表示闭眼,“0”表示睁眼.该数据集共14 980个样本,每个样本有14个属性变量.
3)Messidor数据集包含从Messidor图像集中提取的特征以预测图像是否包含糖尿病性视网膜病变的体征.该数据集包含1 151个样本,每个样本含有19个属性变量,分为2个类别:0表示正常;1表示患有糖尿病视网膜病变.
2.2 数据集描述
本实验是基于数据流在线更新子模型,基于滑动窗口选择子模型,即在模型完成一个样本的预测得到其真实标签后更新各子模型的参数,当预测的样本达到一定数量时,根据各子模型在该窗口数据上的性能指标选择保留或移除,被选择的模型用于最终的集成.选择模型的阈值v决定了基准子模型的数量,本实验设置的初始阈值为0,每次选择基准子模型后,将会更新一次阈值.本实验采取的阈值更新策略为
(16)
式中:δ={δ2,…,δm}为m个子模型产生的m-1个ALD值;med(·)表示取中值.
选择基准子模型的同时,用该窗口中的数据训练新的子模型,使总的子模型个数保持一致.

(17)
式中Tp、Fp、Fn、Tn为混淆矩阵中的元素,具体含义如表3所示.

表3 混淆矩阵Table 3 Confusion matrix
2.3 实验结果
本实验均采用数据集的20%作为训练集,80%作为测试集,表4给出了不同算法在不同数据集上的运行结果.表4中的选择集成在线极限学习机(selection ensemble online sequential extreme learning machine,SEOS_ELM)算法和核选择集成在线极限学习机(kernel selection ensemble online sequential extreme learning machine,KSEOS_ELM)算法挑选基准子模型时的滑动窗口大小设置为50,关于滑动窗口大小的选择在后面讨论.
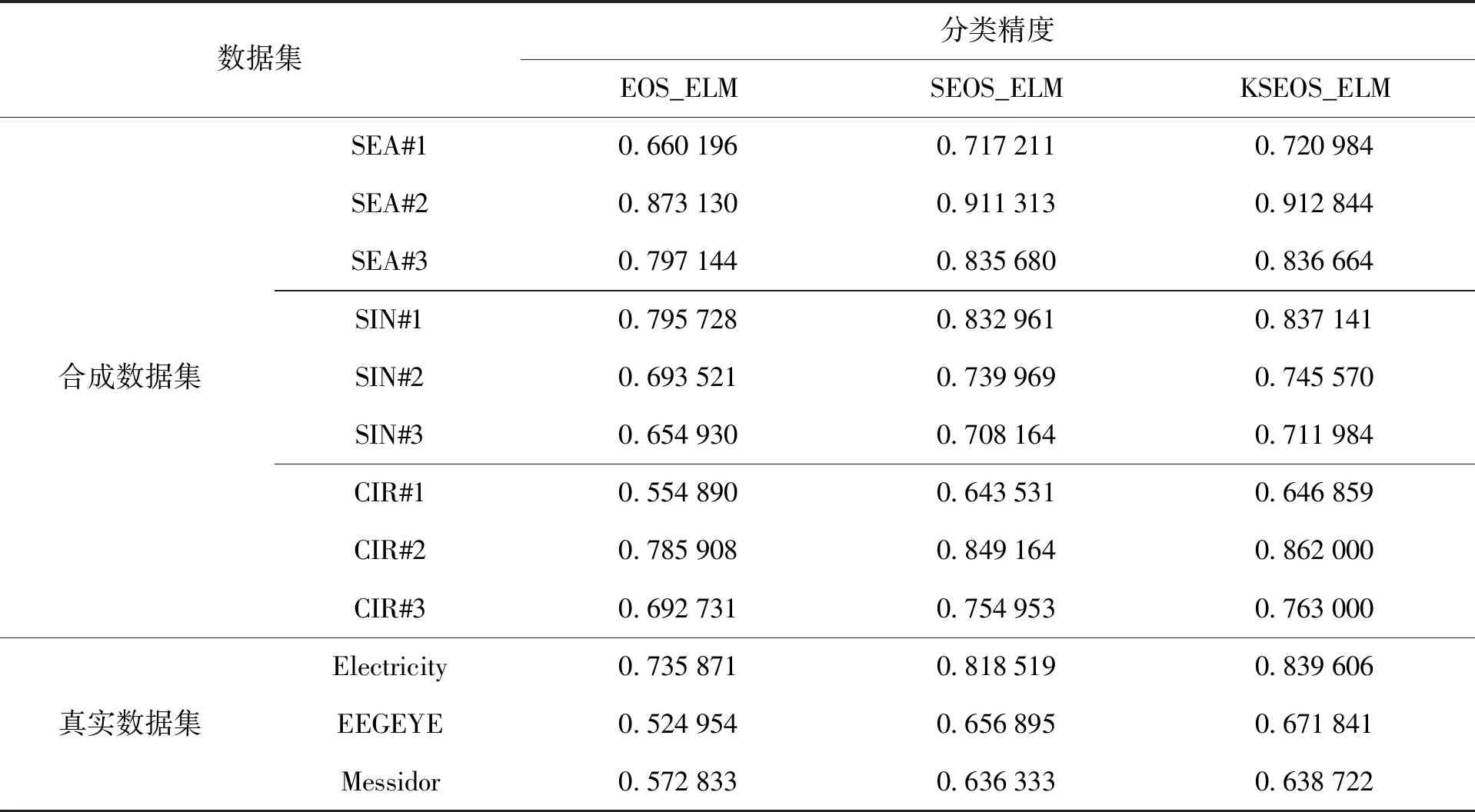
表4 不同算法的运行结果对比Table 4 Comparison of running results of different algorithms
从表4可以看出,提出的SEOS_ELM算法和KSEOS_ELM算法的分类精度明显高于EOS_ELM算法的分类精度.
为了验证不同大小的滑动窗口与SEOS_ELM、KSEOS_ELM算法的分类精度有关,本实验选取滑动窗口分别为250、200、150、100、50和30进行实验,实验结果如表5所示.
从表5中可以看出,模型的分类精度会随着滑动窗口的减小而提高,但随着滑动窗口的逐步减小,模型分类精度的提升越来越小.根据表5中的结果,滑动窗口一般选择在50或100较为合适.
2.4 实验结果分析
本文提出的SEOS_ELM和KSEOS_ELM模型之所以能够提升集成模型的预测精度,是因为在集成的过程中,首先按照各子模型的分类精度对其进行排序,优先挑选精度较高的子模型.在考虑子模型精度的同时,根据各子模型的ALD值,保留了差异性较大的子模型,这样在不同概念的漂移出现时,不同的子模型将会更好地应对.表4中的结果表明,所提出的选择集成模型对数据流分类是有效的,在合成数据集和真实数据集上,分类精度都有明显的提升.
EOS_ELM算法在解决概念漂移问题时虽然有一定的优势,但是在未发生概念漂移时,随着集成中子模型的在线更新,其预测性能慢慢趋向一致,导致子模型间的多样性降低.一旦发生概念漂移,集成中的子模型不能及时适应漂移后的概念,导致预测精度下降,而SEOS_ELM和KSEOS_ELM算法中的子模型在在线更新的基础上,挑选出精度较高、多样性较大的子模型用于最终的集成,即使发生概念漂移,SEOS_ELM和KSEOS_ELM算法也能迅速适应当前的概念,因此,本文提出的SEOS_ELM和KSEOS_ELM算法的预测性能优于EOS_ELM算法.
在选择基准子模型时,滑动窗口太小会导致子模型更新频繁,在根据混淆矩阵计算各子模型的特征属性(性能指标)时,为了避免分母为0的情况,进行了拉普拉斯修正,滑动窗口太小还会影响各子模型特征属性的计算精度且减小滑动窗口对集成模型分类性能的提升也越来越小;滑动窗口过大,导致基准子模型不能及时更换,子模型的多样性会随着子模型的在线更新而减小,即基准子模型的预测性能慢慢趋向一致,在新的概念漂移发生时,现有的基准子模型反应相对缓慢.表5中的实验结果表明,滑动窗口的大小应选择50或100较为合适.
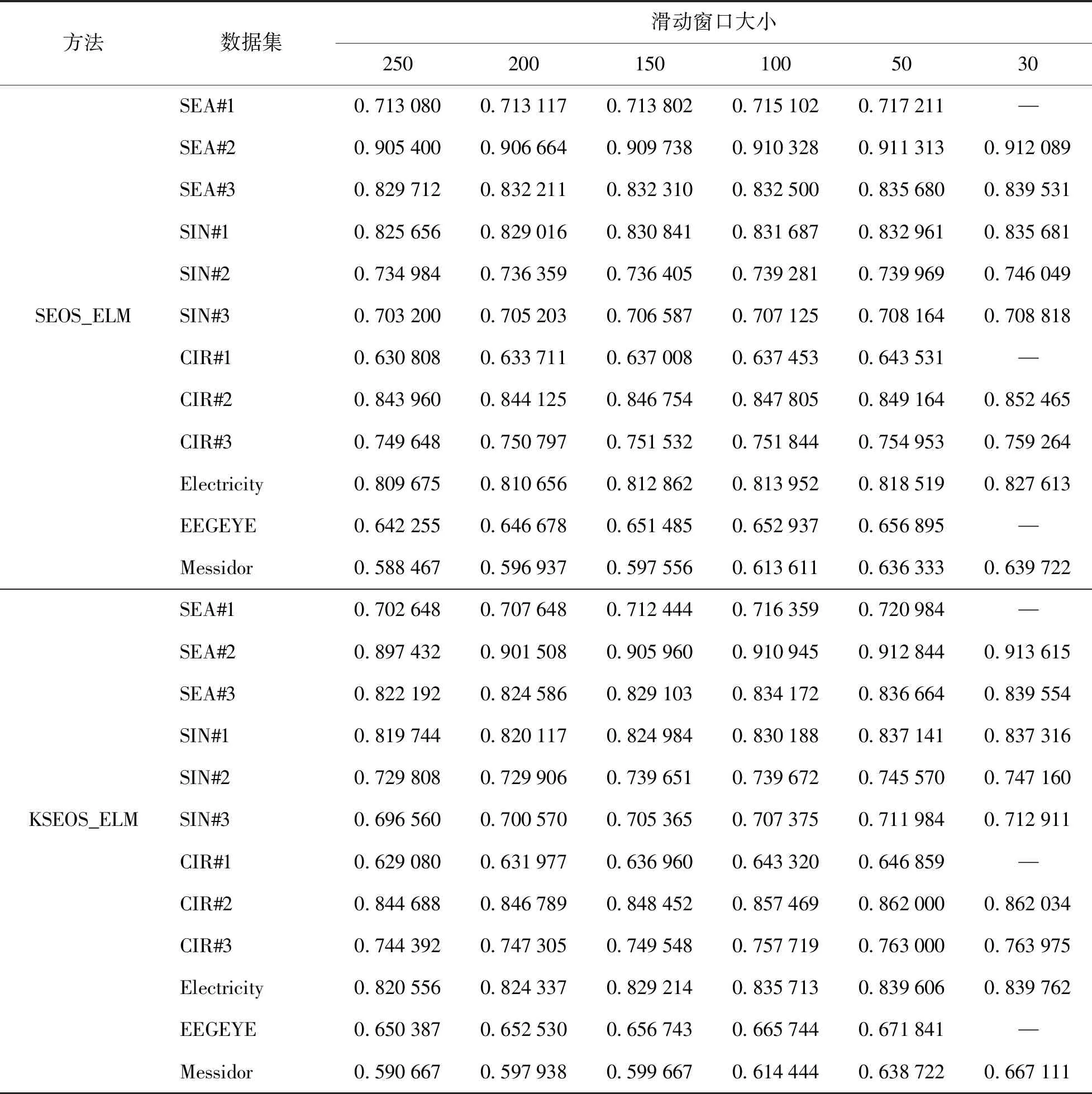
表5 不同窗口大小对模型精度的影响Table 5 Influence of different sliding window sizes on model accuracy
3 结论
1)根据子模型在滑动窗口上的性能指标,本文提出了一种基于精度排序,利用ALD条件的选择性集成建模方法——SEOS_ELM.该方法将各子模型按照分类精度排序,在考虑各子模型预测精度的同时,根据各子模型在滑动窗口数据中的其他性能指标挑选出差异性较大的子模型用于集成,在确保集成子模型多样性的同时,又能确保子模型拥有较高的精度,进而提升了集成模型应对概念漂移的能力.
2)在计算子模型与基准子模型的ALD值时,引入核函数,将子模型的原始空间映射到高维空间,提出了KSEOS_ELM算法.
3)设计了对比实验,实验结果表明,SEOS_ELM和KSEOS_ELM算法具有更好的预测性能,对具有概念漂移的数据集效果更好.
