基于文化鲸鱼优化算法的特征权重优化分配方法
2021-11-17严爱军曹付起
严爱军,曹付起
(1.北京工业大学信息学部,北京 100124;2.数字社区教育部工程研究中心,北京 100124;3.城市轨道交通北京实验室,北京 100124)
权重指的是某一因素或指标相对于某一事物的重要程度,反映该因素或指标的相对重要性.权重的分配广泛应用于社会的各种系统中,无论是在多目标多因素系统的综合评价[1]和决策领域[2],还是在经济、社会、环境、科技等系统的软科学研究领域[3],以及不确定性环境下的参数预测领域[4],都涉及权重分配的问题.研究证明,权重的合理分配与否会对预测和决策结果产生较大的影响,因此,国内外学者对特征权重的分配方法展开了大量的研究.
综合国内外的研究,特征权重的分配方法主要分为3类:主观赋权法、客观赋权法和组合赋权法.主观赋权法主要是根据专家的知识经验或偏好,根据重要性程度对各特征的权重进行比较、分配或计算,主要方法有层次分析法[5]、专家估评法[6]和环比评分法[7],但主观赋权法的主观性和不确定性很强,专家对于权重的分配是根据实际经验和对预测对象的熟悉程度来制定的,不同的专家得到的结果并不完全一样,因此,主观赋权法的一致性和可信性难以得到保障.客观赋权法则是根据一定的数学理论和计算方法从特征数据出发对特征权重进行分配.主要方法有灰色关联度分析法[8]、神经网络法[9]、遗传算法[10]等.灰色关联度分析法通过将数据对比与几何图形发展态势相结合来求权重,该方法具有计算过程简单、无需大量样本等优点,但无法解决特征间相关性导致的冗余问题;神经网络法通过训练样本得到特征权重优化分配的计算模型,但其结构设计较为困难,对训练样本的要求也比较严格;遗传算法是一种通过模拟自然进化过程搜索最优个体的方法,通过对权重进行迭代寻优得到最优权重,具有运行简单、鲁棒性强等优点,但收敛速度慢、局部搜索能力差.组合赋权法[11]将上述的主观赋权法和客观赋权法结合起来,依据不同的偏好系数确定特征权重,这种方法可能存在较大的随机性偏差,计算复杂度普遍比较高.可见,上述3类赋权法在特征权重的优化分配中得到了广泛应用,但仍具有一些缺陷以及局限性,因此,研究一种新的权重分配方法十分必要.
元启发式算法由于其具有简单性、灵活性、鲁棒性以及高性能性被运用到各学科或工程问题中.作为元启发式算法的一个热点研究方向,群体智能优化算法通过不停地对群体进行迭代从而获得最优解.目前,已经有很多群体智能优化算法及其改进方法被提出,比如粒子群算法[12]、人工蜂群算法[13]、萤火虫算法[14]、灰狼算法[15]等.
鲸鱼优化算法(whale optimization algorithm,WOA)是由澳大利亚学者Mirjalili等[16]于2016年提出的一种群体智能优化算法,它通过鲸鱼群体搜索、包围和追捕攻击猎物等过程实现搜索和优化目的.虽然鲸鱼算法已被证明在求解精度和收敛速度方面存在很大优势,但仍存在局部最优问题.针对此问题,学者提出了一些改进的方法.文献[17]提出一种反向学习自适应的WOA,在搜索空间中利用反向学习算法对鲸鱼的位置进行初始化,并在局部搜索阶段加入线性权重增强算法的局部搜索能力.该文献对高维度基准函数进行计算,展现出了良好的计算性能.文献[18]使用混沌映射来优化鲸鱼算法的内部参数,进一步地提高了算法的计算精度,具有更好的全局搜索能力.文献[19]提出了一种结合自适应权重和模拟退火的鲸鱼算法,通过改进的自适应权重来调整算法的收敛速度,并使用模拟退火加强鲸鱼算法的全局搜索能力,用于对测试函数的极值计算,计算精度和收敛速度都有了一定的提高.
Reynolds[20]于1994年提出了文化算法,其思想是利用种群进化过程中的知识构造信仰空间,以知识的方式指导种群空间的种群进化,能有效提高算法的全局搜索能力.种群空间可用于实现任何基于种群的优化算法,一方面,对种群个体进行演化操作,另一方面,将优秀的个体作为样本提供给信仰空间.信仰空间通过接受函数接受种群空间中选择出来的优势个体,并在各类演化算法的作用下,提取样本个体携带的隐含信息,以知识的形式加以概括、描述和储存.最终各类知识通过影响函数作用于种群空间,从而实现对种群空间中个体的更新指导.目前已成功应用于粒子群算法[21]、萤火虫算法[22]、蜂群算法[23]等随机优化算法.文化算法的优势及成功应用为有效解决鲸鱼算法容易陷入局部最优提供了一种很好的思路.鉴于文化算法的全局搜索优势,本文将鲸鱼算法纳入到文化算法的种群空间,得到一种文化鲸鱼优化算法(cultural whale optimization algorithm,CWOA)来进行特征权重的优化分配.
本文以案例推理预测模型为例,对加州大学欧文分校(University of California Irvine,UCI)标准预测数据集中的特征权重研究了优化分配方法.将本文提出的文化鲸鱼算法用于权重的优化分配,并通过实验测试证明了本文方法的有效性.
1 基于CWOA的权重优化
CWOA的框架结构如图1所示,包括种群空间和信仰空间.它采用双层进化机制,即在种群进化算法的基础上构建信仰空间,2个空间相对独立地进行进化,并通过接受函数和影响函数进行交互.图中的种群空间是求解最优权重的主空间,具有性能评价和演化操作2个功能,其中,演化操作是利用WOA更新权重,性能评价则是通过计算适应度对这些权重进行评价.信仰空间采用形势知识和规范知识进行该空间的知识描述,权重的更新则是利用双变异演化策略来实现.2个空间之间的交互操作主要有接受操作和影响操作2种方式,信仰空间通过接受函数选取种群空间中的最优权重,种群空间通过影响函数利用信仰空间的形势知识和规范知识来指导权重的更新[24].下面从种群空间的演化策略、信仰空间的知识描述以及2个空间之间的交互操作三方面来介绍.
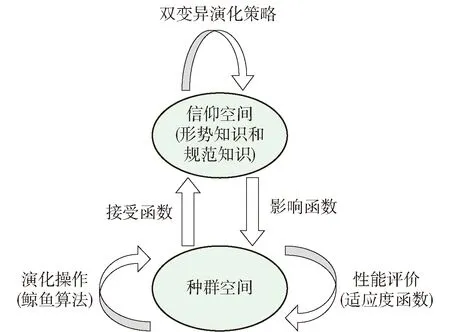
图1 文化鲸鱼算法框架Fig.1 Cultural whale algorithm framework
1.1 种群空间的演化策略
种群空间采用鲸鱼算法进行权重的演化更新和性能评价.鲸鱼算法是一种模仿座头鲸泡泡网觅食行为的仿生智能优化算法.令每个鲸鱼的位置代表一个权重的可行解,该算法主要分为2个部分:一部分为随机搜索最优权重,另一部分是通过泡泡网觅食行为获得最优权重.
1)随机搜索
随机搜索阶段对应着算法的全局探索阶段,是随机寻找最优权重的过程.在n个特征权重中,令每一个权重的可行解在D维空间内,则第j个权重的可行解可表示为ωj=(ωj,1,ωj,2,…,ωj,i,…,ωj,D),更新公式为
(1)

A=2ar1-a
C=2r2
(2)
计算.式中:r1和r2为[0,1]中的随机数;a为控制参数,随着迭代次数t的增加从2线性减小到0,即
a=2-2t/tmax
(3)
式中tmax为最大迭代次数.
当式(2)中的|A|≥1时,进入随机搜索阶段,根据各权重的可行解进行随机搜索最优权重;当|A|<1时,进入局部搜索阶段,采用泡泡网觅食行为进行最优权重的搜索.
2)泡泡网觅食
泡泡网觅食对应着算法的局部搜索阶段,通过收缩包围和螺旋上升更新权重.当式(2)中的|A|<1时,权重值会通过泡泡网觅食行为不断趋向当前最优解.其中收缩包围方式可表示为
(4)

在进行螺旋更新权重时,当前权重以螺旋形运动趋向最优权重,即
(5)
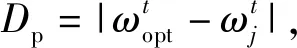
上述的式(4)收缩包围和式(5)螺旋更新权重的选择由随机产生的概率因子p的值来决定.当p≥0.5时,进入螺旋更新权重阶段;当p<0.5时,进入收缩包围阶段.即
(6)
在种群空间,通过上述的随机搜索和泡泡网觅食算法可得到该空间中的最优权重.
1.2 信仰空间的知识描述和更新策略
信仰空间的核心是知识表示和存储更新,知识表示根据种群空间的演化策略和应用领域来制定,该空间中的知识共有5类:形势知识、规范知识、拓扑知识、领域知识和历史知识[25].本文采用形势知识和规范知识描述信仰空间,这2种知识的形成依赖于对种群空间的最优权重进行双变异演化和性能评价的结果.下面是具体的算法描述.
1)形势知识
形势知识用于记录进化过程中的最优权重,采用双变异演化策略进行权重的更新演化.双变异演化策略的基本思想是在迭代的早期和后期分别采用非均匀变异算子和柯西变异算子对权重进行变异操作.其中的非均匀变异算子[26]在迭代早期能均匀地搜索整个空间以尽快发现可能的最优区域,但随着算法的进行,搜索范围随概率变小不断缩减,到算法临近结束时仅在当前解的小范围中搜索,因此,需要在迭代后期采用柯西变异算子进行变异.柯西变异算子[27]可以产生较大的变异步长,有利于算法引导个体跳出局部最优解,保证了算法的全局搜索能力.下面介绍非均匀变异算子和柯西变异算子,并从中获得权重更新演化的形势知识.
非均匀变异算子定义为
(7)

柯西变异算子定义为
(8)

为了实现权重的更新演化,需定义权重所对应的适应度函数,根据案例推理预测模型输出的均方根误差得到适应度函数
(9)
式中:s为源案例总数;y(i)为第i条案例的实际值;y′(i)为第i条案例的预测值.
根据上述双变异策略,可得到信仰空间在第t次迭代时用于权重更新演化的形势知识
(10)
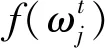
2)规范知识
规范知识用于描述权重的可行解空间,对其更新体现为权重搜索空间的变化.针对权重的优化问题,其结构描述为Ij,Lj,Uj,j=1,2,…,其中Ij=[lj,uj]={lj≤ωj≤uj,ωj∈},表示第j个权重搜索空间边界的值,上界uj初始化为1,下界lj初始化为0.规范知识根据每代获得的优势权重进行更新,规则[28]为
(11)
(12)
(13)
(14)

信仰空间通过双变异演化策略对种群空间的最优权重进行更新演化后,为了达到2个空间相互影响从而提高精度的目的,还需要进行空间之间的交互操作设计.
1.3 空间之间的交互操作设计
种群空间和信仰空间的交互通过接受操作和影响操作来实现,具体操作如下.
1)接受操作
信仰空间通过接受函数从种群空间接受一组最优权重子集,这里采取比例接受策略,即按接受比例ka依适应值升序接受权重个体,接受个数为
m=Nka
(15)
式中:m为信仰空间接受权重个数;N为种群空间权重个数.
在种群空间的权重进行过程中,每当接受操作执行间隔为Acc时,按照
KM=ωopt
(16)
用种群空间中的最优权重代替信仰空间中适应度差的权重.式中:KM为信仰空间中适应度最差的权重个体,M为信仰空间权重个数;ωopt为种群空间中适应度最好的权重个体.
2)影响操作
信仰空间中的形势知识和规范知识形成后,通过影响函数对种群空间的权重进行引导以使种群空间在进化过程中得到全局最优值,每当影响操作执行间隔为Inf时,按照
ωf=Xr
(17)
用信仰空间中适应度最好的权重代替种群空间中适应度最差的权重.式中:Xr为信仰空间中适应度最好的权重个体;ωf为种群空间中适应度最差的权重个体.
CWOA通过双层进化机制不断更新迭代权重,当迭代到最后一次时,取种群空间中的最优权重ωopt作为特征权重的最优化分配.
根据上述1.1~1.3节的算法描述,可以得到CWOA伪代码如下.
算法1CWOA
输入:数据集Ck=(x1,…,xj,…,xn;y)、最大迭代次数tmax、信仰空间权重个数M、种群空间权重个数N、接受操作执行间隔Acc、影响操作执行间隔Inf、权重搜索空间上限uj和下限lj.
输出:特征变量权重值ωopt.
1 随机产生种群空间的权重;
2 通过式(9)计算每组权重的适应度,并由小到大排列;
3 根据随机权重的信息给信仰空间中的形势知识和规范化知识赋初值;
4 获得当前最优权重ωopt;
5 while满足停止条件
6 fori=1,2,…,tmaxdo
7 ifi%Acc=0
8 通过式(16)将种群空间中的最优权重代替信仰空间中适应度差的权重;
9 end if
10 if|A|≥1
11 种群空间通过式(1)更新下一代权重;
12 else
13 种群空间通过式(6)更新下一代权重;
14 ifi>tmax/2
15 信仰空间通过式(8)(10)更新权重;
16 else
17 信仰空间通过式(7)(10)更新权重;
18 end if
19 信仰空间通过式(11)(12)(13)(14)进行规范知识的更新;
20 ifi%Inf=0
21 通过式(17)将信仰空间中适应度最好的权重代替种群空间中适应度最差的权重;
22 end if
23 end for
24 end while
25 返回权重值ωopt;
1.4 收敛性分析
下面首先给出随机优化算法全局收敛需要满足的2个条件[29],然后分析CWOA的全局收敛性.
条件1若f(D(x,ξ))≤f(x)且ξ∈A,则f(D(x,ξ))≤f(ξ).

条件2对于A的任意Borel子集B,若其概率测度v(B)>0,则有
(18)
式中μk(B)为算法第k次迭代的权重在集合B上的概率测度.此假设保证了在测度大于0的情况下,算法经无穷多次迭代后,未搜索到空间B中的权重的概率为0.
引理假设适应度函数f为可测的,Rε为全局最优权重集,P(zk∈Rε)为算法第k步生成的权重xk属于最优解Rε的概率测度,若条件1和2成立,则有
(19)
CWOA采用信仰空间保存最优权重集,保证了最优权重适应度不递增,符合条件1.

综上可知,CWOA收敛于全局最优权重.
2 实验研究
2.1 实验设计
为了验证本文方法进行特征权重优化分配的有效性,以基于案例推理的数据预测模型为例,选取UCI机器学习的4个数据集作为测试数据进行实验.4个数据集分别是Airfoil Self-Noise、Concrete Slump Test、Concrete Compressive Strength、QSAR aquatic toxicity,具体信息如表1所示.Airfoil Self-Noise为预测机翼自身噪声的数据集,Concrete Slump Test是混凝土坍落度测试数据集,Concrete Compressive Strength是预测混凝土抗压强度的数据集,QSAR aquatic toxicity是预测水生毒性定量构效关系的数据集.
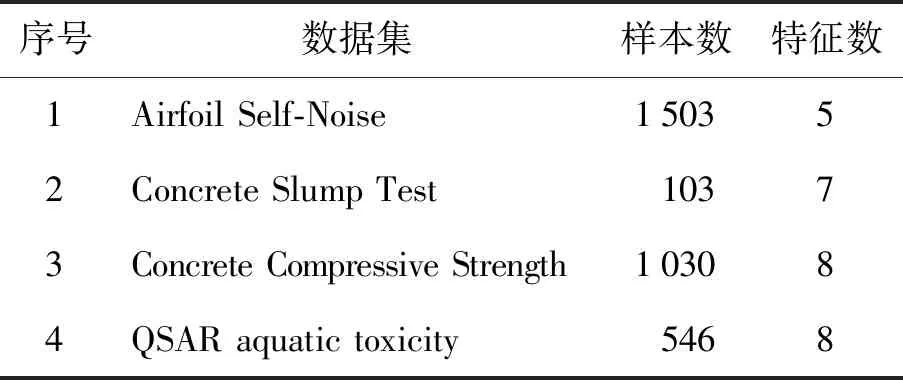
表1 数据集信息Table 1 Dataset information
为了全面考察本文方法的效能,采用五折交叉验证法进行实验,实验方案如下.
针对UCI的4个数据集,根据1.3节介绍的算法,对案例推理(case-based reasoning,CBR)检索环节进行特征权重的优化分配,然后利用得到的权重结果进行回归预测,并与其他权重分配方法(传统均权值(mean average,MA)、遗传算法(genetic algorithm,GA)、差分进化(differential evolution,DE)和WOA)进行实验结果的对比.其中,采用CWOA优化权重的CBR预测模型简称为CBRCWOA,采用其他权重分配方法的CBR预测模型依次简称为CBRMA、CBRGA、CBRDE和CBRWOA.
实验中的参数选取情况为:GA种群大小设为100,交叉概率为0.4,变异概率为0.05,进化代数为30;DE的种群规模设为100,缩放因子为0.5,交叉概率为0.9,进化代数为30;WOA的种群规模设为100,最大进化代数为30;CWOA群体空间的种群大小设为100,信仰空间种群大小30,信仰空间非均匀变异概率为0.4,柯西变异概率为0.5,接受操作执行间隔为3,影响操作执行间隔为4.
2.2 实验步骤
根据上文的实验设计,实验步骤如下:
步骤1选择数据集,将数据集的特征变量进行归一化处理,并把特征值和相应的预测值表示成式(1)的形式存储在案例库中.
步骤2采用五折交叉验证法进行实验,将数据集中的数据平均分为5份,其中的4份组成历史案例库,另外1份组成目标案例库.
步骤3分别采用MA、GA、DE、WOA和CWOA五种算法进行特征权重的优化分配.
步骤4对于目标案例库中的案例,采用K最近邻方法在历史案例库中进行案例检索,通过式(9)计算相似度并将其从大到小进行排序,取出前3个案例.
步骤5计算前3个案例输出值的平均值作为目标案例的建议解.
步骤6将目标案例特征值及其建议解存储在历史案例库中.
步骤7重复步骤4~6,直到目标案例库中所有目标案例测试完成.
步骤8利用目标案例的预测值和实际值计算均方根误差和平均绝对百分比误差.
步骤9重复步骤1~7十次,计算10次实验结果的标准差.
2.3 比较分析
根据2.2节中的实验步骤1~7,利用表1中的4个回归数据集分别验证CBRMA、CBRGA、CBRWOA和CBRCWOA的拟合性能,实验结果如图2~5所示.由图中可以看出,相对于CBRMA、CBRGA、CBRDE和CBRWOA,CBRCWOA更能拟合数据的变化趋势.CWOA算法能在信仰空间的作用下对空间全局进行搜索得到最优权重,得到的预测值逼近能力最好,预测精度最优.

图2 Concrete Slump Test数据集拟合曲线Fig.2 Fitting curve of Concrete Slump Test dataset

图3 Airfoil Self-Noise数据集拟合曲线Fig.3 Fitting curve of Airfoil Self-Noise dataset

图4 Concrete Compressive Strength数据集拟合曲线Fig.4 Fitting curve of Concrete Compressive Strength dataset

图5 QSAR aquatic toxicity数据集拟合曲线Fig.5 Fitting curve of QSAR aquatic toxicity dataset
根据2.2节中的实验步骤,利用表1中的4个回归数据集分别验证CBRMA、CBRGA、CBRWOA、CBRDE和CBRCWOA的标准差,实验结果如图6所示.由图中可以看出,在前3个数据集中5种预测模型的标准差由低到高依次为CBRMA、CBRCWOA、CBRDE、CBRWOA、CBRGA,而在最后一个数据集中标准差由低到高依次为CBRMA、CBRCWOA、CBRGA、CBRWOA、CBRDE.从结果可知,CWOA算法通过信仰空间不断对权重迭代寻优,得到的权重比较稳定,使得预测模型的输出比较稳定.

图6 标准差Fig.6 Standard deviation
根据2.2节中的实验步骤,利用表1中的4个回归数据集分别验证CBRMA、CBRGA、CBRWOA、CBRDE和CBRCWOA的平均绝对百分比误差,实验结果如图7所示.由图中可知,5种模型的平均绝对百分比误差由低到高分别为CBRCWOA、CBRWOA、CBRDE、CBRGA、CBRMA.由结果分析可知,CWOA算法能够通过双层空间机制进行全局搜索得到最优权重,使得预测模型的实际预测误差较小.

图7 平均绝对百分比误差Fig.7 Mean absolute percentage error
根据2.2节中的实验步骤,利用表1中的4个回归数据集分别验证CBRMA、CBRGA、CBRWOA、CBRDE和CBRCWOA的均方根误差,实验结果如表2所示.由图中可以看出,在第2、4个数据集中均方根误差由小到大分别为CBRCWOA、CBRWOA、CBRDE、CBRGA、CBRMA,而在第1、3个数据集中均方根误差由小到大分别为CBRCWOA、CBRGA、CBRDE、CBRWOA、CBRMA.由此可得,CWOA算法能有效地利用数据集中数据的潜在信息,跳出局部最优值,得出最优权重,使得模型的预测精度较高.
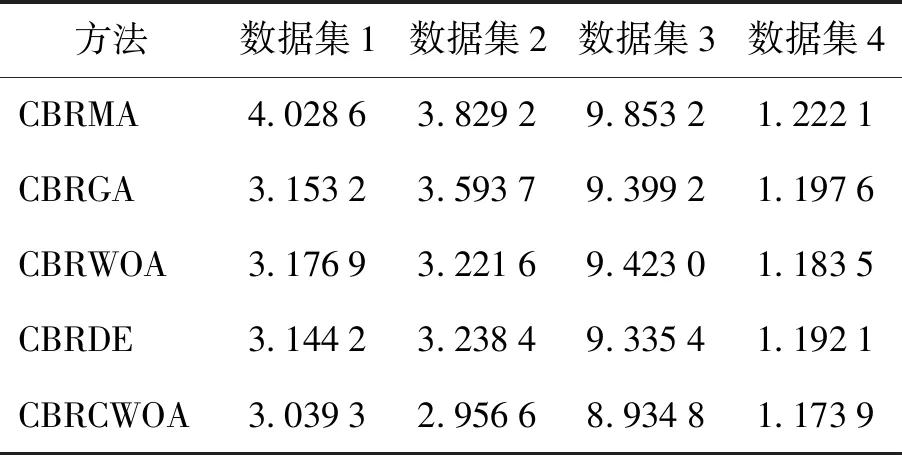
表2 均方根误差Table 2 Root mean squared error
3 结论
1)为了提高预测模型的精度,本文将WOA纳入文化算法的种群空间得到CWOA,进而通过迭代确定特征权重的最优解.通过案例推理的数据预测对比实验,CWOA相对其他方法可以在预测精度方面得到一定的提升,学习性能得到一定的改进.
2)本文方法的最大优势是采用双层进化结构,信仰空间不受种群空间WOA策略的影响,可以更加充分地利用WOA权重迭代过程中的进化信息,提高进化的效率,而且其算法简单,易实现,可拓展性好,可以跳出局部最优,搜索到最优权重.
3)虽然本方法在特征权重学习领域有一定的价值,但仍有一些不足之处,比如:一些问题的变量维数很多,目标和约束条件更加复杂.如何高效实现高维度变量空间的迭代寻优是以后的主要研究方向.
