一种基于位线电荷循环的低功耗 SRAM 阵列设计
2021-11-17张瀚尊贾嵩杨建成王源
张瀚尊 贾嵩 杨建成 王源
1. 北京大学微电子学研究所, 北京100871; 2. 北京大学微电子器件与电路重点实验室, 北京 100871;
目前, SOC 芯片离不开基于 SRAM 的高速缓存,而 SRAM 往往占据 SOC 的绝大部分面积, 因此低功耗 SRAM 对移动设备 SOC[1]非常重要。近年来, 尽管 FinFET 工艺以更小的晶体管尺寸和更低的功耗广泛应用于 SRAM 的制作, 但更低的工作电压和相对剧烈的工艺波动使其需要搭配使用读或写辅助电路才能实现预期的读写指标[2]。辅助电路会带来额外的能量损失, 导致 SRAM 阵列的功耗不能随着电源电压的下降而显著降低。
在 SRAM 阵列中, 动态功耗主要来自对大扇出位线进行预充电或电压状态切换[3]。例如, 在采用标准 14 nm 工艺 spice 模型搭建的位线全摆幅阵列仿真中, 位线预充电消耗的能量占总动态功耗的 90%以上。在常规的 SRAM 阵列的读操作结束后, 这部分位线预充电荷会被单元的存“0”节点直接泄放到 GND, 导致潜在的电能浪费。如果这部分电荷可以伴随读写操作被回收或再利用[4–7], 则可以大幅度降低总体的动态能耗。Kim 等[4]首次提出一种使用0.13 μm 工艺, 电源电压为 1.5 V 的基于位线电荷循环的 SRAM 阵列, 电荷随着连续的写操作, 从第一列的位线向后面的位线传播, 实现电荷共享。这种循环方式以降低写操作的位线摆幅为代价, 与没有用循环位线的阵列功耗相比, 写功耗降低 90%,但是单元的写静态噪声容限(write noise margin,WNM)减少 75%, 此外, 与选中单元(full selected bitcell, FSBC)位于同一行的半选单元(HSBC)的稳定性变得不容乐观。在 Kim 等[4]设计的基础上, Yang[1]在读写操作中都实现位线电荷循环, 而不会降低读静态噪声容限(static noise margin, SNM), 但WNM依然降低。这两种位线电荷循环方法对超低电压供电的深亚纳米工艺节点并不友好。Jeong 等[6]使用三星 14 nm 工艺设计的 SRAM 阵列, 使 HSBC 的位线电荷被控制, 并流向 FSBC 的 VSS, 使其电平高于0, 但由于 VSS 被提高需要一定的时间, 而 FSBC单元的写入速度非常快, 所以电路的时序控制比较复杂。在 Choi 等[7]的设计中位线预充电到 VDD 后会与特定的电容器共享电荷, 产生位线欠驱动电压(sup-pressed bitline, SBL), 用于单元的读辅助, 并且电容器上的共享电荷将被重复利用, 产生负电压位线(negative bitline, NBL), 用于单元的写辅助。但是, 连续的读操作会导致位线欠驱动电压增加,进而使读辅助失效, 并且, NBL 电压会被连续写操作不断地削弱, 直至失效。
本文提出一种基于位线电荷循环的兼具读写辅助的 SRAM 阵列, 其中位线电荷循环结构基于三星的设计, 组合的读写辅助基于 Choi 等[7]的设计。不同的是, 本阵列需要一个负电压发生控制器来实现电荷循环和读写辅助, 以消耗一些能量为代价来获得更好的读写稳定性。
1 基于位线电荷循环的读写辅助结构
1.1 SRAM 6T 单元尺寸选取
在 SRAM 的设计过程中, 首先需要确定基本单元每个晶体管的工艺尺寸。图 1(a)显示典型 6T 单元电路图。在读“0”操作中, 由于受读电流的影响,差分反相器的下拉管(pull down transistor, PD)与门管(gate pass transistor, PG)之间的发生分压使 FSBC中存储的数据“0”受到升压干扰, 数据“1”基本上不受影响。6T 单元的这种读机制使得数据“0”在门管开启时最容易受到外部噪声的影响, 所以需要仔细选择晶体管的尺寸, 以保证 6T 单元功能。由于FinFET 工艺的 Fin 只能是离散的值, 为了实现高密度, FinFET 单元的尺寸没有太多的选择[8]。由于SRAM 单元存在读干扰和半选择问题, 因此在设计尺寸时增大 SNM, 并且较大的 SNM 意味着 FSBC和 HSBC 具有较强的数据稳定性。如图 1(b)所示,β(PD 的 Fin 数:PG 的 Fin 数)越大, 单元的 SNM 越大[9]。尽管具有相同的β数值, 但是 PU:PG:PD = 1:1:1 单元的 SNM 大于 1:2:2 的单元, 原因是 1:2:2 的单元具有较大的读电流和读出速度, 大电流导致 PD 分压变大, 从而存储稳定性较差[10]。

图1 单元结构和读写静态噪声容限对比Fig. 1 Cell structure and comparison of read and write static noise tolerance vs VDD
在 PU:PG:PD = 1:1:1, 1:2:1 和 2:1:1 条件下, 测得单元写噪声容限(WNM)的变化情况, 如图 1(c)所示。通常具有较大γ(PG:PU)的单元, 在位线的作用下容易翻转。从图中可以看出, 尺寸比例为 2:1:1的单元写操作失败, 这是由于 PU 的驱动能力远超PG, 导致单元存储接点的状态“1”不容易被下拉成“0”, 所以该比例在设计中不可取。1:2:1 的单元WNM 最大, 但是相应的 SNM 最小。
考虑到 HSBC 的存储稳定性和电路设计的复杂性, 通常在 SRAM 单元尺寸选择中尽量提高单元的 SNM, 对 WNM 使用写辅助电路来弥补, 使设计能够满足既定的性能要求。本文仅对比例为 1:1:2 的 SRAM 阵列进行研究和优化, 但提出的读写辅助方法可以应用于其他尺寸设计(如 PU:PG:PD =1:1:1)中。
1.2 电路设计的整体布置
本设计中的 256×64 SRAM 阵列基于标准 14 nm spice 模型搭建, 正常工作频率为 1 GHz, 具有读写辅助电路, 字长为 64 bit。图 2 展示整个阵列的结构。基于位线电荷循环的读写辅助电路(charge sharing circuit, CRC)主要由两部分组成: 1) 由NVSS_en 控制的 VSS_switch, 作用是确定 CVSS 是连接到 GND 还是 CS_point; 2) charge_share_part(CSP), 一个负电压发生控制器。在读写操作期间,位线上的电荷通过 FSBC (本文中阵列在读写操作中没有半选单元)的 PD 和 VSS_switch 被 CSP 收集, 这些电荷将在下一个读写周期到来时, 重新用于位线的预充电, 而不是被释放掉后再使用电源对位线进行预充电。CSP 将读辅助与写辅助结合在一起, 单元负接地电压(NVSS)用于加速读操作, 并提高读稳定性, 而 NBL 用于写辅助, 受写使能信号控制。
由于阵列中行数很多, 并且会有大量漏电涌向负电压节点, 导致生成的 CS_point 的负电压减小,因此, 每行 VSS_switch 中 MV 管的尺寸需要精细选择。特别地, 当电路中存在负电压时, 相关的晶体管不会完全关闭, 这一问题可以通过调整时序来解决。
1.3 读操作和位线充电循环工作流程
图 3 为读操作的波形。首先, 将 FSBC 的两根位线预充电至高电平, CSP 的初始化开始: Ini_nc 和iso_nc 各自打开 MC 和 MI, 结果使 NV_point 和CS_point 的电压下降到 0。然后, WL 和 NVSS_en 导通,从而通过 PD 和 VSS_switch, 在 CVSS 和 CS_point之间建立连接。同时, ini_set 的信号从低电平变为高电平, 由于 NV_cap 和 CS_cap 的两个极板之间的电压差不能立即改变, 因此 CS_point 和 NV_point的电压都下降到负值。如图 2(a)所示, 来自存储“0”的 Q 节点相应位线的放电电荷被 CS_cap 接收, 致使 CS_point 的电压从负电平上升。当 WL 关闭时,CS_point 电平接近 0。

图2 实际电路图Fig. 2 Actual circuit diagram
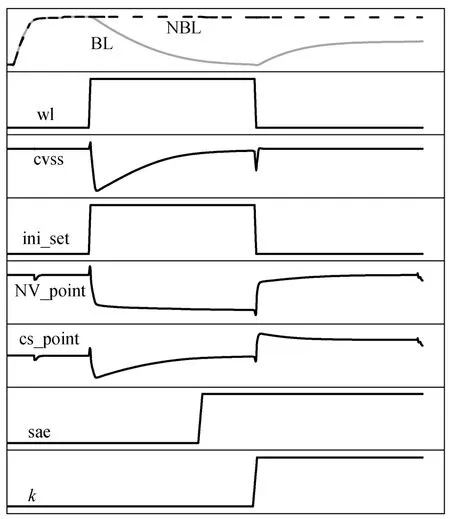
图3 读操作的波形Fig. 3 Waveform of read operation
使用 NVSS 作为读辅助有两个明显的优点: 一是 CS_cap 的负电压使得 FSBC 的 CVSS 电压变为负值, 增加了对应位线的放电速率, 加快读出速度;二是因为 PD 一直工作在线性区, 存“0”节点的电压也被拉至负电平, 由此存“0”节点的稳定性得到增强。另外, NVSS 还允许位线的电平快速降低至 0,进一步减轻位线的正电平对存“0”节点的影响。存“0”节点的负电压使存“1”节点的 NMOS 被完全关断, 对应的 PMOS 被加强, 使得存“1”节点的稳定性更强。因此, 使用 NVSS 的 FSBC 的读稳定性得到增强。
灵敏放大器(sensitive amplifier, SA)从 FSBC 读出数据后, WL 和 NVSS_en 被关断, 存“0”节点的电压恢复到 0。同时, 信号 ini_set 从 0 跳变为高电平,使 CS_point 的电压从低电平升至 0.7~0.8 V。当NV_cap 和 CS_cap 的极板电压都在 ini_set 的作用下完全反转后, 控制信号会控制 CS_cap 与已经被存“0”节点放电的位线电荷共享, 使位线电平被从 0 抬高, 于是位线在下一个读周期中的预充电能量损耗减少, 最大幅度可减少 50%的位线预充功耗。在将NV_cap 和 CS_cap 的电平从低电压拉到高电压时,也存在翻转功耗, 可将电容状态翻转的功率损耗视为电容器充电能量和电容器电势能变化之和。与减少的位线预充电能量相比, 这种程序的损耗是可以接受的。在传统阵列中, 位线上的电荷被无意义地放电到 GND, 但在本设计中, CSP 循环利用位线电荷有效地节省了预充电的电能消耗。
NV_cap 和 CS_cap 的电容可通过以下公式并通过仿真来选择, 以便限制实际电路面积。
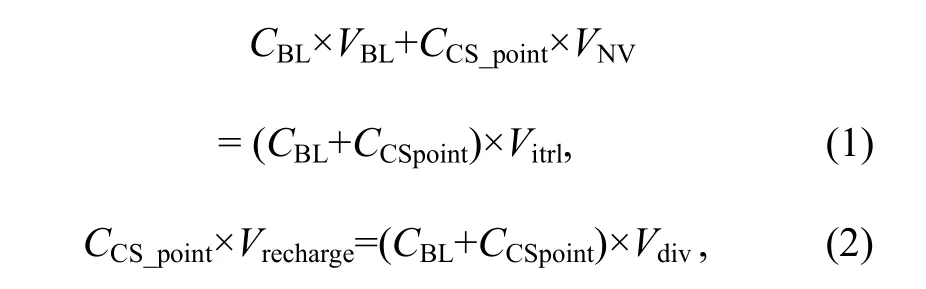
其中,VNV是 CSP 生成的负电压值, 几乎等于–0.8 V;Vitrl指位线与 CS_point 做电荷共享后的平均电压;Vrecharge是 ini_set 从高变低时 CS-point 的电压;Vdiv表示电荷循环后的位线电压, 在VDD/2左右。设计中, 电荷共享电容CS_cap略大于位线电容, 以便在WL脉冲结束时数据存“0”节点的位线电压可以快速地降至0(Vitrl=0)以及中和其余单元向负压节点的漏电。负压电容NV_cap至少是CS_cap的4倍, 因为NV_cap的意义是为CS_cap提供尽可能稳定的负电压, 以便CS_cap准备好从位线接收电荷。
1.4 写辅助电路工作流程
在写操作期间, 写辅助NBL由CSP产生的负电压生成。当写使能信号到达时, 写驱动器会控制相应的位线充电至VDD或与CS_cap共享电荷。写操作期间, CSP无论在结构上还是在时序上都与读操作没有任何区别。WL关闭后, 由div_en控制的NMOS对两个位线的电压进行平均。要实现的效果是, 在一个写周期之后, 在CSP与位线之间的电荷共享的帮助下, 两个位线的平均电压相等且不低于VDD/2, 这样可以使下一个写周期开始的位线充电能耗尽量降低。
图4为本设计中的写驱动电路。由写输入DIN0、写使能W_EN和初始化ini_nc这3个信号共同决定对相应位线进行充电还是放电到0, 再加载负电平。
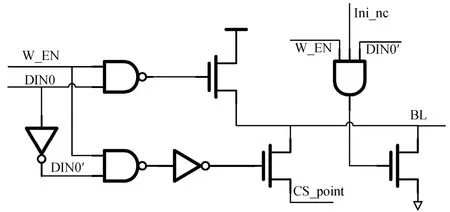
图4 设计中采用的写驱动电路Fig. 4 Write drive circuit used in the design
2 结果分析
本文中, SNM和WNM是量化SRAM读写稳定度的主要指标。如图5所示, 使用辅助电路的SNM和WNM比不使用辅助设计的分别提高32.6%和647.9%。SNM改善的原因是NVSS读辅助产生带负电平的存“0”节点, 这样的“0”节点数据不容易被较高的位线或其他外部噪声电压干扰或改变, 同时存“1”节点的稳定性也得到增强。
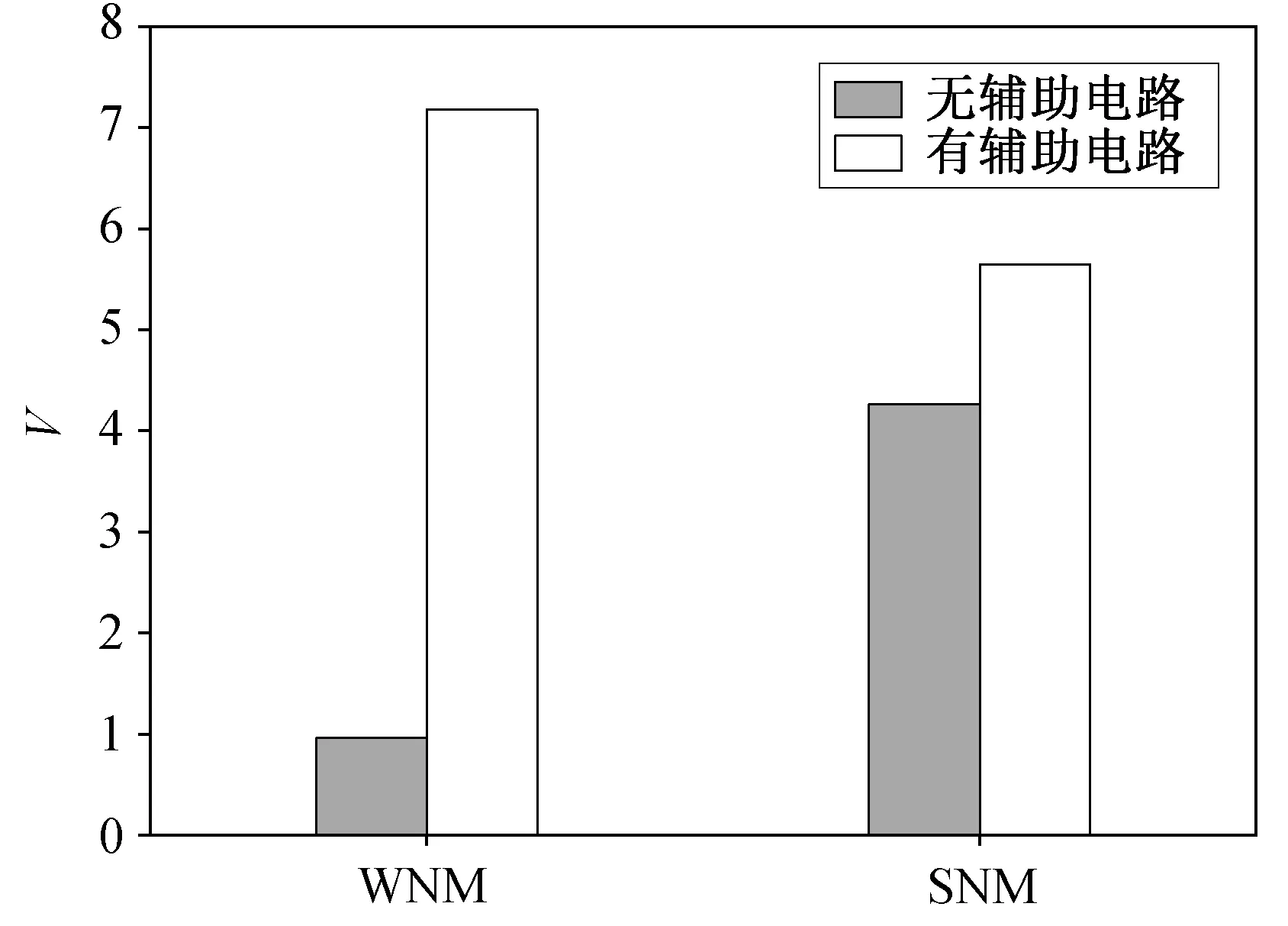
图5 有辅助电路和无辅助电路的阵列SNM 和WNM 比较Fig. 5 Comparison of array SNM and WNM with and without assst circuit
WNM 提高的原因是使用了 NBL 技术。位线上的负电压可以使最初存储“1”的节点状态迅速翻转为“0”。可以将 WNM 近似地视为单元的翻转电压与 VDD 之间的电压差, 而负电压可以有效地降低单元的翻转电压, 即 WNM 得到显著改善。
图 6 为有辅助与无辅助电路各部分的功耗对比情况。R_w/o 表示有辅助与无辅助的读操作, W_w/o 表示有辅助与无辅助的写操作。实际上, 读操作仅使预充电的位线放电, 因此 R_w 和 R_o 之间的读操作单元的功耗没有显著的差异。在使用NBL辅助的情况下, 该单元的写功耗比未使用NBL 降低约 43%。这是因为 NBL 增加了写速度, 使得 FSBC在两个稳定状态之间切换的时间大大减少, 即减少了 VDD 与 GND 之间切换电流的导通时间, 从而显著地降低用于位单元写操作的写功耗。
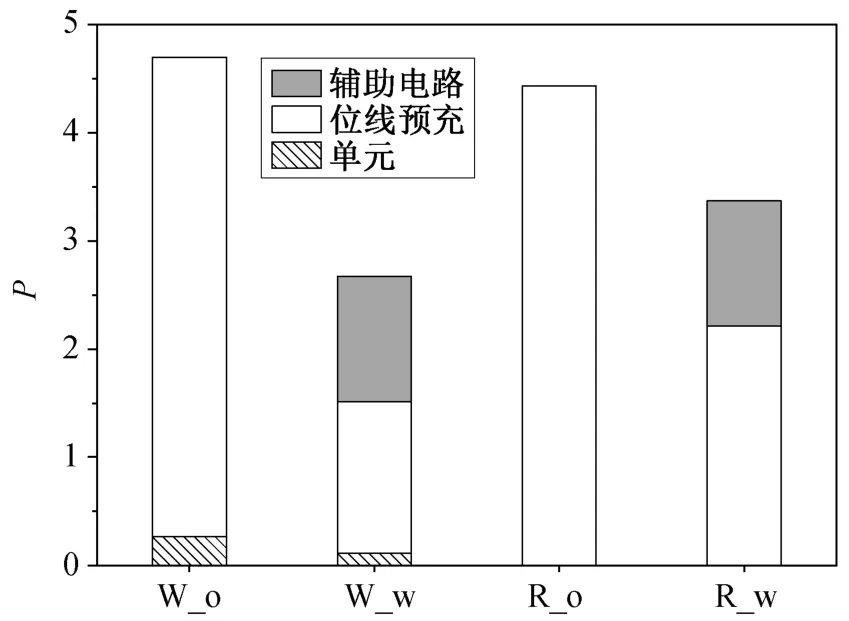
图6 阵列不同部分的能耗对比Fig. 6 Energy consumption comparison of different parts
WL 关闭之后, 通过 CS_cap 与位线之间的的电荷共享, 使位线的电压被上拉, 从而在下一个周期开始时降低预充电功耗。如图 5 所示, 读写周期中的预充电或电压转换功耗分别降低 50%和 68.3%,与预充电功耗的降低相比, 辅助电路的功耗 CRC可以忽略。CRC 电路的功耗主要包括两个电容电压切换的损耗以及电容器电势能的变化(NV_cap 电容器的电荷在第一次开机时要消耗大量电能来完成充电, 以便起到提供稳定负压的作用)。
在常规阵列的读操作中, 从 VDD 获得的功率是用来将位线预充电至 VDD, 单元本身不会消耗太多的能量。并且, 只要 SA 有较好的灵敏度和 PVT包容度, 没有读辅助功能的 SRAM 设计也不需要全幅位线。在常规阵列的写操作中, 根据输入对大扇出位线电压进行切换是写操作的主要动态功耗来源。在本文的阵列中, CRC 用于实现位线从 VDD到 GND 的完全放电, 并通过充电循环, 将其重新充电回 VDD/2。因此, 在这种设计中, 位线与 CRC 之间有相对大量的电荷流动, 与没有辅助的设计相比,本文的设计更容易加热。如图 7 所示, 热功率 heat_pwr 明显大于单纯来自外部电源 vdd_pwr 的功率。

图7 电源的能耗和热功耗的对比Fig. 7 Comparison of power consumption and thermal power consumption
图 8 为具有辅助电路和不具有读操作的位线电压变化的比较。没有辅助电路的位单元的位线电压不能在 300 ps 内降至 0, 而 NVSS 读辅助可改善这一情况。在本设计中, 数据“0”节点的位线可以在读过程中借助 CRC 完全放电, 因此 SA 对 FinFET 的PVT 波动不大敏感。
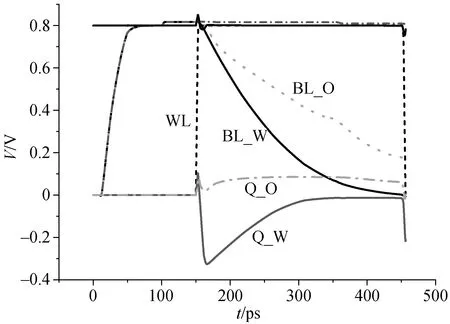
图8 读操作位线在有辅助电路和无辅助电路的波形对比Fig. 8 Voltage waveform comparison of the bit line with and without assist circuit
在每个读写周期结束时, CS_cap 和位线进行由CRC 控制的充电循环, 减少下一个周期中位线的预充电能量。但是, 此过程将需要一定的时间才能完成, 因此结构将占用一个周期中更多的时间, 降低了工作频率。
图 9 为基于不同读写辅助电路的 SRAM 读写功耗对比情况, 各个电路在 1 GHZ 工作频率下的最小工作电压都可以达到 0.6 V。通常写辅助电路会增加SRAM 的写入功耗, 如文献[5–6,8]中的写入功耗分别为不使用辅助电路的 1.59, 1.28 和 1.46 倍, 这是由于文献[5–6]中用于电荷共享的电荷被直接放掉了, 文献[8]中的电荷循环利用率并不高, 并且辅助效果也不理想。本文提出的辅助电路使用额外的电能来改变共享电容的电压状态, 维护电荷循环的稳定性, 并且可以显著地减少位线的状态变化功耗,所以总体功耗比不使用辅助电路的 SRAM 阵列的写功耗更小, 仅为其 58%。
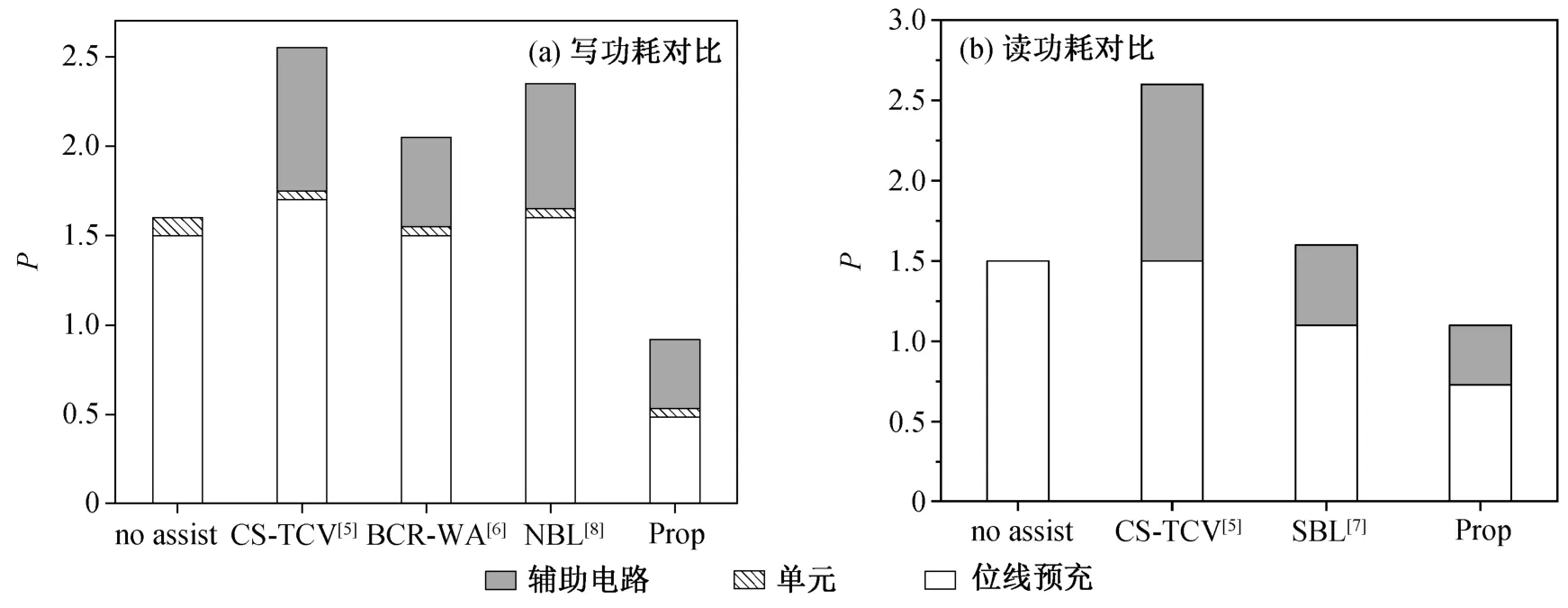
图9 不同辅助电路的能耗对比(工作电压为 0.8 V)Fig. 9 Power consumption comparison of different assist circuits (VDD is 0.8 V)
在一个读周期内, 放电的位线会在周期末充电至高电平, 所以读周期的能耗主要是位线充电的功耗, 与不用辅助电路的 SRAM 相比, 读功耗下降23%。
对 SRAM 来说, 还需要考虑电路的工艺、电压和温度等 PVT 因素对其读写特性的影响, 图 10 为本设计读操作的蒙特卡洛仿真结果, 可以看出, 在不同工艺角和温度下, 在位线电压在辅助电路的帮助下, 300 ps 内可以降至 200 mV 以下, 从而可以使SA 稳定地工作。在 25ºC 和 125ºC 条件下, 位线电压的区别不大, 都可以在 300 ps 内降至 0。因此, 本设计表现出较好的抗 PVT 特性。
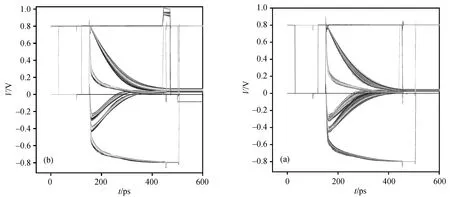
图10 读操作的2000 点Monte Carlo 仿真结果Fig. 10 2000-point Monte Carlo simulation result of read operation
3 结论
本文提出一种具有基于位线电荷循环思想的读写辅助电路的 SRAM 阵列, 旨在获得更低的功耗、更快的读出速度以及更好的 SNM/WNM。基于标准 14 nm spice 模型的 0.8V SRAM 阵列仿真结果显示, 与传统的 SRAM 阵列相比, 辅助电路可以将总功耗降低 23%~43%, 并有效地将 SNM 和 WNM 分别提高 25%和 647.9%。
