面向轻量化网络的改进双通道注意力机制图像分类方法
2021-11-12宋泰年秦伟伟梁卓王魁刘刚
宋泰年 秦伟伟 梁卓 王魁 刘刚

摘 要:为解决弹载终端环境下深度卷积神经网络模型体积较大、 运算硬件要求高的问题, 构建了一种基于改进双通道注意力机制的轻量化网络结构。 针对网络轻量化会牺牲分类准确率的问题, 以轻量化网络结构MobileNetV2为基准网络架构, 引入自主设计的注意力模块, 设计了基于SPP-DCAM模块的MobileNetV2网络架构, 使卷积层学习的显著特征图的权重增加, 以提升其分类准确率; 设计的空间信息与通道信息并联输入, 通过定义1×1和3×3的小卷积在保证结构轻量化的基础上减少了计算量和计算复杂度。 最后, 在cifar-100图像分类数据集进行实验对比。 结果表明: 相对于改进MobileNetV2, 在参数量和计算复杂度基本不变的基础上, 分类精度优于传统的VGG16, ResNet18和DenseNet卷积网络, 综合性能更强, 更适合弹载计算资源有限情况下的快速分类。
关键词: MobileNetV2; 注意力机制; 图像分类; 卷积神经网络; 轻量化网络; 人工智能
中图分类号: TJ760; TP183 文献标识码: A 文章编号: 1673-5048(2021)05-0081-05
0 引 言
近年来, 卷积神经网络发展迅猛, 取得了丰硕的成果。 在军事应用方面, 卷积神经网络被用来识别并检测军事目标, 但是在弹载终端环境中, 对于网络以及硬件的要求较高, 需要网络在保证识别准确率的基础上保持轻量化且嵌入性能好。 随着AlexNet[1]在ImageNet大型数据集上的分类准确率实现质的飞越后, 卷积神经网络朝着复杂化趋势发展, 卷积层数也越来越多。 代表性网络有2014年提出的VGG[2]和GoogLeNet[3], 两者分别增加卷积神经网络的深度和宽度以提升网络性能。 2015年, 何恺明团队创新性地提出ResNet网络[4], 首次引入残差的概念, 利用残差来传递信息, 有效缓解了网络因深度增加而导致的过拟合以及梯度消失问题, 这一网络也为后续轻量化的发展提供了思路。 随后, 研究人员将注意力机制引入卷积神经网络中, 2017年的SENet[5]借鉴注意力机制的思想, 赋予不同特征图以不同的权重, 提升了网络的学习能力。 后来提出的注意力模块都借鉴了这一思想并在SENet的基础上加以改进研究。 如CBAM模块[6]在通道注意力的基础上又对空间注意力加以研究, 使得网络设计趋向于簡单、 快捷、 可移植。 轻量化研究方面的典型网络MobileNetV2[7]在逐点卷积和深度卷积的基础上, 引入倒残差结构和线性瓶颈结构, 使得网络结构大幅减小, 速度也进一步提升。 李慧慧等人将MobileNetV2网络模型与传统的Hough变换相结合, 在识别任务中表现较优, 能够在拥有较低参数量和计算量的情况下提高准确率[8]。 杨国亮等人在MobileNetV2网络的基础上, 借鉴DenseNet密集连接的思想, 利用特征复用的特点, 在提高网络性能的同时缩减网络规模[9]。 毕鹏程等人在MobileNetV2瓶颈层的基础上改进步长模块, 使得网络准确率提升的情况下复杂度和计算量进一步减小[10]。 任坤等人选择MobileNetV2网络作为目标检测的骨干网络, 并引入通道注意力机制, 实现特征增强, 在保证算法轻量化的同时有效提升网络的检测性能[11]。
本文以MobileNetV2轻量化网络为基础, 设计了一种通道空间双协同注意力模块, 通过赋予提取的特征以更大的权重, 在保证网络轻量化的基础上增加其识别准确率。 在cifar-100标准数据集上, 通过对比不同典型卷积神经网络和不同注意力模块来验证网络的有效性。
1 MobileNetV2网络及注意力机制介绍
1.1 MobileNetV2网络
随着卷积神经网络的飞速发展, 其结构越来越复杂, 体积越来越大, 计算量也日益变大, 对硬件资源的需求逐渐变多。 在资源受限的平台上无法部署训练, 所以研究方向为轻量化、 高速化[12]。 一种方法是将训练好的网络进行压缩, 得到相对小的模型; 另一种方法是设计小型模型进行训练, 而MobileNetV2网络就是具有代表性的轻量型网络。
航空兵器 2021年第28卷第5期
宋泰年, 等: 面向轻量化网络的改进双通道注意力机制图像分类方法
MobileNetV2在网络中引入了倒残差结构和线性瓶颈结构。 传统的残差结构是先降低维度再将其升高, 而倒残差结构采用相反的顺序, 先利用一层1×1的逐点卷积提升维度, 再利用3×3的深度卷积来代替3×3标准卷积, 能够将计算量大幅降低, 进而提升网络模型的效果。 线性瓶颈结构是设计1×1逐点卷积降低维度并同输入相加, 去除最后一层的激活函数ReLU, 用线性激活函数来替代, 以改进信息损失严重的问题。 此外, 在网络中引入了扩张系数用于控制网络的大小。 其瓶颈结构如图1所示。
表1为图1中瓶颈图上每一层的输入输出关系, 其中: k为输入通道数; h, w分别为输入的高和宽; s为步长; t为扩张系数; k′ 为输出通道数。
1.2 注意力机制
当增加深度和宽度在卷积神经网络中的改进效果已经不明显时, 研究者们把研究方向放在注意力机制上。 注意力机制首先应用于自然语言处理中。 在图像分类中, 注意力机制通过增加部分特征图的权重, 让卷积神经网络选择性地重视一些特征图, 抑制一些特征图。 目前, 在这方面已经开展大量研究。 SENet注意力设计了一种通道模块, 引入压缩和激励两个过程, 利用全局平均池化将空间压缩为1×1×C的特征图, 再经过两个全连接层对不同特征图赋予不同权重。 CBAM模块在通道注意力的基础上关注了空间注意力, 在通道和空间注意力上利用全局平均池化和全局最大池化进行权重重置, 结果证明比单通道注意力机制效果更好。 除此之外, CBAM还探索了通道空间注意力的排列顺序对分类效果的影响。 最近提出的ECANet模块[13]在SENet模块的基础上, 避免了通道维度的降低, 同时通过增加一维卷积的数量, 实现了局部跨信道交互的覆盖率, 分类准确率有一定提升。
2 基于SPP-DCAM模块的MobileNetV2网络架构
2.1 改进的网络结构
针对弹载终端环境下对于深度卷积神经网络轻量化和准确率两方面的要求, 以MobileNetV2为基准, 在保证其轻量化的基础上加入自主设计的注意力机制结构来提升网络的分类准确率。 在通道注意力及空间注意力的设计过程中, 采用小卷积块来保证网络对于计算量的要求, 并且设计不同尺寸的卷积块来提取特征图的多尺度信息, 设计空洞率不同的卷积块使网络注意全局特征, 将设计好的注意力模块加入MobileNetV2网络结构中。
本文提出了一种新的通道和空间注意力模块SPP-DCAM, 其构成如图2所示。 首先, 输入卷积层提取的特征图, 并行进入通道和空间模块; 然后, 在通道注意力模块里经过空间金字塔池化层[14], 提取多尺度语义信息, 进入多层感知机, 在激活函数的作用下, 得到重新分配权重后的特征图; 在空间注意力模块中, 设计不同尺度的空洞卷积增大感受野, 得到语义全面的空间特征图; 最后, 将两个模块生成的特征图融合生成提取特征图。
由于MobileNetV2引入倒残差结构和线性瓶颈结构, 使其计算量大大降低。 本文引入自主设计的注意力模块来提升其分类准确率。 改进后的网络结构如表2所示。 将设计好的注意力模块融入网络结构的第3, 5, 6, 7层, 在保证网络尺寸及计算量不改变的基础上增加识别准确率。
2.2 通道注意力增强模块
通道注意力如图3所示, 当输入的特征图为XK∈RH×W×C 时, 经过空间金字塔池化对全局信息在空间维度进行H×W压缩, 压缩为1×1×C的通道特征图, 映射生成相对应的权重信息。 空间金字塔结构自适应平均地将输入特征图存入3个尺度。 将3个通道的输出重新调整为3个1维向量, 融合后生成1维注意图。
在空间金字塔池化层中提取1维注意力图之后, 为了赋予不同通道以不同权重。 在后面接两个全连接层, 采用sigmoid函数将输出归一化到(0, 1)的范围。 经过SPP池化层和两个全连接层后的输出为
M~=sig(W2ρ(W1M)) (1)
式中: M~为经过SPP池化层和两个全连接层后的输出; W1和W2分别为第1层和第2层全连接层; M代表经过SPP层后生成的1维特征图; ρ 表示ReLU函数出; sig ()为sigmoid函数。
空间通道注意力机制的输出为
XK=XK M~ (2)
SPP本质上是多个平均池化层, 对于不同尺寸的a×a的特征图, 通过调整滑窗大小及步长, 生成固定大小的输出n×n。 如图4中由3个平均池化层组成, 对于任意大小的输入, 提取4×4, 2×2, 1×1的特征向量, 经过特征融合统一输出21维的特征向量。 使输入图像的尺寸在不会受到限制的同时又能提取多尺度的语义特征。
2.3 空间注意力增强模块
为了在增加感受野的基础上, 突出显著空间特征, 抑制不重要的特征, 提升网络的分类准确率, 设计了空间信息与通道信息并联输入, 空间注意力模块是由2个3×3的空洞卷积和2个1×1卷积组成。
其中, 空间注意力模块如图5所示。 首先, 特征图在经过压缩后分别经过2个空洞率为2和3的空洞卷积层,
最后经过压缩生成1维特征图。 选择2个空洞卷积层的原因是尽可能增大感受野, 但如果仅选择空洞率大的卷积块, 会出现特征语义在空间上不连续、 提取的特征过于分散的情况, 导致分类准确率不增反降。 因而, 选择空洞率为2和3的2个尺寸为3×3的空洞卷积块, 经过叠加后可以增加感受野大小, 也能提取到连续的特征语义。 2个空洞卷积实际感受野的大小为
Fi+1=Fi+(K-1)×Si (3)
式中: Fi+1 为当前层的感受野; Fi 为上一层的感受野; Si 为之前所有层的步长的乘积(不包括本层); K为卷积核的大小。 经计算可得实际感受野大小为12×12, 用 f 12×12表示。 空间注意力模块的输出为
X″K=XK V~ (4)
式中: V~=( f12×12(Aavg ))avg为经过空洞卷积之后生成的注意力图,
Aavg为输入特征图经过1×1卷积后的输出。
3 实验与分析
本文算法的驗证平台是戴尔R740服务器, 深度学习框架采用pytorch, 验证环境为pycharm+anaconda。
利用的数据集为cifar-100基准数据集, 此数据集被广泛应用在分类算法中以验证算法的有效性。 数据集中有60 000张尺寸为32×32的彩色图片, 分为100类, 每类包含600张图片, 这100类从属于20个超类。 其中, 50 000张用来训练, 10 000张用来测试。 试验参数设置为: 优化算法选择梯度下降法; 批大小为512; 学习初始率为0.1; 训练批次设定为100; 动量设定为0.9; 迭代次数设定为300; 权重衰减为0.000 5。
3.1 与不同卷积神经网络的对比
为验证设计的网络性能, 将提出的基于SPP-DCAM模块的MobileNetV2(SPP-DCAM- MobileNetV2)与不同的经典卷积神经网络进行对比。 试验选取典型的神经网络, 分别为代表增加深度以提升分类效果的VGG16典型网络; 代表残差网络的ResNet18典型网络; 代表稠密连接网络的DenseNet[15]卷积网络。 分类效果及提升效果如表3所示。
由表3可知, 所提出的SPP-DCAM- MobileNetV2卷积神经网络在分类效果上取得良好效果, 准确率有大幅度提升。 在4种网络中平均提升幅度为0.995%。
3.2 与不同注意力模块的对比
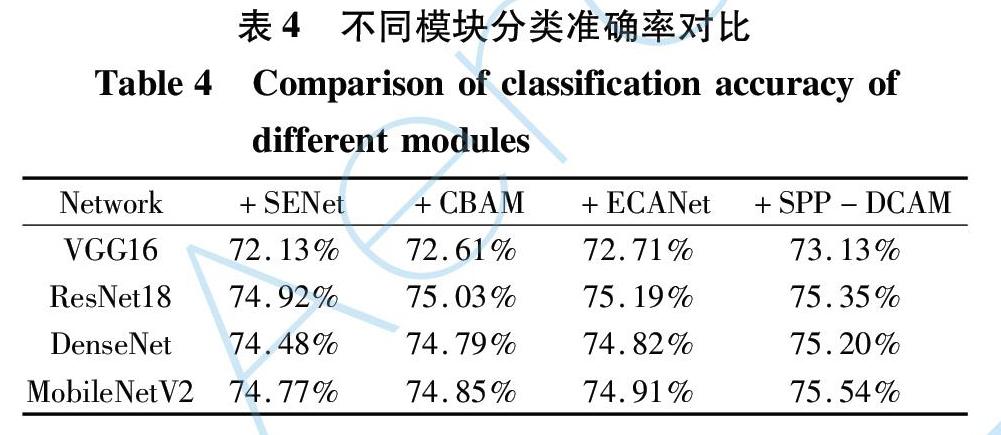
通过对比在图像分类方面取得优秀成绩的SENet和CBAM注意力模块, 以及最近提出的ECANet模块来检验本文算法的有效性和改进效果。 分类准确率如表4所示。
由表4可知, 在不同卷积神经网络中, 双注意力机制的CBAM模块的分类效果要好于单注意力的SENet注意力模块, 最新提出的ECANet模块的分类准确率高于CBAM模块, 而本文提出的SPP-DCAM又比ECANet模块分类效果更好。
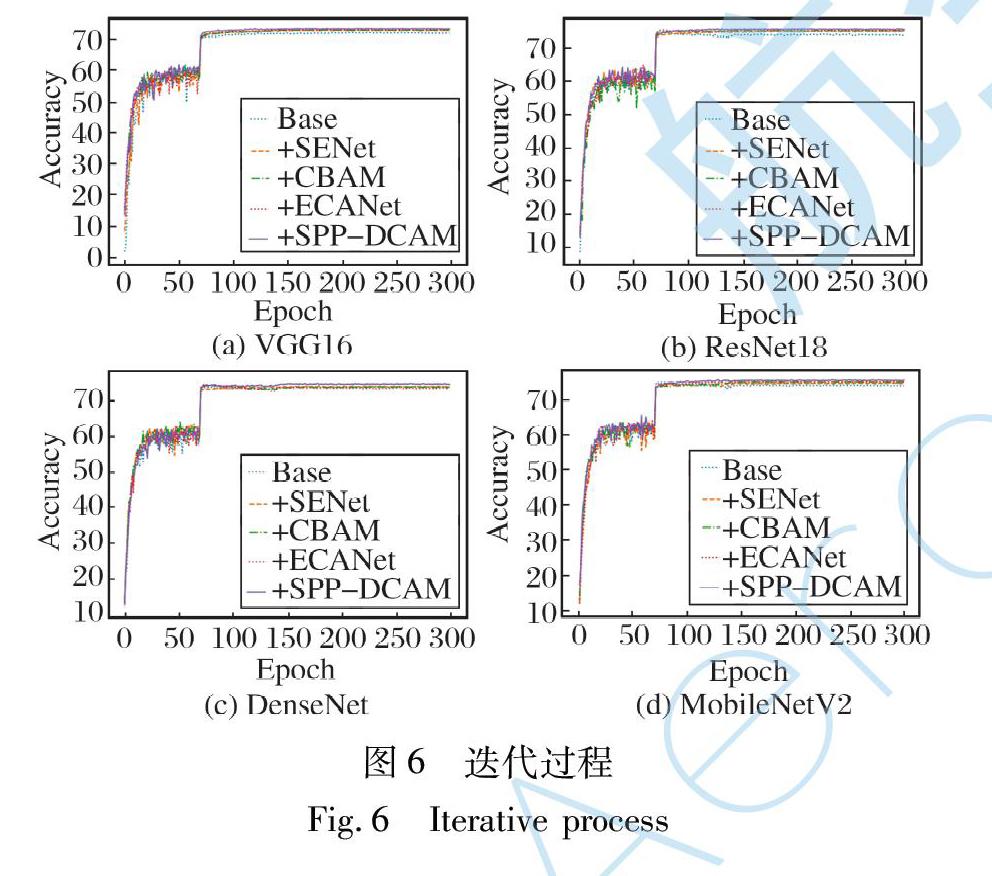
在300次迭代过程中, 4种注意力模块在4种卷积神经网络中的准确率变化如图6所示。 可以看出, SPP-DCAM模块在迭代过程中优于其他模块。
综合数据分析, 证明了SPP-DCAM-MobileNetV2卷积神经网络的有效性和优越性, 特别是在分类准确率上有了较大提升。 其主要原因包括两个方面: 一是通道注意力打破了全局平均池化和全局最大池化的束缚, 将SPP引入了模块, 提取的特征层次性更强, 权重分配更加合理, 特征表征能力优化明显; 二是在空间注意力中设计了空洞卷积, 合理选择了池化块大小和空洞率大小。 相比于传统的空间注意力模块, SPP-DCAM能够增大感受野, 提取范围进一步扩大并且兼顾语义连续性的问题, 达到了一个很好的动态平衡, 提取的显著特征图更加合理。 两方面的优化效果叠加使得本文提出的网络的分类准确率提升明显。
3.3 算法复杂度对比
为进一步检验本文算法在轻量化网络方面的优势, 将所提出的网络结构在cifar-100数据集上进行参数量和计算复杂度对比, 结果如表5所示。 可以看到, 在增加了注意力模块的情况下, 既能够提高分类准确率, 同时也能够保证网络参数量以及计算复杂度变化较小, 使网络保持轻量化。
参考文献:
[1] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[2] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[EB/OL]. (2015-04-10)[2020-12-20].https:∥arxiv.org/pdf/1409.1556.pdf.
[3] Szegedy C, Liu W, Jia Y Q, et al. Going Deeper with Convolutions[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 1-9.
[4] He K M, Zhang X Y, Ren S Q, et al. Deep Residual Learning for Image Recognition[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 770-778.
[5] Hu J, Shen L, Albanie S, et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023.
[6] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]∥ European Conference on Computer Vision, 2018: 3-19.
[7] Sandler M, Howard A, Zhu M L, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[J]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520.
[8] 李慧慧, 閆坤, 张李轩, 等. 基于MobileNetV2的圆形指针式仪表识别系统[J]. 计算机应用, 2021, 41(4): 1214-1220.
Li Huihui, Yan Kun, Zhang Lixuan, et al. Circular Pointer Instrument Recognition System Based on MobileNetV2[J]. Journal of Computer Applications, 2021, 41(4): 1214-1220. (in Chinese)
[9] 杨国亮, 李放, 朱晨, 等. 改进MobileNetV2网络在遥感影像场景分类中的应用[J]. 遥感信息, 2020, 35(1): 1-8.
Yang Guoliang, Li Fang, Zhu Chen, et al. Application of Improved MobileNetV2 Network in Remote Sensing Image Classification[J]. Remote Sensing Information, 2020, 35(1): 1-8.(in Chinese)
[10] 畢鹏程, 罗健欣, 陈卫卫, 等. 面向移动端的轻量化卷积神经网络结构[J]. 信息技术与网络安全, 2019, 38(9): 24-29.
Bi Pengcheng, Luo Jianxin, Chen Weiwei, et al. Lightweight Convolutional Neural Network Structure for Mobile[J]. Information Technology and Network Security, 2019, 38(9): 24-29.(in Chinese)
[11] 任坤, 黄泷, 范春奇, 等. 基于多尺度像素特征融合的实时小交通标志检测算法[J]. 信号处理, 2020, 36(9): 1457-1463.
Ren Kun, Huang Long, Fan Chunqi, et al. Real-Time Small Traffic Sign Detection Algorithm Based on Multi-Scale Pixel Feature Fusion[J]. Journal of Signal Processing, 2020, 36(9): 1457-1463.(in Chinese)
[12] 崔洲涓, 安军社, 张羽丰, 等. 面向无人机的轻量级Siamese注意力网络目标跟踪[J]. 光学学报, 2020, 40(19): 132-144.
Cui Zhoujuan, An Junshe, Zhang Yufeng, et al. Light-Weight Siamese Attention Network Object Tracking for Unmanned Aerial Vehicle[J]. Acta Optica Sinica, 2020, 40(19): 132-144.(in Chinese)
[13] Wang Q L, Wu B G, Zhu P F, et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 11531-11539.
[14] He K M, Zhang X Y, Ren S Q, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[15] Huang G, Liu Z, van der Maaten L, et al. Densely Connected Convolutional Networks[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 2261-2269.
Improved Dual-Channel Attention Mechanism Image
Classification Method for Lightweight Network
Song Tainian1, Qin Weiwei1*, Liang Zhuo2, Wang Kui1, Liu Gang1
(1. Rocket Force University of Engineering, Xian 710025, China;
2. China Academy of Launch Vehicle Technology, Beijing 100076, China)
Abstract: In order to solve the problems of large volume and high hardware requirements of deep convolutional neural network model in missile-borne terminal environment, a lightweight network structure based on improved dual-channel attention mechanism is constructed. Aiming at the problem that the network lightweight will sacrifice the classification accuracy, taking the MobileNetV2 lightweight network as the network basic structure, the self-designed attention module is introduced, and the MobileNetV2 network architecture based on SPP-DCAM module is designed to increase the weight of the significant feature map of convolutional layer learning, so as to improve the classification accuracy. The designed spatial information is input in parallel with channel information. By defining 1×1 and 3×3 small convolution, the computation amount and computational complexity are reduced on the basis of ensuring the lightweight of the structure. Finally, an experimental comparison is conducted on the cifar-100 image classification dataset. The results show that the classification accuracy of
improved MobileNetV2 is better than that of the traditional VGG16, ResNet18 and DenseNet convoluted networks with the same number of parameters and computational complexity, and the comprehensive performance is stronger, which is more suitable for rapid classification under the condition of limited onboard computational resources.
Key words: MobileNetV2; attention mechanism; image classification; convolutional neural network; lightweight network; artificial intelligence
