基于多粒度信息的中医文本关系抽取的研究
2021-11-08王亚文王培卢苗苗
王亚文 王培 卢苗苗
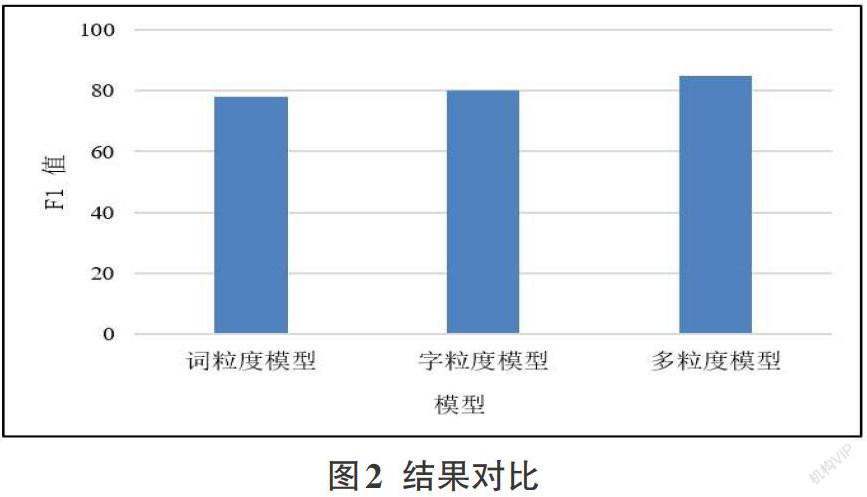

摘要:中医领域知识主要是以文本的形式存在,具有无规律的语言特性,中医知识的有效挖掘对充分利用文本中蕴藏的经验知识具有重要作用,信息抽取任务是中医知识管理的重要子任务,而关系抽取又是信息抽取任务中的重要环节。针对单粒度信息关系抽取方法中存在的句意传递错误和文本语义丢失的问题,提出将句子中的多粒度信息应用于中医文本关系抽取任务,构建多粒度信息抽取模型,将词语级信息整合到字符序列中,多种粒度的文本信息可以为模型提供更多的知识引导,更全面的挖掘语义特征。实验结果证明,此方法能够更加精确的抽取中医文本关系,使模型具有更好的鲁棒性,基本不受噪声的影响。
关键词:多粒度信息;关系抽取;深度学习;中医文本
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2021)27-0015-02
1引言
中医知识包含了中华民族千百年来在和疾病斗争中总结的丰富诊疗经验,在长期发展的过程中也形成了一种独特的诊疗体系,留下了大量对现代疾病诊断具有重要指导价值的文献资料。然而,中医文本信息尚未得到有效利用,关系抽取[1]技术是有效利用中医文本信息的关键技术之一,目的是提取中医文本实体对之间的语义关系[2]。例如:“若兼有气虚者,身倦乏力,少气自汗宜加黄芪,并加以重用,以补气行血”,这句中的“黄芪”和“气虚”是“治疗”的关系。
随着深度学习[3]的不断发展,以其自动提取特征的优势被更多地应用在关系抽取任务中[4]。目前大多数的关系抽取模型是基于字粒度或者基于词粒度的单一粒度进行抽取。基于字符的关系抽取将每个输入语句视为一个字符序列。这种方法不能充分利用词语级信息,捕获的句子特征较少,字符、语法和语义之间的关系较为松散,无法完整的表达出句子语义,比如“羌活”这个词如果拆成字粒度就成了“羌”和“活”,这两个字的单独含义明显与它们组合起来的词的含义大相径庭。所以利用字粒度信息捕获的句子特征比较少,存在“文本语义丢失”的问题,完全依赖字符进行关系抽取效果不佳。基于词粒度的关系抽取模型,首先要进行分词,然后推导出单词序列,再将每个词语表示为词向量,输入到神经网络模型中,利用词粒度信息容易引入词语分割错误带来的“句意错误传播”问题。例如给定中医句子:“酒黄疸,心中懊或热甚而痛,栀子大黄汤主之,盖为实热之邪立法也”。句中黄疸和大黄是治疗关系,但是经过分词操作之后“栀子大黄汤主之”被分为“栀子”“大”“黄汤”和“主之”,分完词之后没有得到“大黄”这个词。
因此,基于单粒度信息的抽取方法会存在“文本语义丢失”和“句意传递错误”的问题。本文结合字符粒度信息与词粒度信息的优点,使用多粒度信息[5]对中医文本进行特征学习,既利用了字粒度模型参数少和不依赖分词算法的优点,解决句意传递错误的问题,同时利用了词语中包含的词法、句法和语义等信息,捕获更多的文本语义特征,解决文本语义丢失的问题。两种粒度方法互为补充,提升了中医文本关系抽取的效率。
2 多粒度关系抽取模型
对于基于字符级信息和词语级信息训练的模型存在文本实体分割错误问题,不能够充分利用句子的语义特征,限制了模型挖掘深层语义特征的能力。本文利用多种文本粒度的,为模型提供更多的知识引导,从而获取句子更充分地語义信息,模型具有更好的鲁棒性,基本不受噪声的影响。多粒度关系抽取模型是在基于字符的双向长短期记忆网络[6](Bidirectional long short-term memory network,Bi-LSTM)的结构基础上增加了词粒度信息流,利用门结构控制信息的嵌入。模型结构如图1所示。
基于多粒度信息的中医文本关系抽取模型分为四层,分别是嵌入层、编码层、注意力层和分类层。
2.1嵌入层
由于神经网络的输入是数值类型数据,所以在对文本编码之前需要将中医文本数据转换为数值数据表示。本文的多粒度信息包括字粒度信息和词粒度信息,同时利用位置信息,因此在嵌入层需要将字符、词语和相对位置信息进行向量化表示。
(1)字词嵌入
在通过神经网络处理之前将预处理之后的中医文本进行向量化表示,本文采用的是word2vec技术把文本中包含的字符和词语分别映射成具有一定维度的实值向量,很好地表达了字和词语的语义依赖关系。嵌入层中的[l]表示字符和[w]表示词语分别映射为字向量[dl]和词向量[dw]。
(2)位置嵌入
关系抽取是预测句子中两个实体存在的关系,一般距离实体对越近的字隐含表达实体对的关系的贡献越大。句子的每个字符都有两个位置信息,分别代表与头实体和尾实体的相对距离,例如给定中医句子“若兼阳分气虚,而脉微神困,懒言多汗者,必加人参”。此句子的头实体是“脉微”,尾实体是“人参”,字“加”与头实体的相对距离为10,与尾实体的相对距离是0。
2.2编码层
本文使用基于网格结构的双向长短时记忆网络(Lattice BiLSTM)作为编码器,该模型是基于字符的双向长短期记忆神经网络(BiLSTM),将字符作为直接输入,即将每个输入句子作为字符序列,不同点在于增加了词粒度信息流,在字符输入的同时嵌入词语信息,利用句子中包含的多种粒度信息。模型编码层中[x]表示编码层的输入,[h]表示正向隐藏层,[h]表示逆向隐藏层,[h]表示汇总隐藏层。隐藏层计算如下公式所示,[hci]表示第i个隐藏单元状态。
2.3注意力层
在实际应用场景中,句子中有些字符对预测两个实体关系具有更加重要的地位。例如给定中医句子“黄疸腹满,小便不利而赤,自汗出,此为表和里实,当下之,宜大黄硝石汤”,在预测“黄疸”与“大黄”之间的关系时,字“宜”比其他字对关系预测的贡献更大。为了使模型能够获得对关系抽取贡献较大的特征,本文通过给句子中的每个字分配权重,增强句子的局部特征。
