基于EEMD-CS-LSSVM的短期负荷预测方法研究
2021-10-22雷炳银王子驰苏雨晴孙炜哲杨灵艺
雷炳银,王子驰,苏雨晴,孙炜哲,杨灵艺
(平高集团有限公司,平顶山 467000)
电力系统运行的一个重要方面是系统性能满足负荷要求[1]。负荷供需平衡是电力系统稳定运行的基本要求,精确的负荷预测对保证电力系统经济、安全、可靠运行起着至关重要的作用[2-3]。
针对短期负荷预测的研究,国内外学者提出了许多行之有效的方法[4],可概括为3类。第1类是基于数学统计的建模预测方法,例如线性回归法[5]和时间序列建模方法,此类方法具有模型简单、计算速度快、易于释因等优点,但在处理非线性数据时对数据稳定性要求高,预测精度变低。第2类是基于机器学习的预测方法,包括人工神经网络、强化学习和支持向量机SVM(support vector machine)[6-7]等,此类方法可构建复杂非线性高维模型,在非线性系统分析方面具有优越性。文献[8]在深度学习框架中构建了长短期记忆神经网络来预测电力负荷。最小二乘支持向量回归机LSSVM(least squares support vector machine)是SVM的改进体,主要通过任意的精度对非线性系统拟合,在非线性建模和预测方面具有优势[9]。第3类是组合预测方法,此类方法针对电力负荷预测面临的多重问题,分别将具有针对性的预测模型进行组合以提升预测精度。针对电力负荷强非线性与波动性特征,直接利用负荷历史数据进行训练与预测,难以实现高精度预测。因此文献[10]提出EEMD-GRU-MLR组合预测方法,采用集合经验模式分解EEMD(ensem⁃ble empirical mode decomposition)方法分解原始负荷序列;高频分量利用门控循环单元GRU(gated re⁃current unit)神经网络进行训练预测,网络输入为预测时刻前24 h内(每0.5 h)的负荷高频分量值,每次输出1个预测值,即该预测时刻(0.5 h)的负荷高频分量值;低频分量采用多元线性回归MLR(multiple linear regression)进行预测,但该方法未针对预测模型的关键参数进行优化。文献[11]提出一种脉冲神经网络预测模型,有效提高了预测精度。
现有研究表明LSSVM在解决非线性系统建模方面具有优势[6],但由于电力负荷序列含有多种频率特征,现有研究在LSSVM预测模型中难以选取同时适用于所有频率特征的核函数,同时也缺少针对LSSVM关键参数的优化配置,LSSVM预测精度恰受核函数类型和关键参数配置影响较大。因此,本文首先采用EEMD将负荷序列分解为高频分量、随机分量和低频分量3类,进而采用具有不同核函数的LSSVM模型进行训练和预测,同时利用布谷鸟搜索CS(cuckoo search)算法优化LSS⁃VM预测模型的关键参数,最后通过算例验证本文所提方法能有效提高短期电力负荷的预测精度。
1 基于EEMD-CS-LSSVM预测方法
1.1 EEMD-CS-LSSVM预测流程
本文提出的EEMD-CS-LSSVM预测方法流程如图1所示。电力负荷历史数据进行EEMD,将电力负荷数据的各分量分别进行归一化处理并输入到具有不同核函数特征的LSSVM网络进行训练,同时利用CS算法进行LSSVM参数寻优,最后将各个LSSVM预测分量进行叠加得出最终预测值,具体方法如下。
步骤1对电力负荷历史数据进行EEMD,依据文献[10]提出的过零率指标,将分解后的各分量定义为高频分量、随机分量和低频分量3类。
步骤2对电力负荷各分量及温度分别进行归一化处理。利用已有历史数据计算电力负荷分量与天气状态、温度、湿度的皮尔逊相关系数,其中,温度的相关系数超过0.8视为强相关关系,因而选用温度作为电力负荷预测变量。
步骤3将归一化的电力负荷高频分量和随机分量及温度变量输入到具有径向基函数RBF(radi⁃al basis function)核函数的LSSVM中进行训练;低频分量和温度数据输入到具有线性核函数的LSSVM网络中训练。
步骤4利用CS算法分别对各分量的LSSVM预测模型关键参数进行优化,获得最优参数配置。
步骤5将经CS训练的LSSVM预测模型用于电力负荷各分量预测,并输出各分量的预测值。
步骤6将所有LSSVM模型预测的分量值叠加,还原得到电力负荷预测值。
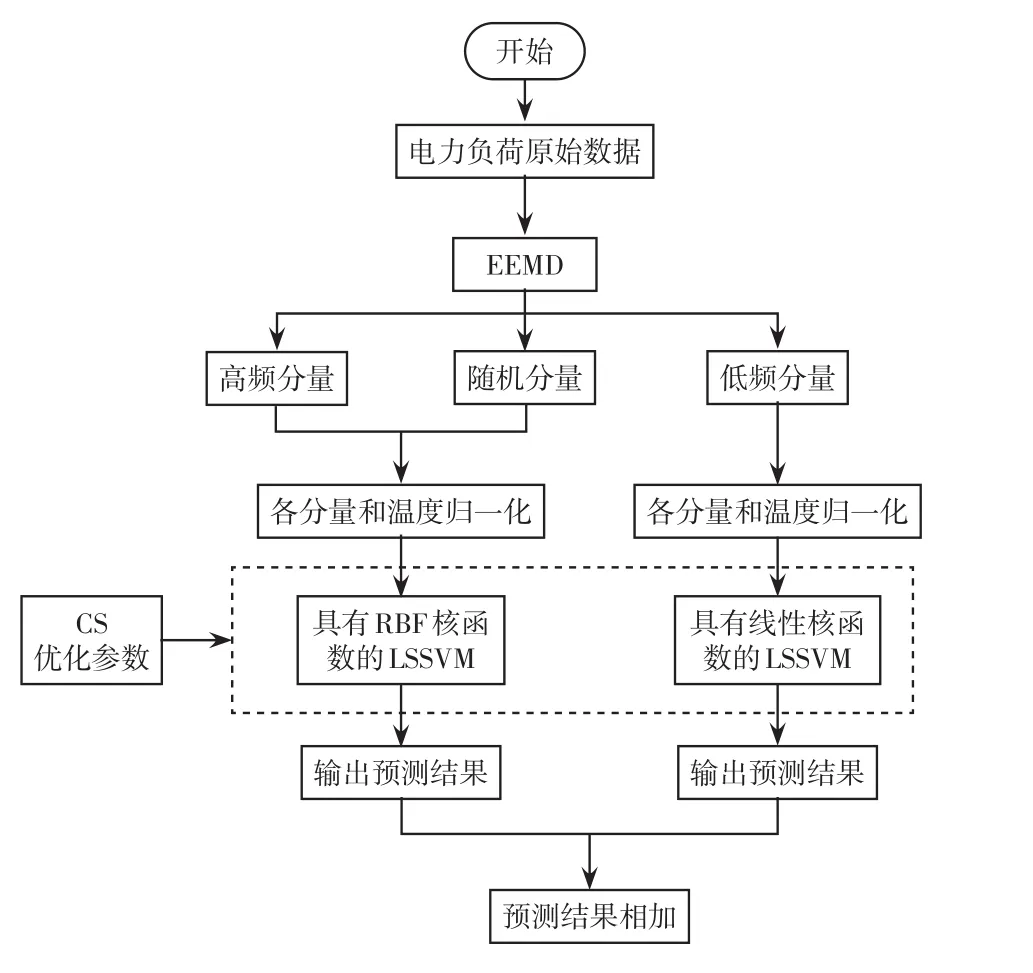
图1 EEMD-CS-LSSVM流程Fig.1 Flow chart of EEMD-CS-LSSVM
1.2 集合经验模态分解算法
经验模态分解法EMD(empirical mode decom⁃position)作为一种基于自适应正交基的时频信号处理方法,可直接分解非线性平稳时间序列,减少了复杂的信号分析过程。但当实际信号中存在间歇性信号时,EMD会导致模式混叠现象,即1个固有模态函数IMF(inherent modal function)分量中存在多个尺度分量,或者多个IMF分量中存在1个尺度分量,使得各IMF的代表性不够清晰。EEMD通过加入白噪声,改变极值点结构,获得满足要求的信号特征,解决了EMD混叠问题[12]。具体方法如下。
步骤1将n组符号相反的噪声信号加到原信号上,即

式中:x(t)为原始信号;n+i(t)为正噪声;ni(t)为负噪声;分别为正、负模态函数。
步骤2具有正、负噪声的模态函数被含噪声的经验模态分解成多个分量。
步骤3利用EEMD得到第j阶IMF分量,即

1.3 LSSVM算法
LSSVM为支持向量机的扩展,基本原理是将非线性函数把数据映射到高维空间[13-14]后,再进行线性回归,其回归函数为

式中:ω为权值向量;b为偏置值;x为输入值;φ()为映射函数。
通过结构风险最小化原则,寻优目标函数为
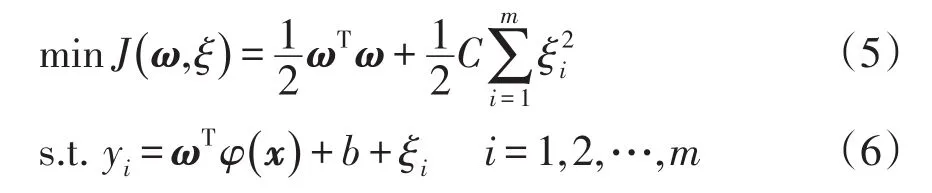
式中:yi为第i个输出值;C为误差惩罚系数;ξi为松弛变量。
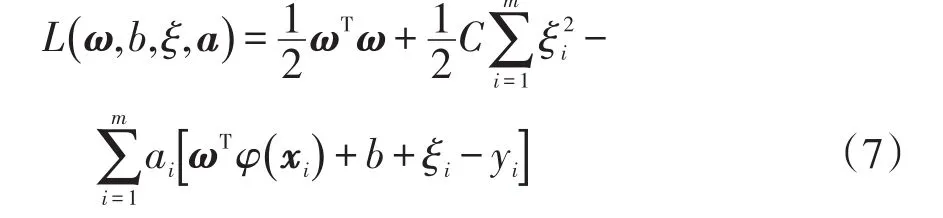
式中:ai为第i维拉格朗日乘数;L为拉格朗日函数;xi为第i个输入值。根据KKT条件可得
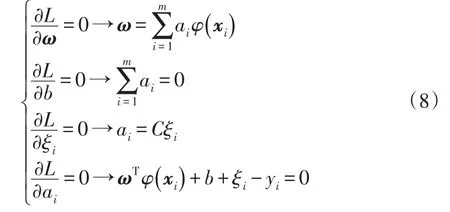
将式(8)消去 ω 和 ξi可得
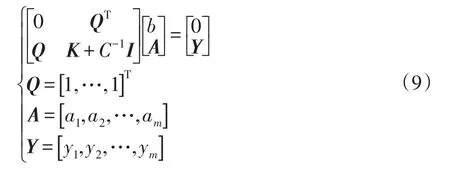
根据Mercer条件可以确定核函数,即

则LSSVM的拟合函数为
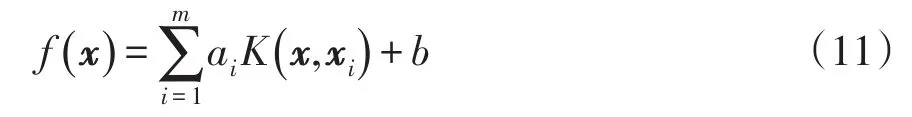
用于电力负荷低频分量预测的线性核函数为

用于电力负荷高频和随机分量预测的RBF核函数为

式中:x和xi分别为m维输入向量和m维第i个径向基函数的中心;‖x-xi‖为x与xi之间的距离,具有范数含义;σ为核函数宽度。
1.4 CS算法寻优LSSVM参数
CS算法属于启发式寻优算法,相关研究验证了该算法比其他群体算法更有效[15]。本文利用CS算法优化LSSVM预测模型的两个关键参数:惩罚系数C与核函数宽度σ。
布谷鸟目标函数定义为
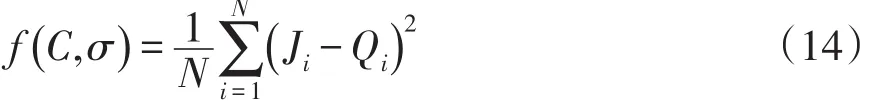
式中:N为样本范围;Ji为真实值;Qi为预测值,由LSSVM拟合函数式(11)计算得到,其值受惩罚系数与核函数宽度的影响。
CS算法具体步骤如下。
步骤1设定CS算法目标函数为式(14),其中,种群规模为N,维数为nd,被宿主鸟发现的最大概率为 pa。
步骤2全局搜索。布谷鸟在迭代前期会进行全局搜索,通过比较目标函数值,保留上一代最优鸟巢方位,并通过下式对鸟巢方位进行更新:
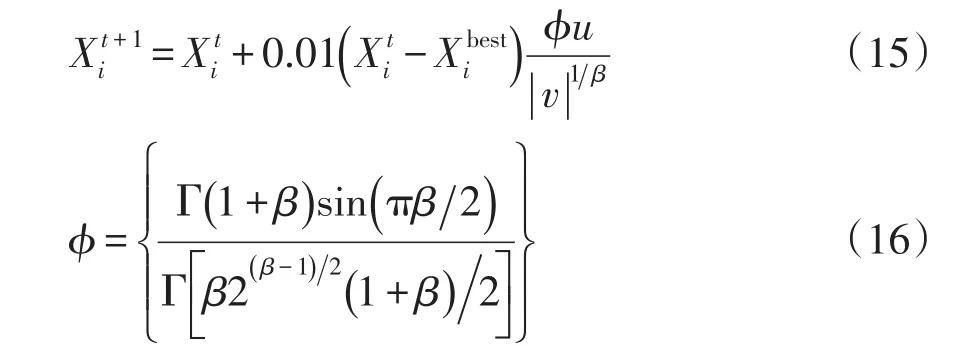
式中:Xit为第i个鸟巢第t代的方位;Xibest为鸟巢第t代最佳方位;为莱维飞行随机搜索路径,其中β=1.5,u服从正态分布;Γ()为伽玛函数。
步骤3局部搜索。利用式(15)调整方位后,每个解产生1个随机数R,R为布谷鸟鸟蛋被宿主鸟发现的概率。将R与 pa比较,若R

式中:R∈[0 , 1];Xjt、Xit为随机鸟窝方位。
步骤4当算法满足收敛精度和收敛条件后,得到适应度最高的LSSVM模型参数。
1.5 数据归一化
由于负荷数据与温度数据的量纲不同,因此分别进行在[0,1]区间内的归一化处理。(1)负荷数据归一化可表示为

式中:xnorm为归一化后电力负荷;xmin和xmax分别为历史电力负荷的最小值和最大值;x为原始电力负荷。
(2)温度归一化可表示为

式中:Tnorm为归一化后的温度;T为原始温度;Tmin和Tmax分别为历史温度的最小值和最大值。
2 算例与误差分析
2.1 算例分析
实测获得河南某地区2018年6月1日—2018年8月29日共计90 d电力负荷数据及温度数据,时间间隔为1 h,共计2 160个数据点。将前89 d数据为训练数据,预测第90 d的电力负荷数据。
电力负荷历史数据如图2所示,可以看出,该负荷具有强烈的非线性特性。因此,本文利用EEMD方法对电力负荷历史序列进行分解,得到电力负荷IMF分量。分解出的电力负荷分量中IMF1~IMF4分量波动周期短、波动频繁,属于高频分量,如图3所示;IMF5和IMF6分量随机性较强,属于随机分量,如图4所示;IMF7、IMF8及余量Res具有一定的周期性和线性特征,属于低频分量,如图5所示。依据各电力负荷分量的不同特征,IMF1~IMF6分量采用基于RBF核函数的LSSVM网络进行预测,RBF核函数如式(13)所示;IMF7、IMF8和Res分量采用基于线性核函数的LSSVM网络进行预测,线性核函数如式(12)所示。
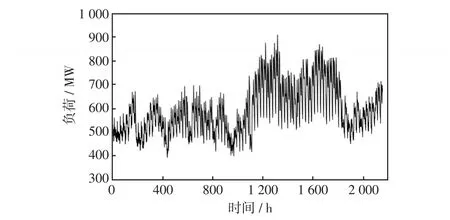
图2 历史负荷数据Fig.2 Historical load data
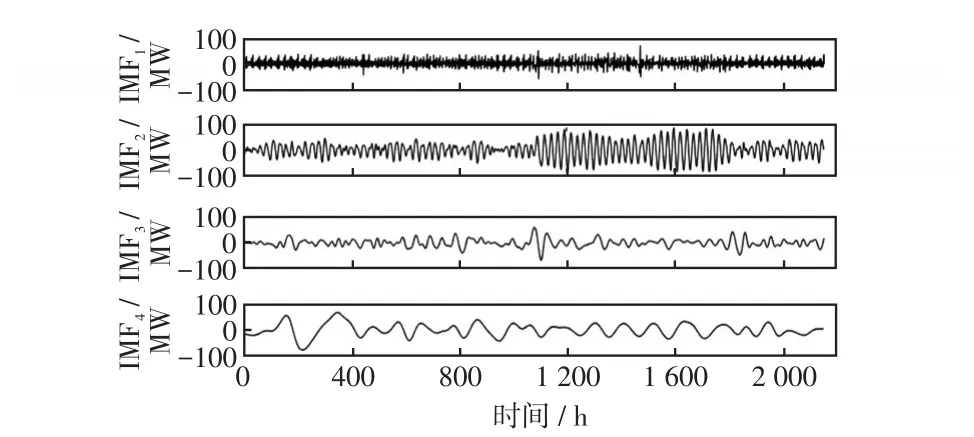
图3 EEMD高频分量Fig.3 High-frequency components obtained by EEMD
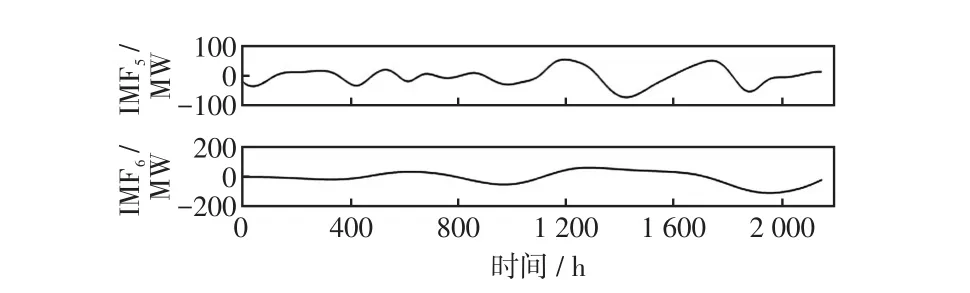
图4 EEMD随机分量Fig.4 Random components obtained by EEMD
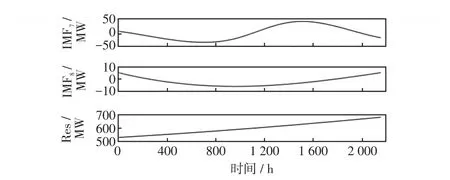
图5 EEMD低频分量Fig.5 Low-frequency components obtained by EEMD
分别应用本文提出的EEMD-CS-LSSVM方法、以及CS-LSSVM、反向传播BP(back propagation)神经网络和差分整合移动平均自回归ARIMA(autore⁃gressive integrated moving average)模型共4种预测方法,对算例地区的电力负荷数据进行预测,得到日内24 h的负荷预测结果,如图6所示。从图6可以看出,4种预测模型都能较好地反映出电力负荷变化趋势。
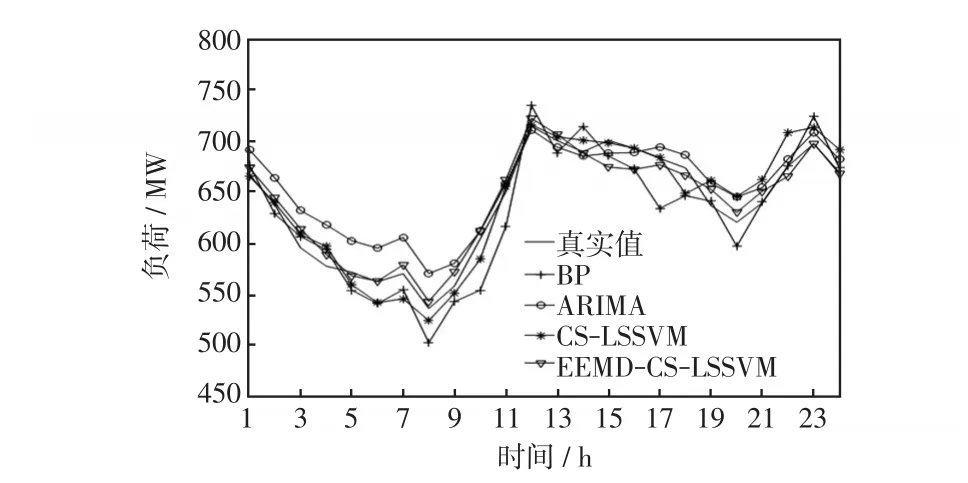
图6 4种模型预测结果Fig.6 Prediction results of four models
2.2 误差评价指标与分析
由于电力负荷具有不确定性和随机性,4种预测方法都无法避免出现误差。本文采用平均绝对百分比误差作为各模型的误差评价指标,即
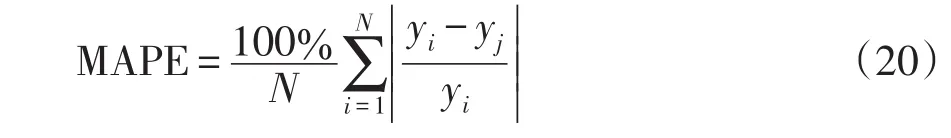
式中:MAPE为平均绝对百分比误差;yi为真实值;yj为预测值;N为预测总数。
4种预测方法的预测误差如表1所示。ARIMA模型的预测误差指标最大,BP神经网络模型较ARIMA下降0.8%,表明针对电力负荷数据的非线性特点BP神经网络预测效果优于ARIMA模型;CS-LSSVM的预测误差指标低于BP神经网络,表明应用CS算法优化预测模型的关键参数可以提高预测精度;而本文提出的EEMD-CS-LSSVM方法相比于CS-LSSVM方法,误差指标进一步下降0.6%,表明针对不同频率特征的电力负荷分量选用具有不同核函数的LSSVM模型进行预测可以进一步提升电力负荷的预测精度。

表1 4种模型预测误差对比Tab.1 Comparison of prediction error among four models
3 结语
电力负荷预测是电网调度人员合理安排发电计划的主要依据,精确的负荷预测可提高调度准确性,进而提高系统运行效率、降低发电成本。由于电力负荷具有非线性及波动特征,为提高短期电力负荷预测精度,本文应用EEMD方法分析了电力负荷在不同频率分量上的波动特征,提出了基于EEMD-CS-LSSVM短期负荷预测方法。本文首先通过EEMD算法把负荷数据进行分解为多个高频分量、随机分量和低频分量,针对负荷分量的波动特点分别采用RBF核函数和线性核函数的LSSVM模型进行电力负荷分量预测。同时采用了CS算法对EEMD-LSSVM预测模型的关键参数进行优化。将本文预测方法与BP神经网络模型、ARIMA模型及CS-LSSVM算法进行对比,误差分析结果显示本文提出的方法具有最小的平均绝对百分比误差。研究表明,针对不同频率特征的电力负荷分量选用具有不同核函数的LSSVM预测模型,以及针对预测模型的关键参数进行优化均可以有效提升电力负荷的预测精度。
