融合多种使用词信息方法的命名实体识别研究
2021-10-19郭鹏刘俊南
郭鹏 刘俊南


摘 要:文章对融合词信息增强中文命名实体识别问题进行了研究,提出一种用于中文命名实体识别的融合词信息神经网络模型系统。首先使用预训练语言模型Bert对字进行编码得到字标识,然后使用SoftLexicon基于统计的方法将词统计语义信息融合进入字表示中,之后使用设计的GraphLexicon根据文本内字、词之间的交互关系图结构,将字词信息表示相互融合,达到较高的命名实体识别准确率。
关键字:中文命名实体识别;图神经网络;融合;词信息;字词交互;图结构
中图分类号:TP183 文献标识码:A 文章编号:2096-4706(2021)06-0025-04
Research on Named Entity Recognition Based on Multiple Words Used
Information Methods
GUO Peng,LIU Junnan
(Innovem Technology (Tianjin)Co.,Ltd.,Tianjin 300384,China)
Abstract:In this paper,the problem of enhancing Chinese named entity recognition by fusing word information is studied,and a neural network model system based on fusing word information for Chinese named entity recognition is proposed. First,the pre training language model Bert is used to encode the character to get the character identification,and then the statistic based approach SoftLexicon is used to fuse the word statistical semantic information into the character representation. Then,according to the structure of the interaction graph between characters and words in the text,the character and word information representation are fused to achieve a high accuracy of named entity recognition.
Keywords:Chinese named entity recognition;graph neural network;fuse;word information;character and word interaction;graph structure
0 引 言
中文命名实体(Named Entity Recognize,NER)[1]识别是指标记识别出输入文本中特定的实体,并确定该识别类型,例如人名,地名,机构名称,手术名称,患病部位等。命名实体识别经常作为其他自然语言处理系统的预处理步骤,例如关系抽取,事件抽取,问答系统等。作为自然语言文本结构化系统的重要部分,为了构建结构化系统,提升中文命名实体识别的准确率是非常重要的。
早期的命名实体识别大多是基于规则的方法,但是由于语言结构本身具有不确定性,制定出统一完整的规则难度较大。现阶段针对命名实体识别问题最有效的方法是机器学习的方法。传统的机器学习的命名实体识别方法大多采用有监督的机器学习模型,如SVM、HMM、CRF等。最近几年深度学习在自然语言处理上得到广泛的应用,如循环神经网络BiLSTM-CRF,卷积循环神经网络BiLSTM-CNN-CRF,图神经网络模型GraphNN以及许多其他方案模型,如将命名实体识别作为问答解决的变体模型。谷歌在2018年发布预训练语言模型BERT[2],将多项自然语言处理任务的结果精度推到了更高的精确度。
相对于英文命名实体识别,中文没有明显的词边界,因此直觉上会认为对于中文自然语言处理只使用字信息就足够完成命名实体识别任务,虽然这样会缺失词信息。然而词信息对于中文命名实体识别乃至其他中文自然語言处理任务都是十分有价值的,例如识别机构名“北京机场”时,如果输入有词“北京”“机场”的边界信息和词信息,会增加机构名的识别概率。
本文结构为:第一章介绍词信息的命名实体识别相关工作,第二章介绍本文设计的模型结构,第三章通过实验对比其他方法模型并进行分析,第四章对本文工作进行总结。
1 相关工作
由于引入词信息可以增强命名实体识别准确率,出现了很多方法将词信息融合到命名实体识别任务中,如:联合学习中文分词(Chinese word segment,CWS)和命名实体识别,但联合学习方法需要词边界标注信息,需要花费大量精力进行额外的分词标注。又如:使用word2vec,word2vec使用大量领域内文本进行训练得到。Word2vec包含了词边界信息和词语义信息。相对于联合方案,word2vec更容易获得,并且不需要额外的分词标注,例如Lattice-LSTM将词信息融合进入LSTM网络结构中,FlatBert将词信息和字信息展平,通过Attention模型进行注意力计算[3]。
然而融合词信息的方法多种多样,怎么有效的融合词信息仍是一个开放挑战,Lattice-LSTM为了融合词信息,会将词作为文本内的子序列,在字序列上为词子序列增加大量额外链接,极大的加剧了训练和推断的时间,并且由于模型的复杂结构,导致该方法无法迁移使用到其他结构中。SoftLexicon通过使用BMES(begin,middle,end,single),在字序列上通过融合词的不同交互位置的统计信息和词语义信息,实现利用词信息。这样的方法使用了很多统计信息,而统计信息随着训练数据量的降低,会降低模型准确率。CGN(Collaborative Graph Network)[4]方法,构建字词的多种不同的邻接图,然后通过图神经网络,将词信息融合进入命名实体识别系统,该方案因为构建了多种图结构,存在多次重复的交互计算,模型计算复杂,没有充分利用图神经网络能力。
本文在CGN模型基础上通过改进其邻接图的设计方法,融合其设计的不同的网络结构,只构建一个邻接图。进一步利用SoftLexicon在领域数据上的词统计信息的使用方法,构建一个多种利用词信息的模型方法。经过在多个数据集上的测试,发现本文设计的方法达到当前最佳模型系统效果。
2 模型结构
本文设计的命名实体识别模型,利用两种使用词信息的方式,在不同角度上将词信息和字词关系融合进入字表示,来增强模型的命名实体识别性能。首先使用Bert[2]预训练模型,对输入字符进行编码得到字表示,然后使用SoftLexicon得到的字对应的BMES词表示,通过拼接方式融合到字表示中。然后改进CGN使用字词交互信息的方式,通过GAT(Graphs Attention[5])层将字词相关矩阵和词信息融合进入字表示中,最后通过CRF层对编码表示进行解码,得到命名实体识别标签序列。记本文设计的模型为Graph+Soft。
接下来,介绍模型详细模块结构,包括编码模块、SoftLexicon词统计信息融合模块和构建字词相关关系图和字词交互图注意力网络模块。
2.1 编码
设输入序列S={c1,c2,…,cn}为输入文本,ci为输入文本序列的第i个字,通过编码器将输入序列编码为特征序列X={x1,x2,…,xn}。
2.2 SoftLexicon
SoftLexicon方法在领域文本内对词典内词进行词频统计,以用作将词表示(word embedding)融合进入字表示的融合权重。首先,获得输入序列的每个字的字表示(char embedding)。然后,构建SoftLexicon特征,并拼接在字表示上,增强字表示。整体结构如图1所示(图中实线框表示字或词,虚线框代表与该字具有BMES交互位置相关的词)。
对词在数据集文本内进行词频统计,z(w)代表词w在数据集中的出现次数。注意,如果w被另外一个词覆盖,则这个样本内w不进行计数。
对每个词ci搜索获得文本内对应的所有匹配词W(ci),然后将W(ci)根据ci在词w中的位置BMES(开始,中间,结束,单个)分成四类,构成四个词序列WB(ci),WM(ci),WE(ci),WS(ci)。
获得BMES序列后,以统计计数作为权重和词表示,每个序列加权平均得到一个新的与字相关的融合表示,eW为词向量表。BMES对应的字相关词信息的计算公式为:
(1)
(2)
将字表示和词统计语义信息在特征维度上进行拼接融合得到新的字表示:
(3)
2.3 GraphLexicon
在使用SoftLexicon方法通过BMES序列强化实体边界和引入词信息后,模型还通过字词相关关系图注意力网络融合字词信息,进一步利用词信息,即将字词信息按照字词间的关系以图方式进行交互,进而实现将字词间关系和词信息融合进入字序列表示。
CGN方法详尽地描述了字词之间的关系,但是由于每种关系分别进行图注意力计算,导致计算冗余,三种关系结果的拼接融合信息利用不充分。
本文设计GraphLexicon模块,修改CGN方法,通过合并多种关系图结构,将字与其所有有关的字和词都构建成为一个统一的相关关系图,然后使用图神经网络通过该相关关系图将字相关的字和词信息融合到字序列中,实现字词相关融合,减少冗余计算,不用拼接融合不同的信息,提升图结构的使用效率,如图2所示。
图2中,字与字之间存在邻接关系,字与词之间存在邻接关系、包含关系、边界关系。这里实线代表字词间的包含关系,虚线代表字词间的邻接关系,词和字边界的关系包含在了包含关系中,输入字序列表示为Xci,长度为N,词序列表示为XWi,长度为M,构建成展平的表示序列F={XC,XW},长度为L=N+M。此时特征序列表示为F={f1,f2,…,fN+M},根据字词相关关系图构建关系矩阵A,如果fi,fj存在關系,则Aij=1否则Aij=0 。
具体计算流程如式(4)~式(9)所示:
fih=Wfi (4)
att1=Repeat(α1fih,n=L,dim=-1) (5)
att2=Repeat(α2fih,n=L,dim=-1) (6)
att=att1+att2 (7)
(8)
(9)
W,α1,α2为可训练参数,W将特征维度Fin变换为Fout,α1,α2将特征加权平均计算得到权值,Repeat()为复制操作,在dim维度上,复制n份。
此时G∈RFOUT×(N+M),保留了融合后的字表示和词表示。通过切片操作最终只保留融合信息后的字表示Q=G[:,0:N]。
至此,将字词相关关系和词表示XW通过字词相关关系Aij融合进入了字表示Xc中,经过一个残差层,强化字表示R=W1Xc+W2Q。
2.4 解码
本文使用标准的CRF层来进行序列标签解码,给定一个句子S={c1,c2,…,cn},CRF层的输入是R={r1,r2,…,rn},真实标签序列为Y={y1,y2,…,yn},其概率为:
(10)
其中,W yi为激发矩阵,T為转移矩阵,使用Viterbi算法进行解码,来获得得分概率最高的标签序列。
3 实验
3.1 实验设置
本文设置使用三个公开的中文命名实体识别数据集进行测试实验,分别是Weibo NER,MSRA NER和Resume NER。其中Weibo是社交领域的命名实体识别数据集,MSRA和Resume都是新闻领域命名实体识别数据集。进行两个对比实验,分别实验本文修改的GraphLexicon和Graph+Soft的准确率和性能。本文在评价模型进行命名实体识别任务的效果时,采取通用的查准率和召回率结合之后的F1值指标,F1值越大,说明模型识别的效果越好。
3.2 实验结果及分析
为了方便对比,由于SoftLexicon和CGN在原论文实现中,没有使用Bert作为字表示的编码器,本文Bert作为编码器重新实现得到SoftLexicon-bert和CGN-bert模型。
GraphLexicon是本文设计修改了CGN的方法,以Bert为编码器。
表1显示了GraphLexicon和本文提出的Graph+Soft在三个数据集上和其他方法的对比结果。在三个数据集上,本文修改的GraphLexicon方法,相对于原始CGN-bert方法F1(%)值都有提升,对应为3.63,0.62,0.08。本文提出的Graph+Soft,对比CGN-bert两个方法F1(%)值分别提升5.03,1.76,0.05(CGN-bert)和4.55,1.90,0.39(SoftLexicon-bert)。结果显示本文修改的GraphLexicon和本文提出的Graph+Soft命名实体识别模型结构,都达到了极高的准确率(为更直观体现对比结果,表1中各项最高值加粗表示)。
表1 GraphLexicon和Graph+Soft与其他方法在NER
数据集上进行的对比实验
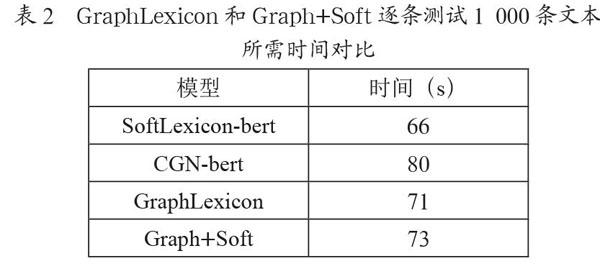
表2GraphLexicon和Graph+Soft逐条测试1 000条文本所需时间对比显示,GraphLexicon相对CGN-bert识别速度提升11.25%。同时对比表1GraphLexicon和Graph+Soft与其他方法在NER数据集上进行的对比实验中CGN-bert和GraphLexicon的实验结果发现,CGN-Bert原始设计的三个邻接矩阵需要对三个不同的字词关系图,进行三次字词图注意力网络计算,耗时较大,并且识别结果交叉,说明计算性能不高,本文修改的使用统一的字词相关关系图进行一次图注意力网络计算,不仅提升了模型准确率,并且提升了模型效率。
表2 GraphLexicon和Graph+Soft逐条测试1 000条文本所需时间对比
4 结 论
在本文工作中,我们为了进一步利用词信息,从两个角度使用词信息融合进入字表示中,并修改了CGN网络方法,提升识别准确率的同时,提升了模型性能。本文提出的模型结构在词信息的利用上简单易用,后续可以轻易扩展到相关的自然语言处理任务上,例如信息抽取、事件抽取等序列标记任务。
参考文献:
[1] DAVID N,SATOSHI S. A survey of named entity recognition and classification [J].Lingvistic Investigationes.International Journal of Linguistics and Language Resources,2007,30(1):3-26.
[2] DEVLIN J,CHANG M,KENTON L,et al. Bert:Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805.
[3] MA R,PENG M,ZHANG Q,WEI Z,et al. Simplify the Usage of Lexicon in Chinese NER [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.2019:5951-5960.
[4] SUI D B,CHEN Y B,LIU K,et al. Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing(EMNLP-IJCNLP).Hong Kong:Association for Computational Linguistics,2019:3830-3840.
[5] VELI?KOVI? P,CUCURULL G,CASANOVA A,et al. Graph Attention Networks [J/OL].arXiv:1710.10903v1 [stat.ML].(2018-02-04).https://arxiv.org/abs/1710.10903v1.
作者简介:郭鹏(1988—),男,汉族,河南信阳人,总工程师,硕士研究生,研究方向:无线通信,人工智能;刘俊南(1990—),男,汉族,天津人,中级软件工程师,本科,研究方向:语音识别,自然语言处理。
