基于自然语言处理的发电设备知识库系统研究
2021-10-19沈铭科程相杰方超丁刚陈家颖
沈铭科 程相杰 方超 丁刚 陈家颖

摘 要:文章设计了一种基于自然语言处理的发电设备知识库系统,包括知识抽取、语料和知识存储、知识问答排序和知识库前端问答等模块,构建过程为:首先进行发电设备领域自然语言处理基础模型训练,再针对领域语料进行知识抽取,最后利用排序模型实现知识问答。对比4种知识抽取方案可得:对于Top1和Top3准确率,知识抽取前处理增加MRC模型比后处理增加MRC校验回路准确率高;对于Top5准确率,后处理中增加MRC校验回路较前处理中增加MRC模型准确率高。
关键词:自然语言处理;发电设备;知识库系统;知识抽取;知识问答
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2021)06-0013-05
Research on Knowledge Base System of Power Generation Equipment Based on Natural Language Processing
SHEN Mingke,CHENG Xiangjie,FANG Chao,DING Gang,CHEN Jiaying
(Shanghai Power Equipment Research Institute Co.,Ltd.,Shanghai 200240,China)
Abstract:This paper designs a knowledge base system for power generation equipment based on natural language processing,which includes knowledge extraction,corpus and knowledge storage,knowledge question and answer sorting,and front-end question and answer of knowledge base and other modules. The construction process is:firstly,performs natural language processing basic model training in the field of power generation equipment;then extracts knowledge from the domain corpus;finally,uses the sorting model to achieve knowledge question and answer. Comparing the four knowledge extraction schemes can be obtained that for the accuracy of Top1 and Top3,the accuracy of adding MRC model in the pre-processing of knowledge extraction is higher than that of adding the MRC verification loop in the post-processing. For Top5 accuracy,adding MRC verification loop in post-processing has a higher accuracy rate than adding MRC model in pre-processing.
Keywords:natural language processing;power generation equipment;knowledge base system;knowledge extraction;knowledge question and answer
0 引 言
在發电机组设备管理过程中,涉及大量自然语言形式承载的不同形式的非结构化文档,如标准规范、设备说明书、作业手册、检修报告、案例总结报告等。这些非结构化文档是发电企业在日常工作中编写、业务专家定期分析汇总的经验性文档,对指导设备管理工作具有重要意义[1,2]。但往往这些宝贵的文档分散存储在企业不同的文档管理系统和办公电脑中,导致技术人员在查阅和分析过程中存在困难。虽然发电企业已经开始应用设备文件管理系统和知识库系统,但大多数的文件系统和知识库系统存在着一些不容忽视的问题,比如无法针对文本内容进行检索或者只能采用关键词检索,缺乏语义层面上的知识问答能力[3,4]。因此随着数据量逐渐增大,在工作中需要检索某个设备相关文件具体的章节、段落或条目时,查询检索依然非常不方便导致工作效率低下,大量的知识经验没有有效发挥其应有的数据价值。
目前,基于自然语言处理的知识库系统已经在电网、客服、医疗、旅游等领域取得了良好的应用效果[5-9]。为解决发电企业文件系统和传统知识库系统的弊端,本文提出了一种基于自然语言处理的发电设备知识库系统,可以有效提升发电设备文本知识的查询效率。
1 基于自然语言处理的知识库系统架构设计
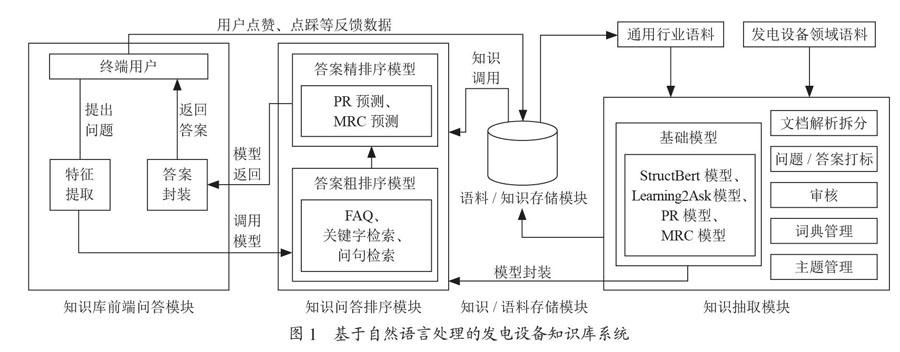
如图1所示,基于自然语言处理的发电设备知识库系统主要包含4个模块:知识抽取模块、知识/语料存储模块、知识问答排序模块和知识库前端问答模块。
各模块具体内容为:
(1)知识抽取模块。该模块包含了文档解析拆分、问答/答案打标、数据清洗、审核等语料数据预处理功能,以及词向量预训练(StructBert)、机器学习提问(Learning2Ask)、篇章排序(PR)、机器阅读理解(MRC)等用于知识抽取的基础模型训练。训练好的模型经过封装后还用于知识问答排序模块进行答案预测。词典管理、主题管理等功能可以配置行业同义词和知识主题,用以提高知识抽取的准确率。
(2)知识/语料存储模块。该模块用于存储语料数据、抽取的知识数据以及终端用户针对答案进行点赞和点踩的反馈数据。语料数据用来进行知识抽取模块中模型的训练,知识数据将为知识问答排序模块提供答案,用户反馈数据用来优化模型训练效果。
(3)知识问答排序模块。该模块包括答案粗排序模型和答案精排序模型,用于对知识问答的答案进行排序。粗排序模型中主要有常用问答对(FAQ)、关键词检索(ES)、问句检索等算法引擎[10-14];精排序中主要有知识抽取模块中训练并封装后的PR和MRC模型。
(4)知识库前端问答模块。该模块主要包含用户交互、特征提取、答案封装等功能。用户交互功能可以获取用户提出的问题,并返回封装后答案;特征提取主要用于针对问题的分词、扩词纠错、用户特征识别等特征提取过程;答案封装主要用于针对知识问题排序模块返回的多条答案进行组装展示。
2 发电设备知识库系统构建
2.1 知识抽取基础模型训练
2.1.1 发电设备领域Bert模型训练
本系统采用的是融合语言结构的Bert预训练模型(StructBert),通过在训练任务中增加词序(Word-level ordering)和句序(Sentence-level ordering)两项任务,来解决传统预训练语言模型BERT在预训练任务中忽略了语言结构的问题[15,16]。首先,将大规模的通用行业语料文档进行数据预处理,并训练生成通用行业的StructBert预训练模型,再通过数据预处理后的发电设备领域语料将其微调至针对发电设备领域的StructBert模型。
2.1.2 Learning2Ask模型训练
Learning2Ask模型是根据一段自然语言文本而生成问题的模型[17]。本系统采用基于StructBert预训练模型的自然语言生成模型来实现机器自动生成问题。首先,将训练生成的发电设备领域的StructBert预训练模型作为编码器,并用于问题生成模型的初始化,再搭建一个解码器来产生问题。
2.1.3 PR&MRC模型训练
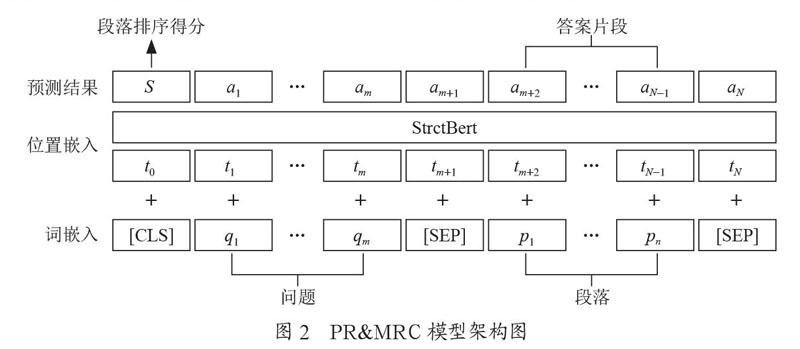
篇章排序模型(PR)用于匹配问题与段落的相关性,为用户提出问题答案所在的候选段落集进行排序[18]。其具体任务描述为:给定一个三元组(Qi,Pi,Si),根据问题Qi=[q1,q2,…,qm]和相對应的篇章段落Pi=[p1,p2,…,pn],通过自然语言理解,推理给出问题Qi与段落Pi的相关性评分Si,再根据Si进行排序。其中,qi是问题的某个词语,pi是段落的某个词语,m为问题的长度,n为段落的长度。
机器阅读理解模型(MRC)是利用机器来阅读特定的文本段落并回答给出的问题[19,20]。其具体任务描述为:给定一个三元组(Qi,Pi,Ai),根据问题Qi=[q1,q2,…,qm]和相对应的篇章段落Pi=[p1,p2,…,pn],通过自然语言理解,推理给出问题答案Ai。其中,qi是问题的某个词语,pi是段落的某个词语,m为问题的长度,n为段落的长度。
上述两个模型输入均为问答文本和段落文本候选集,故本系统采用PR模型与MRC模型综合考虑的方式,搭建PR&MRC模型,其模型输出为段落排名分数和答案,模型架构如图2所示。
2.2 发电设备知识抽取
2.2.1 前处理过程
知识抽取前处理过程指发电设备语料文本经过粗拆、精拆形成一个个知识点(答案)的过程,如图3所示。
首先,将语料文本利用文档序号层级、标点符号识别等规则进行粗拆处理形成段落,段落字数要求控制在500字以内,然后将段落再精拆处理形成答案。根据精拆处理方法不同,前处理过程可以分为2种方式:
方式1(规则拆解):在粗拆形成段落后,再利用规则拆解的方法进行精拆处理得到答案;
方式2(规则拆解+MRC抽取):在粗拆形成段落后,同时利用规则拆解的方法和抽取式MRC方法进行精拆处理得到答案。抽取式MRC是指机器通过阅读问题和文章后,从原文中抽取一段连续文本作为答案[21,22]。
2.2.2 后处理过程
知识抽取后处理过程指文本精拆处理后产生的答案经过Learning2Ask模型自动生成问题、PR模型篇章排序过滤后形成FAQ并存储至语料/知识存储模块,如图3所示。根据机器自动提问流程不同,后处理过程也可以分为2种方案:
方案1(串行):精拆后生成的答案和对应的段落<段落,答案>,输入至Learning2Ask模型中自动生成问题,再将<问题,段落>输入至PR模型中进行过滤,置信度高的<问题,答案,段落>将以三元组形式作为知识存储起来,置信度低的<问题,答案,段落>将提取出来作为数据集,对PR模型进行增强训练。
方案2(串行+MRC校验回路):与方案1不同的是,将<段落,答案1>输入至Learning2Ask模型生成问题后,再将问题输入至MRC模型进行预测生成答案2,并对答案1、答案2进行一致性检查,只有通过一致性检查的<问题,答案,段落>才能进入PR模型过滤过程,未通过一致性检查的<问题,答案,段落>提取出来作为数据集,对MRC模型进行增强训练。
2.3 发电设备知识问答
用户在知识库前端问答模块输入问题后,知识库系统针对问题进行分词、扩词等过程提取问题特征,并输入到知识问答排序模块中进行答案粗排序。利用ES关键词检索引擎从知识库中选取候选FAQ集,通过用户问题文本与候选FAQ集中的问题文本进行相似度匹配,如果相似度大于设定的阈值,则输出相应FAQ中的答案文本封装后返回用户;如果相似度小于设定的阈值,则将用户问题文本、候选FAQ集中的段落文本输入到PR&MRC模型中进行预测,并将预测答案封装后返回用户,如图4所示。用户评估答案后进行点赞或点踩,系统收集用户反馈信息后对PR&MRC模型进行增强训练。知识库系统问答效果示例如图5所示。
3 不同知识抽取方案的知识问答效果对比
将某电厂80份发电设备相关技术文件利用设备知识库系统进行知识拆解,并利用人工标注的方式从80份文件中提取3 000个问答对进行知识库问答效果验证,不同知识抽取方案的知识问答准确率如表1所示。
由图6可以看出,4种不同知识抽取方案的知识问答Top1准确率到Top5准确率都有明显的提升,方案1的Top5准确率达到76.7%,说明基于自然语言处理的发电设备知识库系统具有较好的问答效果;由表1可得,针对知识问题Top1准确率和Top3准确率,前处理过程中增加MRC生成模型可以提升4.4%~5.8%,后处理过程中增加MRC校验回路可以提升2.3%~3.7%,说明在前处理过程中增加MRC生成模型相对于后处理过程增加MRC校验回路提升问答准确率效果更加明显;但从图6可以看出,方案3在Top1和Top3的准确率虽然高于方案2,但方案2的Top5准确率提升较大,并且超过方案3的Top5准确率,说明后处理过程中增加MRC校验回路在对答案排名要求较低的场景应用效果较前处理过程中增加MRC生成模型的效果更好;知识问答准确率最高的是方案4,可见同时在前处理过程中增加MRC生成模型和在后处理过程中增加MRC校验回路,将显著提升设备知识库的问答准确率。
图6 不同知识抽取过程的知识问答效果对比图
4 结 论
为提升文本知识的查询效率,文章提出一种基于自然语言处理的发电设备知识库系统,包括知识抽取、语料/知识存储、知识问答排序和知识库前端问答等4个模块。利用发电设备领域语料训练得出的StructBert、Learning2Ask、PR&MRC模型能有效实现发电设备知识抽取,完成设备知识库构建。
4种不同知识抽取方案中,知识问答的Top5准确率最低达到78.1%,说明知识库系统具有较好的问答效果;针对知识问题Top1准确率和Top3准确率,在前处理过程中增加MRC生成模型相对于后处理过程增加MRC校验回路提升问答准确率效果更加明显;而后处理过程中增加MRC校验回路在对答案排名要求较低的场景应用效果较前处理过程中增加MRC生成模型的效果更好;同时在前处理过程中增加MRC生成模型和在后处理过程中增加MRC校验回路,将显著提升设备知识库的问答准确率。
参考文献:
[1] 李广伟,王永.火力发电机组日常性能检测的流程及结论规范化研究 [J].锅炉制造,2020(3):21-23.
[2] 刘青,车鹏程.某电厂2#炉高再异种钢焊口裂纹原因分析报告 [J].锅炉制造,2019(4):47-49+52.
[3] 任纪兵.基于.NET的兴隆电厂档案管理系统设计与实现 [D].成都:电子科技大学,2016.
[4] 刘欣,李怡.文档管理在发电厂信息化管理中的应用 [J].信息技术与信息化,2016(10):36-38.
[5] 李佳,杨婷婷,刘伟.数字多媒体旅游咨询信息智能问答系统设计 [J].现代电子技术,2017,40(12):66-68+71.
[6] 汤伟,杨铖.智能检索技术在电网调度本体知识库中的应用 [J].自动化与仪器仪表,2019(2):193-196.
[7] 佟佳弘,武志刚,管霖,等.电力调度文本的自然语言理解与解析技术及应用 [J].电网技术,2020,44(11):4148-4156.
[8] 陆婕,李少波.基于知识库的智能客服机器人问答系统设计 [J].计算机科学与应用,2019,9(11):7.
[9] 管棋,蔡荣杰,杨小燕,等.智能问答系统在乳腺疾病影像领域的研究与应用 [J].实用放射学杂志,2019,35(7):1159-1163.
[10] 张琳,胡杰.FAQ问答系统句子相似度计算 [J].郑州大学学报(理学版),2010,42(1):57-61.
[11] 梁敬东,崔丙剑,姜海燕,等.基于word2vec和LSTM的句子相似度计算及其在水稻FAQ问答系统中的应用 [J].南京农业大学学报,2018,41(5):946-953.
[12] 周映,韩晓霞.ElasticSearch在电子商务系统中的应用实例 [J].信息技术与标准化,2015(5):72-74.
[13] 张建中,黄艳飞,熊拥军.基于ElasticSearch的数字图书馆检索系统 [J].计算机与现代化,2015(6):69-73.
[14] 王宇,王芳.基于HNC句类的社区问答系统问句检索模型构建 [J].计算机应用研究,2020,37(6):1769-1773.
[15] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,Volume 1(Long and Short Papers).Minneapolis:Association for Computational Linguistics,2019:4171-4186.
[16] WANG W,BI B,YAN M,et al. StructBERT:Incorporating Language Structures into Pre-training for Deep Language Understanding [J/OL].arXiv:1908.04577v3 [cs.CL].(2019-08-13).https://arxiv.org/abs/1908.04577v3.
[17] DU X Y,SHAO J R,CARDIE C. Learning to Ask:Neural Question Generation for Reading Comprehension [C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).Vancover:Association for Computational Linguistics,2017:1342-1352.
[18] 龐博,刘远超.融合pointwise及深度学习方法的篇章排序 [J].山东大学学报(理学版),2018,53(3):30-35.
[19] 顾迎捷,桂小林,李德福,等.基于神经网络的机器阅读理解综述 [J].软件学报,2020,31(7):2095-2126.
[20] 张超然,裘杭萍,孙毅,等.基于预训练模型的机器阅读理解研究综述 [J].计算机工程与应用,2020,56(11):17-25.
[21] 曾俊.抽取式中文机器阅读理解研究 [D].武汉:华中师范大学,2020.
[22] WANG Z,LIU J C,XIAO X Y,et al. Joint Training of Candidate Extraction and Answer Selection for Reading Comprehension [C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Melbourne:Association for Computational Linguistics,2018:1715-1724.
作者简介:沈铭科(1991.11—),男,汉族,浙江丽水人,中级工程师,硕士,研究方向:智慧电站技术研究。
